基于多層感知機和近端策略優化的滾動軸承故障診斷方法
2024-02-20 06:38:14呂淵張西良
軸承 2024年2期
呂淵,張西良
(江蘇大學 機械工程學院,江蘇 鎮江 212013)
滾動軸承是工業生產中應用廣泛且極其重要的部件,研究滾動軸承工作狀態及其故障診斷方法有利于提升設備的穩定性,預防設備發生嚴重故障。滾動軸承在運行過程中出現磨損、腐蝕,甚至損壞等異常情況時,其振動信號幅值將逐漸升高。傳統的軸承故障診斷方法通過提取振動信號的時、頻域特征進行分析并判斷軸承性能是否衰退以及是否發生故障:文獻[1]提出基于自適應自相關譜峭度圖的滾動軸承故障診斷方法,通過譜峭度對振動信號進行人工判別;文獻[2]提出基于改進變分模態分解的滾動軸承故障診斷方法,采用模態分解進行故障判別。以上基于人工判別的方法需要專業的專家知識,面對龐大數據時低效且無法滿足要求,人工智能算法的優勢逐漸凸顯:文獻[3]提出基于變學習率多層感知機的軸承故障診斷方法,在不同學習率下觀測了多層感知機的診斷效果;文獻[4]采用深度學習卷積神經網絡結合支持向量機進行故障診斷;文獻[5]提出基于BP神經網絡的滾動軸承故障診斷。
然而,深度學習模型的泛化能力不強。強化學習具有自主學習以及強大的數據處理能力,能夠充分挖掘數據中的有效信息,從而準確診斷滾動軸承的故障類型,是目前主流的滾動軸承故障診斷方法[6]。基于價值函數的強化學習方法中比較典型的為Q 學習、深度Q 學習:文獻[7]提出基于深度Q 學習策略的旋轉機械故障診斷,利用深度學習提取信號特征,擬合當前狀態對應的Q 值,形成深度Q 學習模型完成對信號的診斷,識別準確率達到78%;文獻[8]將深度Q 學習和連續小波變換結合,通過卷積神經網絡擬合Q 函數,將環境返回的狀態輸入深度Q 網絡中學習故障數據具體的狀態特征表示,并據此表征學習策略,在樣本量有限的旋轉機械故障中診斷優勢突出;另外,文獻[9]提出了基于多尺度注意力深度強化學習網絡的行星齒輪箱智能診斷方法,文獻[10]提出了多Agent 深度Q 學習和模糊積分的行星齒輪箱故障診斷方法,文獻[11]提出了基于SAE 與深度Q網絡的旋轉機械故障診斷方法,文獻[12]提出了基于改進DQN網絡的滾動軸承故障診斷方法。以上基于價值函數的方法能夠較好的實現滾動軸承故障診斷,但仍存在策略固定,無法應對隨機策略、策略微弱變化導致的維度爆炸等問題,直接影響模型的穩定性和泛化能力。
強化學習的本質是學習策略,基于價值函數的方法通過學習價值函數或動作函數間接學習策略,導致其在連續空間和維度上存在很大缺點,同時動作的微弱變化直接影響策略函數是否選取動作,存在一定弊端;基于策略函數的方法直接建立策略函數模型,采用策略優化方式進行學習,文獻[13]提出了基于策略梯度的智能體,解決了因動作空間過大而無法收斂的問題,文獻[14]進一步解決了步長帶來的學習過程過緩問題,但仍存在難以選取懲罰系數的問題,文獻[15]提出的近端策略優化(Proxi?mal Policy Optimization,PPO)方法則消除了步長帶來的影響并解決了系數選取問題。因此,本文基于多層感知機(Multi?Layer Perceptron,MLP)網絡構建強化學習智能體以增強特征提取能力,基于近端策略優化方法進行策略梯度優化并對故障診斷目標進行函數擬合,從而實現滾動軸承故障診斷。
1 近端策略優化
1.1 強化學習
強化學習是智能體不斷與環境進行交互,通過反饋獎勵更新策略的馬爾可夫決策過程,主要由集合{S,A,P,R}組成,其原理為:智能體利用轉移概率矩陣P選擇動作集合A,動作A選擇與環境交互后改變狀態集合S,同時智能體獲取環境給出正負獎勵R并更新狀態轉移矩陣P[16],如圖1所示。
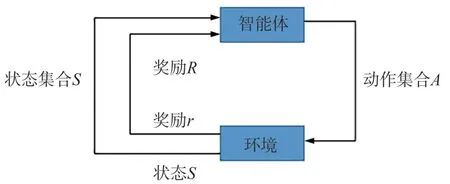
圖1 強化學習原理圖Fig.1 Schematic diagram of reinforcement learning
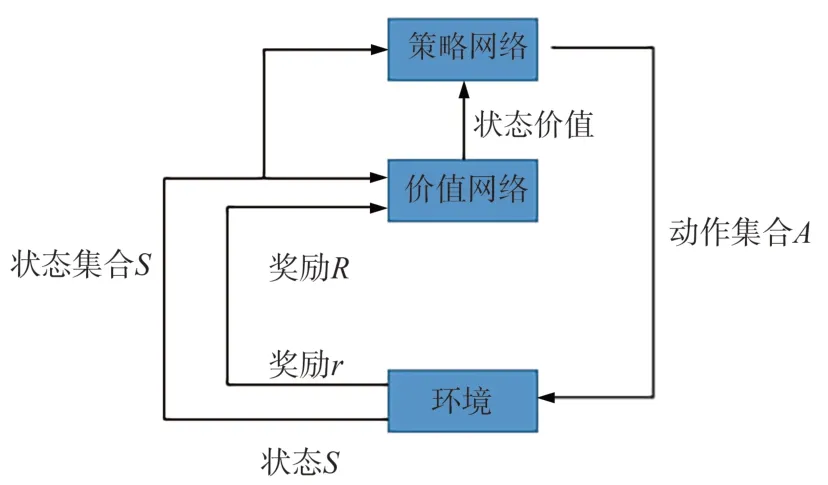
圖2 基于AC(Actor?Critic)框架的學習網絡Fig.2 Learning network based on AC(Actor?Critic)framework
1.2 策略梯度及其評估函數
策略梯度是一種基于策略函數,函數π采用神經網絡π(s|θ) =a將狀態s映射到動作a。π代表策略,a代表概率值,a值越大,代表對應動作被選中的概率越高。在學習過程中,學習對象為一組動作序列τ =(s0,a0,s1,a1,…,sT,aT),其發生的概率為
對該完整序列,經過環境與智能體交互獲得的獎勵總和記為R(τ)。對于給定參數θ的策略,其加權和的獎勵為
在環境與智能體交互中,每次獎勵的大小會通過權重參數η更新θ,即
由于θ同樣會影響獎勵的大小,需要求解最佳的策略參數θ以獲得最大獎勵。因此,以獎勵函數的期望公式作為目標函數對θ進行求導,即
基于策略函數的優勢在于:當動作集合A越來越大時,能夠高效找出此刻對應的動作, 進而與環境進行下一步參數更新,從而有效解決滾動軸承故障診斷數據量大,特征提取困難等問題。
1.3 近端策略優化
近端策略優化是一種策略梯度算法,對步長較敏感,因此選擇合適的步長是算法的關鍵。在訓練過程中,新舊策略的差異過大或過小均不利于學習。近端策略優化提出的新目標函數可以在多個訓練步驟中實現小批量的更新,從而解決了策略梯度算法中步長難以確定的問題。與信任區域策略優化(Trust Region Policy Optimization,TRPO)算法使用自然梯度下降計算參數不同,PPO?Clip 算法通過裁切動作似然比例實現KL 散度的約束,其目標函數可表示為
式中:ε為超參數,通常設為0.1 或0.2;rt(θ)的加入是基于重要性采樣,保證數據的充分利用和學習效率的提升,用于生成策略的數據可以重復利用且同時保證數據的一致性,使策略參數由θ′向θ更新;A?t為優勢函數;V?(st)為st時刻的期價值;γ為折扣系數。
近端策略優化方法在實際訓練過程中基于AC(Actor?Critic)框架,需要引入一個價值網絡,單獨于環境進行互動,策略網絡利用價值網絡生成的參數進行訓練,從而達到數據的重復利用并提高訓練效率,進而快速準確地找到最佳策略。
2 基于多層感知機和近端策略優化的滾動軸承故障診斷方法
設訓練數據集為T={(x1,y1),(x2,y2),…,(xn,yn)},xn為第n個訓練樣本,yn為第n個樣本的真實標簽,采用AC 框架并基于多層感知機網絡構建強化學習智能體,將滾動軸承故障診斷看作智能體的識別過程,即由集合{S,A,P,R}組成一個序列決策任務[17?19],采用近端策略優化方法進行真實標簽擬合。
2.1 AC框架網絡
近端策略優化算法基于AC 框架,即智能體由策略網絡(Actor?network)和價值網絡(Critic?network)組成[20],策略網絡負責與環境互動收集樣本,包含2 個多層感知機網絡,一個與環境進行交互,另一個進行參數更新;價值網絡負責評判動作好壞,包含1 個多層感知機網絡,輸入為環境的狀態,輸出為該狀態的價值。
由(7)式可知,價值網絡對當前序列進行評估并給出當前評估的價值結果V?(st),策略網絡則獲取當前序列的平均。為提高訓練的準確性,將二者的結果進行結合,即將當前序列相對于價值網絡評價結果的優勢記為實際獎勵。
2.2 基于MLP-PPO的故障診斷模型
基于多層感知機的智能體內部神經網絡結構主要包含輸入層、2層隱藏層和輸出層,各層之間為全連接結構,每層都有自己的權重系數,如圖3所示。

圖3 基于多層感知機的智能體網絡結構Fig.3 Structure of agent network based on multi?layer perceptron
網絡各層均包含多個神經元,輸入神經元X=[x1,x2,…,xn],神經元權重W=[w1,w2,…,wn],對神經元添加偏移量可得其隱式特征值,即
特征值通過激活函數運算后輸出。
本方法包含2個多層感知機神經網絡,價值網絡輸出當前價值至策略網絡并用于獎勵期望計算,策略網絡依據期望大小更新策略。
2.3 滾動軸承故障診斷的主要步驟
滾動軸承故障診斷流程如圖4所示,主要步驟如下:
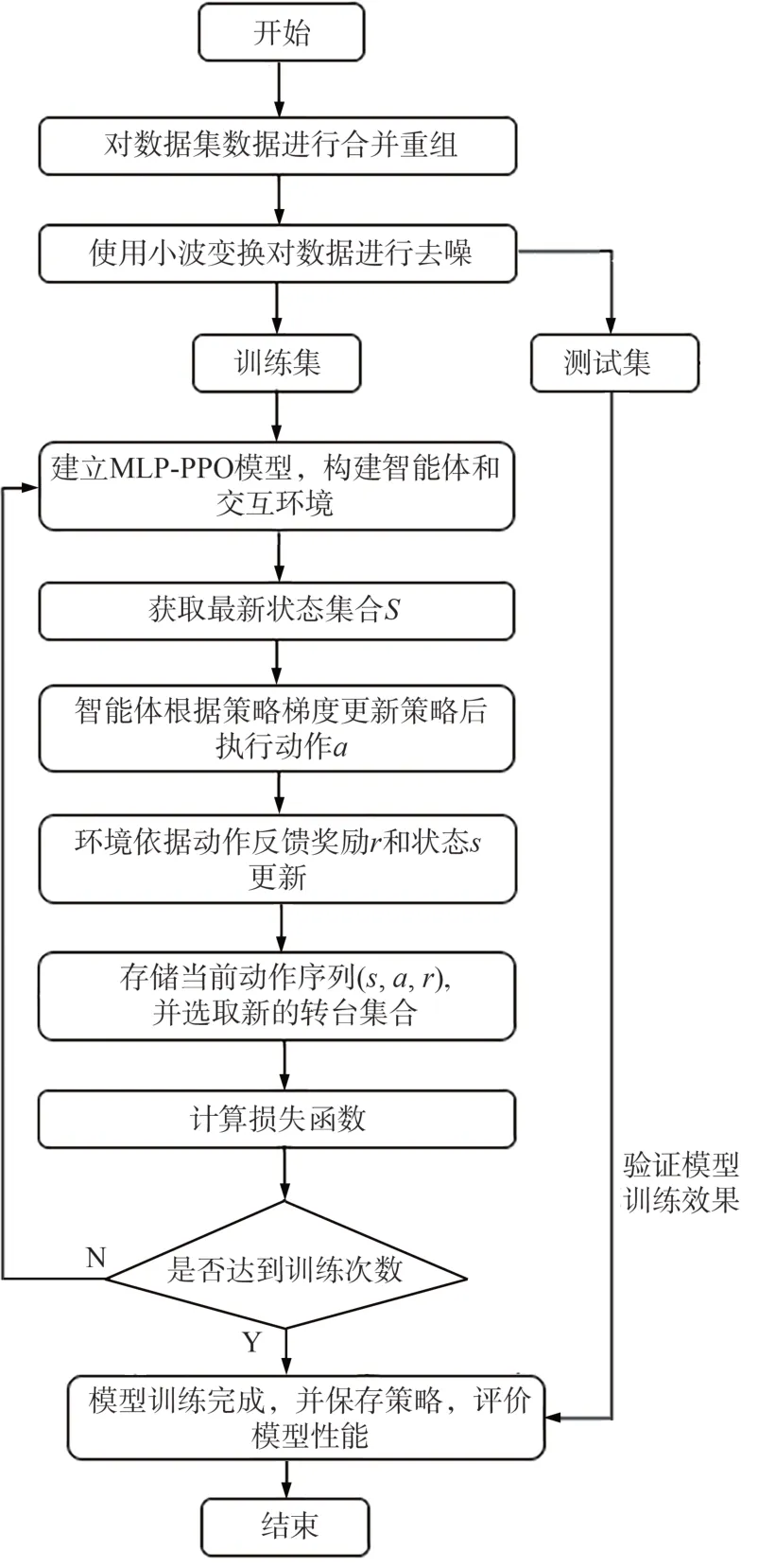
圖4 基于MLP?PPO的故障診斷流程Fig.4 Flowchart of fault diagnosis based on MLP?PPO
1)對網絡輸入數據進行濾波處理,采用小波變換去除噪聲,同時對數據進行重整后分成訓練集和測試集。
2)構建交互環境,設置多層感知機智能體中策略網絡、價值網絡的層數和神經元個數。
3)設置智能體與環境迭代次數、獎勵大小以及單次數據訓練的步長。
4)在智能體與環境交互中,智能體獲取當前最新數據并由策略網絡生成策略參數和平均獎勵總和,策略網絡數據同時批量更新至價值網絡并由其當前參數更新評價結果,與策略網絡生成的帶權重獎勵結合從而生成當前序列的實際獎勵。
5)完成單次更新后,由價值網絡進行重要性采樣,獲取新一批數據并進行計算,當達到訓練次數后完成第一批數據訓練,智能體再次更新數據源。
6)當所有數據訓練完成后,計算當前策略的損失函數是否滿足要求。
7)模型訓練完成后,利用測試集進行效果驗證并保存生成的結果。
3 試驗分析
試驗基于Windows10 系統,CPU 為Intel Core i7?9700f,GPU 為NVIDA RTX308016G,采用python 編程以及深度學習框架pytorch,基于Ope?nAI gym搭建環境。
MLP?PPO 模型包含3 個多層感知機網絡,每個網絡包含2 層大小均為128 的隱藏層并采用全連接方式進行連接,策略網絡中隱藏層的丟棄率為0.2,各層間采用ReLU激活函數,價值網絡輸出層的激活函數為Softmax,用于策略網絡中更新參數θ的學習率參數α為0.0003,權重λ為0.95,動量γ為0.99,迭代次數為1000,單步更新參數為3,單步輸入數據量為16,原始數據被切割為單份1024大小的樣本。
3.1 試驗數據集
采用西安交通大學滾動軸承加速壽命試驗數據集XJTU?SY[21]驗證MLP?PPO 模型的有效性,選取工況1(轉速2100 r/min,徑向載荷12 kN)的數據進行試驗,試驗軸承型號為LDK UER204,其具體參數見表1;采樣頻率為25.6 kHz,采樣間隔為1 min,每次采樣時長為1.28 s,具體工況信息見表2。

表1 LDK UER204軸承參數Tab.1 Parameters of LDK UER204 bearing

表2 XJTU?SY數據集工況1具體信息Tab.2 Specific information of condition 1 in XJTU?SY dataset
工況1 各軸承振動信號的時頻域波形如圖5所示:在相同工況下,軸承不同位置出現故障時,其振動信號呈現不同的趨勢,發生故障的時間以及振動幅值存在差異;隨著時間變化,軸承出現損傷時對應的故障特征頻率處能量加強,不同故障軸承的故障特征頻率及振幅均存在差異。
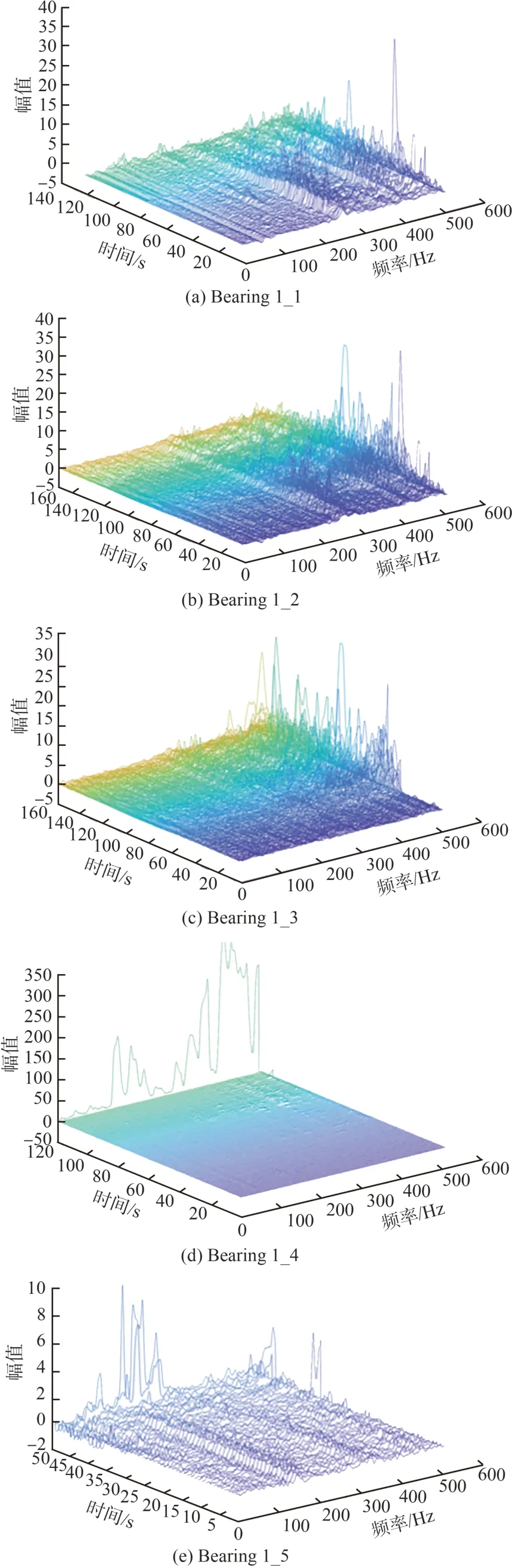
圖5 工況1各故障軸承的振動信號Fig.5 Vibration signals of each faulty bearing in condition 1
3.2 試驗過程
本次試驗對數據集進行故障分類,其中包括1類健康狀態(HEA),3類滾動軸承故障:外圈故障(ORF)、內外圈復合磨損故障(CWF)、保持架故障(BWF)。
實際訓練中選取每個故障類型的最后2次采樣數據作為訓練對象,原始數據中單個樣本的數據格式為1*32768, 數據量較大且需要在訓練過程中添加標簽,為有利于數據迭代訓練并盡可能使用完整數據,通過拆分重組將數據格式重整為30*1024,即輸入動作空間的數據格式為N*1024,N為實際所需訓練的樣本數量。實際訓練得到的模型準確率如圖6所示。
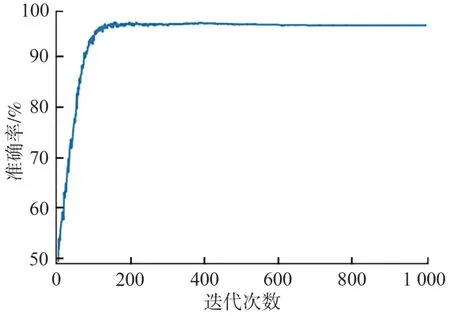
圖6 MLP?PPO模型訓練準確率Fig.6 Training accuracy of MLP?PPO model
3.3 試驗結果
從傳統機器學習、深度學習、強化學習中選取代表性的方法進行對比分析,各網絡的參數設置如下:
1) 支持向量機(SVM),利用主成分分析將振動信號降維至4個特征,利用SVM 進行識別,其采用高斯徑向基核函數,核系數為 0.01;
2) 卷積神經網絡(CNN),設置2 個卷積層,2 個池化層和1 個全連接層,卷積核尺寸為3*3,激活函數為ReLU;
3) 深度Q 學習(DQN),智能體采用多層感知機,設置一層隱藏層,激活函數為ReLU,迭代次數為20000。
各模型在訓練集、測試集上的故障診斷準確性以及訓練耗時見表3:本文所提MLP?PPO 模型的準確率為96%(混淆矩陣如圖7 所示),與SVM,CNN 和DQN 模型相比準確率分別提升了31%,24%和18%;MLP?PPO 模型中智能體與環境之間需進行大量數據信息交互,因此其訓練耗時大于其他模型,但模型訓練完成后的實際診斷耗時僅1 s,能夠較快速的完成故障診斷任務。
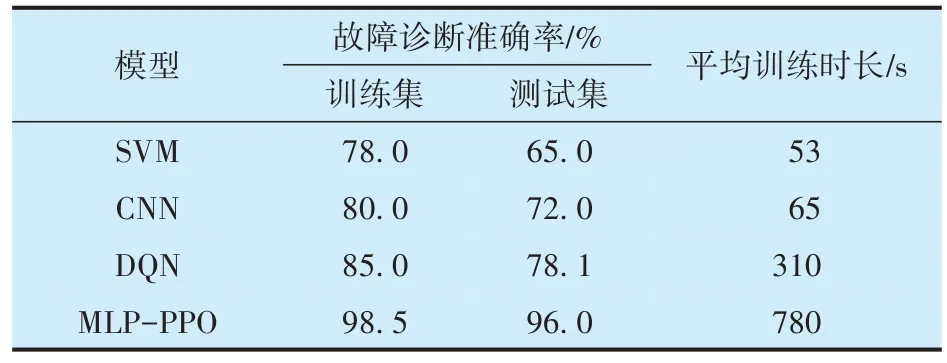
表3 基于不同模型的故障診斷結果Tab.3 Fault diagnosis results based on different models
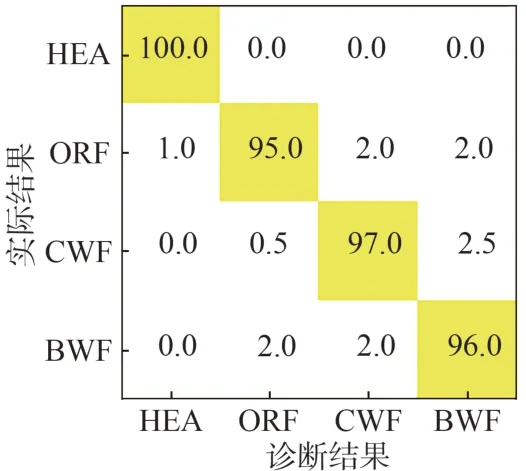
圖7 MLP?PPO對測試集診斷結果的混淆矩陣Fig.7 Confusion matrix of test set diagnostic results of MLP?PPO model
4 結束語
基于強化學習策略函數理論,提出了基于多層感知機和近端策略優化的滾動軸承故障診斷方法,利用多層感知機構建強化學習智能體并通過近端策略優化算法,實現對不同工況下滾動軸承的故障診斷,其具備以下優點:
1) 利用強化學習自主挖掘信息優勢,充分挖掘數據特征,結合策略梯度優勢可以很好地擬合故障診斷目標函數,無需人工干預且自主完成滾動軸承故障診斷。
2) 結合AC 框架,充分利用多層感知機網絡完成智能體與環境的互動,自主學習的模式充分提升了滾動軸承故障診斷的準確性。
3) 與傳統的SVM,CNN 以及基于價值函數的DQN方法相比,MLP?PPO的故障診斷準確率更高。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
