大數據如何影響勞動收入份額?
——來自國家級大數據綜合試驗區的證據
2023-12-01 12:49:58高遠東
南方經濟 2023年11期
卜 寒 高遠東 尋 舟
一、引 言
近些年來,數據技術的進步、云計算的廣泛運用、物聯網的發展以及智能手機和社交媒體的普及使得世界步入了大數據時代(Pan et al.,2017)。大數據是指海量、高速增長、類型多樣和價值巨大的數據,它們來自各種不同的數據源,如社交媒體、移動設備、互聯網和傳感器網絡等(Chen et al.,2014)。目前,大數據已經滲透到生產、銷售、營銷以及售后的各個領域(Li,2020),成為可以與物質資產、人力資本相媲美的重要生產要素(謝康等,2020),不僅在促進經濟增長、提高生產效率、提升創新能力、改善環境等方面發揮著重要作用(楊俊等,2022;張葉青等,2021;Ghasemaghaei and Calic,2020;許憲春等,2019),同時改變了傳統生產函數形式(劉國武等,2023),沖擊了傳統要素收入分配結構,并對勞動收入份額產生了重要影響。從理論上看,大數據對勞動收入份額的影響是復雜的。一方面,大數據能夠通過緩解融資約束、創造新任務(Begenau et al.,2018;Gardiner et al.,2018),提高勞動收入份額(Duygan-Bump et al.,2015;Acemoglu and Restrepo,2019)。另一方面,大數據會進一步推動自動化技術快速發展與廣泛應用(Helbing,2019),導致勞動收入份額降低(Acemoglu and Restrepo,2019)。然而,遺憾的是,現有研究并未從理論和實證上充分回答大數據是否以及如何影響勞動收入份額。
黨的二十大報告明確強調,要“努力提高居民收入在國民收入分配中的比重,提高勞動報酬在初次分配中的比重”。勞動收入份額的增長,不僅關系著國內大循環新發展格局的形成,更是保證全體人民共享經濟發展成果、推動更多人群邁入中等收入行列和實現共同富裕的重要機制(鈔小靜、周文慧,2021)。伴隨著數字經濟的快速發展,如何在數據要素的沖擊下穩定并提升勞動收入份額就顯得尤為關鍵。因此,從理論和實證上深入探索大數據與勞動收入份額的關系,有助于準確把握數字經濟時代數據要素對要素收入分配結構的綜合效應,為政府制定大數據相關的產業政策、深化收入分配制度提供理論依據與經驗證據。
中國一直致力于推動大數據的發展。2015 年8 月,國務院印發了《促進大數據發展行動綱要》,將大數據作為國家重要戰略進行全面部署,并提出開展國家級大數據綜合試驗區建設。國家級大數據綜合試驗區建設是我國推動大數據發展邁向實際應用的重要一步①國家級大數據綜合試驗區建設如何推動大數據發展在政策描述部分進行了進一步說明。,具有里程碑意義。該試點政策的實施為研究大數據與勞動收入份額的關系提供了絕佳機會。一方面,國家級大數據綜合試驗區試點政策的實施對企業勞動收入份額而言,是相對外生的。因為國家級大數據綜合試驗區建設的初衷是為了在數據資源管理、數據資源整合、數據資源共享、數字資源應用等方面做探索,從而發揮其輻射作用和示范作用(陳文、常琦,2022)。另一方面,國家級大數據綜合試驗區分批確定名單,使得在不同時間點存在差異化的實驗組和對照組樣本,讓本文可以在錯層發生事件形成的準自然實驗情境下構建雙重差分模型,更為清晰地揭示大數據與勞動收入份額變化的因果關系。
為此,本文嘗試利用上市公司微觀層面的勞動收入份額數據,對大數據是否以及如何影響勞動收入份額展開研究。與以往研究相比,本文可能存在的邊際貢獻有:第一,本文在理論和實證上深入探討了大數據對勞動收入份額的影響,不僅豐富了勞動收入份額影響因素的相關研究,而且拓展了大數據經濟后果的研究視角。盡管信息通訊技術(ICT)、人工智能、智能機器人、企業數字化轉型對勞動收入份額的影響已有部分研究進行了探討(Karabarbounis and Neiman,2014;郭凱明,2019;Acemoglu and Restrepo,2020;黃逵友等,2023),但對大數據與勞動收入份額之間的直接關系缺乏足夠的關注,這也成為了本文研究的一個重要缺口。第二,本文基于數據要素已經成為數字經濟發展的關鍵要素,能夠助推各類數字技術不斷深入發展這一基本事實,以大數據作為研究切入點,在一定程度上回應了“數字技術如何影響勞動收入份額”這一爭議性話題(黃逵友等,2023),進一步厘清了二者之間的關系,為數字經濟趨勢下收入分配結構的變動規律提供了新的證據。第三,本文通過將國家級大數據綜合試驗區試點作為我國大數據發展的一項準自然實驗展開研究,不僅有助于大數據與勞動收入份額之間因果效應的準確識別,而且豐富了國家級大數據綜合試驗區試點政策評估的相關文獻。在評估國家級大數據綜合試驗區試點政策效應的文獻中,學者們大多研究國家級大數據綜合試驗區建設對全要素生產率、企業創新等的影響(邱子迅、周亞虹,2021;陳文、常琦,2022),缺乏對勞動收入份額的探討。第四,大數據如何改變勞動收入份額的影響機制探究更是缺乏,本文提出并檢驗了表現為新任務創造效應、自動化擴張效應、自動化加深效應與融資約束緩解效應的影響機制,有助于更為全面地認識數字經濟時代下數據要素如何改變要素收入分配結構,為政府部門強化大數據在改善收入差距的作用提供了決策參考。
二、文獻綜述、政策背景與典型事實
(一)文獻綜述
勞動收入份額問題一直是經濟學關注的重要話題。大量研究探討了勞動收入份額變化的成因,但都未達成共識。Elsby et al.(2013)認為貿易和離岸外包是美國勞動收入份額下降的主要原因。Piketty(2014)強調了社會規范和勞動力市場制度在解釋勞動收入份額變化中的重要作用,比如工會和最低工資的實際價值等。Ergül and G?ksel(2020)發現技術進步能夠解釋20世紀80年代后大多數發達國家和發展中國家勞動收入份額的下降。Autor et al.(2020)發現超級明星企業的崛起是勞動收入份額下降的重要原因。還有一些研究從經濟增長(Rubin and Segal,2015)、金融發展(劉長庚等,2022)、資本市場開放(江軒宇、朱冰,2022)等方面研究了勞動收入份額變化的原因。
數字經濟時代下,數字技術作為技術進步的一種表現,其對勞動收入份額的影響也得到了學界的廣泛關注。理論上而言,數字技術對勞動收入份額的具體影響是不能確定的,這取決于資本對勞動的替代效應、產業部門之間的替代效應、生產率效應以及新任務創造效應的相對大小。首先,數字技術的發展與應用能夠降低資本設備成本以及推動生產方式進一步自動化和智能化,從而加快資本對勞動的替代,導致勞動收入份額降低(Karabarbounis and Neiman,2014;Acemoglu and Restrepo,2020)。其次,數字技術的發展與應用催生出新業態、新產業、新需求等,這會創造出勞動具有比較優勢的新任務,從而通過崗位增加所帶來的就業效應提升勞動收入份額(Acemoglu and Restrepo,2020)。然后,數字技術的發展與應用促進了傳統產業生產率提升,使得勞動需求增加,從而引起勞動收入份額增加(Acemoglu and Restrepo,2020)。最后,數字技術的發展與應用會造成生產要素在產業部門之間的差異,如果數字技術使得生產要素流動到資本密集型產業或者自動化產業,就會導致勞動收入份額下降(Aghion et al.,2018;郭凱明,2019)。從實證來看,一些研究從ICT、工業機器人、自動化、人工智能的角度發現了數字技術的應用顯著降低了勞動收入份額(Cette et al.,2022;Acemoglu and Restrepo,2020;鈔小靜、周文慧,2021)。然而,也有實證研究發現,人工智能以及數字化轉型能顯著提升企業勞動收入份額(金陳飛等,2020;黃逵友等,2023)。
綜上,盡管現有研究關注到數字技術對勞動收入份額的影響,但仍然存在幾點不足。第一,數字技術作用于勞動收入份額的本質在于,數據投入生產對原先的要素收入結構造成了沖擊。然而,現有研究在理論和實證研究上都忽略了數字技術是由數據驅動的本質,對數據要素與勞動收入份額之間的直接關系缺乏足夠的重視。第二,由于研究對象選擇的局限性,現有研究往往無法清晰地評估數字技術對勞動收入份額的作用機制。第三,現有研究在度量人工智能、自動化、數字化轉型、大數據應用等發展程度上仍然未能形成統一的標準,這會造成研究結論的偏差。本文通過選擇國家級大數據綜合試驗區建立這一外生沖擊研究大數據對勞動收入份額的影響及其作用機制,不僅補充了數字技術影響勞動收入份額的相關研究,而且在一定程度上彌補了上述三點不足。
(二)政策背景
隨著互聯網、5G、物聯網、云計算等信息技術的發展與普及,世界步入大數據時代。如何從大數據中發現知識并將其轉化為生產力已經成為贏得全球競爭的重要因素。近年來,中國和世界其他國家一樣,一直致力于推動大數據的發展。總體來說,我國大數據發展可以分為三個階段。第一個階段為初步階段。該階段位于2014年以前,更多的是對大數據理念和技術的探討,未能形成完整的體系。第二階段為落地階段。該階段位于2014年到2019年之間,大數據發展已經上升到國家戰略,大數據綜合試驗區有序推進,各個省份大數據相關政策陸續出臺。第三階段為深化階段。該階段位于2019年之后,數據已經正式成為新型生產要素,并明確提出數據要素是數字經濟發展的關鍵要素。
其中,國家級大數據綜合試驗區試點政策是中國推動大數據發展邁向實際應用的重要一步,具有里程碑意義。該試點政策主要從三個方面推動大數據發展。第一,建立健全的市場體系是大數據發展的重要基礎,大數據綜合試驗區通過建立法律法規、產業生態和安全保障體系等方式完善市場體系。第二,完善大數據基礎設施是大數據發展的必要保障,大數據綜合試驗區將加強大數據共享、交易、聚集和應用等平臺建設,從而形成完整的大數據基礎設施,以促進數據資源的共享和應用。第三,優質的數據資源是大數據發展的關鍵,大數據綜合試驗區將加大大數據產業投資,推動當地產業數字化,以提升數據資源的質量。這些舉措將有助于中國在大數據領域取得更大的進步,推動數字經濟的快速發展。
此外,盡管國家級大數據綜合試驗區與“寬帶中國”示范城市和智慧城市等一系列相近政策都能夠促進數字經濟和信息化的發展,但在政策目標、重點領域和實施手段等方面存在著本質差異,以推動多個方面的數字經濟發展和適應不同層面的需求。在政策目標方面,大數據綜合試驗區政策是以數據創新和應用為主要目標,通過充分挖掘和利用大數據的經濟社會價值,加速數字經濟的轉型升級;“寬帶中國”示范城市政策是以推進信息基礎設施建設為主要目標,通過提升網絡速度和質量,促進數字經濟發展;智慧城市政策的目標是建設具有智能化和互聯網化特征的城市,通過促進城市數字化、信息化發展,加強城市智能治理。在重點領域方面,大數據綜合試驗區政策主要關注大數據技術的創新和應用,以及大數據產業的發展;“寬帶中國”示范城市政策主要關注信息基礎設施建設,以及網絡速度和質量的提升;智慧城市政策則注重城市數字化、信息化建設,推動城市智能化和互聯網化發展。在實施手段方面,大數據綜合試驗區政策主要通過組建試驗區、推動科技創新、扶持創業創新等多種手段來推動大數據產業和應用創新;“寬帶中國”示范城市政策主要加強網絡基礎設施建設,如寬帶網絡覆蓋率的提升和網絡質量的優化;智慧城市政策主要是通過數字技術應用對城市管理進行變革,例如城市智慧交通、智能醫療等。
目前,大數據綜合試驗區總共分為兩批獲批建設。第一批建設名單為貴州省,于2015年獲批成為全國首個大數據綜合試驗區建設省份。第二批建設名單在2016 年公布,包括京津冀、珠江三角洲、上海、河南、重慶、沈陽以及內蒙古。至此,國內一共有八大大數據綜合試驗區,將共同引領東部、中部、西部、東北等“四大板塊”的大數據產業發展,實現數據共享、區域內協同發展、加快產業轉型。國家級大數據綜合試驗區的設立,將在大數據創新與應用、大數據產業發展、數據共享與利用等方面發揮示范與引領作用,進而推動我國大數據發展邁向新的臺階。
(三)典型事實
本文通過分別測算勞動收入份額整體趨勢變動以及非試點城市與試點城市勞動收入份額變化①城市勞動收入份額為城市內上市企業的平均勞動收入份額。,對試點政策與勞動收入份額之間的關系進行直觀上的探討。由圖1可知,勞動收入份額整體存在一個上升趨勢,這與現有的研究結論一致。另外,在2015 年大數據試點區第一批名單實施后,勞動收入份額整體有一定幅度的下降,而隨著2016年大數據試點區第二批名單實施,勞動收入份額整體又出現上升。與此同時,由圖2可知,在試點政策實施之前,非試點城市和試點城市勞動收入份額非常一致,變化趨勢相同。在試點政策實施之后,非試點城市和試點城市勞動收入份額出現明顯差異,試點城市的勞動收入份額水平開始顯著高于非試點城市的相應水平②圖1 與圖2都顯示在2020年勞動收入份額存在一個大幅度下降,這可能是由于新冠疫情所引起的反應。。因此,初步推斷大數據試點區的實施與勞動收入份額可能存在一定的正相關關系。

圖1 勞動收入份額整體變化趨勢
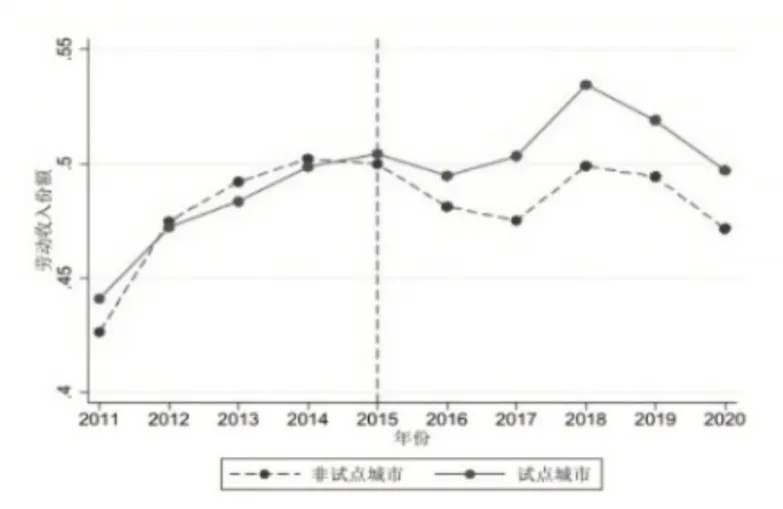
圖2 非試點城市與試點城市勞動收入份額變化
三、理論分析
本文在Acemoglu and Restrepo(2019)的任務模型框架下進行理論分析,包括構建基本模型與提出研究假說兩部分內容。
(一)基本模型
假設企業總產出是由一系列任務構成的服務(產品)生產,且服從C-D 函數形式:
其中,Y 為總產出;y(x)為任務x 提供的服務(產品);積分上限N 代表任務上限,定積分在[N-1,N]可積。之所以將積分下限和上限設定在N-1 到N 之間,是為了保證在任務總量不變(任務總量始終為1)的情況下考慮任務變化帶來的影響。
假設存在一個自動化界限I,任務x ∈[N - 1,I]能夠從技術上實現自動化,而任務x ∈(I,N]不能夠從技術上實現自動化。那么,任務x ∈[N - 1,I]既可以由勞動生產,也可以由資本生產,而任務x ∈(I,N]只能夠由勞動生產。因此,y(x)的函數可以進一步表示為:
其中,L( x )與C( x )分別為任務x的勞動投入與資本投入,τL( x )與τC( x )分別為勞動生產率與資本生產率。
為了簡化討論,進一步假設:
其中,W和R分別為勞動的均衡工資率與資本的均衡成本。第一個不等式意味著新任務會引起總產出的增加。第二個不等式意味著任務x ∈[N - 1,I]將全部由資本生產,即全部自動化。
在式(3)的假設下,任務x的勞動需求C(x) 為:
假設市場上總勞動供給L 是固定且無彈性的。那么,在市場出清的條件下,總的勞動需求可以表示為:
進一步地,可以得到市場的勞動收入份額LIS:
(二)研究假說
1.大數據、新任務創造與勞動收入份額
由式(6)對工作任務N求偏導:
由式(7)可知,創造勞動具有比較優勢的新任務能提高勞動收入份額。與此同時,大數據投入生產會形成新任務創造效應,增加對高、中低技能勞動力的需求。一方面,大數據中所提取的知識能夠直接用于改進決策和提高績效,進而幫助企業獲得競爭優勢(Shan et al.,2019)。因此,利用大數據獲得競爭優勢的企業發展戰略正在沖擊就業市場,形成了對統計人員、數據分析師、數據工程師、數據科學家以及處理數據的其他專業人員的強烈需求(Gardiner et al.,2018),有助于高技能勞動力就業。另一方面,大數據發展對平臺經濟、共享經濟發展的推動(Lobel,2018),進一步催生了更為靈活的數字勞動平臺(Schmidt,2017),從而產生了連接供給和需求兩端的新任務和新就業,如外賣配送員、網約司機、線上銷售、網絡主播等,這極大地增加了對中低技能勞動力的需求。基于上述分析,提出如下假說:
假說1:大數據通過新任務創造效應提升勞動收入份額。
2.大數據、自動化擴張與勞動收入份額
由式(6)對自動化界限I求偏導:
由式(8)可知,自動化擴張會降低勞動收入份額。這是因為自動化擴張會產生替代效應,將原先勞動執行的任務替換為更廉價的資本,導致勞動力的需求減少,降低了勞動收入份額(Acemoglu and Restrepo,2019)。與此同時,大數據的普及和發展將進一步推動自動化的擴張(Helbing,2019)。大數據能夠通過促進人工智能技術發展(Allam and Dhunny,2019)和推動農業、工業以及服務業機器人“智能化”(Li and Lai,2022),擴展機器人在生產和服務中的應用場景,引起更廣泛的自動化應用。不僅如此,大數據已經滲透到生產、銷售、營銷以及售后的各個領域(Li,2020),實現了部分程序自動化,例如個性化醫療服務、無人零售超市、物流智能分揀等。智能機器人應用邊界的擴展以及部分程序自動化的實現使得更多的不同技能勞動力面臨被替換的風險。基于上述分析,提出如下假說:
假說2:大數據通過自動化擴張效應降低勞動收入份額。
3.大數據、自動化加深與勞動收入份額
對式(5)求微分:
dln(Y N) dI 表示自動化擴張對生產率的影響即自動化加深效應(Acemoglu and Restrepo,2018)。由式(9)可知,如果自動化擴張能夠形成自動化加深效應,那么自動化加深效應就可以促使工資的增加來提升勞動收入份額。與此同時,大數據會促進生產率的提升(張葉青等,2021)。具體而言,大數據主要通過幫助企業決策、推動企業實現智能生產以及促進企業創新三個渠道提升企業生產率。第一,信息理論認為更詳細和準確的信息有利于決策者決策(Blackwell,1953)。由于大數據的存在,管理者可以更全面地衡量和了解自身業務以及客戶需求,并將這些知識直接轉化為改進的決策,提高生產率(Brynjolfsson et al.,2011)。第二,大數據通過物聯網實時自動采集,并將其應用于產品設計、生產計劃、制造和預測性維護等各方面,推動企業實現智能生產,從而帶來更高的生產率(He and Bai,2021)。第三,一方面,大數據可以通過提升企業新知識發現率與知識分享和合作能力促進企業創新(Ghasemaghaei and Calic,2020)。此外,大數據還能夠通過幫助企業充分了解客戶的產品和服務需求(Farboodi et al.,2019),提前分析并預測客戶的偏好,創造新的產品和服務。另一方面,創新能夠顯著促進企業生產率的提升(Mukhametzhanova et al.,2019)。基于上述分析,提出如下假說:
假說3:大數據通過自動化加深效應提升勞動收入份額。
4.大數據、融資約束與勞動收入份額
企業的投資行為和創新活動受到融資約束制約(Chen and Yoon,2022;趙揚、杜凱,2023)。那么,自動化升級與開發新產品和新服務勢必也會受到融資約束的影響,從而對勞動收入份額造成影響。不僅如此,融資約束所引起的留存利潤分配效應、流動性約束效應與要素配置效應同樣會制約勞動收入份額的增長(熊家財等,2022)。然而,大數據能夠有效緩解融資約束(Begenau et al.,2018)。一方面,大數據通過規避信息不對稱與道德風險緩解企業融資約束。信息不對稱與道德風險不利于企業獲得融資機會以及降低其利率(Armstrong et al.,2010;Momtaz,2021)。投資者可以通過使用大數據深度挖掘企業生產、交易、財務等信息,以盡量規避事前的信息不對稱。同時,在大數據的基礎上,投資者也可以運用機器學習、人工智能等技術,建立相應動態分控模型,以規避事后的道德風險。另一方面,大數據能夠助推數字金融平臺發展(Gomber et al.,2017),進而緩解融資約束(熊家財等,2022)。數字金融發展使得原來單調的融資服務更為多元,從而引起融資增量的提升。此外,數字金融發展帶來的市場競爭效應有利于傳統金融機構貸款利率的降低以及貸款意愿的提高。基于上述分析,提出如下假說:
假說4:大數據通過融資約束緩解效應提升勞動收入份額。
基于上述全部理論分析,提出如下假說:
假說5a:大數據能夠提升勞動收入份額。
假說5b:大數據能夠降低勞動收入份額。
四、研究設計
(一)計量模型
考慮到國家級大數據綜合試驗區試點地區并非在同一時點被批復,參考已有文獻(陳文、常琦,2022),本文使用多期雙重差分模型進行評估,具體模型設定為:
其中,被解釋變量LISit代表企業i在t年的勞動收入份額;核心解釋變量BDcit表示在t年企業i的注冊地所在城市c是否為國家級大數據綜合試驗區試點城市,是則取值為1,否則為0;δi和μt分別為公司固定效應和年份固定效應;?it為干擾項;Zt表示一系列影響勞動收入份額的控制變量,包括企業層面和城市層面的控制變量。θ為本文關注的核心結果,衡量了大數據對勞動收入份額的影響效果。
(二)變量選取
1.被解釋變量為勞動收入份額(LIS)。本文使用江軒宇、朱冰(2022)的要素成本增加值法度量勞動收入份額,即勞動收入份額(LIS)表示為“支付給職工以及為職工支付的現金”與“營業收入-營業成本+支付給職工以及為職工支付的現金+固定資產折舊”之比。
2.核心解釋變量為BDcit。若在t年企業i的注冊地所在城市c為國家級大數據綜合試驗區試點城市,BDcit取值為1,否則為0。
3.中介變量。(1)員工雇傭(EN_LN)。借鑒劉長庚等(2022)的做法,以企業職工人數自然對數作為其員工雇傭的代理變量。(2)全要素生產率(TFP_OP 和TFP_LP)。分別以OP 法和LP 法計算企業全要素生產率。(3)融資約束(SA)。以SA指數衡量企業融資約束程度。
4.控制變量。為了避免遺漏重要變量對估計結果造成的影響,參考施新政等(2019),江軒宇、朱冰(2022)等文獻,本文選取以下控制變量:企業層面的控制變量包括總資產自然對數(TA_LN)、總資產負債率(TALR)、銷售收入增長率(SRGR)、銷售毛利率(SGP)、上市年限自然對數(AGE_LN)、總資產收益率(RTA)、資本產出比(COR)、資本密集度(CI)、托賓Q(QB)、員工收入自然對數(INCOME_LN)、第一大股東占比(FP)、管理層持股比例(MSR)、董事會規模(BS)、獨立董事占比(IDR);城市層面的控制變量包括生產總值自然對數(GDP_ln)、年末人口總量自然對數(TP_ln)、產業結構(IS)、人均國際互聯網用戶數(PINTER)、人均移動電話用戶數(PMOBILE)、人均電信業務總量(PTB)。
(三)數據說明
考慮到國家級大數據綜合試驗區的批復時間以及數據的可得性,本文選取2011—2020年我國A股上市公司作為研究對象。在樣本處理過程中,參考施新政等(2019)以及江軒宇、朱冰(2022)的做法:(1)剔除金融和保險行業的上市公司;(2)剔除ST 和*ST 公司;(3)剔除關鍵變量缺失的樣本;(4)剔除勞動收入份額大于等于1 或者小于等于0 的樣本。經過上述處理,最終得到21927 個觀測值的非平衡面板數據①以勞動收入份額的樣本個數為最終樣本數據總量。。本文使用的企業數據來源于CSMAR 數據庫和Wind數據庫,城市數據來源于《中國城市統計年鑒》。主要變量的描述性統計結果見表1。
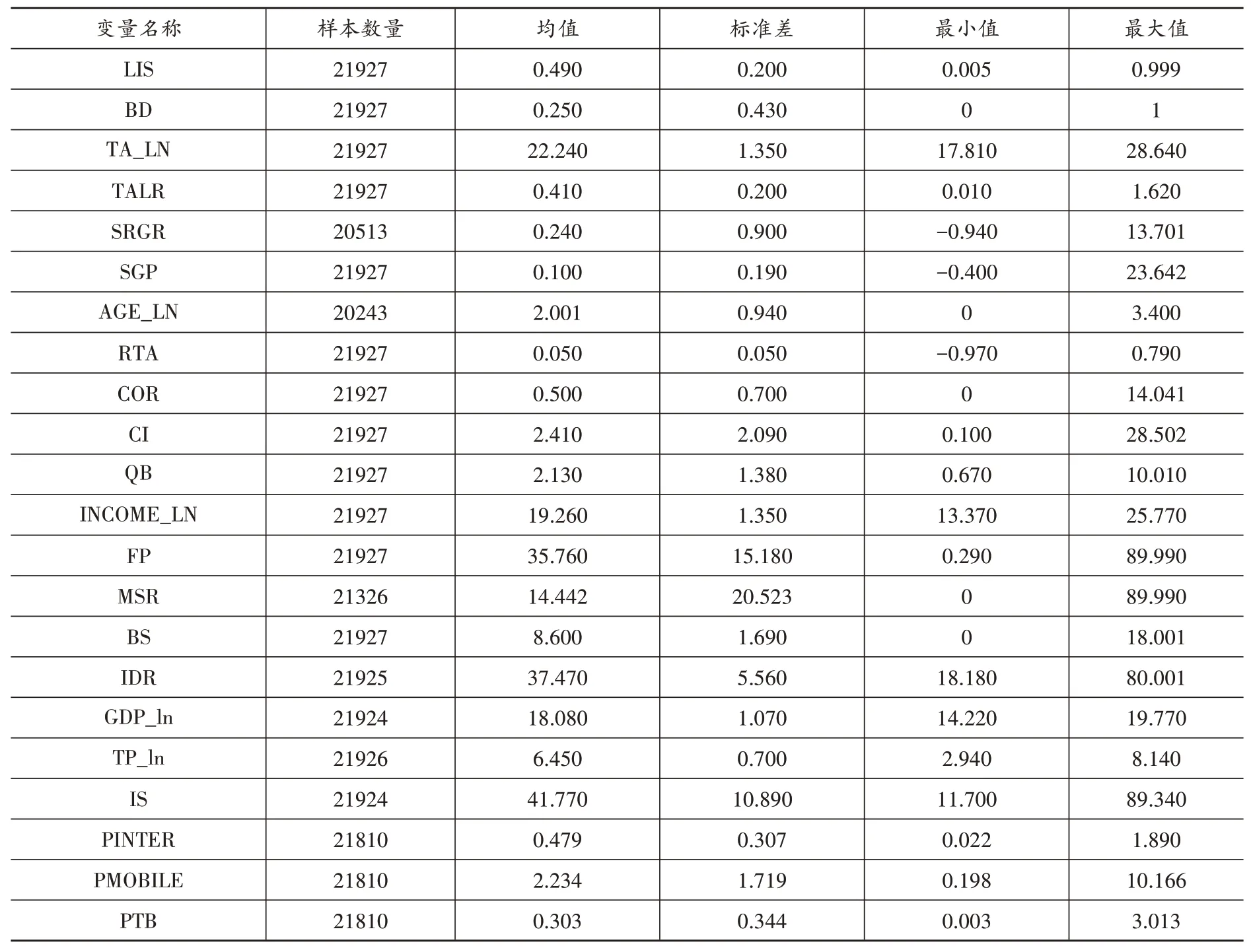
表1 變量描述性統計結果
五、實證結果與分析
(一)基準回歸結果
表2報告了多期DID 的基準回歸結果,其中列(1)僅考慮核心解釋變量;列(2)進一步加入企業層面控制變量;列(3)則加入全部控制變量。三個回歸結果顯示,虛擬變量BD 的回歸系數分別在10%、5%和1%的統計水平上顯著為正。該結果說明,國家級大數據綜合試驗區試點政策的實施顯著提高了試點城市企業的勞動收入份額。以列(3)為基準,從經濟意義看,國家級大數據試點政策實施后,試點城市企業的勞動收入份額平均提高了0.7個百分點。因此,假說5a初步得到驗證。
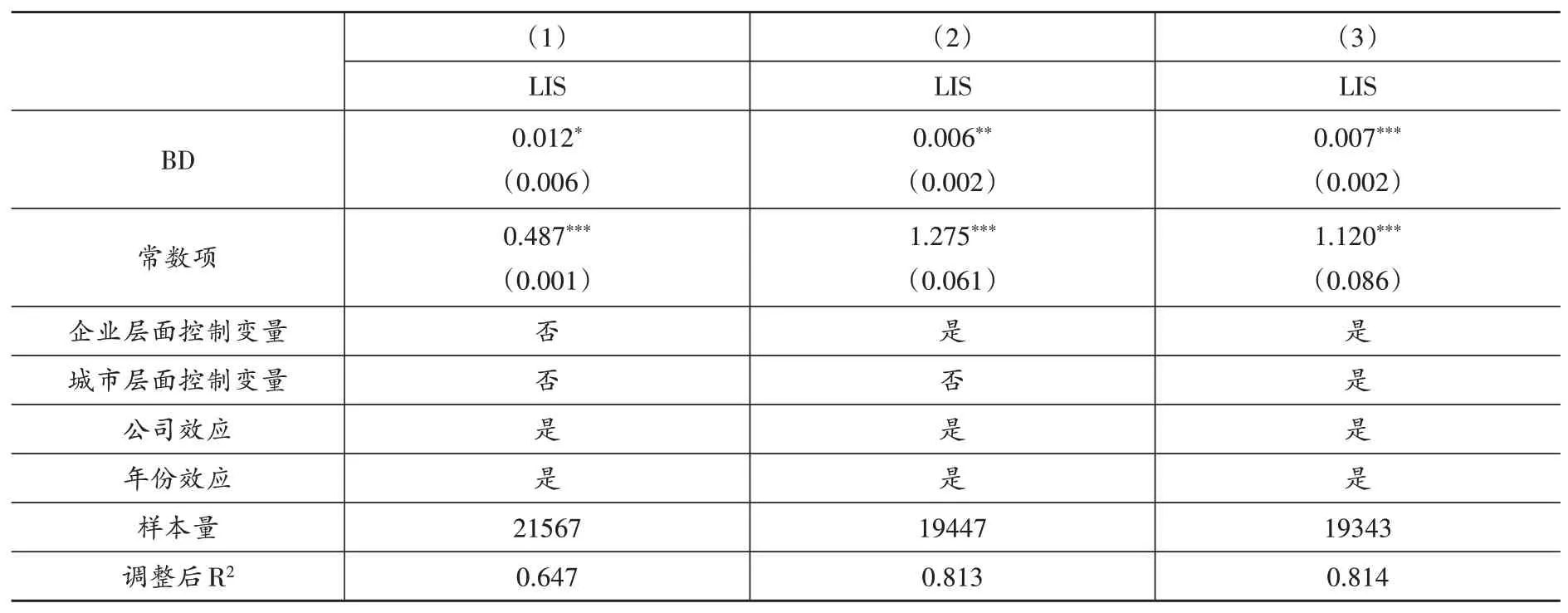
表2 基準回歸結果
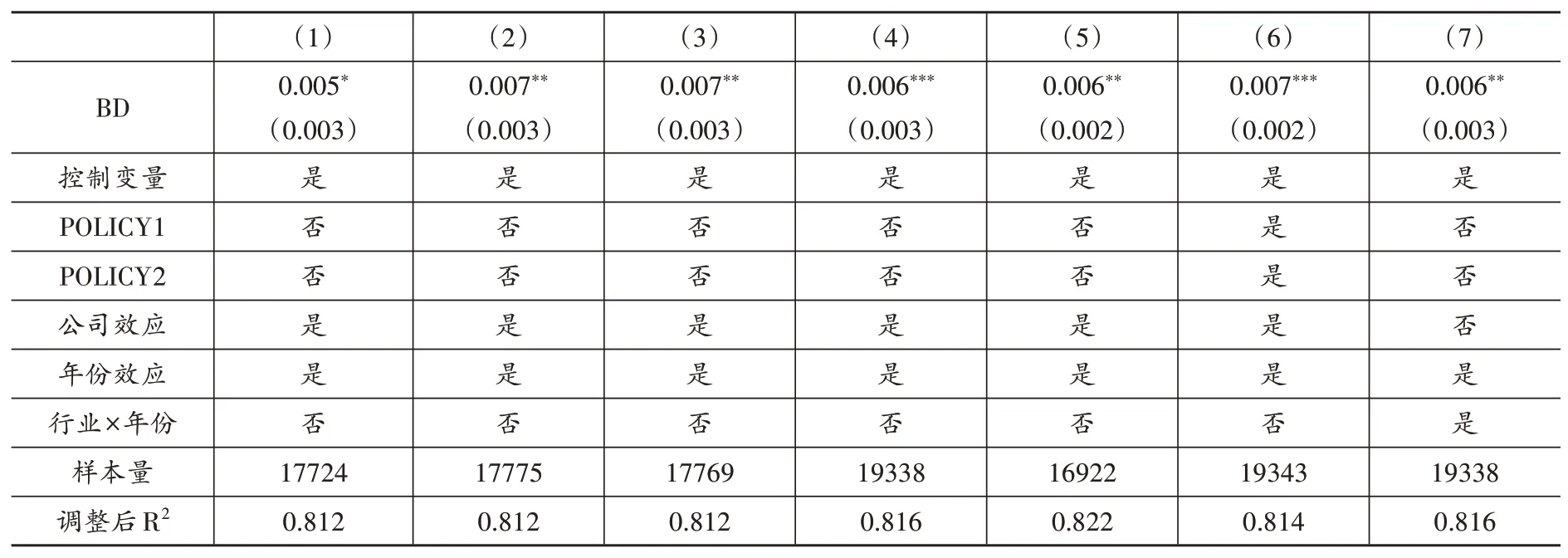
表3 穩健性檢驗
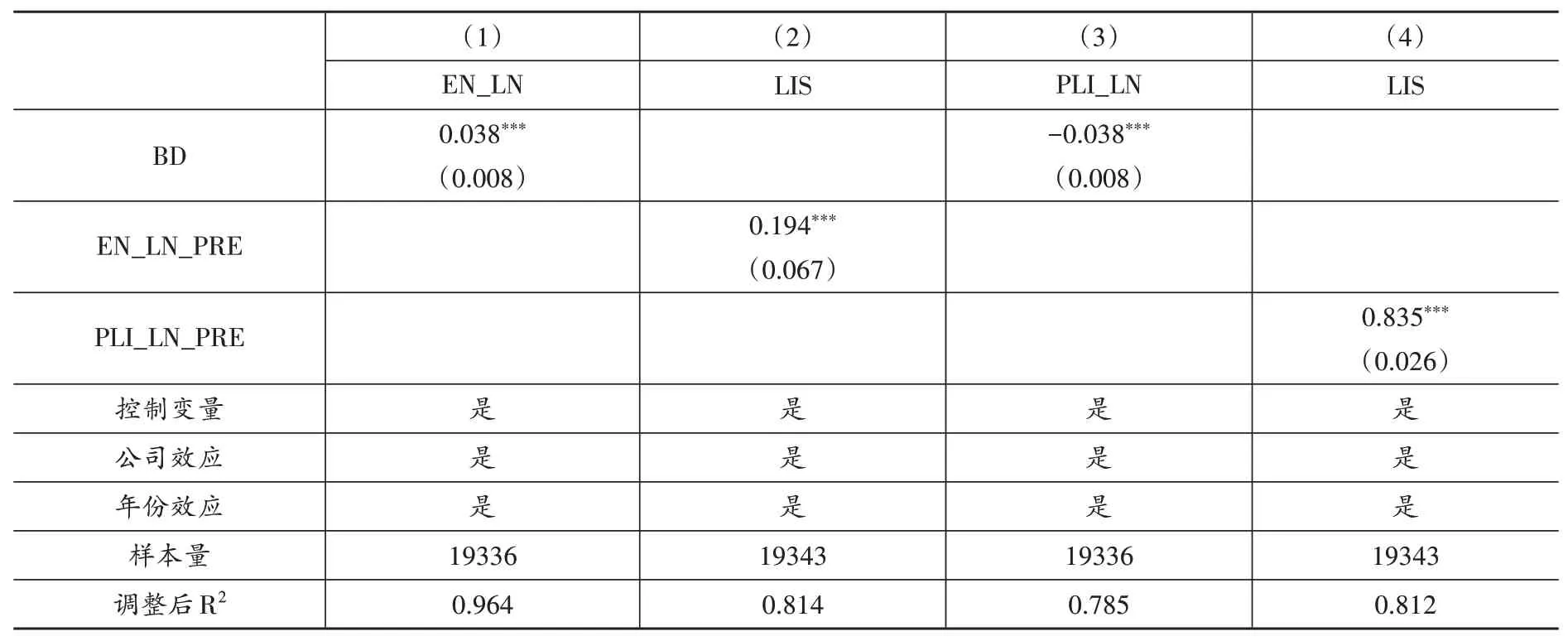
表4 新任務創造與自動化擴張
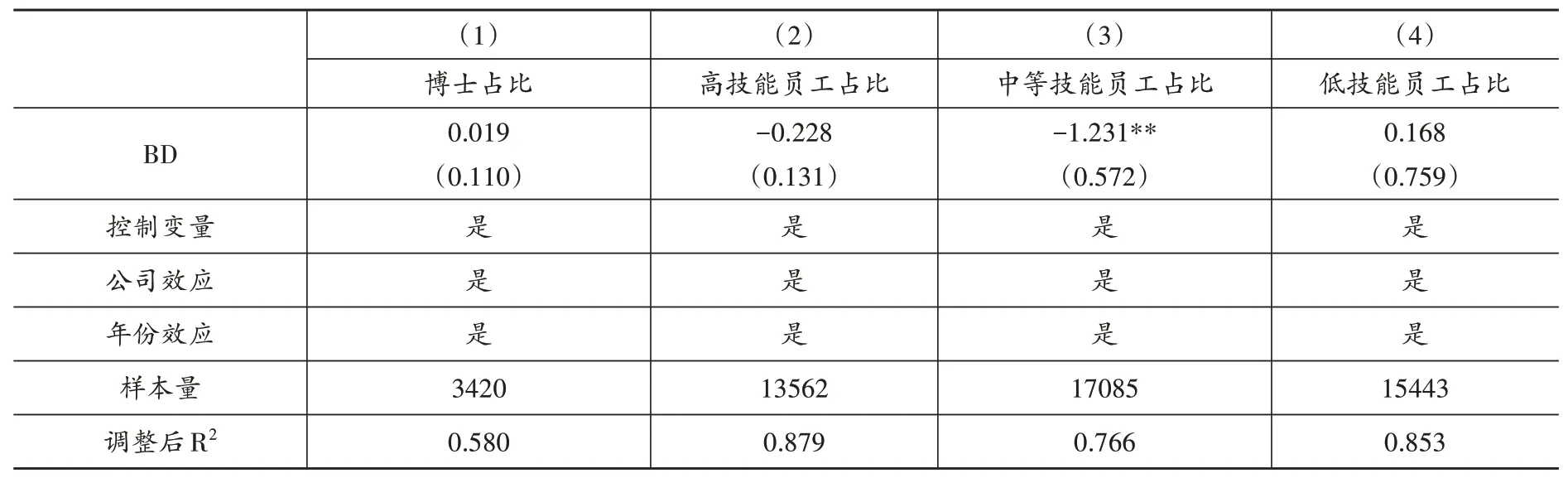
表5 大數據對不同類型員工的影響
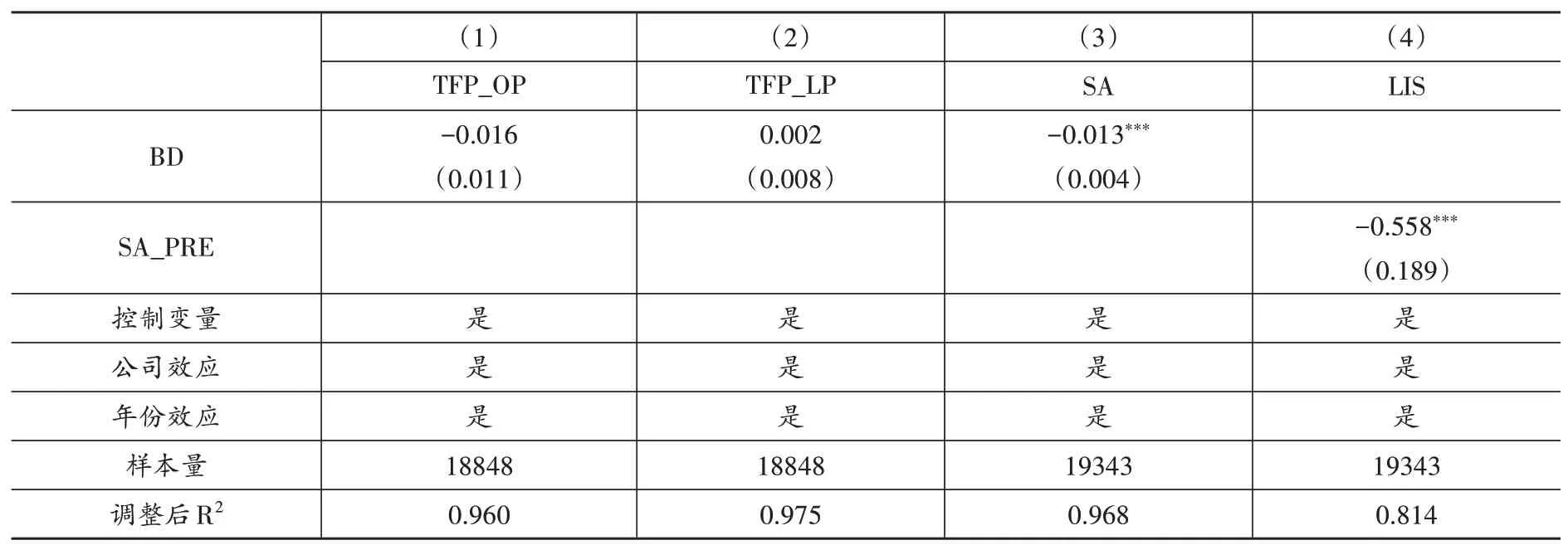
表6 自動化加深與融資約束緩解
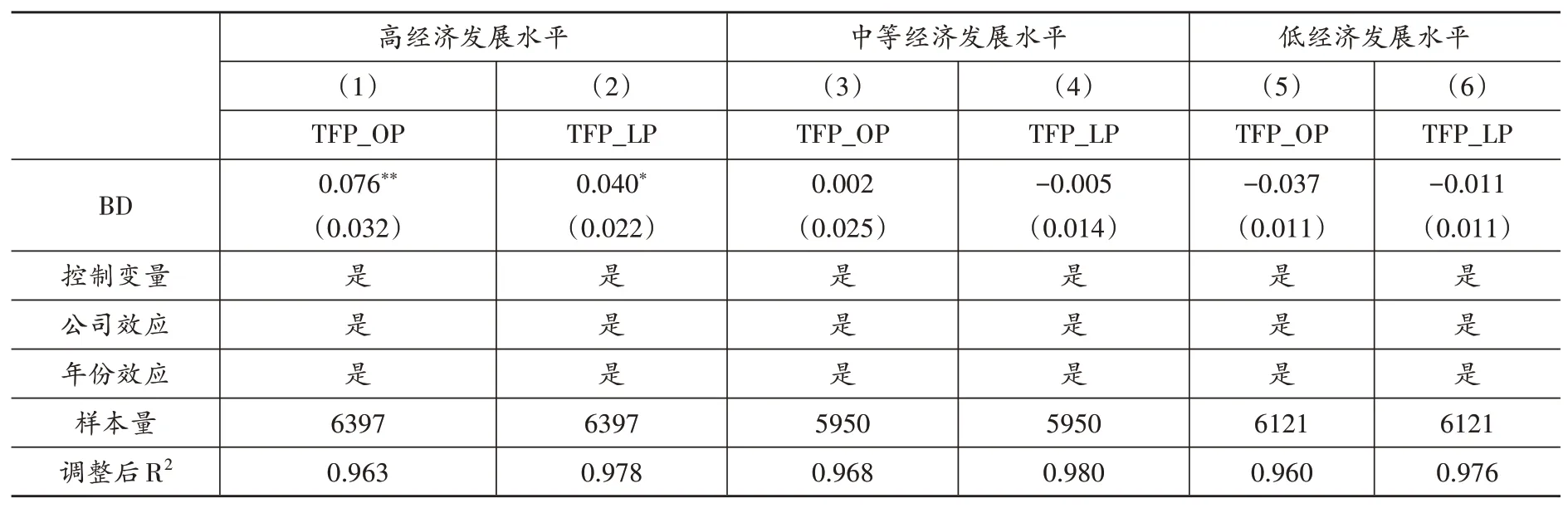
表7 自動加深效應的進一步分析結果
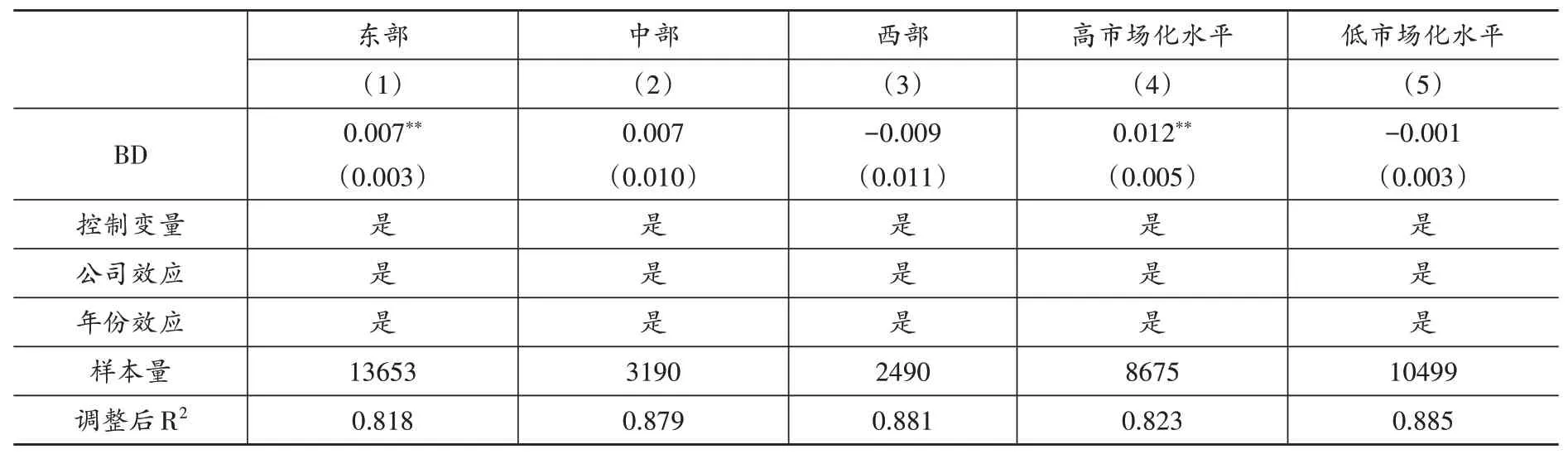
表8 區分區域和市場特征的回歸結果
(二)穩健性檢驗
1.平行趨勢檢驗
平行趨勢假設是多期DID 模型準確識別因果關系的關鍵前提,即在政策實施前,試驗組和控制組的勞動收入份額變化趨勢必須是平行的。為此,本文使用事件研究法檢驗該假設,其具體模型表示為:
該式中各變量的符號含義與式(10)一致。本文重點關注系數θt,其反映了大數據綜合試驗區建立的第t年,試點城市與非試點城市企業的勞動收入份額差異。此外,本文將大數據綜合試驗區建立前5 年的數據匯總到第-5 期,大數據綜合試驗區建立后5 年的數據匯總到第4 期,并以第-5 期為基期。圖3所示的平行趨勢檢驗結果顯示,大數據綜合試驗區建立前各年份的系數估計值均不顯著①圖3 中的短豎線代表90%水平置信區間,實心原點代表式(11)中的θt估計值。。該結果說明,試點城市和非試點城市企業的勞動收入份額在大數據綜合試驗區建立前無顯著差異,研究樣本通過了平行趨勢檢驗。同時,該結果顯示大數據綜合試驗區的建立對企業勞動收入份額存在持續的促進效應。
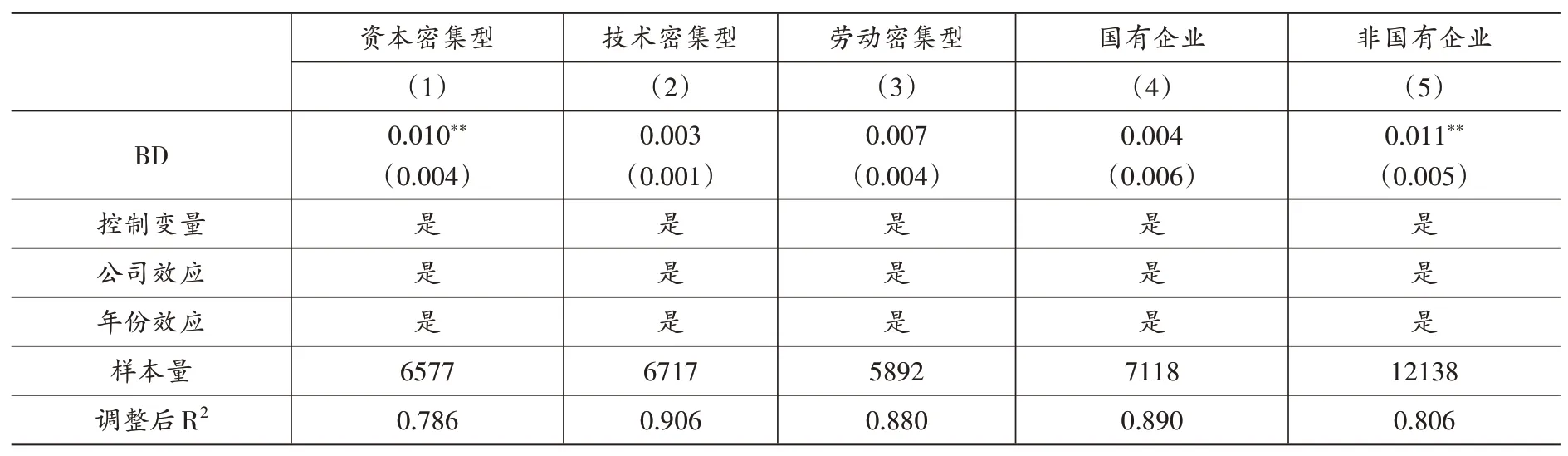
表9 區分要素結構和所有制特征的回歸結果
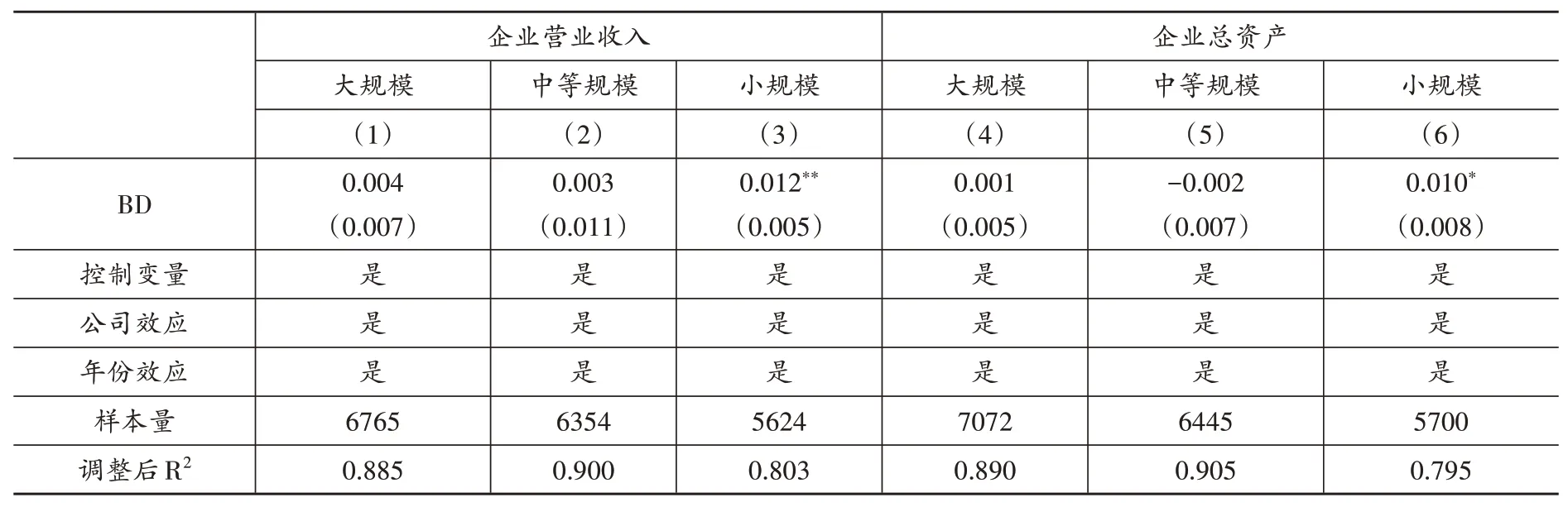
表10 區分規模特征的回歸結果
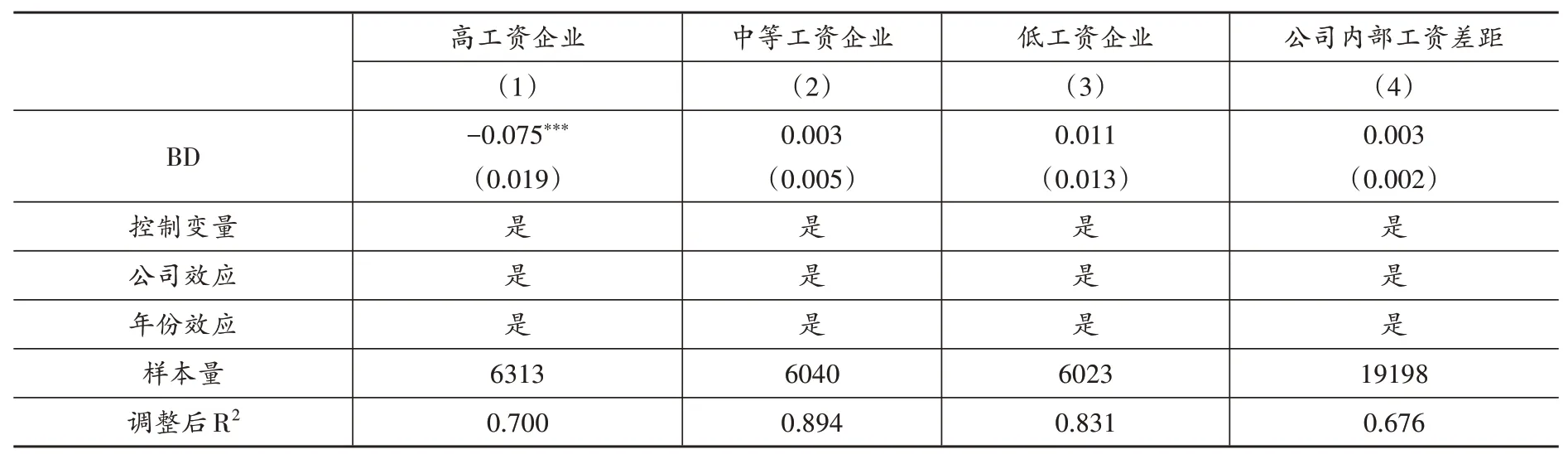
表11 大數據對工資差距的影響
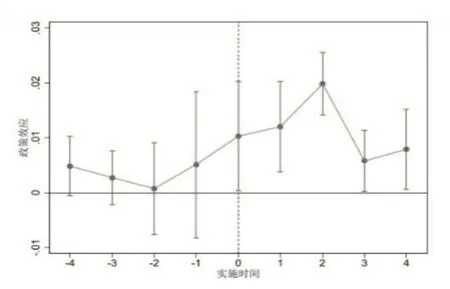
圖3 平行趨勢檢驗圖
2.安慰劑檢驗
為了進一步排除不可觀測因素對基準回歸結果的影響,本文通過隨機處理城市與年份進行安慰劑檢驗。在所有樣本中隨機假定大數據綜合試驗區試點政策實施時間與地區,用以代替模型(10)中的BD 變量,并對其重新進行回歸。為使安慰劑檢驗結果更加穩健可靠,本文重復上述過程500 次,結果如圖4 所示,虛假的θ 值大都落在0 附近且服從正態分布,絕大多數結果的P 值均大于0.1。另外,真實θ 值大于大多數的虛假θ 值,這表明該結果在安慰劑下是極小概率會發生的情況。因此,可以說明基礎回歸結果通過安慰劑檢驗,大數據綜合試驗區試點地區所屬企業勞動收入份額的提升作用與不可觀測因素的因果關系不大。
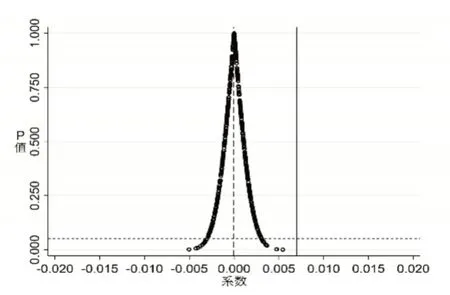
圖4 安慰劑檢驗
3.PSM-DID模型
為了避免樣本選擇性偏差所造成的內生性問題,本文使用了PSM-DID 模型,重新對式(10)進行估計。結果如表3第(1)、(2)以及(3)列所示,分別采用最鄰近匹配法、核匹配法和半徑匹配法后,BD的估計系數仍然在10%、5%和5%的水平上顯著,該結果與基礎回歸結果一致。
4.其他穩健性檢驗
為了進一步保證研究結論的穩健性,本文還從樣本數據篩選、排除重大事件的干擾、排除其他政策干擾以及控制高維固定效應等多個維度進行分析。
(1)樣本數據篩選。為了避免極端值對研究結論的影響,根據變量LISit對研究樣本進行1%的縮尾處理,重新對式(10)進行估計。結果如表3 第(4)列所示,在剔除極端值后,BD 的估計系數仍然在1%的水平上顯著為正,該結果與基準回歸結果一致。
(2)排除重大事件的干擾。2020 年新冠疫情爆發對企業的生產和經營都產生了重大影響,為了避免在樣本期間所發生的重大事件影響勞動收入份額,造成基準結果的估計偏誤,本文刪除2020年的樣本數據,重新對式(10)進行估計。結果如表3 第(5)列所示,在刪除2020 年的樣本數據后,大數據綜合試驗區試點政策仍然在5%的顯著水平上提升了勞動收入份額,該結果與基礎回歸結果相似。
(3)排除其他政策干擾。在大數據綜合試驗區政策實施期間,其他相近政策可能也會對大數據發展以及勞動收入份額產生影響,例如“寬帶中國”示范城市、智慧城市建設等政策①本文的政策背景部分已對國家級大數據綜合試驗區建設與“寬帶中國”示范城市、智慧城市建設等相似政策的本質差異進行了說明。。為了避免樣本期間由于這些相似政策干擾所產生的估計結果偏誤,本文在基準回歸中加入“寬帶中國”示范城市(POLICY1)、智慧城市建設(POLICY2)等政策的虛擬變量,重新對式(10)進行估計。結果如表3 第(6)列所示,在加入“寬帶中國”示范城市以及智慧城市試點政策的虛擬變量后,大數據綜合試驗區試點政策仍然在1%的顯著水平上提升了勞動收入份額,該結果與基礎回歸結果一致。
(4)控制高維固定效應。盡管同時控制年份和公司固定效應能緩解一部分遺漏變量引起的估計偏誤,但仍然存在一些隨時間變化的不可觀察的行業因素對研究結果產生影響。為此,本文進一步控制“行業-年份”層面的固定效應,重新對式(10)進行估計。結果如表3 第(7)列所示,在控制“行業-年份”層面的固定效應后,大數據綜合試驗區試點政策仍然在5%的顯著水平上提升了勞動收入份額,該結果與基礎回歸結果相似。
六、影響機制的經驗分析
(一)直接效應:新任務創造與自動化擴張
理論分析表明,大數據能通過新任務創造與自動化擴張效應影響勞動收入份額。為了驗證該渠道是否成立,本文從如下三方面展開研究:
首先,檢驗大數據對企業員工雇傭規模的影響。大數據投入生產所導致的新任務創造與自動化擴張效應會直接影響企業員工雇傭規模。本文以員工人數自然對數(EN_LN)作為企業雇傭的代理變量,并借鑒陸雪琴、魯建坤(2022)的做法使用兩階段回歸法識別影響機制,表(4)第(1)和第(2)列分別報告了第一階段和第二階段回歸結果。第一階段回歸中,BD 的估計系數顯著為正(0.038),說明大數據綜合試驗區試點城市企業雇傭規模相對于其他企業上升了3.8%。第二階段回歸中,將第一階段回歸得到的因變量員工人數自然對數預測值(EN_LN_PRE)作為自變量,來分析大數據綜合試驗區試點政策是否通過擴大企業員工雇傭規模對勞動收入份額產生作用。第二階段回歸中,EN_LN_PRE 的估計系數顯著為正(0.194),說明大數據綜合試驗區試點政策實施所引起的企業員工雇傭規模增加導致了企業勞動收入份額的上升。上述結果表明,大數據能夠通過新任務創造效應提升勞動收入份額,假說1 得到印證。但是,對于是否存在自動化擴張效應,還需進一步驗證①員工雇傭規模取決于新任務創造效應與自動化擴張效應的相對大小。。
其次,檢驗大數據對企業不同類型員工雇傭規模的影響。理論分析表明,大數據引起的新任務創造效應既能創造高技能任務,也能創造中低技能任務。同時,大數據引起的自動化擴張效應不僅會減少低技能任務,還會進一步替換掉部分中等技能任務。本文按照教育程度,將碩士及以上學歷的員工視為高技能員工,本科及專科學歷的員工視為中等技能員工,高中及以下學歷的員工視為低技能員工。表(5)報告了大數據綜合試驗區試點政策影響不同類型員工雇傭規模的回歸結果。第(1)列表明,大數據綜合試驗區試點政策對博士學歷員工的需求存在一個正向影響,但并不顯著。第(2)—(4)列結果顯示,大數據綜合試驗區試點政策顯著降低了中等技能員工需求,而對高技能與低技能員工需求影響不顯著。上述結果至少可以得出兩點結論:第一,大數據能夠通過自動化擴張效應降低勞動收入份額,假說2得到印證;第二,大數據可能會引起“就業極化”現象。
最后,檢驗大數據對企業員工工資水平的影響。大數據投入生產所引起的新任務創造與自動化擴張效應會導致勞動市場需求與供給的相對變化,從而引起工資水平變化,這會直接影響勞動收入份額。為此,本文以企業員工人均工資自然對數(PLI_LN)作為企業員工工資水平的代理變量,并使用兩階段回歸法識別影響機制,表(4)的第(3)和第(4)列分別報告了第一階段和第二階段回歸結果。第一階段回歸中,BD 的估計系數顯著為負(-0.038);第二階段回歸中,企業員工人均工資自然對數預測值(PLI_LN_PRE)的估計系數顯著為正(0.835)。該結果說明,大數據主要通過擴張低工資崗位提升勞動收入份額。
(二)間接效應:自動化加深與融資約束緩解
理論分析表明,大數據能通過自動化加深與融資約束緩解效應影響勞動收入份額。為了驗證該渠道是否成立,本文從如下兩方面展開研究:
首先,檢驗大數據對企業全要素生產率的影響。自動化加深的標志是生產率的提升(Acemoglu and Restrepo,2018)。因此,本文分別采用OP 法與LP 法測算企業全要素生產率(TFP_OP 和TFP_LP),并以企業全要素生產率作為企業自動化加深的代理變量來識別該作用機制,表6前兩列報告了回歸結果。從第(1)和第(2)列來看,BD的估計系數并不顯著,說明大數據綜合試驗區試點政策并未提升企業全要素生產率。之所以會出現這種情況,原因可能在于缺乏與大數據匹配的新型基礎設施、缺乏大數據人才、大數據與企業生產融合度不夠等。也就說,在經濟發展水平高的地區,可能才會產生自動化加深效應。為此,本文進一步以樣本內各年份地區GDP 的1/3 分位數以及2/3 分位數為臨界點,分別將樣本劃分為高經濟發展水平地區、中等經濟發展水平地區與低經濟發展水平地區三組后進行回歸,表(7)中報告了該分組回歸結果。結果表明,在經濟發展水平高的地區大數據才能顯著地提升全要素生產率,即產生顯著的自動化加深效應。因此,假說3得到驗證。
其次,檢驗大數據對企業融資約束程度的影響。本文使用SA指數(SA)衡量企業融資約束程度,并使用兩階段回歸法識別作用渠道,表(6)的第(3)和第(4)列報告了兩階段回歸結果。第一階段回歸中,BD 的估計系數顯著為負(-0.013),說明大數據綜合試驗區試點城市企業融資約束程度相對于其他企業下降了1.3%。第二階段回歸中,將第一階段回歸得到的因變量SA指數預測值(SA_PRE)作為自變量,來分析大數據綜合試驗區試點政策是否通過降低融資約束對勞動收入份額產生作用。第二階段回歸中,SA_PRE的估計系數顯著為負(-0.558),說明企業融資約束的增加會導致企業勞動收入份額的下降。上述結果表明,大數據能夠通過緩解企業融資約束提升勞動收入份額,假說4 得到驗證。
七、進一步分析
(一)企業外部環境的異質性影響
1.區域差異。區域發展不平衡是我國長期存在的問題。區域發展不平衡所導致的各地區大數據發展與應用的不平衡,會使得大數據對勞動收入份額的影響存在差異。為了考察大數據對勞動收入份額影響的區域異質性,本文按照企業注冊地,將全樣本劃分為東部、中部與西部三組后分別進行回歸,表(8)中的第(1)-(3)列分別報告了三組回歸結果。從回歸結果可知,大數據綜合試驗區的建立顯著提高了東部地區試點城市企業的勞動收入份額,而對中西部企業的勞動收入份額影響不顯著。出現該情況的原因可能在于,東部地區相對中西部地區擁有更完善的新型基礎設施建設、巨大的人力資本優勢以及良好的融資環境,這有利于當地企業發揮大數據在生產中形成的新任務創造效應、自動化加深(生產率)效應以及融資約束緩解效應,進而提升企業勞動收入份額。
2.市場化差異。市場化水平越高的地區,該地區企業技術效率越高(李勝文等,2013)。市場化水平會影響大數據技術效率,進而對勞動收入份額產生影響。大數據對勞動收入份額的影響可能因為市場化水平的不同而存在差異。為了考察大數據對勞動收入份額影響的市場化異質性,本文根據王小魯等(2021)編制的省級市場化水平總指數,以各年份省份市場化水平總指數的中位數為界,將全樣本劃分為高市場化水平與低市場化水平兩組后分別進行回歸,表(8)中的第(4)-(5)列分別報告了兩組回歸結果。從回歸結果可知,大數據綜合試驗區的建立顯著提高了高市場化水平地區試點城市企業的勞動收入份額,而對低市場化地區試點城市企業的勞動收入份額影響不顯著。在高水平市場化地區,大數據技術效率更高,這有利于企業基于大數據提高生產效率,開發新產品、新服務,創造出新的崗位,進而提升勞動收入份額。
(二)企業內部特征的異質性影響
1.要素結構差異。相對于資本密集型行業,技術密集型行業與勞動密集型行業更依賴于勞動力。大數據對勞動收入份額的影響可能因企業不同要素結構而存在差異。為了考察大數據對企業勞動收入份額影響的要素結構異質性,本文根據魯桐、黨印(2014)的做法將樣本劃分為資本密集型企業、技術密集型企業與勞動密集型企業三組后進行回歸,表(9)中的第(1)-(3)列分別報告了三組回歸結果。從回歸結果可知,大數據綜合試驗區的建立顯著提高了試點城市資本密集型企業的勞動收入份額,而對試點城市技術密集型企業與勞動密集型企業的勞動收入份額影響不顯著。可能的原因在于,相對于技術密集型與勞動密集型企業,資本密集型企業擁有更完備的信息基礎設施與較少的中低技能勞動力,這使得大數據在資本密集型企業中產生了更大的新任務創造效應與自動化加深效應以及更小的自動化擴張效應,這有助于資本密集型企業提升勞動收入份額。
2.所有制差異。相對于國有企業,非國有企業具有更高的逐利性和更大的競爭壓力。大數據對勞動收入份額的影響可能因企業所有制不同而存在差異。為了考察大數據對企業勞動收入份額影響的所有制異質性,本文將樣本劃分為國有企業與非國有企業兩組后進行回歸,表(9)中的第(4)-(5)列分別報告了兩組回歸結果。從回歸結果可知,大數據綜合試驗區的建立顯著提升了試點城市非國有企業的勞動收入份額,而對試點城市國有企業的勞動收入份額影響不顯著。可能的解釋為,非國有企業為了保持競爭力、取得更大利潤,大力投資并應用大數據,充分發揮了大數據在生產中形成的新任務創造效應、自動化加深(生產率)效應以及融資約束緩解效應,進而提升企業勞動收入份額。
3.規模差異。勞動收入份額會受到企業規模的影響(陸雪琴、田磊,2020)。因此,大數據對勞動收入份額的影響可能因企業規模不同而存在差異。為了考察大數據對企業勞動收入份額影響的規模異質性,本文以樣本內各年份企業營業收入與總資產的1/3 分位數以及2/3 分位數為臨界點,分別將樣本劃分為大規模企業、中等規模企業與小規模企業三組后進行回歸,表(10)中的第(1)-(3)列報告了以企業營業收入為劃分標準的回歸結果,第(4)-(6)列報告了以企業總資產為劃分標準的回歸結果。從回歸結果可知,兩種企業規模劃分標準下,大數據綜合試驗區的建立均顯著增加了試點城市小規模企業的勞動收入份額,但并未在試點城市大規模企業與中等規模企業中產生顯著的影響。一個可能的原因是,對于規模大的企業而言,大數據既能產生較大的新任務創造效應,又能產生較大的自動化擴張效應,這不利于勞動收入份額的提升。然而,對于規模小的企業而言,大數據帶來的企業發展更傾向于使得其擴展業務,這會產生新任務創造效應與自動化加深效應,進而提升勞動收入份額。
(三)大數據與勞動收入內部分配
由于社會大多數群體都是企業雇員,且收入主要是工資,企業工資分配對整體社會收入分配格局具有重要影響(Gartenberg and Wulf,2020)。前文已經回答了大數據對企業勞動收入份額的影響,那么大數據在企業工資分配中的具體效應又是如何呢?為了回答該問題,本文進一步地從企業間和企業內部的工資收入差距實證檢驗大數據對勞動收入內部分配的影響。首先,為了考察大數據對企業間工資收入差距的影響,本文以樣本內各年份企業人均工資的1/3 分位數以及2/3 分位數為臨界點,分別將樣本劃分為高工資企業、中等工資企業與低工資企業三組后進行回歸,表(11)中的第(1)-(3)列分別報告了三組回歸結果。回歸結果顯示,大數據綜合試驗區的建立僅顯著降低了試點城市高工資企業的勞動收入份額,而對試點城市中等工資企業與低工資企業的勞動收入份額影響不顯著。該結果表明,大數據能夠通過降低高工資企業的人均工資收入改善公司間的工資收入差距。其次,為了考察大數據對企業內部工資收入差距的影響,本文借鑒張克中等(2021)的做法,使用企業管理層與普通員工工資二者的比值衡量企業內部公司收入情況,表(11)中的第(4)列報告了回歸結果。回歸結果顯示,大數據不會對企業內部工資差距產生顯著的影響。
八、研究結論與政策啟示
提高勞動收入份額關系著國內大循環新發展格局的形成以及共同富裕目標的實現。本文立足于數據已經成為中國經濟發展最重要的生產要素之一這一基本事實,以大數據作為研究切入,在理論分析的基礎上,基于2011—2020 年中國A 股上市公司數據,利用國家級大數據綜合試驗區建立這一外生事件,采用多期雙重差分方法系統探討了大數據如何影響勞動收入份額。實證結果表明,大數據能夠顯著提升企業勞動收入份額,且在經過平行趨勢檢驗、安慰劑檢驗等一系列穩健性檢驗后,該結論依然成立。機制分析發現,大數據可以通過直接效應和間接效應影響企業勞動收入份額。其中,直接效應表現為新任務創造和自動化擴張效應,間接效應表現為自動化加深和融資約束緩解效應。進一步分析顯示,大數據的勞動收入份額提升效應僅存在位于東部地區和高市場化水平地區的企業、資本密集型企業、非國有企業以及小規模企業。此外,大數據主要通過緩解企業間的工資收入差距,而非企業內部的工資收入差距來改善勞動收入內部分配結構。
基于上述研究結論,本文得到如下政策啟示:
第一,堅定數字經濟發展方向,充分發揮大數據在要素分配中的作用。本文研究結論表明,大數據切實提高了企業勞動收入份額,并且能夠通過緩解企業間的工資收入差距來改善勞動收入內部分配結構,這對于加快國內大循環新發展格局的形成以及促進共同富裕目標的實現至關重要。因此,以大數據為支點撬動生產方式和治理方式的變革勢在必行,政府應當加大大數據產業投資,推動產生數字化,并為企業提供充足的數字化轉型動能。
第二,努力提升人力資本水平,積極適應大數據發展帶來的技術紅利。通過本文研究可知,大數據通過自動化擴張效應產生的勞動收入份額降低能夠被新任務創造與自動化加深效應有效緩解。高質量的人力資本不僅能夠補充新任務創造產生的中高技能崗位,而且可以進一步促進自動化加深效應的實現。因此,政府應當順應時代需求,積極推行教育改革以適應數字時代下新的人力資本需求,從而充分利用大數據發展帶來的技術紅利,提高勞動收入份額。
第三,推進大數據發展需要“因地制宜”,不能一刀切。本文的研究表明,在市場化水平不強的地區,企業可能因為無法有效利用市場促進大數據發揮其新任務創造和自動化加深效應;國有企業因其競爭壓力不大、公司治理水平不足等導致其無法充分發揮大數據的價值。因此,考慮到大數據在不同環境與不同企業中的勞動收入份額提升效應存在差異,在實施相應政策時,政府應當統籌兼顧,穩步推進。比如,對市場化水平不高的地區,由于無法有效發揮市場在促進效率中的作用,政府應當給予更多的市場支持政策。
猜你喜歡
當代水產(2022年8期)2022-09-20 06:44:30
當代水產(2022年6期)2022-06-29 01:11:44
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
核科學與工程(2021年4期)2022-01-12 06:30:26
今日農業(2020年19期)2020-12-14 14:16:52
小學生必讀(中年級版)(2020年9期)2020-12-04 02:07:22
云南畫報(2020年9期)2020-10-27 02:03:26
中學物理·高中(2016年12期)2017-04-22 11:53:03
