面向ICS不平衡數據的重疊區混合采樣方法
2023-10-10 10:39:52顧兆軍周景賢
計算機工程與應用 2023年19期
高 冰,顧兆軍,周景賢,隋 翯
1.中國民航大學 信息安全測評中心,天津 300300
2.中國民航大學 計算機科學與技術學院,天津 300300
3.中國民航大學 航空工程學院,天津 300300
工業控制系統(industrial control system,ⅠCS)是能源、交通、城市公用設施等國家關鍵基礎設施的重要組成部分[1-3]。信息技術與工業生產的深度融合,拓寬了ⅠCS 的發展空間[4],但融合發展的同時也帶來了復雜嚴峻的網絡安全威脅[5]。典型ⅠCS安全保障體系可分為防護、檢測、響應和恢復四個層次[6],其中檢測尤為關鍵,其負責識別企圖破壞系統完整性、機密性以及可用性的行為,并為系統響應提供了必要的反饋[7-8]。
ⅠCS 數據大多存在著不平衡性,同時不平衡的ⅠCS數據普遍存在著類重疊現象。相關研究表明,數據的不平衡性并非是導致檢測困難的唯一因素,當類別間的可分性較強且數據量足夠多時,即使數據的不平衡程度很高,也并不需要太復雜的模式來區分各類樣本[9]。不平衡問題在孤立狀態下可能不會造成分類器性能明顯下降,但當不平衡數據中存在著較為嚴重的數據重疊時,分類器的性能將受到很大影響[10-11]。
針對不平衡數據的檢測問題,目前常采用平衡數據類別或檢測數據重疊的策略[12]。
在平衡數據類別的策略中,常采用過采樣、欠采樣或混合采樣方法。其中,Pan等人[13]提出了基于合成少數類過采樣(synthetic minority over-sampling technique,SMOTE)[14]的方法,通過線性插值合成不平衡數據中的少數類樣本使數據達到平衡狀態。該方法提高了分類器對異常數據的學習能力,緩解了隨機過采樣的過擬合問題[15],提高了檢測性能。Agustianto 等人[16]提出了基于鄰域清洗規則NCL(neighborhood cleaning rule)的欠采樣方法,通過尋找某個樣本的k個近鄰,若該樣本類別與k個近鄰的類別不一致則刪除屬于多數類的樣本或近鄰。該方法能夠達到平衡樣本的目的,并與決策樹C4.5 分類算法結合達到了較高的準確率。鄭建華等人[17]提出了一種級聯過采樣與欠采樣的混合采樣方法,通過利用高斯混合模型和SMOTE-Borderline1 進行二次過采樣,并利用一次隨機欠采樣以平衡數據,最后該方法以隨機森林為基分類器實現了較好的分類性能。上述方法均取得了一定的成效,但存在著一定的局限性,比如數據中噪聲樣本增加或所提方法對不同分類器的適配性較低等,而且沒有考慮到不平衡數據中存在的數據類別重疊問題。
在檢測數據重疊的策略中,常依據聚類或無監督分類模型來檢測重疊并輔以欠采樣方法對重疊多數類樣本進行處理。對此,Vuttipittayamongkol 等人[18]基于軟聚類算法提出了一種面向重疊的欠采樣框架OBU(overlap-based under-sampling),該方法依據軟聚類算法分配的樣本成員度確定潛在的重疊樣本,并將負類樣本從重疊樣本中剔除且無須平衡數據。Devi 等人[19]提出將多數類和少數類樣本分別送入一類支持向量機OCSVM(one-class support vector machine)中進行檢測,兩類樣本被檢測出的離群點即為二者的重疊數據,同時選擇Tomek-link 欠采樣方法來消除重疊邊界的多數類樣本并平衡數據。Li 等人[20]提出先用少數類樣本訓練異常檢測模型,然后將原始數據輸入模型中以排除少數類的異常值和大量的多數類樣本,剩余數據形成重疊子集,并運用欠采樣方法剔除該子集中的多數類樣本,最后將重疊與非重疊子集合并以訓練分類器。上述方法均不同程度上優化了數據分布、改善了分類器的學習能力,相比于平衡數據類別的方法在處理不平衡數據上具有獨特優勢,但同時也存在著重疊識別率較低或沒有考慮到重疊數據中多數類樣本的數據清洗以及少數類樣本的采樣問題等。
本文針對ⅠCS異常檢測中存在的數據不平衡問題,從類重疊的角度出發,提出了一種面向重疊區域的混合采樣方法:OverlapRHS(overlap region with hybrid sampling)。該方法基于分而治之的思想,分別利用多數類樣本和少數類樣本訓練支持向量數據描述SVDD(support vector data description)[21]以構建重疊檢測模型,并在此基礎上合成重疊數據區域的少數類樣本,增強少數類樣本的數據特征,然后對該區域的多數類樣本進行鄰域清洗以削弱分類器在訓練時偏向于多數類樣本。本文通過將OverlapRHS 與支持向量機、邏輯回歸、k-近鄰、決策樹分類器進行組合,在公開的3個ⅠCS數據集和1 個入侵檢測數據集上進行了測試,并對比了其他4 種處理不平衡問題的采樣方法。結果表明,OverlapRHS 在數據重疊檢測、混合采樣以及對分類器訓練效果提升方面均展現出了有效性,分類器的檢測性能與泛化能力得到了顯著提升,并且該方法明顯優于其他處理不平衡數據的采樣方法。
1 OverlapRHS概述
OverlapRHS分為兩個階段,如圖1所示。第一個階段是重疊區域檢測階段,第二個階段是重疊區域采樣階段。OverlapRHS 的具體實施流程如下:不平衡數據集以8∶2 的比例被劃分為訓練集Xtrain和測試集Xtest,訓練集Xtrain在經過重疊區域檢測階段時,首先依據其類標簽將Xtrain劃分為多數類樣本集Xmajor和少數類樣本集Xminor,之后利用Xmajor和Xminor分別訓練SVDDmajor和SVDDminor,由此得到兩個不同的決策函數Fmajor(xi)和Fminor(xi),然后計算訓練集Xtrain中的所有樣本分別在兩個決策函數上的函數值,最后根據函數值以及相關預定規則判斷訓練集Xtrain中樣本點的分布情況。
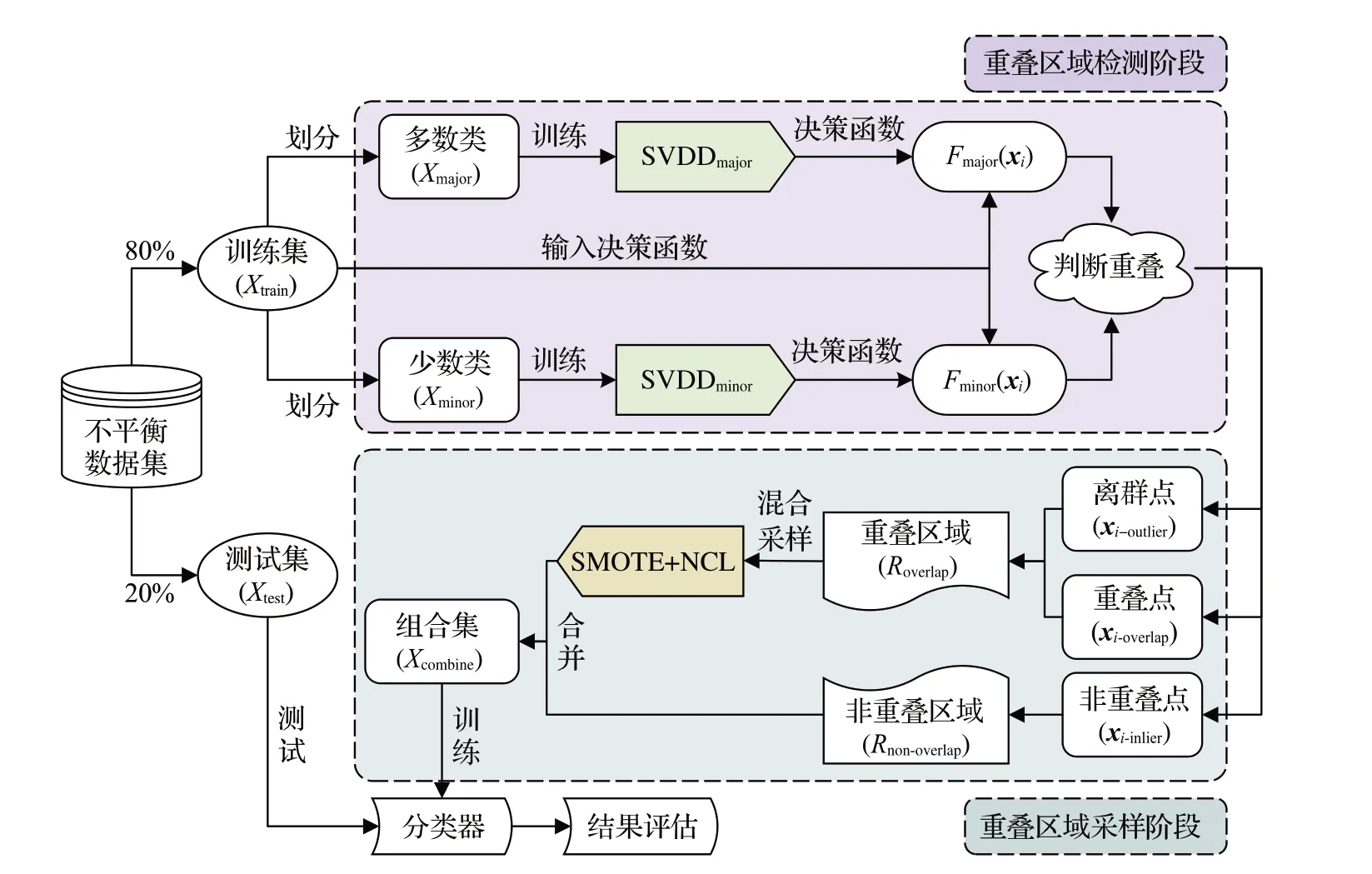
圖1 OverlapRHS方法結構圖Fig.1 Structure diagram of OverlapRHS method
在重疊區域采樣階段中,重疊區域Roverlap由離群點xi-outlier和重疊點xi-overlap共同構成,非重疊區域Rnon-overlap僅由非重疊點xi-inlier構成。在重疊區域Roverlap內加入離群點xi-outlier主要是考慮在后續采樣過程中可以生成多樣化的少數類樣本,以及在最大限度保留整體多數類信息的情況下剔除更多的多數類樣本。在確定重疊區域Roverlap之后,通過融合SMOTE合成少數類過采樣和NCL鄰域清洗規則以完成該區域內的混合采樣工作,非重疊區域Rnon-overlap則不做采樣處理。最后將重疊區域Roverlap混合采樣之后的所有樣本與非重疊區域Rnon-overlap內的所有樣本合并得到組合樣本訓練集Xcombine,并用其訓練分類器,最后使用測試集Xtest在訓練好的分類器上進行測試評估。下面將對OverlapRHS兩個階段的內容作詳細闡述。
1.1 重疊區域檢測階段
重疊區域檢測階段結構示意圖如圖2 所示。根據訓練集Xtrain所劃分的多數類樣本集Xmajor和少數類樣本集Xminor分別在SVDDmajor和SVDDminor上構建最小超球,并利用所得到的最小超球半徑Rmajor和Rminor設置相應的決策函數Fmajor(xi)和Fminor(xi),最后依據重疊判斷規則對訓練集Xtrain中樣本點的分布進行劃分。
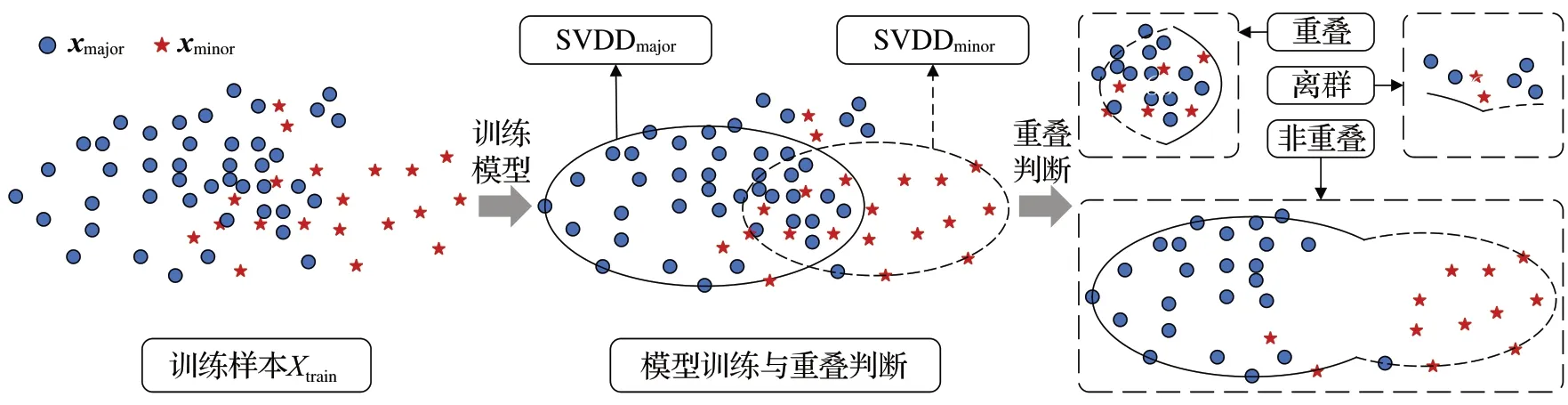
圖2 重疊區域檢測階段結構示意圖Fig.2 Structure schematic diagram of overlap region detection stage
假定有數據集X={x1,x2,…,xn},為了構造最小超球,同時為了更好地處理高維復雜數據的非線性映射問題,本文采用徑向基函數核(radial basis function kernel,RBF核)作為高維特征空間映射函數K,將數據從原始空間Ok映射到特征空間Fk,并解決如(1)所示的優化問題:
其中,R>0 是超球半徑,c∈Fk是超球球心,ξi≥0 是用于懲罰數據中噪聲的松弛變量,其目的是防止模型出現過擬合,C是平衡超球半徑和松弛變量的參數。
上述優化問題的約束條件可通過拉格朗日乘子法納入優化問題(1)中,結果如公式(2)所示:
其中,拉格朗日乘數αi、γi≥0。利用L分別對超球半徑R、超球球心c和松弛變量ξi求偏導,并將偏導數設置為0,有:當xi在Fmajor(xi)和Fminor(xi)上的決策函數值均大于或等于0,此時xi同時位于兩個超球的內部或邊界上,那么該點被定義為重疊點xi-overlap;當xi當且僅當在Fmajor(xi)或Fminor(xi)其中一個決策函數上的值小于0時,此時xi僅位于一個超球內部而位于另一個超球外部,那么該點被定義為非重疊點xi-inlier。
將公式(3)中得出的結果重新納入公式(2)中,整理可得出最終的超球半徑計算公式為:
1.2 重疊區域采樣階段
其中,xv∈SV,SV為支持向量集合,當xi滿足約束條件‖xi-c‖2=R2時,有0<αi
由公式(4)和公式(5),本文通過設定如公式(6)的決策函數來檢測樣本的分布情況:
即,如果F(xt)>0 ,那么樣本xt位于超球內部;如果F(xt)=0,那么樣本xt位于超球邊界上;如果F(xt)<0,則樣本xt位于超球外部。
在SVDDmajor和SVDDminor均訓練完畢之后,將訓練集Xtrain中的所有樣本分別輸入至決策函數Fmajor(xi)和Fminor(xi)中,并根據Fmajor(xi)和Fminor(xi)所得出的決策函數值,判斷Xtrain中樣本點的分布情況,判斷規則如下:
(1)if(Fmajor(xi)<0) and (Fminor(xi)<0):xi→outlier
(2)if(Fmajor(xi)≥0) and (Fminor(xi)≥0):xi→overlap
(3)if[(Fmajor(xi)<0) and (Fminor(xi)≥0)]or[(Fmajor(xi)≥0) and (Fminor(xi)<0)]:xi→inlier
簡述之,即有樣本點xi∈Xtrain,當xi在Fmajor(xi)和Fminor(xi)上的決策函數值均小于0 時,此時xi同時位于兩個超球外部,那么該點被定義為離群點xi-outlier;
重疊區域采樣階段結構示意圖如圖3 所示。首先利用SMOTE對所確定的重疊區域Roverlap內的少數類樣本進行線性插值過采樣,其目的是增大少數類樣本對分類器的可見性,同時避免大量的生成樣本嵌入至非重疊區域Rnon-overlap內多數類樣本的數據空間中,以防止在樣本生成時加劇整體數據的類別重疊。在此基礎上,利用NCL對過采樣之后重疊區域Roverlap內的多數類樣本進行鄰域清洗,其目的是緩解整體數據的不平衡,降低數據重疊程度,削弱分類器偏向于多數類樣本的趨勢,進一步增大少數類樣本的可見性。下面將對重疊區域采樣階段的過采樣和欠采樣兩部分內容作更進一步的論述。
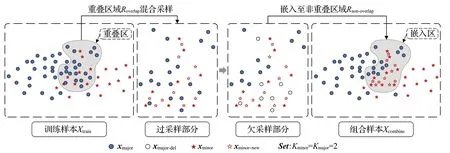
圖3 重疊區域采樣階段結構示意圖Fig.3 Structure schematic diagram of overlap region sampling stage
1.2.1 過采樣部分
在過采樣部分,利用SMOTE 對該區域內的少數類樣本進行過采樣,過程如下:
首先依據歐式距離(euclidean distance,ED)計算出Roverlap區域內每個少數類樣本xminor到此區域內其他少數類樣本xminor-rest的距離,如公式(7)所示:
之后依據式(7)所得到的結果,選取距離xminor最近的Kminor個近鄰,根據經驗與實驗驗證,文中Kminor設置為5。對于每個少數類樣本xminor,從其Kminor個近鄰中隨機選擇a個近鄰,對于選出的每一個近鄰xa,其與xminor以如下方式構建新的少數類樣本:
其中,Nrand為0 至1 間的隨機數,Vdiffer為少數類樣本xminor與其近鄰xa差的絕對值,新的少數類樣本xminor-new則由xminor、Nrand和Vdiffer插值構建。在處理完每一個少數類樣本之后,將構建的所有新樣本xminor-new嵌入至重疊區域Roverlap內。至此,過采樣部分完成。
1.2.2 欠采樣部分
在欠采樣部分,利用NCL 清理過采樣之后重疊區域Roverlap內的部分多數類樣本,過程如下:
同樣依據歐式距離計算出Roverlap區域內每個多數類樣本xmajor到此區域內其他多數類樣本xmajor-rest的距離,如公式(9)所示,并依據結果選取每個多數類樣本xmajor的Kmajor個最近鄰,為了避免多數類樣本信息丟失過度,經驗證,本文中Kmajor以4為宜。
然后對于該區域內的每個多數類樣本xmajor,以如下規則進行領域清洗:
其中,為xmajor的Kmajor個近鄰中多數類樣本的個數,即如果xmajor的Kmajor個近鄰中有超過半數的樣本都不屬于多數類樣本,那么該樣本將被標記為xmajor-del。在處理完Roverlap區域內的全部多數類樣本之后,所有標記為xmajor-del的多數類樣本將從該區域中剔除。至此,欠采樣部分完成。
完成重疊區域Roverlap的混合采樣之后,將該區域內的所有樣本與非重疊區域Rnon-overlap內的所有樣本合并為組合樣本集Xcombine作為最終的訓練集來訓練分類器,如公式(10)所示,最后用測試集Xtest進行測試。
2 實驗與結果分析
2.1 數據集與實驗設計
實驗所用的3 個公開ⅠCS 數據集分別是:BHP(burst header packet)為光突發交換網絡中多控制分組存在洪泛攻擊的數據集[22];GP(gas pipeline)為天然氣管道傳感器數據集[23];Power 為電力輸電系統數據集[24]。同時使用1個入侵檢測數據集NSLKDD[25]作為實驗對比。表1 所示為4 個數據集的基本信息:數據集名稱、數據量、特征維數,多數類個數,少數類個數和不平衡率Imb。Imb計算公式如下所示:
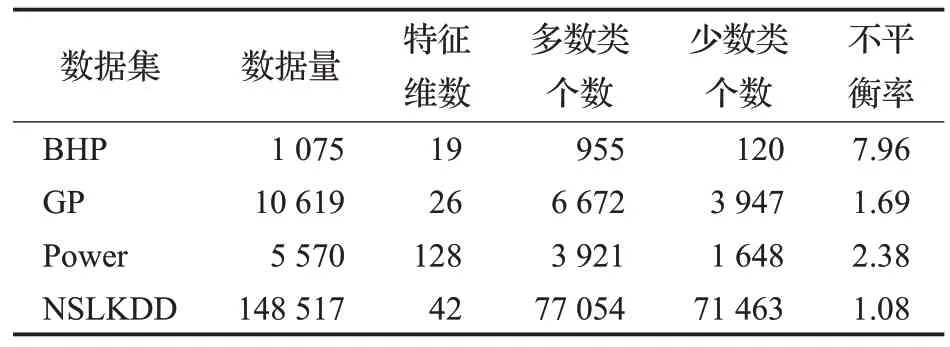
表1 數據集基本信息Table 1 Basic information of datasets
其中,Nmajor是多數類個數,Nminor是少數類個數,Imb值越大,表明數據不平衡程度越高。
實驗所用評估指標有準確率(accuracy,Acc)、精確率(precision,Pre)、召回率(recall,Rec)、F1 分數(F1-score,F1)以及G-mean值。
其中G-mean值是評估正類召回率和負類召回率的綜合指標,其求解公式如下所示:
其中,TP表示被正確預測為正類的正樣本數,FP表示被錯誤預測為正類的負樣本數,TN表示被正確預測為負類的負樣本數,FN是被錯誤預測為負類的正樣本數。
實驗所用對比采樣方法有:NearMiss 欠采樣方法、SMOTE 過采樣方法、ADASYN 自適應抽樣方法,以及跳過重疊檢測階段直接利用SMOTE 與NCL 對數據集進行重采樣的SMOTE-NCL方法。
2.2 實驗結果分析
2.2.1 重疊檢測與混合采樣效果分析
為了較為直觀地展示OverlapRHS的重疊檢測和混合采樣效果,本文以BHP數據集為例,采用t-SNE[26]數據降維方法對OverlapRHS各階段數據的大致分布情況進行可視化分析。設定t-SNE嵌入空間維數為3,為了確保嵌入空間的全局穩定性,嵌入初始化方法設為PCA[27];○代表多數類樣本,☆代表少數類樣本;顏色的深淺程度代表著樣本點的分布密度,顏色越深,說明該區域的樣本密度越大,分布在該區域的相似樣本越多。圖4所示即為BHP數據集在OverlapRHS各階段的數據分布情況。
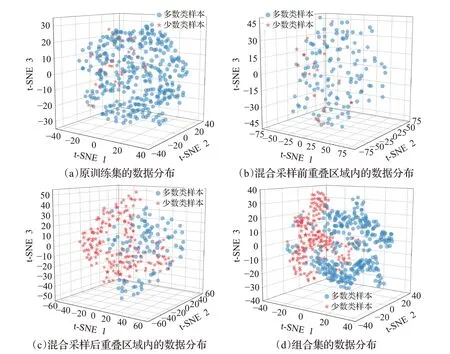
圖4 BHP數據集在OverlapRHS各階段的數據分布情況Fig.4 Data distribution of BHP dataset at each stage of OverlapRHS
圖4(a)為原訓練集的數據分布,其中少數類樣本與多數類樣本存在較大程度的數據重疊,分類邊界模糊。圖4(b)為所檢測出來的重疊數據區域,該區域中大部分少數類分布于多數類樣本的數據空間中,不過也存在著小部分少數類和部分多數類樣本沒有重疊的情況,這是因為重疊區域是由離群點xi-outlier和重疊點xi-overlap共同構成的,原因已在1.2節作出相關闡述。圖4(c)中,重疊區域少數類樣本在經過采樣后,數據規模得到擴充,多數類樣本在經鄰域清洗后,與少數類樣本的重疊降低。圖4(d)中組合集相比于原訓練集來說重疊程度減輕,不平衡程度緩解,少數類樣本在數據得到增強的同時并沒有大規模地侵入到多數類樣本的數據空間中,且有較為明顯的分類邊界,分類器能更容易地學習到少數類樣本的特征分布,說明OverlapRHS 在重疊檢測和混合采樣中具有有效性。
為了考證不同采樣方法間的差異性,本文繼續以BHP數據集為基準,利用t-SNE對比OverlapRHS與NearMiss、SMOTE、ADASYN以及SMOTE-NCL的采樣效果。如圖5所示即為各方法對BHP數據集采樣后的數據分布情況。
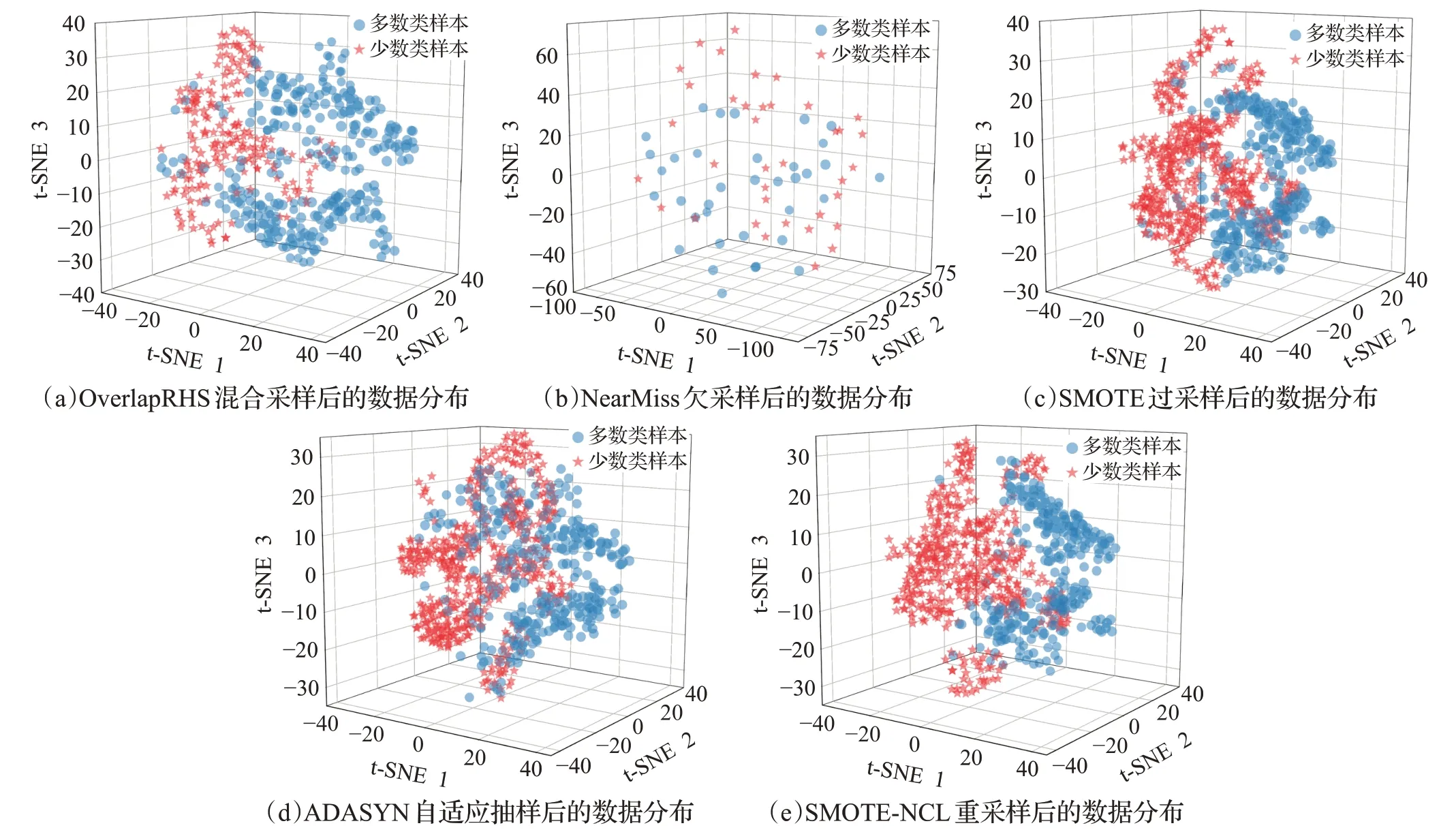
圖5 各方法在BHP數據集上采樣后的數據分布情況Fig.5 Data distribution of BHP dataset after sampling by each method
圖5(a)為OverlapRHS對數據集重疊區域混合采樣后的數據分布,也即組合集的數據分布。在圖5(b)中,NearMiss 的目的是剔除數據集中的多數類樣本以達到類別平衡,但這會導致多數類樣本的代表性不足,有效信息丟失,分類器準確性下降,而且沒有緩解重疊問題。除NearMiss 外,圖5(c)、(d)、(e)中的SMOTE、ADASYN 和SMOTE-NCL 均不同程度地擴展了少數類樣本的數據規模,使少數類樣本與多數類樣本達到了平衡狀態。但從三者的數據分布來看,雖然它們的數據類別得以平衡,但生成的少數類樣本卻大量地嵌入到多數類樣本的數據空間中,加劇了數據集的重疊程度,并且大量的生成樣本對分類器的訓練過程也存在著潛在的過擬合風險。
表2 為4 個數據集經OverlapRHS 處理前后的數據不平衡率對比。由表可知,各數據集在經過OverlapRHS處理之后的不平衡率并沒有達到平衡狀態,這說明OverlapRHS與現有方法有所不同。OverlapRHS旨在檢測出重疊數據,并在重疊數據區域內進行重采樣,這一點在圖4中得到驗證,重采樣數據不會對非重疊數據區域內的數據分布造成影響,并且能在一定程度上緩解整體數據的不平衡程度,而無須刻意謀求數據類別的最終平衡。
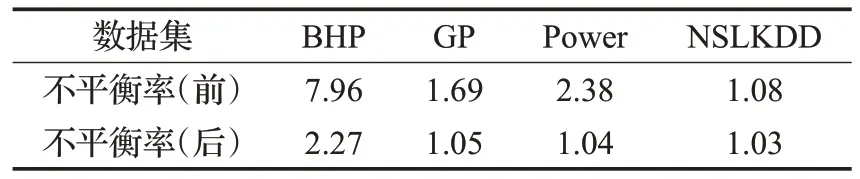
表2 各數據集經OverlapRHS處理前后的不平衡率Table 2 Ⅰmbalance rate of each dataset before and after OverlapRHS processing
2.2.2 OverlapRHS對分類器性能提升效果分析
為了檢驗OverlapRHS 對分類器性能的提升效果,實驗選取支持向量機、邏輯回歸、k-近鄰、決策樹分類器以及BHP、GP、Power、NSLKDD 數據集對其進行測試,通過對比各分類器在數據集原始無采樣(origin)狀態和經OverlapRHS處理后的狀態上的準確率(Acc)、精確率(Pre)、召回率(Rec)和F1 分數(F1)對其進行評估。實驗結果如圖6~9所示。
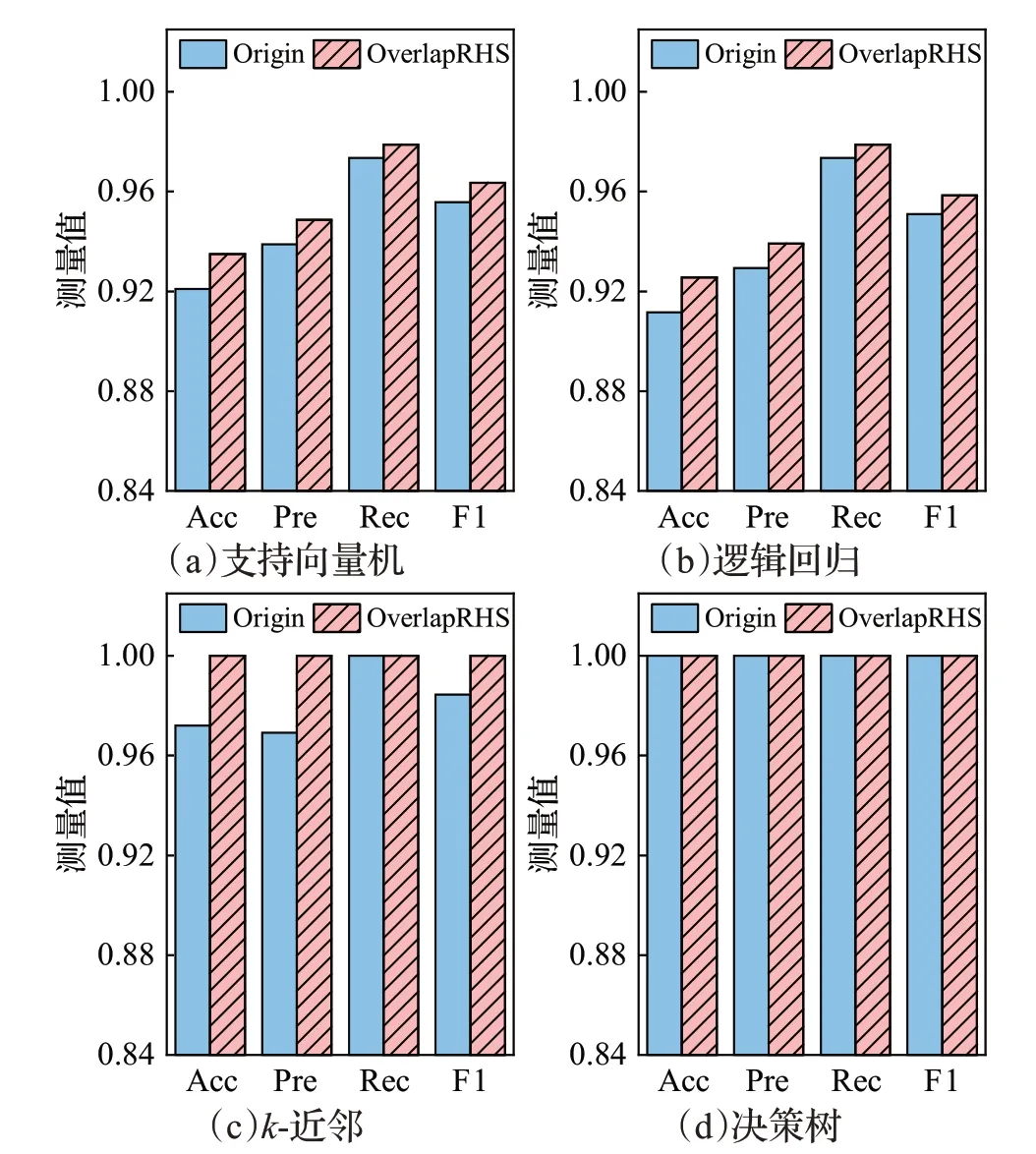
圖6 BHP數據集上OverlapRHS對各分類器的性能提升對比Fig.6 Performance improvement comparison of OverlapRHS on BHP dataset for each classifier
如圖6是BHP數據集上OverlapRHS對各分類器的性能提升對比結果。由圖可知,支持向量機和邏輯回歸在OverlapRHS 上的各項指標均有不同程度的提升,二者在OverlapRHS 上的準確率分別為0.934 9 和0.952 6,精確率分別為0.948 7和0.937 1,召回率均達到了0.978 8,F1 分數分別為0.772 6 和0.726 0。k-近鄰在Origin 和OverlapRHS 上的召回率均為1,但OverlapRHS 在保持召回率為1 的情況下,將k-近鄰的準確率、精確率和F1分數均提升到了1,體現了OverlapRHS 的不俗性能,有效檢測出了BHP 數據集的重疊數據,再輔以混合采樣顯著提升了k-近鄰的檢測效果。最后,決策樹在Origin和OverlapRHS 上的各項指標均為1,這一方面與BHP數據集的屬性有關,其特征維數僅為19,維數越少,數據特征分布越簡單,越易于分類器的學習,其次,BHP數據集的數據量也比較小,數據量越小,數據中存在的噪聲數據就越少,從而對分類器性能影響越小;另一方面,決策樹是基于樹的分類器,自帶正則項,能有效緩解過擬合問題。
如圖7 是GP 數據集上OverlapRHS 對各分類器的性能提升對比結果。從整體上來看,OverlapRHS 對支持向量機和邏輯回歸的性能提升比較有限,兩個分類器在Origin 和OverlapRHS 上的召回率達到了一致的0.974 7,除此之外,OverlapRHS在支持向量機和邏輯回歸的其余各項指標上僅提升了約0.04%~0.13%不等。從圖中可以得知,k-近鄰在OverlapRHS 上的各項指標均有不同程度的改善。對GP 數據集而言,OverlapRHS對決策樹的性能提升最為明顯,其將決策樹的各項分類指標提升了約2.6%~3.8%,其中召回率達到了0.974 7。

圖7 GP數據集上OverlapRHS對各分類器的性能提升對比Fig.7 Performance improvement comparison of OverlapRHS on GP dataset for each classifier
如圖8 是Power 數據集上OverlapRHS 對各分類器的性能提升對比結果。首先需要說明的是,Power數據集雖然僅有較少的5 570 條數據,但是卻具有高達128維的數據特征維度,一般情況下,數據集特征維度越高,數據特征分布越復雜,復雜的數據特征分布會對分類器的性能造成嚴重影響。本文所采用的支持向量機(線性核)和邏輯回歸均是線性分類器,它們的分類決策面都是線性的,無法較好地擬合復雜的數據特征分布,從而導致分類效果較差。從圖8(a)、(b)中可以很直觀地看出,支持向量機和邏輯回歸在Origin和OverlapRHS上的整體性能較低,特別是召回率和F1分數。但是,OverlapRHS依然展現出了效果,Power數據集在經過OverlapRHS處理之后,在支持向量機和邏輯回歸上的各項指標均有提升,邏輯回歸相較于支持向量機提升稍大。在非線性分類器上,k-近鄰在OverlapRHS上的提升最為顯著,其中召回率提升了約24.6%,F1分數提升了約15.7%,準確率和精確率也分別有5.9%和5.5%的性能改善。對決策樹而言,其在OverlapRHS 上的精確率降低了約1%的性能,但在召回率上提升了約6.4%,準確率以及綜合評價指標F1 分數都有所改觀,在異常檢測中,相較于精確率,召回率更加重要,較高的召回率能夠減少系統漏報率,防止檢測系統因遺漏攻擊導致重大損失。所以,OverlapRHS 僅以損失些許精確率為代價,提升了召回率以及綜合性能,進一步體現了OverlapRHS的優勢。
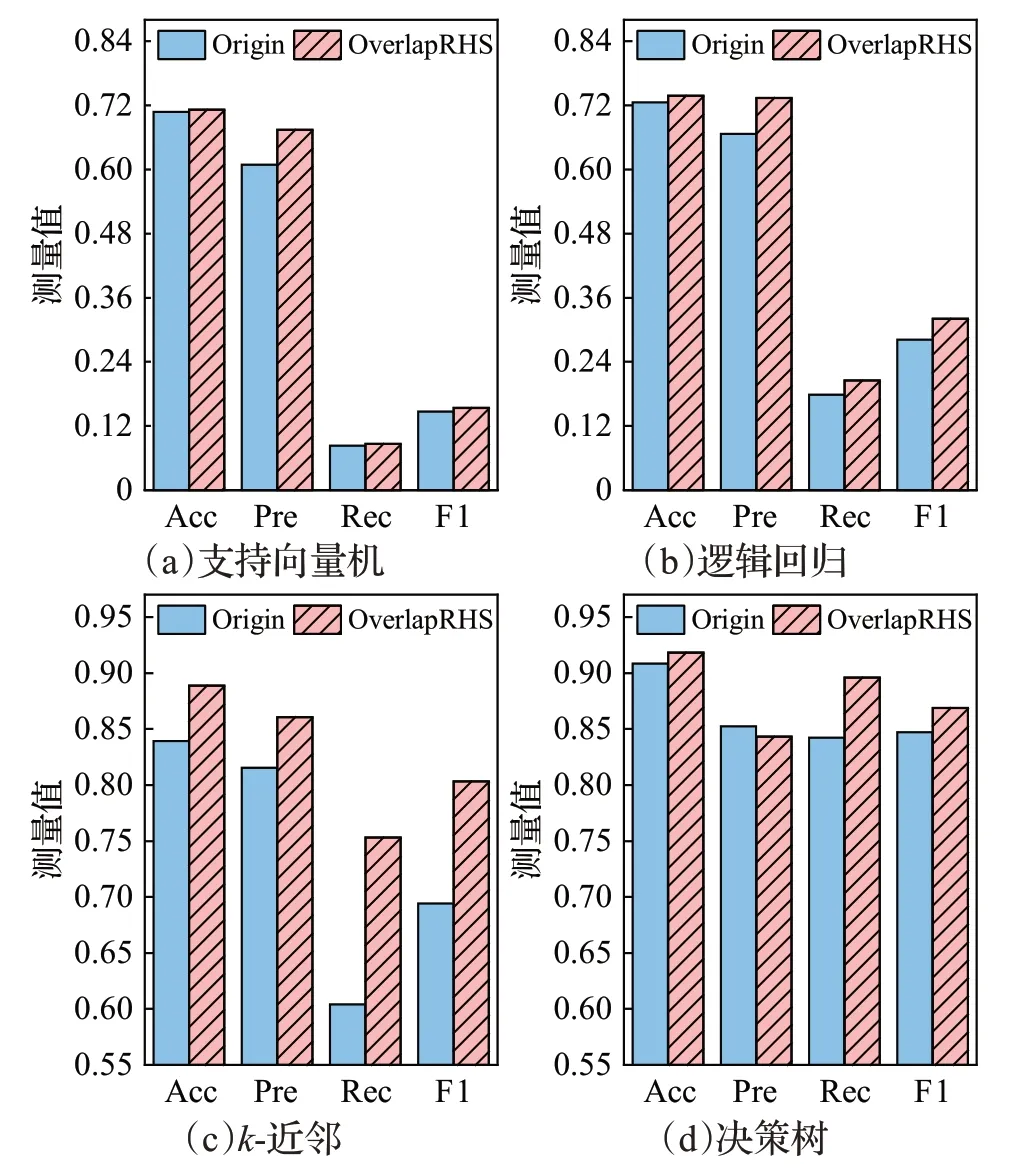
圖8 Power數據集上OverlapRHS對各分類器的性能提升對比Fig.8 Performance improvement comparison of OverlapRHS on Power dataset for each classifier
如圖9是NSLKDD數據集上OverlapRHS對各分類器的性能提升對比結果。由圖可知,各分類器在Origin和OverlapRHS 上均達到了很高的召回率,這說明各分類器存在著較低的漏報率,但同時也說明NSLKDD 數據集中存在著大量具有相似特征分布的正類和負類樣本,也即是存在較高的類別重疊,從而導致分類器無法有效學習各類數據特征,在面對負類樣本時錯誤地將其歸為正類,導致了高召回率、低精確率。前面提到,召回率對異常檢測很重要,但是并不意味著精確率不重要,精確率較低會導致系統的誤報率較高。從圖中可以直觀地看出,高召回率導致了各分類器存在著較低的精確率。但是NSLKDD 數據集在經過OverlapRHS 的優化之后,各分類器維持或略微提升了當前的高召回率,并且將各分類器的精確率提升了約2.9%~6.9%,準確率提升了約2.3%~6.1%,F1 分數提升了約1.6%~3.7%。可見,對于網絡入侵檢測領域的數據集,OverlapRHS依然展現出了不俗的數據優化能力。

圖9 NSLKDD數據集上OverlapRHS對各分類器的性能提升對比Fig.9 Performance improvement comparison of OverlapRHS on NSLKDD dataset for each classifier
2.2.3 各采樣方法對比結果分析
為了進一步探索OverlapRHS相較于其他處理類不平衡問題采樣方法的有效性,實驗以G-mean值為基準,它是評估數據各類別召回率的綜合評價指標,并兼顧整體檢測效果,G-mean 值越大,表明分類器的性能越好、漏報率越低。通過在每個數據集上分別計算支持向量機、邏輯回歸、k-近鄰和決策樹分類器在NearMiss、SMOTE、ADASYN、SMOTE-NCL 以及OverlapRHS 方法上的G-mean 值,得到如圖10 所示的對比結果,圖中每個數據集為一個子圖,橫軸為不同的分類器,縱軸為各方法在每個分類器上的G-mean值。
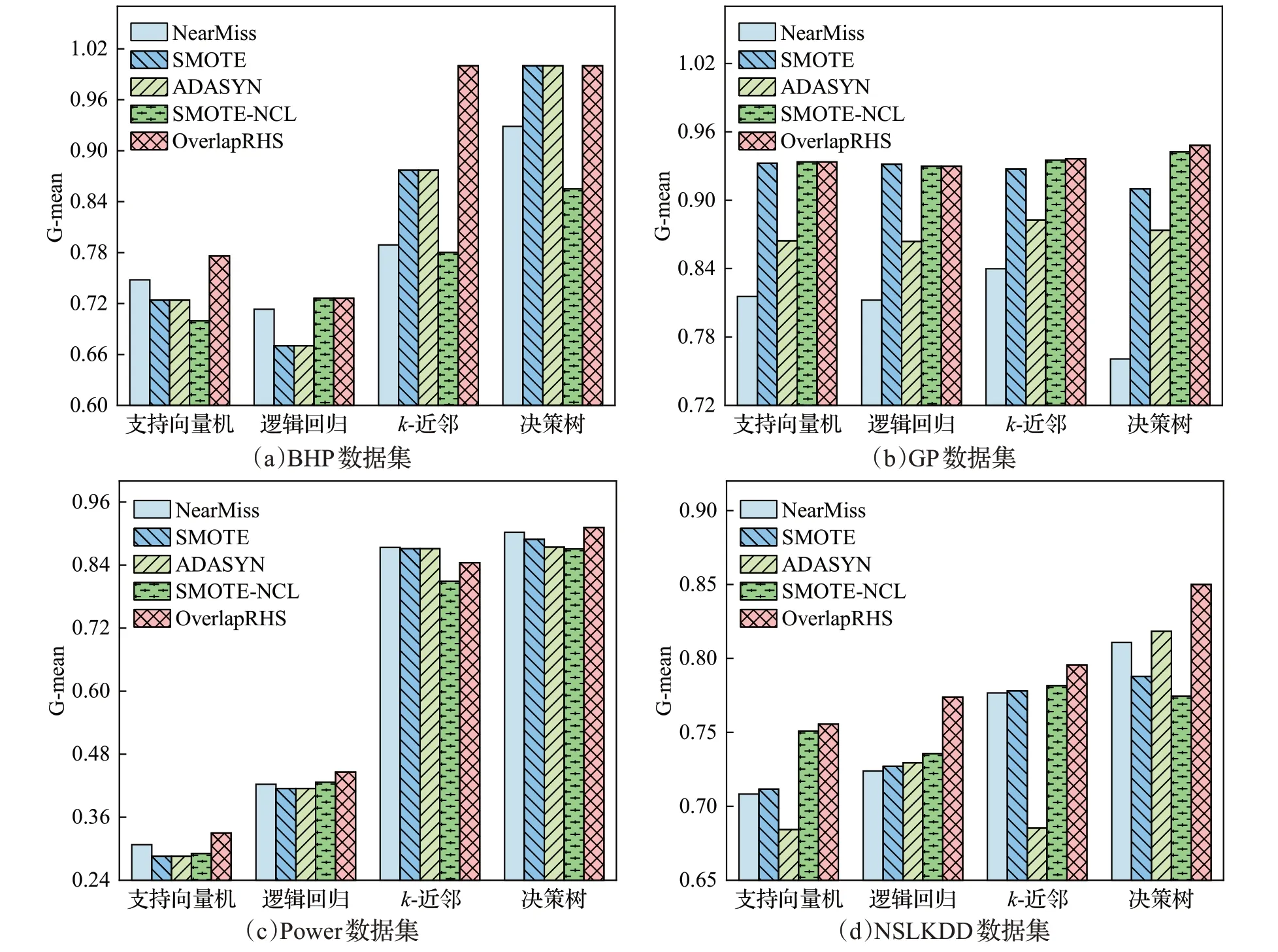
圖10 不同數據集下各分類器在不同方法上的G-mean值對比Fig.10 Comparison of G-mean values of each classifier on different methods under different datasets
觀圖可知,在圖10(a)BHP 數據集中,OverlapRHS與其他4 種方法相比,在支持向量機上提高了約3.8%~10.9%。但在邏輯回歸上相比于SMOTE-NCL 并未改善,但較其他3種方法提高了約1.9%~8.3%。其中OverlapRHS 在K-近鄰上相比其他方法提升最為顯著,約14.0%~28.2%。在決策樹上,OverlapRHS 相較于SMOTE 和ADASYN 雖未改善,是因為它們的G-mean值均為1,不過與NearMiss 和SMOTE-NCL 相比卻有約7.7%~17.0%的大幅提升,進而說明OverlapRHS 具有有效性。在圖10(b)GP數據集中,OverlapRHS與SMOTE、SMOTE-NCL在支持向量機和邏輯回歸上的G-mean值相差無幾,性能差距不大,不過與NearMiss和ADASYN相比,OverlapRHS 分別提升了兩個分類器約8.0%~14.5%和7.6%~14.5%的性能。OverlapRHS 在k-近鄰和決策樹上相比于4種對比方法均有改觀,其中在決策樹分類器上改進較為可觀,相比各方法提升了約0.6%~24.6%。在圖10(c)Power數據集中,各方法在各分類器上的G-mean值難分伯仲。由于數據集存在的高維復雜分布特性,且G-mean值較為關注各類別數據的召回率,所以導致線性分類器的G-mean值較低。整體來看,雖然OverlapRHS結合各分類器在Power數據集上的G-mean值與其他方法相比改進不太明顯,甚至在k-近鄰分類器上的G-mean 值略遜于NearMiss、SMOTE 和ADASYN,但在絕大多數情況下,OverlapRHS在復雜Power數據集上的表現依然略勝于其他方法。在圖10(d)NSLKDD數據集中,可以看出,各分類器結合OverlapRHS 的G-mean 值均在不同程度上優于其他方法,相比于其他方法策略,在支持向量機上提升了約0.7%~10.5%,在邏輯回歸上提升了約5.2%~6.9%,在k-近鄰上提升了約1.8%~16.1%,在決策樹上提升了約3.9%~9.8%,進一步展現了OverlapRHS的有效性與魯棒性。
此外,從G-mean值角度考慮各分類器與OverlapRHS的搭配效果,縱觀全局,在4個數據集上,k-近鄰和決策樹是與OverlapRHS 結合最好的兩個分類器,二者整體的分類效果優于支持向量機和邏輯回歸。這一方面與分類器特性有關,k-近鄰和決策樹是非線性分類器,能很好地學習數據特征間的非線性關系;另一方面體現了OverlapRHS能夠很好地適應具有不同屬性且特征分布較為復雜的數據集,并在不同數據集下展現了較之于其他采樣方法的良好效果。
2.2.4 各采樣方法計算代價分析
計算代價是所有采樣方法需要考慮的重要因素之一,為了驗證OverlapRHS的計算代價,本文從時間代價和空間代價兩個角度出發,并以維數較高、數據特征分布較為復雜的Power 數據集和數據規模較大的NSLKDD數據集為基準,分析OverlapRHS 與NearMiss、SMOTE、ADASYN以及SMOTE-NCL方法之間的計算代價。
實驗所用運行平臺統一為Ⅰntel Core i7-7700HQ處理器,16 GB 內存。所得到的各采樣方法在Power 和NSLKDD 數據集上的時間代價和空間代價結果分別如表3、表4 所示。表3 中,STC(sampling time cost)表示采樣時間代價,單位為秒(s)。表4 中,SMC(sampling memory cost)表示采樣空間代價,單位為兆字節(MB)。
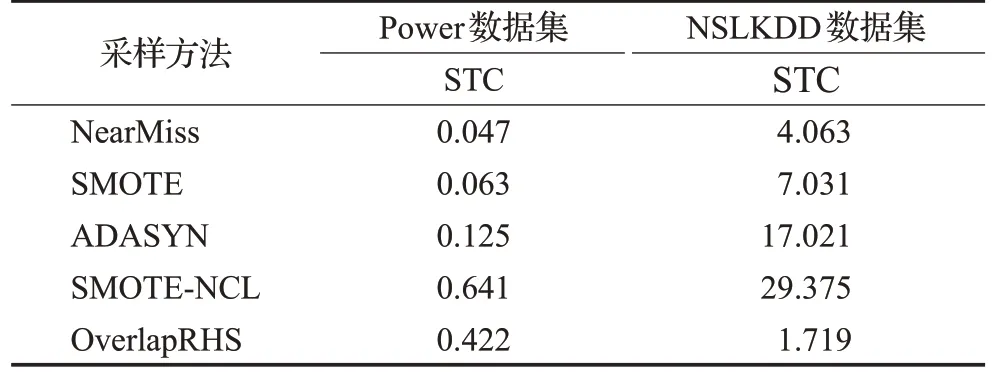
表3 各采樣方法的采樣時間代價Table 3 Sampling time cost of each sampling method單位:s
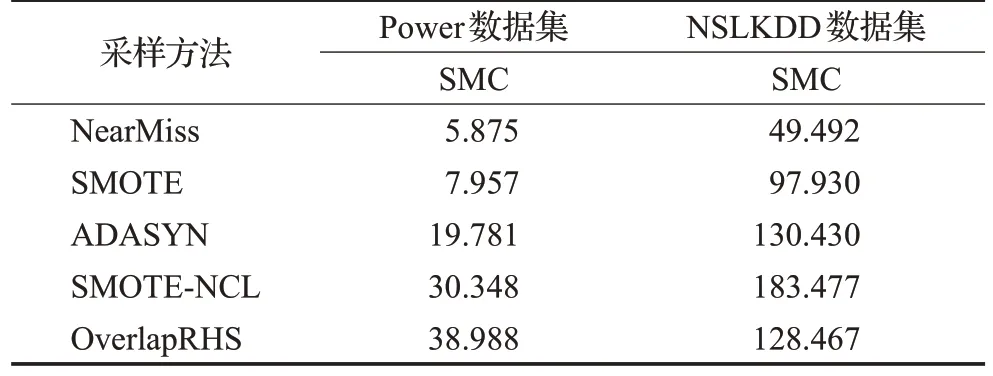
表4 各采樣方法的采樣空間代價Table 4 Sampling memory cost of each sampling method單位:MB
觀察表3和表4可知,4種對比方法在兩個數據集上的計算代價表現具有一般規律,即在時間和空間代價上,NearMiss 欠采樣方法要低于其他3 種非欠采樣方法,且混合采樣方法的時間和空間代價最高。由于OverlapRHS 僅作用于重疊區域的數據,所以在表3 中,其在Power 數據集上的時間代價相比于SMOTE-NCL要有所降低,甚至在NSLKDD 數據集上的表現要優于耗時最低的NearMiss 方法;在表4 中,雖然OverlapRHS在Power數據集上的空間代價要高于其他方法,但在規模較大的NSLKDD 數據集上的空間代價卻略低于ADASYN和SMOTE-NCL方法。
由上述分析可以得出,OverlapRHS 在采樣效率方面相比于其他部分方法有一定的提高。此外,從數據集屬性角度而言,數據特征分布的復雜與否以及數據規模的大小對于OverlapRHS的時間代價影響甚微;但OverlapRHS 空間代價的高低,相較于數據規模,更多地與數據特征分布的復雜程度有較大關系,即復雜的數據特征分布會加大OverlapRHS的空間占用。
3 結束語
本文針對工業控制系統異常檢測中存在的數據不平衡問題,從類重疊角度出發,利用支持向量數據描述構建了重疊檢測模型,并在此基礎上提出了一種面向重疊區域的混合采樣方法:OverlapRHS。
經實驗驗證,本文所提之方法,能夠有效檢測出不平衡數據的重疊數據,并通過對重疊數據區域施加混合采樣,增強了分類器的學習能力,使之在檢測精度、召回率等指標上均得到了不同程度的提升,并且普遍優于其他處理不平衡數據的采樣方法。未來的工作將研究如何運用生成對抗網絡在重疊數據區域生成高質量的少數類樣本,以防止插值采樣帶來的潛在過擬合風險;以及針對特征分布較復雜的數據進一步優化方法結構,以緩解計算資源的占用。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
