好奇心蒸餾雙Q網絡移動機器人路徑規劃方法
2023-10-10 10:39:56顧琦然
計算機工程與應用 2023年19期
張 鳳,顧琦然,袁 帥
沈陽建筑大學 電氣與控制工程學院,沈陽 110168
路徑規劃是移動機器人的自主導航中十分關鍵的技術之一。為實現對移動機器人的運動軌跡進行有效的控制,使其能夠順利地通過各種障礙到達目的地,通常需要使用路徑規劃算法來保證獲得最優路徑。傳統的路徑規劃方法過于依賴環境模型。而在深度強化學習中,深度學習能夠對高維信息進行有效的處理,從而使機器人能夠與周圍的環境進行持續的互動;在馬爾可夫決策過程的基礎上,強化學習能夠在復雜的環境中,實現移動機器人的連續決策來規劃出實時路徑。深度強化學習已成為工業機器人和室內移動機器人的路徑規劃方案之一[1],其最初用于游戲仿真領域中,Deep-Mind團隊在2013年首次提出DQN(deep Q-network)模型[2]。當前,DQN 算法已成為路徑規劃的主要算法之一,可是傳統的DQN算法存在著獎勵稀疏、樣本利用率低且過估計等問題。且針對這些問題,國內外許多學者進行了大量的研究。
對于獎勵稀疏問題,文獻[3]提出了一種基于DQN的路徑規劃算法,在此基礎上對實際目標進行采樣,加速訓練,并在一定程度上解決了獎勵稀缺性問題。文獻[4]根據人的喜好來學習獎勵函數,通過不使用獎勵功能,而是通過選擇路徑來獲得人類的喜好。文獻[5]采用虛擬計數方法,通過信息增益,將狀態頻率轉換為虛擬計數,并將其作為附加的內部獎勵。
文獻[6-12]分別通過RSV-DuDQN、二次主動采樣方法、NDQN、LSTM、重采樣優選機制、輸入深度圖像等對DQN算法進行改進,使DQN的性能得到了一定的改善,同時也解決了DQN的低采樣率問題。
對于DQN 過估計問題,許多學者也提出了不同的解決辦法。文獻[13]提出一種DTDDQN算法,通過融合DDQN 與平均DQN 進行參數訓練,使機器人在選擇動作時不會過估計。文獻[14]在DQN算法基礎上與Sarsa算法進行融合,用于減少過估計對DQN 產生的不良影響。文獻[15]提出一種EN-DRQN 算法,使得機器人可以發現許多新穎狀態,并作出合理的決策。文獻[16]提出使用重放緩沖器存儲網絡輸出以改進DQN 算法,使機器人驅動功率提升。文獻[17]在DQN 中引入修正函數來改善評估功能,使狀態-動作值的最優與非最優的差異增大,來解決過估計問題。文獻[18]提出了一種分散的傳感器級避碰策略,能夠為大型機器人系統找到有效的、無碰撞的路徑。文獻[19]提出在Gazebo仿真環境中對DQN 進行訓練提升機器人的環境適應性,降低過估計影響。
上述方法,一定程度上提高了DQN算法的性能,但只是針對過估計、樣本利用率低和稀疏獎勵中的單一問題進行了有效改進,為了更有效地綜合性解決此類問題,提出一種基于CDM-D3QN-PER 的端到端路徑規劃算法。在機器人感知端引入LSTM,通過“門”篩選關鍵信息解決點云信息的長序列數據問題;其次,使用PER對具有較高優先級的樣本進行訓練,解決樣本質量的問題;接著融合CDM,增加機器人的內在好奇心,避免出現機器人因缺乏反饋而陷入困境的問題,提高環境探索率。最后,利用Gazebo平臺對算法進行驗證,并在兩種不同的復雜仿真環境下,分別對DQN、DDQN、D3QN和CDM-D3QN-PER進行了比較。實驗表明,CDM-D3QNPER算法的穩定性和到達目標點次數得到有效提升,該算法使移動機器人在與環境交互中可更高效地獲取最優路徑,在路經規劃技術中具有一定的研究意義。
1 DQN及其改進算法
1.1 DQN
DQN 算法的兩個創新點,即經驗回放與設立單獨的目標網絡。DQN 針對Q-learning 做出一下改進:(1)DQN 中的數值函數是由深度CNN 逼近的。(2)在DQN中引入了一種基于經驗回放的訓練模型。(3)DQN獨立地設定了用于分別處理時差算法TD誤差的目標網絡。Q-learning中的參數更新公式如式(1)所示:
其中,TD 目標r+γmaxa′Q( )s′,a′;θ在計算時用到了網絡參數θ。
1.2 Double DQN
Double DQN 主要是解決DQN 過估計問題[20]。該方法的關鍵在于利用不需要的值函數,分別對TD 對象的行為進行選擇以及對TD對象的行為評價。
在Q-learning中,TD對象的動作選擇是在下一種狀態下,被確定為最大的狀態動作。動作評價是在選擇下一種狀態下的最佳動作,從而構建目標。DDQN使用不同的數值函數來選取和評價動作。其更新公式見式(2):
由上式可以看出,動作的選擇采用θ網絡,a*=arg maxaQ(St+1,a;θt)。動作評估采用θ′ ,1+γQ(St+1,a*;θ′t)。
1.3 Dueling DQN
Dueling DQN[21]把神經網絡中Q價值的輸出分成兩部分,第一部分是狀態價值V,這部分價值由狀態直接決定和Action 無關。第二部分就是動作價值和狀態價值的差值A,每一個Action都存在一個差值。這兩部分構成倒數第二層的神經網絡,節點數為Action數加1。然后最后一層的Q值就可以直接由V和A相加構成:
在實際操作中,需要減去一個平均值:
2 CDM-D3QN-PER算法
傳統DQN算法在復雜環境中因為缺乏關鍵信息且獎勵稀疏,規劃任務很難成功,為了提高路徑規劃任務,提出了一種基于改進的雙Q網絡移動機器人路徑規劃方法——CDM-D3QN-PER算法。該算法在DDQN與Dueling DQN 融合的D3QN 模型的基礎上,加入LSTM、CDM 和PER。CDM-D3QN-PER 算法模型如圖1所示。
(1)移動機器人通過激光傳感器搜集環境信息,并將當前時刻的狀態信息送入可專用于處理雷達產生的長序列點云信息的LSTM中。
(2)雙目相機將收集到的圖像信息經過卷積神經網絡處理,兩者信息與Concat 函數結合,輸入到D3QN 的輸入端進行訓練。
(3)獲取到Q值和當前最優執行動作A,切換到下一時刻狀態,將當前和下一刻狀態信息輸入到CDM 模型,計算出前向損失函數與預測損失函數。
(4)將當前和預測狀態信息輸入到CDM,獲取反向損失函數,將兩個損失函數整體優化并與預測損失函數對比,提高移動機器人環境探索效率,獲取更多獎勵值。不斷重復進行以上過程,累積獎勵值最大化,直至得到最優動作值函數Q對應的最優動作。
CDM-D3QN-PER算法具體流程如下所示:
2.1 機器人內在獎勵獲取方法——CDM
CDM-D3QN-PER算法中采用內在好奇心模塊(ⅠCM)和隨即網絡蒸餾(RND)結合的隨即網絡蒸餾(CDM)算法獲取內在獎勵值。算法模型如圖2所示。
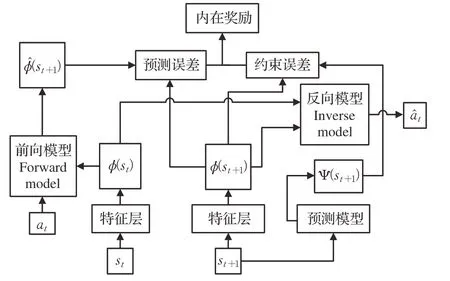
圖2 CDM模型Fig.2 CDM model
ⅠCM 模型通過對前時間狀態信息st和下一時間狀態信息st+1進行特征提取計算出前向損失函數LF。輸入當前動作at和預測動作a?t,計算出反向損失函數LI。RND模型通過輸入下一時間狀態信息st+1計算出預測損失函數LP。
二者結合后的CDM 算法既保留了ⅠCM 把無用信息過濾掉的優勢,確定特征提取后的信息都是有用的信息并保持探索,同時兼顧了RND 判斷當前狀態是否已經探索過。
其中前向模型(forward model)利用L2范數作為損失函數:
反向模型(inverse model)的損失函數為:
預測模型(predict model)的損失函數可表示為:
最后,機器人的學習目的是:
在D3QN算法中添加改進后的內在好奇心機制,將激光雷達采集的狀態信息st作為CDM 模型的輸入數據,在訓練時不斷優化網絡參數,通過好奇心驅動機器人在路徑規劃任務中主動探索未知狀態。
2.2 機器人點云信息處理方法——LSTM
激光雷達能夠適應不同的光照環境,長短時記憶網絡(LSTM)利用點云數據處理激光雷達采集到的環境與機器人狀態數據,以解決長序列訓練中的梯度消失、爆炸等問題。在路徑規劃中,收集到的數據經過該網絡處理后得到統一的障礙物狀態與機器人自身狀態輸入到D3QN網絡中,再次經過全連接層處理后輸出的便是用于選取最優動作的動作值函數Q,LSTM 的結構模型如圖3所示。
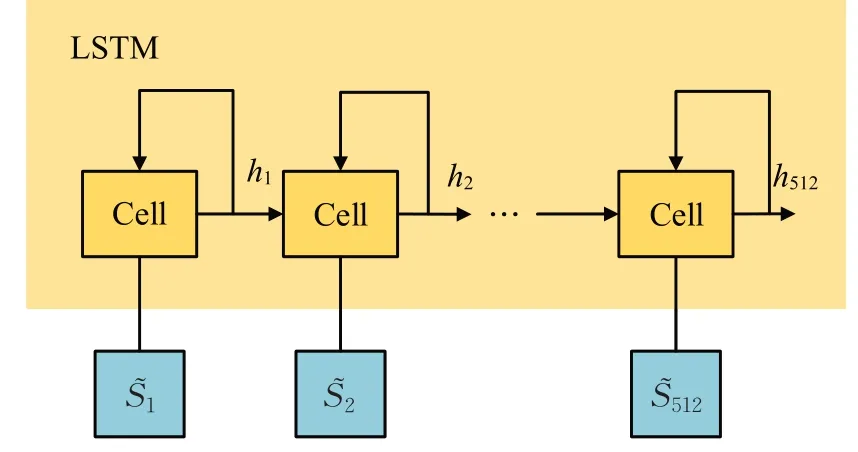
圖3 LSTM模型Fig.3 LSTM model
LSTM通過三個“門”機制完成信息的去留:
(1)首先,確定細胞狀態丟棄的信息由一個叫“遺忘之門”的sigmoid 單元進行處理。在0 到1 之間,通過觀察ht-1和xt信息,可以輸出向量的保存還是放棄。
(2)利用ht-1和xt通過輸入門的操作來決定更新信息。通過輸入門得到新的機器人狀態信息。
(3)在更新狀態之后,要根據輸入的和來判斷輸出的狀態,通過輸出端的sigmoid層獲得一個判定條件,再通過tanh層獲得-1的矢量,再用輸出端獲得的判定條件乘以這個矢量。
各單元門的工作原理公式如式(9)~(13)所示:
2.3 機器人樣本處理方法——PER
在路徑規劃中,DQN 的取樣方法采用了在經驗回放中均勻取樣,這種方法并不高效,對于機器人而言,由于這些數據的偏重性不同,針對該問題使用優先經驗回放(PER)。該算法是指在均勻取樣中,給有較高學習效率的樣品以較大的取樣加權。定義采樣的概率為:
其中,Pα j對于第j個傳輸樣本的優先權,α被用來調整優先度(當α取零時化成均勻取樣),下面兩種方式的不同是優先權的定義不同:
其中,δi為DQN的TD-error,?用于防止概率為0。
PER 將當前狀態信息、下一個狀態信息、動作值等環境交互信息通過存儲到記憶回放單元中,并對其中的樣本以概率P進行優先級排序。
當記憶回放單元里的樣本被儲存到一定容量時,通過提取其中部分概率P高的樣本,將樣本中的當前狀態信息輸入到Q網絡中,以獲取當前狀態信息的Q值。
3 實驗結果與分析
3.1 仿真實驗環境
由于深度強化學習的訓練要求有海量的數據支持,而且在實際操作中很可能會破壞硬件設備,所以大部分的訓練都是在仿真環境中進行。為了減少虛擬和真實場景中機器人可視測量的差異,即將激光測距技術應用于實驗環境中。
實驗環境為CPU服務器,TensorFlow框架,Python3.6,Gazebo7.0,采用Jackal 四輪機器人在Gazebo 搭建仿真環境中進行訓練,其機器人帶有激光測距技術。Jackal四輪機器人通過對運動中的實時定位進行分析,并對其與障礙物及目標點的距離進行分析,將激光傳感器收集到相對自己坐標的坐標數據作為輸入,輸出連續的轉向指令,通過激光測距傳感器來實現探索最優路徑。
在實驗中,先把移動機器人的前向速度設置為:3 m/s,角速度為:0.03 rad/s,其余速度為:0.05 m/s。再構建有障礙和無障礙的室內環境進行訓練,來檢驗DQN、DDQN、D3QN和CDM-D3QN-PER的算法性能。
如圖4、5 所示,仿真環境1 是四面圍墻都是完全封閉的,可以讓機器人在這里接受訓練,從而達到躲避圍墻和抵達目的地的能力。仿真環境2是加入了5個正方體障礙物,分別是4個有規則和1個無規則,進一步提高了機器人的路徑規劃難度,并使其具備了規避靜止障礙的能力,從而可以進一步驗證算法的穩定性。
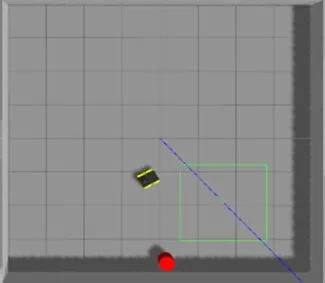
圖4 仿真環境1Fig.4 Simulation environment 1

圖5 仿真環境2Fig.5 Simulation environment 2
表1 為CDM-D3QN-PER 參數設置。在這里,探索因子ε起初值為1,ε∈(0.1,1),跟隨機器人的迭代數增大呈線性下降趨勢。經網絡中的參數更新是基于均方根的隨機梯度遞減算法,根據每個緩存器的優先回放機制,從緩沖區中抽取最小比特尺寸為32 的采樣更新網絡。為達到路徑規劃的目的,將運動進行離散化,其基礎運動包括:向前、向左轉、向右轉、左轉彎、右轉彎。在基礎動作上修改不同速度值,使其增加到11 個離散的可執行動作,動作名稱與速度值分別為A1(1,-1)、A2(1,-0.5)、A3(1,0)、A4(1,0.5)、A5(1,1)、A6(0.5,-1)、A7(0.5,0)、A8(0.5,1)、A9(0,-1)、A10(0,0)、A11(0,1)。
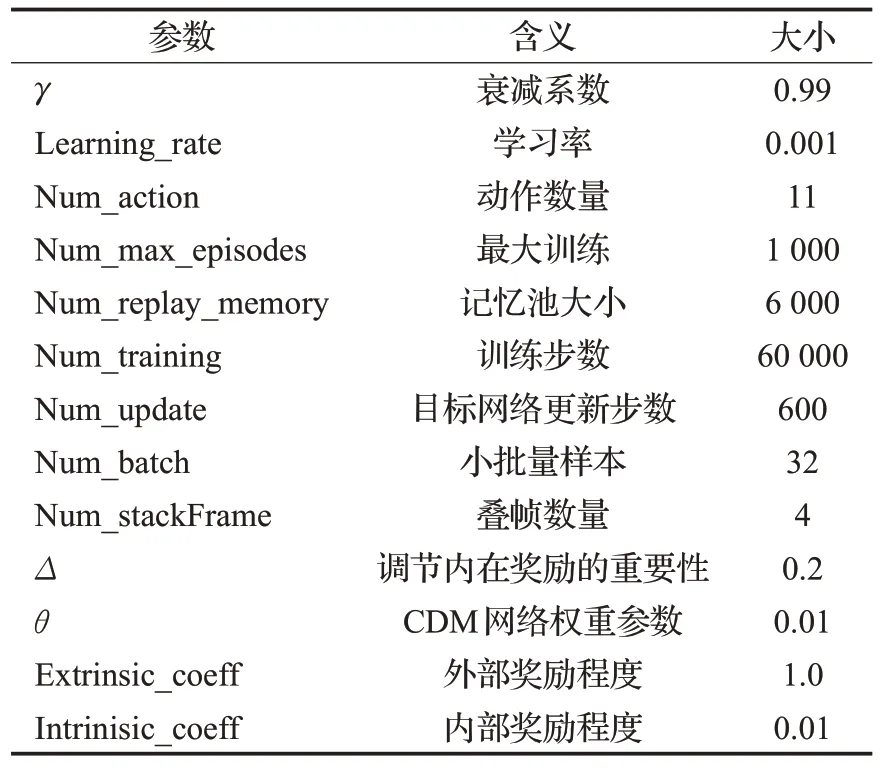
表1 仿真參數設置Table 1 Simulation parameters setting
獎賞值設置如式(17)所示:
在獎勵設定中,獎勵設定包含正、負兩個獎勵,以1為單位的紅色圓筒為目標點,作用距離為0.8 m,移動機器人以影響距離閾值檢測到目標位置,獲得+20 正獎勵,持續訓練,直到超過時間或者沖撞,才能繼續進行下一輪;如果機器人在最小的影響范圍內與障礙物發生碰撞,則獲得負值-20,本次訓練結束,繼續進行下一輪,完成指定的訓練次數結束。訓練次數是600回合。
3.2 實驗結果對比分析
(1)無障礙環境仿真分析
DQN、DDQN、D3QN 和CDM-D3QN-PER 這4 種算法的獎勵值隨訓練步數的變化趨勢如圖6所示,可以明顯驗證出CDM-D3QN-PER 算法的獎勵得分更加穩定,在300回合逐漸穩定收斂。D3QN在410回合開始穩定收斂。可DQN、DDQN 算法波動性較大,尤其是DQN幾乎完全波動,且兩者獎勵值均未出現穩定收斂。
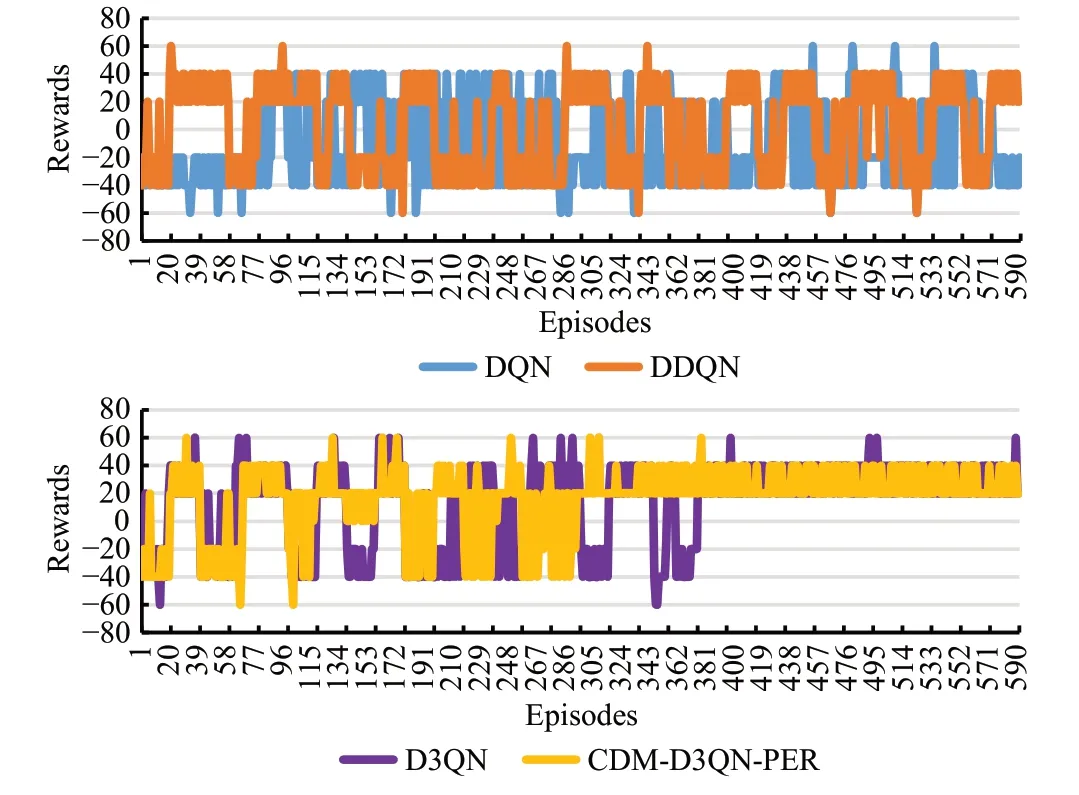
圖6 無障礙仿真環境累積獎勵值Fig.6 Accumulated reward value for empty simulation environment
由表2可知,CDM-D3QN-PER算法在301~600回合中,平均獎勵值穩定達到了30左右,且均為正數并穩定變化,在401~500 回合達到最大平均值30.82,其收斂效果遠遠超過其他3種算法。D3QN在401回合后平均獎勵值才剛剛穩定在30左右,并在401~500回合達到最大平均獎勵值29.82。DDQN 在201~300 回合達到最大平均獎勵值15.60,且最終平均獎勵值為負數。DQN 平均獎勵值均為負數,在101~200 回合達到最大平均獎勵值-5.59。
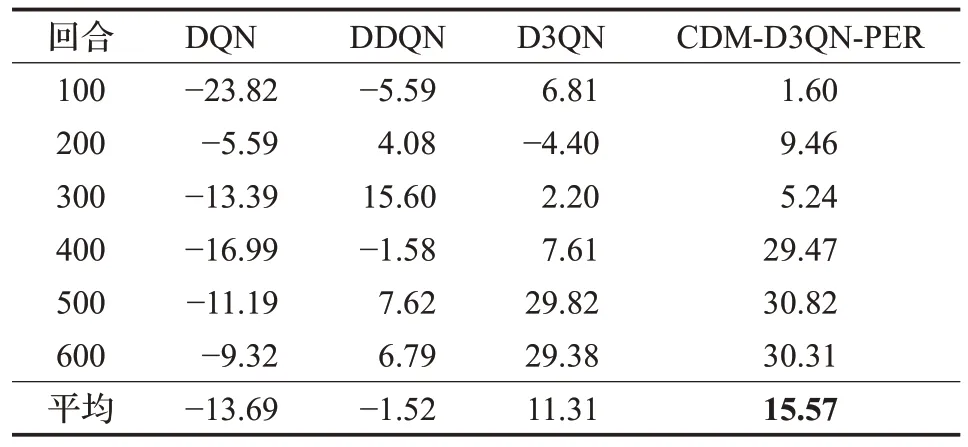
表2 無障礙環境的平均獎勵值Table 2 Average reward value of empty environment
以上結果表明,CDM-D3QN-PER 算法可以在較少的回合數中完成對移動機器人的訓練,并獲得較高的平均獎勵值,在該算法下移動機器人可以更好地與無障礙環境進行交互。
(2)有障礙環境仿真分析
從圖7可以看出,除了CDM-D3QN-PER算法在350回合左右開始穩定收斂并已經完全掌握躲避障礙物的能力,并且可以成功到達指定目標點,獲得相應正向獎勵+20,其獎勵值穩定在20 到40 以內。D3QN 在450 回合剛剛開始收斂,其余兩種算法的獎勵值均一直在正負值波動。
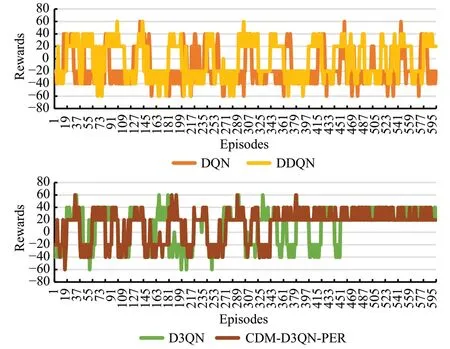
圖7 有障礙仿真環境累積獎勵值Fig.7 Cumulative reward value of obstacle simulation environment
表3 表明,DQN 算法的平均獎勵值均為負值,說明移動機器人幾乎無法到達指定目標點獲取最優路徑。DDQN算法除了在前100回合獲得短暫的正值,且為最高平均獎勵值5.60。D3QN 在101~200 回合中為負值1.19,其余皆為正值,并在401~500 回合中獲得最高平均獎勵值11.39,雖然與DQN、DDQN 相比訓練效果有提升,但是仍然會產生碰撞。CDM-D3QN-PER 算法雖然因為環境增加了障礙物訓練效果略微有些影響,但平均獎勵值全為正值,最高平均獎勵值為26.01。而DQN 和DDQN 算法的總平均獎勵值皆為負數,這表示移動機器人訓練效果欠佳,不適合復雜度較高的有障礙環境,并且D3QN 的訓練效果也遠不如CDM-D3QNPER穩定。
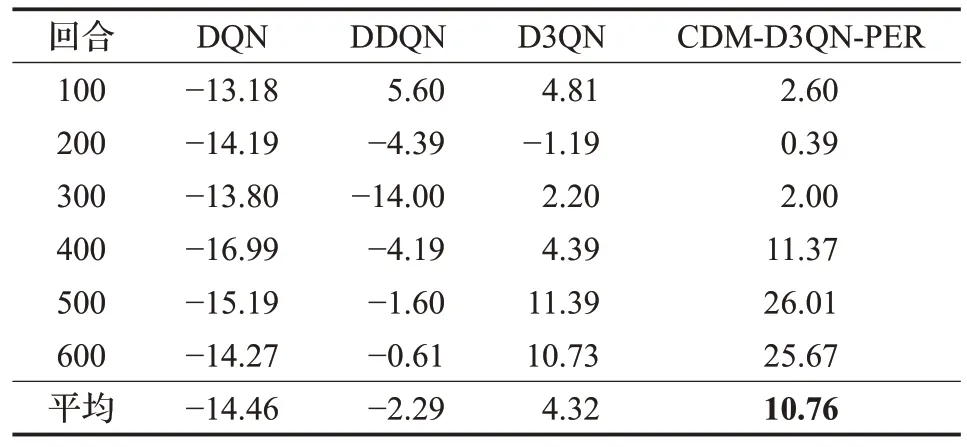
表3 有障礙環境的平均獎勵值Table 3 Average reward value of obstacle environment
以上結果表明,CDM-D3QN-PER算法可以在較少的迭代次數下達成對移動機器人在有障礙仿真環境的訓練效果,并獲得較高的平均獎勵值,獲得最優路徑。
移動機器人訓練時,獲取的正獎勵值越多,說明機器人的動作策略越準確,在路徑規劃過程中,越容易繞開障礙物到達指定的目標點,最后得到的路徑也是越接近最優的。
以成功率P(如式(18)所示),即移動機器人到達指定位置這一指標分析,CDM-D3QN-PER 比其他3 種算法有明顯提高,CDM-D3QN-PER 在無障礙環境下600 回合中,有501 次到達了目標點,是DQN 算法到達次數的2.84 倍;在有障礙環境下,600 回合中,有428 次到達了目標點,是DQN算法到達次數的2.80倍。
在所有的600 回合中,Ng代表了成功完成任務的回合數,N代表了訓練中的全部回合。
4 結束語
本文在傳統DQN 算法的基礎上,提出了基于CDM-D3QN-PER 的路徑規劃方法。首先,該方法以D3QN 模型為基礎,使Q 值函數的估計更加準確。其次,在輸入端將多傳感器信息輸入到LSTM和CNN中,使環境信息得到更有效的處理。然后,PER 算法的利用給重要的樣本設置了優先級,提高了樣本的利用率和網絡收斂的速度。最后,融入CDM 算法增加了機器人的內在獎勵值,提高了對環境的探索率。實驗結果表明,CDM-D3QN-PER 算法的收斂性遠優于其余三種算法,在移動機器人路徑規劃中具有更好的自適應能力和穩定性。
猜你喜歡
北京航空航天大學學報(2022年6期)2022-07-02 01:59:12
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
制造技術與機床(2017年3期)2017-06-23 08:11:21
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
中國海洋大學學報(自然科學版)(2014年8期)2014-02-28 12:21:31
中國海洋大學學報(自然科學版)(2014年7期)2014-02-28 12:21:19
