基于深度學習的軟件自動修復方法的修復偏好研究
2023-10-12 02:24:26姜元鵬姜淑娟
計算機工程與應用 2023年19期
姜元鵬,黃 穎,姜淑娟
1.中國礦業大學 圖書館,江蘇 徐州 221116
2.中國礦業大學 計算機科學與技術學院,江蘇 徐州 221116
軟件缺陷修復是軟件調試維護過程中的重要環節,并且隨著軟件復雜程度的增加以及軟件規模的擴大,人工定位并修復軟件缺陷越來越難實現,且面臨成本昂貴、難以修復等問題[1-2]。而利用軟件自動修復方法可以大幅度提高軟件調試的效率,減少軟件維護所耗費的開銷。近年來,隨著深度學習技術的發展,越來越多研究人員將深度學習方法引入到軟件自動修復領域,軟件自動修復方法成為軟件工程領域研究熱點[3-5]。
目前主要的傳統的軟件自動修復方法可以分為基于搜索的方法與基于語義的方法,國內外專家學者已經重點對傳統的基于搜索的程序自動修復方法以及基于語義的軟件自動修復方法進行了大量研究[6-9];近幾年提出了不少基于深度學習的軟件自動修復方法[10-12],基于深度學習的軟件修復方法主要從使用學習模型學習正確補丁特征、學習搜索相似性代碼以及學習錯誤代碼與正確代碼的轉換等角度來生成正確補丁。
目前的深度學習的軟件自動修復方法大多是通用的,即不針對某種特定的缺陷類型,更多的是引入深度學習模型與相關的程序分析技術嘗試修復軟件代碼中的所有缺陷。而通用的自動修復方法由于針對性不強,因此對不同類型缺陷的修復效果通常是不同的。在已有的文獻中,部分文獻對修復的缺陷進行了簡單的分類,但是并沒有系統地對缺陷庫中的缺陷進行分類;不同類型的缺陷以及補丁具有不同的特征,在基于深度學習的程序自動修復方法中,深度學習模型的選擇是至關重要的,因為不同模型可能提取的特征不同。目前基于不同學習模型的程序修復方法針對不同類型缺陷的修復偏好尚不明確,在現存的文獻中沒有關于基于深度學習的軟件自動修復方法以及不同學習模型對不同缺陷類型修復性能的研究,因此,本文擬在對缺陷分類的基礎上通過分析比較近幾年有代表性的深度學習自動軟件修復方法對不同缺陷類型的修復偏好,可以幫助研究人員更好地了解不同的深度學習模型在軟件自動修復當中的作用,以便更好地進行軟件自動修復工作。
1 基于深度學習的軟件修復工具
目前幾種比較常用的基于深度學習的軟件缺陷修復工具,其使用的深度學習模型包括自編碼器、卷積神經網絡、循環神經網絡、長短期記憶模型,它們的相關修復工具信息如表1所示。

表1 修復工具信息Table 1 Ⅰnformation about repair tools
表1 的第一列為5 種自動修復工具;第二列是每種修復工具使用的模型,其中EDM指的是編碼器-解碼器模型(encoder-decoder model,EDM),LSTM-EDM 即為基于LSTM 的編碼器-解碼器模型,同理CNNs-EDM 是指基于CNNs的編碼器-解碼器模型,attention指注意力機制,copy 則是指復制機制;第三列是各種工具工作的代碼粒度,包括了多粒度級、代碼行以及方法級;最后一列則是各個工具用于評估的數據集,這5種自動修復工具都在Java程序的缺陷庫Defects4J[13]上進行驗證評估。
1.1 DeepRepair
DeepRepair[14]工具旨在通過深度學習代碼的相似性排序并轉換語句來推導程序修復成分,主要使用的學習模型為嵌入模型與自編碼器。實現這一工具的技術方法可分為三個階段:語言識別、機器學習與程序修復階段。該工具的方法框架如圖1所示。
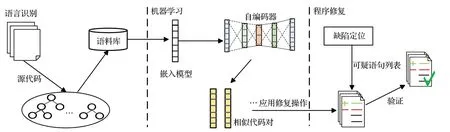
圖1 DeepRepair方法框架Fig.1 Framework of DeepRepair
1.2 SequenceR
SequenceR[15]是一種基于序列到序列的端到端的程序修復方法,該方法主要使用兩層的雙向長短期記憶模型。這一技術主要分為兩個階段:訓練以及推理階段。如圖2為SequenceR的方法框架。
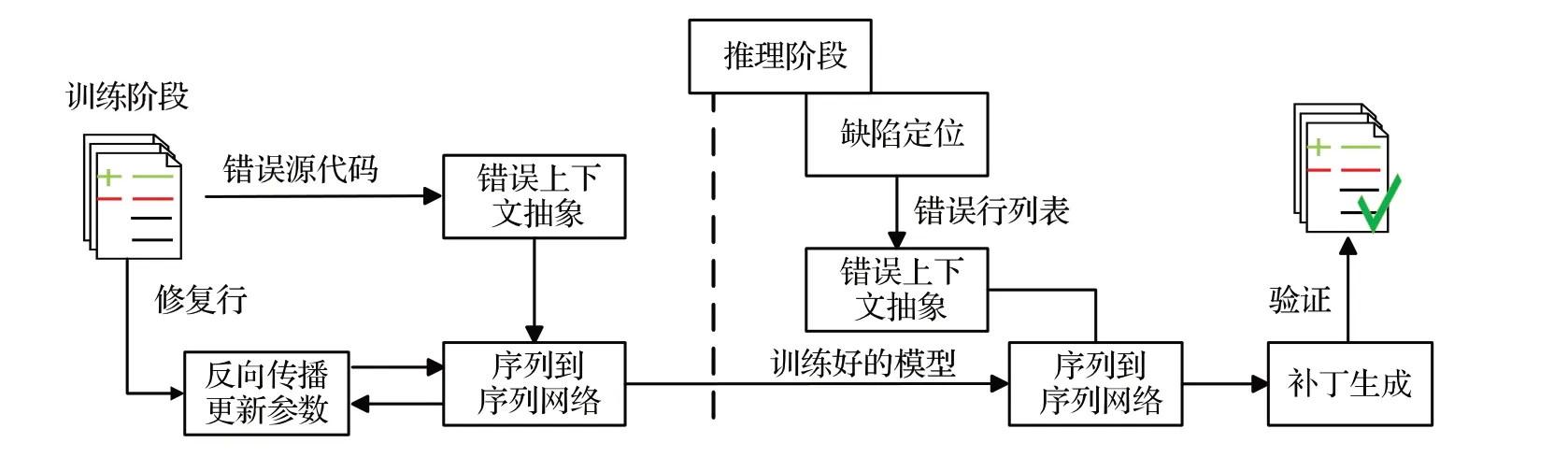
圖2 SequenceR方法框架Fig.2 Framework of SequenceR
1.3 CODIT
CODⅠT[16]使用基于樹的神經網絡對源代碼更改進行建模并學習代碼更改模式,即利用一個基于樹神經機器翻譯模型來學習代碼中更改的概率分布,該方法包括兩個模型,使用的都為LSTM。如圖3 所示,實現這一工具同樣為三個階段:補丁預處理、模型訓練、模型測試階段。
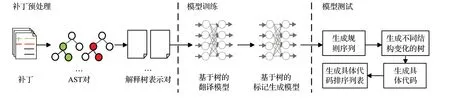
圖3 CODⅠT方法框架Fig.3 Framework of CODⅠT
1.4 DLFix
DLFix[17]是用于程序自動修復的基于上下文的代碼轉換學習方法,使用的是雙層基于樹的深度學習模型,該深度學習模型同樣為LSTM。工具實現主要分為四個階段:預處理、模型訓練、程序分析過濾和補丁重排序階段。如圖4為DLFix的方法框架。
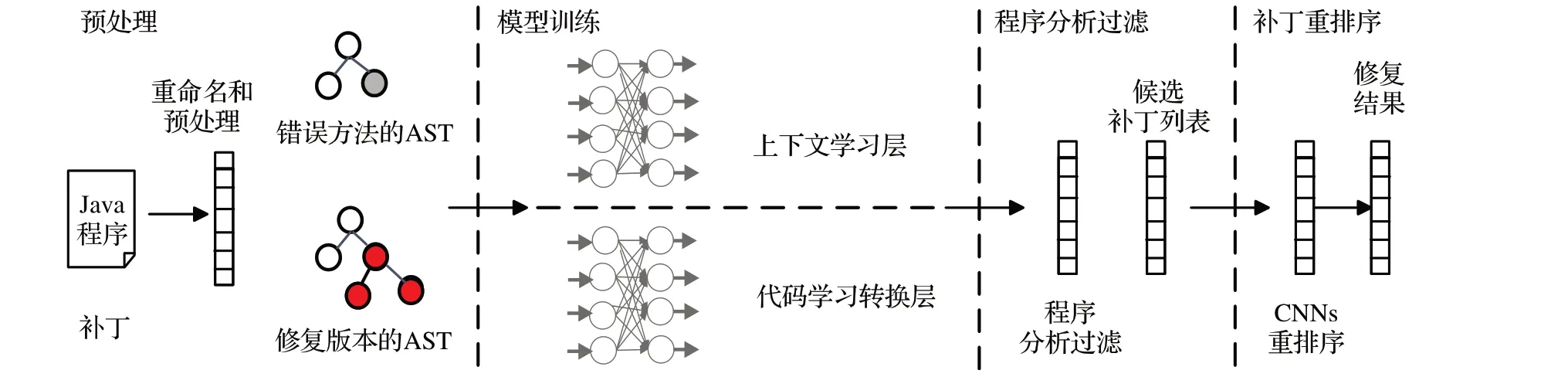
圖4 DLFix方法框架Fig.4 Framework of DLFix
1.5 CoCoNuT
CoCoNuT[18]結合上下文感知的神經機器翻譯模型并使用集成學習來進行跨多語言的自動修復,主要使用的神經網絡模型為卷積神經網絡,這是卷積神經網絡在程序自動修復中的首次應用。如圖5所示,這一技術同樣包括三個階段:訓練、推理和驗證階段。
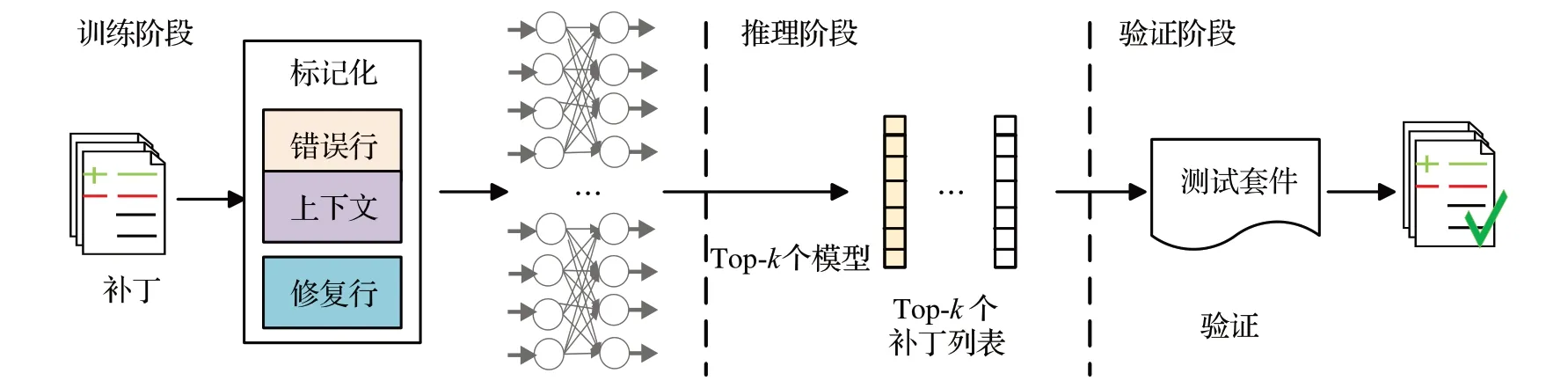
圖5 CoCoNuT方法框架Fig.5 Framework of CoCoNuT
2 缺陷分類研究
2.1 缺陷分類
缺陷分類有很多種方法,根據不同的分類目的,缺陷分類的過程、復雜度和應用領域也不同。在程序修復領域,Pan 等人[19]提出了針對Java 程序中的缺陷分類方法,并將缺陷根據語句特征分為9 大類。參照Pan 等人[19]及Liu 等人[20]提出修復模式,總結了10 個缺陷修復模式,并對缺陷庫Defects4J中缺陷進行分類。
通過對Defects4J 中的補丁進行分析,總結了基于代碼更改操作的10 個基本的缺陷類型,每個類型下會有不同的子類型。
(1)ⅠF語句:這一類是與ⅠF語句相關的缺陷,包括增加/刪除ⅠF謂詞、增加/刪除ⅠF主體、增加/刪除else語句、ⅠF條件表達式的更改,以及ⅠF語句與其他語句的替換。
(2)方法語句:這一類是與方法語句相關的缺陷。包括增加/刪除/更改方法聲明、增加/刪除方法調用、更改調用方法、更改參數值或參數數量、其他語句與方法調用的替換。
(3)循環語句:這一類是與循環語句相關的缺陷。包括增加/刪除循環、循環條件更改以及其他語句與循環體之間的替換。
(4)賦值語句:這一類是與賦值語句相關的缺陷。包括增加/刪除賦值語句以及賦值表達式的更改。
(5)switch:這一類是與switch語句相關的缺陷。主要包括增加/刪除case分支/switch條件的更改。
(6)try/catch:這一類是與try/catch 語句相關的缺陷。包括添加/刪除try語句或catch語句塊。
(7)return:這里的return 指代是return/break/continue/throw(拋出異常)語句,這類缺陷是指與它們相關的缺陷。包括增加/刪除這些語句、return 表達式的更改,以及這些語句之間的替換。
(8)類字段:這一類是與類字段相關的缺陷。包括類字段聲明更改、執行多個類實例創建。
(9)移動語句:這一類主要是指需要改變語句所在位置的缺陷。
(10)其他:這一類缺陷的修復包括類型更改、運算符更改、變量更改、整數除法更改。這些類型排除之前提到過的相關類型。
2.2 評測對象
由于目前Defects4J 是軟件自動修復工具最常使用的基準集,且進行比較的幾種基于深度學習的軟件自動修復工具都可在Defects4J 上進行評估,Defects4J 缺陷庫中的缺陷類型包括6 個項目,如表2 所示。這里使用的是Defects4J-v1.1.0
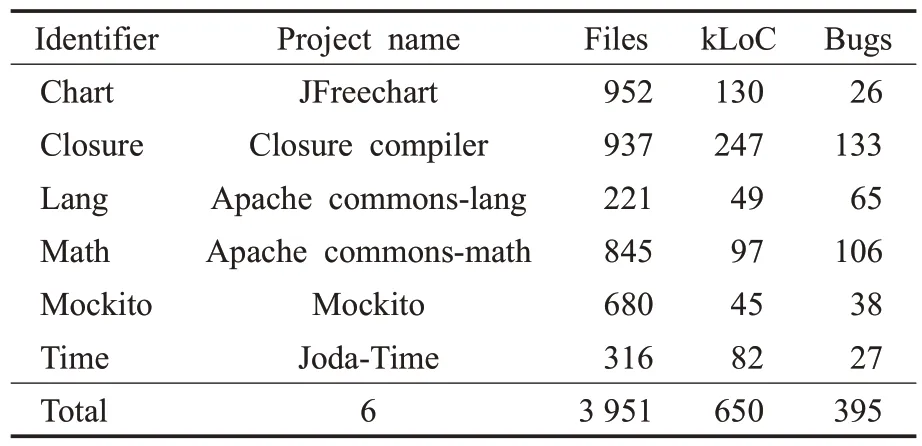
表2 Defects4J 的組成Table 2 Composition of Defects4J
在使用Defects4J數據集時,需要根據不同的模型對數據集進行不同的預處理。比如,在使用工具SequenceR時,由于SequenceR 專注于修復單行缺陷代碼,所以需要排除掉Defects4J中的非單行缺陷;在使用CODⅠT時,則需要從Defects4J的6個項目中創建一個代碼更改集。
2.3 Defects4J缺陷類型分析
Defects4J中全部缺陷類型組成,如表3所示。
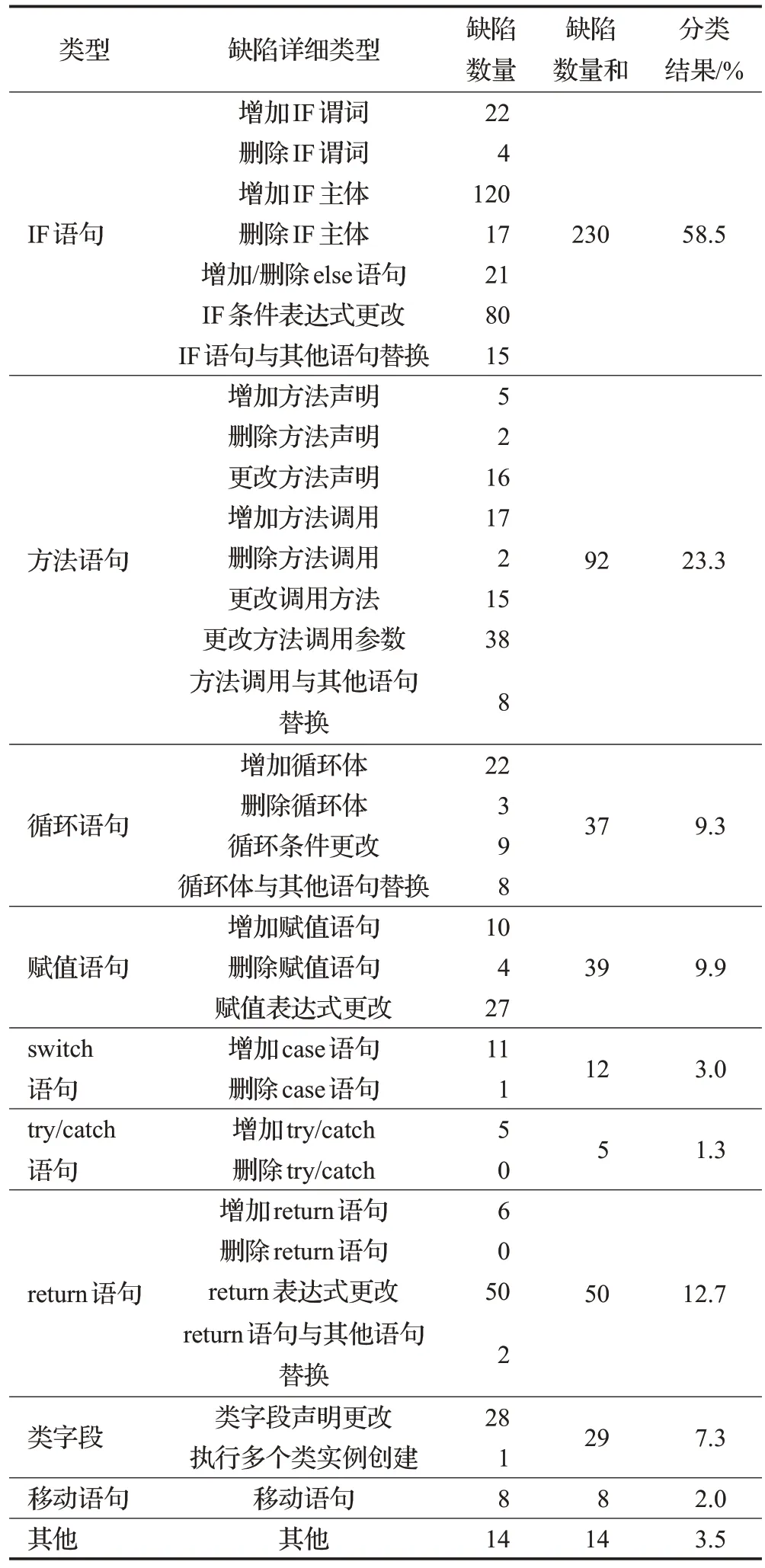
表3 Defects4J中缺陷的類型Table 3 Types of defects in Defects4J
Defects4J中與ⅠF語句相關的缺陷多達230個,占所有缺陷的58.5%,其中類型為“增加ⅠF主體的缺陷”數量最多,有120個,占ⅠF語句缺陷類型的51.9%,其次有80個缺陷為“ⅠF條件表達式更改”類型,占ⅠF語句缺陷類型的34.6%;方法語句類型:Defects4J 中與其相關的缺陷有92 個,是全部缺陷的23.3%,是除ⅠF 語句類型外最多的缺陷類型,而其中“更改方法調用參數”類型的缺陷數量最多;除此之外,Defects4J 中與return 語句類型相關的缺陷數量最多,共50個,占Defects4J中缺陷的12.7%;最少的是try/catch類型。要注意的是,由于Defects4J中的缺陷一般包含多個錯誤行,因此一個缺陷可能和多種缺陷類型相關,在表3 中,將Defects4J 中的缺陷歸到某一類時,主要是指該缺陷包含該缺陷類型的錯誤行,所以每種缺陷類型的缺陷數量之和會超過Defects4J中的缺陷數量395,因為同一個缺陷可能會與多種缺陷類型相關。
3 實驗
該實證研究的目的是研究基于深度學習的軟件自動修復方法對不同類型缺陷的修復偏好。為此,首先分析基于深度學習模型的軟件自動修復方法整體上對不同類型缺陷的修復概率,然后比較不同學習模型對不同類型缺陷的修復偏好,并比較分析每種方法各自更傾向于修復哪一類型的缺陷。
本文實驗的運行環境為64 位Windows 與Linux 系統,編譯環境為Python3。
3.1 不同缺陷類型的總修復概率
表4展示了5種修復工具通過實驗修復的不同類型缺陷的總的修復概率。由第三列可以看出,5種修復工具修復的缺陷類型涉及了除try/catch語句之外的9種基本類型,修復的缺陷數量最多的3種缺陷類型依次為ⅠF語句類型、方法語句類型以及return語句類型,然后是賦值語句與類字段類型的缺陷。而try/catch 語句類型的缺陷沒有得到修復的原因,可能是Defects4J 中這一類型的缺陷量最少,總共只有5個。
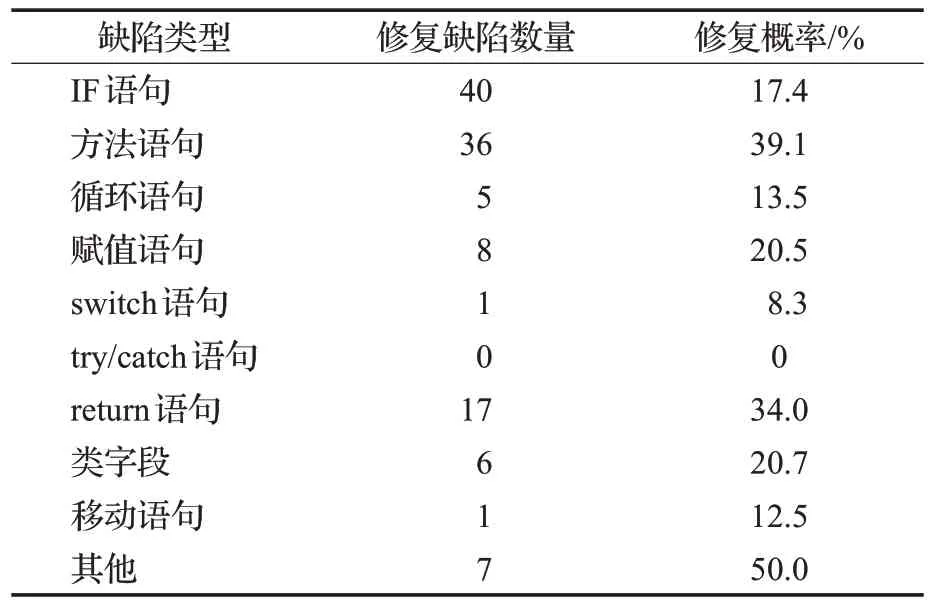
表4 所有修復缺陷的缺陷類型Table 4 Types of all repaired defects
表4所示的修復概率可以看出,其他類型的缺陷修復概率最高,其次是方法語句類型的缺陷,然后是return語句類型,賦值語句與類字段類型的修復概率相當,其后才是ⅠF語句類型的缺陷。可以看出,修復概率與修復缺陷數量并不是成正比的關系,基于下面的原因。
首先,其他類型的缺陷基本上只包含運算符更改、類型更改等簡單易修復的缺陷,而且數據集中這一類缺陷數量較少,因此盡管結果顯示這一類缺陷修復概率較高,但這只是表明修復方法傾向于修復復雜程度低的缺陷,而方法語句與return語句類型的修復概率較高,與之對應的修復缺陷數量也較高,可以得出基于深度學習的軟件自動修復方法對這兩種缺陷的修復偏好是較高的;對于賦值語句與類字段類型來說,由于類字段類型當中包括類字段的聲明與賦值,所以這兩種在很大程度上可以看作是賦值語句類型,因此兩者的修復數量與概率都相差不大;對于ⅠF語句,從缺陷分類的結果可以看到,數據集中與這一類型相關的缺陷數量最多,而復雜程度較高的缺陷基本都與這一類型相關,復雜程度越高越難以修復,因此這一類型相關的缺陷修復概率與前面幾種相比顯得不高。
因此,經過綜合分析后可以得知:對于修復的缺陷數量來說,基于深度學習的軟件自動修復方法修復最多的是ⅠF 語句類型、方法語句類型、return 語句類型的缺陷,但是對于缺陷修復的概率來說,由于受到缺陷復雜程度的影響,基于深度學習的軟件自動修復方法對ⅠF語句的修復概率較低,其他類型的缺陷修復概率較高,同時修復方法語句類型、return語句類型、賦值語句與類字段類型缺陷的概率也較高。
3.2 缺陷的修復偏好比較分析
表5 展示了基于不同深度學習模型的軟件修復工具在Defects4J上修復的不同類型的缺陷數量。第一列為缺陷類型,第二至六列是5種缺陷修復工具的修復缺陷數量;最后一行的缺陷總數總是小于等于10 種缺陷類型的修復缺陷數量之和,因為存在同一缺陷與多種缺陷類型相關的情況。
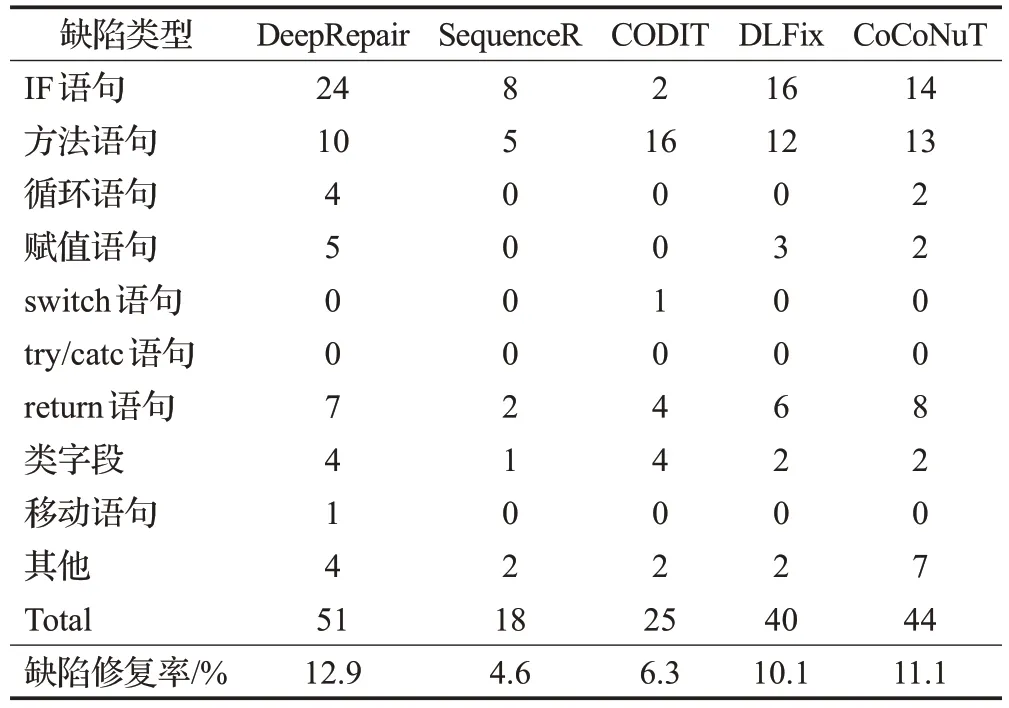
表5 各修復工具修復缺陷的缺陷類型組成Table 5 Types composition of defects repaired by each repair tool
如果僅從表4的占比來看,每一種類型缺陷的修復偏好相差不大,其根本原因在于現有的缺陷自動修復方法修復能力不足。例如,表5 中所示的修復Defect4J 數據集缺陷最多的DeepRepair 方法,僅僅修復了51 個缺陷,占總缺陷數的12.9%(51/395),使得每一種類的修復占比都比較低,差距小。在此背景下,DeepRepair 修復24個ⅠF語句類型缺陷,10個方法語句缺陷,前者是后者的2.4倍,由此可以看出修復偏好相差較大。
整體來看,除了CODⅠT之外,其他每種修復工具與3.1節的結論相符,修復最多的缺陷為ⅠF語句類型、方法語句類型以及return 語句類型的缺陷;對于CODⅠT,除了方法語句類型以及return語句類型的缺陷,修復的類字段類型的缺陷比ⅠF語句類型的缺陷更多。從最后一行可以看到,基于自編碼器且在多粒度上運行的Deep-Repair 修復的缺陷最多,與其他的修復工具相比,它修復的ⅠF語句類型、循環語句類型、賦值語句類型以及類字段類型相關的缺陷數量明顯高于其他工具,原因是DeepRepair使用了多個修復策略,并在多個粒度上尋找補丁。由此可知,修復策略、工作粒度對學習模型的修復效果具有極大的促進作用;而SequenceR修復的缺陷數最少,因為它只針對單行缺陷。下面詳細分析比較幾種修復方法的修復結果。
(1)基于LSTM、AE以及CNNs模型修復工具的修復結果分析
由于SequenceR、CODⅠT 與DLFix 使用基本的深度學習模型都為基于LSTM的編碼器-解碼器的神經機器翻譯模型,可將三者的修復結果合為一體以LSTM 表示,與其他兩種工具的修復結果進行比較;AE指的是基于自編碼器的DeepRepair 的結果;CNNs 指的是基于CNNs的CoCoNuT的結果。
如圖6通過韋恩圖表示了3種學習模型所修復缺陷的重疊的情況,重點關注修復結果的不同之處,并結合表5分析圖6中非重疊的部分的缺陷。
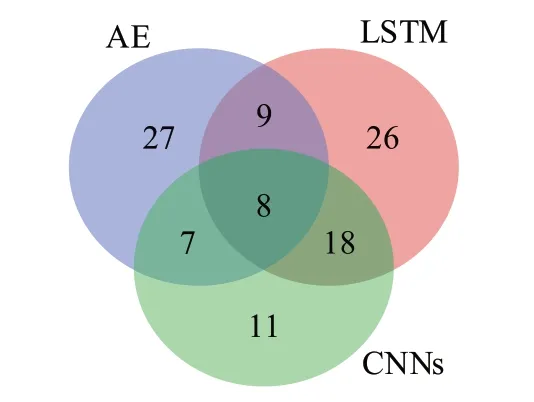
圖6 3種不同學習模型修復缺陷的重疊情況Fig.6 Overlapping of repaired defects of three different learning models
首先,對于DeepRepair,非重疊部分的27個缺陷,其中有48.1%的缺陷與ⅠF語句類型相關,這表明與其他模型相比,它更擅長于修復ⅠF 語句類型的缺陷,這與表5中的結果一致;同時,DeepRepair 修復的缺陷種類數是最多的,只有它修復了一個移動語句類型的缺陷,而且它修復缺陷中的賦值語句類型的缺陷占比明顯高于其他兩種基本學習模型。這表明基于自編碼器且擁有多種修復策略與工作粒度的軟件自動修復方法在修復的缺陷數量和缺陷類型數量上具有一定優勢。
其次,對使用基于LSTM 的編碼器-解碼器的神經機器翻譯模型的修復方法來說,與其他兩種模型相比,它們修復的26個缺陷中與方法語句類型相關的缺陷數最多,占比達到61.5%,這表明本文用于比較的3種基于LSTM 的修復方法整體上更傾向于修復方法語句類型的缺陷,這同樣與表5中的結果一致;同時,只有它獨自修復的缺陷中包含switch類型的語句。
最后,對于基于CNNs 的修復工具CoCoNuT 來說,不僅是從非重疊部分的11個缺陷的分析,還是從表5的分析中都可以發現,它的修復結果中,與ⅠF語句類型、方法語句類型以及return語句類型相關的缺陷數量相差不大,這表明它對這3 種類型缺陷的修復偏好相差不大。而從缺陷的復雜程度來看,DeepRepair 與CoCoNuT 能修復更高復雜程度的缺陷。
(2)SequenceR與CODⅠT的修復結果分析
對于同樣使用LSTM模型的兩種修復方法SequenceR與CODⅠT來說,SequenceR是序列到序列的神經機器翻譯模型,CODⅠT 是基于樹的序列到序列的神經機器翻譯模型,如圖7是SequenceR與CODⅠT的修復結果的重疊情況。
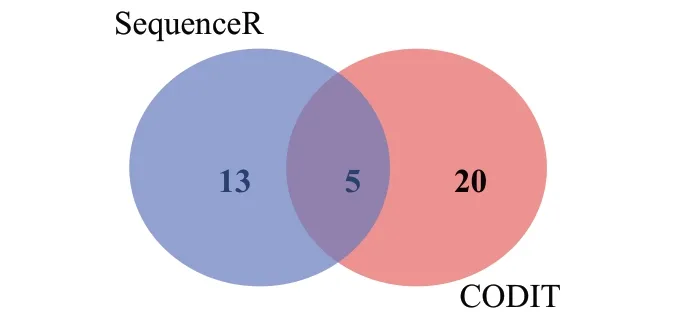
圖7 SequenceR與CODⅠT修復缺陷的重疊情況Fig.7 Overlapping of repaired defects of SequenceR and CODⅠT
其中SequenceR 單獨修復13 個缺陷,而CODⅠT 單獨修復20個缺陷。在非重疊部分,SequenceR修復更多的是與ⅠF 語句類型相關的缺陷,而CODⅠT 修復更多的是與方法語句類型相關的缺陷。造成這一結果的原因是SequenceR 是序列到序列的模型,針對的是代碼行,而CODⅠT和DLFix都是方法粒度的。這說明工作粒度在很大程度上影響了修復的缺陷類型。
(3)CODⅠT與DLFix的修復結果分析
對于使用LSTM 模型的兩種修復方法CODⅠT 與DLFix來說,CODⅠT是基于樹的序列到序列的神經機器翻譯模型,而DLFix則是雙層基于樹的代碼轉換的神經機器翻譯模型,如圖8是CODⅠT與DLFix的修復結果的重疊情況,CODⅠT單獨修復缺陷17個,而DLFix單獨修復缺陷32個。對圖8的非重疊部分的缺陷進行分析,并結合表5可以看到,使用DLFix比CODⅠT能夠修復更多缺陷;同時,從表5中可以看到,CODⅠT主要修復方法語句類型缺陷而較大程度上忽略ⅠF 語句類型的缺陷,而DLFix則彌補了這一缺陷,它對這兩種類型缺陷的修復偏好相差不大。
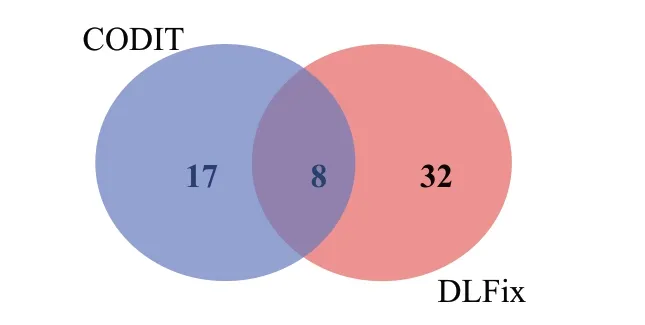
圖8 CODⅠT與DLFix修復缺陷的重疊情況Fig.8 Overlapping of repaired defects of CODⅠT and DLFix
3.3 有效性影響因素分析
可從內部有效性和外部有效性兩個方面來分析可能影響到本文實證研究結論有效性的影響因素。
影響內部有效性的因素主要來自兩個方面,一個是缺陷分類的標準,另一個是用于比較的修復方法。對于缺陷分類,本文參考了多篇文獻,根據修復模式逐個對缺陷進行了分類,保證了分類的準確性;對于修復方法,本文主要比較的是文中選取的五種修復方法的結果,而其他修復方法的結果如何有待進一步研究。而且在研究不同模型對缺陷類型的修復偏好時,其他因素(如工作粒度等)的影響較大,之后的工作可以進行探討。
而影響外部有效性的因素主要來源于缺陷庫。Defects4J中部分項目的缺陷數量較少,因此在分析不同項目內的缺陷時對結果的影響較大,但是本文主要是針對整體缺陷進行研究,因此很大程度上可以避免這一影響;而Defect4J 數據集不涉及深度學習模型的訓練,只是對訓練后的深度學習模型進行評估。本文之所以選取Defect4J進行分析,是因為本文中所有的方法在評估時都用到了該數據集。同時,Defect4J數據集是一個被廣泛使用的缺陷基準數據集,涉及的缺陷類型全面,適合進行缺陷修復偏好研究。為了進一步減少數據集方面存在的有效性威脅,在未來的工作中,將進行更全面的實驗,從而分析本文中的這些方法在更多缺陷基準中的修復偏好性。
4 結束語
本文根據缺陷修復模式對Defects4J 中的缺陷進行分類,通過實驗給出了5種基于不同學習模型的修復工具 在Defects4J 上整體的修復概率,同時分析這5 種修復工具各自在Defects4J 上的修復結果,并對各類缺陷的修復偏好進行比較分析。實驗結果表明,基于深度學習的軟件自動修復方法傾向于修復ⅠF語句類型、方法語句類型、return 語句類型的缺陷。基于自編碼器的軟件自動修復方法DeepRepair 更傾向于修復ⅠF 語句類型的缺陷,選取的基于LSTM 的編碼器-解碼器的修復方法整體上更傾向于修復與方法語句類型相關的缺陷,而基于CNNs 編碼器-解碼器的修復方法則對ⅠF 語句類型、方法語句類型以及return語句類型這3種類型缺陷的修復偏好相差不大。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
