基于PPO2強化學習算法的空間站軌道預報方法
2023-09-18 04:16:08雷騏瑋張洪波
中國空間科學技術 2023年4期
雷騏瑋,張洪波
國防科技大學 空天科學學院,長沙 410073
1 引言
建設空間站是載人航天發展的高級階段,高精度的軌道預報是空間站在軌安全穩定運行和制定合理的軌道控制策略的前提條件。空間站一般運行在低地球軌道,且面質比較大,大氣阻力攝動是空間站軌道預報的主要誤差源[1]。
計算低軌航天器所受的大氣阻力時,誤差主要來源于大氣密度、阻力系數和迎風面積的計算誤差,阻力系數和迎風面積的誤差可以通過在線辨識的方法予以部分修正[2]。大氣密度主要通過大氣模型計算得到,但由于影響熱層大氣密度的因素較多且變化機理復雜,現有模型都不能準確描述大氣密度的實際變化情況,從而造成軌道預報誤差。
劉亞英等探索了大氣阻力攝動的精密計算方法,提高了低軌道衛星軌道預報精度[3]。Kong等利用三種大氣密度模型,對基于動力學模型的軌道預報方法進行了研究[4]。Chen等研究了僅使用兩行軌道根數提高低軌航天器軌道預報精度的方法,利用實測軌道數據對經驗模型進行校準[5]。李夢奇對低軌航天器的大氣參數修正方法進行了研究,降低了大氣阻力攝動誤差并提高了軌道預報精度[6]。Ray等利用傅立葉阻力系數模型對大氣阻力系數進行了精確建模,讓阻力系數成為與航天器軌道和姿態相關參量的函數[7]。劉舒蒔等基于線性回歸分析建立了大氣阻力系數補償算法,提高了近地航天器軌道預報精度[8]。
強化學習是一種機器學習方法,將學習看成一個試探-評價的過程[9]。在強化學習中,智能體從環境獲取信息,依據動作策略采取動作作用于環境;環境接受智能體的動作并發生變化,同時反饋給智能體獎勵或懲罰,即環境對智能體的動作進行評價;智能體根據環境反饋信號和當前觀測的環境狀態選擇下一時刻的動作,依據是能夠最大化智能體得到的獎勵或者累積獎勵[10]。
諸多學者對強化學習技術在航天動力學領域中的應用開展了研究。Hovell等提出了一種基于深度強化學習的航天器接近操作制導策略,設計了一個航天器姿態跟蹤和對接場景,并驗證了該策略的可行性[11]。吳其昌基于MADDPG強化學習算法,對航天器追逃博弈問題進行了研究,并能滿足航天器機動策略求解的實時性與快速性的要求[12]。王月嬌等將DQN強化學習算法用于衛星自主姿態控制,有效解決了傳統PD控制器依賴被控對象質量參數的問題[13]。Nicholas等采用強化學習算法來生成一種新型閉環控制器,該控制器能適用于復雜空間動態區域的星載低推力制導,并能夠在初始偏差較大的情況下直接引導航天器,提高了制導精度[14]。
綜上所述,對于航天器軌道動力學模型中大氣阻力攝動建模不準確的問題,當前的研究工作主要是通過解析的方法進行參數矯正,進而提高航天器軌道預報精度。強化學習算法可以通過智能體在線學習適應動力學環境的變化。本文提出了一種基于軌道動力學模型修正的軌道預報方案,該方案將PPO2強化學習算法與大氣參數可調的動力學模型相結合,在動力學積分預報軌道的過程中實時修正大氣阻力引起的建模誤差,從而提高軌道預報精度和預報效率。該方案對低軌航天器的軌道預報具有一定的參考價值。
2 動力學模型修正的軌道預報方案設計
空間站的軌道動力學方程可表示為
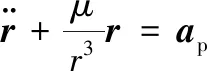
(1)
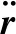
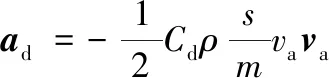
(2)
式中:Cd為阻力系數;ρ為大氣密度;s為迎風面積;m為空間站質量;va為空間站相對于大氣的速度。定義空間站的面質比與大氣阻力系數的乘積為彈道系數B,即
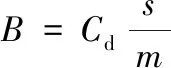
(3)
式中:阻力系數Cd和面質比s/m由地面實驗數據及工程經驗給定。假設大氣與地球一起旋轉,則由空間站在地心慣性坐標系中的位置r和速度v可得
va=v-?E×r
(4)
式中:?E為地球自轉角速度。
軌道預報時一般用經驗大氣模型計算大氣密度,常用的有US1976標準大氣、NRLMSISE-00模型等。US1976標準大氣模型表示了中等太陽活動期間,由地面到1000km的理性化、靜態的中緯度平均大氣結構,大氣密度的計算公式為
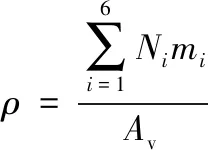
(5)
式中:Av為阿伏伽德羅常數;mi為N2,O,O2,Ar,He,H六種氣體的標稱分子量;Ni為氣體分子的數密度。Ni只與高度有關,可以通過對標準大氣氣體成分數密度隨高度變化表插值得到。因此基于US1976模型計算得到的大氣密度只和高度有關,故計算時效率較高。相比于US1976模型,NRLMSISE-00大氣模型計算精度較高,其詳細計算公式可參考文獻[15]。NRLMSISE-00大氣模型的大氣密度計算如下:
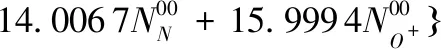
(6)
在計算大氣密度時,NRLMSISE-00大氣模型在US1976模型的基礎上添加了6種氣體分子數密度的修正項ΔNi,并引入了氮N和電離層正氧離子O+兩項。基于中國空間站的軌道根數,分別采用兩種大氣模型計算得到1天內空間站所在高度的大氣密度,結果如圖1所示。
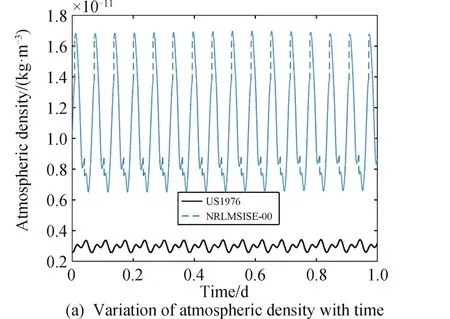
圖1 大氣密度與大氣密度之差隨時間變化
由圖1可知,US1976模型計算得到的大氣密度隨時間變化幅度較小,NRLMSISE-00模型計算得到的大氣密度隨時間呈周期性波動,波動周期大致和空間站軌道周期相同。
在實際工程應用中,根據星載軌道大氣環境探測器的探測結果發現,在太陽和地磁活動平靜期,NRLMSISE-00大氣模型計算得到的大氣密度日均誤差值也能達到10%,其變化規律難以用解析表達式描述。且由于空間站的真實軌道數據難以實時獲取,故考慮在各時刻基于經驗大氣模型計算得到的大氣密度的基礎上引入一個連續隨機噪聲,作為真實大氣密度值,然后進行軌道數值積分,將得到的數據作為真實軌道數據。為驗證強化學習方法的修正效果,本文工作中引入了一個隨機信號Δk(t)來模擬真實大氣密度,即
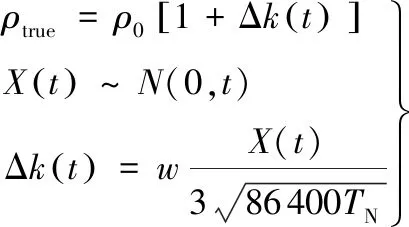
(7)
式中:ρ0為基于NRLMSISE-00大氣模型計算得到的大氣密度。|Δk(t)|<0.15。真實大氣密度具有時空連續性,故Δk(t)是一個隨時間連續變化的量,考慮采用隨時間呈正態分布的變量X(t)來描述Δk(t)的變化。X(t)經過標準化處理(仿真時段長度為TN,單位為天;規范化系數w=0.15),限制Δk(t)的取值范圍。
相比于NRLMSISE-00模型,US1976模型的計算量更小,因此考慮在軌道預報中,通過對US1976模型進行修正來計算大氣密度。根據式(7),定義
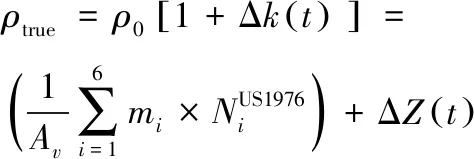
(8)
式中:ΔZ(t)表示US1976模型與真實大氣模型密度之差。若能通過強化學習得到ΔZ(t)隨時間的變化規律,并補償到預報模型中,則能有效提高軌道預報精度和效率。
基于上述分析,將空間站軌道預報的運動模型表示為
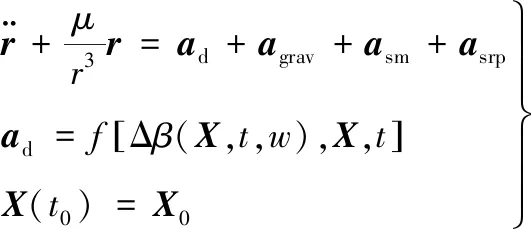
(9)
式中:ad,agrav,asm,asrp分別為大氣阻力攝動、地球非球形引力攝動、日月引力攝動、太陽光壓攝動產生的攝動加速度,
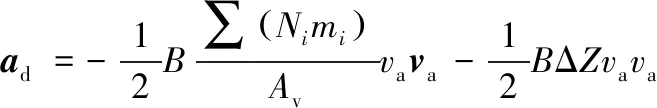
(10)
記Δβ=BΔZ。方程(9)即為大氣參數可調的動力學模型。Δβ綜合考慮了大氣模型計算不準確和軌道動力學模型建模時彈道系數B估計不準確的影響。由之前的分析可知ΔZ(t)隨時間呈周期性變化,實際工程應用中彈道系數B的估計誤差較小,故Δβ隨時間呈周期性變化。若能夠利用強化學習網絡學習得到大氣參數修正量Δβ隨時間的變化規律,則能夠利用強化學習網絡提高空間站軌道動力學模型建模精度,從而提高軌道預報精度。
由此,設計一種基于軌道動力學模型修正的軌道預報方案,其原理如圖2、圖3所示。其中箭頭表示利用獎勵函數Re(t)對強化學習網絡進行訓練,將大氣參數修正量Δβ加到大氣參數可調整的動力學模型上。
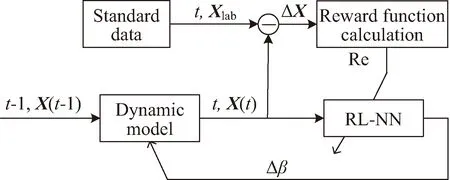
圖2 訓練段軌道動力學模型修正方案框架
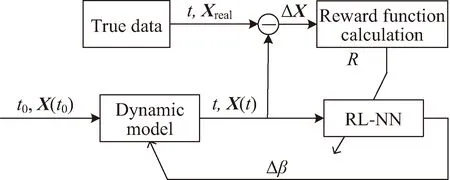
圖3 預報段軌道動力學模型修正方案框架
圖2表示的是強化學習網絡的訓練段。已知J2000.0慣性坐標系下t-1時刻空間站的狀態量X(t-1),根據式(9)得到下一時刻的狀態量X(t),并與已知的標準軌道數據Xlab(t)作差得到狀態偏差量ΔX(t),
ΔX(t)=X(t)-Xlab(t)
(11)
圖2中RL-NN為強化學習網絡,其輸入為狀態量X(t)和時間t,輸出為大氣模型參數調整量Δβ,其映射關系為
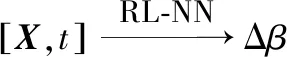
(12)
為補償大氣模型不準造成軌道預報偏差,應使狀態偏差量ΔX接近于0,因此將RL-NN的獎勵函數R定義為ΔX的函數:
R(t)=f(X(t),Xlab)
(13)
按照圖2完成網絡訓練后,利用強化學習網絡進行軌道預報,其原理如圖3所示。
3 強化學習算法設計與樣本生成
3.1 強化學習過程建模與訓練流程設計
強化學習過程可抽象為馬爾可夫決策過程。其中,狀態空間S中的狀態量為[X(t),t]T,動作空間A中動作量為[Δβ],狀態轉移函數P由大氣參數可調的動力學模型決定;獎勵函數Re為f(X(t),Xlab),表征t時刻軌道數值積分結果X(t)與標準狀態量Xlab的接近程度,獎勵函數值越大,表明兩者越接近,即當前智能體所采取的策略表現越好。圖3中RL-NN的輸出量Δβ為連續型變量,故考慮選擇適用于連續動作空間的高斯策略作為探索策略進行策略優化。
近端策略優化算法,簡稱PPO算法,該算法的特點是實現復雜度較低,超參數調試較為容易。在PPO算法中智能體每一步訓練時都會選擇新策略,通過自適應的方式選擇超參數,確保了智能體與環境交互過程中每一步獲得的獎勵值單調不減,從而持續獲得更優的策略。
PPO算法包含策略網絡與評價網絡,采用重要性采樣方法實現參數更新。策略網絡輸出一個均值μ和標準差σ,得到一個由該均值和方差確定的正態分布。智能體輸出的動作,即大氣模型參數調整量Δβ通過對該正態分布采樣得到,有
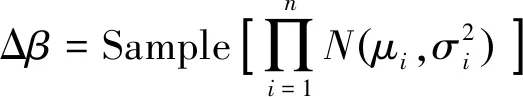
(14)
式中:n為動作矢量的維數;Sample函數為采樣函數。在PPO網絡權重參數更新過程中,引入了重要性采樣方法,采樣公式如下:
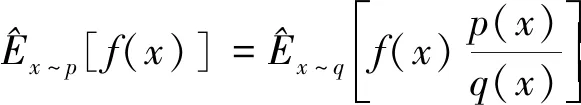
(15)
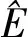

(16)
從而將f(x)對于策略分布函數p的期望值轉化為相對于策略分布函數q的期望值。PPO算法中的策略網絡可等價為策略分布函數,PPO算法中的策略網絡包含行為策略網絡和目標策略網絡兩部分,行為策略網絡輸出的數據用于更新目標策略網絡。
為定量評估PPO算法中策略網絡的性能表現,要定義目標函數。先定義優勢函數Aθ′(st,at),其大小與各時刻智能體從環境中獲得的獎勵值rt相關,反映了當前策略得到的大氣參數補償量Δβ對US1976模型的有效補償程度,即動力學模型軌道數值積分得到的狀態量與標準狀態量的偏差量越小,則補償效果越好,rt與Aθ′(st,at)的取值越大。PPO2算法是PPO算法的一種,運用了截斷函數來控制策略網絡參數的梯度更新,PPO2算法的截斷函數為
(17)
式中:clip函數為TensorFlow中numpy函數庫所包含的函數,用于限制ht(θ)的取值范圍,min為取最小值的函數,θ為策略網絡參數,式(17)中ht(θ)的定義如下:
(18)
式(17)引入了超參數ε對重要性采樣獲得的優勢函數進行截斷化處理,在策略網絡參數進行梯度更新時控制最大更新步長,防止參數更新速度過快導致訓練發散。PPO2算法進行策略網絡參數梯度更新的目標函數為
clip(ht(θ),1-ε,1+ε)Aθk(st,at)]
(19)
PPO2算法的網絡結構與訓練流程如圖4所示。PPO2算法仿真訓練流程的具體步驟可描述如下。
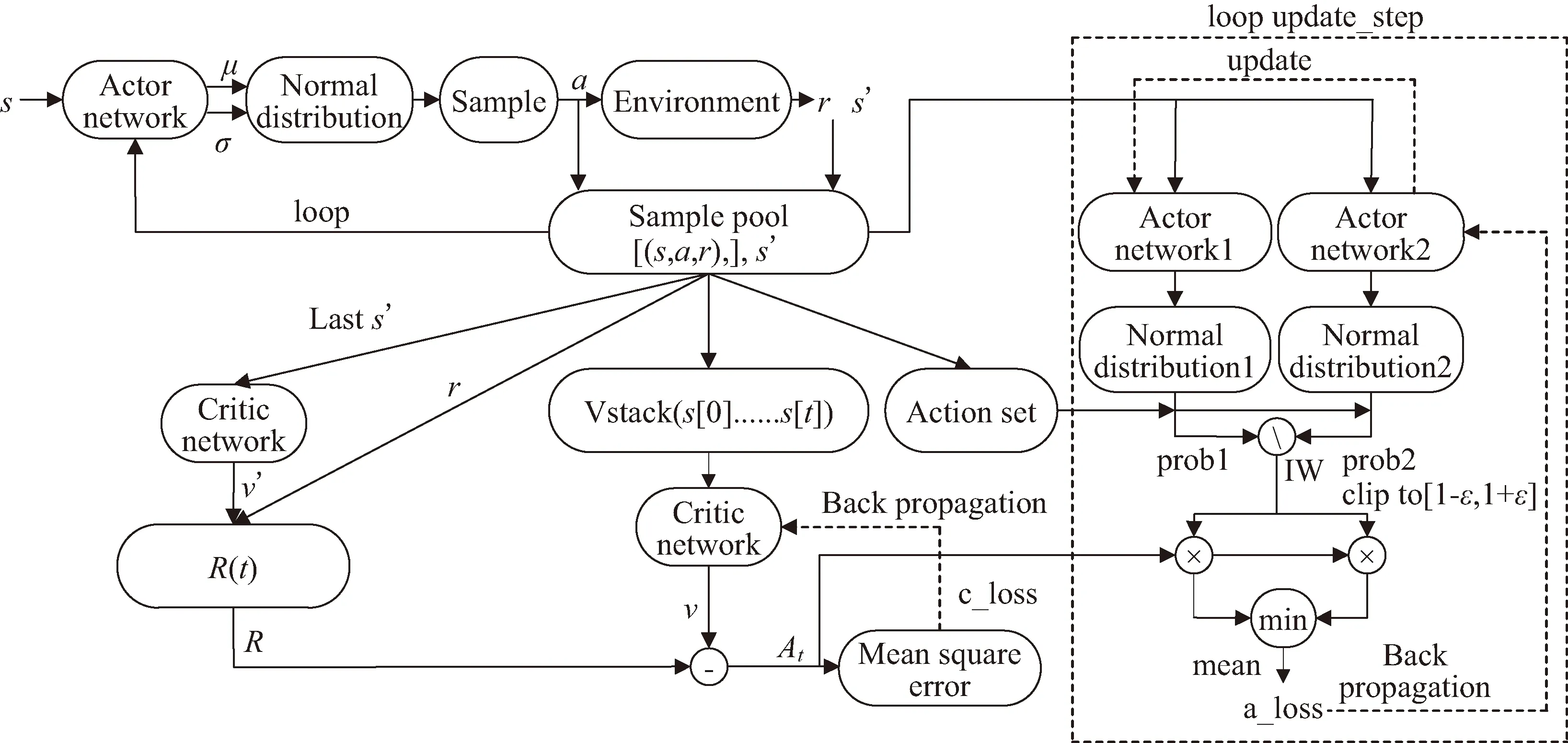
圖4 PPO2網絡結構與訓練流程
At=R-v
(21)
Step 1:將智能體狀態量s輸入到策略網絡,得到大氣參數修正量Δβ的均值μ和標準差σ,由該均值與標準差構建一個正態分布,采樣得到動作量Δβ,將其輸入到動力學環境中得到獎勵值rt和下一仿真時刻的狀態s′,然后存儲該時刻[(s,a,rt),…],將s′輸入到策略網絡,循環該過程,直到存儲了一定量的[(s,a,rt),…]。
Step 2:將Step1循環完最后一步得到的s′輸入到評價網絡中,得到狀態的v′值,計算折扣獎勵,即獎勵函數,有
R(t)=rt+γrt+1+…+γTE-t+1rT-1+γTE-tv′
(20)
式中:γ為折扣因子,表示智能體在學習過程中對未來潛在獎勵的關注程度。由此得到各時刻折扣獎勵列表R=[R[0],R[1],…,R[t],…,R[TE]],TE為一個訓練仿真回合的最后時刻。
Step 3:將存儲的所有狀態s組合輸入到評價網絡中,得到所有狀態下的v值,計算優勢函數,
Step 4:計算評價網絡優化的損失函數c_loss,取均方誤差,
c_loss=MSE(At)
(22)
將c_loss值反向傳播,用于更新評價網絡。
Step 5:將存儲的所有狀態s組合輸入策略網絡1和策略網絡2,輸出大氣參數修正量Δβ的均值和標準差,分別構造得到正態分布1和2。將樣本池中所有動作量Δβj組合為動作序列[Δβ1,Δβ2,…]傳入到正態分布1和2,得到相應狀態下每個Δβj對應的概率值prob1和prob2,用prob2除以prob1得到重要性權重IW。
Step 6:根據式(19)計算策略網絡的損失函數a_loss,如圖4所示,進行反向傳播,更新策略網絡2。
Step 7:循環Step 5~6,一定步數后循環結束,用策略網絡2權重更新策略網絡1。
Step 8:循環Step 1~7,直到滿足迭代結束條件,即達到訓練精度要求或最大訓練輪次,訓練結束。
3.2 強化學習訓練參量與網絡模型設計
在軌道預報場景中,強化學習智能體訓練時觀察到環境信息o為大氣參數可調的軌道動力學模型在數值積分后,得到的空間站各時刻運動狀態量S以及時刻量T,記為
o=[S,T]
(23)
智能體狀態量s通過軌道數值積分得到,即引入強化學習網絡的軌道動力學模型進行軌道積分得到空間站各時刻的運動狀態量S,記為
s=S
(24)
智能體的動作為PPO2算法中策略網絡的輸出,即各時刻大氣參數調整量Δβ采樣的正態分布的均值和標準差,
a=[μ,σ]Δβ
(25)
獎勵函數選擇為預期結果與實際預測結果的范數,用于表征兩者的偏離程度。經反復試驗后,在仿真中最終選擇了兩種獎勵函數:
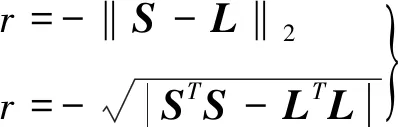
(26)
式中:L為已知的標準軌道數據在J2000.0系下各時刻的空間站運動狀態量。獎勵函數取負值的原因是PPO2算法的優化目標是最大化與累加獎勵相關的目標函數項。
PPO2網絡包含策略網絡和評價網絡。策略網絡包含目標網絡與行為網絡,且假定兩者具有完全相同的結構,包含7個輸入量,即各時刻空間站的運動狀態量及對應的時間,策略網絡包含2個輸出量,即各時刻大氣參數修正量Δβ正態分布采樣的均值和方差;評價網絡包含7個輸入量,與策略網絡的輸入一致,評價網絡包含1個輸出量,為當前的狀態值函數v。
按照從少到多的原則,經過反復試驗,最終選擇隱藏層數為3、神經元個數為200的策略網絡模型,以及隱藏層數為3、神經元個數為220的評價網絡模型。隱藏層激活函數選擇SELU函數,輸出層激活函數選擇tanh函數,其中SELU函數的公式如下:
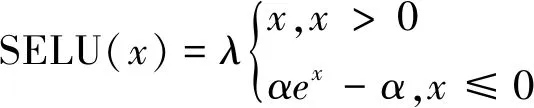
(27)
式中:α和λ是訓練前預設的。網絡訓練優化算法采用Adam算法,性能指標選擇為回合累加獎勵。回合累計獎勵rs為一個仿真回合中,各時刻環境反饋獎勵ri(i=0,1,2,…,TE)的累加,有
rs=r0+r1+r2+…+rTE
(28)
3.3 訓練與測試數據生成
軌道預報前需要用標準軌道數據對強化學習網絡進行訓練。選擇2022年4月25日某時中國空間站的軌道參數作為初始標準軌道參數,其半長軸為6765.12km,偏心率為0.0012238,軌道傾角為41.4694°,升交點赤經為182.3343°,緯度幅角為210.1109°,平近點角為130.8179°。
在NRLMSISE-00大氣模型上加入了一個時長13天的連續維納噪聲信號|Δk(t)|<0.15模擬真實大氣密度,然后通過軌道積分得到模擬的真實軌道數據。仿真時長設置為13天,引力場模型選擇EGM2008(72×72階),光壓模型選擇BERN模型,三體引力僅考慮日月引力,日月星歷選擇DE405,數值積分方法選擇RKF7(8),最大積分步長設置為10s,地磁指數為3,日均F10.7為270,面質比選擇為0.02m2/kg,大氣阻力系數為2.2。以前10天的數據作為訓練數據樣本,后3天的數據作為測試數據樣本。
由于原始數據的量級差別較大,需要在訓練前進行歸一化處理。假設某時刻空間站的運動狀態量為[rx,ry,rz,vx,vy,vz],以仿真時段內各方向上位置、速度量模的最大值為標準,對策略網絡與評價網絡的輸入量進行歸一化處理。
4 數值仿真分析
PPO2算法中對策略網絡和評價網絡的權重參數按照標準正態分布進行初始化后,還需要對PPO2網絡訓練初始化條件進行設置,各項初始化條件設置如表1所示。
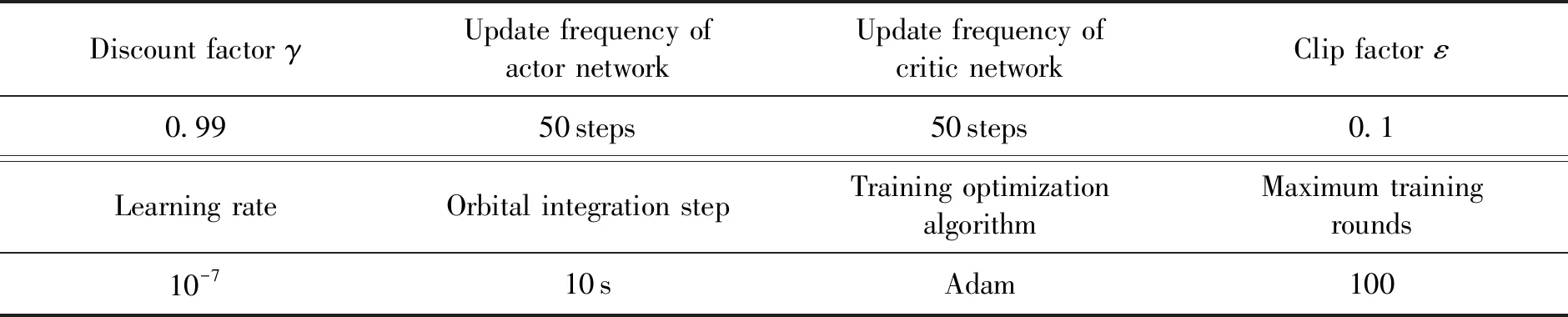
表1 仿真訓練參數設置
為保證策略網絡表現性能的單調提升,記錄每經過一個回合(即對應10天訓練樣本)訓練后訓練樣本的累計獎勵(性能指標,見式(28))。若性能指標相比上一輪提升超過1%,則保存此時的神經網絡模型參數;若新一輪訓練后性能指標變差,則載入當前已獲得的最優網絡模型參數進行訓練,直到最終模型性能表現不再有明顯提升。當完成一個回合訓練后,清零累積獎勵,重置動力學環境參數,開始下一回合的訓練。
經過100回合訓練后,訓練樣本對應累積獎勵的變化情況如圖5所示。采用兩種獎勵函數時,性能指標分別提升92.97%、92.84%,累積獎勵分別從-0.20285提升到-0.01427,從-0.213741提升到-0.015303。

圖5 累積獎勵隨訓練回合變化(訓練段)
利用測試樣本測試強化學習網絡表現時,強化學習網絡不再更新,直接用于軌道預報,軌道預報結果與標準軌道數據之間存在的偏差即強化學習方法的軌道預報精度,由此驗證強化學習方法的泛化能力。
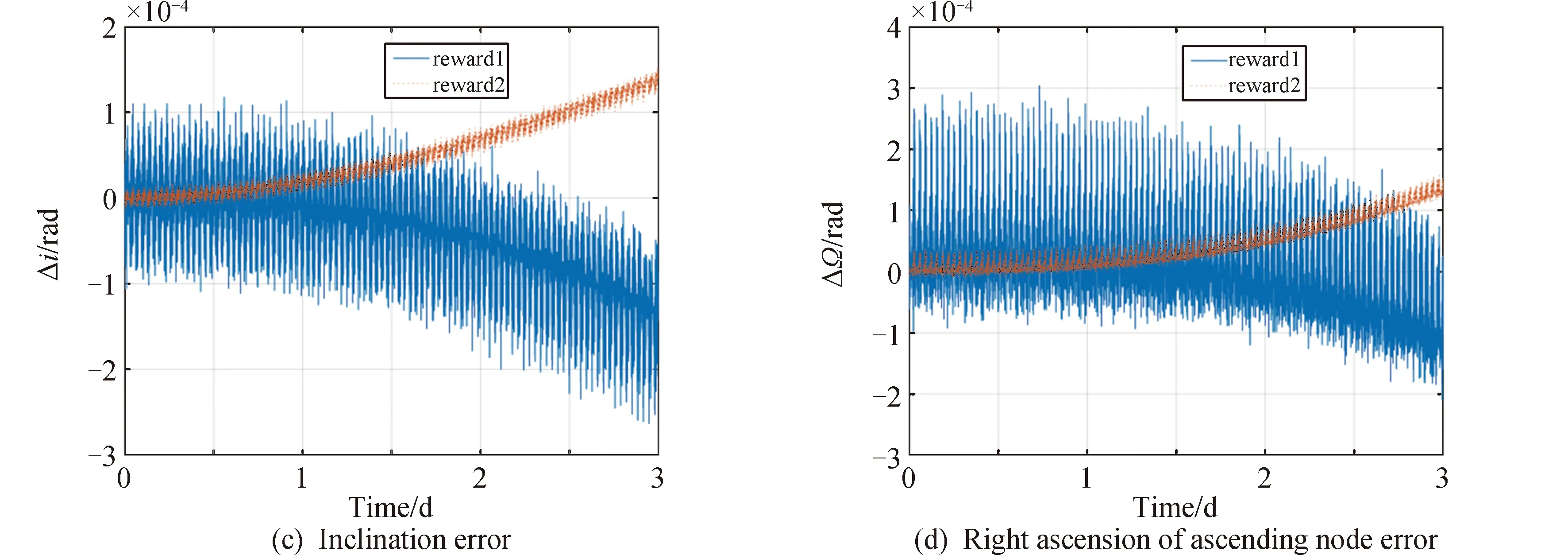
基于測試樣本,分別采用兩種獎勵函數進行軌道預報時的軌道根數誤差變化如圖6所示,進行軌道預報的位置誤差(J2000.0系下)與僅考慮NRLMSISE-00大氣模型進行軌道預報時的位置誤差以及程序運行時間的對比情況如圖7、圖8、表2所示。
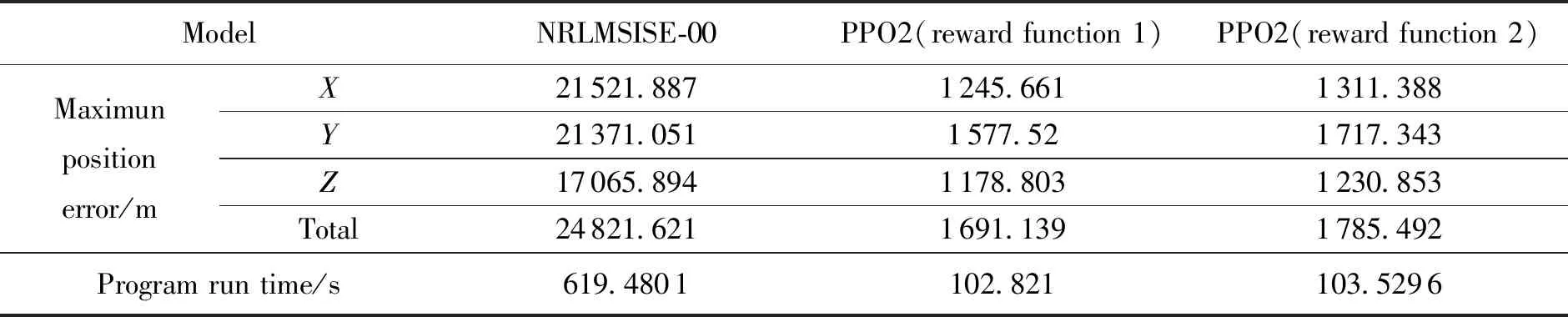
表2 基于經驗大氣模型與混合動力學模型的最大預報位置誤差與預報時間
續圖6

圖7 基于經驗大氣模型與混合動力學模型所得位置誤差(獎勵函數一)
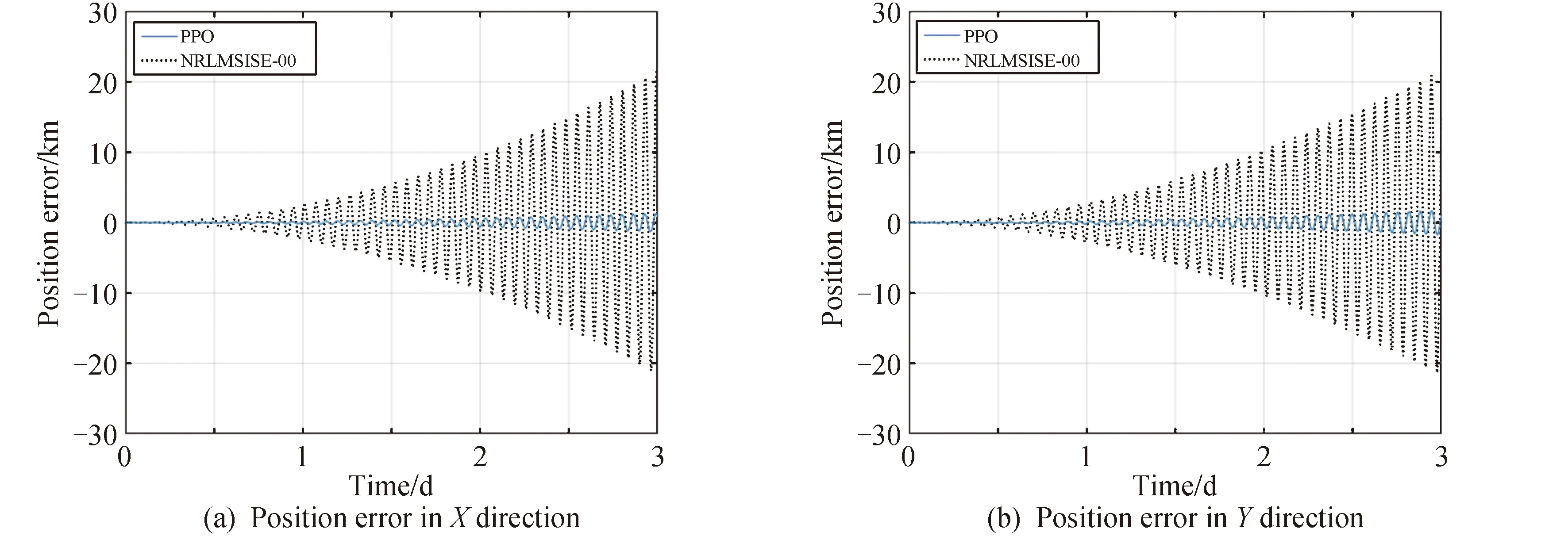
圖8 基于經驗大氣模型與混合動力學模型所得位置誤差(獎勵函數二)
由圖6、圖7、圖8和表2可知,在測試樣本中,相比于僅考慮NRLMSISE-00模型,包含強化學習網絡的混合動力學模型用于軌道預報的誤差更小。采用獎勵函數一時X、Y、Z方向上的最大位置誤差與最大總位置誤差分別減少了94.21%、92.62%、93.09%、93.19%;在采用獎勵函數二時X、Y、Z方向上的最大位置誤差與最大總位置誤差分別減少了93.91%、91.96%、92.79%、92.81%,且軌道根數誤差變化更為平緩,波動幅度較小。將訓練后得到的強化學習網絡用于預報,程序運行時間分別減小了83.40%,83.29%,由此驗證了強化學習方法的有效性。
另構造與PPO2網絡中策略網絡隱藏層層數與神經元個數相同的深度神經網絡模型,令其輸入量為僅考慮NRLMSISE-00模型進行軌道數值積分得到的空間站J2000.0系下各時刻的狀態量,令其輸出量為輸入狀態量相比于標準狀態量的偏差量,采用10天的標準軌道數據對神經網絡模型進行訓練,隨后進行3天的軌道預報,預報狀態量為神經網絡輸出狀態偏差量與神經網絡輸入狀態量的和,此時軌道預報的最大位置誤差與程序運行時間如表3所示。
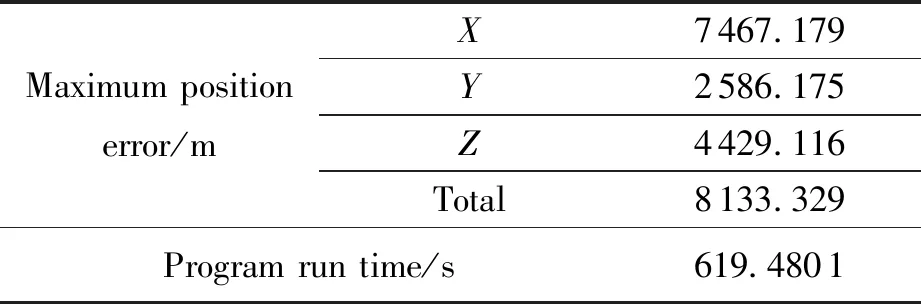
表3 基于強化學習網絡模型的最大預報位置誤差與預報時間
由表3可知,在進行軌道預報時,相比于強化學習方法,直接利用深度神經網絡對原動力學模型的軌道數值積分結果偏差進行補償,其預報的程序運行時間更長,預報精度更低,由此驗證了本文研究的強化學習方法的優越性。
5 結論
本文針對大氣阻力攝動難以準確建模的問題,提出了一種融合PPO2強化學習網絡和軌道動力學模型修正的軌道預報方案,隨后完成了網絡模型構建,訓練和測試。結合最終仿真測試結果進行如下總結:
1)該方案具有較高的預報精度和預報效率,相比于經驗大氣模型,采用兩種獎勵函數時,三方向上最大位置誤差與最大總位置誤差分別減少了94.21%、92.62%、93.09%、93.19%及93.91%、91.96%、92.79%、92.81%;進行軌道預報時,程序運行時間分別減小了83.40%、83.29%。
2)利用PPO2算法和強化學習網絡可有效修正經驗大氣模型得到的大氣模型參數存在的誤差,與深度學習方法不同,強化學習方法引入了獎勵函數,在與動力學環境互動過程中為強化學習網絡的訓練優化提供了一個學習目標。
3)與空間站軌道預報類似,該方案對其他低軌航天器的軌道預報同樣具有一定參考價值。
未來的研究工作中,可以考慮在本文研究工作的基礎上,利用高精度定軌得到的軌道數據用于大氣模型參數的實時修正。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
軍事文摘(2023年10期)2023-06-09 09:15:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
光學精密工程(2016年6期)2016-11-07 09:07:19
河北書畫研究(2016年2期)2016-08-24 02:14:50
新農業(2016年18期)2016-08-16 03:28:27
