基于圖像識別與動力學融合的路面附著系數估計方法
2023-07-31 04:23:56關可人丁曉林郭鵬宇王震坡孫逢春
汽車工程 2023年7期
張 雷,關可人,丁曉林,郭鵬宇,王震坡,孫逢春
(1.北京理工大學,北京電動車輛協同創新中心,北京 100081;2.北京理工大學,電動車輛國家工程研究中心,北京 100081)
前言
隨著汽車電子技術的快速發展,車輛主動安全控制系統逐漸在量產車型上普及應用,有效提高了車輛安全性。路面附著系數是車輛主動安全控制系統的關鍵參數,其準確、快速估計可有效提升車輛安全性。
圍繞路面附著系數估計,現有研究主要分為實驗法、模型法與融合法3 類[1-2]。實驗法利用聲波[3]、紅外[4]、攝像頭[5-9]、雷達[10-11]等傳感器辨識路面狀態,在此基礎上進一步估計路面附著系數。隨著計算機視覺技術的迅速發展,有學者將圖像識別與分割技術應用于路面狀態識別。圖像識別法通常是從車載攝像頭或路端監控攝像頭獲取道路圖像,通過預訓練的分類器識別路面類型,再通過查表等方法將路面類型對應的路面附著系數經驗值作為估計結果。圖像識別法主要包括機器學習法和深度學習法。機器學習法通過人工提取RGB 值、紋理、灰度等圖片特征,使用支持向量機、K 最鄰近、貝葉斯分類器等識別路面類型[5-6],但該方法存在人為設計特征復雜、泛化能力差等缺點。為克服上述弊端,深度學習方法利用卷積神經網絡實現樣本特征自動提取與自適應學習,已廣泛應用于路面類型識別。例如,王海等[7]利用語義分割網絡Res-UNet++分割出路面的積水和濕滑區域,取得了平均交并比為90.07%的分割精度。等[8]設計了一種深度卷積神經網絡,對干濕瀝青、干濕鵝卵石、干濕碎石等6 種路面類型的辨識準確率達88.8%。Nolte等[9]對比了ResNet50 和InceptionNetV3 兩種深度卷積神經網絡在6 種典型路面多數據集上的識別效果,結果表明,Resnet50 相對于InceptionNetV3 具備更強的分類能力。還有學者通過分析輪胎噪聲[12]、胎面形變[13]、車輪振動[14]等參數估計路面附著系數,但這類方法對傳感器要求高,且受周圍環境影響大。
模型法通過建立與路面附著系數相關的車輛動力學模型,并結合狀態觀測器設計實現路面附著系數估計。現有研究主要聚焦于通過輪胎或車輛動力學響應特性實現路面附著系數估計。在輪胎動力學方面,有學者提出利用縱向輪胎模型激勵特征,如μ-s曲線小滑移率區間斜率[15]、變化率[16]或Burckhardt模型參數[17]等進行路面附著系數估計。但受限于輪胎滑動率噪聲、環境干擾等影響,該類方法在估計精度、可靠性等方面仍有待提升。在整車動力學方面,主要利用車輛動力學響應特性與路面附著系數的關聯關系構建狀態觀測器,實現路面附著系數估計[18-21]。常見的狀態觀測器包括卡爾曼濾波[18]、無跡卡爾曼濾波[19]、容積卡爾曼濾波[20]、模糊自適應融合估計器[21]等。
實驗法僅能確定路面類型而無法準確獲得路面附著系數值,估計效果易受環境影響;模型法存在時間滯后問題,且僅在輪胎處于大滑動區間時才具有較高估計精度。為進一步提升附著系數估計效果,有學者提出了基于多方法融合的路面附著系數估計方法。例如,王世峰等[22]綜合不同路面的加速度信號特征與路面圖像紋理特征,通過神經網絡實現了不同路面類型識別,但該方法未發揮利用圖像識別實現路面附著系數預測的優勢。Leng 等[23]和熊璐等[24]考慮路面類型映射經驗值與真實值間的差異,構造了基于擾動觀測的路面附著系數估計器。庹文坤[25]利用圖像識別結果修正基于動力學方法的路面附著系數估計結果。但上述兩種估計方法高度依賴于估計器增益設計,且未考慮圖像識別錯誤等異常情況的影響。Leng 等[26]提出了一種綜合數據級、模型級和決策級的融合規則,考慮到輪胎小滑移率和小側偏時動力學估計結果不可靠,提出了基于圖像識別的動力學估計器啟停機制,根據圖像識別結果自校正動力學估計器參數,但該方法同樣未考慮圖像識別結果不準確的情況。脫王捷[27]分別建立了基于圖像識別和基于動力學的路面附著系數估計器,提出了基于前方路面變化的融合機制。劉惠[28]提出了視覺與動力學信息時空同步機制,基于不同路面類型對應的附著系數范圍,采用概率密度函數截斷法約束了基于動力學路面附著系數估計方法的估計值范圍。何中正[29]綜合利用路端三維相機、車載攝像頭以及車輛動力學狀態等多源信息,提出了“三選一”的路面附著系數融合估計機制,實現車輛小激勵工況下的附著系數估計。
綜上所述,現有的路面附著系數估計方法尚未充分發揮圖像識別和動力學估計方法的性能優勢,存在融合邏輯簡單、適用工況有限等問題。由于四輪輪轂電機驅動電動汽車的車輪轉矩、轉速等信息可實時獲取,本文中提出了一種圖像識別與動力學融合的路面附著系數估計方法(圖1)。首先,基于單輪動力學模型估計輪胎縱向力,結合魔術輪胎模型,構建了基于粒子濾波的路面附著系數估計器;其次,建立基于圖像識別的路面附著系數預測方法;針對結構化道路干燥、潮濕、冰雪3 種狀態,通過DeeplabV3+語義分割網絡分割道路,再利用MobileNetV2 輕量化卷積神經網絡實現路面類型辨識,并通過查表獲取前向路面附著系數;最后,建立圖像識別與動力學估計時空同步方法與融合策略,實現了兩種估計器的有效關聯和可靠融合。

圖1 圖像識別與動力學融合的路面附著系數估計方法
1 基于車輛動力學的路面附著系數估計
基于車輛動力學的路面附著系數估計方法,其主要思路是根據輪胎力學響應特性設計路面附著系數觀測器。因此,首先需要實時準確估計輪胎力。
1.1 輪胎模型
為精準表征輪胎力學特性,采用摩擦相似原理修正魔術輪胎公式[30],表示為
式中:Fx(x)為輪胎縱向力;μ為實際路面附著系數;s為輪胎滑移率;B、C、D和E分別表示輪胎力學特性曲線的剛度因子、形狀因子、峰值因子和曲率因子;Sh和Sv分別為輪胎力曲線相對于原點的水平偏移和縱向偏移,本文取0。
1.2 輪胎縱向力估計
由于可實時精確獲取4 個車輪的轉速和轉矩,因此,通過建立單輪動力學模型并利用卡爾曼濾波算法可實現對車輪縱向力的準確估計。
如圖2所示,單輪動力學模型可表示為
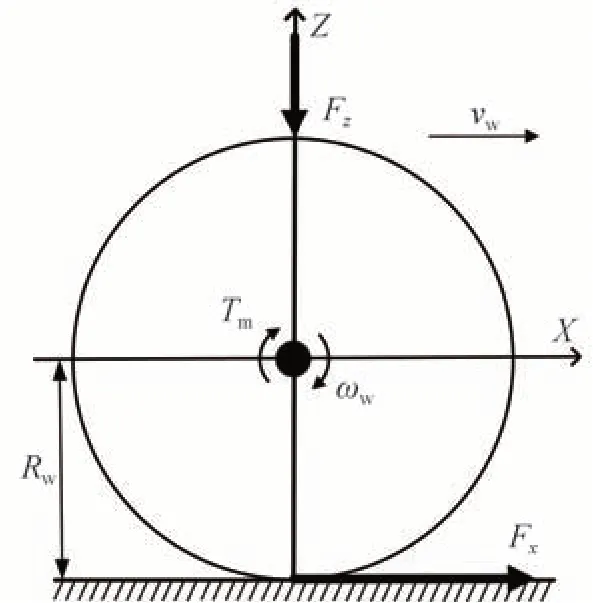
圖2 單輪動力學模型
式中:Jw為車輪轉動慣量;ωw為車輪旋轉角速度;Tm為作用于車輪的驅動或制動力矩;Rw為車輪滾動半徑;Fx為輪胎縱向力。
式(2)的離散狀態空間方程為
式中:k表示離散時刻;x=[ωw,Fx]T為狀態變量;z=ωw為觀測變量;u=Tm為控制量;w與v分別表示服從正態分布N(0,Q)的過程噪聲和服從正態分布N(0,R)的觀測噪聲。狀態矩陣A、控制矩陣B與觀測矩陣H分別為
式中ts為離散采樣時間。
卡爾曼濾波的基本流程如下。
步驟 1:根據上一時刻狀態量及過程噪聲計算先驗估計值,可表示為
步驟 2:計算卡爾曼增益,可表示為
步驟 3:對先驗估計進行校正,可表示為
步驟 4:獲得由k-1 時刻到k時刻狀態量的最優估計值重復步驟 1-步驟 4。
1.3 粒子濾波算法原理
粒子濾波算法采用蒙特卡洛模擬實現貝葉斯濾波,其基本原理為:隨機抽樣生成一組粒子集合,一個粒子代表一個樣本;計算觀測值與測量值之差,通過不斷更新粒子權重使粒子分布逐漸貼近后驗概率分布;計算樣本均值近似為積分計算以減小運算量。由于路面附著系數與輪胎力之間呈非線性關系,因此,粒子濾波算法適用于路面附著系數估計。
非線性系統的后驗分布概率密度函數復雜,難以對其采樣。因此,間接對一個已知且易采樣的重要性函數進行采樣,通過計算后驗分布概率密度函數與重要性函數的比值獲得重要性函數與后驗分布概率密度函數的接近程度,將該值作為粒子權重使符合重要性函數分布的粒子集接近后驗分布。
經過多次迭代后,估計器的少數粒子權重增大,多數粒子權重減小,權重方差增大,粒子多樣性減弱,導致粒子濾波結果出現偏差,形成粒子退化現象。為解決粒子退化問題,采用系統重采樣方法(system resampling,SR)[31],首先由均勻分布U(0,1]生成隨機數在此基礎上生成隨機數組:
重新平均分配新粒子權重得到新的粒子集合為
1.4 路面附著系數估計器
假設路面附著系數短時間內不發生劇烈變化,則狀態空間方程可表示為
式中:x=[μfl,μfr,μrl,μrr]T為狀態矢量,其中,fl、fr、rl、rr分別表示左前輪、右前輪、左后輪、右后輪;z=[Fxfl,Fxfr,Fxrl,Fxrr,ax]T為觀測矢量。
狀態轉移方程表示為
觀測方程為車輛縱向運動方程和縱向工況魔術輪胎模型,表示為
式中:m為整車質量;ax為由慣性元件測得的車輛縱向加速度;δf為前輪轉角。
(3)圖像數據在服務器上的上傳和下載過程都在服務器端完成,這種設計增加了服務器端的負擔,影響了針對數據倉庫的上傳、檢索和下載速度。
以單個車輪為例,粒子濾波算法流程如下。
步驟 1:初始化粒子數N、過程噪聲w、觀測噪聲v,基于圖像識別法預測的路面附著系數值確定初始粒子集合X(0);
步驟 2:根據k-1 時刻的粒子集合X(k-1)中的每個粒子,由狀態轉移方程計算得到k時刻路面附著系數的先驗估計值:
式中下標j=1,2,3,…,N表示第j個粒子。
以后驗分布概率密度函數p(·)與重要性函數π(·)的比值作為粒子權重,即
粒子權重歸一化后的粒子權重可表示為
k時刻路面附著系數的后驗估計為
步驟4:代入式(8)-式(10)進行重采樣,得到新的粒子集合及其權重,代入下一次循環,重復步驟 2-步驟 4。
2 基于圖像識別的路面附著系數預測
基于圖像識別的路面附著系數預測包括離線訓練和在線辨識兩部分。對于離線訓練,首先訓練語義分割網絡,利用訓練后獲得的語義分割模型將原始數據集轉化為僅保留路面區域的新數據集,再基于新數據集訓練分類神經網絡。對于在線辨識,先后利用訓練好的DeeplabV3+網絡和MobileNetV2 網絡對采集圖像進行路面區域分割和分類。
2.1 路面區域語義分割
語義分割可通過像素分類提取圖像重要信息,目前已廣泛應用于醫療診斷、自動駕駛等領域。為減小背景因素對分類的影響,首先通過語義分割劃分路面區域。谷歌提出了Deeplab 系列語義分割網絡,其中DeeplabV3+[32]在分割精度等方面具有較好性能。本文采用DeeplabV3+實現路面語義分割,同時考慮模型計算速度和分割性能,將骨干網絡Xception 替換為MobileNetV2[33]輕量化卷積神經網絡,DeeplabV3+采用編碼-解碼結構,具體網絡結構如圖3 所示。編碼器首先經過骨干網絡提取低維特征圖,然后由空洞空間金字塔池化(atrous spatial pyramid pooling,ASPP)提取多尺度特征信息。1×1卷積提取細致的特征信息,不同空洞率的3×3 空洞卷積提取不同大小感受野的信息,全局平均池化提取全局信息。解碼器部分由低維特征圖與4 倍上采樣的高維特征圖級聯,融合空間信息與通道信息以提高語義分割性能。最后,通過3×3卷積和4倍上采樣得到最終預測結果。
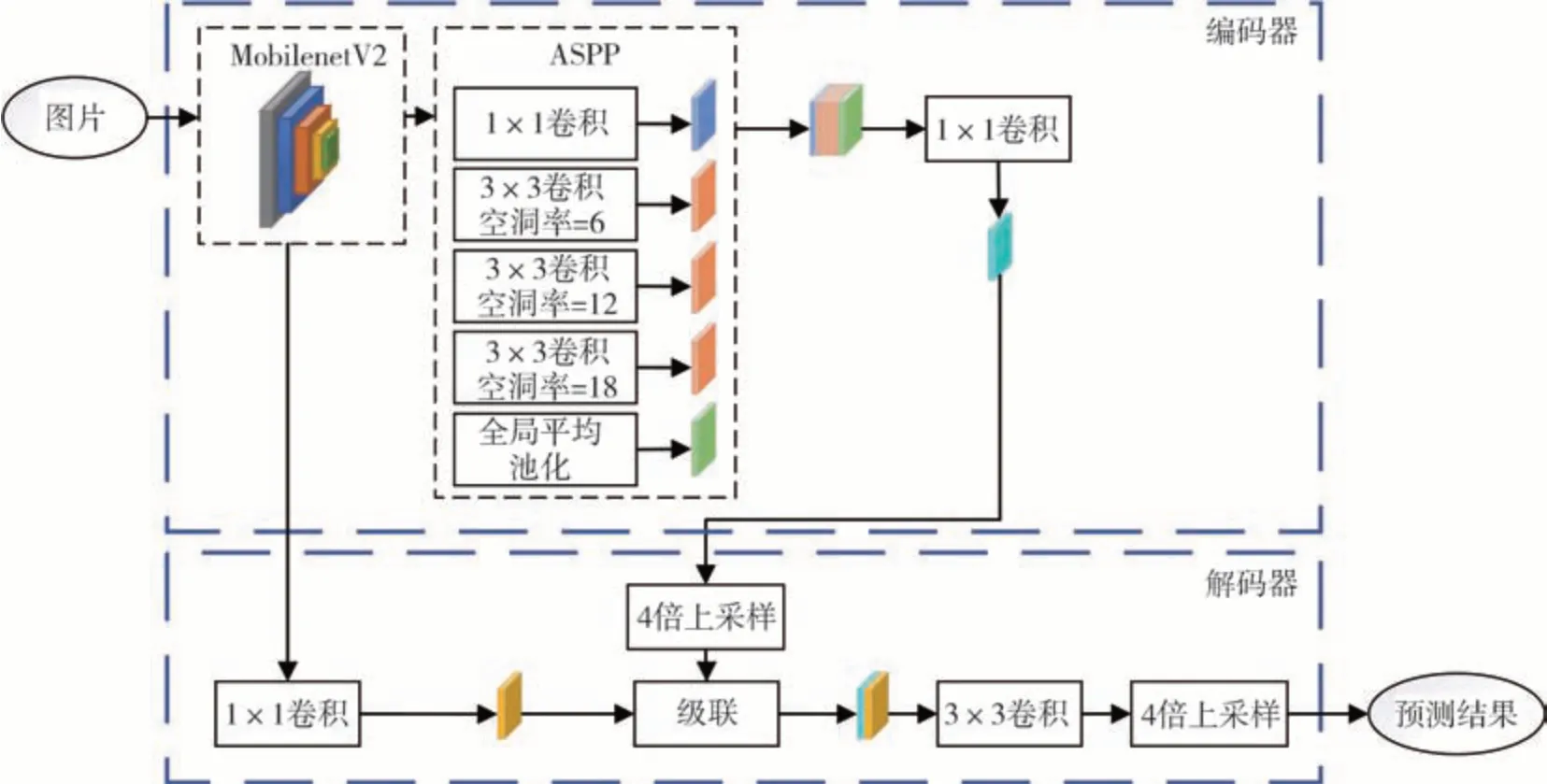
圖3 DeeplabV3+網絡結構
2.2 路面類型識別
作為深度學習的重要分支,卷積神經網絡已先后發展出LeNet[34]、AlexNet[35]、VGGNet[36]、ResNet[37]、MobileNet[33,38-39]、ShuffleNet[40-41]等網絡。相比于傳統卷積神經網絡,MobileNet 和ShuffleNet 等輕量化神經網絡具備較小的模型參數計算量,適用于移動端部署。車輛高速行駛工況對模型計算效率要求高,且車載控制系統算力有限,綜合考慮分類準確性、模型大小、計算效率等因素,選用MobileNetV2 輕量化神經網絡作為分類網絡。
MobileNetV2 采用深度可分離卷積[35]。首先,特征圖的每個通道僅與一個卷積核進行卷積運算,得到的特征圖個數與通道數C一致;然后對新特征圖采用N個1×1×C大小的卷積核進行卷積運算;最后得到與卷積核個數一致的N個特征圖。深度可分離卷積操作可有效減少參數計算量。MobileNetv2 在此基礎上加入倒殘差結構和線性瓶頸模塊。倒殘差結構將先降維再升維的殘差結構[37]調整為先升維再降維,先升維可豐富特征數量以提高模型精度。由于ReLU 激活函數將非正的輸入特征置0 而導致大量信息丟失,因此,瓶頸模塊采用線性激活函數可有效減少信息丟失。MobileNetV2 網絡結構見表1,表中:Bottleneck 代表倒殘差的線性瓶頸模塊;Conv2d代表二維卷積,未特殊標注的卷積均為3×3 卷積;Avgpool代表平均池化;k代表類別數。
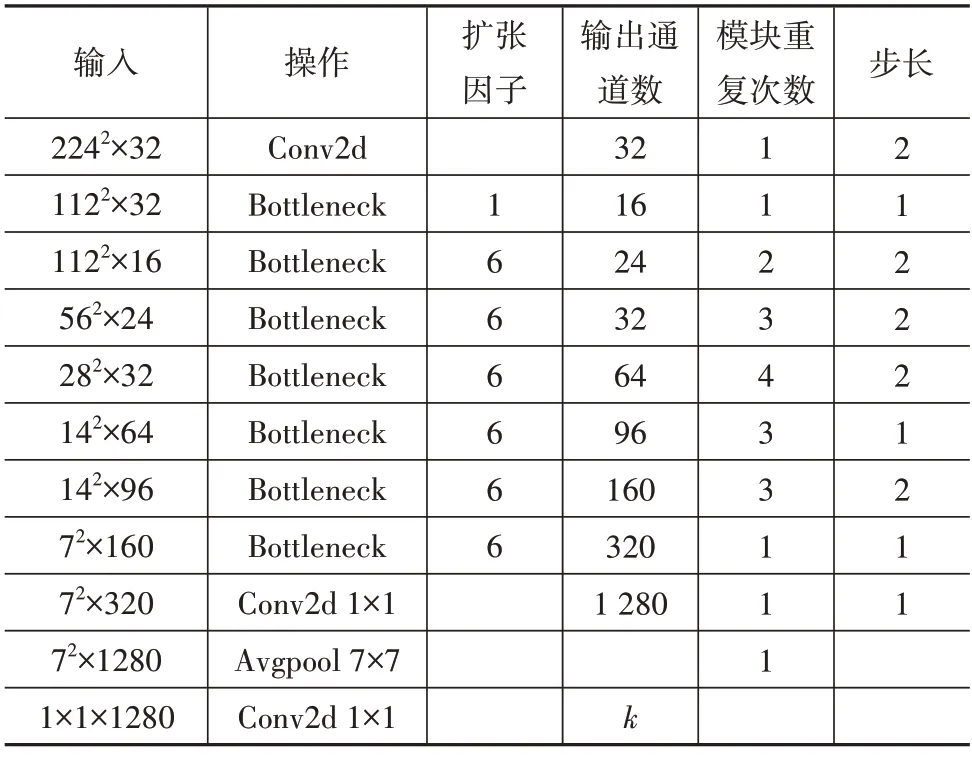
表1 MobileNetV2網絡結構
2.3 路面類型與路面附著系數對照表
由GA/T 643—2006[42]和《汽車理論》[43]獲得路面類型-路面附著系數對應關系,詳見表2。

表2 路面類型-路面附著系數對照表
2.4 訓練與驗證
本文采用多個公開數據集[44-46]、網絡圖片和人工拍攝照片作為數據集,圖片來源均為車輛前置攝像頭,共計4 254 張。其中,訓練集與驗證集的比例為9∶1。
受限于計算資源,單次可訓練的圖片數量較少,從0 開始訓練得到的模型精確度較低。因此,本文采用遷移學習方法,在已訓練模型基礎上針對分類任務重新訓練模型,可以提高模型精度、縮短訓練時長。本文使用的具體軟件及硬件配置見表3。
表3 軟硬件配置
2.4.1 語義分割網絡訓練
首先凍結骨干網絡,僅訓練骨干網絡以外的參數,骨干網絡部分采用已經訓練好的模型參數。經過多次凍結訓練,再對骨干網絡解凍,訓練整個網絡。該訓練方法可在獲得較好模型訓練效果的同時減小內存占用。凍結訓練次數設置為epoch_freeze=50,解凍訓練次數設置為epoch_unfreeze=50,采用SGD 優化器,設置余弦退火學習率,初始學習率lr=0.007,下采樣倍率=16,batch_size=16。
RGB是一種顏色標準,在語義分割中,不同類別區域被賦予不同RGB 值。首先,根據目標提取區域RGB值查找語義分割結果圖的3個通道R、G、B中相同的值,值相同的像素點賦為1,其它像素點賦0;然后,將得到3 個掩膜拼接,保留3 個掩膜值都為1 的像素點,其余像素點賦值0;最后,通過掩膜與原圖矩陣運算即可提取原圖中的目標區域。本文僅包括背景和路面兩類語義分割對象,將生成掩膜過程簡化為對語義分割結果圖的灰度化處理,得到的灰度圖僅有兩個值:背景區域灰度值為0,路面區域灰度值為90。值為90 的像素點賦1,得到背景為0、路面為1 的掩膜,再通過掩膜與原圖矩陣運算提取路面區域。
分割和提取結果見圖4。語義分割通常采用平均交并比作為評價指標,此訓練模型在驗證集上的平均交并比miou=87.41%,表明模型精度較高。

圖4 路面區域語義分割結果
2.4.2 分類網絡訓練
MobileNetV2遷移學習流程見圖5。為保證各類別樣本均衡,從語義分割提取路面結果中選取瀝青路面的干燥、潮濕、冰雪3 種狀態圖片各1 100 張,共計3 300張。導入MobileNetV2網絡在ImageNet數據集上訓練的參數,在此基礎上僅對網絡微調訓練。將圖片壓縮至像素為224×224,batch size=32,訓練次數設置為epoch=100,采用Adam優化器,學習率lr=0.0001。此模型在驗證集上的分類準確率為92.90%。
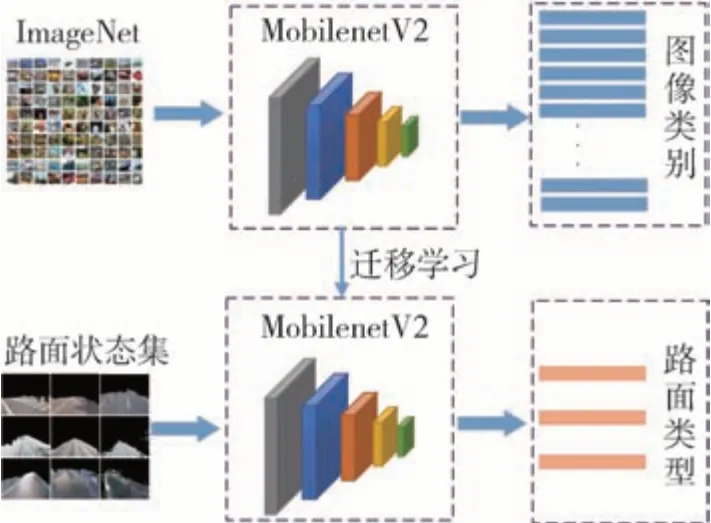
圖5 MobileNetV2遷移訓練流程圖
3 融合估計策略
3.1 時空同步
車載前置攝像頭可通過拍攝車輛前向道路實現路面附著預測,而車輛動力學估計方法僅能估計車輛當下路面附著系數,首先須將兩種方法估計結果進行時間和空間匹配。攝像頭采樣頻率為30 Hz,GPS 采樣頻率為20 Hz,慣導采樣頻率為100 Hz,以20 Hz頻率進行采樣。
由于基于圖像識別的路面附著系數預測是對整車未來行駛區域的路面條件的辨識,不針對單個車輪,在時空同步中可將車輛近似為質點進行分析。如圖6所示,lr為攝像頭拍攝范圍,ln為車輛質心到拍攝范圍最小距離。在xik(k=1,2,…,N)點攝像頭獲取前方路面信息;在xd點獲取車輛動力學響應信息。xi1-xiN區間內攝像頭獲取的路面信息均包含xd點。攝像頭采集圖像須經過語義分割和卷積神經網絡處理,設運算時間為timage,則經過timage后車輛由xik移動到,須保證不超過xd。因此,能夠與xd處車輛動力學算法融合的攝像頭拍攝點應滿足:

圖6 時空同步示意圖
選取xi1-xiN區間所有圖像識結果中出現頻率最高的路面類型作為最終圖像識別結果,輸入動力學響應處xd,記該類型出現次數為NMAX,則分類概率為P=NMAX/N。設置圖像識別法置信度Pc,當某類型路面出現頻率高于Pc時才將該路面類型作為圖像識別的最終結果,本文圖像識別法置信度取值為80%。
3.2 融合機制
圖像識別法雖可預測路面附著系數,但受外界光照、天氣等影響,且只能根據識別類型獲得路面附著系數經驗范圍。車輛動力學法具有較高估計精度,但時效性較弱,且在車輛小滑移等工況下難以實現路面附著系數準確估計。因此,本文結合兩種算法的優勢,提出基于圖像識別與基于動力學的路面附著系數估計方法融合機制,具體流程如圖7所示。
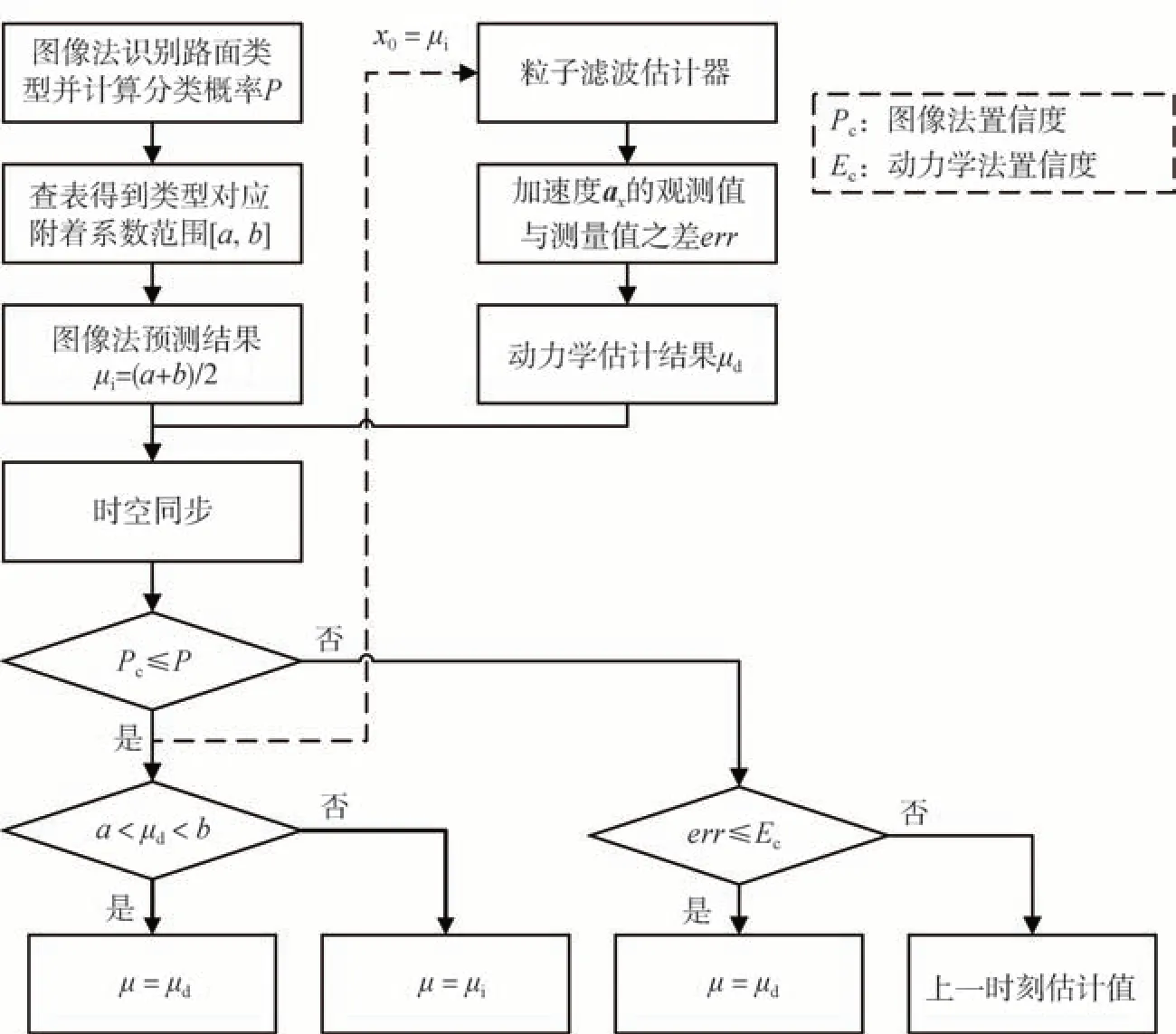
圖7 基于圖像識別和基于動力學的路面附著系數估計融合機制流程圖
(1)當P≥Pc時,圖像識別結果可信,查表得到路面類型對應的路面附著系數范圍[a,b],預測值為μi=(a+b)/2,作為基于動力學的粒子濾波估計器初始值。判斷μd是否在區間[a,b]之間;若μd位于區間[a,b],則動力學估計準確,以動力學估計值μd作為最終μ估計值;相反,以圖像法預測結果μi作為最終μ估計值。
(2)當P<Pc時,此時圖像預測結果不可信,則須判斷基于動力學的估計結果是否可信。以縱向加速度的觀測值與傳感器測量值之差err作為判斷依據,若err≤Ec則基于動力學的估計準確,以動力學估計值μd作為最終μ估計值;否則保持上一時刻估計值不變。
4 仿真
通過CarSim-Simulink 聯合仿真驗證所提的融合估計方法的有效性。選擇CarSim 中B級轎車作為實驗原型車,車輛參數見表4。為更好檢驗本文方法對路面附著變化的魯棒性,仿真道路工況設置為對接路面。假設圖像法識別的路面類型準確并將其作為已知條件。
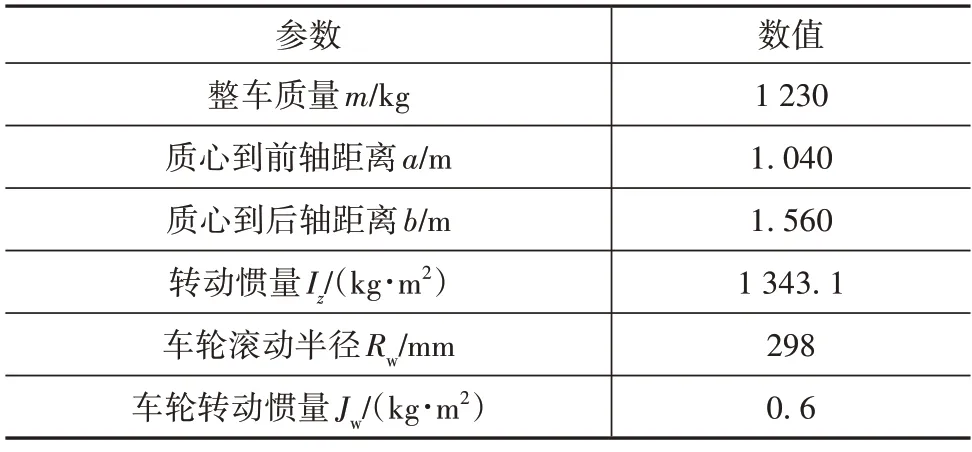
表4 車輛模型參數
對接路面1 如圖8 所示,設置為0-40 m 冰雪路面、40-80 m 潮濕瀝青路面,相應圖像法預測路面附著系數為0.275 和0.525,設定路面附著系數為0.3和0.5。初始車速設為40 km/h,采用開環節氣門控制,0-3 s 內節氣門開度在0.2-0.5 區間波動,3-5 s節氣門開度在0.8-1.0 區間波動,車輛縱向車速、縱向加速度和車輪轉速、滑移率變化情況如圖9 所示。輪胎縱向力估計結果如圖10 所示,左前輪、右前輪、左后輪、右后輪輪胎縱向力的均方根估計誤差分別為74.13、83.90、73.18、74.29 N。路面附著系數估計結果如圖11 所示,可以看出,在路面狀態變化位置,基于動力學的附著系數估計器需要一定的收斂時間,此時估計值存在明顯偏差。因此,通過圖像識別法融合修正該階段估計誤差。僅采用基于動力學的估計方法,左前輪、右前輪、左后輪、右后輪處的路面附著系數均方根估計誤差分別為0.040 1、0.030 0、0.040 0、0.030 5;基于圖像法與動力學融合方法的均方根估計誤差分別為0.023 9、0.023 6、0.028 6、0.026 0。
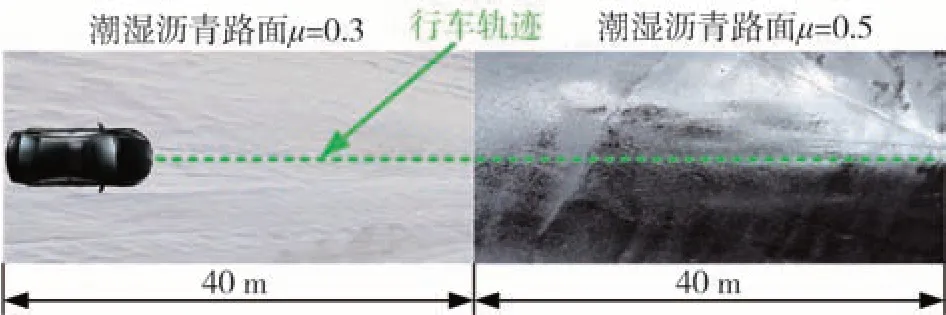
圖8 對接路面1示意圖
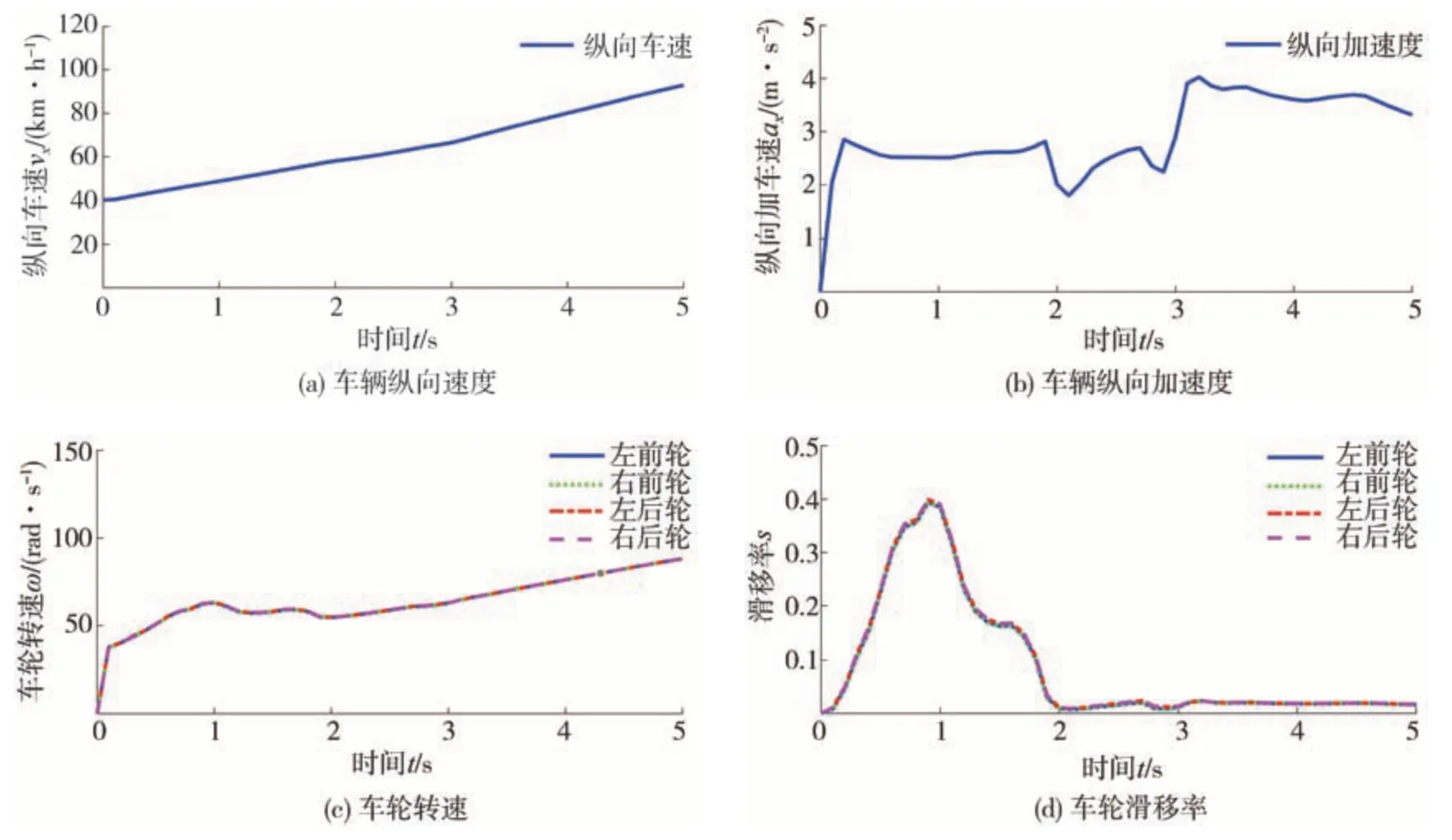
圖9 車輛動力學參數
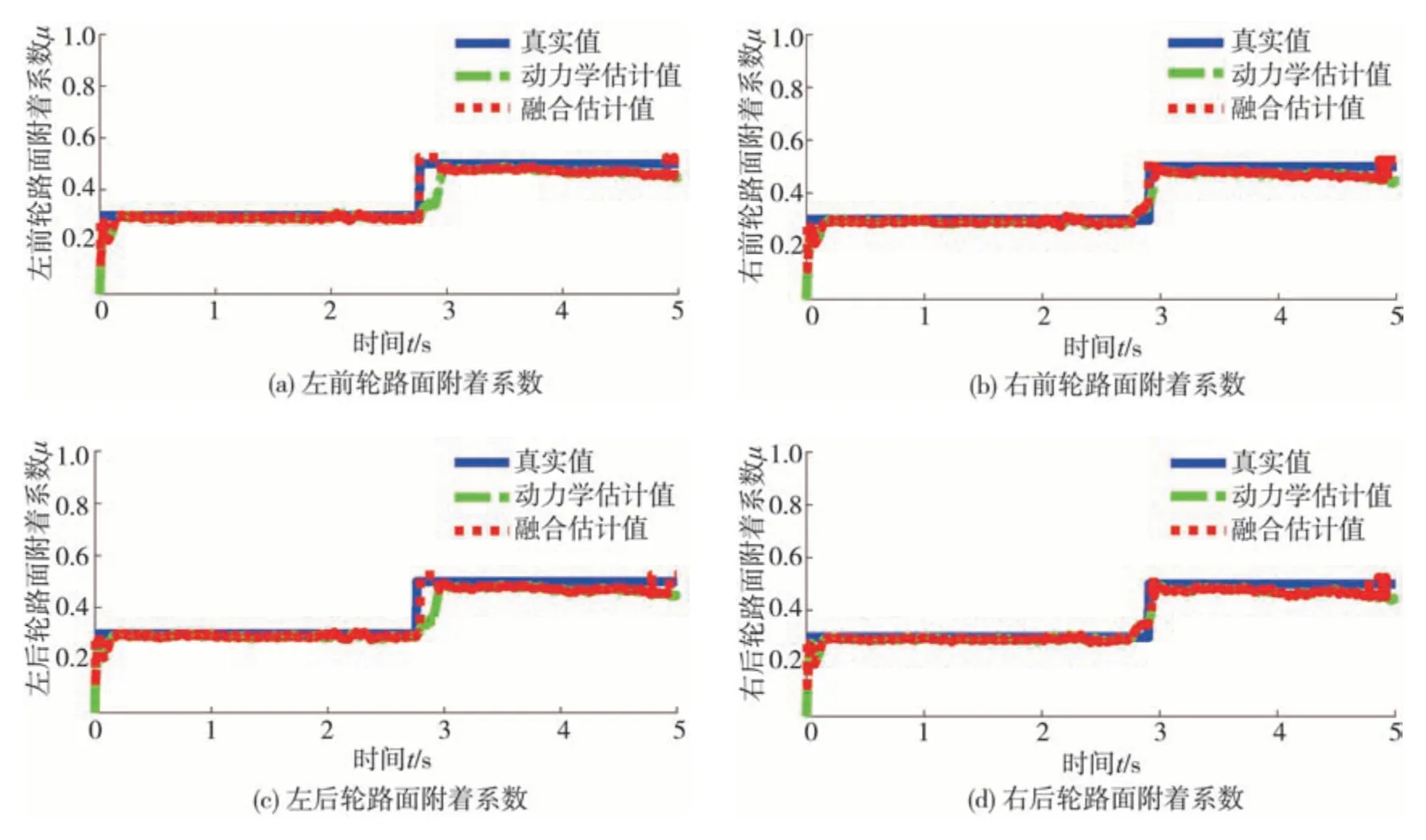
圖11 路面附著系數估計結果
對接路面2 如圖12 所示,設置為0-40 m 干燥瀝青路面、40-80 m 潮濕瀝青路面、80-120 m 冰雪路面,相應圖像法預測路面附著系數為0.75、0.525和0.275,設定路面附著系數為0.7、0.5 和0.3。測試車輛初始車速設為120 km/h,制動輪缸壓力0-3 s為3 MPa,3-5 s 為2 MPa,車輛縱向車速、縱向加速度和車輪轉速、滑移率變化如圖13 所示。輪胎縱向力估計結果和路面附著系數估計結果分別如圖14 和圖15 所示,左前輪、右前輪、左后輪、右后輪輪胎縱向力均方根估計誤差分別為88.40、98.06、90.15、89.13 N,而僅采用基于動力學的估計方法,左前輪、右前輪、左后輪、右后輪處的路面附著系數均方根估計誤差分別為0.068 6、0.065 4、0.066 3、0.064 6;基于圖像法與動力學融合方法的均方根估計誤差分別為0.028 2、0.024 6、0.035 2、0.034 3。
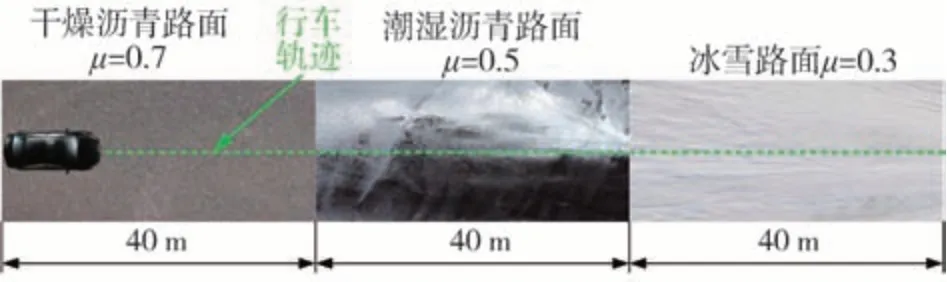
圖12 對接路面2示意圖
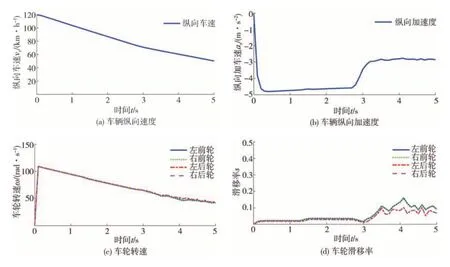
圖13 車輛動力學參數
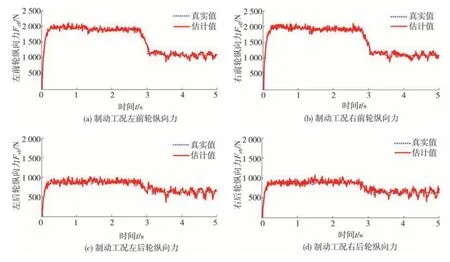
圖14 輪胎縱向力估計結果
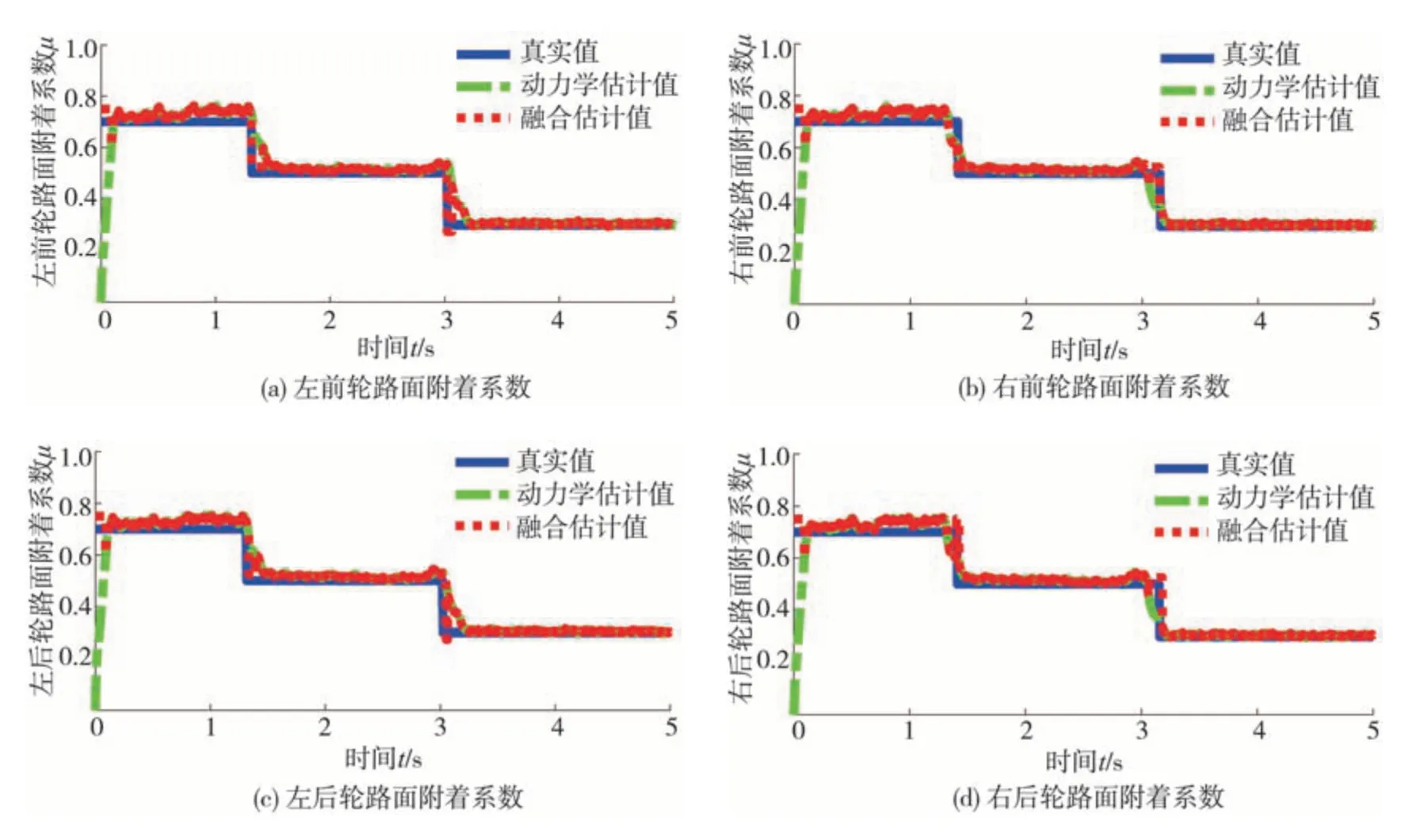
圖15 路面附著系數估計結果
在表3 給定的電腦配置下,對每張圖片進行語義分割和分類的總用時為0.3 s,偏差在0.05 s 以內,攝像頭拍攝范圍為車輛前方15-50 m 范圍[28]。動力學法估計四輪輪胎力和路面附著系數總用時為0.04 s。高速公路限速為120 km/h,假設車輛以120 km/h速度行駛,識別每張圖片車輛前行約10 m,x'ik未超過xd,在動力學相應點xd能夠獲得5個圖像識別結果。因此,不同車速下圖像識別均符合時空同步模塊要求,能夠在動力學響應點前完成識別,為粒子濾波算法提供參考輸入,本文算法可實現路面參數的實時估計。
綜上,本文提出基于圖像識別與動力學融合的估計方法能夠準確估計路面附著系數,相較于單一動力學方法估計精度顯著提升。
5 結論
本文中提出了一種基于圖像法與動力學法融合的路面附著系數估計方法。首先,基于卡爾曼濾波算法和單輪動力學模型估計輪胎縱向力,利用估計的輪胎縱向力與魔術輪胎模型建立基于粒子濾波的路面附著系數估計器。其次,通過輕量化DeeplavV3+語義分割網絡劃分路面區域,再通過MobileNetV2卷積神經網絡識別路面類型,查表獲得基于圖像識別的路面附著系數預估值。最后,建立時空同步體系和融合規則,實現了兩類路面附著系數估計結果的有效關聯和可靠融合。CarSim-Simulink 聯合仿真驗證結果表明,本文所提出的基于圖像識別與動力學融合的方法有效提高了路面附著系數估計精度和工況適應性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
核科學與工程(2015年4期)2015-09-26 11:59:03
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
