無人機集群控制技術研究
2023-07-14 08:24:32費陳,鄭晗,趙亮
彈箭與制導學報 2023年3期
費 陳,鄭 晗,趙 亮
(武警士官學校,浙江 杭州 311400)
0 引言
集群智能行為是一種自然現象,這種方式提高了數百種不同動物物種的生存機會,如鳥群、蟻群、蜂群、魚群、狼群等,它們通過某種方式進行信息交流,集群中每個物種都遵循一套規則來優化自身的行為,在決策中使用分散和自組織行為來適應環境變化和解決問題,以最大限度地提高集群的整體生存能力。
隨著無人化、智能化和導航技術的不斷發展,無人機從最初的訓練靶機,逐漸發展成為具有自主決策和自主攻擊能力的察打一體化無人機。基于無人機諸多特點,無人機在軍事[1-5]、民用[6]、未來電子戰[7-9]等領域都扮演著極其重要的角色,也是當前各國軍事智能化研究的熱點問題之一[10-12]。在最近的俄烏沖突中,烏克蘭就利用了TB2無人機成功摧毀2個Buk-M1-2防空系統和大約14輛軍車[13-14]。
但是面對日益繁雜的應用場景、詭譎多變的戰場態勢,無人機受自身硬件、軟件等因素的影響,依然存在一定的局限性[15-16]。對無人機而言,飛行能源、凈重和規格大小都具有限制性,一架無人機難以實現任務區域內的多維度、大規模任務執行,特別是在執行高危任務后,單架無人機可能會受到地面威脅源的打擊或防空系統的干擾而無法執行任務[17]。因此,為解決單架無人機的局限性,無人機一般較少單獨行動,而是用集群的方法來協調執行工作[18-19],無人機集群、無人機和無人重型坦克等其他載人或無人戰斗裝備構成混合的異構集群必然是現代化戰爭中關鍵的作戰方式之一[20-23]。
無人機智能集群作為無人作戰平臺的重要組成部分,具有個體簡單、集群協同,可形成高度智能的集合體特點[24],能夠完成監視、偵察、情報匯集和目標打擊等任務[25-27]。因此,無人機集群不同于多無人機,它是多無人機的高階形式,通過人工智能算法對多無人機進行合理配置、協調所演化的智能無人機群[28-30],相比于多無人機,無人機集群的控制難度更大,成本更低,協調能力、空間密度和智能化程度更高。
1 集中式控制系統結構
集中式控制系統是指無人機集群通過唯一的控制中心進行信息傳輸、交互的一種控制結構[31-33],如圖1所示。集群內的無人機將自身所收集的數據、信息傳送給任務控制站(控制中心)[34],而任務控制站負責對這些數據、信息進行整理、計算和分析,最終將處理完成的數據和信息反饋到集群內的無人機,集群內的無人機接收到這些反饋指令后進行任務的分配和實現。
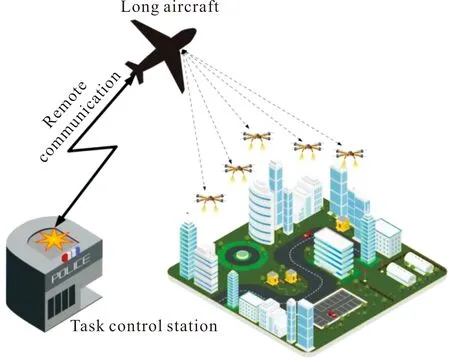
圖1 無人機集中式控制系統結構Fig.1 Structure of UAV centralized control system
1.1 集中式控制任務分配方法
如圖2所示,集中式控制下的任務分配方法主要分為智能類算法[35]和遷移模型[36]。其中,智能類算法由群體智能算法和遺傳算法構成[37],而通過模仿自然界生物群體協作表現出來的智能行為所形成的算法稱為群體智能算法,包括狼群算法[38]、魚群算法[39]、蟻群算法[40]、粒子群算法[41]等。

圖2 集中式任務分配方法Fig.2 Centralized task allocation method
蟻群算法模仿螞蟻的合作行為來解決復雜的組合優化問題,用螞蟻的路徑表示優化問題的可行解,整個蟻群的所有路徑構成優化問題的解空間。由圖3可知,該蟻群的解空間為路徑A、路徑B、路徑C,蟻群出發地與食物之間最短的路徑為路徑B,隨著時間的推移,路徑A和路徑C上的信息素含量較少,路徑B上的信息素含量最多,因此路徑B上螞蟻的數量也越來越多,在正反饋作用下,路徑B成為該蟻群獲取食物的最優路徑,對應優化問題的最優解。

圖3 蟻群算法概念圖Fig.3 Concept diagram of ant colony algorithm
粒子群算法是指將族群中的個體(粒子)當作優化問題的一個解,在解空間中,粒子之間進行信息融合、共享,并結合自身的策略和經驗尋找最優解;而遺傳算法(genetic algorithm)則是借鑒自然選擇和遺傳機制,遵循“優勝劣汰”的原則,模擬動物繁衍進化中的自然選擇、混合交叉、突變等方法進行更新迭代,以此來尋找最優解。
遷移模型主要有多旅行商模型(multiple traveling salesman problem,MTSP)[42]、車輛路徑模型(multiple capacitated vehicle routing problem,MVRP)[43],這兩種模型是將基于集中式控制下的無人機任務分配問題遷移到旅行商和車輛路徑規劃上面,從而進行最優求解。MTSP模型源于傳統的旅行商問題,將無人機集群中的個體看為旅行商,待分配的任務看作城市,該模型具有原理簡單、復雜度較低、可擴展性強的優點,要求進行任務分配時需要遍歷所有的任務點,適用于有限時間內無人機集群任務分配問題;MVRP模型源于無人機智能汽車的貨物配送問題,根據異構無人機集群的個體無人機任務分配性能約束,利用VRP模型對任務分配問題進行建模,得到優質的任務規劃方案。
1.2 集中式控制信息傳輸方式
如圖4所示,在無人機集中式控制結構中,無人機根據任務控制站或者長機傳輸的信息和數據進行決策,而無人機本身不具備決策能力[44-45]。
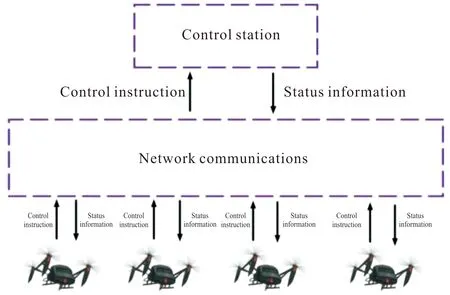
圖4 無人機集中式控制信息傳輸Fig.4 Centralized control information transmission of UAV
該控制結構存在以下弊端:1)決策不及時。由于在該控制結構中,無人機本身不具備決策能力,無人機需要根據任務控制站或者長機傳輸的信息、數據來決策[46],任務控制站需要不斷分析和處理所有無人機的全部信息,因此所承受的計算壓力較大,計算信息多、計算步驟復雜,進行任務分配時間久[47-48],特別是當集群中出現異構無人機時,需要進行海量數據交互,任務控制站可能會出現接收信息不全或信息紊亂的局面,導致任務決策有誤或任務決策延遲。2)抗干擾性差。由于任務控制站通常只有一個,當任務控制站進行任務分配時,一旦遭到破壞,那么造成的損害極大[49-50]。但這種方式的優點是無人機進行信息傳輸穩定、傳輸速率快,易獲得全局最優策略,適用于戰場環境條件已知,敵方攻擊能力弱和攻擊范圍小,或己方控制站或長機隱身能力和機動能力較強,對全局的態勢感知強,且自身的數據處理能力出色,執行任務規模較小、傳輸數據和信息少。
2 分布式控制系統結構
分布式控制系統是指采取自治和協作的方法來解決全局控制問題,基于各無人機之間的信息交互來完成任務,具有充分的自治權[51],如圖5所示。分布式控制的集群內無人機不僅具有收集信息、信息交互的能力,還具有對數據進行整理計算、分析決策的能力[52],并且具備與自然環境、任務目標和其他無人機交互的能力,充分考慮各種環境因素,無人機自身通過計算,能夠生成處理任務分配的策略。

圖5 分布式控制系統結構Fig.5 Distributed control system structure
2.1 分布式控制任務分配方法
目前,基于分布式控制系統進行任務分配的方法主要有優化算法[53]和類市場機制[54],如圖6所示。
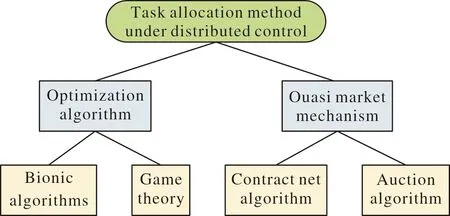
圖6 分布式任務分配方法Fig.6 Distributed task allocation method
優化算法主要有基于仿生算法[55]和博弈論[56],基于仿生算法是通過模擬生物自身規律,并將其通過算法的形式體現出來的一種方法,該算法在分布式控制任務分配中應用十分廣泛,極具代表性的仿生算法是果蠅算法(drosophila algorithm)[57]。如圖7所示,果蠅覓食首先根據果蠅個體隨機選擇方向進行飛行,然后所有果蠅根據自身嗅覺能力飛向高氣味食物濃度高的位置,進入該位置范圍后,再利用敏銳的視覺尋找食物源或同伴聚集的位置,形成新的果蠅聯盟,最后再一次隨機選擇方向飛行,飛向新的氣味食物濃度高的位置并再次聚集,以這樣的方式循環往復,直到找到食物源為止。
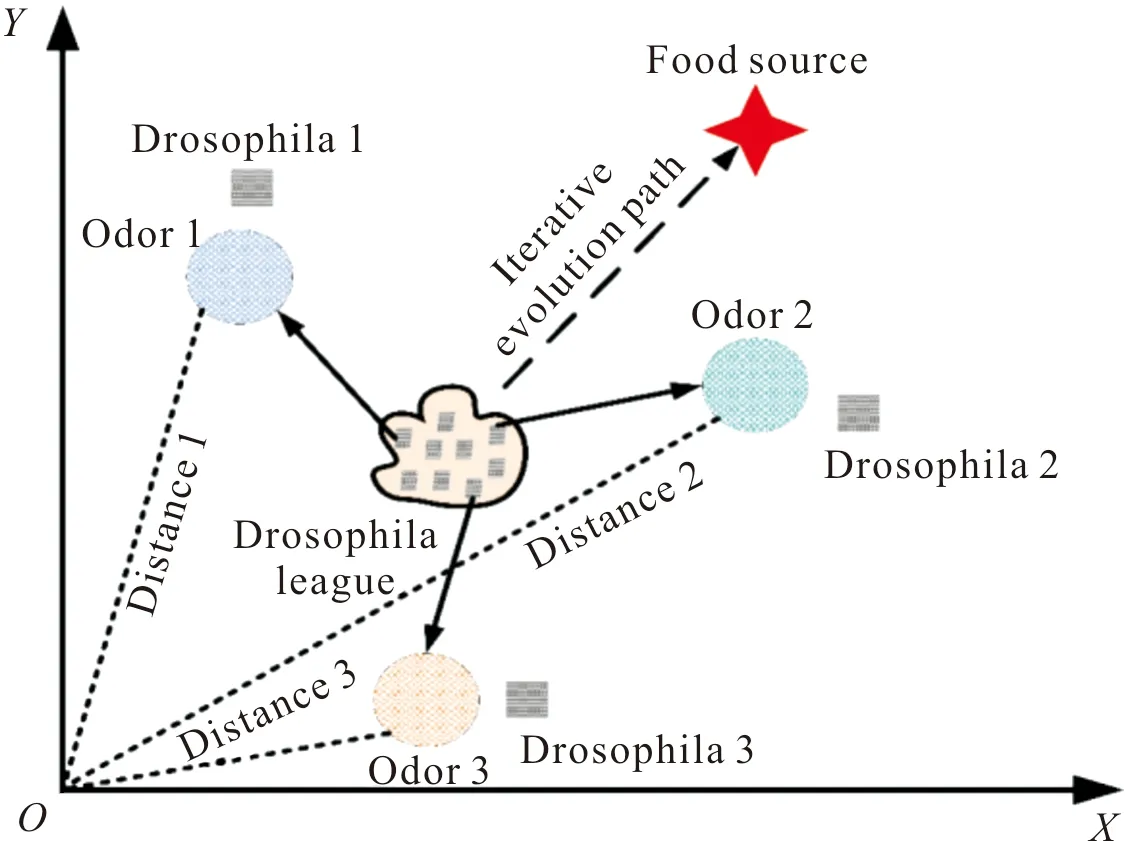
圖7 果蠅覓食Fig.7 Drosophila foraging
文中的博弈論(game-theory)則是研究無人機集群中每架無人機進行任務分配時所產生的策略,并對策略進行優化,實現全局最優策略[58],首先將無人機任務分配問題公式化為成本函數的最小化,其中包括每架無人機的多個目標和約束條件,然后,建立了一個基于博弈論的框架,將最小化問題歸結為尋找納什(Nash)均衡,最后利用改進的人工智能算法收斂至納什均衡,即獲得全局最優解。
類市場機制主要有合同網算法[59]和拍賣算法[60]。其中,合同網算法是指將集群中每架無人機的任務分配情況作為投標值,每架無人機都是獨立存在的,招標無人機發布任務信息即為招標,接到此次任務信息的無人機,根據自身能力和任務信息進行評估,投放投標值并成為投標無人機,最后評估這些投標無人機的投標值并選擇合適的投標無人機,最終,被選中的投標無人機即為中標無人機而執行任務。拍賣算法與合同網算法類似,都是無人機根據自身利益依次對分配任務進行報價,通過多輪次的競標,將該任務分配給適合的無人機,實現任務的合理化分配。
2.2 分布式控制信息傳輸方式
如圖8所示,在分布式控制結構內,無人機之間可以進行信息的融合、交互,將全局的任務分配難題轉變為局部的無人機之間的任務分配問題,由無人機自身通過信息協調的方式來進行決策和解決[61]。
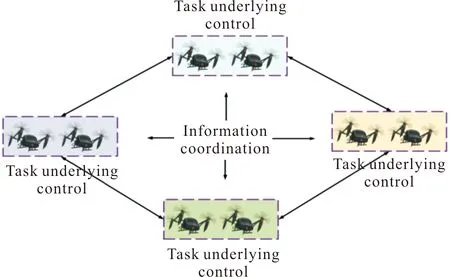
圖8 無人機分布式控制信息傳輸Fig.8 Distributed control information transmission of UAV
分布式控制結構存在以下問題:1)無人機資源浪費[62]。由于無人機集群中無人機數量眾多,當無人機進行自主決策時,難于掌握全局信息,存在同一任務由多架無人機重復完成,這就導致無人機資源的浪費。2)數據信息多,處理信息量大[63]。為具有任務決策的實時性,在此控制模式下,無人機之間要進行大量的數據傳輸和共享,信息量會隨著集群內無人機的數量呈指數增長[64]。
與集中式控制方式相比,分布式控制下的無人機具有較強的主體性和機動性,能夠對任務信息、自身信息展開分析和管理決策,抗干擾能力強、數據計算速度快,可以自主與其他無人機進行信息融合,實現信息共享并協作完成任務,并對局部態勢變化做出反應,提高了系統的靈活性與魯棒性。該控制方式適用于戰場環境條件未知、動態環境或中等至大規模系統中,對敵方掌握的信息較少,己方無人機集群中單架無人機應具備較強的單兵作戰能力,且對局部戰場態勢感知能力強,自身的數據處理能力出色,具有高頻次切換通信的能力、通信質量高,執行任務規模較廣、執行任務層次多等特點。
3 集散式控制系統結構
集散式控制系統如圖9所示。
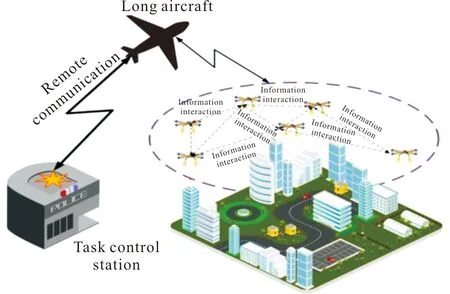
圖9 集散式控制系統結構Fig.9 Centralized and distributed control system structure
該方法主要是借鑒多智能體系統(MAS)的思想[65],結合集中式和分布式的優缺點,由地面任務控制站或長機將任務轉化為多項子任務,再分給各無人機,各無人機根據自身的任務進行信息共享和信息交互,將完成任務的收益及損失等信息發送給長機或地面任務控制站。各無人機在完成任務后,都會根據自身的局部利益、環境信息進行任務評估,一旦發現對自身非常有利的解決方案,將該方案遞交給地面任務控制站或長機,地面任務控制站或長機將對每架無人機計劃方案開展總體評定[66-67]。若該方案能夠提高無人機集群整體收益,則方案將被選用,否則被否決,每架無人機的任務分配方案都是根據全局收益來規劃和設計。
3.1 集散式控制任務分配方法
相對于集中式控制體現在任務控制站或長機對所有任務先進行集中分配、調整,分布式控制則體現在以下兩個方面:一是在預分配環節,各無人機收到任務控制站或長機的任務分配信息后,無人機之間協作完成任務[68];二是任務或環境突然變化時,可采用分布式協調的方式,根據環境、任務的變化情況,及時調整任務分配策略,以最小損失代價應對態勢的變化。一般利用集散式任務分層框架來描述無人機集散式控制系統結構[69],如圖10所示。從集散式任務分層框架中可以看出,主要包括以下兩個部分:

圖10 集散式任務分層框架Fig.10 Centralized and distributed task hierarchical framework
1)集中控制部分。任務控制站根據掌握的任務信息、環境資源信息和無人機狀態信息,對任務集進行目標聚類,目標聚類的目的是將彼此接近的目標歸為一組,是簡化大規模任務分配問題的關鍵和基本步驟,經過這一步,NT目標被劃分為M簇,M等于無人機聯盟的數量,為了在無人機聯盟之間平均分配工作負載,聚類算法必須平衡每個集群中的目標數量。然后進行任務集群分配,將多個小無人機聯盟看為一個大的無人機聯盟,M個集群分配給大無人機聯盟中的M個小無人機聯盟,通過人工智能算法,計算出無人機目標任務分配的最優策略,即每個小無人機聯盟被分配一個最優任務集群。任務控制站實現目標聚類和任務集群分配功能。
在集中控制部分所使用的算法是聚類算法,主要有K均值聚類算法(K-Means)[70]、均值漂移聚類算法[71]、基于密度聚類算法(DBSCAN)[72]、高斯混合模型(GMN)的最大期望(EM)聚類算法[73]等,而K-Means算法是眾多算法中應用最為廣泛的聚類算法。如圖11所示,該算法首先隨機確定質心數量K,然后對所有點進行劃分并形成多個簇,將每簇的質心更新為該簇所有點的平均值,最后迭代該過程,直到數據集中的所有點距離其所對應的質心最小時結束循環。
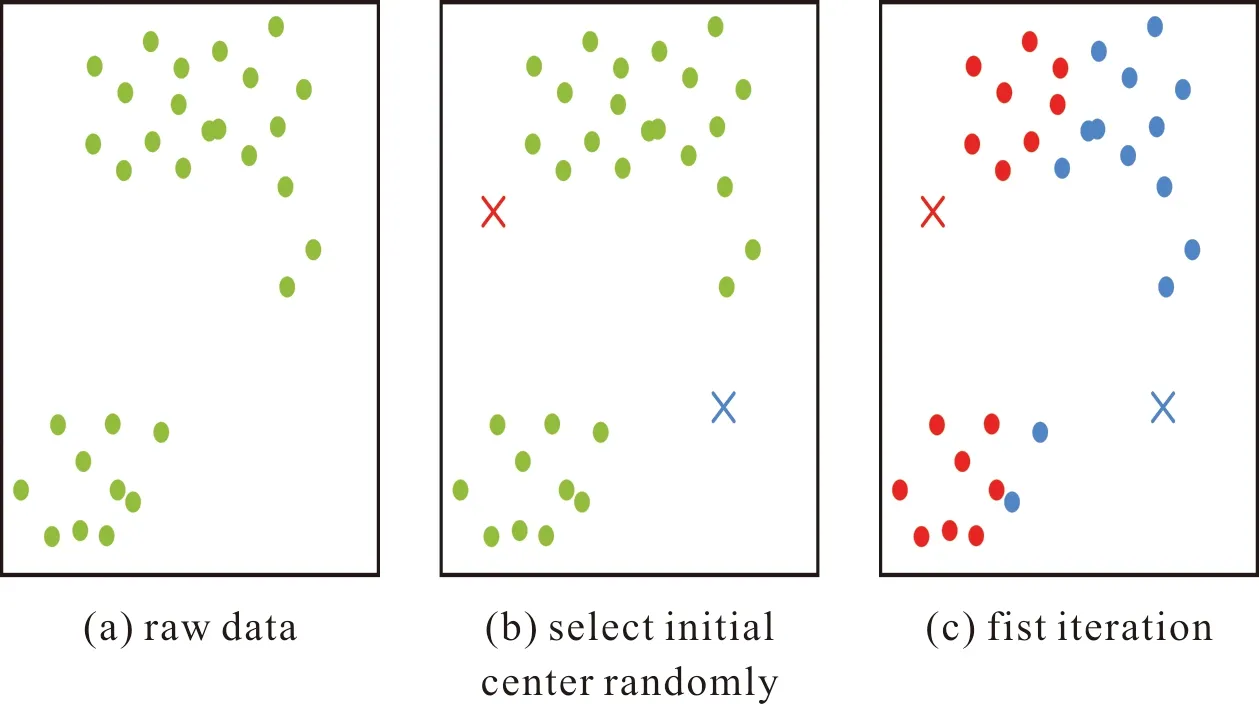
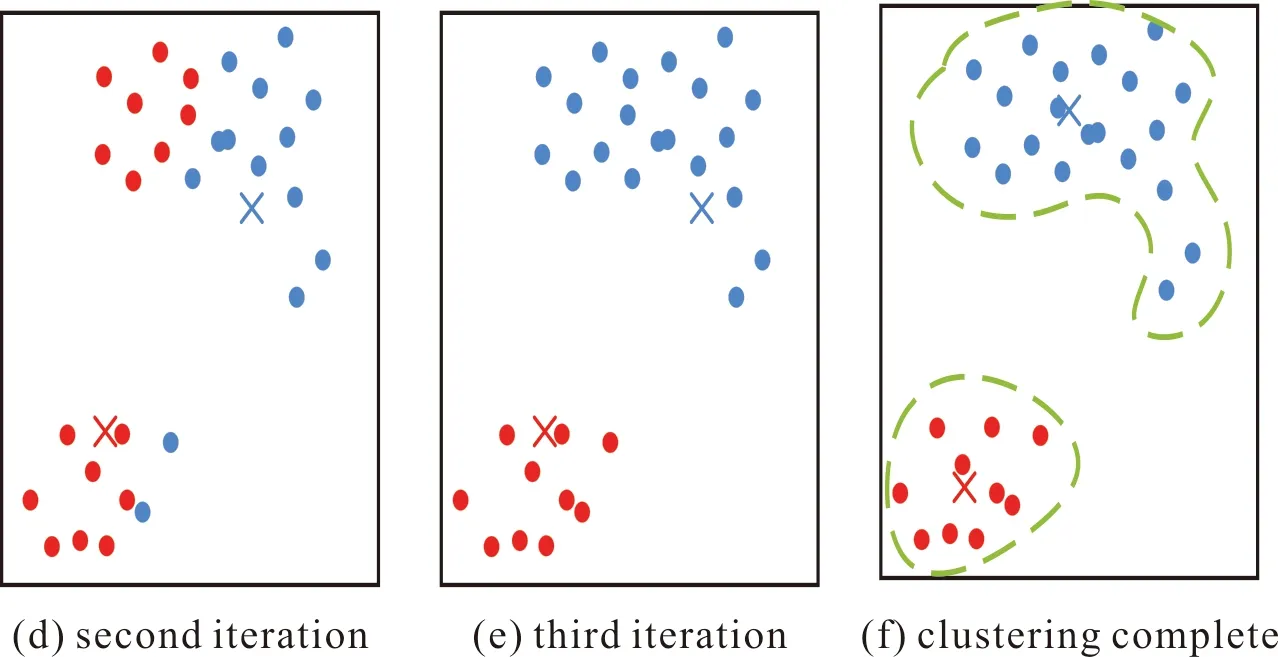
圖11 K-Means聚類過程Fig.11 K-Means clustering process
2)分布控制部分。在戰場態勢發生變化時,小無人機聯盟內決策、協調并對任務進行分配。在每個小無人機聯盟內,都有一個Leader無人機,該無人機具有對小無人機聯盟內的指揮作用,Leader無人機通過強化學習算法,將小無人機聯盟內的每架無人機與目標任務進行交互,獲得這個小無人機聯盟完成目標任務的最優策略。小無人機聯盟中Leader無人機獲得聯盟內目標任務分配的最優策略并將任務分配給單架無人機,指定聯盟內成員的攻擊任務目標,確定攻擊順序。同時,聯盟內的任務執行情況、環境變化等信息由Leader無人機向任務控制站進行反饋交互,任務控制站可根據這些信息對任務和無人機進行二次分配,起到提升任務執行效率和保障任務完成率的作用。
在分布式控制部分所使用的算法主要是強化學習算法[74],強化學習通過“探索-利用”機制,一方面讓智能體不斷對環境進行探索,獲得觀測值;另一方面,對已有經驗和信息加以利用,不斷更新學習策略,以使累積獎勵最大化。強化學習原理如圖12所示,在強化學習中,一般先定義決策者或智能體(agent),再將智能體之外的事物定義為“環境(environment)”,系統與環境相融,智能體和環境之間的交互過程由三個要素組成,分別是:狀態(state)、動作(action)、獎勵(reward)。智能體根據狀態St,執行動作At并與環境進行交互,得到獎勵Rt并獲得更新的狀態St+1,在時間步t下,根據當前狀態St和獎勵Rt,智能體提供當前動作At,系統狀態由St轉變為St+1,與環境交互反饋獎勵Rt+1。
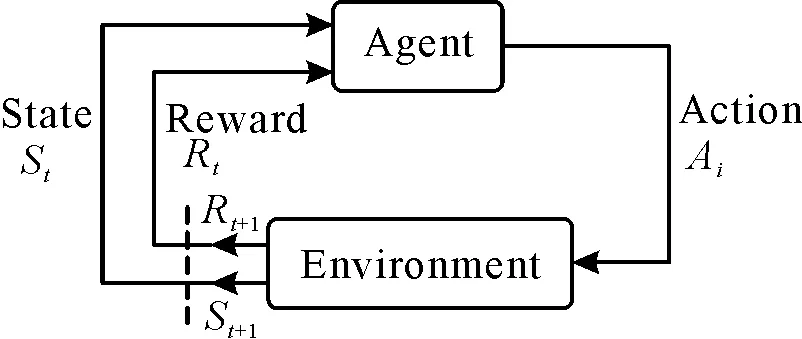
圖12 強化學習原理Fig.12 Principles of intensive learning
強化學習算法主要有Q學習算法(Q-Learning)[75]、狀態-動作-獎勵-狀態-動作算法(state-action-reward-state-action,SARSA)[76]、深度Q網絡算法(deepQnetwork,DQN)[77]、深度確定性策略梯度算法(deep deterministic policy gradient,DDPG)[78]、多智能體強化學習(multi-agent deep deterministic policy gradient,MADDPG)[79]等,而傳統的強化學習算法需要一個穩定的環境,由于無人機集群中無人機數量多,每架無人機的策略都在變化,可選擇的動作空間變大,對于集群中的無人機而言,環境是不穩定的且每架無人機所能觀測的環境信息也是有限的,這些原因導致傳統強化學習算法無法收斂,而MADDPG可以解決這些問題,因此,MADDPG在無人機集群任務分配中的應用十分廣泛。
如圖13所示,MADDPG采用的是“中心化訓練,去中心化決策”的網絡架構,其核心思想是Actor-critic網絡:每個Agent都有一個動作網絡(策略網絡)和價值網絡,動作網絡根據當前獲取的狀態si計算出執行動作的概率分布,根據動作概率分布隨機選擇動作ai,而價值網絡根據當前執行的動作和狀態(ai,si)得到一個Qi值,并根據Qi值評估當前狀態下該動作ai的好壞,以此更新動作網絡參數θi,提高動作網絡性能;而價值網絡則根據全局狀態S、所有Agent的動作A,得到一個實數,該實數表示基于全局狀態S下,第i個Agent執行動作ai的好壞程度,以此來對第i個Agent的動作網絡性能進行改進,價值網絡則是根據ri進行價值網絡參數ωi更新,以此來保持較高的評判水平。

圖13 MADDPG網絡架構Fig.13 MADDPG network architecture
在訓練過程中,為了避免經驗數據的浪費,同時也為了將訓練數據序列打散,消除相關性,使訓練更加穩定,加入了訓練回放機制,引入經驗池。將每一輪迭代的四元組數據(si,ai,ri,si+1)存放在經驗池中,經驗池大小設置為N,當數據量超過N時,每存入一條新的四元組數據將覆蓋掉最早的一條四元組數據,在訓練階段,動作網絡隨機抽取一條四元組數據進行訓練,價值網絡則獲取Agent自身信息以及其他Agent的動作和狀態等信息進行訓練,即中心化訓練;在執行階段,由于每個Agent的動作網絡在訓練階段已經訓練完畢,因此在執行時,不涉及價值網絡,只需要Agent自身的動作網絡,即去中心化執行。這種訓練-執行方式克服了環境的非平穩性和觀測環境信息局部性,使訓練更加穩定。
3.2 集散式控制信息傳輸方式
集散式信息控制結構如圖14所示,無人機組成多個無人機聯盟,各聯盟內有一個Leader無人機負責聯盟內的信息交流、協同控制、任務分配等,即在局部任務執行范圍內,各無人機聯盟內就可完成任務,無需等待無人機控制中心的指令。同時,Leader無人機對信息進行過濾,將聯盟內收集到的高價值信息傳送給無人機控制中心,無人機控制中心整合各無人機聯盟的信息,根據實際需求和態勢變化,從戰場大局的角度對各無人機聯盟做統一宏觀調配,無人機控制中心也可通過遠程通信的方式和任務控制站保持信息交互,接收新的任務指令,調整策略。集散式控制方式將目標任務分配的集中式全局優化問題轉化為分散的局部優化問題。該方式既消除集中式計算量大、分布式獲得信息不全的問題,又能使無人機具備自治能力,極大的提升作戰效率,滿足全局利益最大化。

圖14 集散式信息控制結構框架Fig.14 Distributed information control framework
因此,集散式控制方式下,對無人機的智能化、信息化要求最高,該控制方式適用于戰場環境詭譎多變,敵方目標多且需精確打擊,或敵方目標不斷改變自身策略,難以在短時間內對目標進行打擊等情況。集散式控制方式是最貼近戰場實際情況的一種控制方式,且在該方式下,無人機任務完成度更高、任務執行效率也更高,即能在短時間內對敵方造成毀滅性傷害。
4 結論
無人機集群任務分配和控制是無人機集群技術研究的重要部分。首先就當前無人機集群任務分配和控制方式的發展和研究現狀進行了概述,具體分析了集中式、分布式、集散式控制系統結構的關鍵技術和研究進展,然后從任務分配方法、信息傳輸方式等角度進行剖析,著重分析了3種控制結構下的適用范圍、優缺點,以及任務分配算法的種類、原理,以期為無人機集群任務分配控制發展提供理論基礎,對未來無人機集群任務分配控制技術起到一定的推動作用。
猜你喜歡
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
中華手工(2017年2期)2017-06-06 23:00:31
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
