應對ChatGPT的六招
2023-06-22 22:46:53埃森哲
21世紀商業評論 2023年6期
ChatGPT 推出僅兩個月,月活躍用戶就達到1億,成為有史以來增長最快的消費應用程序。
所有人,所有地方,都將切實感受到這項技術的顛覆性潛力。
ChatGPT背后的大語言模型,正在憑借兩項優勢改變著市場規則:
第一,這類模型破解語言復雜性的密碼,機器擁有前所未有的能力,可以學習語言、上下文含義和表述意圖,并獨立生成和創建內容。
第二,在利用大量數據(文本、圖像或音頻)進行預訓練后,這些模型能夠針對眾多不同的任務做出調整或微調。用戶可以多種方式,對模型按原樣重復使用或稍加修改后再次使用。
商界領袖們普遍認識到了這一時刻的重要性。
例如,我們研究發現,所有行業中40%的工作時間,都將得到GPT-4等大語言模型的協助。
大語言模型具有處理大規模數據集的能力,所有用語言記錄傳達的內容,如應用、系統、文檔、電子郵件、聊天、視頻和音頻等等,都將進行創新、優化和重塑,最終走向全新的高度。
語言任務占企業人員工作總時長的 62%,其中65%的時間可借助人員強化和自動化技術來提升工作活動的生產力。
時機就是一切。
最近一項技術趨勢調研中,225名受訪中國企業高管里面,有72%對人工智能基礎模型帶來的新功能表示非常、或極為興奮,比例略低于全球平均水平。
越來越多的中國企業,正在積極探索生成式人工智能技術,開始應用大型語言模型來實現更多的創新和效率提升。
在中國,大語言模型應用方式主要有三種:SaaS、私有云部署、本地化部署,成熟度依次從高到低排列。
目前,SaaS化的部署方式是最為成熟的,以國外Azure Open AI Services為標桿。
在國內市場,百度的文心一言和阿里的通義千問,正在參與到激烈的競爭中。與 Azure 提供的服務相比,國內廠商提供的 SaaS服務,更具有數據安全和合規性上的優勢,盡管在綜合能力上還有待加強。
私有云部署方式同樣以百度為領先。
相較于SaaS 服務,私有化部署更具有數據和模型自定義能力和垂直行業定制化能力。
這種方式可更好地服務于相對較為專業的客戶,可充分利用客戶提供的行業知識,同時保證不對競爭對手可用。更柔性的服務器使用策略,也讓這種方式相較于本地化的前期投資大為降低。
綜合來看,這是目前國內垂直行業客戶最可行的實現方式。
本地化部署方式有非常多的選擇。
學術界中提供的有清華大學的ChatGLM、斯坦福提供的Alpaca,商業公司提供的有Databricks的Dolly、Scale.ai的圖像專精的大語言模型等等。
本地化部署存著成本高昂、無法確定使用效果等兩個問題。目前處于非常早期的階段,是否可以進一步使用有待后續觀察。
總的來說,大語言模型正處于快速發展的階段,其未來的形態無法被預測,可以肯定的是,大規模的應用一定是必然的趨勢。
我們對生成式人工智能的了解越來越深入,它將顛覆傳統的工作模式。大多數工作者都將擁有得力的“助手”,從根本上改變工作的完成方式和完成內容。
企業需要像技術投資一樣,持續投入不斷發展的業務運營和人員技能培訓。徹底重新構想工作的完成方式,并幫助員工緊跟技術驅動型變革
積極迎接生成式人工智能時代,存在六大技術應用要點。
業務驅動
即使創新技術有諸多優勢,在整個組織中全面推廣并非易事,尤其當新技術會徹底改變現有工作方法時,會遇到特別多的阻力。
企業可以先通過嘗試生成式人工智能的諸多功能,累積早期成功并得到變革倡導者和意見領袖的支持,不斷提高員工對新技術的接納程度,為進一步普及創造所需條件,進而啟動轉型和技能再培訓議程。
企業必須雙管齊下地進行嘗試:
其一,專注于容易獲得的機會,使用可消費的模型和應用迅速實現回報;其二,著力使用根據自身數據定制的模型來重塑業務、客戶洽談、以及產品和服務。
業務驅動型思維,是定義并成功建立應用模式的關鍵。
隨著企業深入開展人工智能重塑業務的各種探索,他們將切實收獲價值,明確各種應用場景下最為匹配的人工智能類型,厘清投資規模和復雜程度。
他們還能測試和改進有關數據隱私安全、增強模型準確性、防止偏見和保護公平的方法,并知曉何時需要采取“由人主導迭代”(Human in the Loop)的保護措施。
舉例,一家大型歐洲銀行集團啟用微軟Azure云平臺和GPT-3大語言模型,來幫助員工進行電子文檔檢索。
這一舉措,使用戶可以快速獲得問題的答案,大大節省了時間,并提高準確性和合規性。
為了進一步提升員工技能,這家銀行構建了三年創新計劃,后續還會在合同管理、對話型報告、以及票據分類等領域應用生成式人工智能。
圖1:生成式人工智能技術堆棧的每一層級都將迅速進化
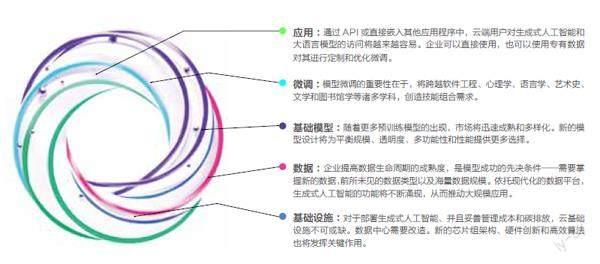
此舉不僅將內部知識庫進行升級、幫助員工獲取所需信息,更有助推進自身向數據驅動型機構的目標邁進。
以人為本
為了使生成式人工智能取得成功,企業需要像重視技術那樣,關注人員及培訓工作。
他們應當大幅增加對人才的投資,以應對兩類不同的挑戰:創建人工智能和使用人工智能。
這意味著, 要在人工智能設計、企業架構等技術能力方面培養人才;同時培訓整個組織的人員,使他們有效地與人工智能化的流程合作。
例如,在對22個工作類別的分析中,我們發現,大語言模型會影響所有類別,最低程度為每個工作日的 9%,最高可達63%。在22種職業中,有5種可以利用大語言模型來革新一半以上的工作時長。
即使是現實世界中精通如何應用數據的各領域專家(例如,醫生對患者健康數據的解析), 也缺乏足夠的技術知識來了解這些模型如何工作,以及相信技術能成為“工作伙伴”。
企業還將設立全新的崗位,包括語言學專家、人工智能質 量控制員、人工智能編輯和提示工程師。
對于生成式人工智最有前途的領域,企業應當首先將現有工作分解為基礎任務組合,然后評估生成式人工智能可能影響每項任務的程度——完全自動化、人員增強,抑或與之無關。
籌備數據?
為了定制基礎模型,企業需要使用特定領域的企業數據、語義、知識和方法。
在生成式人工智能時代到來之前,企業可以通過以應用模式為核心的人工智能方法,從人工智能中獲得價值,無需對其數據架構和資產進行現代化改造。
現在情況已經截然不同。基礎模型需要大量精心組織的數據來學習,因此,破解數據挑戰,已成為每家企業的當務之急。
企業需要采用一種戰略性、規范化的方法,獲取、 開發、提煉、保護和部署數據。
具體而言,應依托云環境構建現代化的企業數據平臺,其中包含一組可信賴、 可重復使用的數據產品。
憑借此類平臺的跨職能特征、企業級的分析工具、以及將數據存儲在云端倉庫或數據湖當中,數據能夠擺脫組織孤島的束縛,在整個企業中普遍使用。
隨后,企業可在某一地點或通過分布式計算策略(如數據網格),統一分析所有業務數據。
打造基礎
為了充分滿足大語言模型和生成式人工智能的大規模計算需求,企業需要考慮自身是否擁有合適的技術基礎設施、架構、運營模式和治理結構,同時密切關注成 本和可持續能源消耗。
他們必須設法從成本和收益的角度,評估比較這些技術與其他人工智能或分析工具,后者可能更適合特定的應用模式,并且成本僅為前者的幾分之一。
企業需要建立一套強有力的綠色軟件開發框架,在軟件開發生命周期的所有階段,考慮能源效率和材料相關排放。
人工智能還可以發揮更廣泛的作用,使業務更具可持續性并實現環境、社會和治理(ESG)目標。我們調研發現,在生產和運營環節成功減少排放的企業中,70%都使用了人工智能。
尋找伙伴
創建基礎模型很可能是一項復雜、成本高昂的計算密集型工作。
除了全球頂級企業外,幾乎所有組織都無法僅憑一己之力完成該任務,這超出了他們所掌握的能力和方法。
令人振奮的是,得益于超大規模云服務機構、科技巨頭和初創企業的海量投資,企業可借助新興生態系統的威力。
僅在2023年,全球對人工智能初創公司和成長階段公司的投資,預計就將超過 500 億美元。
這些合作伙伴能夠帶來經過多年打磨的最佳實踐,并為特定應用模式下如何高效而有效地使用基礎模型提供寶貴洞見。
擁有恰當的合作伙伴網絡——包括技術企業、專業服務商和學術機構,將成為駕馭快速變革的關鍵。
構建體系
生成式人工智能的快速采用為所有企業提出了新的緊迫工作:建立一套穩健、負責任的人工智能合規體系。
這包括兩方面的事項——建立控制流程,在設計階段評估生成式人工智能應用方式的潛在風險;制定明確措施,在整個業務中嵌入負責任人工智能方法。
我們研究表明,大多數企業仍任重而道遠。
我們2022年面向全球850名高管人員的調研顯示,受訪者普遍認識到負責任人工智能和人工智能監管的重要性。僅有6%的企業認為,自身已打造了充分穩健的負責任人工智能基礎。
企業的負責任人工智能原則應當由高層定義和領導,并轉化為有效的風險管理和合規治理架構,包括組織原則和政策、以及適用的法律和法規。
負責任人工智能的使用必須由CEO引領,從加強培訓和意識培養開始,然后擴展至關注執行與合規。
早在數年前,埃森哲就已率先采用這種方法來管理負責任的人工智能,不但設置了由CEO領導的議程,現在進一步出臺了正式的合規計劃。
我們自身的經驗表明,原則驅動的合規方法既能提供護欄,又足夠靈活,可以隨著技術的快速發展而更新,確保企業不會始終疲于“追趕”。
為通過設計來實現負責,企業需要從被動響應的遵從策略,轉向主動開發完善的負責任人工智能系統。
這必須借助一套綜合框架,其中涵蓋:原則和治理措施;風險管理、政策和控制手段;以及技術、賦能因素、文化和培訓工作。
本文改編自埃森哲最新發布的《生成式人工智能:人人可用的新時代——ChatGPT 背后的技術將深刻改變工作模式,重塑商業形態》,編輯略有改動,經授權發表。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
小康(2017年16期)2017-06-07 09:00:59
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
