工業(yè)企業(yè)數(shù)據(jù)挖掘和知識圖譜系統(tǒng)建設(shè)研究
2023-04-05 16:03:38王輝邢偉曹帥陰鵬飛史夢瑤
中國標(biāo)準(zhǔn)化 2023年20期
關(guān)鍵詞:數(shù)據(jù)分析數(shù)據(jù)挖掘
王輝 邢偉 曹帥 陰鵬飛 史夢瑤

摘 要:本文介紹了工業(yè)企業(yè)數(shù)據(jù)平臺分析系統(tǒng)的數(shù)據(jù)挖掘和知識圖譜相關(guān)知識,分析了數(shù)據(jù)挖掘方面的知識體系建設(shè)、實體識別、相關(guān)的算法和知識圖譜方面的技術(shù)路線、業(yè)務(wù)建設(shè)、具體應(yīng)用、核心算法,為業(yè)務(wù)應(yīng)用的智能問答系統(tǒng)提供了數(shù)據(jù)和服務(wù)支持。
關(guān)鍵詞:工業(yè)企業(yè),數(shù)據(jù)分析,可視化工具,數(shù)據(jù)挖掘,知識圖譜
DOI編碼:10.3969/j.issn.1002-5944.2023.20.013
0 引 言
數(shù)據(jù)挖掘和知識圖譜系統(tǒng)是工業(yè)企業(yè)數(shù)據(jù)平臺的大數(shù)據(jù)中臺的重要組成部分。它以工業(yè)企業(yè)數(shù)據(jù)平臺的采集系統(tǒng)的元數(shù)據(jù)為基礎(chǔ)數(shù)據(jù)源,其輸出成果為工業(yè)企業(yè)的智能問答系統(tǒng)的業(yè)務(wù)應(yīng)用提供數(shù)據(jù)支撐和服務(wù)支撐,對數(shù)據(jù)挖掘和知識圖譜起到承上啟下的作用。下面分別從數(shù)據(jù)挖掘、知識圖譜和自然語言處理工具三個方面做論述,希望對讀者能有一定的借鑒意義。
1 數(shù)據(jù)挖掘
1.1 知識體系建設(shè)
本平臺的知識體系建設(shè)包括平臺知識體系和機構(gòu)知識體系。
平臺知識體系是指針對工業(yè)企業(yè)的各個業(yè)務(wù)平臺創(chuàng)建的指標(biāo)標(biāo)簽體系。包括辦公協(xié)同平臺、經(jīng)營管理平臺、安全生產(chǎn)平臺、標(biāo)準(zhǔn)運行平臺、共享服務(wù)平臺、移動支付平臺等一級標(biāo)簽。其中辦公協(xié)同平臺對應(yīng)有一站式信息平臺標(biāo)簽、員工自助標(biāo)簽、業(yè)務(wù)云平臺、工資報表、自主招聘等二級標(biāo)簽;安全生產(chǎn)下對應(yīng)安全生產(chǎn)管理信息平臺、安全生產(chǎn)OMS、雙預(yù)控;虹膜稽核等二級標(biāo)簽;經(jīng)營管理對應(yīng)BPC全面預(yù)算、數(shù)據(jù)治理平臺、電子商務(wù)、合同審計、招投標(biāo)平臺等二級標(biāo)簽[1]。
機構(gòu)知識體系主要針對本平臺所在的直屬機構(gòu)創(chuàng)建的指標(biāo)標(biāo)簽體系。包括機關(guān)部室、共享中心、各級業(yè)務(wù)部門、客戶、供應(yīng)商等一級標(biāo)簽。
1.2 實體識別
實體識別的技術(shù)路線是通過構(gòu)建結(jié)合數(shù)據(jù)主動命名實體識別系統(tǒng),準(zhǔn)備訓(xùn)練命名實體識別模型所需要的數(shù)據(jù)集,主動學(xué)習(xí)模塊、數(shù)據(jù)標(biāo)注模塊、數(shù)據(jù)增強模塊采用順序化循環(huán)的方式對實體識別模塊中的命名實體識別模型繼續(xù)訓(xùn)練并對數(shù)據(jù)進行標(biāo)注和增強。訓(xùn)練后的命名實體識別模塊對各個數(shù)據(jù)源的文本進行命名實體識別的過程。本章重點對部門識別樣本、人員識別樣本、標(biāo)準(zhǔn)識別樣本來闡述實體識別的過程。
1.2.1 組織識別樣本
業(yè)務(wù)組織部門識別樣本是利用實體識別技術(shù)路線對業(yè)務(wù)組織部門信息識別的具體應(yīng)用。業(yè)務(wù)組織部門識別體系包括業(yè)務(wù)組織部門詞典數(shù)據(jù)集、業(yè)務(wù)組織部門關(guān)聯(lián)數(shù)據(jù)集、業(yè)務(wù)組織部門屬性集、測試數(shù)據(jù)源、業(yè)務(wù)組織部門主題詞識別模塊、業(yè)務(wù)組織部門數(shù)據(jù)標(biāo)注模塊、業(yè)務(wù)組織部門實體識別模塊,業(yè)務(wù)組織部門實體增強模塊、業(yè)務(wù)組織部門屬性關(guān)聯(lián)模塊等組成。
具體實現(xiàn)過程:利用業(yè)務(wù)組織部門主題詞識別模塊,從數(shù)據(jù)源中提取與業(yè)務(wù)組織部門相關(guān)的主題詞;通過業(yè)務(wù)組織部門增強模塊和實體識別模塊在詞典數(shù)據(jù)集、關(guān)聯(lián)數(shù)據(jù)集、屬性集對識別到的信息進一步加強和規(guī)范化;通過業(yè)務(wù)組織部門數(shù)據(jù)標(biāo)注模塊對被監(jiān)測數(shù)據(jù)源進行實體標(biāo)簽標(biāo)注,并建立索引;根據(jù)檢測結(jié)果和基礎(chǔ)數(shù)據(jù)集進行反饋和補充,進一步完善業(yè)務(wù)組織部門基礎(chǔ)數(shù)據(jù)的過程。
針對不同的測試樣本進行往復(fù)循環(huán)的過程成為業(yè)務(wù)組織部門識別算法的訓(xùn)練和完善的過程。
1.2.2 人員識別樣本
人員識別樣本是利用人名識別技術(shù)路線對不同數(shù)據(jù)源進行行業(yè)人員的識別過程。人員識別體系由行業(yè)人員基礎(chǔ)數(shù)據(jù)集、人員屬性數(shù)據(jù)集、測試數(shù)據(jù)源、基礎(chǔ)人名識別模塊、人員數(shù)據(jù)標(biāo)注模塊、人員屬性實體識別模塊,人員實體增強模塊、人員屬性關(guān)聯(lián)模塊等組成。
具體實現(xiàn)過程:利用基礎(chǔ)人名識別模塊從數(shù)據(jù)源中提取出疑似人名的清單;通過人名停用詞進行疑似人名的清洗。接下來通過疑似人名與人員實體庫進行匹配,滿足條件詞匯,根據(jù)人員屬性實體識別模塊和人員實體增強模塊給疑似人名創(chuàng)建人員實體對象。通過被檢數(shù)據(jù)源中匹配對應(yīng)的屬性信息,對人員實體對象進一步規(guī)范化;通過人員數(shù)據(jù)標(biāo)注模塊對人員信息和被監(jiān)測數(shù)據(jù)源進行實體標(biāo)簽標(biāo)注,并建立索引;經(jīng)過人工審核后把新識別的人員基礎(chǔ)數(shù)據(jù)對基礎(chǔ)數(shù)據(jù)集進行反饋和補充。
針對不同的測試樣本進行往復(fù)循環(huán)的過程成為識別算法的訓(xùn)練和完善的過程。
1.2.3 標(biāo)準(zhǔn)識別樣本
標(biāo)準(zhǔn)識別樣本是利用上下游標(biāo)準(zhǔn)固有類別數(shù)據(jù)集為基礎(chǔ),從不同數(shù)據(jù)源進行標(biāo)準(zhǔn)信息提取、識別和融合的過程。專家識別體系包括行業(yè)標(biāo)準(zhǔn)基礎(chǔ)數(shù)據(jù)集、行業(yè)企業(yè)基礎(chǔ)數(shù)據(jù)集、標(biāo)準(zhǔn)屬性數(shù)據(jù)集、測試數(shù)據(jù)源、標(biāo)準(zhǔn)主題詞識別模塊、標(biāo)準(zhǔn)數(shù)據(jù)標(biāo)注模塊、標(biāo)準(zhǔn)屬性實體識別模塊,標(biāo)準(zhǔn)實體增強模塊、標(biāo)準(zhǔn)屬性關(guān)聯(lián)模塊等組成。
針對不同的測試樣本進行往復(fù)循環(huán)的過程成為標(biāo)準(zhǔn)識別算法的訓(xùn)練和完善的過程。
1.2.4 其它實體識別樣本
其它實體還包括辦公協(xié)同實體識別、經(jīng)營管理實體識別、安全生產(chǎn)實體識別、共享服務(wù)實體識別、移動支付實體識別、機關(guān)部室實體識別等內(nèi)容。在此不再贅述。
1.3 算法介紹
1.3.1 分詞、詞性標(biāo)注和關(guān)鍵詞抽取算法
(1)分詞算法。分詞主要是基于統(tǒng)計詞典,構(gòu)造一個前綴詞典;然后利用前綴詞典對輸入句子進行切分,得到所有的切分可能,根據(jù)切分位置,構(gòu)造一個有向無環(huán)圖;通過動態(tài)規(guī)劃算法,計算得到最大概率路徑,也就得到了最終的切分形式。
(2)詞性標(biāo)注算法。分詞的詞性標(biāo)注過程非常類似于分詞流程,同時進行分詞和詞性標(biāo)注。
(3)關(guān)鍵詞抽取算法。分詞系統(tǒng)中實現(xiàn)了兩種關(guān)鍵詞抽取算法,分別是基于TF-IDF關(guān)鍵詞抽取算法和基于TextRank關(guān)鍵詞抽取算法,兩類算法均是無監(jiān)督學(xué)習(xí)的算法。
(4)HMM模型。由于處理的文本大部分為中文文本,基于漢字成詞能力的HMM模型識別特別適合本平臺的業(yè)務(wù)場景。利用HMM模型進行分詞,主要是將分詞問題視為一個序列標(biāo)注(sequencelabeling)問題。其中,句子為觀測序列,分詞結(jié)果為狀態(tài)序列。首先通過語料訓(xùn)練出HMM相關(guān)的模型,然后利用Viterbi算法進行求解,最終得到最優(yōu)的狀態(tài)序列,然后再根據(jù)狀態(tài)序列,輸出分詞結(jié)果。
1.3.2 貝葉斯算法
貝葉斯分類算法是統(tǒng)計學(xué)的一種分類方法,它是一類利用概率統(tǒng)計知識進行分類的算法。該算法能運用到大型數(shù)據(jù)庫中,而且方法簡單、分類準(zhǔn)確率高、速度快。
由于貝葉斯定理假設(shè)一個屬性值對給定類的影響?yīng)毩⒂谄渌鼘傩缘闹担思僭O(shè)在實際情況中經(jīng)常是不成立的,因此其分類準(zhǔn)確率可能會下降。為此,就衍生出許多降低獨立性假設(shè)的貝葉斯分類算法,如TAN(tree augmented Bayes network)算法。
2 知識圖譜
2.1 技術(shù)路線
知識圖譜基于語義解析的問答技術(shù),是一種管道式的方法。首先需要對用戶的查詢問句進行語義解析,獲取查詢對象、對象約束與用戶意圖,而后根據(jù)查詢對象、約束之間的關(guān)聯(lián)關(guān)系形成查詢圖,最后使用查詢圖與知識圖譜進行匹配和推理,獲取并推送給用戶所需要的知識。
其中涉及的關(guān)鍵技術(shù)有:命名實體識別(用于獲取查詢對象以及約束對象的字符串表達)、實體鏈接、語義解析、圖匹配算法(用于將查詢圖與知識圖譜進行匹配,獲取最終答案實體)、文本生成算法(以答案實體、知識圖譜與用戶問句作為條件,生成易于理解的文本返回給用戶)[2]。
2.2 業(yè)務(wù)建設(shè)
針對多數(shù)據(jù)源的融合應(yīng)用,構(gòu)建基于多數(shù)據(jù)源的知識圖譜。首先,對不同來源的數(shù)據(jù)構(gòu)建相應(yīng)的本地庫,并將不同的本地庫通過數(shù)據(jù)融合映射到全局本地庫。然后,利用實體對齊和實體方法進行知識獲取和融合。最后搭建知識圖譜應(yīng)用平臺,提供查詢和統(tǒng)計等操作。
2.2.1 知識圖譜構(gòu)建過程
知識圖譜的構(gòu)建分為兩步:知識圖譜本體層構(gòu)建和實體層的學(xué)習(xí)。其中,本體層構(gòu)建包括主題詞抽取、同義詞抽取、概念抽取、分類關(guān)系抽取、公理和規(guī)則學(xué)習(xí);實體層學(xué)習(xí)包括實體學(xué)習(xí)、實體數(shù)據(jù)填充、實體對齊和實體等。
知識圖譜的構(gòu)建方法包括自上向下和自底向上兩種。自上向下的方法指先構(gòu)建知識圖譜的本體,即從煤炭行業(yè)領(lǐng)域、煤炭行業(yè)詞典及其它高質(zhì)量的數(shù)據(jù)源中,提取本體和模式信息,添加到知識庫中;自底向上方法指從實體層開始,借助一定的技術(shù)手段,對實體進展歸納組織,實體對齊和實體等,并提取出具有較高執(zhí)行度的新模式,經(jīng)人工審核后,補充到知識圖譜中。
2.2.2 多數(shù)據(jù)源融合的知識圖譜構(gòu)建
為實現(xiàn)各類知識圖譜服務(wù)支撐的快速查詢,本平臺在融合多種數(shù)據(jù)源的情況下,構(gòu)建了多數(shù)據(jù)源的知識圖譜。首先對不同實體構(gòu)建不同領(lǐng)域的本地庫,然后將不同領(lǐng)域經(jīng)過映射成全局本地庫,接著對各領(lǐng)域的知識庫實施實體對齊過程和實體過程,豐富和擴展構(gòu)造多數(shù)據(jù)融合的知識圖譜。
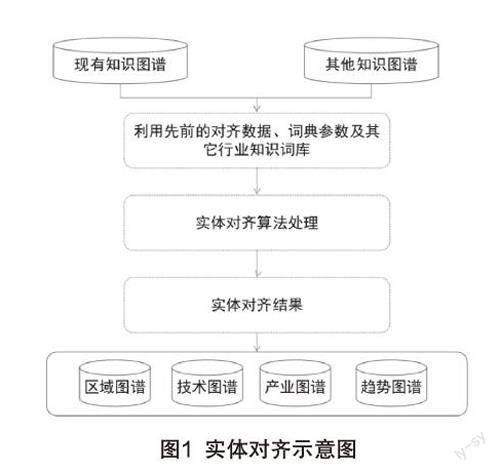
2.2.3 實體對齊
實體對齊,也稱實體匹配或?qū)嶓w解析,是對相同或者不同數(shù)據(jù)集中兩個實體是否指向真實世界同一對象的過程。實體對齊如圖1所示。
本系統(tǒng)通過實體對齊,發(fā)現(xiàn)在不同知識庫中的實體名稱,并將這些實體進一步合并,對該實體創(chuàng)建標(biāo)識索引,最終將該實體添加到對應(yīng)的知識圖譜的過程。
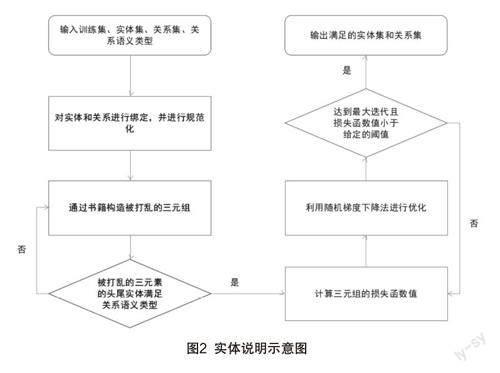
2.2.4 實體說明
實體是指對于從文本中抽取得到的實體對象,將其到知識圖譜中對應(yīng)的正確實體對象的操作。實體說明如圖2所示。
其指導(dǎo)思想是根據(jù)給定三元組的頭(尾)實體和關(guān)系,從知識圖譜激活相關(guān)文本數(shù)據(jù),選出一組候選實體對象,并通過實體預(yù)測算法,計算出正確的尾(頭)實體,并將得到的三元組添加到對應(yīng)的知識圖譜中。
2.3 圖譜應(yīng)用
知識體系統(tǒng)計是指知識體系中結(jié)合具體行業(yè)固有類別標(biāo)簽的分析統(tǒng)計過程。在該過程中,需要依據(jù)行業(yè)固有的類別和標(biāo)簽進行主題詞、屬性詞、相關(guān)詞、場景詞等產(chǎn)生關(guān)聯(lián)和上下拓撲關(guān)系,從而通過行業(yè)固有類別或者標(biāo)簽,根據(jù)知識體系,能通過檢索和識別、拓撲,提取出針對行業(yè)有實際經(jīng)濟效益價值的一系列有效信息。
2.3.1 區(qū)域圖譜
區(qū)域圖譜指能源企業(yè)在地域上的拓撲關(guān)系化。本過程需要關(guān)聯(lián)能源產(chǎn)業(yè)鏈的上下游企業(yè)關(guān)系、能源企業(yè)之間的隸屬歸屬關(guān)系、能源企業(yè)在地域上分布關(guān)系等。輸出成果為在全球地圖上呈現(xiàn)不同地域時間的地區(qū)分布圖譜。
地域信息統(tǒng)計是指把知識體系中的對象信息按照地域信息進行統(tǒng)計的過程。地域范圍從大到小分別包括世界級、洲際級、國家級、行政區(qū)域級、城市級等幾個級別,按地區(qū)進行關(guān)聯(lián)展示。
2.3.2 技術(shù)信息統(tǒng)計
針對技術(shù)類別的屬性指標(biāo)、標(biāo)簽指標(biāo),結(jié)合能源行業(yè)業(yè)務(wù)知識相關(guān)性,按照業(yè)務(wù)權(quán)重形成行業(yè)標(biāo)簽圖譜。圖譜對應(yīng)標(biāo)簽可以關(guān)聯(lián)到企業(yè)、產(chǎn)品、技術(shù)、文獻、組織等一系列的相關(guān)信息。本知識圖譜支持重的上行下鉆動作。
技術(shù)信息統(tǒng)計是知識體系依據(jù)產(chǎn)品標(biāo)簽級行業(yè)固有類別進行統(tǒng)計的過程。本系統(tǒng)統(tǒng)計的對象為企業(yè),可以通過產(chǎn)品類別、固有行業(yè)標(biāo)簽等信息順利統(tǒng)計出相關(guān)聯(lián)的企業(yè)信息。然后再通過企業(yè)信息關(guān)聯(lián)到企業(yè)的其他屬性信息。
2.3.3 趨勢分析統(tǒng)計
趨勢分析圖譜通過對狀態(tài)監(jiān)測、控制系統(tǒng)、回歸分析等一系列指標(biāo)與新聞、論文、專利等發(fā)布時間進行關(guān)聯(lián),從而分析不同指標(biāo)下新聞、論文、專利等的活躍趨勢過程。
趨勢分析統(tǒng)計過程是依據(jù)行業(yè)相關(guān)知識成果體系進行時間范圍統(tǒng)計的過程。統(tǒng)計對象包括新聞、論文、專利等知識成果,統(tǒng)計維度為時間,統(tǒng)計的指標(biāo)為時間段內(nèi)的成果數(shù)目。
2.4 核心算法介紹
2.4.1 三元組構(gòu)建算法
基于知識圖譜的問答系統(tǒng)很難直接回答自然文本狀態(tài)的問題,所以我們要把問題轉(zhuǎn)化為一定的問題模板集。確定了候選的問題模板集,然后就可以利用原始問句,從中找到語義最接近的具體模板(通過最小編輯距離)。再對于具體的問題模板,人工設(shè)定對應(yīng)的具體回答方式,就能夠保證回答與問題在語義上的協(xié)調(diào)性。
2.4.2 關(guān)系模型到本體模型映射算法
關(guān)系數(shù)據(jù)模式到本體映射關(guān)系的建立,是一類典型的模式匹配問題。所謂模式匹配問題,指的是在不同的數(shù)據(jù)模式中找出語義相同或相似的元素對,并構(gòu)造映射關(guān)系的一類問題,即建立數(shù)據(jù)庫表到本體中類的映射以及數(shù)據(jù)庫表中字段到本體類的屬性的映射。
2.4.3 實體對齊算法
(1)實體消歧。含義:實體消歧的本質(zhì)在于一個詞有很多可能的意思,也就是在不同的上下文中所表達的含義不太一樣。例子:“蘋果”實體描述,“我的手機是蘋果”和“我喜歡吃蘋果”這兩個句子中的“蘋果”代表的含義是不一樣的。前者代表是手機、后者代表是水果[3]。
(2)共指消歧。共指消歧,又稱指代消解。由于自然語言充滿歧義,必須使用多種信號和知識來消除歧義。需要基于對周圍世界的了解才能明白這些指代,而這種知識很難編碼到計算機中。
2.4.4 實體映射算法-rans系列算法
知識圖譜的表示學(xué)習(xí)即將知識圖譜構(gòu)建成一個(頭實體,關(guān)系,尾實體)的三元組形式,通過目標(biāo)函數(shù)將實體和關(guān)系分別以低維的向量來表示。Trans方法主要有TransE、TransH、TransR、CtransR、TransD、TransA以及TransG等。
3 自然語言處理工具
3.1 可視化工具描述
本系統(tǒng)采用的可視化工具是通過以WPS插件形式,通過提取結(jié)構(gòu)化數(shù)據(jù)庫數(shù)據(jù)、本地非結(jié)構(gòu)化的文本文件數(shù)據(jù),通過插件面板形式把數(shù)據(jù)處理中涉及的各個步驟均通過功能按鈕或面板形式呈現(xiàn)給客戶。
3.2 數(shù)據(jù)編輯輔助工具
WPS文字端工具,包括文本導(dǎo)航目錄(左側(cè)面板),為用戶提供結(jié)構(gòu)化的庫表數(shù)據(jù)和非結(jié)構(gòu)化的本地數(shù)據(jù)。無論是庫表數(shù)據(jù)還是本地數(shù)據(jù),均可以通過WPS文字端進行呈現(xiàn)和展示,并且允許對呈現(xiàn)的數(shù)據(jù)進行文本編輯和字段編輯。編輯完成后根據(jù)用戶需要把內(nèi)容信息存儲到原始文件/目標(biāo)地址中。
本工具還提供了針對語義分析、標(biāo)簽算法中基礎(chǔ)詞庫的編輯功能。針對圖片、PDF、音頻等功能的自動識別工具。協(xié)助用戶對非常規(guī)的數(shù)據(jù)源進行文本處理轉(zhuǎn)化。
4 結(jié) 語
本文闡述了分析系統(tǒng)的數(shù)據(jù)源情況、數(shù)據(jù)中臺的核心業(yè)務(wù)、用戶服務(wù)的業(yè)務(wù)應(yīng)用對象及數(shù)據(jù)中臺中涉及的可視化工具。通過打造工業(yè)企業(yè)的數(shù)據(jù)中臺服務(wù),并構(gòu)建符合業(yè)務(wù)應(yīng)用的數(shù)據(jù)和服務(wù)支撐,既對大數(shù)據(jù)采集系統(tǒng)的應(yīng)用和能力進行驗證,也被智能問答平臺及其他業(yè)務(wù)系統(tǒng)所驗證。通過此類迭代式相互促進,可大幅度提升工業(yè)企業(yè)對大數(shù)據(jù)中臺建設(shè)的參與和認知程度,從而使數(shù)據(jù)中臺的理念、機制和成果更好地服務(wù)于工業(yè)企業(yè)。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
體育時空(2016年8期)2016-10-25 18:02:39
現(xiàn)代經(jīng)濟信息(2016年19期)2016-10-20 17:46:29
中國科技博覽(2016年18期)2016-10-19 10:30:11
中國市場(2016年36期)2016-10-19 04:31:23
商場現(xiàn)代化(2016年22期)2016-10-18 19:11:00
科技視界(2016年22期)2016-10-18 14:37:36
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
