基于雙模型識別的知識圖譜可視化建模仿真
2023-03-29 13:38:42秦鵬,唐忠
計算機仿真 2023年2期
秦 鵬,唐 忠
(1. 桂林學院理工學院,廣西 桂林 541006;2. 廣西醫科大學信息與管理學院,廣西 南寧 530021)
1 引言
計算機技術與信息技術水平飛速提升,網絡應用呈多元化發展。在互聯網的日益普及下,網絡逐漸演變成信息與知識的主要獲取渠道,但與日俱增的數據量、越來越復雜的內容與形式,都不斷加劇著目標信息的尋找難度。為更便捷地找到目標信息,語義網、萬維網等[1,2]搜索引擎層出不窮,其中,由語義網衍生出的知識圖譜[3]最具研究價值與應用價值。知識圖譜通過字符串符號映射,根據語義關系連接物理世界的實體與概念,形成有向或無向的語義網絡。此種知識表達模式不僅可以實現知識間的智能推理,而且能為用戶提供與檢索詞對應的實體結構化信息。
隨著大數據時代的到來,知識圖譜更是在諸多關鍵領域中發揮著重要作用,建構方案也成為熱點研究課題。例如:電力領域中,郭榕等人[4]利用模式層、數據層等部分,架構出電網故障處置知識圖譜,該方法通過綜合運用TextCNN、LR-CNN、BiGRU-Attention等多種深度學習模型,有效解決了詞錯分、候選詞沖突等問題,有效性與應用性較為理想;教育領域中,李永卉等人[5]利用Protégé軟件,將本體轉換為資源描述框架下的三元組數據,把映射至圖數據結構上的數據儲存至Neo4j圖數據庫中,得到詩詞知識圖譜,該方法充分發揮出檢索、分析、應用等功能作用,有助于知識圖譜得到進一步開發與探索。
可視化技術[6]的發展,使可視化知識圖譜被廣泛應用且優勢顯著,不僅能提升數據的直觀性,而且便于查詢等操作。因此,基于文獻方法優勢,采用深度學習技術,設計一種可視化知識圖譜建構模型。該方法的研究重點如下:
1)jieba分詞工具經動態規劃找出最大詞頻組合,有助于實現高準確性與高效率性的知識圖譜構建;
2)文本分類模型中注意力機制的加權屬性,有助于提高全局信息的處理效果;
3)以深度學習的BiLSTM-CRF算法與BiGRU-Attention模型為基礎,設計知識實體識別模型與實體關系識別模型,能更好地聯立詞向量與語義之間的聯系,更精準地提取出實體關系,為知識圖譜建構奠定基礎。
2 可視化知識圖譜建構模型整體架構
預處理待建圖譜的數據集,利用知識實體識別與實體關系識別方法,結合開源的Neo4j圖數據庫[7],建立可視化知識圖譜建構模型,如圖1所示。該模型的四個主要部分是:數據源層、預處理層、識別層、建構層。
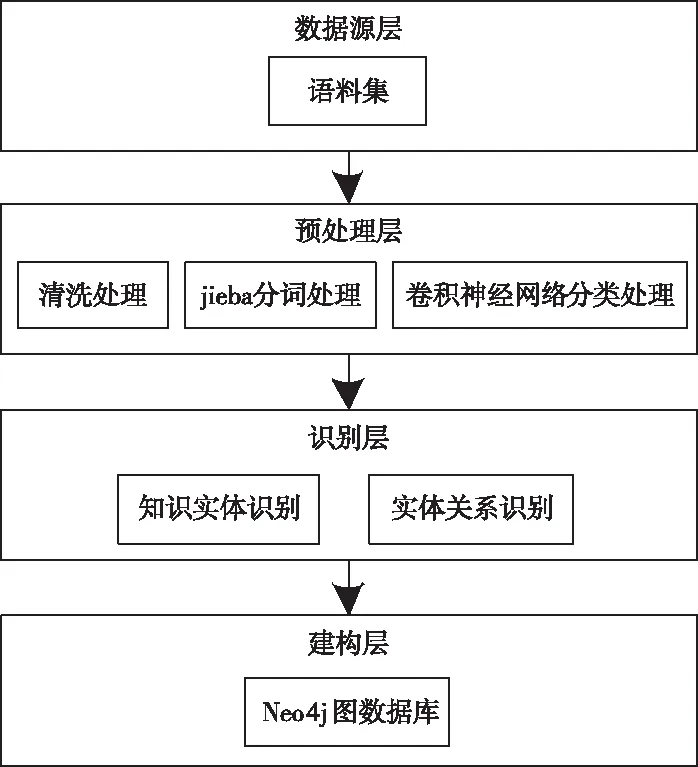
圖1 可視化知識圖譜建構模型
2.1 知識圖譜數據預處理
針對數據集中存在缺失、冗余等問題的數據類型,采用清洗、分詞、分類等處理手段,減少無效信息,為后續操作提供高質量數據集合,提升知識圖譜建構效率。預處理方法的實現流程描述如下:
1)清洗:根據停用詞表[8],直接去除符號、表情等無效字符串;對于信息項空白等缺失類數據,如果不能進行有效填充則去除;對于超文本標記語言標簽、網絡地址等冗余類信息,直接去除。
2)分詞:該階段的處理結果決定知識圖譜的實用性與可靠性,采用jieba0.42.1版本中文分詞工具[9]。經前綴詞典詞圖掃描輸入的句子,由隱馬爾可夫模型[10]進行識別,通過維特比算法的動態規劃計算,得到最優狀態序列,完成分詞處理。
假設t、t-1、t+1時刻下詞i與詞o的狀態分別是it、ot、it-1、ot-1、it+1、ot+1,兩詞的初始狀態與結束狀態分別是i0、o0、ite、ote,則利用下列隱馬爾可夫模型識別數據
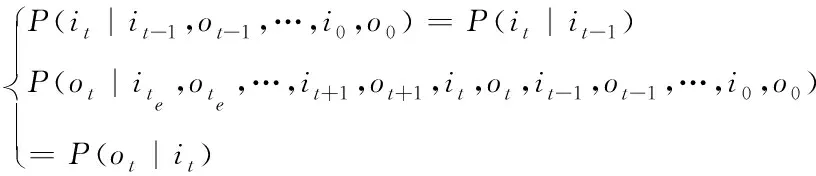
(1)
其中,P(·)表示詞當前狀態的受影響指數;{it-1,ot-1,…,i0,o0}表示詞i與詞o的歷史狀態;{ite,ote,…,it+1,ot+1,it,ot,it-1,ot-1,…,i0,o0}表示兩個詞從初始到結束的全部狀態。
通過維特比算法動態規劃計算識別模型,查找出最優狀態序列。已知詞i、o、ι、j,若t時刻下詞i的單路徑集合是{i1,…,it},則該集合中的最大概率求解公式如下所示:
ιt(i)=max{i1,…,it}P(it-1,ot-1,…,i0,o0|λ)
(2)
其中,λ表示任意詞的任意狀態。
由此推導出詞ι的遞推公式
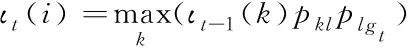
(3)
其中,k、l表示詞的兩種狀態,pkl表示兩狀態間的轉移概率;g表示詞的觀察狀態,plgt表示t時刻下詞狀態從l狀態轉變為觀察狀態的概率。
針對t時刻下詞i的單路徑集合,利用下列公式得出詞頻最大的前n個詞
jt(i)=arg max(ιt-1(k)pklplgt)
(4)
則t+1時刻下詞i的動態規劃結果如下所示
i′t+1=arg max(ιt(i))=jt+2(i)
(5)
經整合,得到由n個詞構成的分詞序列表達形式,如下所示
I=(i′1,i′2,…,i′n)
(6)
3)分類:基于深度學習的卷積神經網絡[11],構建分類模型。分類流程如下所述:
①輸入層:輸入經過分詞處理的數據;
②卷積層:假設句子m中的詞τ經嵌入式表示法[12]處理后,得到詞向量xmτ,通過雙向循環神經網絡[13],取得正反方向的兩種特征編碼h′mτ、h″mτ,如下所示
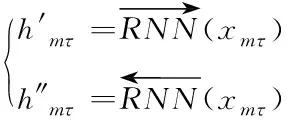
(7)
③池化層:融合注意力機制[14]與雙向門控循環神經網絡[15],構建雙層級網絡層,針對詞與句子對語義影響的權重比,提取特征。根據卷積層得到的特征編碼h′mτ、h″mτ,利用tanh激活函數,取得基于注意力機制的詞向量x′mτ,通過下列sigmoid激活函數求解其權值ωmτ
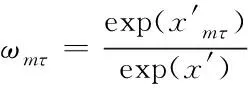
(8)
其中,x′表示融入注意力機制的任意詞向量。
根據所得權重ωmτ與特征編碼h′mτ、h″mτ,生成句子m的雙向特征編碼h′m、h″m,如下所示

(9)
結合sigmoid函數解得的句子權值ωm與網絡的隱藏層信息,得到數據的句向量,如下所示

(10)
④全連接層:拼接所得全部句向量,得到全連接層的輸出項(S′|S″);
⑤softmax函數層:利用該網絡層的二分類模型,完成數據分類
L=softmax(ωS′|S″×(S′|S″)+b)
(11)
其中,ωS′|S″表示輸出項(S′|S″)的權值,b表示偏置項。
2.2 基于深度學習的知識實體識別
在深度學習的BiLSTM-CRF算法[16]中,添加BERT模型[17],建立知識實體識別模型,加強語義關聯度。模型實現知識實體識別的步驟如下所述:
1)輸入層:把預處理過的語料集輸入知識實體識別模型;
2)BERT層:采用BERT模型的自注意力機制函數Att(·)取得字向量,作為下一層的輸入項
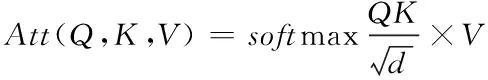
(12)
其中,Q、K、V分別表示字向量矩陣,d指代矩陣Q、K的組合維度。
3)編碼層:經雙向長短時記憶網絡[18]處理,完成數據編碼。假設t時刻下記憶單元c、遺忘門f、輸入門r、輸出門R的輸出結果分別是tanh(ct)、ft、rt、Rt,則通過下列公式得到編碼項ht
ht=ftrtRttanh(ct)
(13)
4)解碼層:該層通過條件隨機場模型[19]實現解碼處理,提升知識實體的識別準確度。若輸入序列與輸出標簽序列各是X、Y,yq、yq+1分別為序列Y中的兩個連續標簽,則知識實體的分值s由下式解得
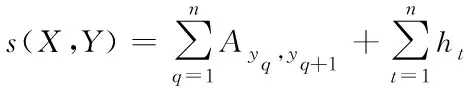
(14)
其中,Ayq,yq+1表示兩標簽間的轉移矩陣。
Y′=argmaxs(X,)
(15)
5)softmax層:利用式(11)分類處理所有實體;
6)輸出層:訓練模型,用取得的最優模型,輸出測試集的知識實體識別結果。
2.3 基于深度學習的實體關系識別
面向BiGRU-Attention模型,引入BERT模型,構建雙注意力機制的實體關系識別模型,在保留關鍵數據的前提下,提高實體關系的識別準確度。實現流程分為以下六個步驟:
1)輸入層:在模型中輸入待識別的知識實體;
2)嵌入層:利用BERT模型構建實體向量,經詞嵌入與位置嵌入處理,傳輸至下一層;
3)編碼層:假設t時刻下雙向門控循環單元網絡的隱藏狀態及權重為ut、ωut,則所得輸出編碼h′t的表達式如下所示
h′t=sigmoid(ωut×ut+b)
(16)
4)機制層:運用雙重注意力機制與式(8)~(10),得到句向量;
5)分類層:利用式(11)分類句向量;
6)輸出層:重復運行第2)~第4)步,訓練模型,針對測試集,得到最優模型輸出的實體關系識別結果。
2.4 知識圖譜可視化實現
為實現知識圖譜可視化,將識別的知識實體與實體關系儲存至Neo4j圖數據庫中,繪制知識圖譜。繪制流程如圖2所示。
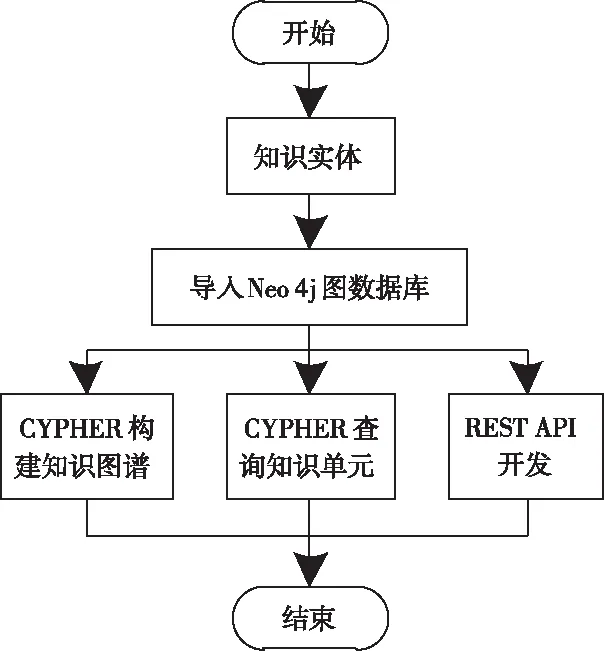
圖2 知識圖譜可視化實現流程圖
3 實驗研究
3.1 數據集與評價指標選取
從百度開放數據集的人工標注數據集合中隨機抽取1000句中文語料,作為知識圖譜的建構對象。將前300句與后700句分別作為模型的測試集與訓練集。通過不斷訓練、更新,得到本文模型中兩個識別模型的最優參數,如表1所示。

表1 建構模型參數設置
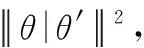
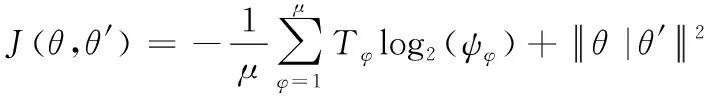
(17)
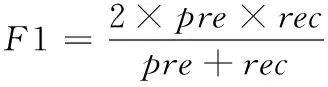
(18)
其中,模型的準確程度與對數損失函數指標呈正相關,J(θ,θ′)值越大,模型建構的知識圖譜越精準;模型的有效程度與F1指標呈正相關,F1值越高,模型性能越好。
3.2 知識實體識別效果分析
圖3為不同方法下損失函數隨迭代次數變化的曲線走勢圖。
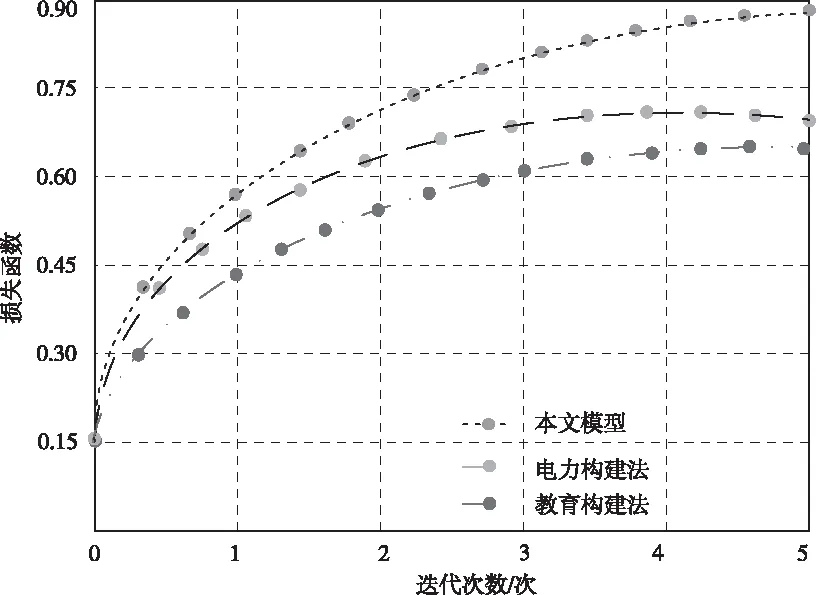
圖3 不同方法的知識實體識別效果評估示意圖
根據圖3可以看出:本文模型的指標值與迭代次數之間存在一定的線性關系,提升幅度較大且速度較快;而對比方法則因領域限制,指標值始終低于本文模型。這說明當迭代至一定次數后,本文模型即可根據預處理后的高質量數據集,通過在BiLSTM-CRF算法中添加BERT模型,精準識得知識實體。
3.3 實體關系識別效果分析
表2為實體關系正確識別數量對比結果,圖4為F1值對比結果。
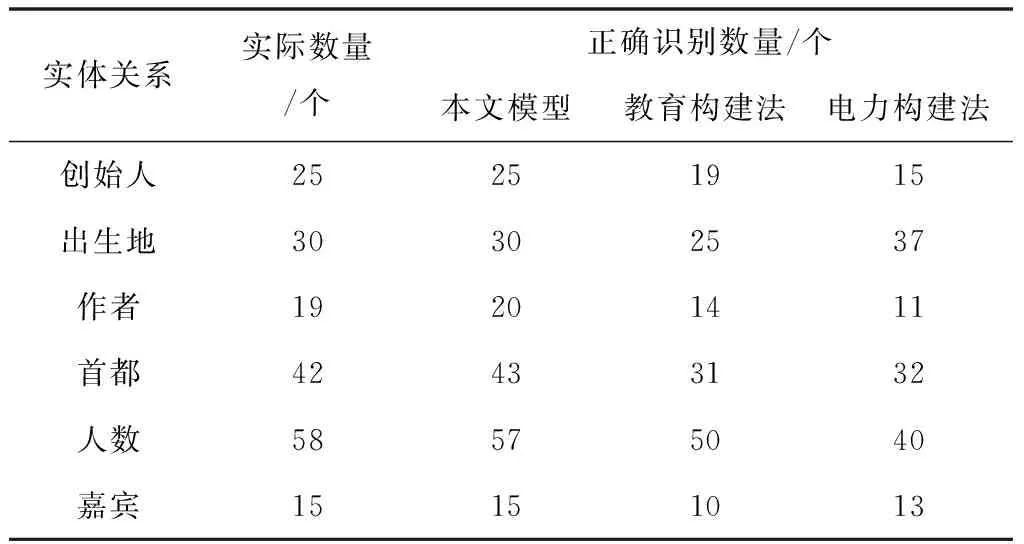
表2 正確識別數量
從表2中的數據可以看出:對于正確識別數量指標,本文模型僅在作者、首都及人數三類關系上,各出現一次錯識別情況,而對比方法則因較強的領域性與針對性,僅識別出極少部分實體間的關系。
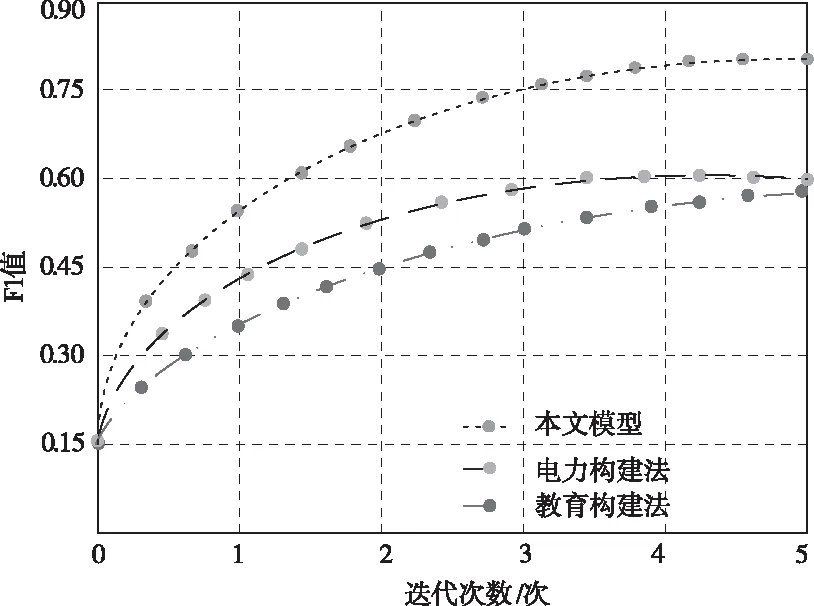
圖4 不同方法的實體關系識別效果評估示意圖
根據圖4可以看出:對于F1值,各方法的數值變化走勢與實體關系識別環節的實驗結果大同小異。以上分析說明,本文通過融合BiGRU-Attention模型與BERT模型,建立雙注意力機制的實體關系識別模型,在保留關鍵數據的前提下,使詞嵌入與位置嵌入處理得以有效開展,令詞向量與語義間的關聯更加緊密,因此,既取得了優越的實體關系識別效果,還拓寬了該模型的應用范圍與發展前景。
4 結論
知識圖譜作為高效的知識表達模型,在人工智能技術的推動下,得以廣泛應用。不論是在個性化推薦領域還是數據挖掘領域中,知識圖譜通過讓計算機學習人的語言交流方式,快速獲取目標知識間的邏輯關系,令反饋給用戶的信息更具智能性。因此,對知識圖譜建構技術展開研究意義重大。盡管本文模型適用性較強,但仍存在以下幾個不足之處:選用的分詞工具對于英文文本不具備良好的適用性,應嘗試采用對中英文均具有較高準確度的分詞工具,打破模型的語料限制;實驗數據量較少,今后應針對大規模數據集建構知識圖譜,探究模型的處理效果;將圖譜后續使用場景對建構模型的影響作為下一階段的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
阿來研究(2021年1期)2021-07-31 07:38:26
新世紀智能(高一語文)(2020年9期)2021-01-04 00:42:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
數學物理學報(2020年2期)2020-06-02 11:29:24
傳媒評論(2019年4期)2019-07-13 05:49:14
幼兒教育·父母孩子版(2016年12期)2017-05-24 13:11:53
