基于數據擴充和特征增強的雷達回波無人機檢測
2023-03-15 02:04:46趙宏宇張志文公茂果呂宇宙
上海航天 2023年1期
關鍵詞:檢測
趙宏宇,張志文,公茂果,武 越,葉 舟,呂宇宙,張 楊
(1.西安電子科技大學 電子工程學院,陜西 西安 710071;2.西安電子科技大學 計算機科學與技術學院,陜西 西安 710071;3.上海航天電子通訊設備研究所,上海 201108)
0 引言
近年來,人工智能技術的不斷突破推動了無人機產業的飛速發展。無人機由于其體積小、能耗低、機動性高等優勢,在航拍測繪、環境監測、應急救援、技術安防、軍事化偵查等民用及軍事領域得到廣泛應用。而我國工業級無人機在民用無人機中的占比達54.3%[1],是民用無人機的應用主體。在推動社會進步的同時,無人機對個人隱私、社會安全、軍事安全等領域構成了嚴重威脅,為此需要發展針對無人機的反制手段。由于無人機較靈活,如何利用現有傳感器實現高效率的無人機目標檢測是一個需要深入研究的課題[2]。
雷達回波數據是一個復序列信號,信號序列中包含大量的冗余信息,傳統方法難以有效挖掘數據內部的信息,從而導致目標檢測的準確率低下。隨著深度神經網絡(Deep Neural Network,DNN)[3]的發展,DNN 可以從復雜數據中學習到高維度的特征信息,因此解決了不同領域中較多的難題,包括視覺識別、語義理解以及語音識別等[4-7]。尤其是深度卷積神經網絡(Convolutional Neural Network,CNN),在目標的分類和識別方面取得了巨大的成功。KRIZHEVSKY 等[8]將DNN 應用在圖像的分類和識別領域中。SZEGEDY 等[9]研究了更深層的卷積神經網絡。卷積網絡可以充分利用圖像的空間信息,提取更加豐富的語義信息,增強目標的特征表示。
針對雷達無人機目標識別精度低、特征提取困難、網絡容易過擬合等問題,構建使用距離-多普勒圖像訓練卷積神經網絡進行目標檢測的方法。首先,利用經典相參累積方法通過積分生成雷達回波的距離-多普勒圖像;隨后,利用卷積神經網絡構建特定于距離-多普勒圖像的目標檢測框架和特征增強模塊實現無人機的準確識別與跟蹤;同時,為解決訓練中可用樣本不足導致的網絡過擬合問題,采用生成對抗模型對距離-多普勒圖像進行數據擴充,以獲得充足的圖像數據訓練性能更加魯棒的卷積神經網絡;最后,通過實驗驗證了提出的方法在雷達回波序列中弱小飛機目標檢測跟蹤數據集上的有效性。
1 研究內容
1.1 相關工作
WANG 等[10]將DNN 應用在雷達波形識別方面。MENDIS 等[11]將DNN 應用在微型無人機識別系統中,提高了檢測的準確率。SEYFIOGLU[12]將DNN 應用在微多普勒分類技術當中。同時還有一系列針對合成孔徑雷達(Synthetic Aperture Radar,SAR)的深度學習方法被眾多學者提出,陳立福等[13]采用MSTAR 中3 類目標數 據集作為源域數據集進行訓練,針對3 類目標識別任務有監督地訓練卷積神經網絡,得到預訓練模型。然后,通過構建與預訓練模型相同的卷積神經網絡,將10 類MSTAR 數據集作為目標域的目標任務,將預訓練模型作為目標域的初始參數,對10 類目標進行微調訓練,效果良好。任碩良等[14]通過遷移VGG16 和ResNet 網絡進行微調訓練形成對比實驗,驗證了遷移學習在SAR 圖像目標識別中的應用,提高了MSTAR 數據集目標識別的準確率。王澤隆等[15]通過電磁仿真得到大量SAR 圖像數據,通過卷積神經網絡模型進行預訓練,通過預訓練權重文件作為初始參數,遷移到實測SAR 圖像數據進行識別,進一步提升識別準確率。王博威等[16]針對SAR 圖像目標識別小樣本的問題,采用正負樣本對策略,對樣本數量進行了擴充后基于深度學習的孿生神經網絡進行目標識別。PAN等[17]采用孿生卷積神經網絡的方法進行小樣本SAR 目標識別。DING 等[18]將CNN 引 入SAR 雷達目標檢測,并進行數據擴充增廣。WANG 等[19]將CNN 引入CFAR 的判別器,利用CNN 替代傳統的CFAR 檢測器,取得了較好的效果。這些研究均是嘗試使用DNN 來解決雷達目標檢測和分類的問題。
1.2 算法整體結構
本文提出的網絡設計主要包括3 個部分,分別為雷達數據的預處理、基于位置感知的卷積神經網絡做目標的檢測識別以及最終的結果處理。具體地,首先利用相參積累對雷達脈沖輸入進行處理,得到距離-多普勒圖像;其次訓練基于位置感知的無人機目標檢測卷積神經網絡,其中為應對訓練樣本稀缺的問題,采用生成對抗網絡對樣本進行擴充;最后根據網絡在距離-多普勒圖像上的檢測結果對物體的實時坐標和速度進行輸出,以實現無人機的識別與跟蹤。整體結構如圖1 所示。
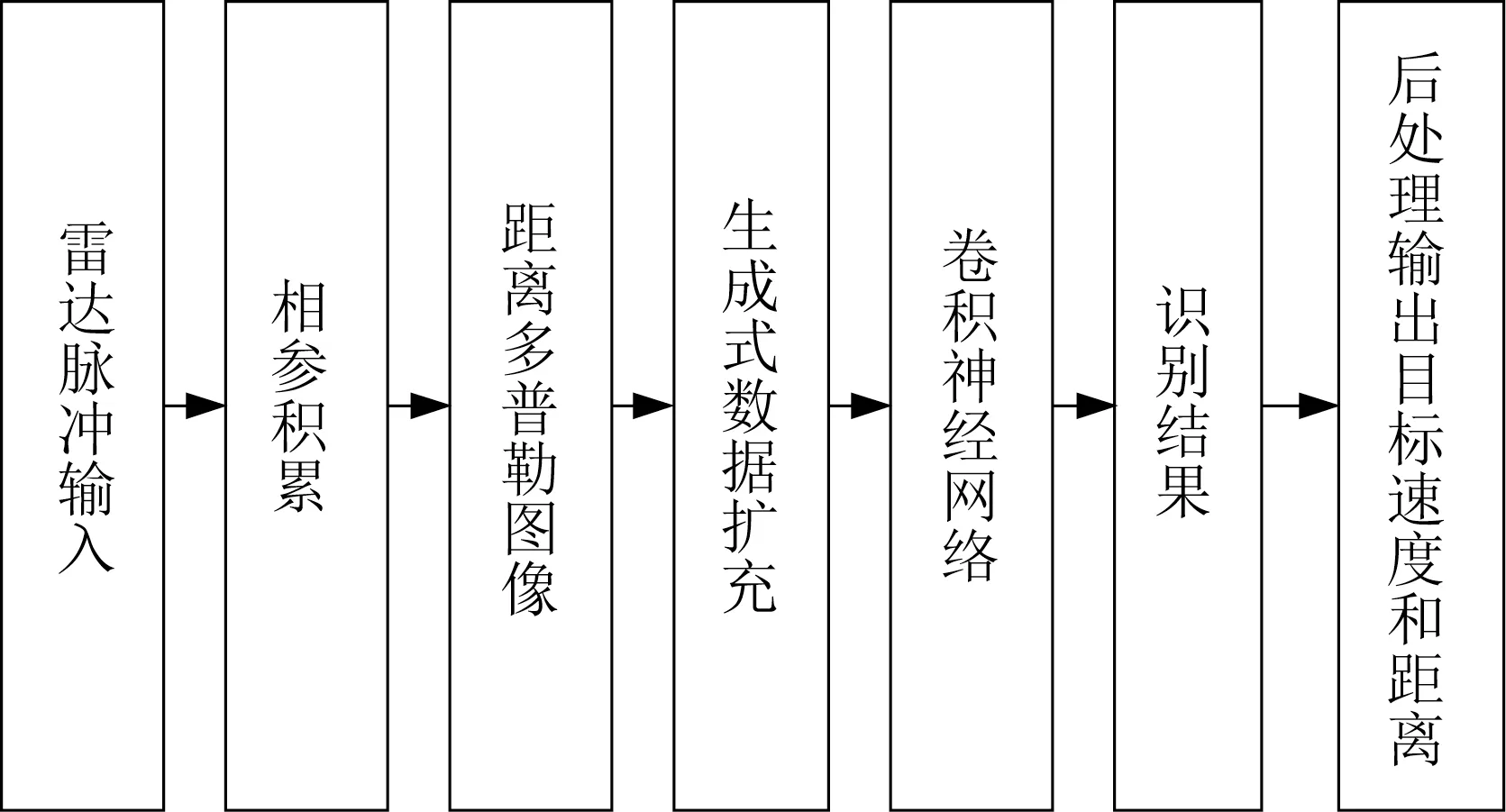
圖1 網絡總體結構Fig.1 Overall frame of the network
1.3 雷達特征分析建模
關于多普勒雷達,最經典的假設檢驗方法是基于Newman-Pearson 準確做判別的恒虛警檢測(Constant False Alarm Rate,CFAR)[20-21],恒虛警檢測首先對輸入的噪聲進行處理后確定門限,將門限與輸入信號進行相比,超過門限則判別為有目標。
由于雷達信號中不僅含有微弱的目標信號,而且包含很強的噪聲,因此在對雷達信號預處理過程中首先需要對目標信號進行放大,增加目標回波信號的信噪比。單純的放大雷達回波信號不僅會放大目標信號,同時也會放大噪聲,使得信噪比下降,因此采用相參累積的方式提高目標信號信噪比。相參累積就是對多個雷達回波進行疊加,由于噪聲隨機,疊加后的結果是信號變強,噪聲由于隨機性強度反而變小,這樣就可以達到提高目標信號與信噪比的目的,通過下述公式可以獲得相參累積后的信號:
式中:xij為第i個脈沖序列壓縮后第j個距離單元的幅值;yj為第j個距離單元慢時間相干積累后的結果;k為脈沖個數;tPR為脈沖重復時間;fd為目標的多普勒頻率。
對于脈沖雷達而言,目標距離由回波脈沖的延遲時間決定,回波脈沖的幅度受到多普勒頻率fd的調制,即回波脈沖的幅度以頻率為fd的正弦規律變化。因此,結合二維的距離-多普勒圖像,可以完成對目標距離和速度的檢測。
對32 個脈沖序列進行相參累積后獲得的距離-多普勒圖像的三維展示如圖2 所示。其中,由于在0 處的脈沖強度過大,因此在后續的數據處理部分會抑制該處過強的幅度值。
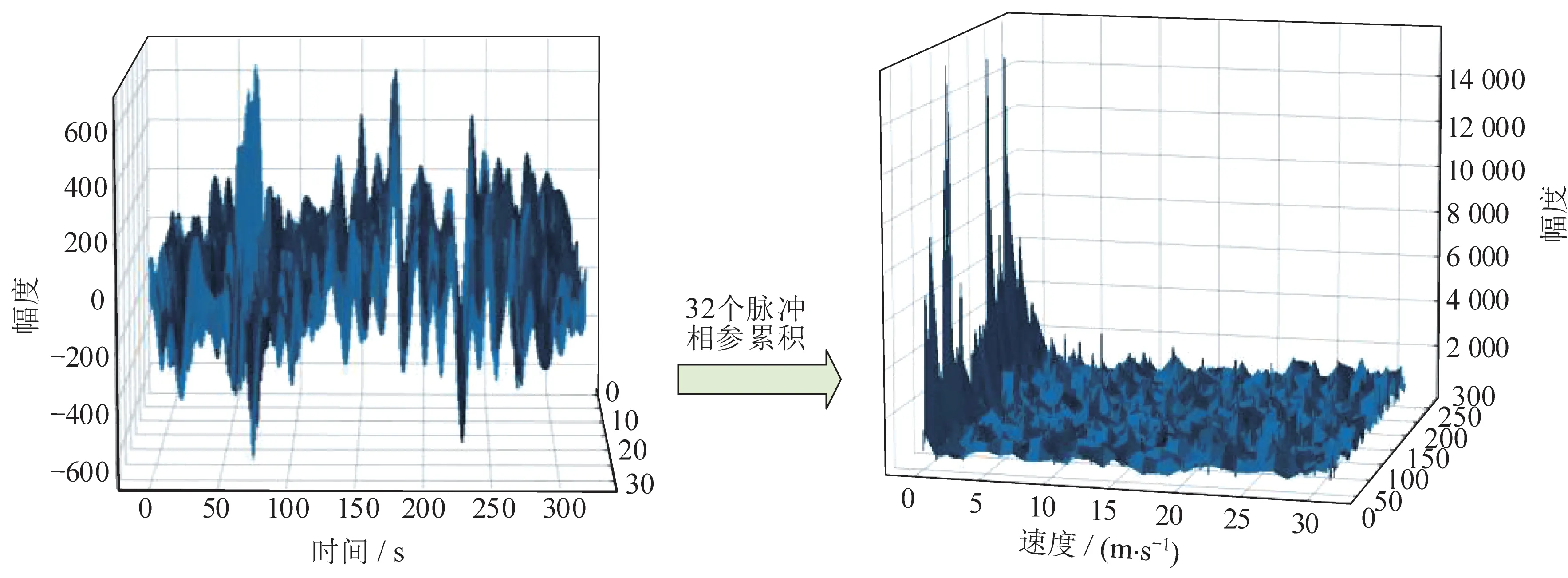
圖2 相參累積Fig.2 Cancellation accumulation
1.4 目標檢測網絡結構
網絡核心結構分為3 個部分:由卷積神經網絡構建的特征提取模塊、由變形卷積構建的特征增強模塊、由全連接層構成的檢測回歸器。網絡的輸入是二維距離-多普勒圖像,通過特征提取骨干網絡獲取輸入圖像的特征圖。由于圖像的2 個維度分別表示目標的不同特性,為進一步增強目標信息,因此采用基于位置感知的特征融合模塊,分別在速度維度和距離維度進行變形卷積,即縱向感知卷積和橫向感知卷積。在得到增強的特征后,將數據送入全連接層進行目標信息的預測,網絡的輸出包含待測目標的坐標信息(x,y)和檢測置信度(Prob),位置感知卷積神經網絡結構如圖3所示。

圖3 位置感知卷積神經網絡結構Fig.3 Structure of the position-aware convolutional neural network
1.4.1 雷達數據特征提取和增強
特征提取網絡的輸入為單通道的距離-多普勒圖像,像素值為信號的幅度值,采用基于殘差連接的DarkNet 作為骨干網絡對目標信號進行特征提取,由于該特定場景下網絡規模較小,為減少額外的計算提高網絡性能,使用了輕量化的MobileNet網絡結構對基準骨干網絡進行了替換,具體過程在實驗部分給出。
輸入的圖像為距離-多普勒圖像,圖像中的H為示波門距離,W為多普勒頻率值,圖像的行表示在同樣的波門距離下的多普勒頻率值,而列則表示同樣多普勒頻率下不同波門距離上信號的強度。在骨干網絡之后額外增加了縱向感知卷積和橫向感知卷積,用于融和同一列和同一行內領域內的特征信息并且對特征圖進行進一步的降采樣。
橫向和縱向感知卷積實現過程可以看作一種特殊的空洞卷積,橫向感知卷積在x軸方向上的空洞率為0,在y軸方向上的空洞率為1,而縱向感知卷積在y軸方向上的空洞率為0,在x軸方向上的空洞率為1。
在3×3 卷積核下的橫向感知卷積的示意圖如圖4 所示,在x軸方向上對鄰域內的特征信息提取,同時在y軸方向上對圖像進行降采樣,縱向感知卷積與其類似,主要用來提取目標信號在縱向領域內的特征,擴大其感受野。感知卷積的計算公式為
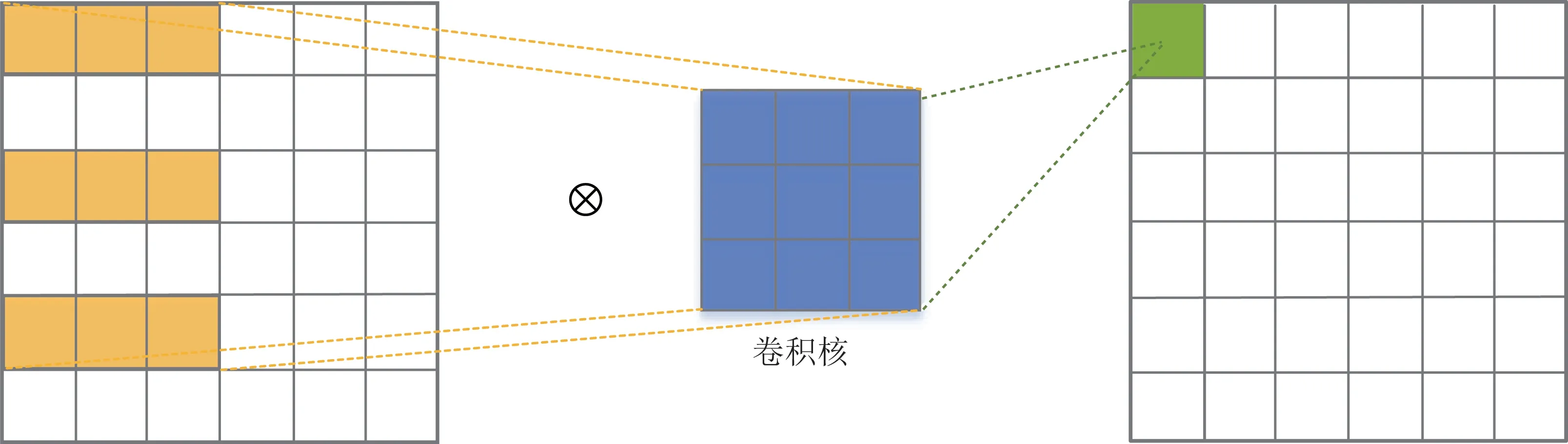
圖4 橫向感知卷積Fig.4 Lateral perceptual convolution
式中:Zin、Zout分別為感知卷積層的輸入與輸出;ωk為當前層的卷積核的參數;k為圖像的信道數。
該橫向和縱向感知模塊既滿足了對特定領域內的目標特征進行提取,并且也達到了降采樣的作用,有利于在不增加計算量的同時提高目標信號的感受野。由于該卷積模塊對輸入圖片進行稀疏采樣,因此不適合級聯多層使用,會導致遠距離獲取信息不具有相關性以及丟失局部信息。
1.4.2 檢測回歸器設計與損失函數
與傳統基于光學圖像的目標檢測網絡不同,對于雷達信號生成的距離-多普勒圖像,圖像中包含的信息維度分別代表了目標的位置和速度。因此在圖像上目標并不是以中心點和長寬的形式存在,而是以點的形式存在,相應的點代表了待檢測的目標。因此,拋棄了傳統目標檢測框架中的錨框結構,設計了針對于特定雷達信號的目標檢測頭,該特征頭將骨干網絡提取到的融合特征作為輸入,輸出是目標在對應位置下的存在概率。
基于網絡特征提取部分得到的特征圖,構建柵格網絡對于目標坐標進行回歸。誤差統計示意圖如圖5 所示,用柵格表示每一個像素,而預測目標的實際位置與柵格左上角頂點的相對差值,這樣得到一個連續預測結果,可更加精確地判斷物體的坐標以及實時的速度。對于損失函數部分,坐標的誤差用均方誤差進行計算,存在物體的置信度用二分類交叉熵,因為此時僅僅考慮存在物體或者不存在物體,為一個二分類的問題。該網絡的損失函數分為兩個部分:1)預測坐標的損失;2)預測柵格是否有物體的損失。預測坐標的損失用預測坐標(xi,yi)與實際目標位置(,)的歐氏距離的平方來度量。總的損失函數如下:
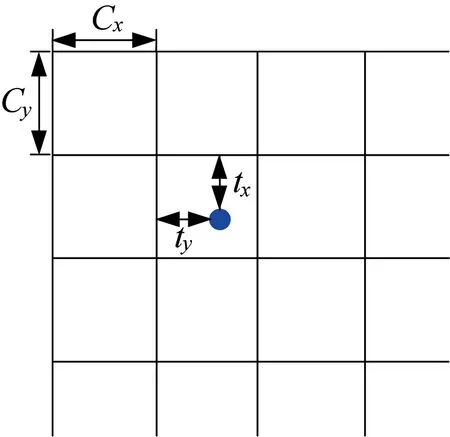
圖5 誤差統計Fig.5 Error statistics
由于樣例中正負樣本不均衡,因此為了讓網絡能更準確地學到物體是否存在的信息,需要將物體不存在時的置信度損失增大,以便于提高準確率。
1.5 少量樣本數據增強
隨著深度學習技術的發展,網絡模型的規模越來越大。基于監督學習的神經網絡模型依賴于高質量的雷達標記數據,然而,獲取高質量的雷達目標檢測數據集比較困難,對數據集的標注工作也會消耗大量的人力和物力,因此有必要研究如何利用少量樣本來訓練可用的網絡模型。
對于上述問題,構建了基于無監督判別模型的數據增強模型進行解決,模型結構如圖6 所示。該生成模型通過無監督訓練可以學習真實樣本的數據分布,并通過判別器來逐漸優化生成模型樣本的質量。通過迭代訓練,可以得到輸出高質量的仿真樣本的生成模型。經過上述的數據增強操作,可以極大地擴充可用的數據樣本。更豐富的數據樣本不僅可以增強網絡的泛化性能,同時也可以避免網絡由于訓練樣本過少導致的過擬合。
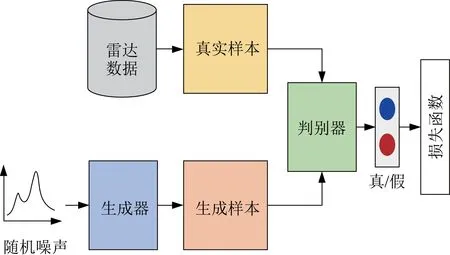
圖6 數據增強流程Fig.6 Flow chart of data augmentation
生成器由4 層轉置卷積網絡級聯而成,判別器由4 層卷積網絡級聯而成。交替訓練判別模型和生成模型,最終會生成逼真的數據,從而擴充樣本。該數據增強網絡的目標函數公式為
式中:D為判別器;G為尾生成器。
該目標函數包含2 個部分,分別是生成器的損失函數和判別器的損失函數。優化判別器的目標函數為
式中:Ex~Pdata(x)logD(x)為判別x屬于真實數據的對數損失函數,最大化該項的目的在于使得判別器能準確預測真實樣本數據;Ez~Pz(z)log(1-D(G(z)))為判別器識別生成假數據的對數損失函數,最大化該項的目的在于使得判別器不會被生成的假數據所欺騙。
式(6)為優化生成模型G的目標函數,最小化該函數即為D(G(z))最大,也即使得樣本越逼真,判別器判別假數據也就越困難。訓練好的模型使用多普勒距離圖像作為輸入。
1.6 結果后處理
輸出結果后,依據多普勒效應進行處理,最終計算出無人機目標的運動速度和到雷達的距離,計算流程如圖7 所示。

圖7 后處理流程Fig.7 Flow chart of post-processing
根據多普勒效應,反射波的頻率和振幅會隨著所碰到的物體的運動狀態發生改變,因此可以利用該效應測量物體的運動速度。可以根據多普勒頻移計算物體運動的徑向速度:
式中:f0為原始發射頻率;v為反射波的行進速度;c為光速。
根據網絡輸出距離-多普勒圖像上檢測點的坐標,可以得到目標點對應的速度坐標和距離坐標;根據速度坐標計算多普勒頻移,可以獲得物體的運動速度;結合采樣數據的距離分辨率,可以獲得物體與雷達之間的距離。
2 實驗
2.1 數據集介紹
本實驗數據集采用公開的雷達回波序列中弱小飛機目標檢測跟蹤數據集[22],該數據集基本信息介紹見表1。
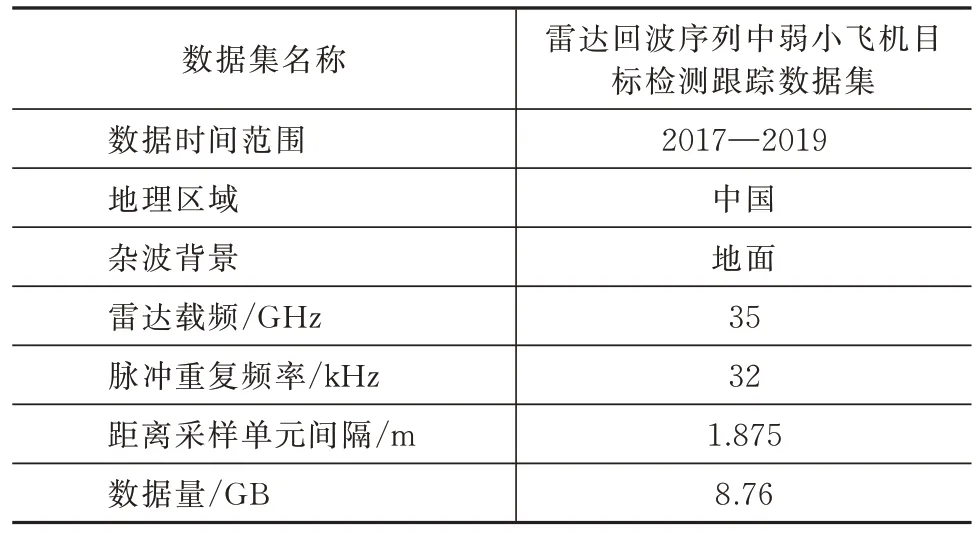
表1 數據集詳情Tab.1 Details of the data set
該數據集包括2 個部分:第1 部分是一定時長內所有脈沖進行脈沖壓縮后形成的連續時間脈沖序列;第2 部分是距離波門文件,采樣數據僅為距離波門后的脈沖序列。連續時間的脈沖序列見表2,距離波門的數據文件如圖8 所示,距離波門的刷新時間為1 ms。
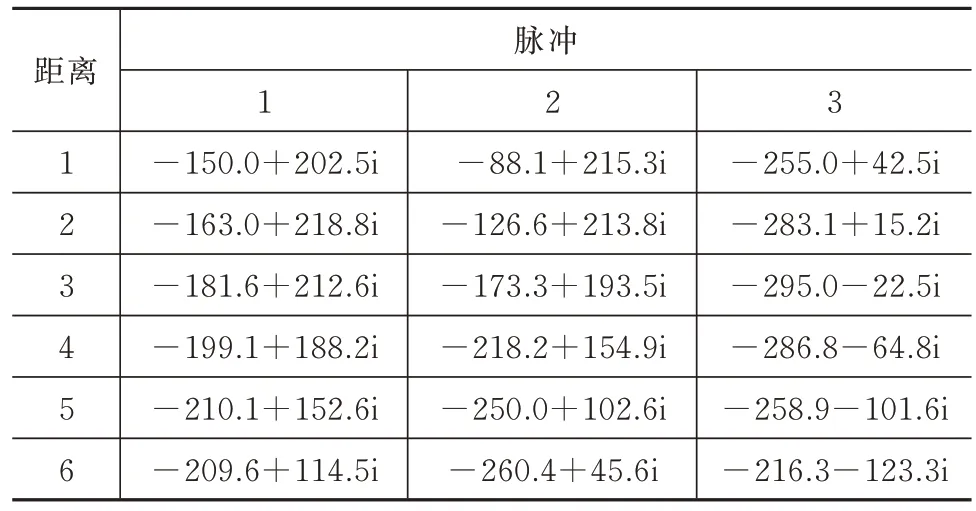
表2 連續時間脈沖序列Tab.2 Continuous time pulse sequences
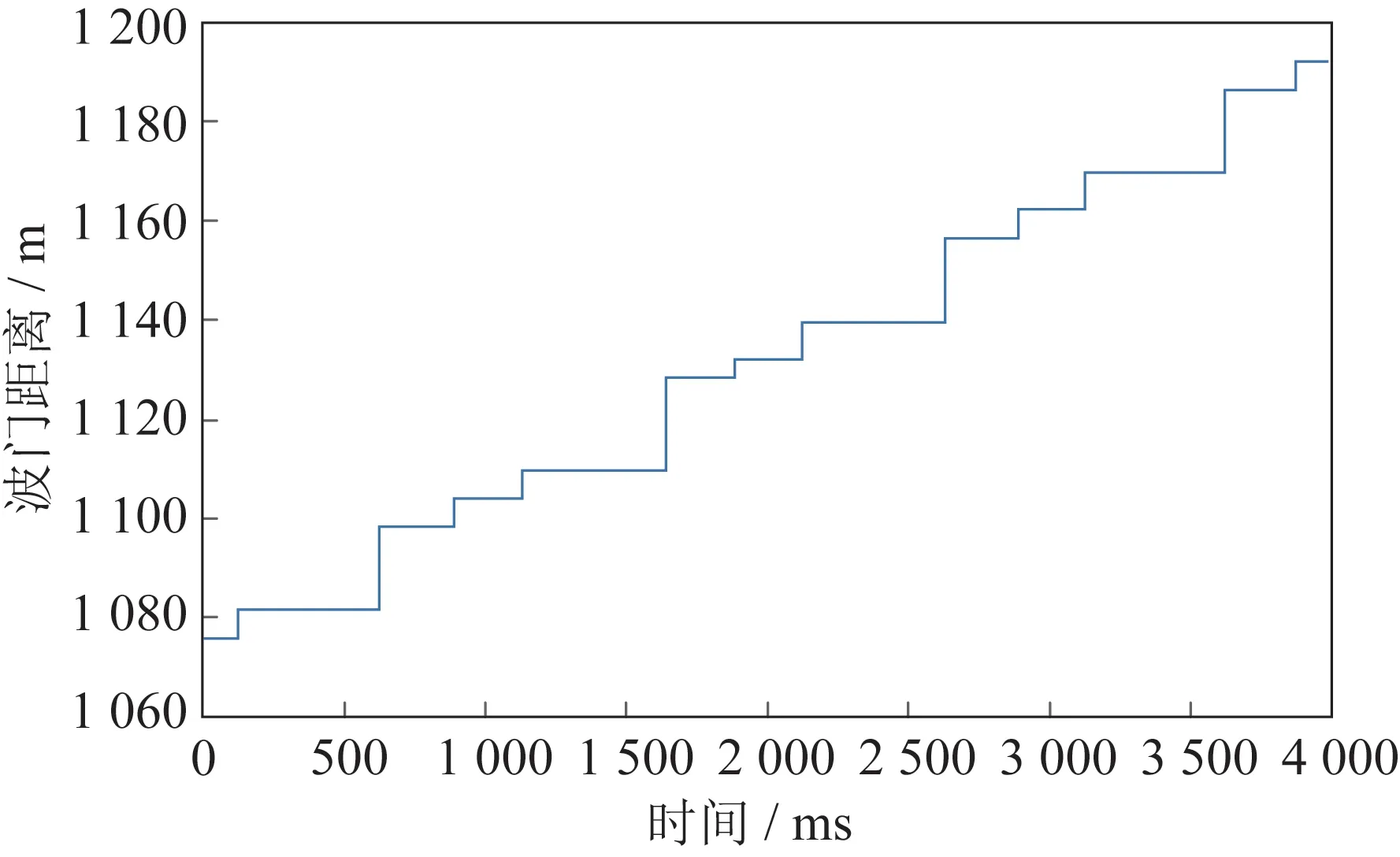
圖8 距離波門Fig.8 Range gate
2.2 實驗結果
2.2.1 原始數據上檢測結果
首先在原始公開數據集上進行測試,實驗中采用DarkNet 作為基準骨干網絡,通過添加提出的檢測頭來進行目標檢測。經過雷達數據預處理得到的連續兩幀距離-多普勒圖像如圖9 所示,距離-多普勒圖像下的檢測結果(綠色代表真值信息,紅色代表檢測結果)如圖10 所示。從圖中可以看出,檢測網絡可以有效地檢出距離-多普勒圖像中的無人機目標。在原數據上進行目標檢測的準確率為82%,召回率為85%,由于原始數據中的目標較少,目標特征比較單一,因此輸入網絡的訓練數據較少,導致最終的檢測精度不高。

圖9 距離-多普勒圖像Fig.9 Range-Doppler images

圖10 基準檢測結果Fig.10 Benchmark results
2.2.2 訓練樣本數據增強
為了減少網絡的過擬合,增加可用的訓練目標樣本,本實驗驗證了提出的基于生成模型的數據增強方法的有效性。在實驗中,使用相同的網絡結構和相同的訓練參數進行測試,相比于基準算法,使用數據增強后,檢測準確率提高了6.5%,可視化結果如圖11 所示。

圖11 數據增強結果Fig.11 Results based on data enhancement
由圖11 可以發現,當部分目標在距離-多普勒圖像上相對靠近的情況下會存在一定程度的漏檢,這可能是由于采用了最大池化層,使得相鄰的目標特征進行了一定程度的融合從而導致后續的檢測出現了漏檢的情況。但從檢測結果來看,該實驗相對基準方法具有更好的檢測精度,說明數據增強有助于提高網絡對于無人機識別的精度。
2.2.3 基于位置感知模塊的檢測結果
本實驗采用1.3 節中圖3 描述的卷積神經網絡模型進行無人機目標識別。在特征提取網絡后接入位置感知模塊,通過該感知模塊增加特征圖中每個像素的感受野,并融合距離多普勒圖像的鄰域信息。本實驗的檢測結果如圖12 所示。

圖12 基于位置感知模塊檢測結果Fig.12 Detection results based on the position perception module
采用特征感知模塊對后,能在一定程度上增強對于相鄰目標的檢測精確度,網絡可以達到91%的準確率和89%的召回率,相對于基準實驗提高了9%的準確率,召回率提高了3%,由此證明設計的特征感知模塊對于無人機目標識別任務的檢測精度具有較好的效果。
2.2.4 特征感知模塊參數消融實驗
為了對提出的特征感知模塊有效性進行驗證,選取不同的空洞率參數進行實驗,實驗結果見表3。從結果中可以看出,空洞率為0 檢測的召回率最低,網絡等效為普通卷積。但是相比表3 中的結果,該實驗說明僅添加額外的卷積層也有助于提升準確率。此外,空洞率設置為1、2 和4 時,會得到更高的召回率結果,也證明了網絡的增益受益于空洞卷積。此外,在空洞率設為1 時達到最高的準確率和召回率。
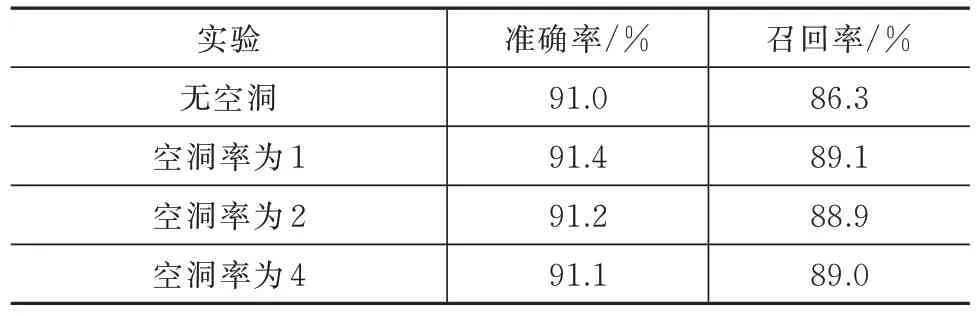
表3 不同空洞率對特征感知模塊的影響Tab.3 Effects of the dilate rate on the feature perception module
2.2.5 基于輕量化骨干網絡的檢測結果
為了測試不同的特征提取骨干網絡對檢測精度的影響,并保證在網絡大小與檢測精度之間進行較好的平衡,以達到在應用場景下對無人機的實時性目標檢測,將采用輕量化的MobileNet 對基于殘差模塊設計的DarkNet 進行替換,保留橫向與縱向感知模塊來對鄰域信息進行提取。
基于輕量化骨干網絡MobileNet 實現的無人機目標識別網絡的檢測結果如圖13 所示,輕量化網絡在使用了位置感知模塊之后仍然可以保持較好的檢測精度和召回率,可視化結果也展示了該方法較魯棒的檢測結果。

圖13 輕量化骨干網絡檢測結果Fig.13 Detection results based on the lightweight backbone network
2.3 不同方法檢測結果對比
4 種實驗檢測精度的對比見表4,添加位置感知模塊的無人機目標識別網絡模型在檢測的準確率和召回率方面都高于其他3 種網絡模型,達到了預期的檢測指標。
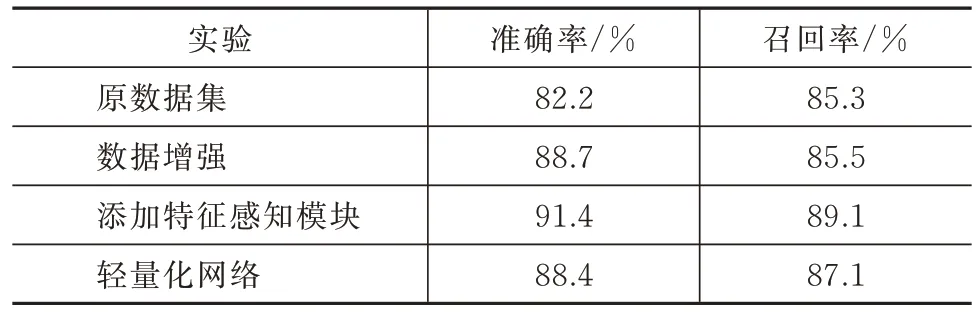
表4 檢測精度和召回率對比Tab.4 Comparison of the detection accuracy and recall rate
2.4 模型參數信息統計
各個模型的相關參數統計見表5。從表中參數可以看出,采用輕量化骨干網絡的情況下模型的參數量和所需算力大幅降低,但是也會帶來檢測精度一定程度上的損失,在算力有限的移動設備端可以采用該方案來實現無人機目標識別,其余3 種實驗在參數量和算力上大致相當,而添加位置感知模塊的識別模型對于無人機目標的檢測精度最高,處理幀率大于50 幀/s,可以滿足實時檢測的需求。
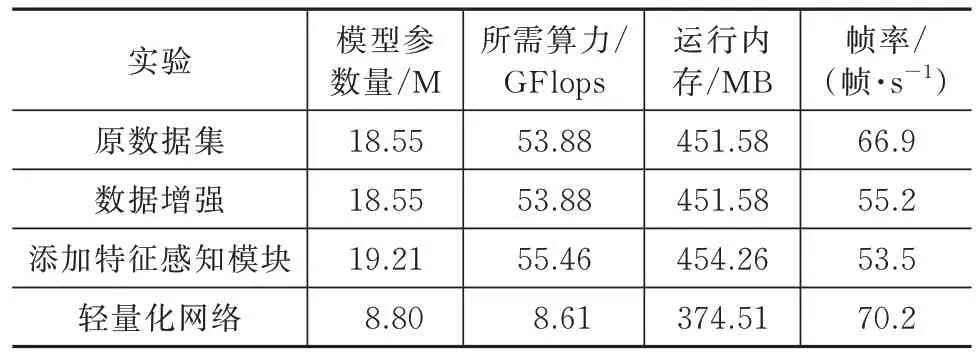
表5 網絡信息統計Tab.5 Statistics of the network information
3 結束語
本文研究了基于卷積神經網絡的無人機檢測技術。針對多普勒雷達回波序列生成距離-多普勒圖像后,利用卷積神經網絡的技術對圖像進行特征提取,從而實現對無人機的檢測。但是本文未考慮實際中的干擾信號與虛假目標,未來計劃在增加虛假目標的情況下對無人機完成更加精準的檢測。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
