融合改進FPN和注意力機制的規范穿戴工作服識別方法
2023-02-14 06:01:46翟永杰張禎琪陳年昊
電力科學與工程 2023年1期
翟永杰,張禎琪,陳年昊
(華北電力大學 自動化系,河北 保定 071003)
0 引言
實現智能化的規范穿戴工作服識別對于電力生產安全的保障具有重要意義。將深度學習技術應用于作業人員規范穿戴工作服的識別,可以減少人工成本的投入,提高工作效率。
受監控圖像像素較低、圖像失真、目標被遮擋等情況影響,一些不規范穿戴情況難以被智能算法準確識別。所以,目前基于圖像識別算法的研究基本都是針對安全帽佩戴[1,2]和輸電線路[3,4],而在作業人員著裝規范性的識別方面尚未有顯著的成果。
文獻[5]提出了基于HOG和HOC提取形狀、顏色特征并結合 SVM 分類器的變電站作業人員服裝規范性識別方法,該方法實現了復雜背景下的著裝規范性識別。相比傳統目標檢測算法,該方法具有較高的識別精度,但依舊有提升空間。
文獻[6]提出了一種基于樣本Q鄰域敏感度的徑向基神經網絡的著裝識別算法。通過優化參數改進傳統的RBFNN,該算法在提高模型的檢測精度和魯棒性能的同時降低其漏警率;但是,該算法的檢測速度較慢。
文獻[7]提出了一種基于Faster R-CNN[8]的穿戴識別方法:采用多特征層融合結合多尺度檢測的改進方法,提高了模型的識別精度和魯棒性能。但是,該算法檢測實時性較低,不適用于實際應用。
文獻[9]提出了一種基于Faster R-CNN的規范穿戴工作服的檢測算法:將L2正則項引入損失函數中,提高了模型的訓練收斂速度。該模型有較好的泛化能力和魯棒性能,準確率和實時性相較于基線模型都有所提高。
文獻[10]提出了一種基于 YOLOv5的工作服規范穿戴識別檢測算法。該算法的思想是:修改YOLOv5中檢測模塊輸出層的維度;以算法在公開數據集上得到的預訓練模型作為基礎,將實際監控圖像作為訓練集進行訓練,并對數據集進行數據增廣;通過調整模型的超參數,使得最終得到的算法模型有較好的查準率和查全率。但是,該模型無法檢測出工作服的材質是否符合要求,并且角度和視線遮蓋的問題對檢測的準確度有較大的影響。
綜上所述,目前基于深度學習的工作服規范穿戴識別方法仍存在一些問題,例如對小目標的識別精度不高、模型魯棒性能和泛化能力較低、實時性不強等。本文通過在基礎的Faster R-CNN模型中加入改進特征圖金字塔網絡(Feature pyramid networks,FPN)[11]模塊和注意力機制[12]模塊,從不同的方面提高算法模型對目標的識別精度。
1 改進的Faster R-CNN算法
針對當前基于Faster R-CNN的規范穿戴工作服識別算法在目標較小、目標被遮擋時識別效果較差的問題,本文提出了一種融合改進FPN和注意力機制的目標檢測算法。
如圖2所示,本文模型分為3部分:特征提取部分,候選區域選取部分,回歸分類部分。圖1中:ResNet50為一類卷積神經網絡;fc為全連接層;區域候選網絡(Region proposal network,RPN)結構和Two MLPHead結構是Faster R-CNN網絡的組成部分。
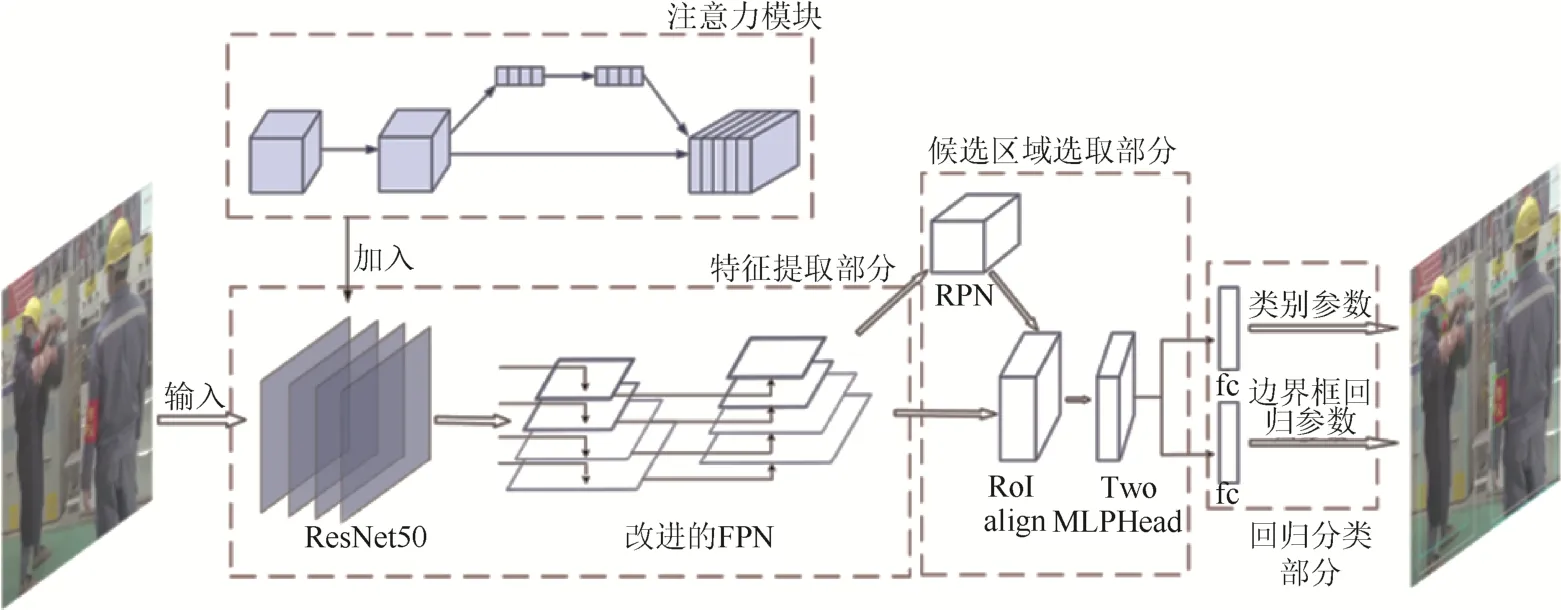
圖1 融合改進FPN和注意力機制的目標檢測算法模型Fig. 1 An object detection algorithm model combining improved FPN and attention mechanism
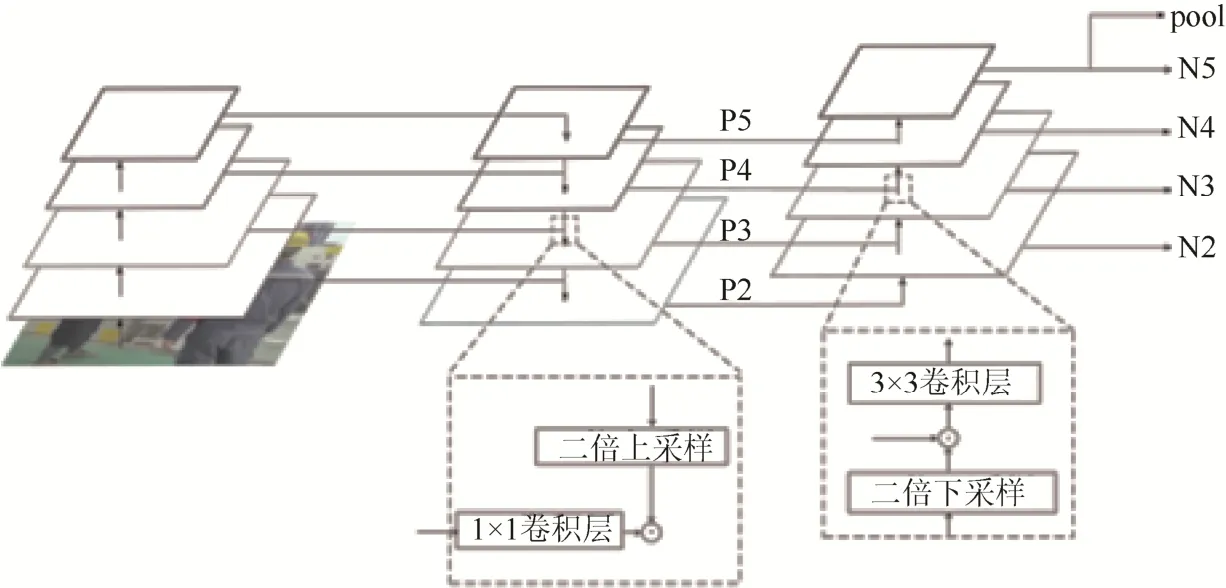
圖2 改進的特征圖金字塔網絡Fig. 2 Improved feature pyramid networks
本文模型以ResNet50網絡為基礎網絡,在其中加入了注意力模塊。輸入圖片經ResNet50網絡和注意力模塊后,傳入改進的FPN結構中;將得到的融合后的特征圖作為特征提取部分的輸出,傳入候選區域選取部分中。將特征圖與RPN選出的候選框一起送入RoI align結構[13]中,得到固定大小的特征矩陣;再通過Two MLPHead結構進行展平,通過全連接層,得到了候選區域選取部分的輸出。最后將候選區域選取部分的輸出內容分別傳入2個全連接層,得到了模型識別出的目標類別參數和邊界框回歸參數。
本文算法的核心,是將基礎Faster R-CNN算法中的RoI pooling層[14]更換為RoI align層,并加入了改進的FPN結構和注意力模塊,進而實現模型識別精度的提高。
1.1 Faster R-CNN算法
Faster R-CNN算法是基于 Fast R-CNN和R-CNN進行改進得到的雙階段目標檢測算法。
Fast R-CNN雖然實現了在R-CNN的基礎上大幅度提升檢測速度,但是由于其依舊采用SS算法[15]生成候選區域,所以模型的檢測耗時仍舊較長,無法滿足實時檢測的需求。Faster R-CNN算法通過RPN結構生成候選框,減少了冗余,實現了模型訓練速度的進一步提升。
Faster R-CNN算法的步驟為:首先將圖像輸入卷積神經網絡中,得到相應的特征圖;然后使用RPN結構生成候選框并將其投影到先前生成的特征圖上,從而獲得相應的特征矩陣;最后將生成的特征矩陣通過RoI pooling層和一系列全連接層運算得到預測結果。
1.2 改進的FPN
在Faster R-CNN網絡模型中,輸入圖像通過基礎卷積神經網絡進行特征提取,從而得到單尺度特征圖,然后將得到的特征圖傳入模型中的RPN結構和RoI pooling層進行預測。
通過神經網絡提取單一深層特征圖進行網絡訓練,可以使網絡得到較強的特征表達能力。這種方法對于較大目標的分類和定位精度較高,但無法準確識別小目標。這是因為在圖像經過深層卷積神經網絡進行大量卷積運算和池化運算的過程中,網絡特征層的感受野會逐漸增大、分辨率逐漸降低,容易造成小目標的漏檢。
與深層特征不同,淺層神經網絡中得到的低層特征分辨率高且包含信息多,其有利于小目標的檢測。因此,將不同尺度的特征進行融合,可以在維持對大目標識別精度的基礎上,提高模型對小目標的識別精度。
為提高模型算法對小目標的檢測精度,本文在Faster R-CNN的基礎上加入改進的FPN。基礎的FPN結構通過將高層特征與低層特征進行自上而下的的融合,提高了輸出的低層特征的語義性。本文改進的FPN結構如圖2所示。從圖2可以看出,模型對基礎FPN輸出的P2、P3、P4、P5進行了自下而上的融合,從而提高了高層特征的分辨率。
1.3 注意力機制
通過現場監控拍攝得到的數據圖像,其像素通常較低,存在目標被遮擋、光線不好等問題。為減輕上述影響因素對模型識別的干擾,本節引入了注意力機制,通過降低背景權重、提高目標部分的權重,實現模型識別精度的進一步提高。
在Faster R-CNN模型中,輸入特征圖中的所有通道權重都相同,即每個通道對于模型而言重要程度相同;這會使得模型使用大量算力對背景部分進行運算,而對目標部分的運算不足。
壓縮和激勵網絡(Squeeze-and-excitation networks,SENet)模塊[16]通過賦予特征圖中各個通道不同的權重,令包含目標的通道權重增高、背景相關通道權重降低,使得模型能夠增加對目標相關通道的運算,從而提高模型的特征表達能力。
在SENet的結構中,輸入的特征圖首先通過自適應平均池化層,得到全局感受野,其中包含了特征在通道維度上的全局信息。然后,將全局感受野通過2個全連接層和ReLU激活函數,使得模型能自動學習通道特征。最后,通過sigmoid函數將所得值轉換到[0,1]范圍內,作為最終權重;將最終權重與最初的輸入特征相乘,結果即為經過SENet處理后的特征。
2 仿真性能測試
2.1 實驗參數與評價指標
實驗計算硬件條件:操作系統為Ubuntn 16.4;GPU為Geforce RTX 1080Ti顯卡;CUDA版本為11.3。
實驗計算軟件條件:以Python3.7為程序開發語言;以Pytorch中的Faster R-CNN代碼框架為基線模型代碼,對其中的代碼進行修改。
實驗中,主要調整的超參數有學習率[17]和一次傳入圖像數量[18]。
學習率可以理解為每一次迭代時參數更新的幅度。學習率過小會導致模型收斂速度過慢,造成模型梯度下降至局部最小點;而學習率過大會導致模型難以收斂,出現震蕩。通過不斷調整學習率,得到本文模型在實驗中的最優學習率為0.016。
一次傳入圖像數量是指模型一次處理的圖像數量。一次傳入圖像數量過少,會導致模型梯度變化的準確性過低,使得模型的收斂速度過慢;而一次傳入圖像數量過多,會導致模型占用內存空間過大,對硬件要求高。通過不斷調整一次傳入圖像的數量,最終確定該參數的最優取值為4,即模型一次同時處理4張傳入圖像。
其他實驗參數設置如下:動量,0.9;權重衰減值,0.000 5。
本文模型選取的評價指標為:當候選框和真實框的交并比取值為0.5時,各個類別的精度均值(Average precison,AP)以及所有類別的平均精度均值(Mean average precision,mAP),即AP50和mAP。
2.2 數據集與數據增強
實驗使用的數據集中共有2 645張圖像,包含了不同的場景、不同目標大小、不同亮度的樣本。
將數據集內標注分為4類,分別為:佩戴紅袖章的監護人員(badge),正確穿戴工作服的人員(clothes),不規范穿戴工作服的人員(wrong clothes),在場人員(person)。
在原有圖像中,wrong clothes類別的目標圖像僅占總量的 11%。考慮數據集長尾分布會導致模型訓練時過擬合,從而使識別精度過低;因此,將數據集中的部分圖像進行數據增強[19]。本文通過對圖像進行翻轉、旋轉、裁剪、移位、模糊、色彩轉換、添加噪聲等操作,對有限的數據進行擴充。通過對圖像進行數據增強,將圖像增廣至4 740張,實現了數據集中各類別目標數量的均衡分布。
數據增強后,將數據集中的圖像劃分為 80%訓練集,10%驗證集和10%測試集。
2.3 實驗驗證
2.3.1 對比實驗
用 YOLOv3-SPP 算法[20]、SSD 算法[21]、Retina Net算法[22]、基礎的Faster R-CNN算法以及本文模型分別進行訓練和測試。
實驗得到4個目標類別的識別精度AP50和所有類別的平均精度均值mAP如表1所示。
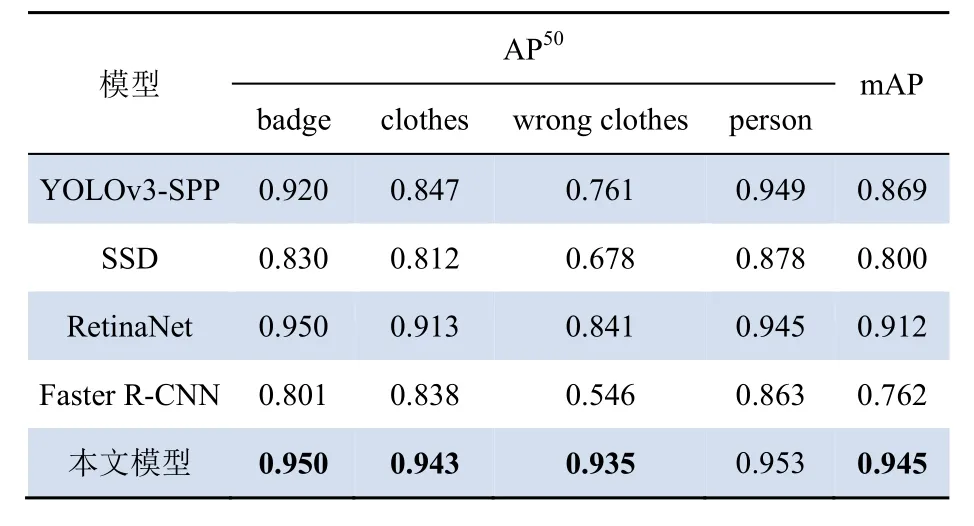
表1 不同模型的對比實驗結果Tab. 1 Comparative experimental results between different models
由表1可知,YOLOv3-SPP算法對小目標的識別精度較高,但整體的檢測精度較低;SSD算法整體識別精度較低;RetinaNet算法整體識別精度都較高,但仍有提升空間;基礎的Faster R-CNN算法對各類別目標的識別效果都較差;相比之下,本文提出的識別模型的精度明顯優于上述各類算法,檢測漏檢、誤檢的情況較少。
2.3.2 消融實驗
本文通過數據增強來平衡數據集中各類別目標的數量,并通過在基線模型中加入改進的 FPN結構、SENet模塊等方法,實現了模型對規范穿戴工作服的識別精度的提升。
表2展示了本文模型消融實驗的結果,由表2可以看出,在Faster R-CNN中加入FPN結構后,各類別的平均精度均值從原先的76.2%提升至92.4%。

表2 不同模塊的消融實驗對比Tab. 2 Comparison of ablation experiments of different modules
以加入FPN的Faster R-CNN模型為基線模型。在基線模型中加入改進的FPN結構后,各類別的平均精度均值從原先的92.4%提升至93.9%。在基線模型中加入SENet模塊后,各類別的平均精度均值從原先的92.4%提升至94.2%。
在基線模型中加入改進的FPN結構和SENet模塊后,各類別的平均精度均值從原先的 92.4%提升至94.5%。
與基礎Faster R-CNN模型相比,本文提出的融合改進FPN和注意力機制的目標檢測算法模型各類別的平均精度均值從原先的 76.2%提升至94.5%,其中,badge一類的AP50提升了14.9%,clothes一類的AP50提升了10.5%,wrong clothes一類的AP50提升了38.9%,person一類的AP50提升了9.0%。
圖3中展示了本文提出模型的檢測效果。由圖3中可以看出,在加入改進的FPN結構和注意力機制后,模型在大目標無遮擋、小目標無遮擋、大目標被遮擋、小目標被遮擋、目標背景復雜等情況下的識別效果都較好。
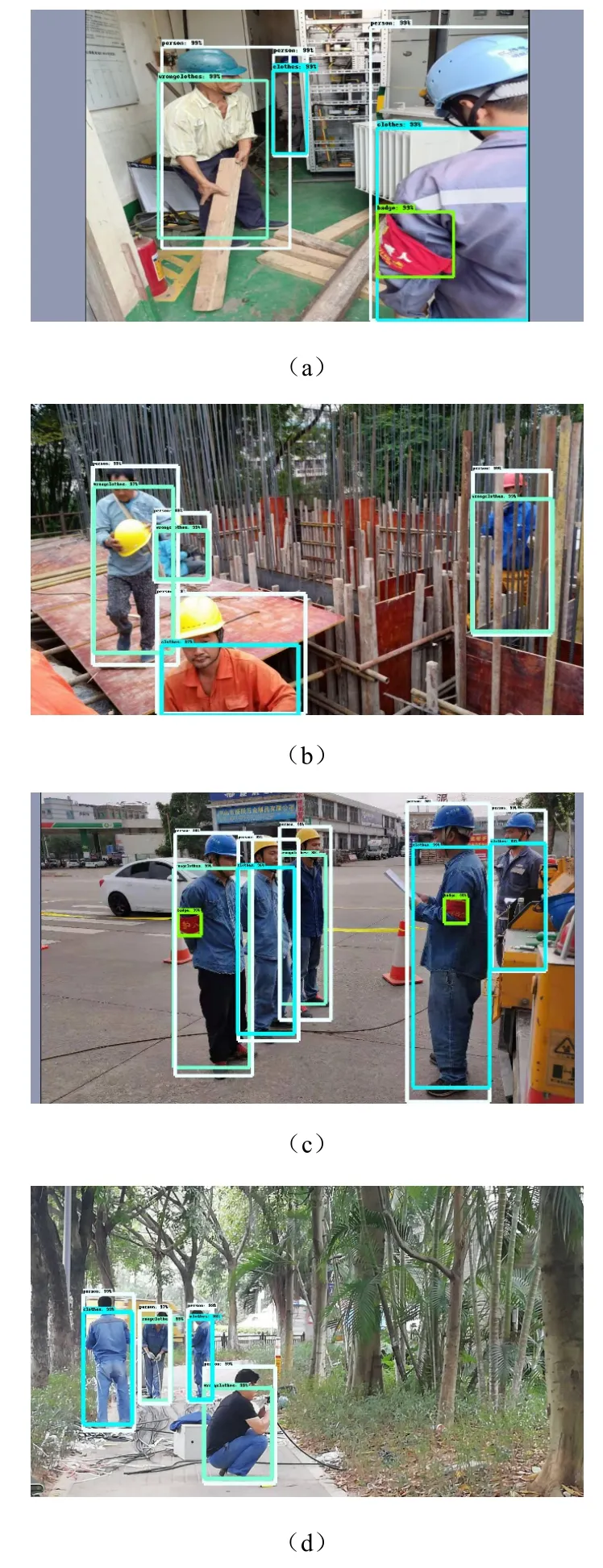
圖3 模型實際檢測效果:(a)—(c)各類目標被遮擋情況,(d)各類目標無被遮擋情況Fig. 3 Detection effects of the model: (a) — (c) the situation that different targets are obscured, (d) the situation that different targets are not obscured
3 結論
本文基于Faster R-CNN算法,設計了一種融合改進FPN和注意力機制的規范穿戴工作服識別方法。
通過在 Faster R-CNN的基礎上加入改進的FPN結構,將ResNet50網絡的輸出特征傳入改進的FPN結構中進行雙向融合,使得模型對小目標的識別精度有一定程度的提高。通過在 Faster R-CNN中加入SENet注意力模塊,降低背景權重、提高目標部分的權重,實現模型對復雜背景下目標識別精度的提高。
通過在包含4個類別的數據集上進行實驗,本文模型較基礎的Faster R-CNN模型有了18.3%的檢測準確率提升。本文模型具有較好的魯棒性能和泛化能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
