融合圖卷積和膠囊網絡的內容感知排序推薦
2023-01-31 03:36:16周文榮
計算機工程與設計 2023年1期
周文榮,張 ,肖 述
(1.湖北大學 校園建設與信息化辦公室,湖北 武漢 430062; 2.湖北大學 計算機與信息工程學院,湖北 武漢 430062)
0 引 言
近年來,隨著深度學習研究在推薦系統領域不斷深入,大多數研究人員從經典的內容感知推薦方法[1,2]開始轉向利用深度神經網絡學習文本內容信息相關特征,將這些特征用于推薦系統的建模,獲得不錯的推薦性能[3,4]。
現有內容感知推薦方法取得了很好的推薦性能,但是仍然存在一些問題亟待解決:
問題1:大多數內容感知推薦方法采用評分預測模型實現項目推薦。但是,實際推薦場景中,項目在推薦列表的排序更加吸引用戶[5]。然而如何將異構的文本內容信息融合到統一的排序推薦模型中,是一項具有挑戰的工作。
問題2:大多數內容感知推薦模型在學習文本特征信息中缺乏對于文本中單詞之間的長程語義關系及其相關依賴性的描述,同時也忽略了文本的層次結構信息。
針對上述問題,本文提出了一種融合圖卷積網絡和膠囊網絡建模文本內容的聯合排序推薦算法(ranking lear-ning fused with capsule networks and graph convolutional network,RL-CNGCN)。具體而言,首先,構建圖卷積網絡學習文本特征并捕捉文本單詞之間豐富關系,同時采用膠囊網絡提取文本信息的高階層次結構信息,從而通過融合圖卷積網絡和膠囊網絡實現文本特征的細粒度學習。然后基于擴展的排序學習模型對用戶與項目交互的聯合關聯以及項目與項目描述相關文本內容之間的關系進行聯合建模,實現精準用戶偏好的推斷。基于公開亞馬遜數據集進行廣泛的實驗結果表明,本文所提出的方法具有更好的推薦性能。
1 相關工作
本節從如下兩個方面回顧與本文相關的內容感知推薦算法研究技術:
(1)基于評論和評分信息實現內容特征學習。傳統方法基于主題模型從評論中提取主題實現用戶和項目的特征表示學習,然后基于評分預測模型進行推薦[2]。由于主題模型是標準的詞袋模型,使得上述傳統方法大多受限于詞袋模型固有的缺陷,不能有效利用內容文本中的上下文信息和單詞序列。當前深度學習模型偏好利用深度學習理論學習文本信息的潛在完整特征,從而達到緩解上述問題的目的。Zheng等[3]采用兩個并行的CNN從評論文本中對用戶行為和項目屬性進行建模。而Xia等[6]則基于注意力的GRU網絡從用戶和項目評論中學習上下文感知表示,然后進行評分預測。Liu等[7]則提出一種基于混合神經網絡融合評分和評論的推薦模型。受限于卷積操作接受域或局部注意力等,使得大多已有深度學習方法在文本特征學習時,忽視了文本中語義信息上下文特征相關性的學習以及文本中固有的高階層次結構信息,無法突出文本中不同語義特征的差異性、多樣性和重要性。
近年來,隨著圖神經網絡研究的深入,GCN超強的特征學習能力為深度學習方法在內容特征建模中遇到的上述問題提供了一種新的解決方案。Wu等[8]基于多視圖的理論,提出了一種新的融合注意力機制和圖神經網絡實現文本信息建模的方法。TextGCN模型[9]則基于詞共現和文本-詞關系構建單個文本圖,然后基于圖卷積網絡實現詞和文本的特征學習。
(2)基于排序的推薦方法。基于內容的推薦方法大多偏好采用評分預測模型,僅僅依靠評分大小的順序并不能準確體現用戶的偏好。用戶在實際場景中更關心項目的排序,而基于排序學習的推薦算法直觀展示了推薦結果。其中最具代表性的基于排序學習推薦模型是逐對排序推薦模型-BPR模型。Shang等[10]將BPR排序模型與貝葉斯模型結合用于事件推薦。Wu等[11]的工作則是將BPR模型和圖嵌入模型結合用于推薦模型。而Gao等[12]利用地理社交相關性,提出一種新的BPR成對排序假設,從而構建一個三級聯合成對排序模型用于興趣點推薦,獲得了更好的推薦性能。
本文基于融合圖卷積網絡和膠囊網絡的方法學習文本信息的細粒度特征表示。然后,提出基于一種新的聯合逐對排序推薦算法實現用戶-項目-文本三者的融合,從而提升推薦性能。
2 提出的模型
本節中,主要介紹所提出的RL-CNGCN算法框架,如圖1所示。本文首先給出相關問題的形式化描述,然后提出融合圖卷積網絡和膠囊網絡的細粒度文本特征學習,再構建一個基于聯合函數的內容感知排序推薦模型,實現用戶-項目交互的聯合關聯以及項目與關聯詞之間的關系建模的融合,從而將評分和評論信息的文本特征表示融合到一個統一的排序推薦模型中,提供精準推薦服務。
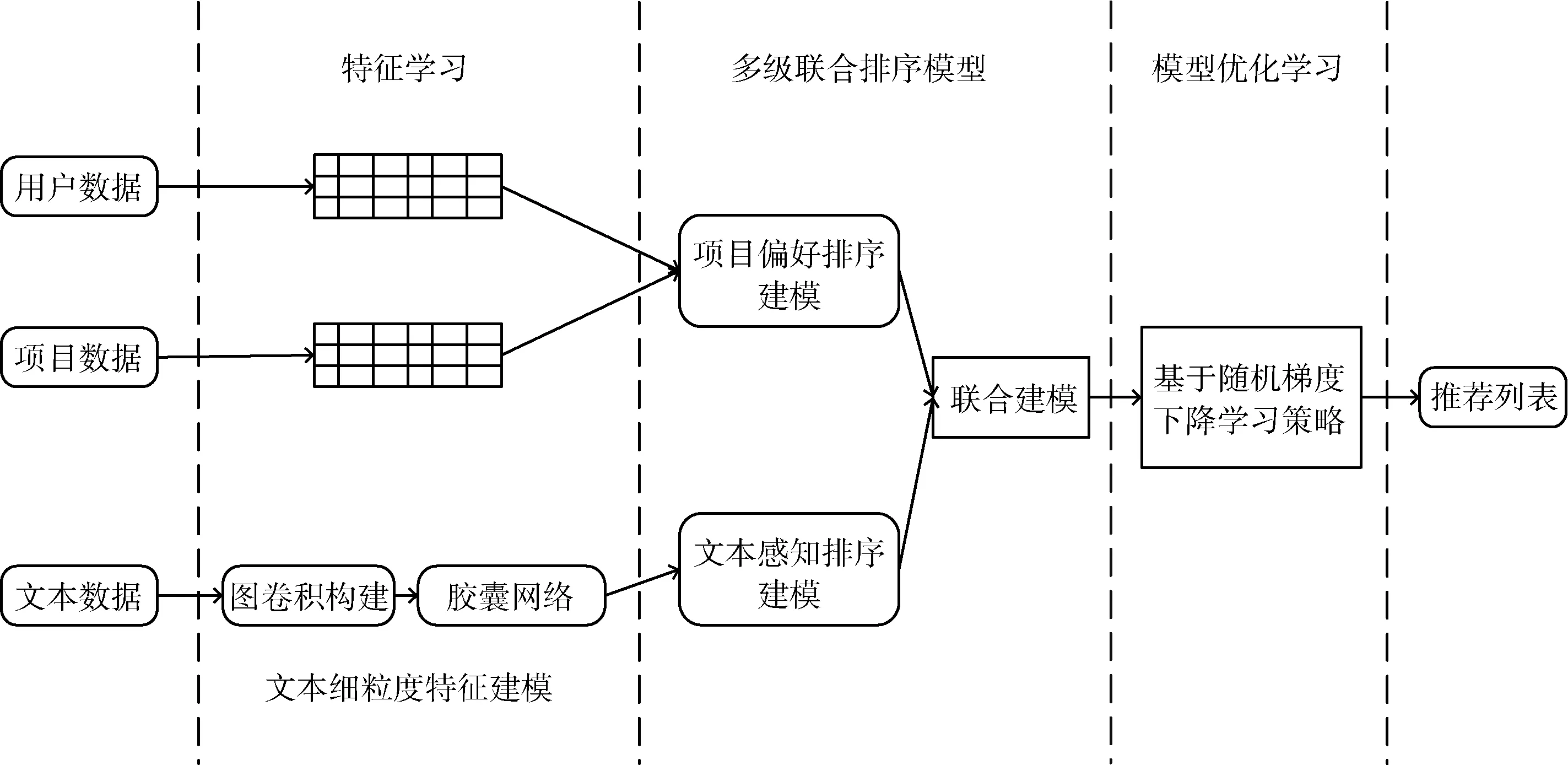
圖1 RL-CNGCN 算法框架
2.1 問題形式化和預備知識
在本文中,讓U、I和N分別表示用戶、項目和詞的集合。對于用戶和項目之間的交互,表示為Cu,i={(u,i)|u∈U,i∈I}, 以及項目和單詞之間的關系,表示為Ci,z={(i,z)|i∈I,z∈N}, 其中每個項目的單詞是從其描述文本中提取的。同時,給定一個無向圖G=(V,E), 其中,V是頂點集, |V| 表示頂點的數量,E是邊集。每個頂點都與一個維度為d的特征向量相關聯,文檔特征矩陣X∈R|V|×d用于表示所有頂點的特征,它也被設置為單位矩陣。邊集E通常由鄰接矩陣A∈R|V|×|V|表示,其中Aim,jn是第im個頂點和第jn個頂點之間的邊的權重。度矩陣B∈R|V|×|V|是對角矩陣,Bim,jn=∑jmAim,jn。 構建的文本圖中的節點數 |V| 是文本的數量加上數據集中唯一詞的數量。一個文本節點和一個詞節點之間的邊的權重是該詞在文本中的詞頻-逆文本頻率,其中詞頻是指該詞在文本中出現的次數,逆文本頻率是包含該詞文本數量的對數比例倒數。

本文的目標就是通過采用融合圖卷積網絡和膠囊網絡的混合網絡學習文本細粒度特征,然后整合用戶-項目、用戶-文本、項目-文本之間的關聯來構建聯合排序推薦模型學習用戶偏好,從而為每個用戶提供個性化項目排名列表。
2.2 文本細粒度特征學習
本節描述如何融合圖卷積網絡和膠囊網絡學習文本細粒度特征。由于文本中存在的層次結構常常在特征學習時被忽略[13],為了學習文本的細粒度特征,本文受到膠囊網絡[14,15]的啟發,利用膠囊網絡提取文本中的層次結構信息,從而融合圖卷積網絡和膠囊網絡來學習文本細粒度特征。如圖2所示,基于圖卷積模型構建相關文本中單詞的圖模型表示,精準捕獲了文本中單詞的長期且非連續關系。然后將獲得的文本單詞特征表示視為一個膠囊,通過構建含有兩個膠囊層的膠囊網絡,實現圖卷積網絡和膠囊網絡的密切融合,達到學習文本的細粒度特征表示的目的。在融合圖卷積網絡的膠囊網絡中,兩個連續膠囊層間基于多次迭代的路由算法進行更新,進而提取文本信息中層次結構信息,這有助于捕獲到復雜場景中文本的細粒度特征。
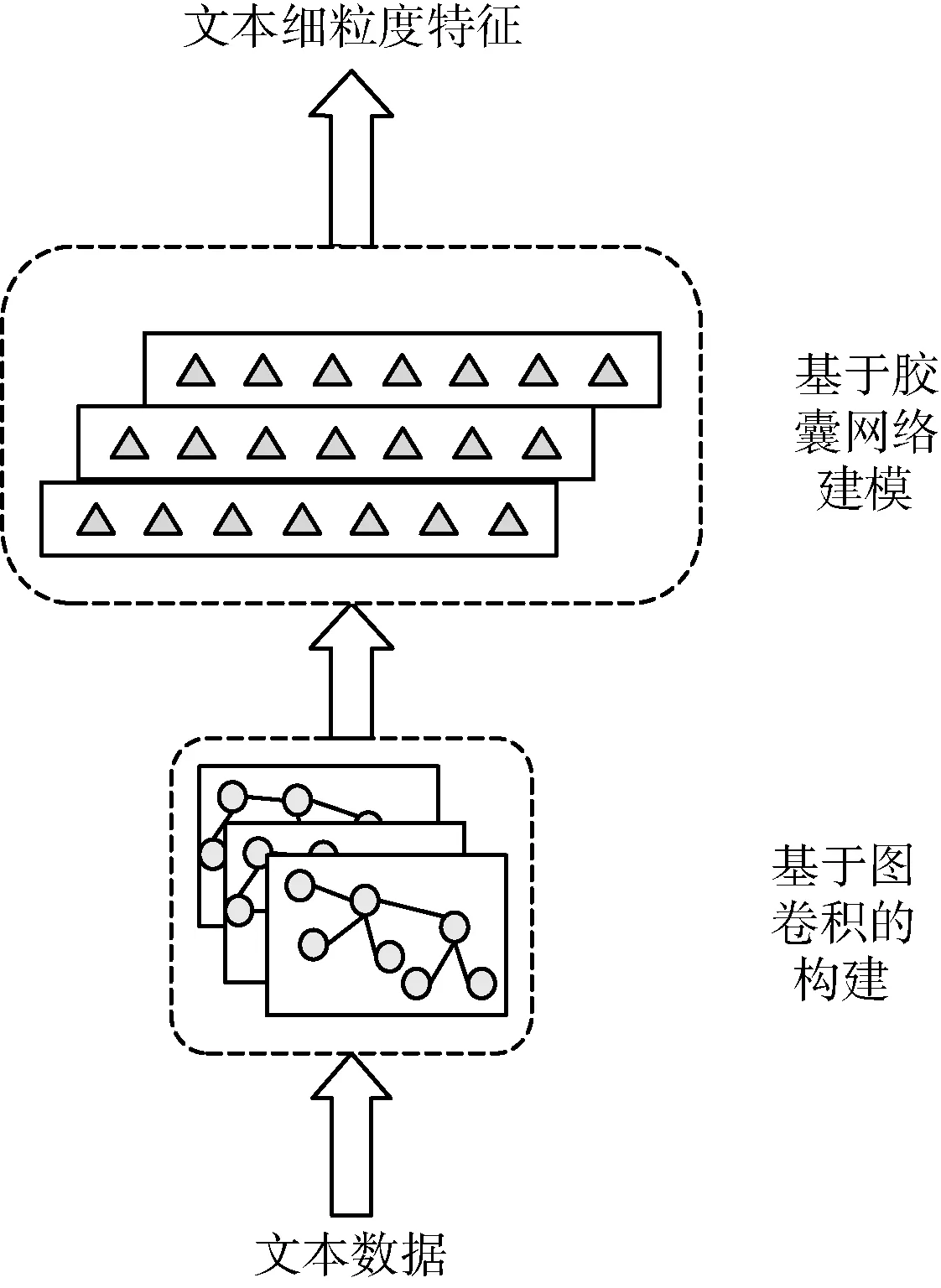
圖2 文本細粒度特征學習
2.2.1 構建基于圖卷積網絡的文本單詞特征學習
首先,本文為每個文本創建一個無向圖來對其內容信息進行建模。給定一個文本,將內容中的詞作為圖的頂點。與Wu等[13]一樣,本文也采用逐點互信息(PMI)來計算邊的權重,從而保留了全局詞共現信息。具體來說,在源域和目標域中的所有文本上使用固定大小的滑動窗口來收集單詞共現統計信息。
計算詞對的PMI如下
(1)
(2)
(3)
其中,Hw(zi) 是包含單詞zi的滑動窗口數,Hw(zi,zj) 是包含單詞zi和zj的滑動窗口數, |Hw| 是滑動窗口的總數。由于PMI分數可以反映詞之間的相關性,PMI分數越高,則反映語義相關性越強[8]。因此,本文只保留具有正PMI分數的詞對之間添加邊
(4)
其中,ai,j是詞zi和zj之間的關系。經過這個過程,得到了全局語料上的詞關系,鄰接矩陣A是每個文檔中詞關系的子集。
然后,本文采用多層GCN模型實現節點級單詞的文本特征學習。本文通過堆疊多個圖卷積層來合并高階鄰域信息,為節點生成新的向量表示l,得到如下公式
l0=X
(5)
(6)
(7)
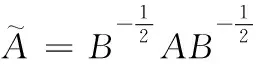
2.2.2 融合圖卷積網絡和膠囊網絡的文本細粒度特征學習
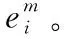
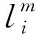
(8)
其中,擠壓函數squash() 確保每個特征向量的方向不變,而其膠囊的長度縮小。
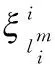
(9)
(10)
(11)
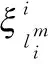
(12)
2.3 聯合排序模型
首先,本節深入分析用戶與項目及項目與文本之間的關系,同時受到Chen等[16]設計的排序學習模型啟發,基于本文提出的模型假設,分別建模項目偏好排名和詞相關性排序模型。然后描述所提出的聯合排序模型,并給出采用模型的推導與優化過程和參數學習過程。
2.3.1 用戶項目偏好排序學習
基于BPR模型實現項目偏好排名模型,本節通過利用三元組Du作為訓練數據來優化項目對的正確排名,基于觀察到的用戶-項目交互為每個用戶生成個性化的項目排名列表。該模型的似然函數如下
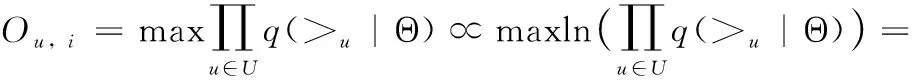
(13)
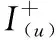
q(j>u|Θ)=η(〈Θu,Θj-Θ′j〉)
(14)
其中, 〈·,·〉 表示兩個向量之間的點積, Θu和Θj分別表示上節中用戶u∈U和項目j∈I的d維向量表示,j>uj′表示用戶u更喜歡項目j而不是項目j′, 對于每個三元組 (u,j,j′)∈Du,j>uj′。 〈Θi,Θj-Θ′j〉 表示對關于項目j和j′與項目i的相似度建模,η(·) 表示sigmoid函數。
2.3.2 項目文本相似性排序學習
基于BPR擴展模型,本文根據項目的描述對項目和相關詞之間的關系基于排序學習模型進行建模。受到Xu等[17]基于單詞分布學習單詞語義建模技術的啟發,本文提出最大化相關(正)項目-詞對的似然函數,通過利用Di中的項目-單詞-單詞三元組作為訓練數據,而不是每個項目的不相關(負)項目詞對,因此有如下公式
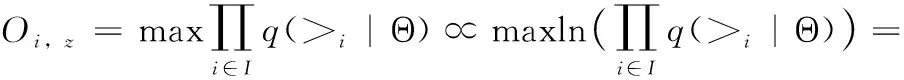
(15)
其中, >i表示項目i的成對單詞相關性(即,ez>iez′表示單詞z比單詞z′與項目i的相關性更高,對于每個三元組 (i,z,z′)∈Di,ez>iez′)。q(ez>iez′|i) 計算為
q(ez>iez′|i)=η(〈Θi,Θz-Θz′〉)
(16)
其中, Θz是來自單詞z∈Z的d維行向量表示, 〈Θi,Θz-Θz′〉 表示對關于單詞z和z′的項目i的詞相關性排序建模。η(·) 表示sigmoid 函數。
2.4 聯合排序模型學習與優化
文本信息來源的重要來源是項目描述。在相關文本信息的描述中,用戶對有些關鍵詞更加關注,因為這些詞能夠更加體現項目的特征(例如它們的長度、年齡或風格),從而潛在的反應用戶的偏好。因此,本節提出構建一個融合文本內容基于排序學習的聯合推薦模型。
首先,本文給出如下定義:
(1)〈Θu,Θj-Θj′〉: 對用戶u關于項目j和j′之間的項目偏好排名進行建模;
(2)〈Θi,Θj-Θj′〉 表示對關于項目j和j′與項目i的相似度建模;
(3)〈Θu,Θz-Θz′〉: 對用戶u關于詞z和z′的詞相關性排名進行建模;
(4)〈Θi,Θz-Θz′〉: 對關于詞z和z′的項目i的詞相關性排名進行建模。
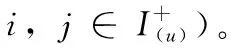
因此本文設計一個聯合似然函數,該函數聯合考慮上述定義中(1)~(4)所示的4種類型結構。即分別由上述2.3.1小節和2.3.2小節的排序學習模型組成: >u和>i。 顯然>u和>i本質上是相互依賴的,因為給定用戶交互的項目在這兩個排序學習結構中重疊。本文設計的這個聯合似然函數的目標是找到一個聯合表示矩陣Θ,從而最大化觀察到的用戶-項目和項目-詞對,并描述上述4種復雜關系
(17)
其中, >u表示給定用戶u∈U的兩個項目之間的偏好結構, >i表示給定項目i∈I的單詞之間的相關性結構。
基于上述假設的上述聯合似然函數的計算如下

(18)
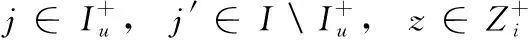
(19)
其中,ζΘ是特定于模型的正則化參數。
根據學習率?更新模型參數
(20)
在本文中,式(17)中的目標函數采用異步隨機梯度下降算法—ADMA算法來最大化公式以并行有效地更新參數。具體來說,對于每個給定的 (u,i) 對,本文為用戶u隨機抽取一個正項目作為j,將一個負項目作為j′, 為項目i隨機抽取一個正負單詞對作為 (z,z′), 從而得到三元組 (u,j,j′)∈Du和 (i,z,z′)∈Di用于更新參數,梯度定義為
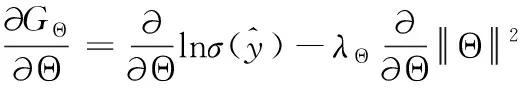
(21)
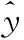
算法:融合圖卷積和膠囊網絡的內容感知排序推薦算法
輸入:用戶評分數據信息、項目屬性信息、目標用戶,文本信息
輸出:目標用戶的排序列表q(j>uj′,ez>iez′|Θ)
具體的步驟如下:
步驟1 對用戶評分數據進行預處理;
步驟2 根據式(1)~式(4)構建文本信息中單詞圖模型;
步驟3 根據式(5)~式(7),基于圖卷積網絡學習文本單詞特征的表示為lm;
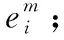
步驟5 利用用戶-項目-項目三元組Du, 根據式(13)~式(14)優化項目的正確排名q(j>u|Θ);
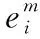
步驟7 根據給出的定義,基于式(17)~式(18),構建聯合排序學習損失函數q(j>uj′,ez>iez′|Θ)。
步驟8 采用異步隨機梯度下降算法-ADMA算法,基于式(18)~式(20)來優化上述損失函數,并更新相關參數。
3 實 驗
3.1 數據集與數據處理
與Liu等[18]類似,本文也采用4個不同領域的亞馬遜數據集上進行實驗,驗證本文提出推薦算法的性能,其數據集描述見表1。顯然,這4個數據集具有不同的特征。對于這些亞馬遜數據,本文在實驗中采用了用戶項目評分和項目描述,將評分項目視為正面反饋,其余視為負面反饋,并刪除評分少于3個項目的用戶。所有的實驗數據集都包含用戶-項目交互和文本項目描述。在預處理中,本文將用戶-項目交互轉換為隱式反饋。對于項目描述,本文過濾掉詞頻小于5的詞或文本頻率小于相應語料庫10%的詞。表1列出了每個數據集的預處理數據的統計信息,包括單詞數、隱式反饋量(U-I邊)以及項目和單詞之間的關系數(I-W 邊)。同時遵循Liu等[18]的方法,對數據集的評論信息還進行了如下預處理:①刪除停用詞;②將原始文本的長度設置為300;③計算每個單詞的詞頻與文本頻率成反比的值。
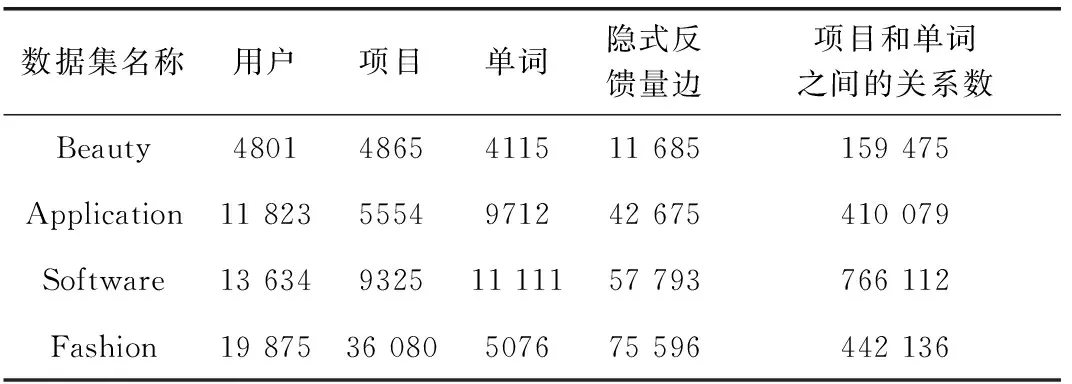
表1 亞馬遜數據集統計
3.2 評估指標與參數設置
本文基于兩個評估指標進行Top-N推薦的性能評估:召回率(表示為Recall@N[8])和歸一化折扣累積增益(表示為NDCG@N[8])。對于所有數據集,本文將用戶-項目交互隨機分為70%和30%,分別作為訓練集和測試集。每個用戶的推薦集是作為正面項目的集合生成的,其中包含1000個隨機選擇的負面項目。
在本文的實驗中,RL-CNGCN和GCN中文本特征的維度為150,ζΘ=0.025, 學習率?=0.05, 窗口大小設置為10,p在訓練中從0到1。NCTR和DAML中批次大小設置為128,丟棄率為0.2,學習率是0.0001,維度大小設置為100,卷積核數量為100,滑動窗口的大小是5,迭代次數設置為200。JRL的批次大小是64,學習率是0.5,維度大小為300。MCRec的批量大小為256,學習率為0.001,正則化參數為0.0001,維度大小為128。RMG的學習率為0.001,潛在維度為32,丟棄比率為0.1,正則化項為0.1。
3.3 實驗方案設計
本文從如下3個不同的角度進行實驗測試,以驗證文中算法的有效性:
(1)將本文提出的算法與4個主流先進推薦算法進行對比;
(2)基于提出的融合圖卷積網絡和膠囊網絡的方法與3個基準方法進行對比,這些基準方法是推薦系統中常用的;
(3)討論了維度參數對于推薦結果的影響。
實驗中選取如下幾種基準算法進行對比:
(1)DAML[18]:一種基于雙層注意力互學習機制的基于內容的推薦算法。
(2)JRL[19]:一種基于圖神經網絡的推薦算法,它在圖神經網絡框架下對協同知識圖中的高階關系進行顯式建模,基于不同信息源中學習聯合表示以進行Top-N推薦。
(3)MCRec[20]:一種融合正則化和基于路徑的推薦算法,這種模型結合了正則化和基于路徑的方法。
(4)NCTR模型[7]:一種混合神經網絡融合評分和評論信息進行項目推薦算法。
為了評估本文提出的方法和下面幾種學習方法進行比較:
(1)GCN[9]:基于圖卷積網絡學習文本特征;
(2)GRU[6]:基于GRU網絡學習文本特征;
(3)RMG[8]:基于層次圖神經網絡和注意力機制學習文本特征。
3.4 實驗結果分析
3.4.1 實驗模型性能對比
實驗結果見表2和表3,顯然,本文提出的RL-CNGCN在所有數據集上始終優于其它上述對比主流先進推薦算法。也驗證了本文提出的模型的有效性和高效性。可能原因如下:①對于內容特征學習這個方面,本文采用融合圖卷積神經網絡和膠囊網絡的混合神經網絡有著更強的學習能力;②基于擴展BPR模型的逐對排序推薦性能優于基于評分預測的推薦性能,同時融入項目-文本的交互實現了對用戶特征向量的一定約束從而得到了用戶偏好更細粒度的描述,很明顯,這也再次驗證了文本內容信息能夠對于用戶的偏好產生一定的影響。MCRec是基于元路徑實現用戶和項目的精準表示,但是其過于依賴元路徑的質量,使得其需要極其廣泛的領域知識來實現元路徑的定義。DAML和NCTR都是基于深度學習的方法融合評論和評分信息進行推薦,其中NCTR缺乏對于用戶和項目高階交互信息的建模,使得其性能落后于DAML。而DAML模型一方面相對于MCREC, 容易受到數據稀疏的影響,另外一方面,也如同3.4.2小節所驗證的,基于圖卷積模型對文本的表示學習優于采用基于卷積操作的文本內容特征學習。JRL模型雖然采用了TOP-N推薦框架,但是它沒有采用深度學習的方法,而是利用doc2vec模型實現了內容特征的學習。在文本內容建模過程中,沒有突出文本中關鍵詞的權重,也沒有考慮文本上下相關詞的特征之間的影響,使得其只實現對文本內容的粗粒度建模,同時上述實驗結果也恰好再次驗證了基于深度學習的方法對比傳統方法可以實現文本內容特征更加精準的學習。
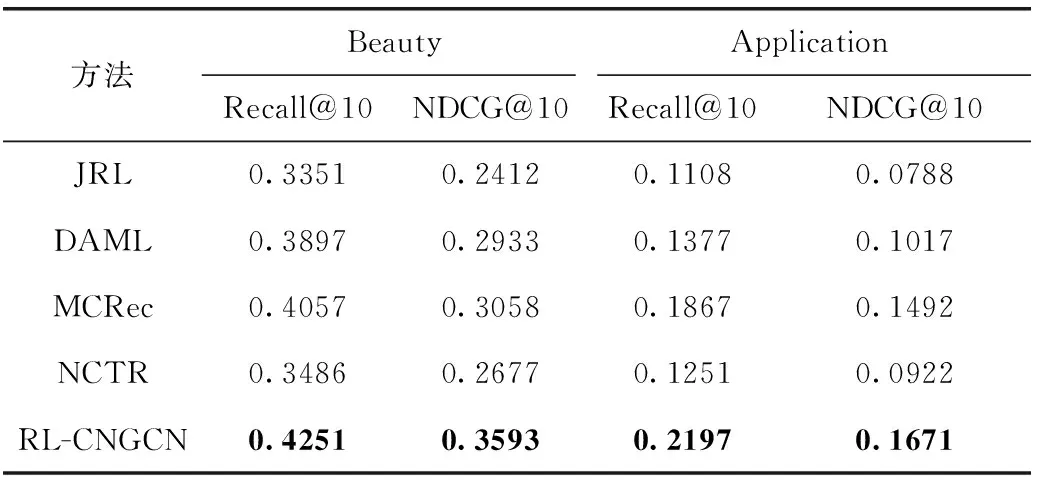
表2 基于Beauty數據集和Application數據集的性能對比
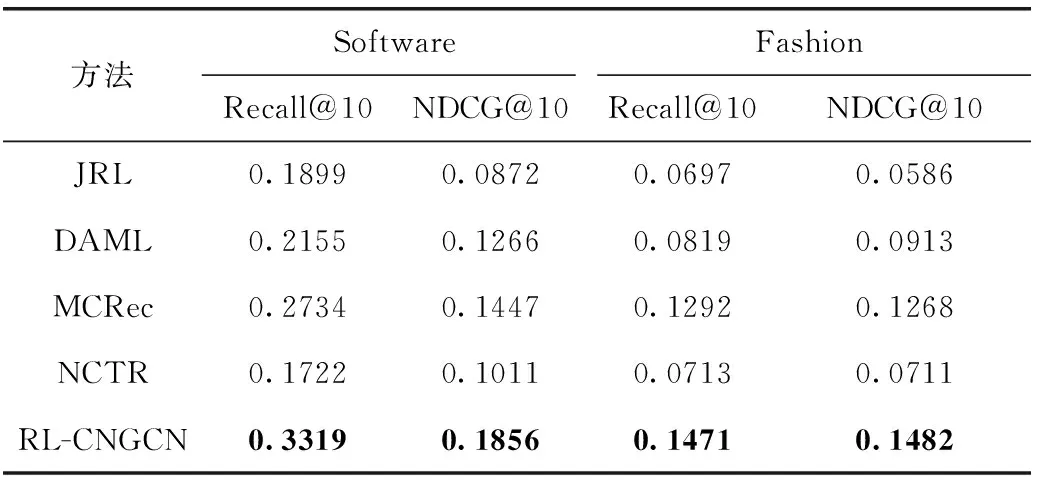
表3 基于Software數據集和Fashion數據集的性能對比
3.4.2 文本特征建模對比
本節將本文采用的方法與幾種主流方法進行對比。
實驗結果見表4和表5,RL-CNGCN在4個數據集上的表現最好并且明顯優于所有對比模型,這展示了所提出的方法的有效性和高效性。其將膠囊理論融合到圖神經網絡中實現了文本內容表示學習,生成的圖和膠囊不僅保留了層次結構等相關的信息,還保留與圖屬性有關的其它信息,這些信息可能對后續建模工作有用。其作為一種新穎的框架,顯然融合膠囊網絡的圖卷積網絡實現了更有效的圖表示學習。對于其更深入的性能分析,本文也發現其在稠密數據集上性能優于稀疏數據集。GCN相對比RMG、GRU,其自身圖卷積結構的特點決定了在捕捉文本-詞關系和文本中全局詞-詞關系,使得其優于GRU方法和RMG方法。但同時GCN也受限其自身運行機制,在文本內容特征抽取中,大多忽略了文本中層次結構關系。GRU模型性能最弱,可能的原因因為基于 RNN 的方法擅長處理序列信息,特別是短期序列信息,但其無法對非連續短語和長距離詞依賴信息進行建模,從而無法獲得文本中長距離的關鍵關系。RMG稍強于GRU,可能的原因因為它們利用層次圖神經網絡加上注意力的方式學習文本特征,通過利用注意力機制來突出文本特征中單詞、句子、段落等重要性。
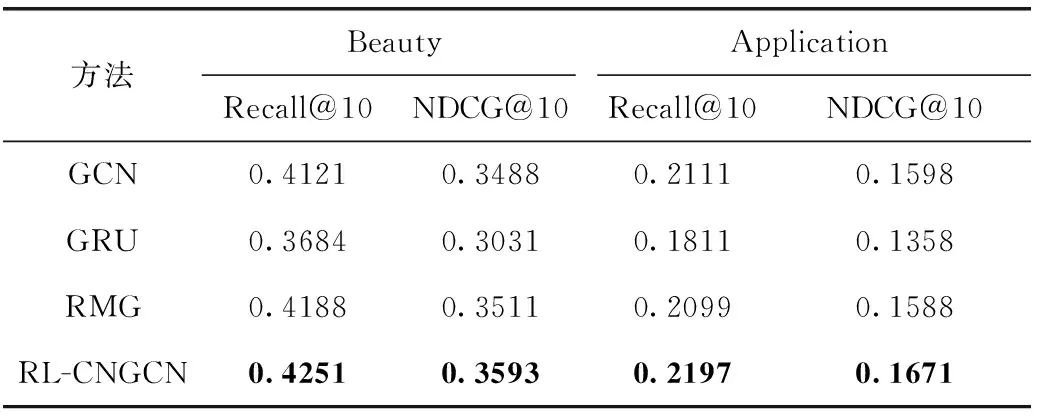
表4 基于Beauty數據集和Application數據集文本特征建模對比
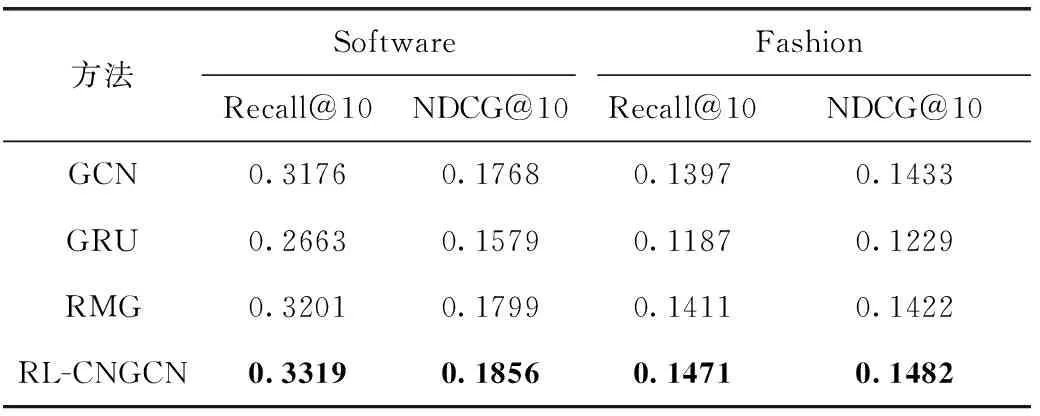
表5 基于Software數據集和Fashion數據集文本特征建模對比
3.4.3 參數影響分析
這一節主要介紹相關參數設置對RL-CNGCN的影響。主要從文檔潛在因子的維度這個方面對RL-CNGCN算法進行分析,結果見表6和表7。
從表6和表7的結果中,可以觀察到:①通過增加潛在維度,模型性能得到了提高。可能的原因是過于小的維度不足以充分表達用戶的潛在特征。但是,當潛在維度增大到一定范圍時,模型趨于穩定,如果繼續增加潛在維度,則推薦性能不再提高。造成這個現象的原因可能是模型也隨維度的增加從而導致過擬合現象的出現。因此,本文將潛在維度設置為150;②在4個數據集上均呈現相似的變化,但是相同的潛在維度在不同的數據集上具有不同的性能。可能的原因是各個數據集的稀疏度各不相同。
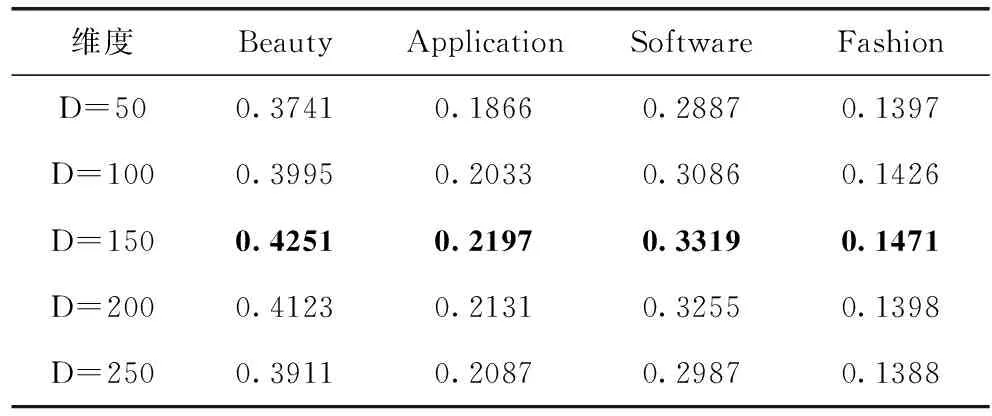
表6 基于亞馬遜數據集潛在維度Recall值分析
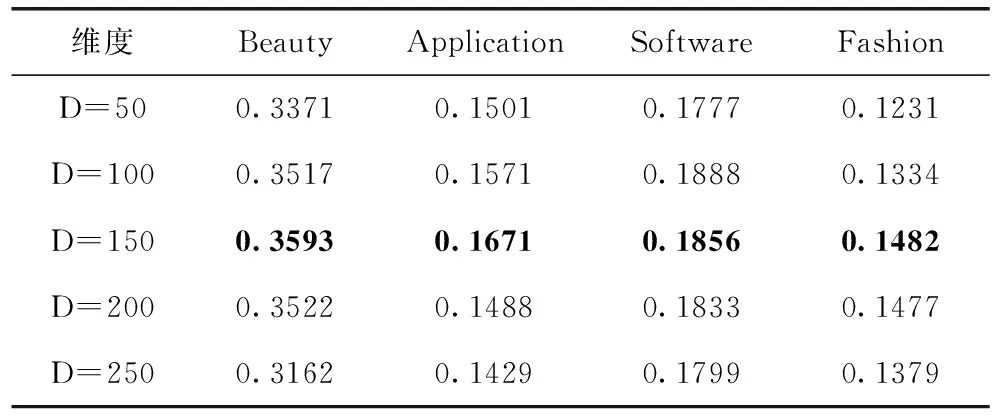
表7 基于亞馬遜數據集潛在維度NDCG值分析
4 結束語
在本文中,提出了一種內容感知推薦算法。它融合圖卷積網絡和膠囊網絡來建模文本評論內容,全面捕獲文本中的語義信息和層次信息。然后將推薦問題視為排序問題,基于擴展的BPR標準,設計一個統一的聯合損失函數,擬合用戶-項目交互的聯合關聯,并融合項目與相關文本之間的關系,最終實現用戶偏好的精準推斷。實驗結果表明,所提出算法優于基準推薦算法。未來工作,將進一步研究圖神經網絡在內容感知推薦系統的應用。
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
兒童繪本(2018年5期)2018-04-12 16:45:32
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
河南科技(2014年23期)2014-02-27 14:19:15
