非獨立同分布下的K-Modes算法
2023-01-31 03:56:22周慧鑫王艷梅
計算機工程與設計 2023年1期
周慧鑫,姜 合,王艷梅
(齊魯工業大學(山東省科學院) 計算機科學與技術學院,山東 濟南 250353)
0 引 言
許多學者根據K-Modes算法[1,2]存在的問題,對算法進行了很多研究和改進。針對初始中心點選擇的問題,Liwen Peng[3]提出了一種基于屬性權重的選擇聚類中心的方法。賈瑞玉等[4]定義了一種新的計算對象密度的方法,通過殘差分析得到初始聚類中心。針對相異度量的問題,趙亮等[5]提出了一種基于樸素貝葉斯分類器中間運算結果的距離度量。施振佺等[6]提出了一種基于粗糙集和知識粒度的屬性加權算法,加權到相異度的計算中。袁方等[7]提出了一種針對有序分類與無序分類兩種屬性的距離度量。針對其它方面的問題,黃苑華等[8]提出一種基于結構相似性的K-Modes算法。張春英等[9]提出了一種基于集對信息粒的集對K-Modes聚類算法。葉霞等[10]提出了一種將蟻群聚類算法與K-Modes算法相結合的算法。
到目前為止,相異度量的計算,大多數都考慮的是數據之間是相互獨立,沒有關系的,然而實際上的數據集中屬性之間是存在著一定的耦合關系,即非獨立同分布。操龍兵首先提出的非獨立同分布思想,隨后很多研究學者運用這個思想,用于許多不同的研究方向。操龍兵提出了基于復雜相互作用的耦合性學習。Jian等為無監督學習定義了一個耦合度量相似度(CMS)[11],它提出了數據對象間的異構耦合關系。Wang等提出了在無監督學習中類別型數據的耦合關系來計算相似性度量的方法并在K-Modes算法中進行了驗證。在真實數據中,數據對象的屬性之間存在著一定的聯系,因此,在非獨立同分布的思想下改進K-Modes算法將更加符合實際。
1 K-modes算法
1.1 算法基本概念
在日常的數據中,數據類型主要包括數值型數據和類別型數據。它們之間有本質性的區別,數值型數據是按數字尺度測量的觀察值,其結果表現為具體的數值,是屬性值的一個數值,屬性值之間具有一定的幾何特征,可以進行數值運算;而類別型數據是一種非數值型數據,表示的是對象的特征屬性,特征的數值既沒有數量大小的含義,代表的是屬性的各種狀態,不能進行數值運算,各種分類內容都屬于類別型數據, 如性別分類(男、女)、地區(省、市)、農藥毒性(劇毒、高毒、中毒、低毒)等[12]。K-Means算法是適用于連續的數值型數據[13]的聚類算法,以效果更好,思想簡單的優點在聚類算法中得到了廣泛的應用[14]。現在常用的距離度量方法有很多像歐氏距離、曼哈頓距離、切比雪夫距離、余弦距離,這些方法都是針對對數值很敏感的數值型數據,而類別型數據之間的相似性是對數據特征很敏感,所以傳統的K-Means算法中計算數據距離的歐式距離不能計算離散屬性之間的距離。K-Modes聚類算法通過對K-Means聚類算法的拓展,使其可應用于類別型屬性數據聚類[15]。
K-Modes算法中采用計算數據間相異度量的方法來表示數據間的距離。相異度量越小,則表示距離越小。K-Modes的基本思想是隨機分配K個對象作為初始聚類中心,計算隸屬度矩陣,將剩余的數據劃分到離初始類中心最近的子類中,基于頻率更新聚類中心,經過多次迭代,聚類函數收斂,算法劃分結束。
1.2 算法描述
輸入:數據集,聚類類簇個數K。
輸出:聚類后劃分好的子類集合。
步驟1 從數據集中隨機選擇K個對象作為初始類中心,其中K表示聚類過程中簇的個數。
步驟2 采用簡單0-1匹配方法計算每個對象與各聚類中心之間的相異度量作為距離度量。某一個對象和另一個對象的相異度量就是它們各個屬性不相同的個數,相同記為0,不相同則記為1,最后計算1的總和,這個和就是兩個對象間的相異度量。
步驟3 將每個對象分配到相異度度量最小的子類中。
步驟4 使用基于頻率的方法更新聚類中心。
步驟5 重復上述的步驟2~步驟4,直到目標函數F收斂,即聚類中心不再發生變化時,算法結束。目標函數見式(1)
(1)
其中,k是聚類類簇的個數,n是數據對象的個數,wli∈{0,1} (1≤l≤k,1≤i≤n,)wli=1表示第i個對象被劃分到第l類中,ml為第l個類的聚類中心,xi表示第i個數據對象。
2 NonIID-HDK-Modes算法
2.1 初始聚類中心的選取
傳統的K-Modes算法中,對初始聚類中心點是隨機選取的,這使得聚類算法的結果會非常依賴初始聚類中心點的選取。隨機選取K個中心點,可能會選取到離群點,而且每次中心點選取的不同也會影響到算法的聚類效果。因此,本文提出一種基于層次聚類對數據集進行預聚類的方法,對預聚類劃分好的類簇進一步處理后,取得的每個類簇中的聚類中心作為K-Modes的初始聚類中心,改變傳統算法隨機選取中心點的缺點。
層次聚類的相似性指的是任意一個數據對象ux與所有數據對象之間的距離,它們的距離越小,相似度就越高。層次聚類的思想就是將相似度高的數據對象不斷的進行合并,直到合并到設定的K個類簇,結束算法。
基于層次聚類預聚類的初始聚類中心選取方法的具體步驟是:
(1)對數據集的數據進行歸一化處理
在數據集中,不同屬性指標往往具有不同的量綱和量綱單位,這樣的情況會影響到數據分析的結果,為了數據處理方便,對數據進行基于均值和標準差的歸一化處理
(2)
其中,μ為所有樣本數據集的均值,σ為所有樣本數據集的標準差。
(2)對數據集進行層次聚類預聚類
計算類簇之間的距離,常用的方法有:最小連接距離法、最大連接距離法、平均連接距離法。采用適用于類別型數據的平均連接距離法計算距離公式如式(3)所示,將數據集中所有數據都當作是一個獨立的類簇,對于給定的聚類簇Ci和Cj,找到距離最小的兩個類簇C1和C2
dmax(Ci,Cj)=|mi-mj|
(3)
其中,mi是簇Ci的均值,mj是簇Cj的均值。
合并距離最小的C1和C2為一個類簇,然后不斷合并距離最近的聚類簇,并對合并得到的聚類簇距離矩陣進行更新。不斷重復上述過程,直至達到K個聚類簇。
(3)分別計算K個類簇中每個對象的局部密度和高密度點距離。
把每個聚類簇中的所有數據對象作為一個子集,分別計算每個子集中每個數據對象的局部密度,局部密度計算公式如式(4)所示
(4)
其中,dij表示任意的數據對象xi和數據對象xj之間的距離,用歐氏距離進行計算,計算公式如式(5)所示
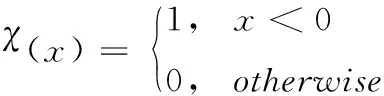
(6)
dc是一個截斷距離參數,設置dc為數據量的1%,把每個樣本點和所有樣本點的距離與先前設定好的截斷距離相比較,所有小于截斷距離的點的個數就是這個樣本點的局部密度大小。
接著,計算高局部密度點距離如式(7)所示
(7)
(4)選取聚類中心
ρi和δi相對較高的數據點標記為簇的中心,所以計算每個子集中ρi和δi的乘積,即γi,取γi的最大值,將每個類簇中的最大值的數據點作為每個類簇中的聚類中心
γi=ρiδi
(8)
將選取出來的所有K個類簇的聚類中心作為K-Modes算法的初始聚類中心。
2.2 相異度量的計算
在傳統的K-modes算法中,相異度量的計算都是基于距離的度量方法,是以數據屬性之間的存在是獨立同分布為前提的,然而現實生活中的數據的屬性之間都是非獨立同分布的。在Wang的文章里將非獨立同分布的思想加入到K-Modes算法的相異度量的計算中與Ahmad等提出的ADD相異度量的計算方法進行了實驗比較,發現在數據結構分析和聚類質量方面,提出的方法優于其它類別型數據的相異度量的方法。所以將非獨立同分布的思想加入到K-Modes算法的相異度量的計算中是可行的。
在Wang改進的K-Modes的算法中屬性之間的耦合相似度的權重參數認為每個屬性的重要程度是均等的,不能反映屬性間真實的權重參數。互信息反映的是任意兩個對象的聯合分布相對于假定兩個對象是獨立情況下的聯合分布之間的內在依賴性,度量兩個事件集合之間的相關性,屬性之間的耦合相似性體現的就是某個屬性值與其它屬性值的共現依賴關系,所以可以采用計算互信息的方法來計算屬性之間的權重關系,在本文中計算屬性之間的互信息后對互信息進行標準化,得到屬性的權重矩陣,更好反映出每個屬性的重要程度以及更加合理改進了計算對象差異度量的方法。
設數據集集合為U={u1,u2,…,um}, 表示一組非空的m個數據對象組成。A={a1,a2,…,an}, 表示每個數據對象包括n個屬性,是一組有限的屬性。V=∪j=1nvj表示的是屬性值集,Vj是屬性aj的值的集合。
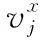
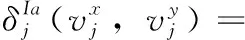
(9)
IaASV反映的是屬性的屬性值頻率之間的關系,頻率近似相等的兩個屬性值具有較大的相似性。
(10)
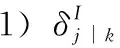
(11)
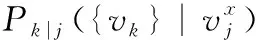
(12)
2)αk是屬性ak的權重參數,利用標準化互信息求取權重矩陣對αk賦值,計算公式如式(13)所示
(13)
I(ai,aj) 是指屬性ai和aj的互信息。計算公式為式(14)
(14)
其中,p(vi),p(vj) 分別是屬性值vi和vj在數據集U中的概率分布函數。p(vi,vj) 是屬性值vi和vj在數據集U中的聯合概率分布函數,計算公式如式(15)所示
p(vi,vj)=p(vi)·p(vj)
(15)
H(ai) 表示的是屬性ai的信息熵,計算公式為
(16)
(3)對象的耦合屬性不相似性(CADO)為
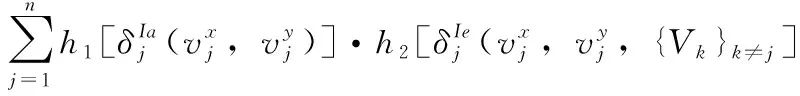
(17)
令h1=1/t-1,h2=1-t,h1(t),h2(t), 都是關于t的遞減函數,滿足相似性和不相似性的互補性。
計算相異度量的步驟為:
步驟3 求取權重矩陣對對αk賦值
步驟4 計算任意兩個對象ux和uy之間的對象耦合屬性不相似性CADO,得到數據對象間的距離矩陣作為數據對象之間的相異度量。
本文選取Breast-cancer數據集中的一個片段為例計算數據片段的相異度量矩陣,6個對象具有8個屬性,分為兩類,具體信息見表1。
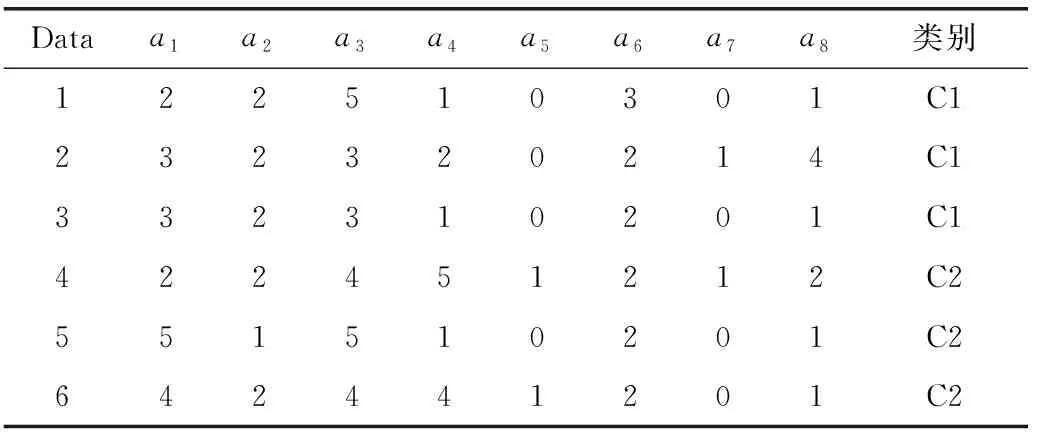
表1 Breast-cancer數據片段
將表1 按照相異度量的計算方法,計算出表1的相異度量見表2。
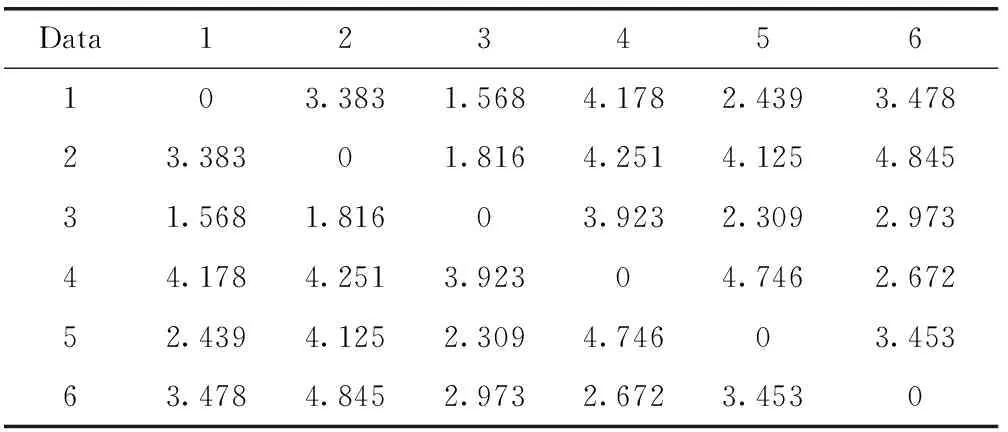
表2 數據片段的相異度量
2.3 算法描述
輸入:數據集,聚類類簇個數K。
輸出:聚類后劃分好的子類集合。
步驟1 按照2.1中的思想選取K個聚類中心。
步驟2 根據2.2中方法計算數據集中任一數據對象ux與選取的聚類中心之間的相異度量。
步驟3 將每個對象分配到與聚類中心相異度量最小的子類中。
步驟4 分配結束后,通過基于頻率的方法來重新確定聚類中心。
步驟5 重復上述的步驟2~步驟4,直到所有數據對象所屬的聚類中心不再變化時,算法結束。
以上是對K-Modes算法初始聚類中心的選擇和相異度量進行了改進,考慮到數據之間的屬性相似性,更好地處理了類內間相似性的問題,解決了傳統K-Modes算法隨機選取中心點和計算相異度量時忽略了類內相似性的問題,更好提高了算法的聚類效果。
3 實驗結果及分析
本文實驗在UCI數據集分別是Zoo數據集、Breast-cancer數據集及Soybean-small數據集這3個數據集上進行實驗驗證。
實驗環境:MATLAB R2019b,Intel(R) Core(TM) i7-6700CPU、3.40 GHz、8.0 GB,Microsoft Windows 7。
3.1 實驗描述
本文改進了傳統隨機選取中心點的缺點,并改進非獨立同分布的公式引入到計算K-Modes算法的相異度量中,主要目的是提升K-Modes算法的聚類精度,避免選取初始聚類中心的時候選到離群點或者同一類別的情況,同時使屬性的權重參數更加合理化,更加準確的將屬性內耦合和屬性之間的耦合的相似性加入到計算數據對象的相異度量中。
本文分別在Zoo數據集、Breast-cancer數據集和Soybean-small數據集上進行了實驗驗證。將數據集在相同的環境中分別在傳統的K-Modes算法、Wang改進的K-Modes算法(簡稱Wang)、文獻[16]和NonIID-HDK-Modes的算法程序中運行20次,分別記錄下每個算法聚類的正確率。
3.2 實驗結果
3.2.1 數據集描述
3個數據集的描述見表3。
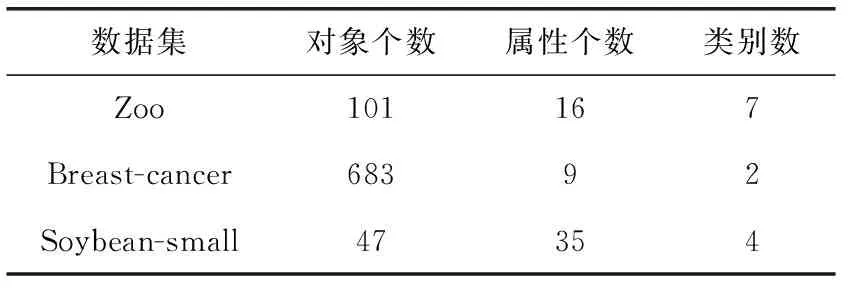
表3 數據集信息
3.2.2 實驗對比結果
下面分別從分類正確率(AC)、類精度(PR)、召回率(RE)這3個方面來分析算法的聚類質量,AC、PR、RE的定義分別如下
其中,U表示的是數據集中的對象的數量,K表示的是聚類類簇的個數,xi表示可以正確分到第i類的對象數量,yi表示錯誤分到第i類的對象數量,zi表示應分到卻沒分到第i類的對象數量。
在Zoo數據集、Breast-cancer數據集和Soybean-small數據集3個數據集中,驗證傳統的K-Modes算法、Wang、文獻[16]的算法和NonIID-HDK-Modes算法。4個算法在相同的環境中運行20次取平均值,具體聚類算法性能比較見表4~表6和圖1。
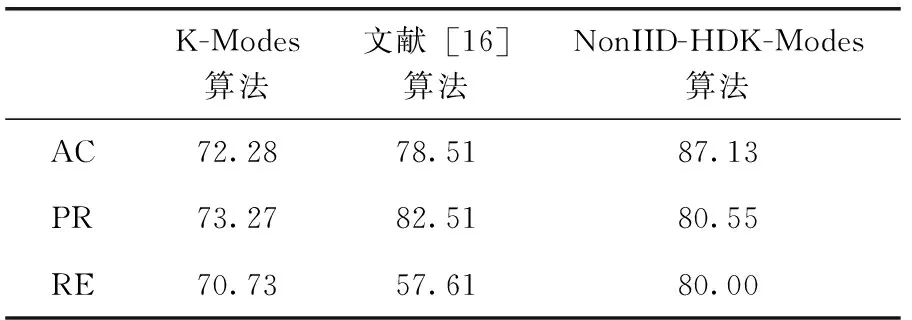
表4 在Zoo數據集下性能比較/%
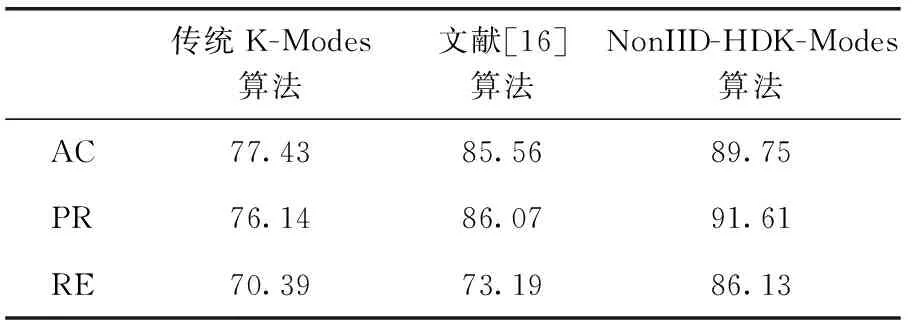
表5 在Breast-cancer數據集下性能比較/%
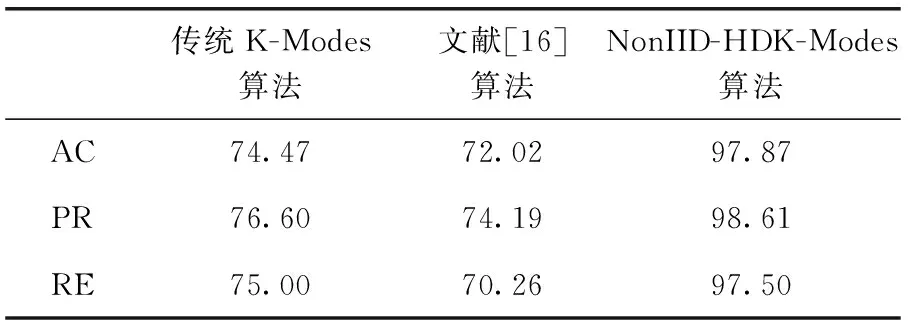
表6 在Soybean-small數據集下性能比較/%
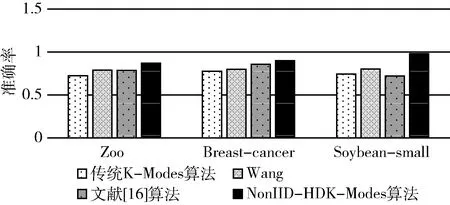
圖1 4種算法的準確率
通過分析圖1,可以發現在非獨立同分布思想下,NonIID-HDK-Modes算法比Wang算法中改進K-Modes算法相異度量的聚類效果更好,準確率更高。
通過分析表4~表6,可以看到在數據集Zoo、Breast-cancer和Soybean-small上,經過修改非獨立同分布思想下計算耦合相似性的權重參數和初始聚類中心點選取方法的K-Modes算法與獨立同分布條件下的K-Modes算法的對比,NonIID-HDK-Modes算法獲取了較好的聚類效果,聚類結果優于文獻[16],驗證NonIID-HDK-Modes算法是有效的。
3.3 實驗分析
根據實驗得到的結果,可以看到Wang的算法在非獨立同分布的思想下把屬性內和屬性之間的相似性一起加入到計算相異度量時,聚類效果會相比傳統的K-Modes算法有一定的提高。因此,把非獨立同分布的思想引入到K-Modes算法中是可以提高算法的聚類效果的,是可行的。
通過圖1我們可以看到,在非獨立同分布的條件下,在相同的運行環境下3個數據集中NonIID-HDK-Modes算法與Wang對K-Modes算法的改進相比,可以更好提高聚類算法的準確率,說明改進耦合權重和初始聚類中心的選取方法是有效的。
由實驗結果可以看到,基于非獨立同分布的思想的NonIID-HDK-Modes算法在Zoo數據集中,相比較文獻[16]的方法聚類準確度提高了8.62%;在Breast-cancer數據集中,相比較文獻[16]的方法聚類準確度提高了4.19%;在Soybean-small數據集中,相比較文獻[16]的方法聚類準確度提高25.85%。在Zoo數據集和Soybean-small數據集與Breast-cancer數據集的準確率提高的較多,兩個數據集中的數據較少,算法準確率的提高較為明顯,對于數據集中數據較多的情況,算法的準確率效果較為不明顯。因此,NonIID-HDK-Modes算法可以更好提高較小數據集的聚類準確率,對于提高較大數據集的準確率存在不足。
通過比較聚類的純度大小,判斷算法聚類效果的好壞,當聚類的純度越接近1,說明算法聚類的效果越好。傳統K-Modes算法、文獻[16]和NonIID-HDK-Modes算法在3個數據集上的純度見表7,在Zoo和Soybean-small兩個數據集上,NonIID-HDK-Modes算法表現較好,聚類的效果更好。在Breast-cancer數據集上,文獻[16]的聚類效果更好,說明改進的算法在整體上還是能夠有效提高算法的聚類純度,提高聚類的效果,這得益于非獨立同分布的思想。
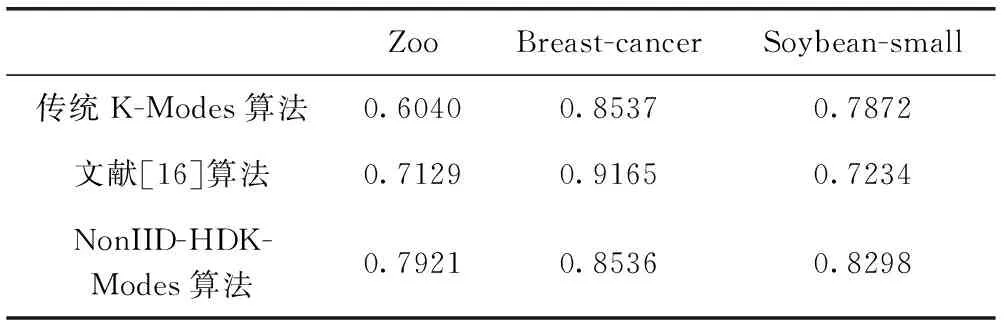
表7 3種算法的純度比較
4 結束語
在本文中針對K-Modes算法隨機選取初始聚類中心的缺點,首先對數據集通過層次聚類預聚類對數據集進行類別劃分,然后再分別計算每個類別中所有對象的局部密度和高密度點距離,選擇兩個距離乘積的最大值作為每個類別的一個聚類中心,逐一選取每個類別的聚類中心,并將所有類別的聚類中心作為算法的初始聚類中心。同時傳統的K-Modes算法計算相異度量時,忽略了數據對象之間的聯系,在本文中根據非獨立同分布的思想計算相異度量,并且在非獨立同分布的基礎上繼續改進計算屬性耦合相似性權重參數的方法,計算兩列間的標準化互信息作為權重矩陣。實驗結果表明,本文在非獨立同分布的思想下提出的NonIID-HDK-Modes算法具有較高的準確率,可以提高K-Modes算法聚類的效果,更加符合現實中數據的實際情況。
