基于漢明權重分組的自適應查詢樹算法
2023-01-31 03:56:48侯培國張小賀田昊瑋
計算機工程與設計 2023年1期
侯培國,張小賀,田昊瑋
(燕山大學 電氣工程學院,河北 秦皇島 066004)
0 引 言
射頻識別(radio frequency identification,RFID)技術是一種以空間電磁波為傳輸媒介的自動識別技術[1-3]。但是在RFID系統中,由于所有的標簽在傳輸數據時都是通過同一信道,極易發生標簽之間的碰撞,進而導致閱讀器無法正確地讀取標簽信息[4]。因此設計一種有效的防碰撞算法,高效、精準識別標簽是當前RFID系統急需解決的問題。
目前,主要有基于ALOHA的概率性算法[5,6]和基于二進制樹的確定性算法[7,8]用于解決標簽的碰撞問題。基于二進制樹的確定性算法,可以很好解決ALOHA算法出現的標簽“饑餓”現象,具有100%的識別率[9],其中,最典型的方法就是查詢樹算法及其改進算法,如文獻[10]提出的IACT算法結合了二叉樹和四叉樹算法的優點,有效減少了查詢過程中產生的空閑時隙,但會增加碰撞時隙;文獻[11]提出的PACT算法通過自適應方法和并行匹配機制減少了消耗的總時隙數,但對空閑時隙沒有優化;文獻[12]提出的BAT算法通過設計基于特征值的分組規則,提高了系統效率,但仍存在空閑時隙;文獻[13]在文獻[14]的基礎上,結合ALOHA算法和查詢樹算法,提出的CF-AMTS算法是將標簽映射到不同的時隙中,然后根據不同的碰撞因子調整搜索方法,從而減少查詢過程中產生的空閑時隙,提高系統吞吐量;文獻[15]提出的GMQT算法則是將標簽均勻分為4組,然后利用分組后的碰撞信息對標簽前綴進行預測,從而減少空閑時隙的產生。
本文在上述算法的基礎上,針對如何減少空閑時隙進一步研究,提出了基于漢明權重分組的自適應查詢樹(adaptive query tree based on Hamming weight grouping,HAQT)算法,該算法只關注3個連續比特中的碰撞比特位,首先閱讀器根據碰撞比特位的個數自適應地選擇不同的查詢機制,然后依據不同查詢機制中的碰撞位特征推斷標簽可能存在的查詢前綴,最后通過構建標簽集識別系統中未被識別的標簽。
1 算法描述
1.1 設計思想
為了消除查詢過程中產生的空閑時隙,提高系統效率,HAQT算法對空閑時隙進行了優化。整體思路是通過調整標簽的分組情況,在不增加新查詢命令的基礎上,自適應選擇不同的查詢機制,從而根據標簽的碰撞信息實現對標簽前綴的準確預測,最后通過構建標簽集判斷標簽是否全部識別完成。
在查詢過程中,閱讀器每次僅關注3個連續比特中的碰撞比特位,然后依據碰撞比特位的個數決定采用何種查詢機制,并根據不同查詢機制中的碰撞位特征實現對當前標簽前綴的準確預測。在該算法中有3種不同的查詢機制,如下所示:
Type1:當從最高碰撞位開始只有一個碰撞比特位時,閱讀器直接將碰撞位置為0和1,即可得到新的前綴。
Type2:當從最高碰撞位開始有兩個碰撞比特位時,閱讀器將這兩個碰撞位提取出來,并執行式(1)~式(4),將碰撞位映射成一個4位且漢明權重為1的識別碼,由于映射后的識別碼和標簽是一一對應的,因此閱讀器只需要根據映射碼的碰撞位就可以推斷出標簽的前綴組合
y1=x1&x2
(1)
(2)
(3)
(4)

Type3:當從最高碰撞位開始有3個碰撞比特位時,即XXX,則閱讀器按照漢明權重原則對標簽進行分組,并根據標簽識別碼中非0字符的數目計算漢明權重,然后將具有相同漢明權重的標簽分為一組,于是得到標簽識別碼碰撞比特位的分組情況見表1。在標簽分組完成后,閱讀器首先判斷標簽的二進制組號是否發生碰撞,若組號發生碰撞,則將返回的分組信息進行映射,并根據映射后的碰撞信息確定標簽前綴對應的組號;若組號沒有發生碰撞,則閱讀器可以直接判斷出標簽的組號;當組號確定后,將組號存入堆棧S。由于在00組和11組中的標簽識別碼只有一個,所以當存在00組和11組的標簽時,閱讀器根據組號就可以推斷出存在的標簽前綴為000和111;然而在01組和10組中存在多個標簽識別碼,所以當組號確定后,還需再次進行檢測,在01組中比特1的個數只有一個,而在10組中比特1的個數有兩個,因此閱讀器根據01組和10組中標簽識別碼的組號和具體碰撞信息,就可以推斷出相應的前綴組合。例如,在RFID系統中存在的標簽是001和010,標簽向閱讀器發送自身識別碼和組號RGC,閱讀器接收到標簽發送的信息為0XX和RGC=01,由于當RGC等于01時,漢明權重為1,即該標簽的前綴中只有一個比特1,因此閱讀器只需將碰撞位置為比特0和比特1,就可以推測出當前的標簽前綴為001和010。
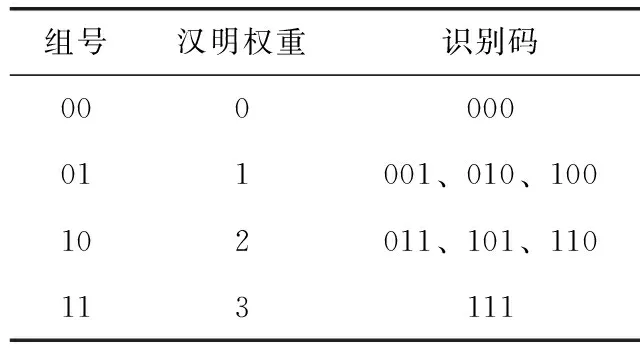
表1 漢明權重分組
1.2 相關指令
(1)Query(PRE)表示查詢指令,PRE是標簽前綴,閱讀器發送Query(PRE)指令后,前綴與PRE相同的標簽開始響應閱讀器,并返回除前綴外的其余識別碼信息;
(2)Query(PRE,RGC)表示查詢指令,PRE是標簽前綴,RGC是前綴組號,閱讀器發送Query(PRE,RGC)指令后,前綴與PRE相同且屬于RGC組的標簽開始響應閱讀器;
(3)PUSH(PRE)表示讀寫指令,發出此指令后閱讀器將前綴PRE存入堆棧Q中;
(4)POP(PRE)表示讀寫指令,發出此指令后閱讀器將前綴PRE從堆棧Q中彈出;
(5)‖表示位串聯指令,將兩組數據連接。
1.3 算法流程
HAQT算法的具體流程如圖1所示。
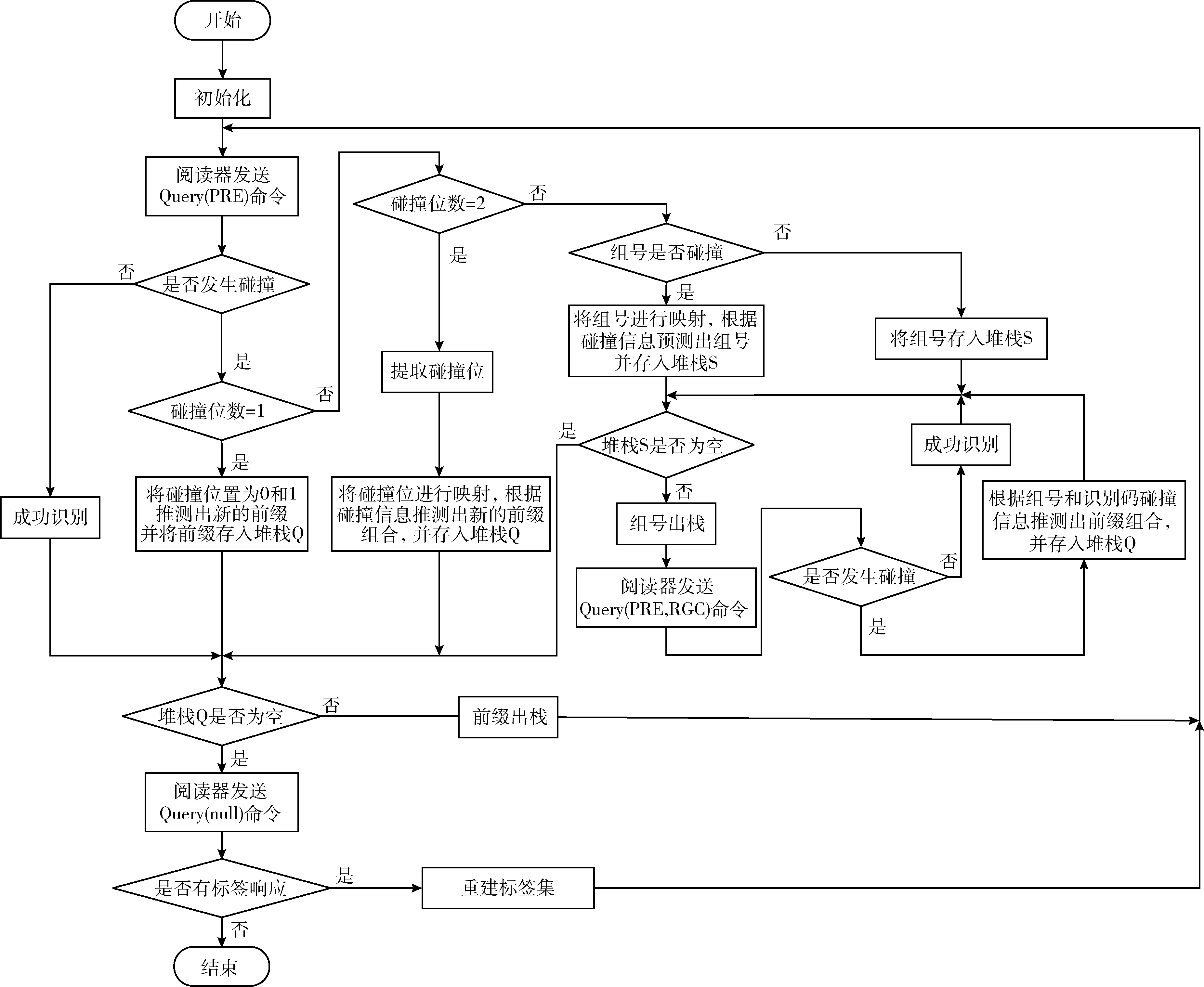
圖1 HAQT算法流程
(1)初始化,將閱讀器內部的堆棧Q和堆棧S置為空;
(2)閱讀器發送Query(PRE)指令,標簽接收該指令后,開始響應閱讀器,由靜默狀態轉向活躍狀態,同時將自身的識別碼發送給閱讀器;
(3)閱讀器判斷標簽是否發生碰撞,若發生碰撞,則執行步驟(4);若未發生碰撞,則說明標簽識別成功,于是執行步驟(5);
(4)閱讀器根據碰撞比特位的個數選擇相應的查詢機制推測標簽的前綴pipi+1pi+2, 并發送PUSH(PRE‖pipi+1pi+2) 指令,將新產生的前綴PRE‖pipi+1pi+2存入堆棧Q,并跳至步驟(6);
(5)閱讀器對標簽的識別碼進行讀取,并將該標簽置為靜默狀態,然后執行步驟(6);
(6)閱讀器確定堆棧Q是否為空,若不為空,則閱讀器發送POP(PRE)指令,將堆棧Q中的新前綴PRE出棧,并跳至步驟(2);若為空,則執行步驟(7);
(7)閱讀器發送Query(null)指令,此時,若有標簽響應,說明存在標簽還沒有被識別,于是重建標簽集,并跳至步驟(2),繼續識別未被識別的標簽;若無標簽響應,說明標簽已經全部識別完成,則查詢結束。
1.4 算法實例分析
下面分別通過一個實例來介紹3種不同的查詢機制,如圖2所示。

圖2 HAQT算法不同查詢機制流程
2 算法性能分析
在防碰撞算法中,時間復雜度(即消耗的總時隙數)和吞吐量是評判算法性能優劣的關鍵指標。因此下面分析了隨著標簽數目變化時,多叉樹算法消耗的時隙數目與吞吐量的變化情況。假設RFID系統中存在m個標簽,通過文獻[16]可以得到一個B叉樹消耗的總時隙數為
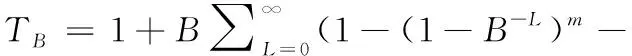
(5)
碰撞時隙數為
(6)
空閑時隙數為
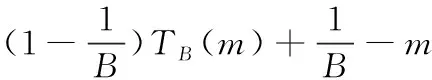
(7)
在標簽的查詢過程中,主要存在以下情況:
(1)當沒有碰撞位時,消耗的總時隙數為
TType0(m)=m
(8)
(2)當只有一個碰撞比特位時,不會產生空閑時隙,消耗的總時隙數為
TType1(m)=T2(m)
(9)
(3)當有兩個碰撞比特位時,通過映射可以有效的消除空閑時隙,消耗的總時隙數為
(10)
(4)當有3個碰撞比特位時,通過對其進行分組,可以消除空閑時隙,分組后消耗的時隙數為
(11)
然而當組號發生碰撞的時候,需要二次發送命令才能確定相應的前綴,為了更加準確進行理論分析,于是對二次發送命令消耗的時隙數進行擬合,如圖3所示。
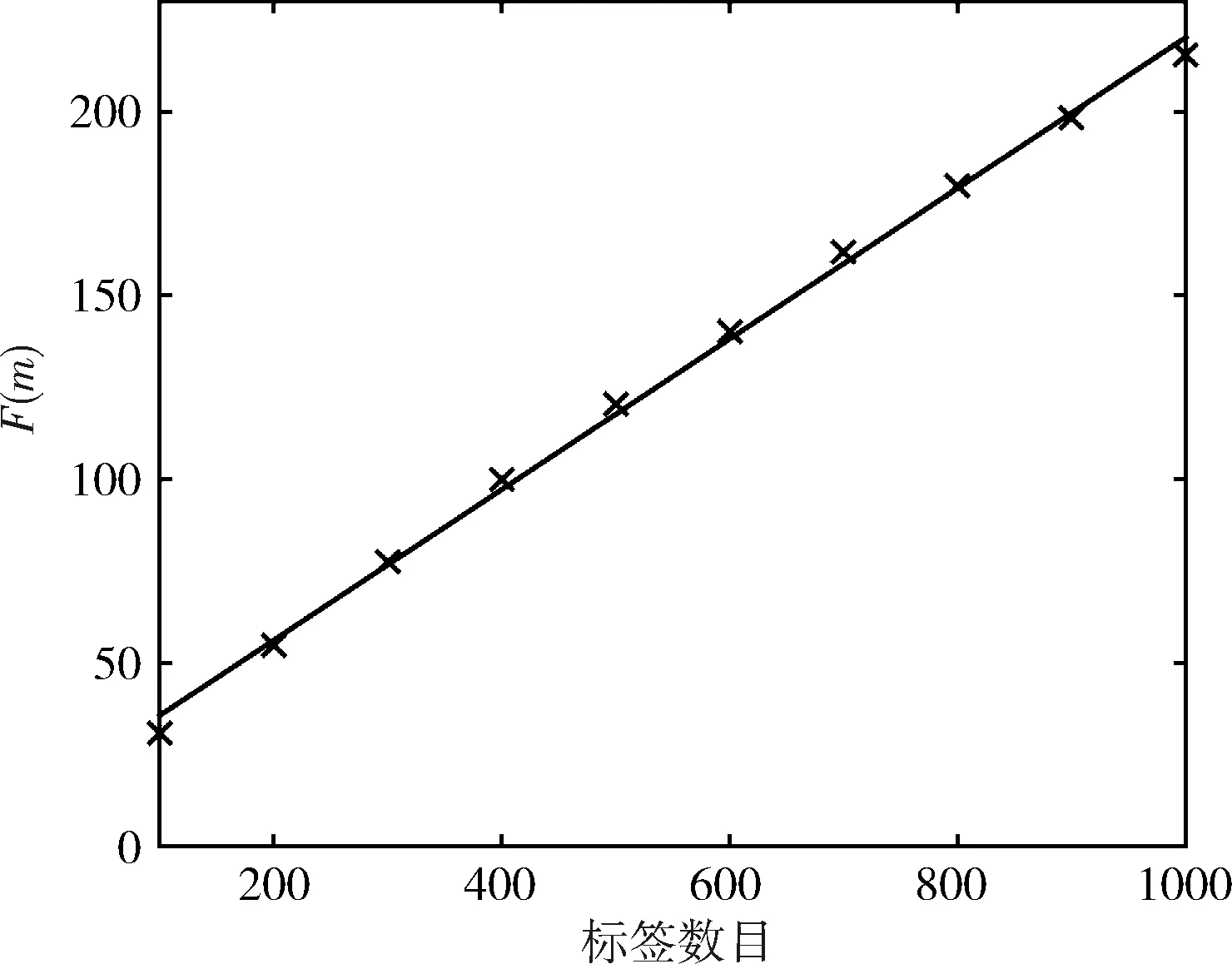
圖3 仿真擬合
經過對二次發送命令消耗的時隙數進行擬合,得到二次發送命令消耗的時隙數F(m)為
F(m)=0.2052m+15.066
(12)
整理后得到在Type3查詢方式下消耗的總時隙數為
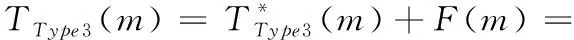
(13)
下面針對在不同查詢方式中標簽發生碰撞的概率進行計算,假設當RFID系統中存在i個標簽時,其中任意一個比特不發生碰撞的概率為
(14)
任意一個比特發生碰撞的概率為
(15)
在連續的3個比特中,沒有發生碰撞的概率為
(16)
在連續的3個比特中,從最高碰撞位開始,有一個碰撞比特位的概率為
(17)
在連續的3個比特中,從最高碰撞位開始,有兩個碰撞比特位的概率為
(18)
在連續的3個比特中,從最高碰撞位開始,有3個碰撞比特位的概率為
(19)
由于HAQT算法是根據每3個比特中碰撞比特位的個數自適應地選擇不同的查詢機制,因此得到HAQT算法消耗的總時隙數為
THAQT(m)=P0TType0(m)+P1TType1(m)+
P2TType2(m)+P3TType3(m)
(20)
得到吞吐量為
(21)
3 仿真結果與分析
在本文中,利用Matlab2014b平臺對RFID系統的通信過程進行了模擬仿真。假設該系統為理想信道,標簽在閱讀器范圍內均勻分布,并且參考EPC C1G2標準,隨機生成數量從100到1000變化,長度為96位的唯一標簽識別碼,最后結果取50次仿真的平均值。下面通過仿真定量分析了HAQT算法、BAT算法、CF-AMTS算法和PACT算法消耗的總時隙數、吞吐量和通信復雜度的變化情況。
為了驗證理論分析的正確性,首先對HAQT算法的理論分析和仿真實驗進行了比較,如圖4(a)和圖4(b)所示。通過圖4(a)和圖4(b)可以看到,在查詢過程中,該算法消耗的總時隙數和吞吐量的理論值和仿真值基本吻合,其吞吐量的最大相對誤差不超2.8%,在誤差允許的范圍內,所以可以認為該理論分析和仿真實驗是一致的。
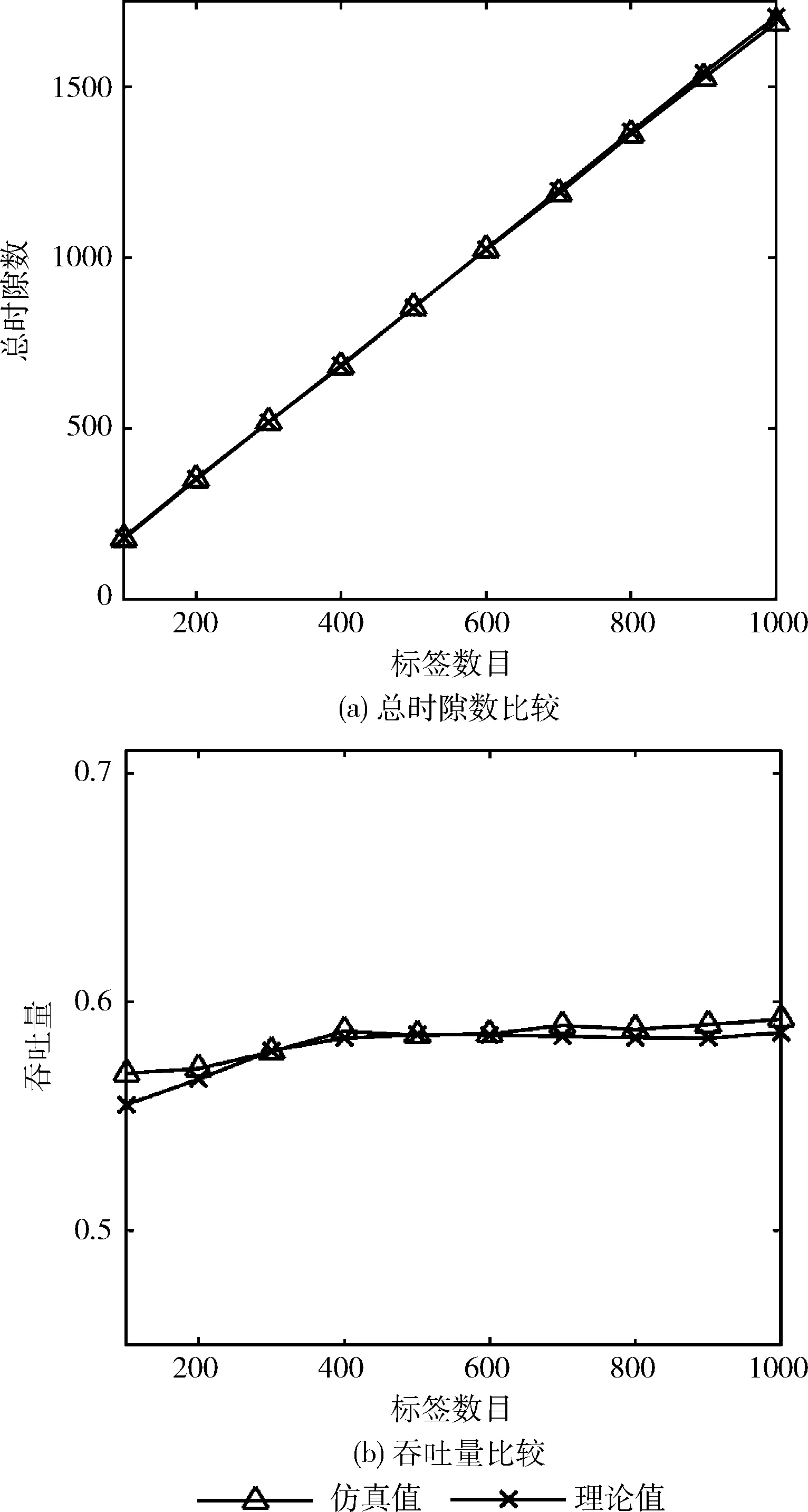
圖4 理論值和仿真值比較
圖5為HAQT算法、BAT算法、CF-AMTS算法和PACT算法的總時隙數比較。由圖5(a)可知,在識別相同數量的標簽時,BAT算法、CF-AMTS算法和PACT算法消耗的總時隙數均大于HAQT算法消耗的總時隙數,且隨著標簽數量的增加,HAQT算法的優勢會更加明顯。在標簽數量等于1000時,該算法消耗的總時隙數目僅為1678,這主要是由于HAQT算法通過采用自適應的查詢方法,實現了對標簽前綴的準確預測,通過減少空閑時隙降低了消耗的總時隙數。空閑時隙的變化情況如圖5(b)所示,可以看出HAQT算法完全避免了空閑時隙的產生。
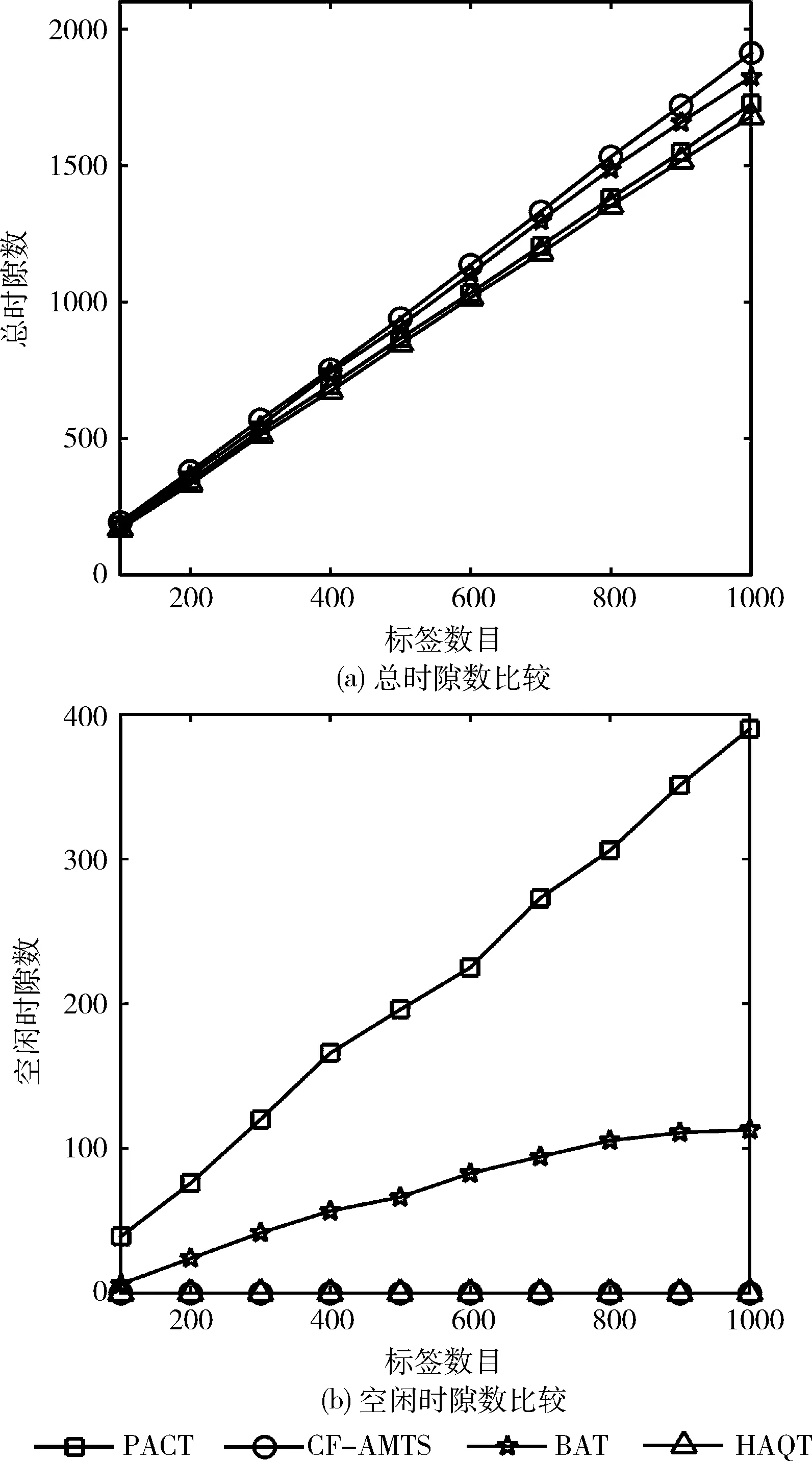
圖5 各種算法消耗的時隙數比較
圖6為HAQT算法、BAT算法、CF-AMTS算法和PACT算法的吞吐量比較。由圖6可以看出,HAQT算法的吞吐量維持在0.60左右,相比于 PACT算法提升了1.7%,相比于BAT算法提升了11.1%,相比于CF-AMTS算法提升了17.6%。

圖6 各種算法吞吐量比較
圖7為HAQT算法、BAT算法、CF-AMTS算法和PACT算法的通信復雜度比較。從圖7可以看到HAQT算法的通信復雜度最低,當待識別標簽數量為1000時,該算法的通信復雜度為2.26×105,這是由于HAQT算法通過調整標簽的分組方法,減少了無效數據傳輸。
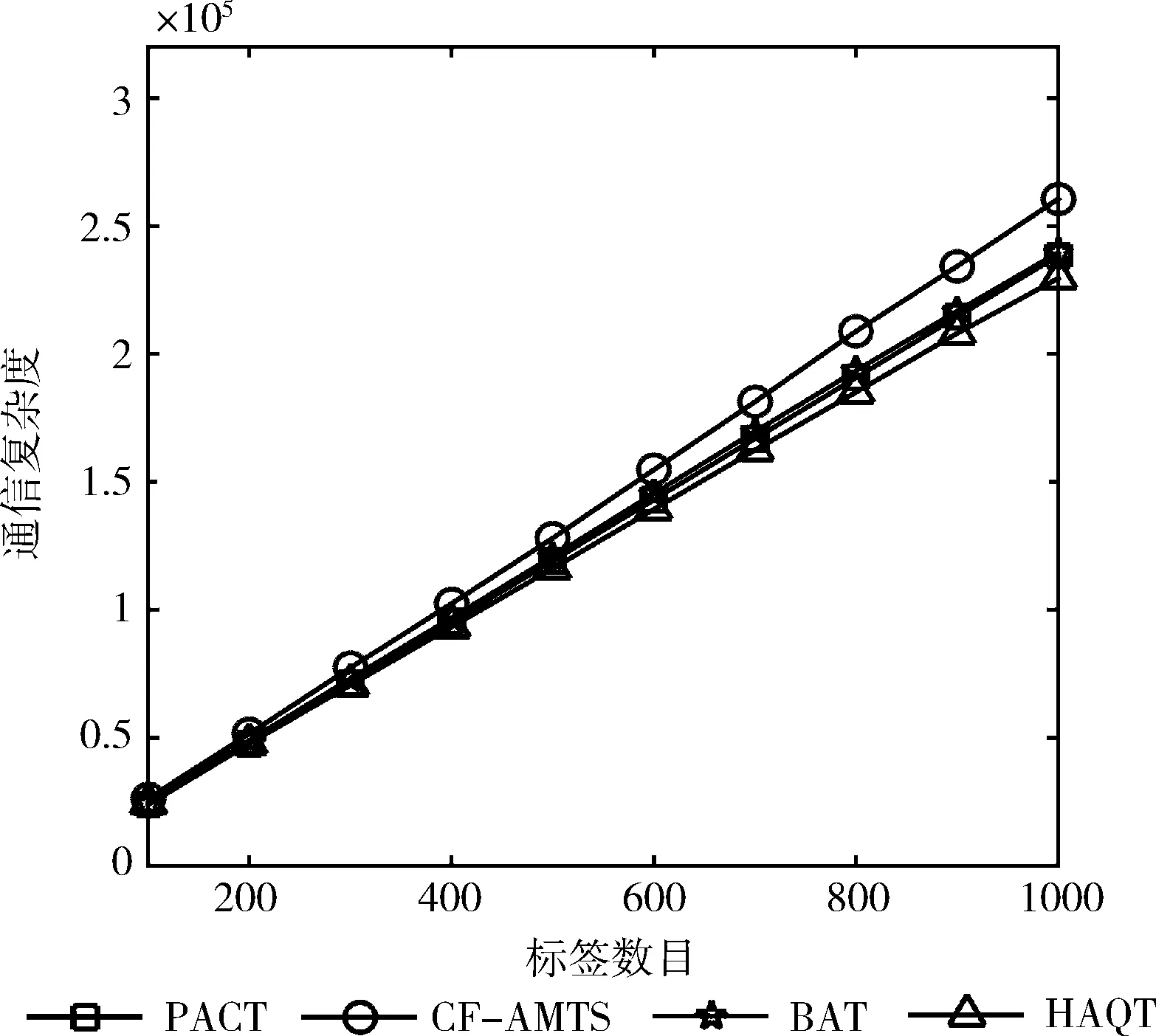
圖7 各種算法通信復雜度比較
表2顯示了不同算法的性能比較。從中可以看到,HAQT算法通過根據碰撞比特位的個數自適應的選擇不同的查詢機制,并采用漢明權重方法對標簽前綴進行分組,實現了對標簽前綴的準確預測,減少了查詢過程中產生的空閑時隙,從而使該算法性能明顯的優于其它算法。另外,該算法通過重建標簽集的方式識別上一個階段中未被識別的標簽,因此還具有一定的抗捕獲作用[17]。
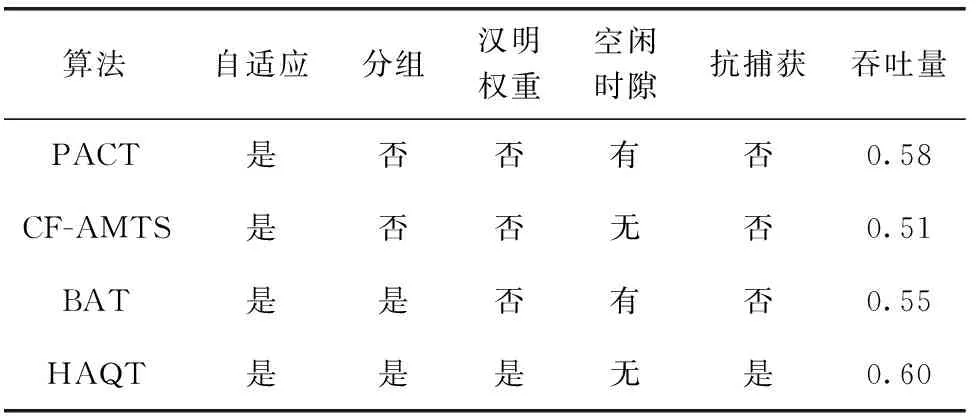
表2 不同算法整體性能比較
4 結束語
在本文中結合分組思想和查詢樹算法,提出一種基于漢明權重分組的自適應查詢樹算法,首先根據每3個比特中碰撞比特位的個數自適應地選擇不同的查詢機制,然后依據不同查詢機制中的碰撞位特征推斷標簽可能存在的查詢前綴,從而降低查詢過程中產生的空閑時隙,最后通過構建標簽集,判斷標簽是否全部識別。仿真結果顯示,HAQT算法能夠消除查詢過程中產生的空閑時隙,且消耗的總時隙數、吞吐量和通信復雜度均優于PACT、BAT和CF-AMTS算法,吞吐量最高可以達到0.60,且具有一定的抗捕獲作用,適合在大規模標簽的RFID系統中應用。下一步的工作是對該算法的抗捕獲功能進一步改進,并進行定量分析。
