高校教師信息素養指標體系研究
——基于RreliefF特征選擇算法
2022-08-29 09:36:34曾慧平
中國新技術新產品 2022年10期
曾慧平
(江西交通職業技術學院,江西 南昌 330013)
0 引言
信息素養包括文化素養、信息意識和信息技能三個層面,決定了什么時候需要什么樣的信息,在哪里能獲取到信息,并能夠評價和有效利用所需的信息。信息素養是人在信息時代所必備的技能,決定了其對社會的適應能力與對事件的應對能力。信息素養涉及多方面的內容,人文、技術、經濟、法律甚至周邊學科的專業知識,都會影響個人的信息素養水平。高校教師作為國家人才的培養者,更需要具備高層次的信息素養,以便在信息爆炸的大背景下敏銳地捕捉到先進、正確的科學知識,并傳授給學生。但是高校教師作為科研育人的特殊群體,如何評價其信息素養,如何確定具體人員的信息素養構成要素,都是一個有待深入研究的課題。
RreliefF特征選擇算法是對各個影響要素的權重進行賦值、綜合評定的一種運算方法。在算法中,首先考慮了對事件結果可能產生影響的所有影響要素,其次注重各要素間的相互作用,用發展的視角看待各要素對結果的制約作用,還可以根據初始條件的不同,動態選擇參與計算的要素種類和內容。因此RreliefF特征選擇算法可以更真實地反映模擬計算結果。
將RreliefF特征選擇算法應用于高校教師的信息素養指標評定,可以區分不同專業、不同需求教師群體的特殊性,并在歸一化的基礎條件之上客觀評價教師的信息素養。基于此思想,該文開發了高校教師信息素養指標體系。
1 基于RreliefF特征選擇算法的信息素養指標體系
1.1 RreliefF算法
RreliefF算法的基本思想是對每個屬性進行權重分配,通過迭代的方式來確定權重,再通過權重的方式來確定屬性的子集合,進而使優秀的屬性集合在一起,而非獨立的個體。對高校教師信息素養的評價,需要枚舉出影響因素。為規范評價行為,針對影響因素進行分類匯總,根據不同高校的專業領域、教師的具體研究方向,概括為人文素質選項、技術實力選項、經濟能力選項、法律儲備選項以及用于個性化定制的其他選項。在每一個選項中,還可以細分為二級考核點,例如人文素質選項中可包括人文常識、表達能力、寫作能力和文字功底等很多考核點;技術實力選項細分為專業技術、通用技術、周邊技術、融合能力和知識產權等。基于此細分原則,假設給定單標簽數據集有個類標簽,其訓練數據集記為{(,)(,)…(x,y)},其中x∈R(=1,2,…,),R為樣本特征空間,為樣本特征空間的序號,y∈R(=1,2,…,),R為樣本類別空間。如果第個樣本x屬于第k類,則記為y()=1,否則記為y()=0。因此,數據集可看作是由的特征矩陣[,,…,x]和的標簽矩陣[,,…,y]構成的,且矩陣的每一列只有1個元素值為1。
將訓練數據集輸入之后,其迭代的次數即為,樣本個數為最接近的值,特征權值向量在輸出時最明顯[6]。特征權值向量()=0.0最開始會出現數據顯現,其內容為=1,2,3,…,。在中不按規則地選取一個隨即樣本,這個隨機樣本被記作R;尋找與這個隨機樣本R一樣的最近鄰值記作,對每個類≠class(R),尋找和R不一樣類別的個最近鄰值M(),for:=1:更新每個特征權值,如公式(1)(RreliefF算法)所示。
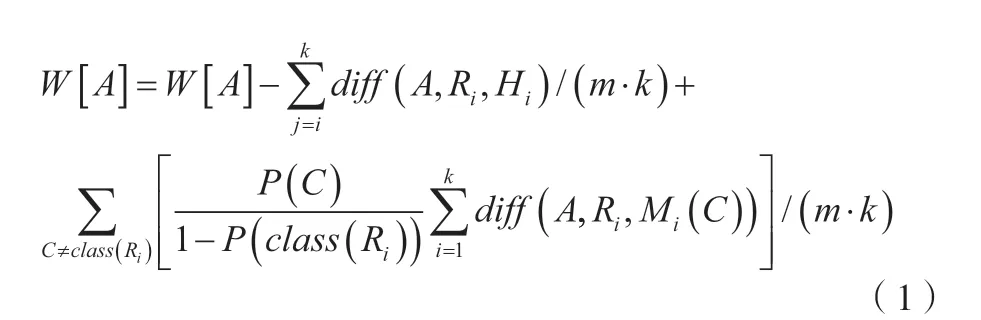
式中:[]為特征全職矩陣集合;(R)為樣本R擁有的類標簽;(,R,M())為樣本關于特征的距離;()為類別的可能性;((R))為R擁有的類標簽的可能性;M()為第C類目標的第個樣本;(·)為按照采樣大小設置和。
在確定各屬性權重后,權重較大,則說明各屬性具有較好的判別能力,由此可以利用門限選取新的特征子集,并在子集中降低維度。
該方法是在訓練集合中隨意選擇一個例子,然后對相鄰的1個例子進行檢索,在該例子中,相似(擊中)的分類樣品被稱作,而相似(錯誤)的分類樣品被稱作。基于該示例的數值對各屬性的差異值進行了評估,并按照下列準則進行加權。當1個例子和1個樣本分類的屬性數值不一樣時,這個特性會把2個執行個體從1個相同的類中分開,從而降低了1個品質評估。當1個例子和1個試品樣品的屬性數值不一樣時,它會把2個例子從1個非相似的例子中分開,并且相應地提高它們的品質。上述步驟反復多次,最終求出每個特性的加權平均值,各屬性的權值愈高,則其分類性能愈好;相反,則表明此特性的分類性能較差。從算法上可以看到,在尋找最接近領值時,只把每一個樣品歸入1個類別,并沒有將這個樣品歸入多個類別(也就是多標記的資料),并且在步驟中,特征權的計算也沒有將多類別標記的貢獻度計算在內,所以ReliefF為單一標記,不能用于多標記的屬性選取,多標記的選取還需要更深入探討。
1.2 多類數據處理
RreliefF是一種求解多類別數字挖掘的擴展方法,其實質是將多個類型的問題分解成單一對多個的問題。RreliefF是一種擴展的方法,該方法利用多重隨機取樣把多個屬性選取問題分為2個類型。從各個分類中隨意選取2種不同類型的情況,可以不做任何修改。采用RreliefF方法對這2種類型問題進行分類后,將各類型的屬性權重合并,進而得出最終的屬性評估。ReliefF并未考慮多個分類的情況下,搜索的最鄰近和屬性權重的變化情況,很明顯不適合多標記的特征選取。為了解決這個問題,該文設計把ReliefF方法推廣到多標記問題,并在此基礎上給出了1種多標記的特征選取方法。
假定樣本所具有的類別標記對其的貢獻是相同的,在屬性權重計算中添加了貢獻度,并對其進行了修正。在查找最近鄰時,需要先找到樣本擁有的個類標簽,記=(,,…,h),然后分別考慮每個類標簽h=(=1,2,…,),該方法可以有效地克服ReliefF方法無法處理多類的共現問題。多標記的訓練資料集合在標記矩陣中,每個欄的取樣可以歸入多個分類,因此每個欄的單元數值是1。在ReliefF算法中,W是選取樣本,R是每個類標簽對其的貢獻程度,其他參數基本一致。用1表示樣品的全部標記貢獻的總和,則樣本R每個標簽的貢獻值W為1/,這種方法通常叫作一范式加權方法。該權值分布將多標記與單一標記的資料并列,但多標記的資料包括了更多的資訊,應該給予更多的關注與更大的權值。另外一個是使用了一個簡單的加權指派,即每類對樣本R的貢獻都設為1(稱單位權重法),那么它的全部貢獻是標記數目的總和。
該方法將類別標記的權值與標記數目相等,許多試驗結果顯示該權值的分配方式再次強調了多重標記的重要性。根據標準規范化的思路,將各標記權重因子之和設為1,則每個標簽的貢獻值W定為范權重法。在強調多個標記的同時,不能設置多個標記的加權,如果樣本R有1個類標簽,貢獻值W的值總為1,這說明ReliefF算法是一種特殊情況。
1.3 特征選擇
特征選擇的屬性抽取是將原資料中的變量進行線性或非線性結合,生成新的群組變量,進而獲得與所要解決的問題有關的某些問題。該文提出一種基于偏極最小二乘子的方法來驗證該方法的正確性,設計了一種基于多元統計的新分析模型。該算法將、這2個變量都進行了拆分,分別從、中隨機抽取各分量(一般稱作“因素”),然后根據這些因素的相互關系由大到小依次進行排序。這種算法的目的主要是利用最少的方差來尋找一套最好的函數,也就是利用一種簡便的算法來獲得某些不知道的真數值,并使2個錯誤的平方和最少。偏最小二乘法近似為多元線性回歸,結合經典相關性和主成份分析,將其應用到多元線性回歸的研究中的最簡化的方法是,用單一的線性模式對和預期組的相關性進行分析。基于上述方法,該文提出了一種基于濾波的特性篩選方法,該方法在對該特性進行評估時,根據該特性的基本性質,對各特征行進行相應的打分,此計算方法無須借助RreliefF就可進行。假設是所有消息的集合,且={,,…,x},()是給定消息的概率,那么的熵()的定義為公式(2)所示。
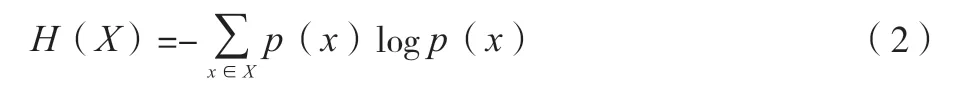
在信息學中,互信息是一種重要的信息測量方法。概率理論與信息學都可以利用2個隨機變數的交互信息使它們彼此依賴,在范圍內交互信息(;)的表達式為公式(3)所示。
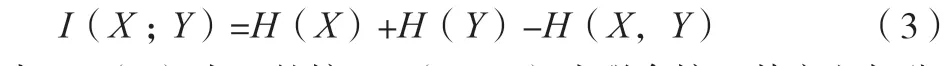
式中:()為的熵;(,)為聯合熵,其定義如公式(4)所示。
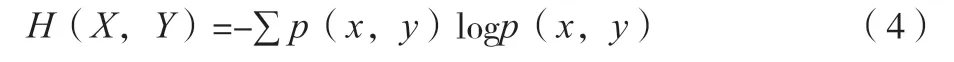
式中:(,)為特征選擇結果的最終概率。
在采用5類信息篩選方法進行分類評估時,一般會先將其與分類的相關資訊分開,若資訊數值高,說明該特性與分類之關系愈大,也就是該特性對分類的辨識能力更強。把各屬性按互信息量的遞減順序排列,可以得出各屬性對分類的優劣程度。在資訊增益方面,通過觀測特性所能給的分類體系的訊息數目便可以測度該特性是否有類別分的能力,此即是資訊擴增的基礎概念,1個特性為分類所能提供的資訊愈多,則該特性愈具價值。1個特性在1個特定的屬性集中,其信息的數量會隨著時間的推移而改變,其大小就是該特性所能提供的信息,即為教師個人的信息素養評價結果。
2 對比試驗
2.1 試驗準備
試驗內容包括2個方面:一個是ReliefF法中的不同貢獻度的計算,另一個是對比了各種特征選取方法。試驗選用KNN作為分類器(為3),使用5 fold交叉校驗,按特征權大小由大到小選擇。該研究選取3位教師的信息素質之綜合指數資料,其中的數據集包括很多部分,這3個數據集的情況見表1。
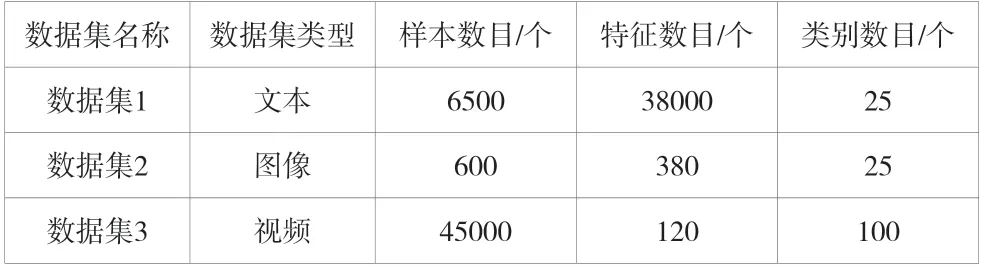
表1 試驗所需數據集數值內容
根據以上2種方法分別求取相應的貢獻度,再采用ReliefF算法選取特征子集中,根據ReliefF算法進行多標記的分類,并通過數據對ReliefF的效果進行比較。
2.2 試驗結果
根據以上方法在試驗中的貢獻值的確定W,采用 ReliefF方法選取了多個特征點,并將其歸類為多標記,并對其效果進行了對比。3個貢獻度對ReliefF的作用如圖1所示。在這些數據中,橫軸代表了所選取的特征量所占的比例。
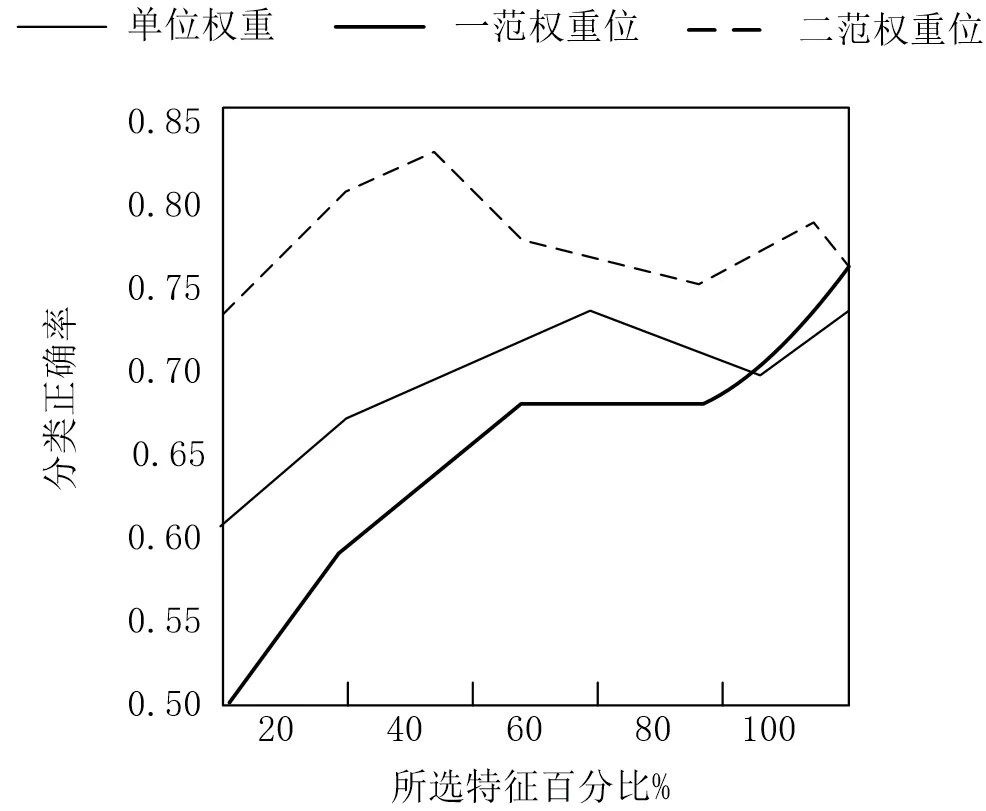
圖1 貢獻值對算法的影響
根據圖1可知,二范權重法的分類準確率最少,表現為穩定性;當屬性維度一致時,采用一范權重法對多標記與單一標記的數據進行比較,選擇的屬性不夠理性,因此一范權重法的分類準確率最低。而單元加權法過于注重多項指標,因此其分類準確率比二范權重法的準確率低。
對ReliefF和ALA-ReliefF這2種特征選取方法進行對比,以全面檢驗該方法的正確性。ALA-ReliefF方法是將多個標記的資料集合轉換為單一標記,再使用ReliefF方法進行標記的選取。ReliefF方法采用二次加權方法,對其進行了求解。如表2所示,在2個特征選擇算法中,對最早20%的屬性進行了分類,在80%以上的情況下也同樣對其進行了分類。
根據表2可知,當具有同樣的特征維度時,基于ReliefF方法的識別準確度要比ALA-ReliefF方法好得多,因為ALAReliefF在將多個標記的信息向單個標記的轉換過程中會形成一些干擾,進而使其識別準確度下降。ReliefF方法在進行了特征選取后,其準確度明顯優于未進行特征選取的情況,表明ReliefF方法能有效地消除噪聲,并能有效地改善其識別準確度。ReliefF方法在識別準確率方面的差異要比ALAReliefF方法低,表明ReliefF方法具有很好的穩定性,其獲得的教師信息素養指標體系評價結果更能夠反映真實情況。
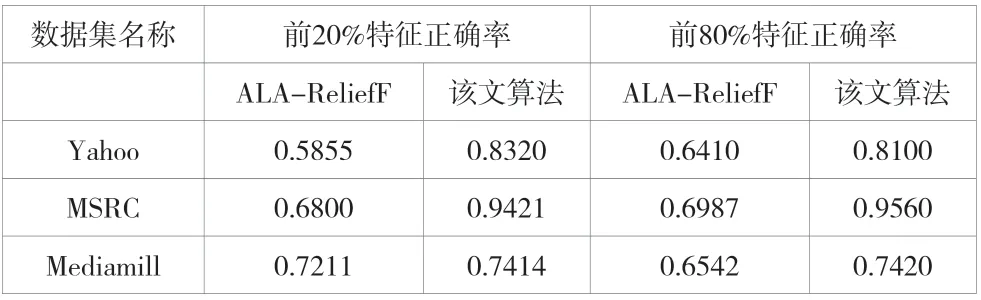
表2 2種特征選擇算法的分類正確率
3 結語
該文基于我國大學教師的信息素質評價指標,分析了我國大學教師的信息素質特征,并對其構成進行了分析。然后基于RreliefF特征選擇算法對大學英語專業教師的信息素質進行了分析,并建立了相應的評估指標和評估標準。大學教師的信息素質指數是一個多層次、多結構且綜合性強、可測性高的量化性時代性評定方法。制定高校教師信息素養指標體系是一個龐大而復雜的系統工程,該文的指標體系只是一個探索和嘗試,希望更多的研究機構和專家學者參與相關研究,基于RreliefF特征選擇算法早日制定出符合我國國情的高校教師信息素養指標體系。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
新世紀智能(高一語文)(2020年10期)2021-01-04 00:44:12
新世紀智能(高一語文)(2020年10期)2021-01-04 00:44:10
新世紀智能(高一語文)(2020年12期)2020-06-01 08:14:28
新世紀智能(高一語文)(2020年12期)2020-06-01 08:14:26
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
