基于手機的OCR測試集構建及自動化評估模型
2022-08-29 02:20:48曹慧靜
現代信息科技
2022年12期
曹慧靜
(傳音控股技術有限公司,上海 202106)
0 引 言
針對人工智能,訓練數據量的大小和豐富性決定了其準確性,因此數據集的構建對識別的準確性非常重要。針對印度市場用戶語言翻譯的問題,引入了選區翻譯功能(用戶在當下使用的界面上可以選擇需要翻譯區域進行翻譯)。根據用戶選中的內容圖像識別成文字,再把文字翻譯成需要的目標語言,用戶選中的區域內容根據用戶的使用場景和用戶的偏好而不一樣。選區翻譯相比競品有其優勢,能夠不中斷用戶當前使用頁面的閱讀體驗,而把需要翻譯的內容直接覆蓋在選中區域原文上,而不影響其他未選擇區域的閱讀,使得翻譯體驗更加便捷。
1 OCR 技術現狀研究
OCR(Optical Character Recognition)是指對文本資料的圖像文件進行分析識別處理,獲取文字及版面信息的過程。亦即將圖像中的文字進行識別,并以文本的形式返回。
OCR 識別應用很多場景,例如OCR 視頻文字識別、人臉識別、身份證件識別、票據識別、車牌碼識別、銀行卡識別等等,在業界也屬于比較成熟的應用;但是對于小語種OCR 識別能力應用于翻譯場景有待繼續提升和挖掘。OCR整體識別的流程如圖1所示。
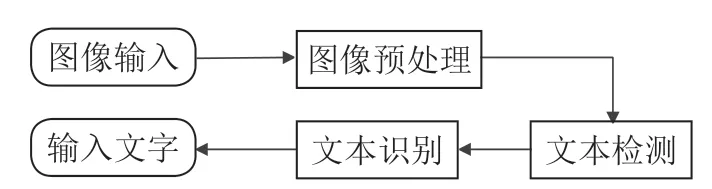
圖1 OCR 整體識別的流程
圖像預處理。通常是針對圖像的成像問題進行修正。由于深度學習的發展,現在普遍使用基于CNN 神經網絡的特征提取手段,得益于CNN 強大的學習能力,配合大量的數據可以增強特征提取的魯棒性。常見的預處理過程包括:幾何變換(透視、扭曲、旋轉等)、畸變校正、去除模糊、圖像增強和光線校正等。……
登錄APP查看全文
猜你喜歡
當代陜西(2020年13期)2020-08-24 08:22:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
制造技術與機床(2017年5期)2018-01-19 02:49:17
商用汽車(2016年11期)2016-12-19 01:20:16
濰坊學院學報(2016年2期)2016-12-01 13:00:11
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
新聞傳播(2015年11期)2015-07-18 11:15:04
