基于特征的遷移神經(jīng)網(wǎng)絡軸承智能故障診斷
2022-08-19 10:58:28王業(yè)統(tǒng)吳海威
機械設計與制造 2022年8期
王業(yè)統(tǒng),吳海威,李 美,蘇 明
(1.海南科技職業(yè)大學信息工程學院,海南 海口 571126;2.海南大學機電工程學院,海南 海口 570228;3.海南科技職業(yè)大學機電工程學院,海南 海口 571126)
1 引言
滾動軸承是旋轉(zhuǎn)機械的重要組成部分,軸承的失效直接影響機械的性能,甚至導致嚴重的事故[1]。實際機器中使用的軸承(Bearings in Real-Case Machines,BRMS)大多在健康狀態(tài)下運行,故障很少發(fā)生,因此,故障數(shù)據(jù)比健康數(shù)據(jù)更難收集。另外,數(shù)據(jù)量持續(xù)增長,由于噪聲大、知識依賴性強,用信號處理的方法來表示數(shù)據(jù)是不合適的[2]。
因此,提出在實驗室中模擬各種故障,然后從軸承試驗機(Bearings in Laboratory Machines,BLM)上收集足夠的標記數(shù)據(jù),然而,由于測量環(huán)境的多樣性、運行條件的多樣性、振動傳遞路徑的多樣性等因素的影響,BLM和BRMS采集到的數(shù)據(jù)分布存在很大差異[3]。
遷移學習的目標是使用源域中包含的知識來減少分布差異并提高目標域預測模型的性能。為了實現(xiàn)這一目標,基于特征的學習方法作為一種常用的遷移學習方法得到了廣泛的研究,該方法致力于從源域和目標域的數(shù)據(jù)中提取可轉(zhuǎn)換特征,以減少跨域差異。文獻[4]提出了一種基于域自適應的軸承故障診斷深度神經(jīng)網(wǎng)絡,利用源域的頻譜數(shù)據(jù)和目標域的部分標記數(shù)據(jù)對其進行訓練。文獻[5]采用稀疏自動編碼器從不同運行條件下的軸承中提取頻譜數(shù)據(jù)的特征,然后最小化最大平均偏差(MMD)以適應學習到的可遷移特征的分布。文獻[6]采用基于域自適應的深度卷積神經(jīng)網(wǎng)絡(CNN)完成不同噪聲環(huán)境下的軸承故障診斷。
雖然上述方法取得了一定效果,但是存在三個缺點:
(1)它們是在同一臺機器上進行的診斷知識的遷移學習任務,能否在不同的機器之間進行遷移學習還需探討。(2)上述方法存在性能下降的問題,并且忽略了振動數(shù)據(jù)的平移不變性。(3)上述方法部分地利用了目標域數(shù)據(jù)的分布信息,由于缺乏標記信息,沒有充分利用目標域中未標記的數(shù)據(jù)來訓練智能診斷模型[7-8]。
為了克服上述缺點,提出了一種基于特征的遷移神經(jīng)網(wǎng)絡軸承智能故障診斷方法,該方法能夠?qū)W習跨域差異小、類間距離小的可遷移特征。實驗結(jié)果證明了提出方法的有效性。
2 基本理論
2.1 問題描述
令Ds和Dt分別表示源域和目標域,如果將樣本空間表示Xs∈Ds和Xt∈Dt,源域和目標域的數(shù)據(jù)樣本分別為xs∈Xs和xt∈Xt。將標簽樣本表示為y={1 ,2,3,...,k} ,其中,包含k種正常工作狀態(tài)。假設從BLM和BRM采集的數(shù)據(jù)樣本服從邊際概率分布P(xs)和Q(xt)。
(1)利 用Ds={Xs,P(xs)}的ns標記 樣本 構(gòu) 建 源 域Xs=,以提供診斷信息。
(3)源域應該為目標域提供足夠的診斷信息,即yt?ys?y,其中ys和yt分別是源域和目標域中的標簽空間。
由于從不同的方位采集源域和目標域的振動數(shù)據(jù),因此,這些數(shù)據(jù)的分布存在嚴重的差異。如果使用智能診斷模型同時從這些數(shù)據(jù)中學習特征,學習到的特征也會受到分布偏差的嚴重影響。從圖1(a)可以看出,通過最小化域共享分類器h( · )僅用源域樣本訓練,這意味著基于所學習的特征可以實現(xiàn)分類任務,該分類器也可以很好地用于目標域。然而,域共享分類器h( · )在目標域上的泛化誤差卻很大,即分類器h( · )由于分別從源域和目標域中的樣本中學習到的特征之間存在嚴重的分布差異,因此對目標域樣本的分類結(jié)果基本上是錯誤的。因此,這里目標是建立一個智能診斷模型,從收集的數(shù)據(jù)中提取可遷移的特征,以減少跨域差異,然后強制域共享分類器h( · )以最小化的目標域風險。如圖1(b)所示,智能診斷模型期望學習具有相似分布的可遷移特征。因此,域共享分類器可以根據(jù)源域提供的診斷信息正確識別目標域樣本。
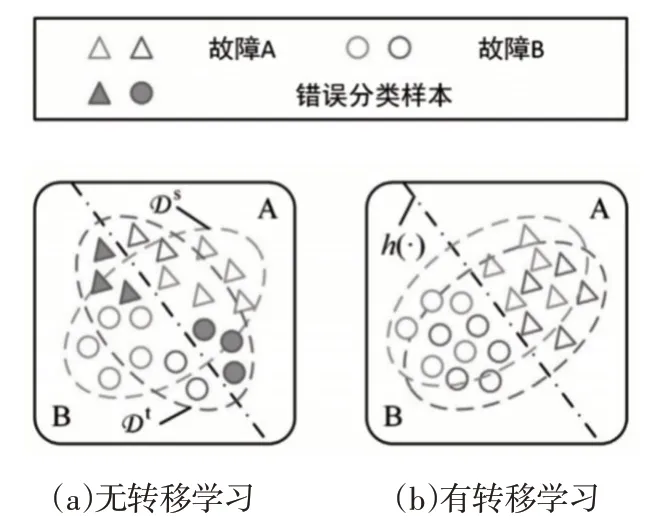
圖1 基于特征的轉(zhuǎn)移學習智能故障診斷Fig.1 Intelligent Fault Diagnosis Based on Feature Transfer Learning
2.2 MMD
最大平均差異(Maximum Mean Discrepancy,MMD)是一種非參數(shù)距離度量,用于度量兩個數(shù)據(jù)集之間的分布差異。如果數(shù)據(jù)集和分別遵循概率分布p和q,則數(shù)據(jù)集X和Y之間的MMD定義如下。
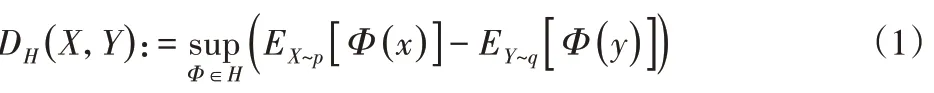
式中:sup( · )—輸入集合的上界;H—再生核Hilbert 空間(Reproducing Kernel Hilbert Space,RKHS);Φ( · )—原始特征空間到RKHS的非線性映射[9]。
通過分布的核平均嵌入,RKHS由拉普拉斯核和高斯核等特征核生成。因此,基于核均值嵌入的MMD經(jīng)驗估計的計算表達式如下:
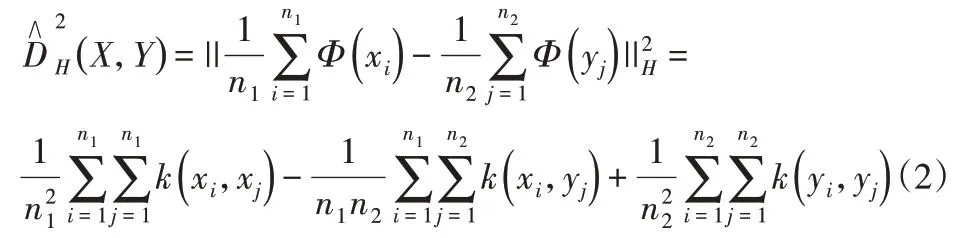
式中:k(·,· )—特征核。
3 提出方法
3.1 整體結(jié)構(gòu)
目的是建立一個基于特征遷移方法的智能診斷模型。該方法包括四個步驟:域劃分、特征提取、域自適應和故障識別,如圖2所示。
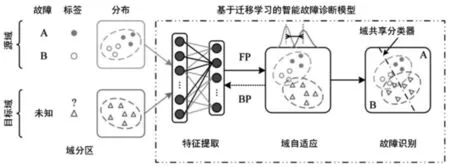
圖2 提出方法的總體結(jié)構(gòu)Fig.2 The Overall Structure of the Proposed Method
在域劃分的一步中,源域包含標記樣本以提供診斷信息,而目標域中的未標記樣本則期望利用源域中的診斷信息進行分類。對于特征提取,采用非線性特征映射從源域和目標域的數(shù)據(jù)中提取可遷移的特征。注意,源域和目標域中的數(shù)據(jù)同時由相同的非線性特征映射處理。在域自適應方面,首先用一個非參數(shù)距離指標MMD來度量學習的可遷移特征的分布差異。然后,以學習到的可遷移特征的分布差異作為優(yōu)化目標,反向傳播,訓練非線性特征映射的參數(shù)。優(yōu)化的目的是使學習到的可遷移特征的分布差異最小化,從而得到具有較小跨域差異的特征。在故障識別中,最后利用域共享分類器對目標域中未標記樣本進行正確分類。分類器充分地從源域樣本中學習特征的分布。基于域自適應訓練,目標域樣本的學習特征分布與源域樣本相似。因此,域共享分類器還能夠正確地對目標域中未標記的樣本進行分類。
3.2 FTNN
3.2.1 域共享CNN
FTNN的結(jié)構(gòu),如圖3所示。該模型利用一個域共享CNN從源域和目標域的原始振動數(shù)據(jù)中提取可遷移特征。然后,通過多層域自適應來減小學習的可遷移特征的分布差異。最后,對目標域中未標記的樣本分配偽標簽,訓練域共享的CNN。當同時處理源域和目標域中的樣本時,域共享CNN需要根據(jù)參數(shù)集進行訓練網(wǎng)絡。參數(shù)設置,如表1所示。通常,域共享CNN由卷積層、池化層和全連接層組成。

圖3 提出的FTNN模型的體系結(jié)構(gòu)Fig.3 The Architecture of the Proposed FTNN Model
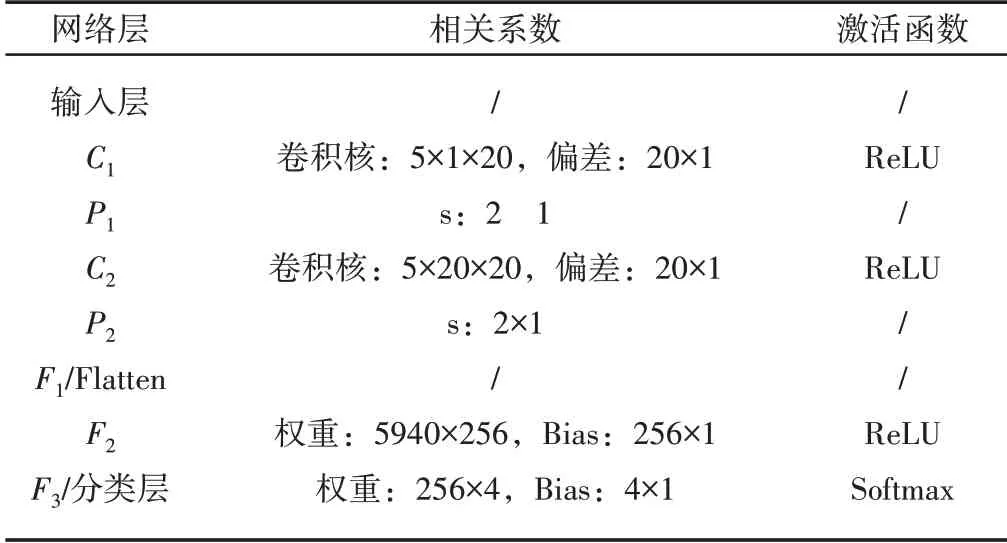
表1 域共享CNN的參數(shù)Tab.1 Parameters of Domain Shared CNN
在卷積層中,域共享CNN采用共享核kl∈RH×L×D對l- 1層的輸出向量進行卷積,其中,H—核的高度;l和D—核的長度和深度。由于原始振動數(shù)據(jù)為一維(1D)矢量,因此L設為1。假設前一層的輸出特征是,則第l層的輸出特征如下所示。
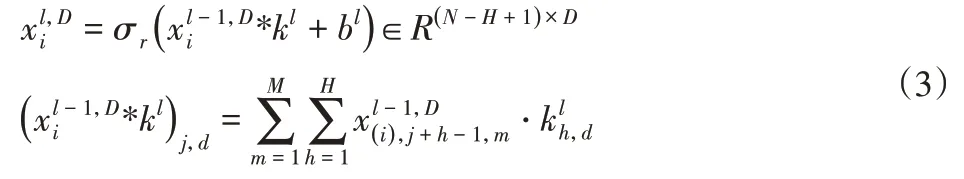
式中:D={s,t}—源域和目標域的索引—從上一層l- 1 的特征中學習到的可遷移特性;bl—C1層偏差;σr( · )—矩形線性單位(ReLU),是解決梯度消失問題的常用的激活函數(shù)。
在此基礎上,利用池化層的下采樣過程來減少訓練參數(shù)的個數(shù),從而有效地克服過擬合問題。本研究采用最大池化的下采樣方式,將可遷移特征劃分為若干個不重疊的部分,并返回每個部分的最大值。源域和目標域中的合并特征表示為:
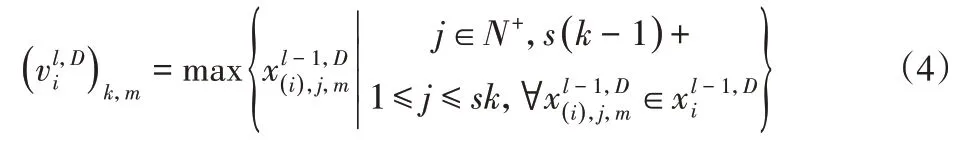
式中:max( · )—返回向量的最大值;s—非重疊像素的高度。
可以根據(jù)層疊卷積層和池化層依次提取高層特征。然后將這些特征擴展為一維向量。例如,層P2中的可遷移特征被擴展成一維特征向量,作為全連接層F1的輸出。與多層神經(jīng)網(wǎng)絡結(jié)構(gòu)類似,F(xiàn)2層的輸出如下所示。
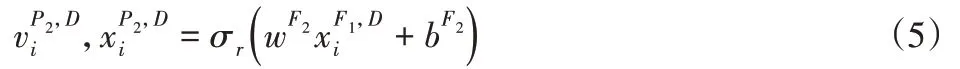
分類過程中,最后一個全連接層F3中使用softmax函數(shù)來預測樣本xsi和xti的類別。層F3的輸出表示樣本類別的概率分布,其表示如下:
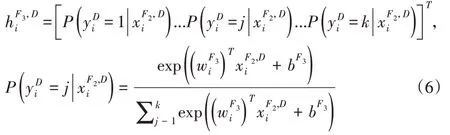
3.2.2 多層域自適應
為了減少分布差異,通過最小化學習到的可遷移特征的MMD 來訓練域共享CNN 的參數(shù)。相關研究證明高層次特征在全連接層中的分布不一致,因此,最后一層神經(jīng)網(wǎng)絡除了用于分類外,還有必要調(diào)整學習的可遷移特征在層F1和F2中的分布。此外,在域共享CNN的訓練過程中,學習特征的分布隨網(wǎng)絡參數(shù)的更新而變化,定義為內(nèi)部協(xié)變量偏移。為了緩解此問題,還需要調(diào)整卷積層C1和C2中學習到的可遷移特征的分布。因此,學習到的可遷移特征的多層MMD計算公式如下:
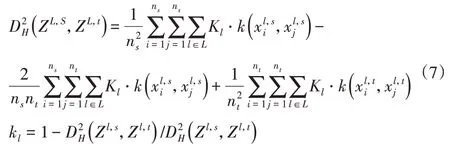
域共享CNN有利于學習具有特定域特性的可遷移特征,這使多層MMD值的變化較大。具體來說,高層特征的MMD值遠大于淺層特征的MMD 值,因此,使用一個權(quán)衡參數(shù)Kl來平衡多層MMD的大小。該權(quán)衡參數(shù)是動態(tài)的,以擴大淺層特征的貢獻度,降低高層特征的貢獻度。
式(7)表明,核寬和時間復雜度嚴重影響MMD。一方面,以高斯核為例,式中:γ—核寬。如果γ→0,MMD會趨于0;同樣,如果選擇較大帶寬,也會降到0,比如γ→∞。為了解決這一問題,通過選取核帶寬γ作為所有樣本對之間的中值距離。另一方面,式(7)的時間復雜度為O(n2×l),在共享域CNN的訓練過程中消耗了大量的時間,為了解決這個問題,引入了的無偏估計來計算MMD。因此,式(7)可簡化為:
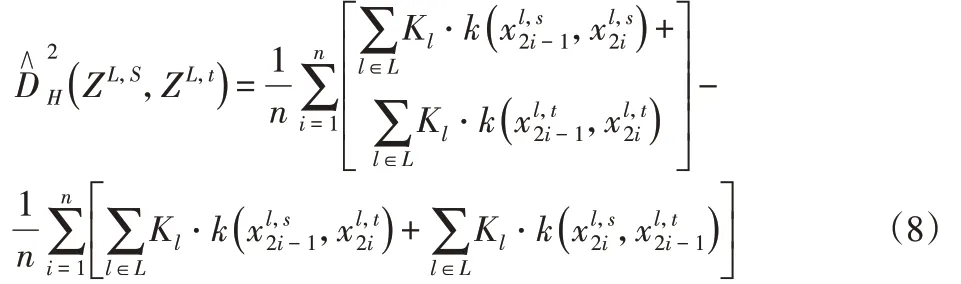
其中,2n=ns=nt。式(8)的時間復雜度減小到O( )n×l,有效地加快了模型的訓練速度。
最后通過最小化代價函數(shù)來減小學習的可遷移特征的分布差異。

式中:θc—C1,C2,F(xiàn)1和F2的參數(shù)集合。
3.2.3 偽標簽學習
基于可遷移特征的多層自適應可以減少可遷移特征的差異分布。然而,由于缺乏標記的樣本,目標域中的未標記樣本不能用于訓練F3層中的參數(shù)。為此,引入偽標簽學習來解決這一問題。一個樣本的偽標簽就是把預測概率最大的標簽當作真標簽來選取,偽標簽的生成包括兩個步驟:標簽的概率預測和偽標簽的轉(zhuǎn)換。F3層中的softmax函數(shù)預測目標域中樣本的標簽概率分布。因此,結(jié)合等式(6),偽標簽可由下式計算:

源域和目標域的樣本都是用來訓練共享域CNN,因此,偽標簽學習的優(yōu)化目標表示為:
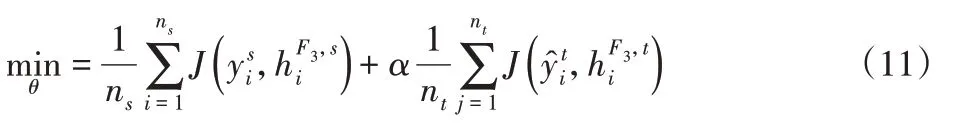
式中:J( ·,· )—損失函數(shù);yis—源域中第i個樣本的真實標簽;α—權(quán)衡參數(shù);θ—域共享CNN的參數(shù)集合。
3.3 訓練過程
提出的FTNN 模型通過三個正則項最小化來訓練:(1)源域樣本的預測標簽與真實標簽之間的誤差;(2)目標域樣本的預測標簽與偽標簽之間的誤差;(3)從跨域數(shù)據(jù)中學習可遷移特征的多層MMD。通過式(9)和式(11),F(xiàn)TNN 模型最終的計算表達式如下:

式中:β—權(quán)衡參數(shù);n—梯度下降的最小批量樣本數(shù)。
本研究采用交叉熵損失函數(shù),定義如下:

利用式(12)中的三個正則化項,提出的FTNN也會有相應特征。首先,F(xiàn)TNN能夠?qū)W習可遷移特征,并根據(jù)這些特征對輸入樣本進行分類。對源域中的標記樣本進行訓練,得到診斷信息。其次,偽標簽學習將目標域樣本中的學習特征按預測的類別集合起來,擴大了學習特征的類間距離,便于識別。最后一個階段,訓練后的FTNN能夠在最小化學習到的可遷移特征的分布差異后,學習到服從相似分布的可遷移特征。通過同時訓練FTNN以及這三個正則化項,可以將來自源域的診斷信息應用于目標域中的相關診斷任務。
在FTNN模型的訓練過程中,采用Adam優(yōu)化算法對式(12)進行優(yōu)化,有效地加快了訓練過程,解決了參數(shù)量大的問題,F(xiàn)TNN模型的訓練過程的流程圖,如圖4所示。在域劃分階段,分別將BLMs和BRMs采集的數(shù)據(jù)集作為源域和目標域。在特征提取過程中,源域和目標域的樣本向前傳播到域共享CNN中,從而逐層獲得可遷移的特征。對于域自適應,學習的可遷移特征的多層MMD由式(8)計算。其次,由式(10)生成目標域中未標記樣本的偽標簽。然后,正則化項對域共享CNN的參數(shù)集合進行約束。最后對提出的FTNN模型進行訓練,直到滿足停止條件為止。在故障識別階段,利用FTNN模型對BRMs中的樣本進行訓練。
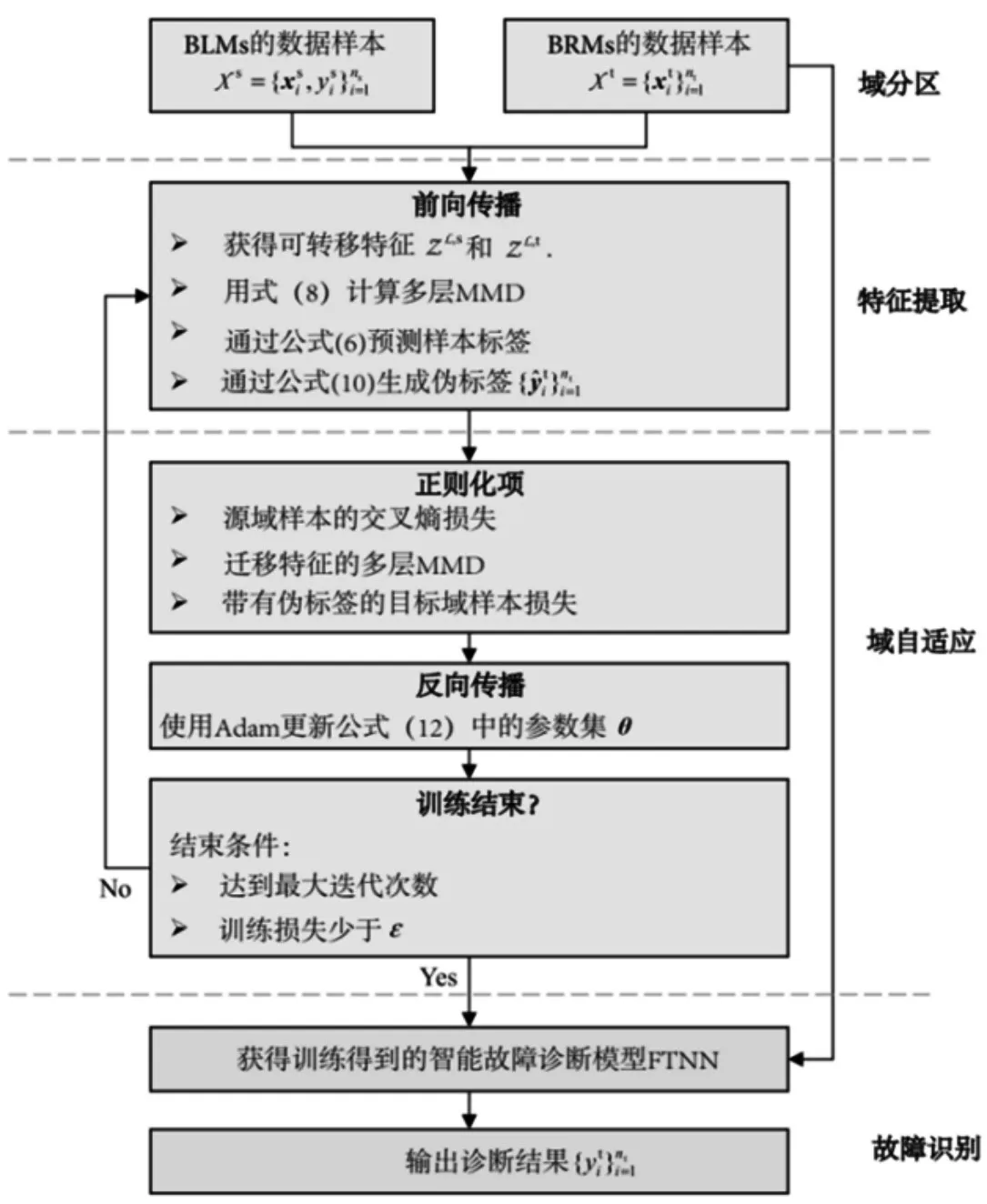
圖4 FTNN訓練流程圖Fig.4 FTNN Training Flow Chart
4 提出算法研究
4.1 數(shù)據(jù)集
通過兩個軸承故障診斷實例,驗證了所提出的FTNN模型的有效性。在案例研究中,嘗試分別利用實驗室電機軸承和實驗室齒輪箱軸承的診斷信息來識別機車軸承的工作狀況。這三種數(shù)據(jù)集的介紹如下:實驗室中使用的電機軸承的數(shù)據(jù)集由凱斯西儲大學提供,軸承(SKF6205)的振動數(shù)據(jù)是通過放置在實驗室電機驅(qū)動端的加速度計獲得的[10]。在實驗室用電火花加工技術(shù)模擬了軸承的單點故障,得出軸承的工作狀態(tài)包括正常(N)、內(nèi)圈故障(IF)、滾子故障(RF)和外圈故障(OF)。此外,還指出,每種斷層的直徑為0.0014英寸。實驗中,采樣頻率設為12kHz。如表2所示,數(shù)據(jù)集A是在無負載(電機轉(zhuǎn)速約為1797r∕min)的情況下采集的,數(shù)據(jù)集B是在電機負載為3HP(電機轉(zhuǎn)速約為1730r∕min)的情況下采集的。數(shù)據(jù)集A和B共有404個樣本,每個樣本有1200個采樣點。
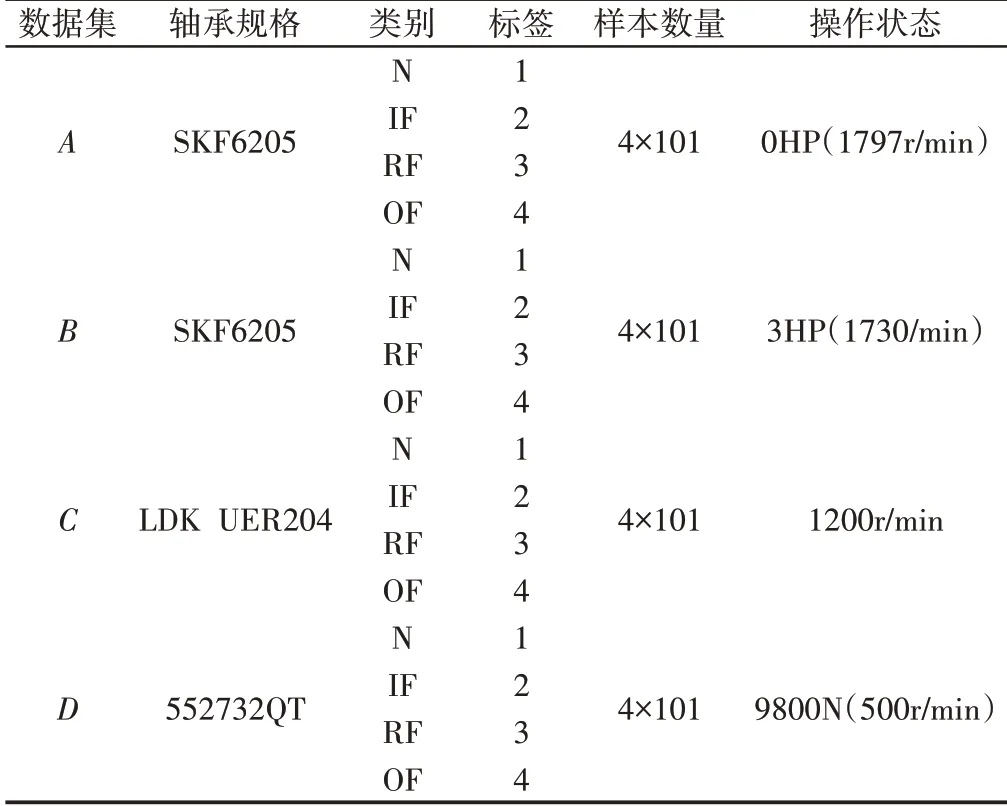
表2 數(shù)據(jù)集介紹Tab.2 Introduction of Data Sets
實驗室齒輪箱軸承的數(shù)據(jù)集是從一個試驗臺上收集的,該試驗臺包括一臺電動機、一個兩級固定軸齒輪箱、一個行星齒輪箱和一個磁力制動器。電機的輸出轉(zhuǎn)速和轉(zhuǎn)矩依次通過定軸齒輪箱和行星齒輪箱傳遞,然后驅(qū)動磁力制動器帶負荷運行。試驗軸承(LDK UER204)安裝在固定軸齒輪箱的第一級輸入軸上,振動數(shù)據(jù)由安裝在齒輪箱殼體軸承座上的加速度計采集。實驗中,測試軸承包括N、IF、RF 和OF 四種工作狀態(tài),采樣頻率設定為12.8kHz,采集不同工作狀態(tài)下的振動數(shù)據(jù)。同時,電機轉(zhuǎn)速設定為1200r∕min,如表2所示。數(shù)據(jù)集C包含404個樣本,每個樣本有1200個采樣點。
另一個數(shù)據(jù)集來自機車軸承,測試軸承(552732QT)安裝在液壓馬達驅(qū)動系統(tǒng)中。此外,試驗軸承還包括正常、內(nèi)圈碰摩故障、滾子碰摩故障和外圈碰摩故障四種工作狀態(tài)。振動數(shù)據(jù)由安裝在試驗軸承外圈的加速計收集,在測試中,采樣頻率設置為12.8kHz。試驗軸承由液壓缸加載,載荷為9800N(軸轉(zhuǎn)速約500r∕min)。如表2所示,數(shù)據(jù)集D包含四個故障類別和404個樣本,每個樣本有1200個采樣點。
根據(jù)表2,創(chuàng)建了三個遷移學習任務,即A→D、B→D、還有C→D、數(shù)據(jù)集A、B和C為提供診斷信息的源域,而數(shù)據(jù)集D為目標域。這些遷移學習任務的目標是盡可能準確地對數(shù)據(jù)集D中的樣本進行分類。
4.2 從實驗室電機軸承向機動車軸承遷移學習
4.2.1 FTNN的遷移結(jié)果
本小節(jié)驗證了FTNN 模型對遷移學習任務A→D的有效性。在該方法中,α和β是重要的權(quán)衡參數(shù),嚴重影響了FTNN的遷移效果,因此,應該分析參數(shù)的選取。分類精度與F2層中學習到的可遷移特征有關,這些特征是分類前的最高層次特征。因此,在選取不同參數(shù)后,利用F2層學習到的可遷移特征的MMD來分析FTNN的遷移結(jié)果。參數(shù)α的取值范圍為{0,0.01,0.05,0.1,0.5,1},參數(shù)b的取值范圍為{0.01,0.05,0.1,0.5,1,5,10,50}。注意,每個實驗進行10次,計算平均值。
如圖5所示,當參數(shù)α和β分別設為0.01和5時,有效地減小了學習的可遷移特征的MMD。具體地說,當權(quán)衡參數(shù)β小于0.5時,MMD明顯大于其他情況下的MMD,這表明學習的可遷移特征的分布是欠適應的。一旦權(quán)衡參數(shù)α較大時,例如大于0.5,跨域差異也很難被校正。因此,偽標記學習的性能與跨域差異有關,較大的權(quán)衡參數(shù)α將限制學習的可遷移特征的分布適應性。解決這一問題的一個有效途徑是選擇一個小的權(quán)衡參數(shù),它能夠平衡偽標簽學習和分布適應在代價函數(shù)中的影響程度。
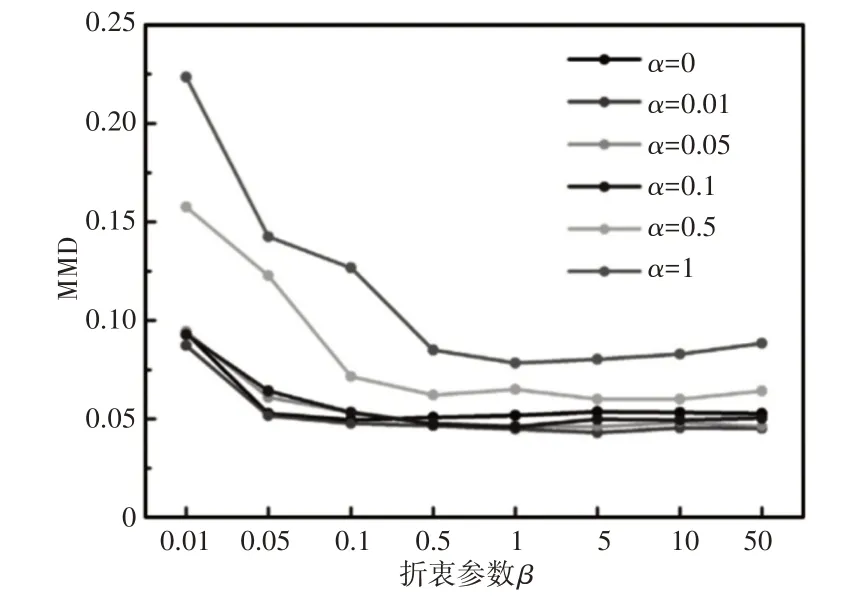
圖5 不同折衷參數(shù)下學習的可轉(zhuǎn)移特征的MMDFig.5 MMD of Transferable Features Learned under Different Compromise Parameters
在用不同的權(quán)衡參數(shù)訓練FTNN模型后,數(shù)據(jù)集D的分類精度,如圖6所示。當參數(shù)α小于0.1,參數(shù)β大于1時,F(xiàn)TNN在數(shù)據(jù)集D上的分類準確率在(80~85)%之間。特別是當α和β分別設為0.01和5時,分類精度可以達到最大值。結(jié)合圖5和圖6中所示的結(jié)果,可以發(fā)現(xiàn)分類精度隨學習的可遷移特征的MMD而變化。可遷移特征的MMD越小,分類精度越高。
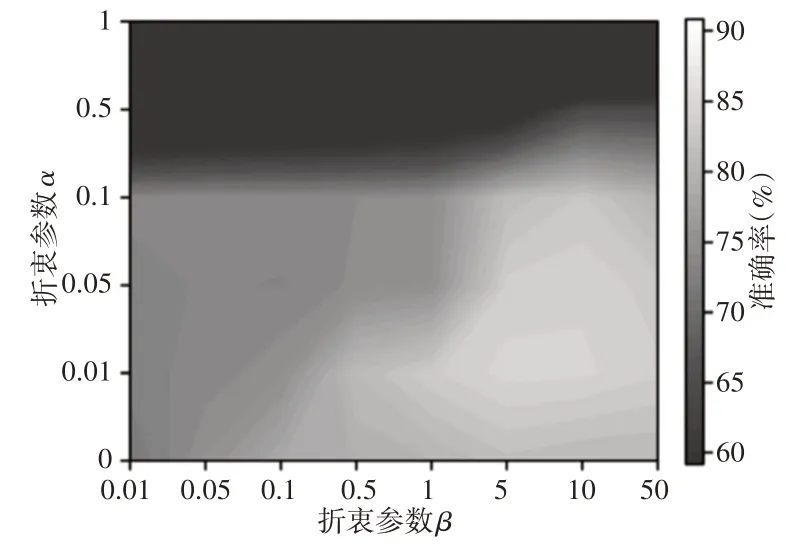
圖6 不同折衷參數(shù)下數(shù)據(jù)集D的分類精度Fig.6 Classification Accuracy of Data set Dwith Different Compromise Parameters
4.2.2 與其他方法的比較
將該方法與CNN[11]、TCA[12]、DAFD[13]、DDC[14]和多層自適應CNN(MACNN)[15]的遷移結(jié)果和遷移性能進行了比較。CNN的模型結(jié)構(gòu)與FTNN相同,TCA是一種常用的遷移學習方法,正則項的權(quán)衡參數(shù)的取值范圍為{0.01,0.1,1,10,100},子空間維數(shù)的取值范圍為{2,4,8,16,32,64,128}。DAFD是一種能夠成功地完成軸承在不同工況下的遷移學習任務的智能診斷模型。對于正則化項,有兩個重要的權(quán)衡參數(shù),它們的取值范圍均為10-5到105。DDC的模型結(jié)構(gòu)與FTNN相同,但它只是通過最小化F2層學習特征的MMD來減小分布差異。MACNN是FTNN的簡化版本,不進行偽標簽學習。TCA和DAFD的輸入是頻譜數(shù)據(jù),而其它方法的輸入是原始振動數(shù)據(jù)。研究表明,每種方法都有適合遷移學習任務的最優(yōu)參數(shù)。此外,每個實驗進行10次,平均值,如表3所示。從表3中可知,F(xiàn)TNN的平均分類準確率為84.32%,是六種方法中分類準確率最高的一種。由于缺乏域自適應,CNN的平均準確率達到51.04%,低于FTNN 的準確率。 TCA 的平均準確率為46.04%,DAFD的準確率為55.05%。這兩種方法的精度比FTNN差,因為它們無法從樣本中提取高層特征,并且可能不適合處理跨域差異嚴重的任務。對于DDC,它的平均準確率為76.23%,低于FTNN 的精度,因為DDC 只是通過最小化最高層次特征的MMD 來減小分布差異。對于MACNN,其平均分類準確率為80.55%,比FTNN小,但高于其它方法。實驗結(jié)果驗證了引入多層域自適應和偽標簽學習的有效性。
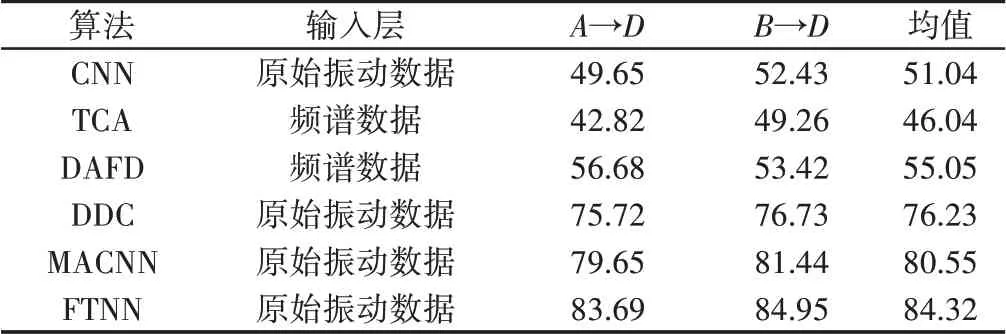
表3 遷移學習的分類精度(%)Tab.3 Classification Accuracy of Transfer Learning
通過引入遷移損耗和遷移比來比較FTNN與其他方法的遷移性能。在得到遷移損耗和遷移比的度量標準之前,需要考慮兩個指標,即遷移誤差err(S,T)和基線域內(nèi)誤差errb(T,T)。傳遞誤差是一種在源域S上訓練并在目標域T上進行測試得到的誤差。如果一個基線模型在目標域上訓練并在同一個域上進行測試,則將其測試誤差定義為基線域內(nèi)誤差。基于這些定義,遷移損耗是遷移誤差與域內(nèi)基線誤差之間的差值。對于特定的遷移學習任務,較小的遷移損失會產(chǎn)生更好的遷移性能,遷移率的計算公式為用于評價一種方法在m個遷移學習任務上的整體遷移性能,遷移比越大,表示遷移性能越好。CNN作為指標計算的基線模型,數(shù)據(jù)集D分為訓練集和測試集,訓練集包含數(shù)據(jù)集D中50%的樣本,其余用于測試的樣本用于計算域內(nèi)基線誤差。CNN的體系結(jié)構(gòu)與FTNN相同,經(jīng)過10次試驗,基線模型在數(shù)據(jù)集D上的平均分類準確率為99.02%,因此,域內(nèi)基線誤差誤差T為0.98%。然后對各種方法的遷移損耗和遷移比進行了計算結(jié)果,如表4 所示。對于任務A→D、FTNN 的遷移損耗為15.33%,低于其它方法。在任務B→D的所有方法中,F(xiàn)TNN的遷移損耗最低,為14.07%。另外,F(xiàn)TNN 的遷移率為0.84,是這六種方法中最高的。結(jié)果表明,F(xiàn)TNN模型比其他方法具有更好的遷移性能。
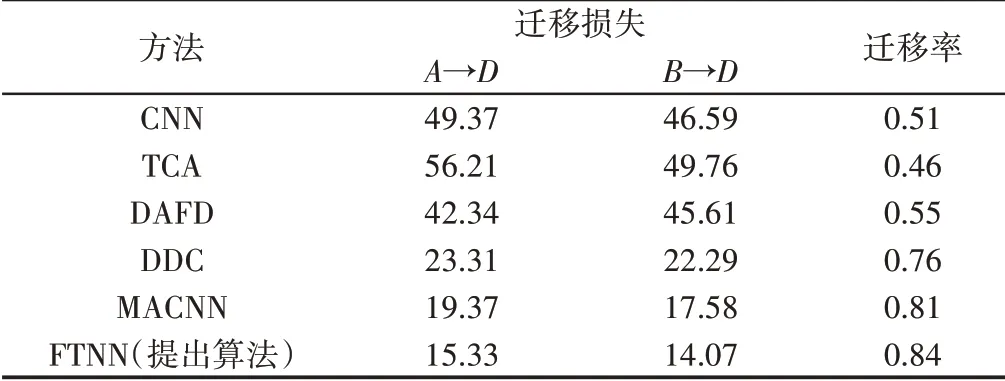
表4 不同遷移任務A→D和B→D的遷移效果Tab.4 Migration Effects of Different Migration Tasks A→Dand B→D
為了直觀地理解遷移學習過程,引入了t分布隨機鄰域嵌入(t-SNE)算法。該算法能夠降低學習特征的維數(shù),并能直接繪制學習特征的分布圖。以任務BD為例,F(xiàn)TNN學習的可遷移特征,如圖7(f)所示。為了方便觀察比較結(jié)果,圖7(a)~圖7(e)中分別顯示了由CNN、TCA、DAFD、DDC 和MACNN 等其他方法提取的可遷移特征。
從圖7(a)所示的結(jié)果來看,由CNN學習的可遷移特征存在嚴重的分布差異。此外,目標域中的特征集合效果差,類間距離小。因此,當只利用源域中的樣本訓練模型時,CNN無法有效地對目標域中未標記的樣本進行分類。從圖7(b)和圖7(c)可以看出,通過使用TCA和DAFD不能有效地適應所學習的可遷移特征的分布。具體地說,在正常情況下和滾筒故障情況下,樣本的可遷移特征仍然存在嚴重的分布差異。結(jié)果表明,TCA和DAFD的分類準確率在50%左右。對于圖7(d),DDC在層F2中調(diào)整學習的可遷移特征的分布,并且跨域差異明顯減小。因此,與CNN、TCA 和DAFD 相比,DDC 在數(shù)據(jù)集C上獲得了更高的診斷準確率。至于圖7(e),學習到的可遷移特征比圖7(d)所示的分布差異小。這一結(jié)果直觀地解釋了多層域自適應的有效性。圖7(f)表明,F(xiàn)TNN不僅有效地適應了學習可遷移特征的分布,而且擴大了學習可遷移特征的類間距離。因此,可以很容易區(qū)分它們,而且分布差異很小,因此,可以對目標域中的樣本進行正確的分類。
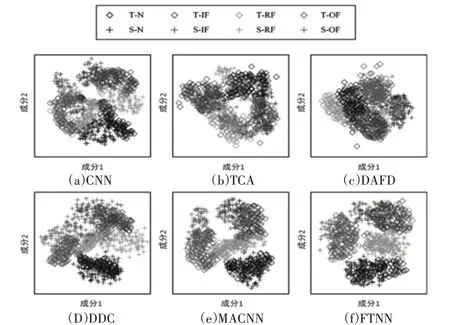
圖7 數(shù)據(jù)集B和數(shù)據(jù)集D上學習特征的可視化Fig.7 Visualization of Learning Features on Dataset Band Dataset D
4.3 從實驗室齒輪箱軸承到機動車軸承的遷移學習
希望利用實驗室齒輪箱軸承的診斷知識來識別機車軸承的健康狀態(tài),即遷移學習任務C→D,對于這項任務同樣進行了10次試驗,數(shù)據(jù)集D的平均診斷準確率,如表5所示。根據(jù)表5的結(jié)果,F(xiàn)TNN的平均精度為74.81%,任務C→D的FTNN遷移性能也可以通過遷移損耗和遷移比來評估。從表5的結(jié)果來看,F(xiàn)TNN的遷移損耗和遷移比分別為24.21和0.76。
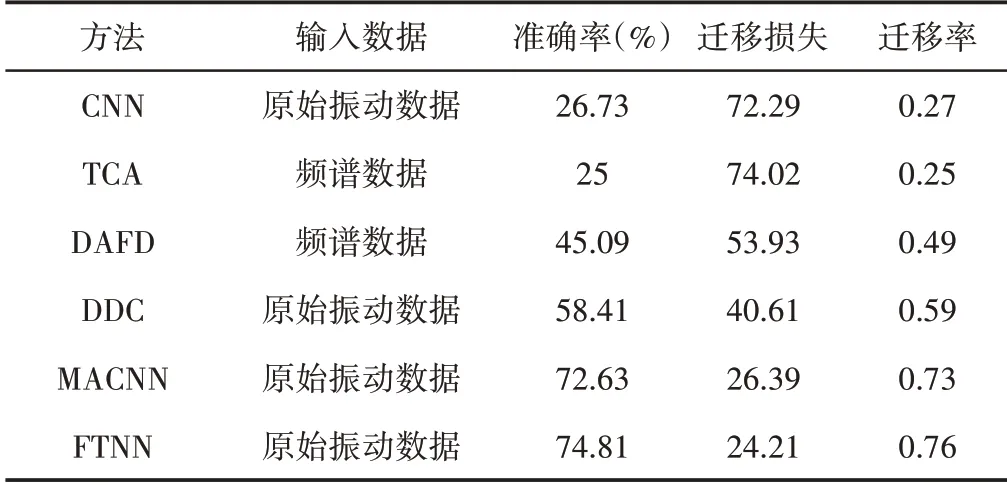
表5 遷移任務C→D的遷移效果Tab.5 Migration Effect of Migration Task C→D
將所提出的FTNN用于任務C→D的遷移結(jié)果和遷移性能與Case I中的其他5種方法進行了比較,結(jié)果表明,每種方法的遷移結(jié)果和遷移性能都是在最優(yōu)參數(shù)選擇下獲得的。根據(jù)表5的比較結(jié)果發(fā)現(xiàn),在這六種方法中,所提出的FTNN 對數(shù)據(jù)集D的診斷精度最高。此外,F(xiàn)TNN的遷移損耗比其它方法低,遷移比也比其他方法高。與其他方法相比,這些結(jié)果也顯示了該方法的優(yōu)越性。通過t-SNE算法,CNN、DDC和FTNN學習到的可遷移特征,如圖8所示。根據(jù)學習特征的可視化,數(shù)據(jù)集D上遷移結(jié)果的混淆矩陣,如圖9所示。

圖8 數(shù)據(jù)集C和數(shù)據(jù)集D上學習特征的可視化Fig.8 Visualization of Learning Features on Data set Cand Data set D

圖9 數(shù)據(jù)集D的傳輸結(jié)果的混淆矩陣Fig.9 Confusion Matrix of Data set D
從圖8(a)可以看出,CNN 學習到的可遷移特征存在嚴重的分布差異。結(jié)果,當CNN用數(shù)據(jù)集C訓練時,其對數(shù)據(jù)集D的分類精度接近預測值,即25%,如圖9(a)所示。對于DDC,可以通過最小化學習到的高級可遷移特征的MMD來調(diào)整跨域數(shù)據(jù)中可遷移特征的分布。因此,從圖8(b)的結(jié)果在一定程度上校正了跨域差異。此外,數(shù)據(jù)集D的DDC 分類精度高于CNN,如圖9(b)所示。從圖8(c)可以看出,所提出的FTNN 能夠修正不同方位數(shù)據(jù)的學習可遷移特征之間的分布差異。此外,由于源域和目標域的子類別樣本之間的可遷移性不同,子類別樣本的分布差異得到了非對稱校正。例如,經(jīng)過遷移學習后,帶射頻的跨域樣本的分布差異仍然嚴重,而其他三類故障的分布差異得到了有效的修正。因此,根據(jù)圖9(c)所示的結(jié)果,F(xiàn)TNN 模型能夠正確地分類N、IF 和RF 的類別,但是對于未標記的目標域樣本錯誤地識別類別RF。
5 結(jié)論
為了提升傳統(tǒng)遷移學習故障診斷中信息挖掘深度,實現(xiàn)不同機器間的遷移學習,提出了一種基于特征的遷移神經(jīng)網(wǎng)絡軸承智能故障診斷方法。
通過多個實驗結(jié)果可以得出如下結(jié)論:
(1)FTNN模型能夠在無標記數(shù)據(jù)的情況下更好地識別軸承的狀態(tài),與其他方法相比,該方法具有更高的分類精度。
(2)FTNN模型比其他方法具有更好的傳輸性能,具有更低的遷移損耗,更高的遷移率。
(3)引入多層域自適應能夠自適應學習可遷移特征的分布,從而校正跨域差異,引入偽標簽學習能夠擴大可遷移特征的類間距離。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
音樂探索(2022年2期)2022-05-30 21:01:37
世界科學技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小天使·一年級語數(shù)英綜合(2019年8期)2019-08-27 02:23:00
當代陜西(2019年10期)2019-06-03 10:12:04
中國特種設備安全(2018年11期)2019-01-08 02:08:32
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
鄭州大學學報(醫(yī)學版)(2015年2期)2015-02-27 14:50:46
