構建海關特殊監管區域風險防控知識圖譜芻議
2022-08-08 12:24:34林煜超陳仰麗
西部學刊 2022年13期
林煜超 陳仰麗
2021年12月17日,習近平總書記在中央全面深化改革發展委員會第二十三次會議上提出“加快構建新發展格局”和“加快建立全方位、多層次、立體化監管體系,實現事前事中事后全鏈條全領域監管,堵塞監管漏洞,創新監管方法,提升監管的精準性和有效性”。“十四五”海關發展規劃明確指出,要全面提升科技創新應用水平、深化海關大數據應用,探索應用區塊鏈、大數據等加強聯網監管,提升監管的精準性和威懾力。
當前,加快形成以國內大循環為主體、國內國際雙循環相互促進的新發展格局,是中央根據我國現階段實際作出的戰略決策,是事關全局的系統性深層次變革。海關特殊監管區域作為聯接國內國際兩個市場的重要節點和對外貿易開放的試驗田,隨著“雙循環”新發展格局快速發展,呈現出幾個特點:參與主體更加靈活多樣、貨物流向更為復雜無序、物流鏈條不斷細分延伸、主體關聯日趨縱橫交錯。由于傳統的數據挖掘手段僅聚焦于單票貨物、單家企業的單線程分析防控手段,因而無法適應高速發展變化的特殊監管區域業務實際,難以滿足全領域系統性研判分析、精準化防控處置風險防控需求,亟需引入新手段、新方法提升防控效能。知識圖譜能把散亂、無序、單線程的信息,通過歸納總結,形成有關聯關系的網狀知識結構,從而輔助風險分析人員系統全面地掌握團伙脈絡,梳理跟蹤貨物流轉,及時定位異常并精準打擊處置,正好契合海關特殊監管區域風險防控面臨的新要求,對于推進風險防控整體水平和防控實戰能力提高具有一定的現實意義。
一、建設海關特殊監管區域風險防控知識圖譜的必要性
海關特殊監管區域,是有別于關境內一般海關監管地區的特殊政策區域,主要包括保稅區、出口加工區、保稅港區、保稅物流園區、綜合保稅區等,相比于一般貿易進出口監管,具有物流鏈條復雜、手賬冊類型繁多、進出口數據量大、區域內企業管理難的特點。知識圖譜是2012年由谷歌公司提出的搜索新功能,目的是優化搜索結果,也可稱為知識域可視化,用可視化技術描述一系列知識的發展與結構的關系。引入知識圖譜及相關智能算法,可以有效解決數據散點分布、物流跟蹤困難的問題,實現數據資源整合,強化海關監管,切實為風險防控賦能。
(一)發揮海關特殊監管區域多元數據的潛力
經過近年來的快速發展,我國海關初步建成大數據資源平臺,不但涵蓋了特殊監管區域貨物進出過程中涉及的保稅業務監管、企業管理、進出通關、衛動食商等管理職能以及稽核查后續監管等海關全領域監管數據,同時又包含各部委之間交換的監管數據。但是,目前的數據分析更多聚焦于一般貿易領域,涉及特殊監管區域的部分數據還沒有經過清洗和挑選,海量的數據中哪些是涉及該領域風險防控的核心要素,對應核心要素之間如何構建關聯,目前均處于探索階段,因而數據仍處于散點狀態,無法直接應用于風險防控之中,進而導致無法借鑒應用現有智能化風控的各種先進技術,實現風險的多元分析和關聯分析。
對相關數據進行甄別和篩選,串聯構建關鍵實體和數據關聯,建立專業化的領域知識圖譜,能夠充分挖掘和發揮各種數據資源的價值和潛力,將沉淀積累的各種數據轉化為知識,為風險分析提供強大的基礎支撐。
(二)為海關特殊監管區域防控提供物流支撐
2022年1月1日,海關總署頒布了《中華人民共和國海關綜合保稅區管理辦法》,其中具體列明了區內企業可以開展的11大類業務。可以看出,綜合保稅區的功能已經從單一的保稅、倉儲逐步擴展到其他業務領域,這使得貨物流轉更加復雜。以貨物從境外進入特殊監管區域為例,不考慮貨物用途和使用目的等情況,按貨物流轉方向進行歸結簡化后就存在三個流向(詳見圖1),一是企業以加工成品出口或貨物復運出境;二是企業以0110監管方式出區進口到國內市場;三是企業將保稅貨物轉運到其他特殊監管區域、保稅監管場所或保稅加工企業進行保稅間結轉。
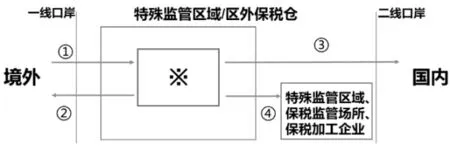
圖1 特殊監管區域相關流程圖
目前,傳統的關系型數據庫存儲方式為二維結構,只能針對單個企業、單票貨物、單個環節的單向數據,與特殊監管區域復雜的流向、復雜的物流鏈條不匹配,導致數據鏈條存在斷層、貨物跟蹤分析難度較大,無法從整體上把握供應鏈存在的風險。
結合特殊監管區域風險防控的具體需求,合理規劃知識圖譜不同實體之間的屬性,充分運用知識圖譜編織關系網絡的能力,串聯構建特殊監管區域貨物流轉的完整鏈路圖,為分析人員開展貨物流向跟蹤和整體性風險掌控提供切實可用的手段和工具。
(三)知識圖譜為特殊監管區域風險防控賦能
海關內部業務數據專業性強,風險特征知識豐富,圍繞監管業務關系密切。知識圖譜為特殊區域風險防控賦能主要體現在以下兩個方面:一是由傳統的專家經驗轉化為風險知識沉淀。風險特征的要素是風險分析人員開展風險研判的基礎,但目前各業務領域的風險特征或存于業務專家的腦海中,或應用于特定工作領域中,無法廣泛應用于基層海關的風險防控中。利用知識圖譜,梳理常見風險特征,建立切實有效的特征體系,將風險知識進行沉淀,應用于海關風險管理業務系統中。二是引入風險“關系”分析能力,拓展風險分析維度和方法。引入知識圖譜各種新的智能化風控技術手段,逐步實現特殊區域風險防控的智慧化,比如不一致性驗證,通過一些人為提前設計好的規則去找出潛在的矛盾點;或者高風險的判定,基于規則對實體深度關系有無觸碰黑名單進行判別;再或者識別團體欺詐,通過實體之間關系、社群的劃分,鎖定強關聯關系,識別團體。
二、構建海關特殊監管區域風險防控需求的知識圖譜
總體思路是,結合特殊區域風險防控的具體經驗,探索建立以物流和加工企業為核心實體、以貨物流轉為核心關系、面向特殊監管區域風險防控的領域知識圖譜,充分將實貨流轉和保稅倉儲過程以及上述過程涉及的核心監管對象、風險把控節點進行展示,從而為貨物流轉跟蹤、異常分析檢測、智慧風險防控提供基礎支撐。
(一)建設知識圖譜具體架構
常見的知識圖譜示意圖主要包含三類要素:實體、屬性、關系。實體指的是具有可區別性且獨立存在的某種事物,如某一個人、某一張報關單、某一件商品等。實體是知識圖譜中的最基本元素,不同的實體間存在不同的關系。而屬性是描述實體和關系的特征,用來區分實體或關系的相同或相異,如性別、國家、民族、籍貫等屬性。關系則表示不同實體之間的聯系,一般在知識圖譜中以“邊”來顯示,不同關系的屬性類型對應于不同類型的“邊”。如果關系的屬性是描述兩個實體之間的關系,稱為對象屬性;如果關系的屬性值是具體的數值,則稱為數據屬性。
(二)知識圖譜架構與海關數據的嵌套
知識圖譜要有效地應用到海關特殊監管區域風險防控,就需要與現有數據資源進行整合嵌套,首先需要思考如何結合業務實際和應用目標,構建對應的三元組:
1.實體選擇包括以下幾個維度
實體的選取和考量,主要是結合特殊監管區域的業務實際,選取在特殊區域內占主導地位或能串聯較多關聯關系的對象:一是選取整個物流鏈條中經營活動的主導者,或是串聯整個圖譜各種關系的核心要素,也是風險防控的處置對象,例如特殊區域內的物流倉儲和加工企業、國內實際貨主企業等;二是選取相對可靠并且可以布控驗證的數據,例如涉及實際貨物進出特殊區域的載體、車牌號和集裝箱號;三是選取能體現總體趨勢或集中度的對象,比如代表貨物實際進出境的口岸、代表貨物的原產國別、貿易國別等;四是選取其他一些常見的風險特征,比如代表貨物境外關聯關系的境外收發貨人、代表貨物代理報關業務的報關行等。
2.不同屬性對應的關系展示
對象屬性的關系分類:以區內物流企業為維度的例子,如圖2所示。
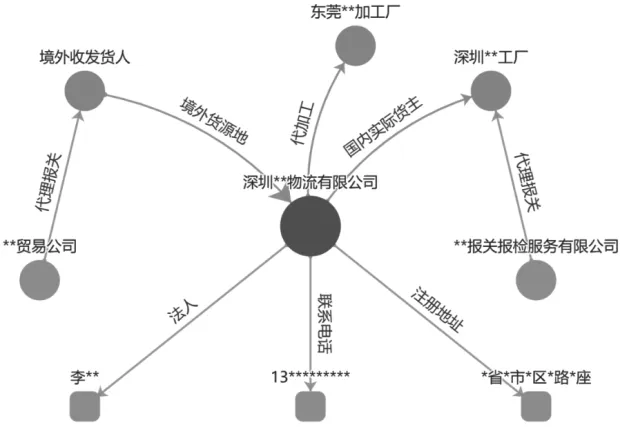
圖2 對象屬性的關系分類
數據屬性的關系分類:以商品流向為維度的例子,如圖3所示。
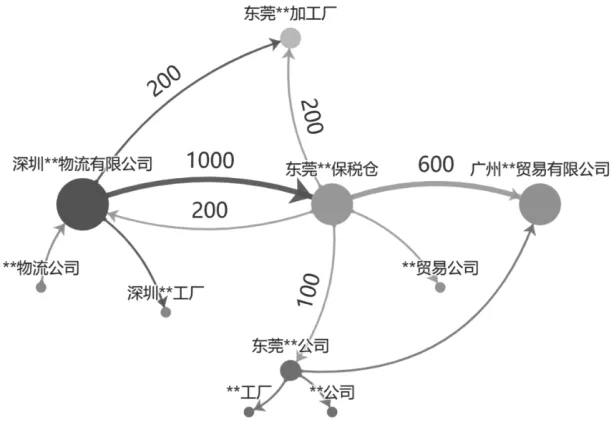
圖3 數據屬性的關系分類
3.不同屬性對應的關系和權重
知識圖譜的關系代表圖上“邊”的劃分,而關系對應的屬性,則代表“邊”的值。如何判定圖譜中各個實體之間關系的密切程度,核心點在于“邊”之間的權重關系,所以需要初擬一個實體關系屬性權重判定表,讓知識圖譜進行學習。結合日常風險防控經驗開展測試和探索,初步構建的權重對應關系,因涉及數據安全要求,僅以下表1為示例。
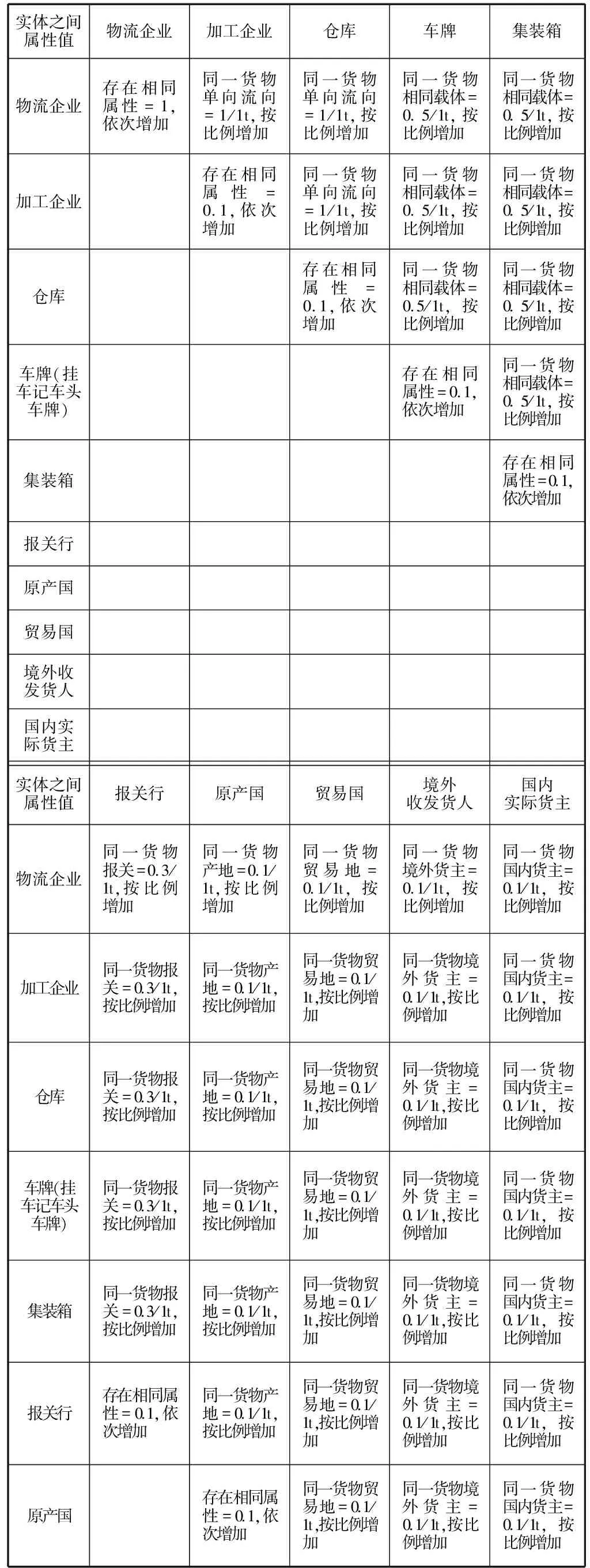
表1 對應權重關系
三、知識圖譜結合海關特殊監管區域風險防控的應用
構建好知識圖譜之后,接下來就要用它來解決具體問題。對于特殊監管區域風險防控的具體需求而言,就是通過挖掘關系網絡中的異常點。鑒于目前技術和業務的現狀,建議采取基于規則為主的各種人工智能算法,應用到數據分析和甄別中,為風險防控提供新的思路和手段,后續再逐步拓展引入基于概率的智能算法。
(一)團伙作案的特征分析
近年來,特殊監管區域走私違法案件出現明顯的團伙作案特征。以某供應鏈公司高檔消費品偽瞞報走私案件為例,根據公開的法律文書檔案,案件涉及的核心主體為被告單位某供應鏈公司,該主體同時聯系國內多家貨主企業,通過跨境電商,利用非法獲取的個人信息,虛假郵寄報關,達到走私目的,逃避海關監管和稅收。
團伙作案一般具有手法隱蔽性強、反風險監測意識強、主觀違法意識明確的特點,在分析和防控處置中,需要充分挖掘團伙成員開展聯動處置,從而防止打草驚蛇。知識圖譜各類團伙檢測算法相對成熟,可以幫助風險分析人員提前探測形成企業團伙關系,在發現其中某一企業存在違法違規行為風險時,即時開展整體分析和聯動處置。結合上述知識圖譜的構造特點,利用知識圖譜近鄰算法和社群算法相結合的方式,最為直接有效。
在對象屬性上,上述圖譜的構建主要側重于實體的自然屬性,可以采用近鄰學習算法對不同企業團伙進行分類劃分。近鄰學習算法(nearest neighbor methods,k-NN)最早是1968年由COVER和HART提出的,目的是判斷實體之間的相似度,實現團伙的識別。該算法能快速鎖定多個實體之間共享的信息要素,比如多家企業共用一個聯系電話和注冊地址,從而揭示實體間的強關聯關系。
在數據屬性上,上述圖譜的構建側重于貨物流轉的關聯關系,因而社群算法更為適用。社群算法(label propagation,LPA)表示與實體A有關聯關系的其他實體屬于哪個社群最多,實體A就屬于哪個社群,實現社群的劃分。比如某企業群的企業,均只與社群內企業頻繁發生貨物流轉關系,呈現典型的閉環關聯,則可以確定為團伙關系;一旦某個新企業突然參與到社群中,則可以認定為“馬甲”企業。
在應用處置方面,對于團伙中的某票貨物在口岸查發異常,則能夠迅速鎖定其他關聯企業開展攔截防控處置,同時能及時發現“馬甲”企業,避免出現漂移行為;某個企業在后續環節查發異常,則應該對社群中的各個企業聯動開展風險排查和處置。
(二)異常物流流向和行為的監測
應用知識圖譜開展異常物流流向和行為監測。特殊監管區域復雜的物流流向使得數據鏈條斷層、貨物跟蹤分析難度較大,若僅針對單個環節進行分析,無法從整體上把握供應鏈存在的風險。采用劃分聚類分析算法可以對全鏈條進行閉環檢測,梳理識別同一商品的關聯客戶關系,挖掘出人工難以發現的潛在異常物流流向。基于劃分的聚類分析算法(partition-based methods)原理是把相似的東西分到一組,充分運用知識圖譜編織關系網絡的能力,串聯構建特殊區域貨物流轉的完整鏈路圖。對物流流向進行閉環監測,防止利用特殊區域多個企業間貨物循環流轉和利用道具貨物反復在兩個企業間進出,從而達到平衡賬冊核銷的目的,防范企業把保稅貨物銷往國內牟利,短少串換料件的風險。
通過關注實際貨物載體,例如車牌號、集裝箱號或時間維度,例如企業報關或實際進出口岸的時間,監測是否出現同一車輛或集裝箱在多地同時出現、是否存在格式化報關時間等維度,對企業進行異常行為監測。
(三)特殊區域貨物核心路徑的識別
利用知識圖譜開展特殊區域貨物核心路徑的識別。根據管理學原理“帕累托法則”抓住關鍵少數的“二八原則”,在所有進出境的貨物中,僅有20%是違法的,特殊區域風險防控的立足點在于精準判斷出這20%的違法行為,既要“管得住”,又要“放得開”。應用貪心算法,能有效解決該問題。貪心算法(greedy algorithm)指的是在對某個具體問題求解時,把問題分解為若干個子問題,并在子問題中總是做出在當前看來是最好的選擇。即貨物在特殊區域中,針對不同流向的物流鏈條,在每一個環節下,只選擇該環節數量最多的物流流向;通過識別整個物流過程中貨物的核心路徑,抓住其中的關鍵少數,排除多余數據的干擾,提高分析研判的效率。
通過對進出特殊區域的貨物數據進行匯總分析,梳理企業間的上下游關系和數據間的關聯關系,厘清統計口徑的計算方法,判斷數據的大小,給風險分析人員提供思路,排除其他物流流向的干擾,準確識別貨物核心路徑。
四、下一步的研究方向
(一)智慧化處置和動態監測
上述風險防控知識圖譜的構建,有利于自動識別風險,供風險人員進行分析,但相關后續處置仍需人工進行,為達到全自動化風險監控,進行智能分撥及處置,可以構建海關特殊監管區域后續風險處置知識圖譜,通過對通關、稽查、緝私相關歷史情事的篩選分析,采集風險特征、整理風險驗證手段和后續處置方式等內容,構造針對特殊監管區域風險防控后續處置的知識圖譜。
針對企業建立常規體檢表,實時動態對企業進行監控分析,并結合知識圖譜在各個關鍵環節通過規則分析或設置閾值的形式嵌入“風險探針”,當觸發探針時,結合風險處置知識圖譜分類型處置:對于風險特征精準明確的預警,根據處置規則采取自動布控或攔截等處置手段;對于分析類的預警,自動預警提醒風險人員開展分析處置,并且自動在圖譜中搜索推薦對應的特征變現、驗證手段和歷史查發情事等,為實時動態監測企業提供有力抓手。
(二)深化拓展圖譜規模
本文構建的知識圖譜,只利用了現有海量數據的小部分實體、關系和通過現有經驗總結出來的規則、條件,還有大量尚未納入圖譜范圍內。一是知識抽取,借助于自然語言處理等技術,在網絡上抓取、清洗相關非結構化的關聯數據,提取出結構化信息,為風險分析提供新的思路。二是基于概率的統計模型,對風險進行預測,不需要人為地去定義規則,而是隨著數據的增加和知識圖譜算法的學習,概率模型算法也將會逐步帶來更大的價值。
(三)提供可視化態勢分析
目前,海關風險分析思路主要為先找到風險點,根據風險點尋找異常企業或貨物,再針對具體企業或貨物開展分析,傳統做法較為落后,有一定的滯后性。而知識圖譜構建的可視化態勢分析,通過上帝視角,利用知識圖譜打破現有業務系統隔閡,吸收融合多元數據,構建價值場景——貫穿海關所有業務板塊,建設可供選擇的不同維度的可視化態勢分析。從首頁的一張圖態勢總覽,到各層級監管板塊,甚至到各關區查驗現場詳情,都可以一覽無遺。總攬全局,提前預判風險,精準打擊,維護國門安全。
①帕累托法則,指在任何特定群體中,重要的因子通常只占少數,而不重要的因子則占多數,因此只要控制關鍵少數就能控制全局。
猜你喜歡
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
環球時報(2022-04-25)2022-04-25 17:20:21
今日農業(2021年15期)2021-10-14 08:20:18
云南畫報(2020年9期)2020-10-27 02:03:26
人大建設(2020年3期)2020-07-27 02:48:40
今日農業(2019年14期)2019-09-18 01:21:44
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
