基于K-means Bayes和AdaBoost-SVM的故障分類①
2022-08-04 09:59:06黃子揚(yáng)周凌柯
計(jì)算機(jī)系統(tǒng)應(yīng)用 2022年7期
黃子揚(yáng),周凌柯
(南京理工大學(xué) 自動化學(xué)院,南京 210014)
隨著社會的發(fā)展和科技的進(jìn)步,化工過程和設(shè)備變得更加復(fù)雜與多樣化,故障診斷也成為了當(dāng)代過程監(jiān)控中的一項(xiàng)重要任務(wù)[1,2]. 近年來,由于信息技術(shù)的快速發(fā)展,使得工業(yè)過程中的數(shù)據(jù)可以大量采集并保存,因此基于數(shù)據(jù)驅(qū)動的故障診斷相關(guān)方法得到了學(xué)者們的廣泛關(guān)注[3,4]. 除了基于數(shù)據(jù)驅(qū)動的方法外,基于數(shù)學(xué)模型的方法及基于知識的方法也都是常用方法. 然而基于數(shù)學(xué)模型的方法存在著模型建立難、診斷的結(jié)果直接受模型準(zhǔn)確性影響等問題,因此在復(fù)雜系統(tǒng)中該類方法的使用受到限制; 基于知識的方法則需要大量的經(jīng)驗(yàn)和專家知識來建立知識庫,通用性差. 而基于數(shù)據(jù)驅(qū)動的方法直接對數(shù)據(jù)進(jìn)行分析,能夠規(guī)避上述兩類方法存在的問題,因此目前在復(fù)雜系統(tǒng)中使用更多[5–7].
故障分類技術(shù)在數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)領(lǐng)域得到快速發(fā)展,但是大多數(shù)的分類方法均假設(shè)其訓(xùn)練集中的各類樣本數(shù)相似或相等,當(dāng)訓(xùn)練集呈現(xiàn)數(shù)據(jù)不平衡特征時,分類性能通常并不令人滿意. 張劍飛等[8]指出不平衡數(shù)據(jù)的分類問題廣泛出現(xiàn)在疾病診斷、垃圾郵件處理、信用卡檢測等領(lǐng)域,但傳統(tǒng)的機(jī)器學(xué)習(xí)算法在數(shù)據(jù)不平衡比過大時,分類效果會急劇下降. Japkowicz等[9]指出利用決策樹處理不平衡數(shù)據(jù)時,訓(xùn)練過程會被多數(shù)類的樣本主導(dǎo),導(dǎo)致對少數(shù)類的樣本識別率低.為了提高對不平衡數(shù)據(jù)的分類性能,目前常采用的方法主要包括兩個方面: 數(shù)據(jù)層面和算法層面[10,11]. 在數(shù)據(jù)層面,為降低數(shù)據(jù)的不平衡比,通常會采取欠采樣或過采樣的方法改變訓(xùn)練樣本的數(shù)量. Liu 等[12]提出了一種EasyEnsemble 的欠采樣方法,該方法通過從多數(shù)類樣本中有放回的隨機(jī)采樣出n個每個子集,使子集的樣本數(shù)與少數(shù)類近似相等,并將各子集分別與少數(shù)類樣本合并進(jìn)行訓(xùn)練,從而達(dá)到保留多數(shù)類樣本信息的目的. Chawla 等[13]提出了一種SMOTE (synthetic minority oversampling technique)的過采樣方法,通過對少數(shù)類中的某個樣本及其鄰近樣本進(jìn)行疊加,產(chǎn)生人造樣本來降低樣本間的不平衡度. 雖然上述方法對部分場景下的不平衡數(shù)據(jù)問題具有一定的效果,但是它們?nèi)杂幸恍┎蛔阒幮枰倪M(jìn). 由此,更復(fù)雜的重采樣技術(shù)被提出. 張?zhí)煲淼萚14]提出了一種改進(jìn)SMOTE的重采樣方法,通過將合成樣本從一維空間擴(kuò)展至更高維空間,使新樣本更加多樣化. 李忠智等[15]結(jié)合卷積神經(jīng)網(wǎng)絡(luò)和生成對抗網(wǎng)絡(luò),利用卷積神經(jīng)網(wǎng)絡(luò)從故障樣本中提取訓(xùn)練特征后輸入至對抗網(wǎng)絡(luò),并由解碼器網(wǎng)絡(luò)來生成新的故障樣本. Chen 等[16]提出了一種Kmeans Bayes 方法,利用T 閾值K-means 在既不減少多數(shù)類樣本也不增加少數(shù)類樣本的前提下,提高對少數(shù)類故障的識別能力. 在算法層面,通常是對現(xiàn)有的分類算法進(jìn)行修改,以增強(qiáng)對少數(shù)類的學(xué)習(xí)能力. 如代價敏感學(xué)習(xí)、集成算法等.
Bayes 和SVM 是故障診斷領(lǐng)域常用的兩種方法.Lemnaru 等[17]指出Bayes 和SVM 使用的前提是不同類型樣本的數(shù)據(jù)量近似相等,當(dāng)數(shù)據(jù)不平衡嚴(yán)重時,這兩種方法通常會表現(xiàn)出較差的分類性能. Zhang 等[18]將D-S 證據(jù)理論應(yīng)用于多分類器實(shí)現(xiàn)故障監(jiān)控,有效提高了分類性能. 本文主要研究數(shù)據(jù)不平衡的算法層面,同時考慮到單一方法在這種數(shù)據(jù)不平衡條件下的局限性,提出了一種基于多分類器融合的故障分類方法. 選擇K-means Bayes 作為分類模型1,AdaBoost-SVM作為分類模型2,并利用D-S 證據(jù)理論將二者的分類結(jié)果進(jìn)行融合,進(jìn)一步提升分類性能. 將該方法運(yùn)用在Tennessee Eastman (TE)數(shù)據(jù)集上,經(jīng)仿真和實(shí)驗(yàn)證明了所提方法的有效性及可行性.
1 K-means Bayes 算法
1.1 Naive Bayes
Naive Bayes 是一種基于貝葉斯定理和條件獨(dú)立性假設(shè)的分類方法[19]. 給定一組訓(xùn)練數(shù)據(jù)T={(x1,y1),(x2,y2),···,(xN,yN)},其中,N為訓(xùn)練樣本總數(shù),xi=為每一個樣本數(shù)據(jù),yi={C1,C2,···,Ck}為各樣本數(shù)據(jù)對應(yīng)的標(biāo)簽,對于一個測試樣本x,Bayes分類器將后驗(yàn)概率P(Y=Ck|X=x)最大的類作為x的類輸出:

依據(jù)條件獨(dú)立性假設(shè),且每個連續(xù)變量x(j)均服從高斯分布:

對于樣本x的分類結(jié)果為:

1.2 K-means Bayes
K-means Bayes 算法[16]的思想為: 在不改變原始數(shù)據(jù)集信息的情況下降低數(shù)據(jù)不平衡性對故障分類帶來的影響. 算法步驟如算法1.

算法1. K-means 對多數(shù)類均分X=[x1,x2,···,xm]X*1)給定多數(shù)類樣本,標(biāo)準(zhǔn)化得到 ;X*kμT=m/k 2)指定個聚類子集: 從 中隨機(jī)選擇個樣本點(diǎn)作為初始聚類中心,并計(jì)算各子集的樣本數(shù);U={U1,···,Uk} U*={U?1,···,U?k}Ui k 3)設(shè)置2 個集合和,其中 存放原始樣本數(shù)據(jù),存放標(biāo)準(zhǔn)化后的數(shù)據(jù);X?x*μi U?i U?i 4)對 的各樣本 ,計(jì)算與各聚類中心的距離,找出距離最近的 及對應(yīng)的 ;U?ini≤Tni≤Tx*x U?iUini≥T Ui 5)判斷 的樣本數(shù) 是否 . 若,則將 和對應(yīng)的分別分配至和 ,并轉(zhuǎn)至4)對下一個樣本進(jìn)行計(jì)算; 若,則該樣本將不再分至 ,并轉(zhuǎn)至4)重新計(jì)算;U?i 6)當(dāng)所有樣本完成分類后,計(jì)算各子集 的樣本均值,并作為新的聚類中心 ,并判斷各 與 是否相等; 若則算法終止輸出結(jié)果,否則返回3)進(jìn)行下一輪計(jì)算.μ′i μi μ′i μi=μ′i Ui
對于測試樣本x,可利用式(3)預(yù)測其類別,再利用
式(4)轉(zhuǎn)換成實(shí)際類別:

2 AdaBoost-SVM 算法
2.1 SVM
SVM (support vector machine)[20]是一種有監(jiān)督的二分類模型,其思想是尋找到一個分離超平面,此超平面不僅能正確劃分開正負(fù)實(shí)例點(diǎn),還能使離超平面最近的點(diǎn)(支持向量)離超平面盡可能的遠(yuǎn). 給定一組線性可分的訓(xùn)練數(shù)據(jù)集T={(x1,y1),···,(xN,yN)},其中xi∈X∈Rn,yi∈Y∈{+1,?1},則分離超平面為:

分類決策函數(shù)為:

為解決多分類問題,通常將多分類問題進(jìn)行拆分并利用投票機(jī)制進(jìn)行分類. 常用的拆分策略包括“一對多”和“一對一”,本文使用“一對一”策略,這樣由少數(shù)類構(gòu)成的子分類器的正類和負(fù)類可看成是平衡的,有利于提高分類性能. 由于可能存在子分類器對某些類的分類能力較差,影響最終的投票結(jié)果,因此引入AdaBoost分類器替換[21,22].
2.2 AdaBoost
AdaBoost (adapative boost)[23]是提升學(xué)習(xí)Boosting里的一種,其思想是通過反復(fù)學(xué)習(xí)得到一系列的弱分類器,并將這些弱分類器進(jìn)行加權(quán)組合得到一個強(qiáng)分類器.

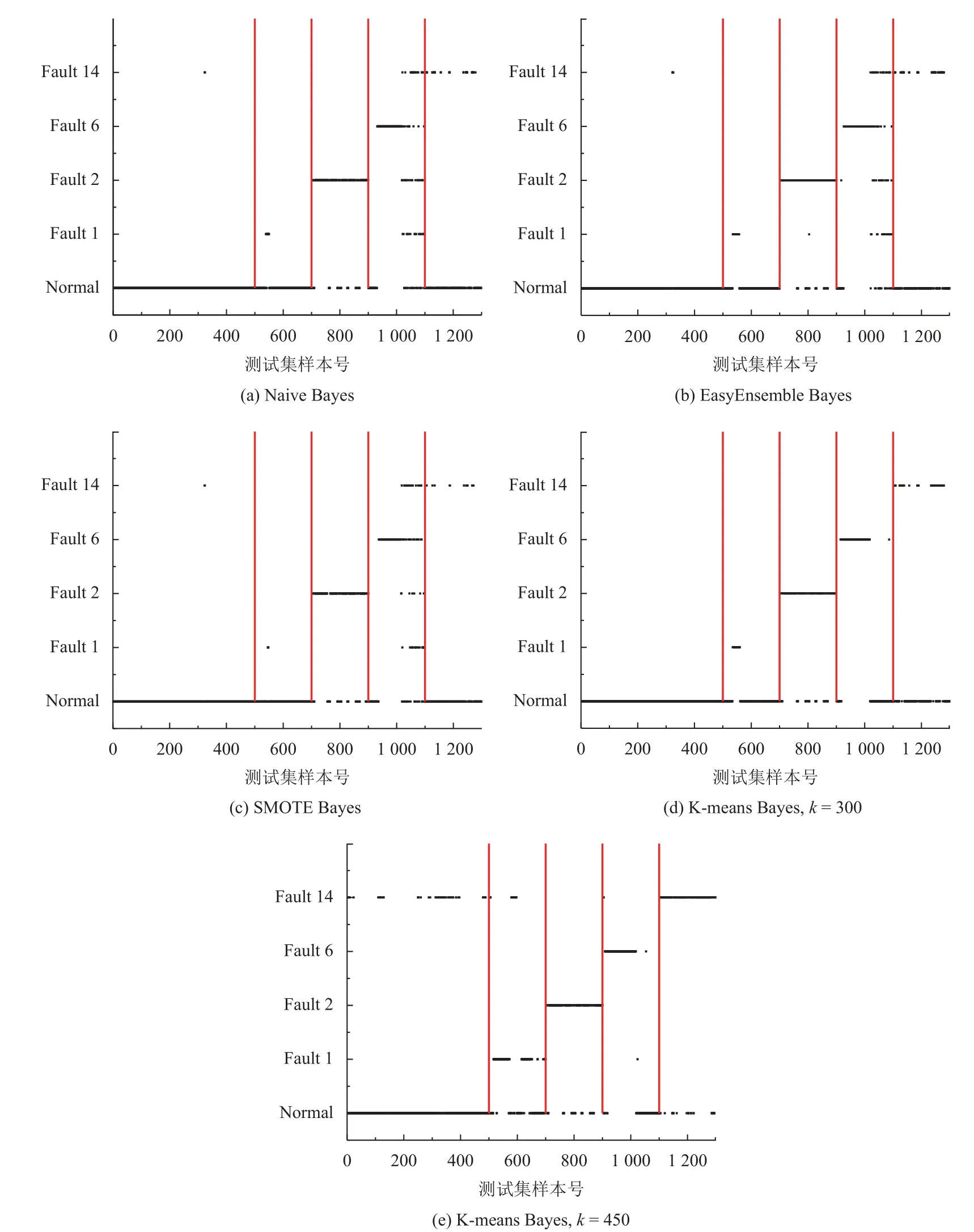
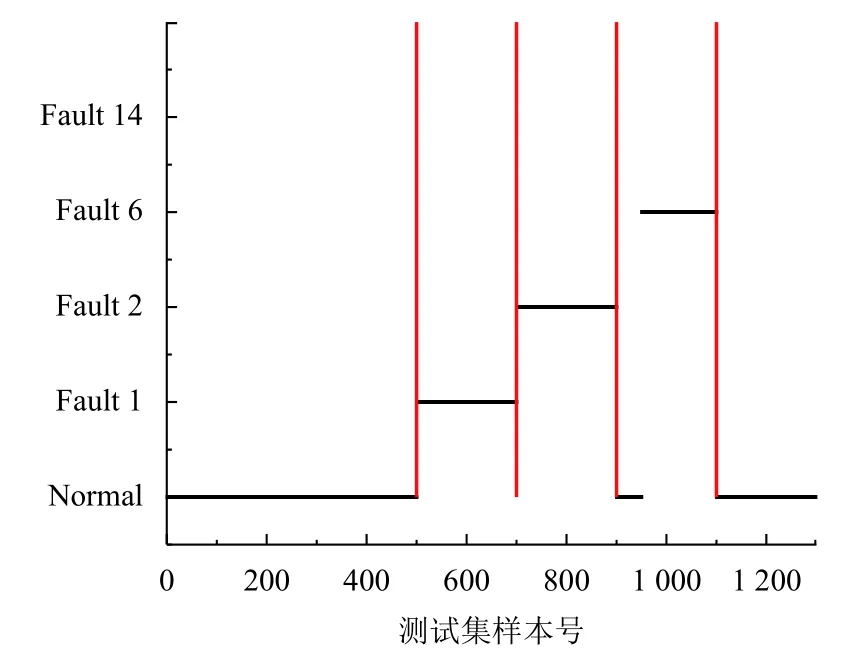
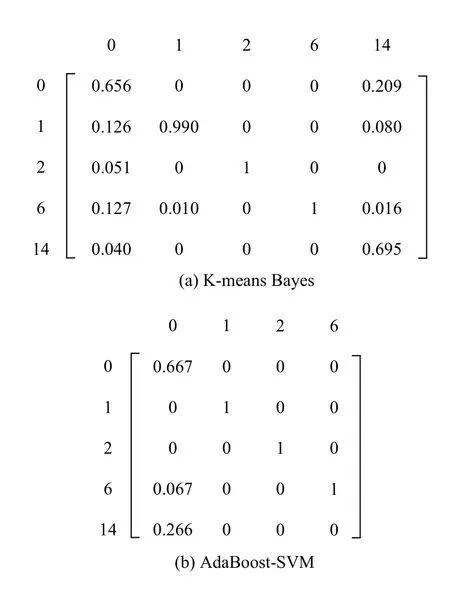
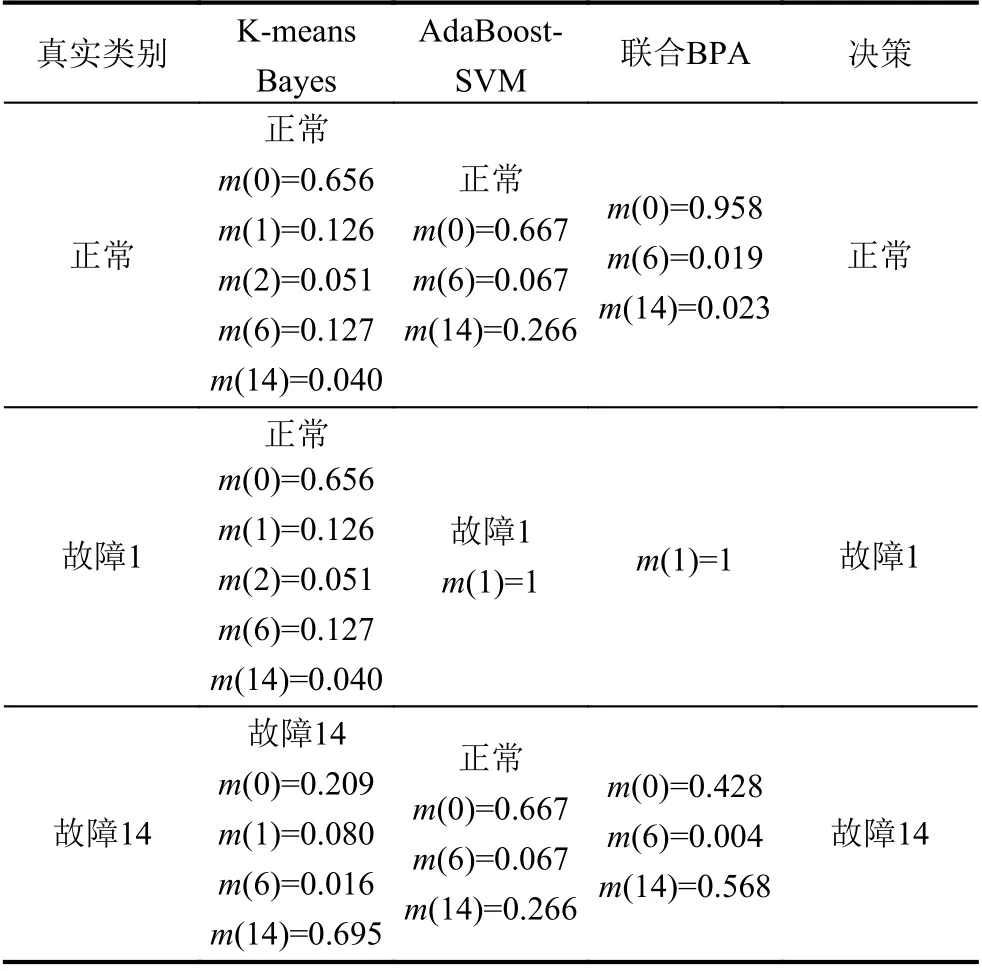
算法2. AdaBoost-SVM 1)設(shè)置每個子分類器的最低分類正確率;Accmin N=C2n 2)根據(jù)類別總數(shù)n 構(gòu)建SVM 子分類器,其中子分類器總數(shù)為;3)對各SVM 子分類器進(jìn)行訓(xùn)練,其中核函數(shù)選擇徑向基核函數(shù)(RBF),并利用網(wǎng)格法和三折交叉驗(yàn)證法進(jìn)行參數(shù)尋優(yōu),選擇合適的懲罰參數(shù)C 及核參數(shù)g;4)對訓(xùn)練好的分類器在相應(yīng)的測試集上進(jìn)行分類,計(jì)算各子分類器的實(shí)際正確率;Accreal 如果能設(shè)計(jì)出一種在任何情況下都具有良好泛化性能的分類器,那么單一分類器就已經(jīng)能夠滿足需要.然而實(shí)際采集到的數(shù)據(jù)存在著噪聲點(diǎn)、異常等問題,使得上述的單一分類器難以實(shí)現(xiàn). 因此考慮創(chuàng)建一個故障分類系統(tǒng),該系統(tǒng)中存在兩個及以上的分類器,并希望其分類性能優(yōu)于其中任意單一分類器. 當(dāng)某個分類器在識別時發(fā)生錯誤,其他分類器可以糾正該分類器的錯誤. 圖1 展示了一種基于D-S 證據(jù)理論的故障分類框架. 該框架主要分為兩個部分: 利用訓(xùn)練數(shù)據(jù)進(jìn)行離線建模、利用建立好的模型對數(shù)據(jù)進(jìn)行在線分類. 具體來說,本系統(tǒng)的實(shí)施主要包括3 個步驟: 1)分類器構(gòu)建;2)計(jì)算各分類器的融合矩陣; 3)利用D-S 證據(jù)理論進(jìn)行決策融合. 圖1 基于D-S 證據(jù)理論的故障分類框架 為了進(jìn)行D-S 證據(jù)理論融合,應(yīng)計(jì)算出各分類器的融合矩陣[18]. 假設(shè)樣本類別集合T={F1,F2,···,Fn},其中第i個類別稱為Fi,i=1,2,···,n,n為所有類別的總數(shù). 分類器總個數(shù)為N,其中第k個分類器的融合矩陣表示為FMk,k=1,2,···,N. 則FMk可表示如式(7). 其中FMk的行代表真實(shí)類別F1,F2,···,Fn,列代表由該分類器預(yù)測出的類別F1,F2,···,Fn,元素Nikj表示由該分類器預(yù)測類別為Fj而真實(shí)類別為Fi的樣本數(shù)之和. 因此對于每個分類器的融合矩陣FMk而言,矩陣的每列之和為定值1. 1)計(jì)算分類器對某個樣本x的預(yù)測類別為Fj時對應(yīng)Fi的基本概率分配(BPA): 2)依據(jù)D-S 融合規(guī)則計(jì)算聯(lián)合BPA 值: 3)選擇最大的聯(lián)合BPA 值所對應(yīng)的類別Fi作為最終決策: 本文所提到算法均以TE 過程數(shù)據(jù)為基礎(chǔ). TE 過程由伊斯曼化學(xué)公司所創(chuàng)建,該仿真模型在真實(shí)化工過程基礎(chǔ)上構(gòu)建[24]. 其工藝流圖如圖2. 該過程通過4 種氣態(tài)反應(yīng)物(A、C、D、E)和惰性成分B 生成產(chǎn)品G、H 及副產(chǎn)品F. TE 數(shù)據(jù)可由開源的Simulink 代碼生成,數(shù)據(jù)集共包括41 個測量變量和11 個控制變量,數(shù)據(jù)除正常類型外還包括21 種不同類型的故障,本文所使用的故障類型如表1. 部分仿真結(jié)果如圖3. 表1 TE 過程故障 圖2 TE 過程流程圖 圖3 Bayes 相關(guān)算法仿真結(jié)果 圖3(a)為利用Naive Bayes 進(jìn)行故障分類的結(jié)果,測試集的分類正確率為62.1%,可以看出該方法在這種不平衡數(shù)據(jù)下的分類能力較差; 圖3(b)為利用EasyEnsemble Bayes 的分類結(jié)果,通過EasyEnsemble將正常類樣本有放回的抽取15 組,每組10 個樣本并分別與故障樣本組合,最終的分類正確率為65.4%,與Naive Bayes 相比略有提升,但故障1 和故障14 的識別率依然較低,說明EasyEnsemble 方法并不能完全解決數(shù)據(jù)稀缺性帶來的問題; 圖3(c)為利用SMOTE Bayes 的分類結(jié)果,通過SMOTE 為每個少數(shù)類增加10 個合成樣本,在一定程度上彌補(bǔ)了少數(shù)類樣本的稀缺性. 但利用這種方式對測試集的分類結(jié)果不理想,甚至低于Naive Bayes,且經(jīng)實(shí)驗(yàn)仿真發(fā)現(xiàn)利用SMOTE分別為每個少數(shù)類依次增加20 個、30 個、40 個樣本時,預(yù)測的準(zhǔn)確率也幾乎沒有提升,其原因可能在于所使用的部分訓(xùn)練樣本本身處于所在樣本集的分布邊緣,則由此及其相鄰樣本產(chǎn)生的人造樣本也會處于這個邊緣,且會越來越邊緣化,從而使分類更加的困難; 圖4(d)、圖4(e)為利用K-means Bayes 的分類結(jié)果,當(dāng)分類子集數(shù)k=450 時,與前幾種方法相比正確率得到顯著提升,預(yù)測的準(zhǔn)確率達(dá)到了76.0%,但對故障1、6 的分類能力仍存在一定的缺陷. 圖4 SVM 仿真結(jié)果 SVM 是一種經(jīng)典的二分類學(xué)習(xí)算法,在使用SVM 之前,為解決多分類問題,本文選擇“一對一”策略對多分類問題進(jìn)行拆分,如表2 所示. 通過構(gòu)建10 個子分類器,對測試集樣本進(jìn)行分類預(yù)測,正確率為70%,如圖4 所示,且對故障1 和故障14 的分類能力差. 通過分析各SVM 子分類器的分類性能,發(fā)現(xiàn)C1、C4、C6、C7 及C10 這5 個子分類器對對應(yīng)測試樣本的分類能力差. 表2 SVM 子分類器 為克服上述5 個子分類器分類能力差的問題,本文利用AdaBoost 算法構(gòu)建5 個強(qiáng)分類器,分別替代原SVM 的C1、C4、C6、C7 及C10 再重新進(jìn)行預(yù)測,如圖5 所示. AdaBoost-SVM 的最終預(yù)測正確率為80.7%,除故障14 外其余類型樣本預(yù)測均比較準(zhǔn)確,其原因?yàn)槔肁daBoost 構(gòu)建的C4 分類器依然無法正確識別故障14 類型的樣本. 圖5 AdaBoost-SVM 仿真結(jié)果 為進(jìn)一步提高分類性能,使用本文提出的決策融合算法,選擇K-means Bayes 和AdaBoost-SVM 的預(yù)測結(jié)果作為證據(jù)體計(jì)算融合矩陣,并進(jìn)行D-S 融合,分類正確率達(dá)到93.1%,結(jié)果如圖6、圖7 所示. 圖6 D-S 融合仿真結(jié)果 圖7 兩種方法的融合矩陣 在上述2 個融合矩陣中,矩陣的行表示數(shù)據(jù)的真實(shí)標(biāo)簽分類,列表示利用模型的預(yù)測分類,矩陣的每一列元素和為1. 由于AdaBoost-SVM 對所有測試樣本均未分類到故障14,故融合矩陣中缺少預(yù)測為故障14 的列. 表3 展示了故障分類的部分信息融合過程,根據(jù)各分類器對某個測試樣本的預(yù)測結(jié)果,選擇對應(yīng)的融合矩陣中的數(shù)據(jù)實(shí)現(xiàn)數(shù)據(jù)融合. 表3 故障分類部分信息融合 本文針對不平衡數(shù)據(jù)的故障分類問題,分別提出了K-means Bayes 和AdaBoost-SVM 的分類策略. 利用K-means 對多數(shù)類的樣本劃分為K個子集,在不丟失多數(shù)類樣本信息的前提下降低了不平衡度,提高了Bayes 的分類準(zhǔn)確率; 利用AdaBoost 對分類能力較差的SVM 子分類器進(jìn)行替換,提高了SVM 的分類準(zhǔn)確率; 再利用D-S 證據(jù)理論對二者的預(yù)測結(jié)果進(jìn)行融合,得到更好的分類結(jié)果. 由基于TE 過程的仿真結(jié)果可知,本文提出的決策融合算法與單一的傳統(tǒng)算法相比具有更好的故障分類性能.3 決策融合算法
3.1 故障分類框架

3.2 計(jì)算各分類器的融合矩陣

3.3 基于D-S 證據(jù)理論的決策融合


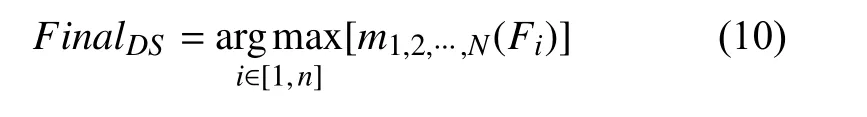
4 仿真實(shí)驗(yàn)
4.1 TE 過程


4.2 仿真結(jié)果及分析



5 結(jié)論與展望
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
汽車維護(hù)與修理(2016年10期)2016-07-10 08:17:41
