基于預訓練模型與無人機可見光影像的樹種識別①
2022-08-04 09:59:44羅仙仙許松芽陳桂蓮萬曉會
計算機系統應用 2022年7期
關鍵詞:模型
羅仙仙,許松芽,陳桂蓮,嚴 洪,萬曉會
1(泉州師范學院 數學與計算機科學學院,泉州 362000)
2(福建省大數據管理新技術與知識工程重點實驗室,泉州 362000)
3(泉州師范學院 教育科學學院,泉州 362000)
4(福建省林業調查規劃院,福州 350003)
人工智能是未來的第一生產力,人工智能技術與方法在我國林業中的應用初見端倪. 遙感圖像的樹種識別始終是國際關注的學術前沿[1]. 無人機低空航拍受天氣影響小,作業方式靈活,獲取的影像比例尺大,精度高,為森林資源遙感調查研究提供了新的技術手段[2].然而,傳統人工目視解譯方法和遙感圖像處理方法,并不能夠對無人機遙感圖像進行自動識別,而且精度難以保證.
深度學習是人工智能研究中重要方法,2006 年加拿大多倫多大學Hinton 等提出[3],能夠模擬人的神經系統,可以從大量數據中自動提取特征. 深度學習方法用于無人機樹種識別的研究剛剛起步. 由于深度學習方法依賴于大量的訓練數據與測試數據,并且數據標注費時費力,一定程度限制深度學習在遙感圖像樹種識別研究,因此,少樣本的遷移學習方法是當前研究熱點. 目前,尚沒有開放的無人機樹種識別數據集[1],武紅敢等人指出林業遙感專用數據庫的必要性和緊迫性,并提出建設思路和原則[4].
遷移概念最早由心理學家提出,一般認為,遷移是指一種學習對于另一種學習的影響[5]. 在人工智能和機器學習領域,遷移學習是一種學習的思想和模式,可以利用數據、任務或模型之間的相似性,將在舊領域學習過的模型和知識應用于新的領域. 基于模型的遷移學習方法(預訓練方法)是指從源域和目標域中找到它們之間共享的參數信息,以實現遷移方法[6]. 預訓練模型在大數據集(如ImageNet[7])上訓練得到一個具有強泛化能力的模型,作為后續任務的基準模型,通過少量有標注的數據微調訓練可以取得較好識別效果.
近兩年,林業遙感領域的研究學者把遷移學習應用于無人機影像的樹種識別. 王莉影等[8]較早應用遷移學習思想,基于Inception-v3 模型在ImageNet 數據集上進行預訓練,然后利用有限樣本重新訓練一個全連接層,對東北林業大學實驗林場只進行針葉林、闊葉林分類研究,總體分類精度為98.4%,Kappa 系數為0.987. 滕文秀等[9]基于遷移學習思想,對4 種常規的卷積神經網絡方法在ImageNet 數據集上進行預訓練后,增加全局平均池化層、1 個全連接層和1 個Softmax層,對4 個樹種進行分類,研究表明VGG16 作為樹種分類模型的預訓練模型是好的. Natesan 等 [10] 基于ResNet50 模型在ImageNet 數據集上進行預訓練后,增加最大池化層和4 個全連接層,基于Keras 框架進行3 類樹種分類,總體精度達80%. 總之,現有研究沒有對數據集制作詳細介紹,數據集尚未共享一定程度影響此領域迅速發展.
論文利用TensorFlow 框架,基于VGG16 在Image-Net 數據集上預訓練模型,進行無人機可見光影像樹種識別研究. 利用大疆精靈4RTK 無人機,搭載FC6310R相機,采集南平市和三明市的杉木和馬尾松人工純林彩色圖像. 通過圖像預處理、標注、裁剪和增強等環節構建兩個數據集UAVTree2k 和UAVTree20k. 基于UAVTree2k 數據集和VGG16 模型在ImageNet 數據集的預訓練模型,重新定義3 個全連接層,輸出層設置成2,進行小樣本的杉木和馬尾松二分類研究; 驗證小樣本的預訓練模型的有效性,以期為復雜林分環境下的樹種分類與制圖提供參考.
1 數據集的構建
1.1 無人機外業數據采集
杉木與馬尾松數據采集,均采用無人機大疆精靈4RTK,搭載機型為FC6310R,相機像素為2000 萬(5472×3648). 杉木拍攝時間為2020 年11 月19 日,圖像采集天氣狀況好. 拍攝地點位于南平市邵武市下沙鎮,地理位置位于117.60°E、27.33°N,森林覆蓋率約73%,拍攝范圍地勢較為平坦,相對高差約100 m,拍攝高度約為150 m,拍攝對象為杉木人工純林,拍攝方式為垂直俯視,經過圖像預處理、拼接后圖像(.tif 格式)如圖1 所示. 馬尾松拍攝時間為2020 年12 月29 日至30 日,天氣狀況良好. 拍攝地點位于三明市清流縣溫郊鄉溫家山村,拍攝高度約為180 m,拍攝對象為馬尾松人工純林,拍攝方式為垂直俯視,經過圖像預處理、拼接后圖像如圖2 所示.
1.2 數據標注
采用圖像標注工具LabelImg (https://github.com/tzutalin/labelImg),分別從圖1 和圖2 中,找出單一杉木或馬尾松區域,采用矩形拉框,長寬大小不一,大約為224×224,坐標為(xmin,ymin,xmax,ymax),杉木標簽設為0,馬尾松標簽設為1,共標注了1 058 張杉木、1 278 張馬尾松圖像,數據標注完成后生成.xml 文件,該文件只存儲矩形拉框的坐標信息,無法直接導出已標注好的圖像.

圖1 杉木人工純林

圖2 馬尾松人工純林
1.3 數據裁剪
采用Python 編程實現批量數據的裁剪. 編寫readXML()函數,讀取xml 文件坐標,并轉化為pillow模塊的圖像坐標格式(left,upper,right,lower); 編寫save_tif()函數,從原始的.tif 圖像中一次性裁剪出1058張杉木、1 278 張馬尾松圖片.
1.4 數據增強
數據增強是一種能夠有效擴充數據集的數據處理手段. 采用10 種方式對原始數據進行增強: (1)對原始圖像進行垂直翻轉和水平翻轉; (2)對原始圖像進行逆時針90°、270°旋轉處理; (3)對原始圖像進行灰度化處理; (4)對原始圖像進行2 種亮化處理(亮化系數分別為1.2 和1.4); (5)對原始圖像進行2 種飽和度處理(飽和度系數為2 和4); (6)對原始圖像進行隨機裁剪,裁剪后圖像大小調整為原始圖像大小. 單張馬尾松圖片數據增強如圖3 所示.

圖3 單張馬尾松的數據增強
1.5 數據集構建
從數據裁剪后的1 058 張杉木、1 278 張馬尾松圖片中,選取杉木、張馬尾松各1 000 張圖片構建數據集,取名為UAVTree2k,其中2 表示2 個樹種,2k 表示訓練集與測試集的總數為2 000 張,其中,杉木和馬尾松圖片各1000 張. 定義數據讀取函數read_image_filenames(),讀取指定目錄下的圖片信息,返回文件名列表和標簽列表; 定義解碼圖片和調整圖片大小函數decode_image_and_resize(),讀取圖片并解碼,重新調整圖片大小并進行歸一化處理; 通過TensorFlow 框架下的tf.data.Dataset 的from_tensor_slices()方法生成小樣本數據對(圖片,標簽). 通過數據增強,將數據裁剪后圖像,擴大為10 580 張杉木圖像和12 780 張馬尾松圖像,從中選取各10 000 張的圖像作為數據集,取名為UAVTree20k,20k 表示訓練集與測試集的總數為20 000 張.
2 研究方法
2.1 VGG16 模型
VGG-Net 是牛津大學計算機視覺組(visual geometry group)和Google DeepMind 公司的研究員一起研發的深度卷積神經網絡[11],VGG-Net 在2014 年大規模視覺識別挑戰賽(ILSVRC)中,奪得圖像分類第2 的成績. VGG-Net 的網絡層數從11 層到19 層不等. 常用的VGG16 模型由13 個卷積層和3 個全連接層堆疊而成,總共包含約1.38 億個參數. 所有卷積層使用3×3 的卷積核和ReLU 激活函數,以加強特征學習的能力.VGG16 模型整體上分為8 段,前5 段為卷積層,后3 段為全連接層. 卷積層重疊2 或3 次后形成一個卷積段,同一段內的卷積層具有相同的卷積核數,每個卷積段后有一個2×2 的最大池化層,池化層將圖片大小縮小一半. 每增加一個卷積段,卷積核數增加一倍. VGG16具體結構見圖4.
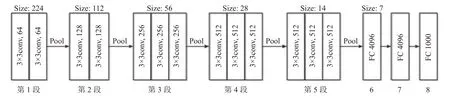
圖4 VGG16 的結構
2.2 基于VGG16 的預訓練—微調模型
基于VGG16 的預訓練—微調模型如圖5 所示,分為共享層和遷移層[6]. 共享層為VGG16 中前13 個卷積層,主要提取圖像的低級特征. 因為這些特征是通用特征,所以共享層采用VGG16 模型在ImageNet 上訓練好的模型,并凍結其權重與參數. 遷移層提取圖像的高級特征,是整體模型的核心層. 重新訓練3 個全連接層,其中包括輸出層FC2,該層采用Sigmoid 激活函數.考慮訓練樣本較少,全連接層分別采用128 和32 個神經元,在FC128 和FC32 后分別加了Dropout 方法,其系數均設置為0.3,隨機刪除全連接層的部分神經元,防止過擬合,提高模型泛化能力.

圖5 基于VGG16 的預訓練—微調模型
3 實驗與結果分析
3.1 云環境及其搭建
本機為Windows 10 的64 位操作系統,采用阿里云服務器2 核4G 的共享型實例,在云端搭建Tensor-Flow 2.3.0、Anacona 3.0、Python 3.7 等環境. 采用基于VGG16 的預訓練-微調模型進行無人機可見光影像的樹種識別,數據集采用UAVTree2k. 基于數據集UAVTree2k,進行VGG16 模型重新訓練與測試. 探討迭代次數、批次大小、數據集劃分比例對訓練精度與測試精度影響. 所有實驗參數更新采用Adam 優化器,學習率采用0.001.
3.2 實驗結果與分析
3.2.1 迭代次數對精度影響
為探討迭代次數對精度的影響,固定訓練集1200張,測試集800 張; 批次大小為16. 迭代次數依次從{10,20,30,40,50,60}中取值,得到訓練集的精度分別為0.9087,0.9319,0.9800,0.9800,0.9856,0.9925,測試集的精度分別為0.9425,0.9525,0.9675,0.98,0.9675,0.9775. 精度與迭代次數關系如圖6 所示. 從圖6 可看出,訓練精度均在90%以上,隨著迭代次數的增加,訓練精度整體呈上升趨勢; 訓練精度均在94%以上,測試精度整體上隨迭代次數的增加而增加. 究其原因,隨迭代次數增加,模型權重、參數不斷更新,學習到的特征越多,測度精度也就越好. 當迭代次數為40 時,測試集精度下降,而后上升,其原因尚不明確. 綜合訓練精度、測試精度,以及訓練時間,后續實驗的迭代次數取40.
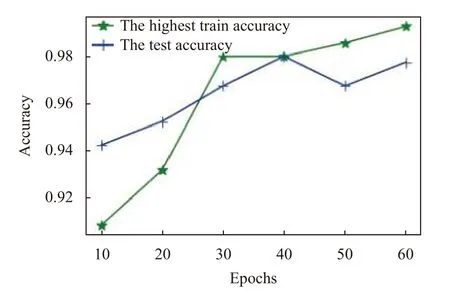
圖6 精度與迭代次數關系圖
3.2.2 批次大小對精度影響
為探討批次大小對精度的影響,固定訓練集1200張,測試集800 張; 迭代次數為40,批次大小依次從{10,12,14,16}中取值. 精度與迭代次數關系如圖7 所示. 從圖7 可看出,訓練精度均在98%以上,隨著批次增加,訓練精度有些波動. 批次大小12 時突然下降,批次大小為14 時降到最低,此后繼續增加; 測試精度隨機批次大小增加而增加,在訓練精度下降時,測試精度增速變緩,可能因為批次偏小,訓練時反向傳播的損失值不穩定導致訓練精度的波動,也導致測試精度增速變緩. 綜合訓練精度、測試精度,最優批次大小取16.
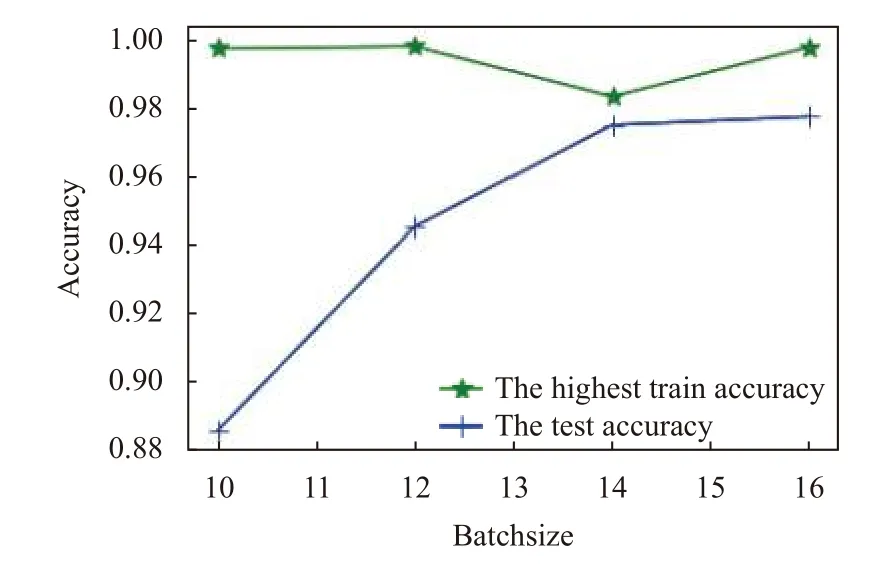
圖7 精度與批次大小的關系圖
3.2.3 不同數據集劃分比例對精度影響
為了探討不同數據集劃分比例對精度的影響,驗證預訓練-微調模型在小樣本下的識別效果. 訓練集與測試集按8:2、7:3、6:4 和5:5 四種比例劃分. 這4 種比例的測試精度分別為98%、98%、98.63%、98.20%.4 種比例劃分訓練集的占比依次減少,但實驗結果表明準確率有上升趨勢,其中6:4 的測試精度最高,達到98.63%. 原因可能是VGG16 模型是在ImageNet 上訓練過的,共享層的權重和參數進行了凍結,可以較好提取物體識別的通用特征,同時,進一步驗證,預訓練-微調模型在小樣本下,可以取得較好的分類效果. 體現了遷移學習具有良好的特征學習能力.
4 結論與展望
4.1 結論
(1)論文利用預訓練-微調模型,進行無人機可見光影響的樹種識別,通過實驗研究,在小樣本下,模型可以取得較好的分類效果. 體現了遷移學習具有良好的特征學習能力.
(2)模型超參數直接影響模型識別效果,當迭代次數為40,批次大小為16,訓練數據與測試數據劃分比例為6:4,模型識別效果最好,測試精度達到98.63%.
(3)利用大疆精靈4RTK 無人機,搭載FC6310R 相機,采集南平市和三明市的杉木和馬尾松人工純林彩色圖像. 通過圖像預處理、標注、裁剪和增強等環節自主構建兩個數據集UAVTree2k 和UAVTree20k,分別可用于預訓練模型和其他卷積神經網絡模型的實驗研究.
4.2 研究不足與展望
(1)由于標注工作量大,自主構建的數據集只有2 個樹種,可進一步采集南方主要樹種,把數據集擴充到10 樹種,每個樹種有10000 條數據集,最終形成無人機可見光影像的數據集UAVTree,并開放共享,供不同模型與不同算法比較.
(2)預訓練模型是基于ImageNet 數據集,是普通圖像識別的數據庫. 而遙感圖像的樹種識別或無人機影像的樹種識別,目標是空對地的識別,因此,預訓練模型可采用中國科學院遙感與數字地球研究所建立的全國地表類型遙感影像樣本數據集[12],可提高源域和目標域間數據的相似度,通過預訓練,把參數調整到合適的范圍,從而提高識別效果或至少減少訓練模型時間.
(3)論文基于VGG16 預訓練-微調模型,只針對數據集進行實驗研究,在完成數據集UAVTree 時,可對復雜林分下的樹種進行分類與制圖. 同時,非常迫切建立不同傳感器的無人機樹種數據集,生成超大規模預訓練樹種識別模型.
(4)論文基于云服務器開展實驗處理,下一步可進行多GPU 資源分布式訓練方法,如數據并行、模型并行、流水并行等. 如何從框架層次自動解決并行策略選擇問題是最近的研究熱點.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
