基于Retina-GAN的視網膜圖像血管分割①
2022-08-04 09:59:42侯松辰張俊虎
計算機系統應用 2022年7期
關鍵詞:模型
侯松辰,張俊虎
(青島科技大學 信息科學技術學院,青島 266061)
眼科專業人士往往將手工分割后的視網膜眼底圖像作為眼科疾病的診斷依據,從血管的病變情況觀察到一些病癥[1]. 然而血管的手工標注工作對于眼科醫生來說費時費力,處理不及時還有可能耽誤病人的病情,自動高效的血管分割不僅緩解相關專業人員的壓力,也有助于患者早發現早治療,因此實現智能的血管分割在疾病識別和預防方面有重要意義.
早期許多研究利用計算機視覺、有監督或無監督的機器學習算法來實現眼底圖像的血管分割. 如高向軍[2],王愛華[3]早期提出的形態學分割方法,Chaudhuri等人[4]的匹配濾波方法等無監督算法,以及Wang 等人[5]提出的基于卷積神經網絡的方法等有監督算法. 伴隨深度學習算法研究的深入,眾多學者在提高血管分割性能方面的研究愈發深入,使用深度學習架構的研究獲得了比現有方法更好的性能,比如,Fu 等人[6]提出的基于深度學習與條件隨機場的分割方法,吳晨玥等人[7]對于卷積神經網絡的改進,Rammy 等人[8]提出的基于塊的條件生成對抗網絡分割方法以及鐘文煜等人[9]對改進的U-Net 方法等血管分割算法. 這些基于深度學習的算法與以往算法相比展現了極大優勢,尤其是生成對抗網絡,在對于血管分割的問題上,準確率等指標都可以看出明顯提升.
當前分割仍存在問題: (1)眼底血管錯綜復雜導致分割結果中各類評價指標還有進步空間; (2)對于血管細微分支類別的準確率還有待優化. 為了嘗試解決這個問題. 本文提出了將RU-Net 網絡作為生成器部分的GAN 改進版模型,并添加了一種Attention 機制,應用在生成器部分,使分割區域更明確,提高分割的準確度和特異度; 判別器選擇卷積神經網絡. 在對數據集的預處理上,本文使用了自動色彩均衡ACE 算法[10],并與其他預處理方式的實驗結果比對,對DRIVE 數據集通過翻轉、旋轉角度、均勻切割等操作將數據集擴充至3 840 張,實驗顯示,本文的模型展現了更好的性能.
1 基于深度學習的Retina-GAN 模型整體網絡架構
本文將生成對抗網絡(generative adversarial network,GAN)與RU-Net 結合并添加一種Attention 機制,構成Retina-GAN 視網膜血管分割模型,如圖1 所示,Retina-GAN 由3 個部分組成:
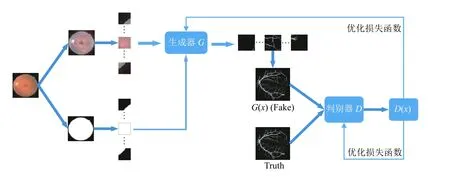
圖1 Retina-GAN 模型整體架構
(1)圖像預處理階段,采用自動色彩均衡(ACE),加強圖像對比度,對圖像閾值分割得到掩膜圖像,擴充數據集,每張圖像分成16 個patch;
(2)生成器部分,該部分采用RU-Net 網絡[11],添加Retina-Attention 機制,將模型關注區域鎖定在有效視網膜區域,生成的patch 進行重組;
(3)判別器部分,采用卷積神經網絡對生成的圖像進行判別,繼而優化損失函數.
1.1 生成對抗網絡GAN
GAN 在被Goodfellow 等人[12]提出后迅速發展,并廣泛應用于圖像合成、樣式轉換、圖像分類、語義分割等領域. 此外,GAN 在醫學圖像處理中也嶄露頭角,如解剖學圖像精準采樣、檢測前列腺癌細胞病變等. 學者們基于GAN 模型又提出了多種擴展網絡模型,如Conditional GANs[13]、Wasserstein GAN[14]、Pix2Pix[15]、DCGAN[16]等.
在本文的架構中,生成器(generator,G)擔任著生成眼底血管分割圖的角色,它的輸入是任意一張眼底圖像z,G通過z生成的視網膜血管圖像,記為G(z). 判別器(discriminator,D)則擔任著判別血管圖片是否真實的角色,以專家手工標注的血管圖像為標準. 判別器的輸入是血管分割圖像x,輸出D(x)是圖像x為專家標注真實圖片的概率,輸出越傾向0,圖片就越虛假,輸出越傾向1,圖像越真實.
對生成器G和判別器D的訓練過程就是令G生成的眼底圖像G(z)越來越逼真,使D難以判斷圖像是否為真實的眼底圖像. 在訓練過程中,G和D逐漸趨向動態平衡. 這個過程最理想的狀態就是在D和G不斷優化的同時,G生成的眼底圖像G(z)越來越真實,令D難以判定其真假性. 對G,D的訓練過程如式(1)[12].

其中,x為真實眼底圖像,符合pdata(x)分布,z是輸入到G的噪聲,符合pz(z)先驗分布,如高斯分布,G生成的眼底圖像用G(z)表示.D(x)是D判斷x是否真實的概率,不難得出,D(G(z))就是G(z)是否真實的概率. 對于G而言,式(1)越小越好,對于D而言,式(1)越大越好.
2 視網膜眼底圖像預處理
實驗選擇DRIVE 公開數據集,DRIVE 由40 張彩色視網膜圖像組成以及對應的專家手工分割圖像組成.
對圖像的預處理選擇了自動色彩均衡ACE,通過對ACE 處理過的圖像水平、垂直翻轉,旋轉角度,平均分割等方式將DRIVE 數據集擴充至3820 張128×128的圖像.
ACE 是由Gatta 等人[10]提出的,并由Rizzi 等人[17]以及Getreuer 等人[18]進一步優化. ACE 模仿人類視覺系統模型來對色彩校正和增強. 文獻[17]依據Retinex理論提出了ACE,ACE 能夠對自適應濾波進行局部的調整,使圖像的對比度、亮度和色彩能夠自適應局部或者是非線性特征的情況. 它需要兩個階段. 第一視覺編碼階段恢復場景區域的外觀,第二顯示映射階段將過濾后的圖像的值歸一化. 如式(2)[10]、式(3)所示,一階段從輸入像素Ic(p)計算Rc(p),二階段從Rc(p)計算增強輸出圖像Oc(p),在一階段,輸出圖像R在色度和空間調整后被創建,創建后每個p都要依據圖像的內容再次計算. 輸出圖像R中的每個像素分別為每個通道c計算.

其中,p和j為兩個像素點,Ic(p)?Ic(j)表示2 個點的亮度差,d(p,j)是距離度量函數,r(·)為亮度表現函數,且為奇函數,式(2)的作用是調整局部圖像的對比度.r(·)的作用是依照局部內容動態放縮范圍,比如放大細微的差異,rmax表示r(·)的最大值,Rc(p)為中間結果.
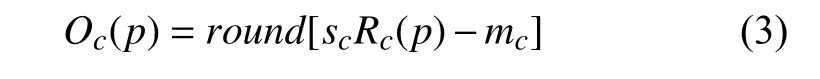
對于輸出圖像Oc(p),sc為線段[(mc,0),(Mc,255)]的斜率,mc=minpRc(p),Mc=maxpRc(p). 使用ACE 的增強結果如圖2(b)所示.
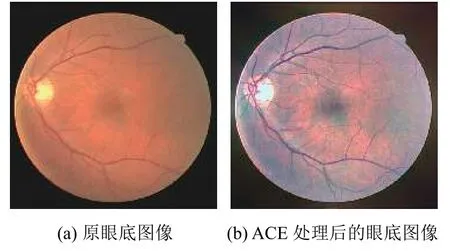
圖2 使用ACE 的增強結果
3 基于Retina-Attention 機制優化的生成器
對于生成器部分,本文引用了RU-Net 結構,并添加了一種Attention 機制對RU-Net 進行優化,將其稱為Retina-Attention 機制.
3.1 RU-Net
Alom 等人被RCNN,U-Net 以及深度殘差模型所啟發,提出了基于U-Net 的RCNN[19]模型RU-Net[11],這種方法結合了這3 種模型的優勢,如圖3. 與U-Net模型相比,所提出的模型有3 方面的差異. RU-Net 由卷積編碼和解碼單元兩部分組成,在編碼單元以及解碼單元中,常規前卷積層被使用循環卷積層RCL 和帶有殘差單元的RCL 所取代. RCL 單元其本身能包含高效的特征積累方法,帶有RCL 的單元對模型的深入建設大有裨益.
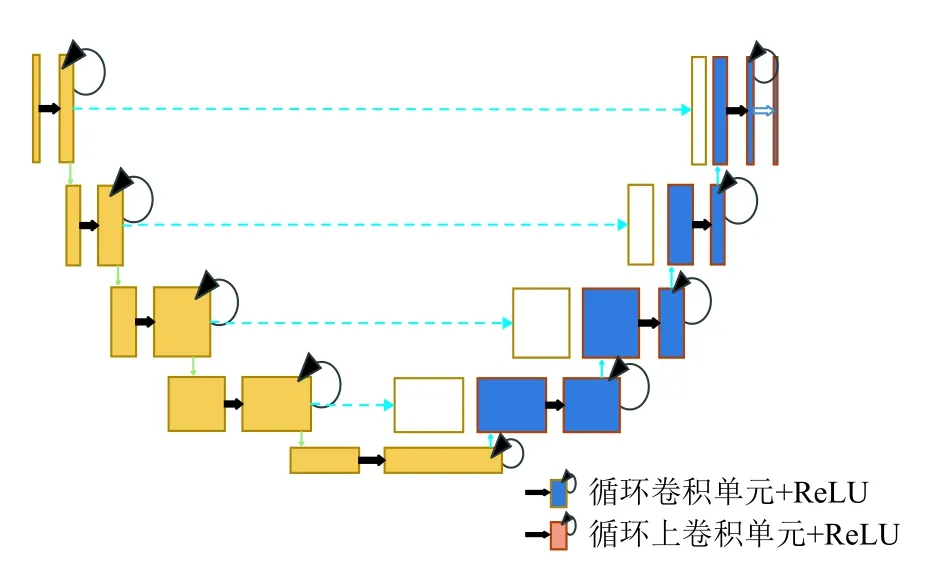
圖3 RU-Net 體系結構[11]
其中,RCL 通過RCNN 的離散時間步長進行的.顧及殘差RCNN (RRCNN)塊的第l層中的xl輸入樣本和RCL 中第k個feature map 上的輸入樣本中位于(i,j)的一個像素,并假設網絡Ol ijk(t)在時間步長t時的輸出,可以表示為式(4)[11]:
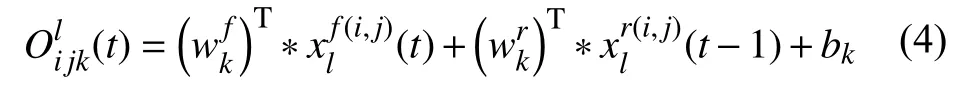
(t)是標準卷積層的輸入,(t?1)為第l層RCL 的輸入.wkf是k的標準卷積層權值,wrk是k的RCL 權值,bk是偏差. RCL 的輸出則被送入標準ReLU激活函數f,表示為式(5)[11]:
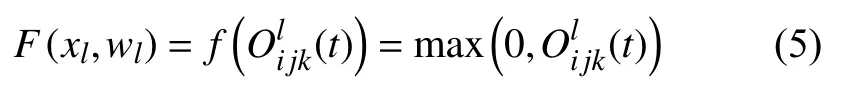
F(xl,wl)表示RCNN 單元第l層的輸出.F(xl,wl)的輸出被用作RU-Net 模型的卷積編碼和解碼單元的下采樣層和上采樣層. RCNN 單元的最終輸出通過殘差單元,假設RRCNN 塊的輸出為xl,可通過式(6)計算:
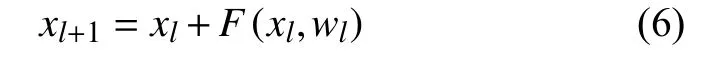
RU-Net 在視網膜圖像血管分割上取得了非常不錯的分割效果,準確率達到0.9528,靈敏度0.7747,特異度0.9770,本文提出的模型意在對RU-Net 加以改進,使其作為GAN 的生成器部分進一步提高分割效果,由此,本文提出在RU-Net 中添加一種Attention 機制.
3.2 Retina-Attention 機制
我們平日所說的注意力是一個神經生理學的概念,它表示人類認真觀察事務的時候能有多專注[20]. 在圖像語義分割領域中,Attention 機制通過學習獲得一個對于目標圖像的特征權重分布,比如我們重點關注的特征的權重相對較高,而不關心的特征權重則相對較低,這個權重分布被加到原圖的特征上,為隨后的任務提供參考,使其更多地關注重點特征,放棄一些不重要的特征,這樣能夠顯著提高效率.
近年,眾多學者將Attention 機制與深度學習的結合研究中不斷探索,使二者相得益彰,其中,提取掩膜(mask)成為一個很好的手段. 掩膜給圖像添加一層新的權重,使圖像中的重點變得突出,然后通過學習和訓練,讓深度神經網絡在后續工作中繼承關注新圖片中的重點或者說我們感興趣的區域,注意力由此而來.
受Self-Attention[21]的啟發,我們需要注意的僅是含有有效視網膜信息的圖像,或者說是含有血管信息的圖像,在本文中也就是圓形內部的信息這部分是我們的感興趣區域(ROI). 由此本文在生成器部分添加了一種Attention 機制,將其命名為Retina-Attention,整體結構如圖4 所示.

圖4 Retina-Attention 結構
該機制分為兩個步驟:
(1)提取掩膜,通過二值分割將ROI 區域與無關背景區別開來,如圖5.
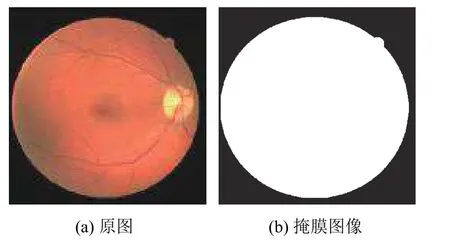
圖5 提取掩膜
(2)將掩膜與RU-Net 的倒數第2 層特征映射進行相乘,如圖4 中長箭頭所示. 如式(7)所示:
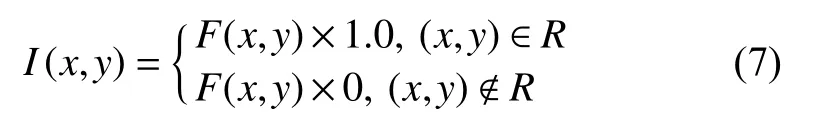
其中,R表示ROI (感興趣區域),也就是我們注意力要關注的區域,F表示特征. 這個Attention 機制的作用就是讓G只關注眼底圖像中有信息的視網膜區域(圓形內部的區域),放棄沒有有效信息的噪聲背景(圓形外黑色區域),這樣做能有效提高分割效率,防止G生成不必要的信息來占用D的效率. 提取掩膜有時由于提取之后信息量太少從而導致分類器網絡層數堆疊大大減少的問題,采用這種掩膜與RU-Net 中的殘差網絡結合的方式對當前網絡層的信息加上掩膜,同時也能夠把上一層的信息傳遞下來,可以有效防止提取信息量較少問題的發生.
4 判別器部分
為了區別G(z)與真實值,判別器D設計成簡單的卷積神經網絡并且運用全局平均池化層(global average pooling,GAP),選擇GAP 的原因是GAP 能夠削減參數數量,有助于給模型訓練提速.
由于G(z)是基于塊的,所以在輸入D之前需要先進行重組再輸入. 關于輸入圖像,正樣本是經過ACE處理后的眼底圖像和專家手工分割圖的組合,負樣本是經過ACE 處理后的眼底圖像和G(z)組合,通道數設置成2.
樣本進入判別器時,卷積提取特征設置成步長2,大小3×3,激活函數選用ReLU,選取批標準化提高訓練進度,然后設置步長1,大小3×3 的卷積提取特征,如圖6 所示,此時分辨率沒有改變,繼而通過2×2 的max-pooling 使分辨率下降,特征提取多次后,通道數為512. 最后采用Sigmoid 函數,配合GAP 連接全連接層,得到D(x).
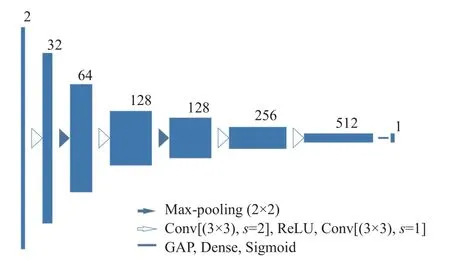
圖6 判別器部分
5 實驗結果
5.1 數據集設置
為了展示Retina-GAN 的性能,我們在DRIVE 數據集上進行了實驗. 對于DRIVE 數據集的處理在第2 節中已經做了一些介紹,選擇其一半圖像作為訓練集,另外一半樣本作為測試集. DRIVE 圖像原始像素為565×584. 為了開發一個方形數據集,我們將圖像壓縮為512×512 像素再進行擴充到3840 張. 在這個模型實現中,我們考慮了從DRIVE 擴充數據集中隨機選擇一半圖像的patch 用于訓練,其余的patch 用于驗證,每個patch 的大小都是128×128.
5.2 實驗設置
實驗選擇Adam 梯度下降方式,動量項系數為默認值,學習率設為0.0005,每訓練一次G,隨后訓練D,交替訓練. 關于硬件,CPU 選擇英特爾i7 處理器,GPU 為英偉達GTX 1080.
模型訓練步驟如下:
(1)將專家手工分割圖像輸入D進行訓練;
(2)把DRIVE 中的眼底圖像和掩膜輸入G得到G(z),再把G(z)與經過ACE 處理后的眼底圖像標記為負樣本輸入到D進行訓練;
(3)訓練G,得到G(z)后再輸入D中繼續訓練. 反向傳播的過程中D的參數沒有更新,只傳遞誤差,G的參數要更新和優化;
步驟(1)–(3)迭代訓練,令G(z)對于D而言能夠以假亂真.
5.3 評價指標
進行定量分析時,選擇使用準確性(accuracy,Acc)、靈敏度(sensitivity,Sen)以及特異性(specificity,Spe)這3 個性能指標. 具體計算公式如下:

TP代表血管被正確分類為血管的像素點數,FP代表背景被誤分為血管的像素點數,TN代表背景被正確分類為背景的像素點數,FN代表血管被誤分為背景的像素點數.
5.4 實驗結果
該方法展現了更精準的分割效果,圖7 分別為專家手工標注以及訓練迭代1000 次,2000 次,4000 次的效果,方框里為血管的細節分支部分,隨著迭代次數的增多,血管的分支和細微部分逐漸詳細.
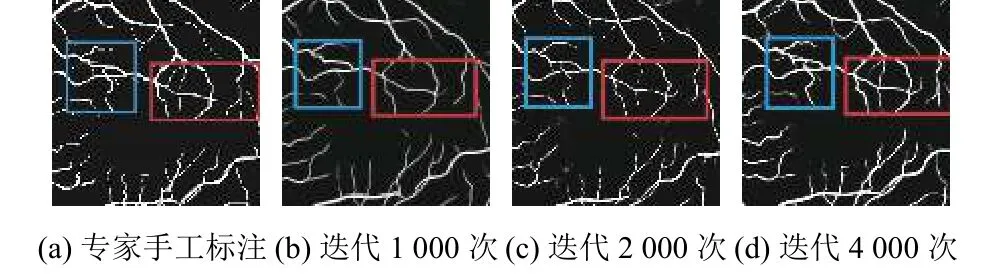
圖7 血管細節圖
圖8 為在DRIVE 數據集上使用不同算法的效果;折線圖9–圖11 橫坐標為測試集圖片序號,縱坐標為指標對應的值,這些數據顯示了Retina-GAN 在各個指標上均有提升. 這些數字表明,與GAN、U-Net、RU-Net等方法相比,本文設計的模型在訓練和驗證階段提供更好的性能,在精確度、靈敏度均有提高. 證實了Retina-GAN 對任務分割的有效性.
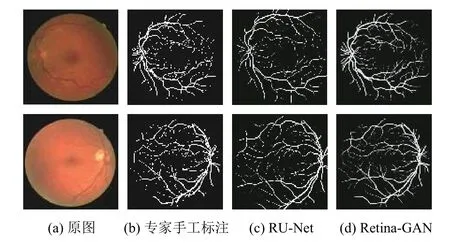
圖8 實驗結果
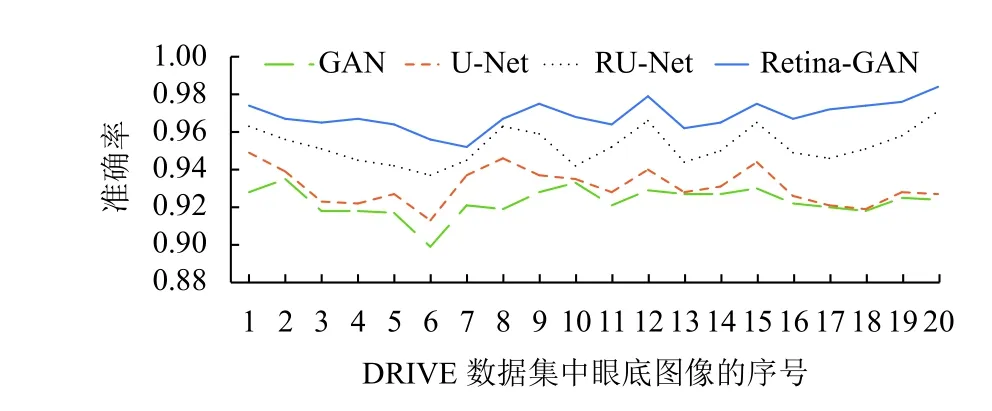
圖9 多種方法在DRIVE 數據集上的準確率
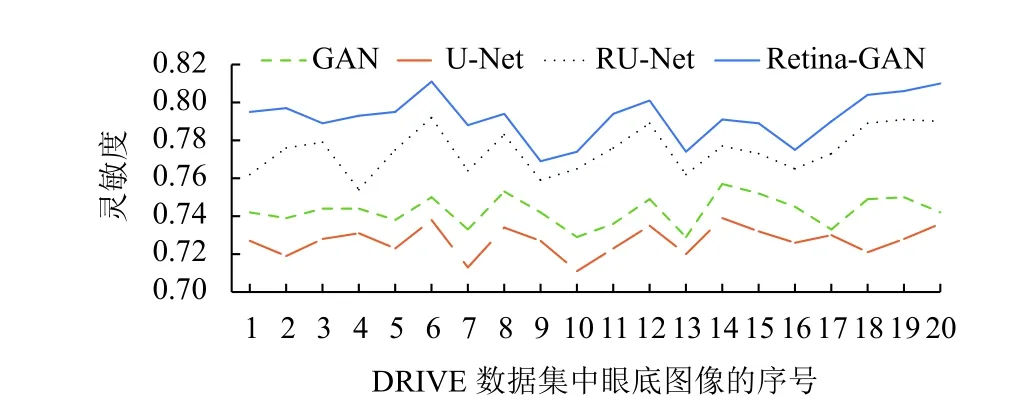
圖10 多種方法在DRIVE 數據集上的靈敏度

圖11 多種方法在DRIVE 數據集上的特異度
同時,預處理方面,為了與滕梓晴[22]和張天琦[23]使用的CLAHE 做比較,我們分別使用ACE 和CLAHE對DRIVE 數據集進行預處理,從表1 和表2 的數據可以看出,不管是GAN 還是Retina-GAN 上,ACE 的表現均優于CLAHE,實驗效果更好.
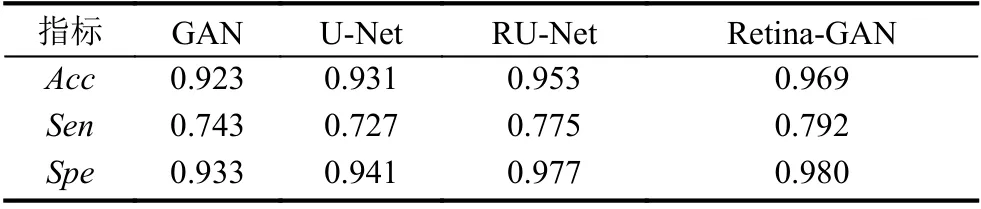
表1 多種方法在DRIVE 數據集上的實驗結果
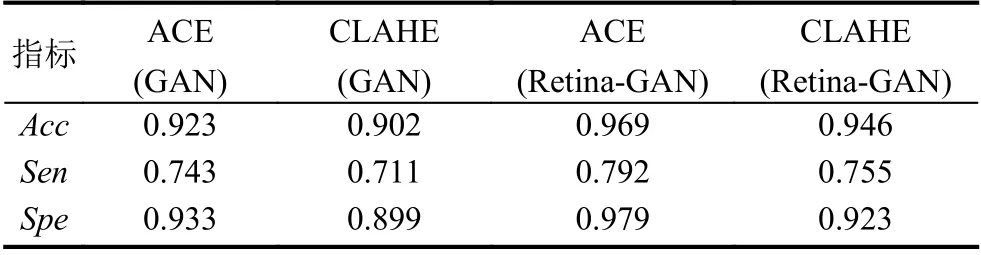
表2 ACE 和CLAHE 在不同算法上的表現
6 結束語
盡管通過實驗證明了Retina-GAN 結構的效果在以往算法上有了提升,但對于靈敏度的指標還有很大提升空間,未來的工作將圍繞在不影響準確率的情況下來優化靈敏度展開.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
