面向知識圖譜的信息抽取技術綜述①
2022-08-04 09:58:12趙肄江鄒子維
計算機系統應用 2022年7期
姜 磊,劉 琦,趙肄江,袁 鵬,李 媛,鄒子維
(湖南科技大學 計算機科學與工程學院,湘潭 411100)
隨著信息時代的到來,數據呈爆發式的增長,如何從這些數據中通過智能技術自動提取出真正有價值的信息,尤為重要. 知識圖譜[1]是一類知識表示,由實體、關系以及屬性構成[2]. 實體又稱為類或實例,是不依附于其他東西而存在的,比如人,機構等. 關系表示實體,實體屬性之間的關系. 屬性是用來描述實體的某種特征,比如身高,體重等. 知識圖譜技術在數據分析、智能搜索、決策支持以及醫療健康等領域越來越發揮出主要的作用.
知識圖譜的構建過程: 首先從數據源中提取出碎片化事實[3],然后對碎片化事實進行知識的融合,再經過知識加工后通過迭代更新建立基于知識的體系[4]. 顯然,知識圖譜的構建過程包括: 信息抽取(information extraction),知識融合,知識加工[5]等. 信息抽取作為知識圖譜的主要組成,從數據源中抽取出實體和實體之間的關系等結構化信息[6]. 包括對實體、關系以及事件等方面的抽取[7]. 信息抽取的正確性對知識圖譜的后續構建質量和效率產生影響.
信息抽取通常采用基于NLP 和文本挖掘的方法.在信息抽取研究的成果中我們發現當前的研究在提升信息抽取準確度的基礎上主要圍繞如何減少人工標注語料、人工提取特征以及人工構建模式展開. 這使得知識圖譜中的信息抽取面對著3 個挑戰: 第一,如何從需要構建知識圖譜的領域語料中利用啟發式的信息來發現語料中的隱含知識,從而在較少的人工標注中獲得較高的準確度. 第二,如何解決已有知識圖譜中部分不完整的實體、關系與事件信息所帶來的噪聲與語義漂移問題. 第三,如何在開放領域中利用現有的標注或加上較少的標注實現知識圖譜在新信息中的完善與更新.
本文綜述了知識圖譜中信息抽取技術,詳細地描述了近年來在實體、關系和事件抽取中的各項技術,探討這些技術在解決上述3 大挑戰的進展. 以便研究者能對信息抽取技術有一個全局認識,進而能厘清技術的發展趨勢與方向. 期望研究者能從中汲取技術的精華和理念,進一步推動信息抽取技術的發展.
1 實體抽取
命名實體識別(named entity recognition,NER)是實體抽取的別稱. 命名實體能在具有相似屬性的一組事物中清楚的標識出一個事物. 它可以理解為有文本標識的實體,而實體(entity)是不依附于其他東西而存在的. 在現實世界中,實體通常分為3 大類7 小類.NER 是從文本中抽取實體信息元素. NER 主要有基于規則和字典的方法[8,9],基于監督學習的方法[10–13]和基于深度學習的方法. 近年來,越來越多的研究者開始關注基于深度學習的NER 方法.
1.1 基于深度學習的方法
近年來,基于深度學習的NER 模型逐漸占主導地位,與傳統的機器學習相比,深度學習有助于自動發現隱藏的特征[14],進行特征抽取,使得泛化能力得到了提升. Hammerton 等人[15]是最早使用LSTM 來進行NER,該模型在序列建模上具有良好的表現.
深度學習在實體抽取領域取得較好效果后,研究人員開始在詞匯級別上對其神經網絡結構進行改進研究. Lample 等人[16]通過加入CRF 模塊以優化標簽序列輸出,提出了BiLSTM-CRF 模型,在語料庫上取得了比較高的F1 值. Ma 等人[17]在雙向LSTM-CNNS結構上,添加了CRF 模塊,提出BiLSTM-CNNs-CRF模型,模型能同時利用詞和字符級表示. Luo 等人[18]提出了一種Att-BiLSTM-CRF 模型,該模型用于文檔級實體識別,在數據集上取得的F1 值為91.14%.
上述模型偏重于詞或字符的特征提取,無法動態的表征上下文語境中的一詞多義. 為了改善這問題,Devlin 等人[19]提出了BERT 模型,該模型可以使上下文語境或語義中的詞得到充分的表征. Souza 等人[20]將BERT-CRF 模型應用于葡萄牙NER任務上,獲得了新的最佳F1 值. 謝騰等人[21]提出一種BERT- BiLSTMCRF 模型,該模型在兩個語料庫上進行實驗,得到的F1 值分別是94.65%和95.67%. 在文獻[19]的基礎上,百度推出了ERNIE 模型[22],該模型是通過加強BERT的masking 來獲取知識. 實驗表明,在5 項NER 任務上,ERNIE 刷新了榜單. 微軟提出了一種多任務的訓練方式的MT-DNN 模型[23],該模型比BERT 更加穩定,泛化能力更好. 由卡內基梅隆大學提出的XLNet 模型[24]是一種通用的自回歸預訓練模型,該模型解決了BERT在預訓練時加入[MASK]的token,從而導致pretrain和finetune 在訓練數據上的差異. Liu 等人[25]對BERT的預訓練進行了仔細的評估,提出了一種能更好地訓練BERT 的方法,稱為RoBERTa 模型,該模型比BERT之后的所有psot-BERT 模型的效果好. Joshi 等人[26]提出一種SpanBERT 模型,模型旨在更清晰的預測和表達文本跨度,不再通過隨機標記而是通過屏蔽連續的隨機跨度來使得BERT 得到擴展. 谷歌提出了ALBERT模型[27],該模型在BERT 模型的基礎上,減小了兩種參數量,通過兩個參數稍減技術克服了擴展預訓練模型面臨的主要障礙,使得訓練更加穩定.
近幾年,在基于深度學習的方法上加入注意力機制[28],遷移學習[29],對抗學習[30],遠程監督[9]等熱門研究技術也是NER 中的一個研究熱潮.
2 關系抽取
關系抽取(relation extraction,RE)旨根據實體之間的上下文語境來確定語義關系,它為許多下游任務提供了基礎支持,比如文本理解中,為了理解復雜的語句,識別語句中的實體對之間的關系是至關重要的.在問答系統中,關系抽取所得到的實體間的關系實例可以作為背景知識支撐問題的問答. 在NLP 領域中,關系抽取最重要的應用是構建知識圖譜.
2.1 基于深度學習的方法
傳統的關系分類模型需要耗費大量的人力去設計特征,而且很多隱性特征也難以定義. 因此傳統方法在大規模關系抽取任務中效果不佳. 基于深度學習的關系抽取能夠自動學習有效特征. 有監督的關系抽取方法是深度學習方法中的一個主要方法,在解決人工特征選擇和特征提取誤差傳播等問題上有不錯的效果.流水線學習和聯合學習是有監督的關系抽取方法主要的兩種類別. 基于深度學習的關系抽取的另一個主要方法是遠程監督的方法,其利用已知知識庫信息以減少人工處理.
2.1.1 流水線學習
流水線學習方法中的關系抽取是在實體抽取完成的基礎上進行的,因此關系抽取結果的好壞與實體抽取的結果有直接關聯. 主要采用的方法是CNNs 和RNNs.其中CNNs 有利于識別目標的結構特征. RNNs 有利于識別序列[31].
Wang 等人[32]提出了一種新的結構塊驅動卷積神經學習新型輕量級關系提取方法. 在兩個數據集上進行實驗,驗證了該方法的有效性. Lin 等人[33]將注意力機制引入句子級中,提出了一種純文本的實體關系抽取方法,該方法動態地降低噪聲對句子的影響,有效地提高了跨語言的一致性和互補性. 深度學習模型在受到有限的標記實例的限制時,可以借助于合適的網絡結構來獲得良好的性能. 如Lin 等人[34]提出了一個自訓練的框架內具有多個語義異構嵌入的循環神經網絡.
隨著不斷的改進和完善CNNs 和RNNs,使它們產生了許多的變體,如雙向長短期記憶網絡(Bi-LSTM).Xiao 等人[35]提出了一種能從原始句子中提取信息進行關系分類的遞階遞歸神經網絡模型. Xu 等人[36]提出了神經網絡SDP-LSTM 模型,該模型對句子中兩個實體之間的關系進行分類.
隨著GCN 在NLP 領域的應用,GCN 也被應用到關系抽取的研究中. Schlichtkrull 等人[37]提出的RGCNs 模型,是一種關系圖卷積網絡. Zhang 等人[38]提出了一種圖卷積網絡的擴展方法來對實體關系進行抽取. 在數據集上取得的最佳結果F1 為68.2%. 優于現有的基于序列和依賴關系的神經模型. Zhu 等人[39]提出的GP-GNNS 模型,是一種新的帶生成參數的圖神經網絡,該模型可以通過多跳關系推理來發現更精確的關系. 在跨句子的n元關系中檢測出n個實體之間的關系. 典型的方法是將輸入制定為文檔圖,集成各種句內和句間依賴關系,但是這種模型可能會使重要的信息在分割過程中丟失,因此,Song 等人[40]提出了一種Graph-State LSTM 模型,來改進這個問題. 為了有效地利用相關信息和忽略不相關信息,Guo 等人[41]提出了注意力機制圖卷積網絡(AGGCNs),一種直接以完全依賴樹為輸入的模型.
流水線方法使得關系抽取能得到實體抽取的有用信息,從而提升了關系抽取的效果. 但該方法也會產生錯誤傳播,使得沒有關系的兩個實體之間出現關系.
2.1.2 聯合學習
為了避免流水線學習中存在的問題,聯合抽取將實體和關系放在同一模型中共同抽取. 聯合學習主要有兩種類別: 參數共享和標注策略.
參數共享是指模型通過共享編碼層產生的共享參數來彼此依賴,最后通過訓練得到全局參數[32]. Zheng等人[42]提出了一種用BiLSTM-ED 模塊對實體進行提取和用于關系分類的CNN 模塊組成的一種混合型神經網絡模型,在BiLSTM-ED 模塊中獲得的實體的上下文信息進一步傳遞到CNN 模塊以改進關系分類.Miwa 等人[43]提出的模型同樣是通過參數共享來聯合學習,F1 達到了84.4%. 上述模型實際還是分別提取實體和關系,通過參數共享機制相關聯. 這會出現沒有關系的實體對信息. 針對這個問題,Zheng 等人[44]提出了將聯合提取任務轉換為標注問題. 直接提取實體及其關系,無需分別識別實體和關系. 取得了不錯的效果.對于之前的模型沒有考慮實體關系重疊問題,Bekoulis等人[45]將聯合抽取問題看作一個multi-head selection(多頭選擇)問題,以此來解決重疊問題. Bekoulis 等人[46]將對抗學習加入到文獻[45]的模型中,使得模型中的詞嵌入的質量更好,性能得到顯著提高.
基于神經網絡的聯合學習除了共享參數和標注策略之外,Nayak 等人[47]通過編解碼架構的設計來實現聯合提取實體和關系. Li 等人[48]將實體關系聯合抽取的任務當作一個多輪問答問題來處理. Wei 等人[49]設計了一種層次二進制標記框架. Sun 等人[50]提出一種首先識別實體跨度,然后對實體類型和關系類型執行聯合推理. Fu 等人[51]提出了一個端到端的關系提取模型GraphRel,它使用圖卷積網絡(GCNS)來聯合學習命名實體和關系. 這些方法都取得了較好的結果.
2.1.3 遠程監督的方法
在文本中,如果實體之間存在某種關聯,那么就會以某種形式表現出這種關聯. 在這種前提下,基于遠程監督的方法,首先從文本中抽取出存在關系的實體對句子,然后將句子作為訓練數據放入模型中進行關系抽取.
采用知識圖譜和文本對齊方式來自動提取訓練數據,減少了人工標注. 但是,這些數據中會引入大量的噪聲,從而引起語義漂移現象. 為了減少語義漂移現象的出現,Ji 等人提出了APCNNs 模型[52],它在句子級別引入attention mechanism. APCNNs 模型有可能會出現包含同一實體對的所有樣例句子都含有大量噪聲的情況. 針對這一問題,Feng 等人提出了基于強化學習的關系分類模型CNN-RL[53],該模型能有效地處理數據中的噪聲,并在句子層次上取得了較好的關系分類性能.遠程監督能夠自動生成大量用于關系提取的訓練樣本.然而,會帶來兩個主要的問題: 不平衡的訓練數據和訓練數據中出現噪聲,使得獲取到的數據集準確率較低,影響整個關系抽取模型的性能. 因此,有較大的提升空間[54].
2.2 基于開放領域的方法
基于開放領域的關系抽取方法,在大規模非限定類型的語料庫中結合語形和語義特征自動進行關系抽取,減少了人工標注成本. TextRunner 開放信息抽取原型系統是一個面向開放領域的信息抽取框架(OIE),實體關系能夠自動進行抽取,但F1 的值不太理想. 在OIE 的基礎上,Wu 等人提出了WOE 系統[55],F1 的值比TextRunner 的F1 提高了18%–34%,但是該系統在速度方面出現了不足. Nakashole 等人提出了PATTY系統[56],用于表示實體之間二元關系的文本模式,這些模式在語義上被分類并構建成一個分類體系. 該模型可以處理Web 規模的語料庫中的關系抽取. Mausam等人[57]提出了一種系統,該系統解決了OIE 系統僅以動詞為主的關系抽取和忽略了上下文這兩個限制,有效地改善了F1 的值. TextRunner、WOE、PATTY、OLLIE 系統都屬于二元的開放式關系抽取. KrakeN[58]是由Akbik 等人提出的一個多元關系抽取系統. 該系統是一種高精度OIE 框架,比現有的OIE 更能完整地捕獲每個句子中的多元關系,但容易受到噪聲和不合法的文本的影響.
基于開放域的關系抽取在二元關系抽取上的準確率和正確率有待于提高,在挖掘隱藏信息方面的提升,有助于關系的抽取. 面向開放域的關系抽取方法在性能上存在不足,這給研究者留下了研究空間.
3 事件抽取
事件抽取(event extraction,EE)被定義為從文本中提取出對人類有用的信息事件,并以結構化的形式表示出來. 例如從“李華1922 年出生于湖南長沙”文本中抽取出事件{類型: 出生,人物: 李華,時間: 1922 年,出生地: 湖南長沙}. 事件抽取主要的任務包括從文本中發現觸發詞和從文本中識別出元素扮演的角色. 如圖1和表1 所示.

圖1 事件抽取結構分析

表1 事件抽取任務
事件抽取中,基于模式匹配的方法通過模式匹配算法進行事件抽取,主要的模型有ExDisco,GenPAM等. 模式匹配方法在特定領域能取得很好的性能,但移植性差,在跨領域進行事件抽取時,需要重新構建.
在機器學習方法中,事件抽取問題轉換成了分類問題. 常見的分類算法有SVM,ME 等. 基于機器學習的事件抽取方法移植性能好,但是需要依賴大規模的知識庫,否則可能會出現數據稀疏問題. 另外,特征選取也是一個重要因素. 怎樣解決這兩個因素,成為了機器學習方法在事件抽取研究中的重要方向.
基于深度學習的事件抽取模型主要有動態多池卷積神經網絡(DMCNN)[59],該模型能夠從單詞的連續及其廣義表示中自動學習隱藏特征表示,解決了人工設計特征、可擴展性差以及依賴復雜NLP 工具等問題.Nguyen 等人[60]提出了一種雙向循環神經網絡的聯合框架(JRNN),該模型與DMCNN 相比,JRNN 避免了誤差累計傳播導致模型性能下降的問題,可以同時抽取出所有的事件信息,使用從整體結構中學到的全局特征來提升局部信息的預測能力. Chen 等人[61]提出了一個具有門控多級注意力機制的分層和偏置標記網絡框架,該框架解決了僅利用詞或者句子信息,忽略了篇章信息的問題.
對信息抽取中的實體抽取,關系抽取和事件抽取的不斷研究,部分學者開始進行多任務聯合學習的研究,多任務聯合學習解決了各任務獨立學習時忽略了依存關系問題. Lee 等人[62]提出了一個新穎的共指解析系統,它可以跨文檔的聯合實體和事件,使用迭代方式構建實體和事件提及的集群,用線性回歸來建模集群合并操作. Barhom 等人[63]受文獻[62]的啟示,提出了一種跨文檔共指解析的神經架構模型ECB+用來聯合建模實體和事件共指. 它的結果優于文獻[62]提出的模型. Xi 等人[64]提出了一種BERD 模型,該模型通過結合實體上下文的參數角色來預測生成參數角色,從而提升隱式參數分布模式中更準確的事件. Han 等人[65]提出了一種Neural SSVM 模型,該模型通過將事件和關系共享上下文嵌入來使事件的表示得到改進. Han等人[66]進一步提出了一個以概率領域知識構建分布約束來增強深層神經網絡框架. Tang 等人[67]提出了一種用于事件關系抽取的多層知識投影網絡(MKPNet),可以有效地利用多層話語知識進行事件關系的抽取.
事件抽取一般從屬于實體、關系才有明顯的意義,所以目前一般采用聯合學習的方式結合實體、關系抽取所獲得的信息來進一步指導事件的抽取.
4 信息抽取的研究趨勢
NER、RE 與EE 是知識圖譜信息抽取的3 個子任務. 圖2 與圖3 是我們針對2015–2020 年NLP 領域的兩個頂級會議ACL 和EMNLP 上的信息抽取各子任務的論文數量的統計. 從圖中可以看出信息抽取3 個子任務的研究熱度逐年上升.

圖2 ACL 會議中信息抽取子任務的論文數量
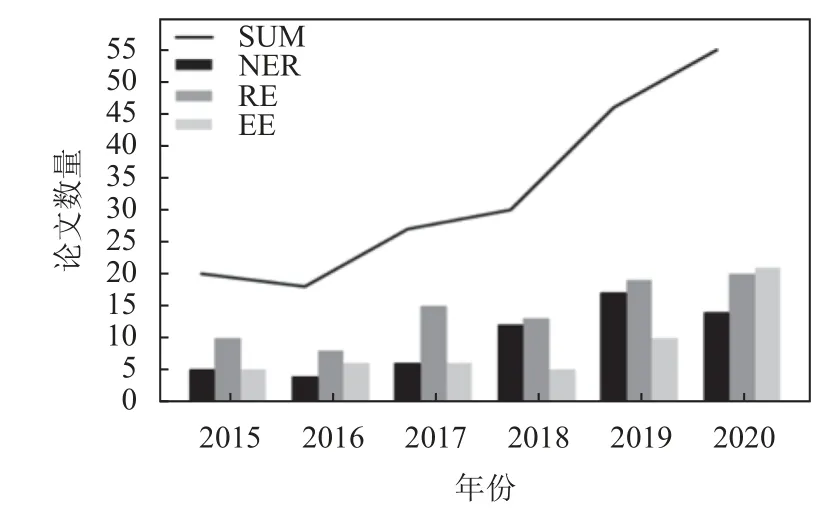
圖3 EMNLP 會議中信息抽取子任務的論文數量
我們將知識圖譜中信息抽取的主要技術整理成表2–表4. 如表2 所示,實體抽取開始于基于規則和字典的方法. 隨后采用基于監督學習的方法進行研究,取得了大量研究成果. 但是該方法需要對語料進行大量的標注,研究的方法主要圍繞如何降低人工標注的數量獲得準確的抽取. 鑒于深度學習能夠很好地發現隱藏特征,可以降低特征的人工抽取,所以目前大量的實體抽取的研究圍繞深度學習展開. 它在當前的研究熱點在于如何引入語言學的成就在詞匯、句法、語義特征等方面來尋找合適的神經網絡結構來提升實體抽取的能力.

表2 實體抽取研究發展趨勢

表4 事件抽取研究發展趨勢
如表3 所示,當前關系抽取的方法主要有4 種. 研究的趨勢主要是采用各種技術來降低人工提取關系特征. 在這里主要分3 種: 一是利用深度學習方法具有的學習隱知識的能力,從詞匯、句法結構、語句塊以及引入圖像處理方面的知識來改進深度學習中的神經網絡的結構; 二是引入外部知識庫中與待抽取關系中重疊知識來降低復雜度,主要采用增強學習來處理噪聲與語義漂移; 第三就是采用監督學習以及啟發式規則等方式對開放領域中新信息的匯入造成的新關系引入、舊關系的偏移進行研究.

表3 關系抽取研究發展趨勢
事件抽取主要方法如表4 所示,主要分為基于模式匹配、機器學習、深度學習與聯合學習的方法. 研究者仍然是圍繞如何降低人工標注的工作量展開. 同時,為了利用實體抽取、關系抽取中獲得的知識,現在將事件抽取與上述兩個任務整合一起進行聯合抽取已逐漸成為研究熱點.
5 結束語
知識圖譜構建過程中信息抽取是必不可少的環節.本文詳細介紹了近年來信息抽取中實體抽取、關系抽取和事件抽取的技術進展,梳理了它們的發展趨勢. 在應對減少人工干預信息抽取的3 大挑戰中,目前的研究主要集中在針對領域語料采用深度學習進行. 它表現在利用句法結構、注意力機制等語言學知識和圖像處理知識來尋找合適的神經網絡結構以改進深度學習. 而在融合已有知識圖譜中知識以及在開放領域中減少人工工作方面,目前的研究成果較少.因此,在知識圖譜的信息抽取研究中繼續進行深度學習的研究是一個重要方向. 而引入機器學習中的降噪技術結合信息抽取的特點做已有相似實體、關系與事件的融合是一個可行的有前景的方向. 另一個非常有前景的方向就是對開發領域中已有標注的語料結合新信息、新語料利用半監督學習的成果進行信息抽取的研究. 希望能有更多的學者就這兩個方向展開研究取得成果.
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
制造技術與機床(2019年10期)2019-10-26 02:48:08
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
電子制作(2018年18期)2018-11-14 01:48:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
