融合注意力與FCN 的圖像修復取證
2022-07-29 06:54:36沈萬里張玉金王永琦
智能計算機與應用 2022年8期
沈萬里,張玉金,王永琦,胡 萬,孫 冉,郭 靜
(上海工程技術大學 電子電氣工程學院,上海 201620)
0 引言
圖像修復可以用來填充圖像內容、修復受損區域。基于區域填充的方法主要分為2 類:基于擴散的修復方法和基于樣本塊的修復方法。其中,基于擴散的方法主要集中在小區域修復,例如舊照片的劃痕等,不會留下易察覺的偽影,但該方法在修復大面積區域時效果不佳;基于樣本塊的修復方法類似于圖像篡改中的復制粘貼操作,是從圖像未受損區域復制圖像塊補丁,填充在受損區域,達到修復的效果。
隨著圖像修復技術的發展,修復后的圖像留下的可感知偽影越來越少,無形中也增加了圖像修復取證工作的難度。Wu 等人提出了一種基于零連通特征和模糊隸屬度的盲檢測方法,但該方法需要人工選擇可疑區域,極大地增加了人工成本。Chang等人提出了一種可以加速搜索像素塊的二階搜索算法,克服了上述缺點。在前文論述基礎上,本文提出了一種融合注意力機制與FCN 的圖像修復取證網絡,使用中心像素映射進行塊搜索,并結合通道注意力模塊(Squeeze and Excitation Block,SE)對最終提取的特征圖進行像素權重判定,篩選出最有效的預測圖。
1 融合SE 與FCN 的圖像修復取證網絡
基于樣本塊的圖像修復主要依賴于圖像的內容,而卷積神經網絡針對圖像內容具有較好的學習能力和特征提取能力,因此,本文設計了一種融合SE模塊與FCN 的圖像修復取證網絡。為避免網絡受圖像內容影響導致的檢測精度降低的情況發生,該全卷積神經網絡的輸出結果與輸入圖像具有相同尺寸,同時為輸出圖像中的每一個像素指定一個類別標簽(0或者1,0 代表未修復區域,1 代表修復區域)。
1.1 SE 模塊
Hu 等人提出一種通道注意力結構SE-net(Squeeze-and-Excitation Net),通過神經網絡來自適應地學習每個特征通道的重要程度,并為每個通道賦予不同的權重系數,從而強化重要的特征,抑制非重要的特征。通過權值重分配的方式來自適應地調整通道間的特征重要性,讓計算資源分配給信息中最有用的部分,又因為其額外所占用的計算成本小,很容易嵌入其他深層網絡,SE 模塊結構如圖1 所示。
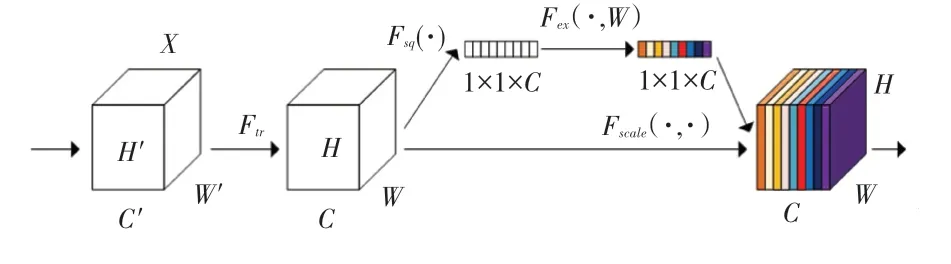
圖1 SE 模塊結構圖Fig.1 SE block structure diagram
為不同的特征通道求得對應權重是關鍵點,首先是操作,將一個通道中整個空間特征編碼為一個全局特征,通過全局池化將特征圖在的空間維度上收縮,對此可表示為:

其中,F(·) 表示全局平均池化,x表示特征圖的第個通道。
得到了全局描述特征后,進行操作來抓取特征通道之間的關系,對此可表示為:
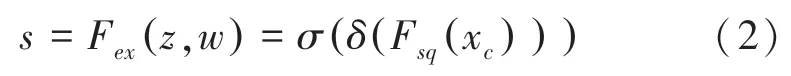
其中,(·) 表示函數,確保值位于0~1,(·) 表示函數。
依前處理后,下面就是操作,即將操作得到的權重看作是重要信息的依據,數學定義式可寫為:

其中,作為比例因子與原通道相乘,利用一維的稀疏卷積操作來優化SE 模塊中涉及到的全連接層操作,達到大幅降低參數量并保持相當性能的目的。為了壓縮參數量和提高計算效率,SE 模塊采用“先降維-再升維”的策略,利用2 個多層感知機來學習不同通道間的相關性,即當前的每一個特征圖都與其它特征圖進行交互,是一種密集型的連接。
1.2 網絡結構設計
為實現對取證區域的定位,本文采用基于全卷積神經網絡(FCN)的圖像修復取證網絡架構,總體網絡結構如圖2 所示。該架構的特征提取模塊由14 個卷積層和5 個最大池化層組成,每一個卷積層后都添加了整流線性單位()作為激活函數。在特征提取模塊的第一層,本文采用了64 個3×3 的卷積核,將第一層的輸出再次經過一個相同結構的卷積模塊,輸出224×224×64 的特征圖;使用窗口大小為2×2 和步長為2 的最大池化層對第二層卷積輸出特征圖進行處理,得到112×112×128 的特征圖。經過5 次不同核數的卷積層及5 次相同窗口大小和步長的最大池化層,輸出大小為7×7 的4 096個特征圖。本文將第四個區塊的特征圖通過1×1 的卷積進行降維操作,同時對第五和第六個區塊的特征圖進行反卷積操作,分別獲得28×28×2 的特征圖,再通過拼接融合方式,得到28×28×6 的特征圖。對這6 個通道的特征圖,使用SE 模塊進行權重分配,得出權重占比最大的兩張特征圖,分別代表修復和未修復樣本的特征圖。

圖2 總體網絡結構圖Fig.2 Overall network structure diagram
2 實驗
2.1 實驗數據庫的建立
本文創建了包含2 000 個大小為256×256 彩色圖像的修復圖像數據庫。該數據庫中的修復區域為不規則形狀,修復區域占比為2%~40%。實驗隨機選擇1 600 張用于訓練,400 張用于測試。本文提出的模型輸入圖像大小為224×224,因此先將數據庫圖像大小裁剪為224×224 作為本文使用的修復圖像數據庫。考慮到在訓練樣本中,修復區域相對于未修復區域較小,研究中采用加權交叉熵作為損失函數,用隨機梯度法來迭代更新超參數。學習率設置為e,動量值設置為0.9,重量衰減值設置為5,設置為8。
2.2 實驗結果與分析
本文針對彩色修復圖像進行了修復檢測和定位,具體可視化結果如圖3 所示。由圖3 可以看出,即使不規則的修復區域面積較大,本文算法仍然能夠較為準確地定位修復區域。

圖3 修復圖像的可視化結果Fig.3 Visualized results of inpainting images
通過精度、召回率、得分和交并比()等數據定量分析本文提出的修復圖像取證網絡,這些參數可由真陽樣本(Ture Positive,TP)、假陽樣本(False Positive,FP)和假陰樣本(False Negative,FN)計算得到。對此擬展開研究分述如下。
(1)精度():定義為個數與和個數之和的比值,該值可由下式計算得出:
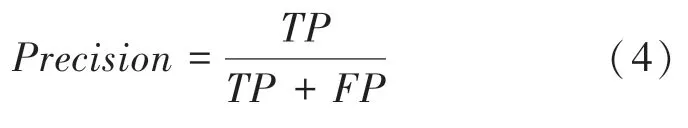
(2)召回率():定義為數量與和數量之和的比值,該值可由下式計算得出:
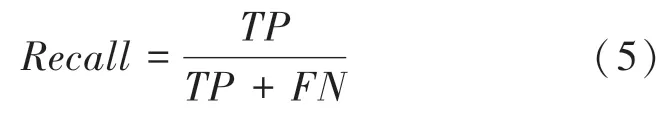
(3):定義為考慮和的調和平均值。該值可由下式計算得出:
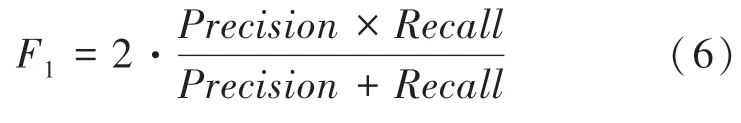
(4)交并比():是一個度量,用于計算預測輸出和目標掩碼之間的重疊百分比。計算方法為預測掩模和目標掩模像素數與2 個掩模像素數并集的交集。
本文采用2 個標簽作為模型的輸出;第一個標簽表示被修復區域,第二個標簽表示未被修復區域。由于有2 個不同的輸出標簽,因此本文計算了測試結果的平均精度()、平均召回率()、平均分數()和平均。本文方法在修復圖像數據庫上運行后的性能分析結果如圖4 所示。由圖4 可見,測試結果、、、分別為78.9、71.15、74.83和70.3,表明本文提出的圖像修復取證模型具有較好的檢測性能。
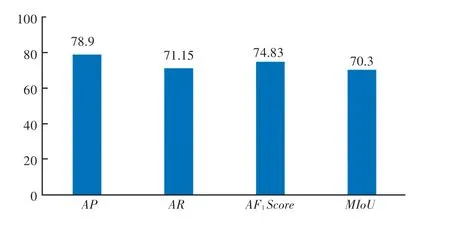
圖4 基于精度、召回率、F1 得分和交并比四個度量數據的性能分析Fig.4 Performance analysis based on average precision(AP),average recall(AR),average F1 Score(AF1 Score)and mean intersection over union(MIoU)
3 結束語
本文提出了一種融合注意力機制與FCN 的圖像修復取證網絡,為了對本文模型進行訓練和驗證,創建了彩色圖像的修復數據庫,并對本文模型進行了訓練和測試。從各種指標定量分析和圖像檢測效果來看,本文模型在檢測基于樣本塊修復的圖像時具有較好的性能。未來可以在本模型的基礎上加以改進,檢測其它圖像篡改操作,如復制、移動和拼接等。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
電測與儀表(2015年5期)2015-04-09 11:30:52
