基于ResNet 模型的回環檢測算法
2022-07-29 06:54:46黨淑雯
智能計算機與應用 2022年8期
陳 勇,黨淑雯,聶 鈴
(上海工程技術大學 航空運輸學院,上海 201620)
0 引言
隨著人工智能的發展,移動機器人已成為熱門研究課題。為實現自主導航任務,移動機器人需要執行實時定位、路徑規劃等操作,在此過程中即時定位和建圖(SLAM)起著至關重要的作用。按傳感器不同,SLAM 可分為激光SLAM 和視覺SLAM。由于RGB-D 相機的更新換代,兼且還具有體積小、重量輕、造價低廉等諸多優點,就使視覺SLAM 引起了學界的廣泛關注與濃厚興趣。回環檢測作為視覺SLAM 的關鍵組成部分,可以識別機器人以前經過的地方,從而減少機器人移動過程中產生的累積誤差。現有的回環檢測方法可以分為基于圖像特征和基于外觀不變性兩種。其中,基于外觀的回環檢測目前獲得了較為廣泛應用,該方法從本質上比較了視覺系統中2 幅相鄰圖像之間的相似性。
在基于外觀的方法中,較為通用的是基于詞袋模型的回環檢測算法。基于詞袋模型的回環檢測算法的主要運行步驟是:首先利用算法(SIFT、SURF、ORB )從采集到的環境信息中提取特征向量作為“單詞”,即通過提取圖像中具有局部不變的特征點作為視覺詞匯;其次,根據K 均值聚類算法與相近的單詞結合構成詞表,并分組到一個詞典中;最后,統計單詞在采集環境信息中出現的次數,用維數值向量表示圖像。但BOW 模型中手工標記的特征有一定局限性,即這些特征忽略了圖像中的一些有用信息,因此可能會產生精度較低的回環檢測。
1 基于ResNet 模型的回環檢測算法
雖然傳統的回環檢測算法能在視覺SLAM 系統中檢測出回環,但需要經過大量訓練來提取特征,且在不同場景下準確率較低。近些年,研究人員嘗試將神經網絡應用于計算機視覺領域,且有大量實驗已經證明了在計算機視覺中神經網絡有著良好表現。Lecun 等人將卷積神經網絡(CNN)應用于視覺中。實驗證明,CNN 能有效提取特征,應用深度學習網絡,能成功檢測出視覺SLAM 的回路,為解決回環檢測問題提供了一種選擇。Gao 等人提出了一種基于良好訓練的神經網絡的深度特征提取方法。但該方法訓練整個網絡耗時長、效率低,不適用于實時的SLAM 系統。Hou 等人使用一個預先訓練過的CNN 模型,生成一個適合于視覺SLAM 中的回環檢測的圖像表示。結果表明,Conv3 和Pool5 的性能最佳。但該模型CNN 描述符的維度非常高。Xia 等比較了數種 CNN模型(PCANet、CaffeNet、AlexNet、GoogLeNet)和傳統方法(BoW、GIST)在回環檢測中的性能。結果表明,該CNN 模型能更好地適用于回環檢測。但是,由于模型中使用支持向量機(SVM)來檢測循環,不能很好地滿足視覺SLAM 系統中實時性要求。Zhang 等人使用一個開源預訓練的CNN 模型、即OverFeat 來提取特征。近年來由于需要大量的標簽來訓練數據,所以就很少用到該CNN 模型。
針對上述算法存在的問題,本文提出了基于ResNet 模型回環檢測算法。總體流程如圖1 所示,算法實現步驟如下:

圖1 算法流程圖Fig.1 Flow chart of the algorithm
(1)根據選取策略,篩選關鍵幀集。
(2)通過預先訓練好的ResNet 模型,提取篩選出的關鍵幀集特征,生成高維特征向量。
(3)利用PCA 白化來降低向量的維數,提高檢測效率。
(4)通過計算特征向量間的歐式距離,再計算相似矩陣,驗證回環的準確率。
1.1 關鍵幀篩選策略
由于移動機器人在運動過程中拍攝的連續幀存在較多冗余信息,造成計算資源浪費,因此引入關鍵幀很有必要。選擇合適的關鍵幀,能有效提高定位和建圖的精準性和實時性。常見的關鍵幀篩選方法有:根據時間間隔對數據幀進行采樣、根據空間距離對數據幀進行采樣、根據圖像相似性進行采樣等。以上這些方法都是使用單一準則來篩選關鍵幀,無法適應不同的環境變化,因此關鍵幀傾向于多重融合選擇。
本文通過設定相對運動量來篩選關鍵幀,具體步驟如下:
(1)關鍵幀集合,第一幀、即為,將其歸入集合。
(2)對于新的一幀F,計算中最后一幀與F的運動,并估計其運動的大小。若≥,則表明2 幀運動變化大,離得較遠,應剔除;或≥,則表明2 幀運動變化小,離得太近,應剔除。這里,表示2 個相鄰幀的運動量,、為設定的閾值。只有2 幀的運動估計正確、能匹配,且兩者存在一定距離,則把該幀F加入到關鍵幀集合中。對應數學模型可表示為:
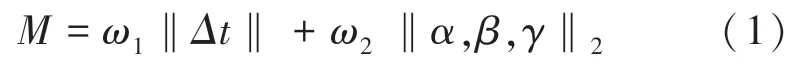
其中,,,表示幀間的三軸方向的旋轉量;,分別表示平移所占的權重和旋轉所占的權重;是2 幀間的平移量。
1.2 ResNet 網絡模型
2015 年,何凱明團隊提出ResNet 網絡。該網絡的發現不僅影響了學術界和工業界深度學習的發展方向,且在圖像檢測、圖像分割和圖像識別等領域獲得廣泛應用。ResNet 網絡結構如圖2 所示。基本設計原理是通過殘差結構來解決神經網絡中出現的退化和梯度消失問題,提高了整個網絡性能,且在ImgeNet 數據集上獲得了良好的分類結果。
由圖2 可知,當輸入后,輸出為:

其中,表示非線性函數。
通過一個捷徑(shortcut),和圖2 中的第2 個相結合,最終輸出:
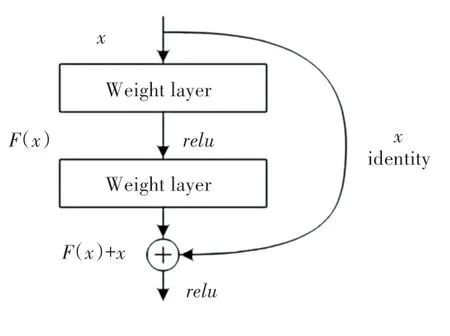
圖2 ResNet 網絡結構圖Fig.2 ResNet network structure
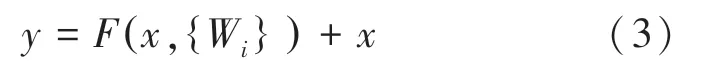
當需要對輸入和輸出維數進行變化時(如改變通道數目),可以在通過“捷徑”時,對加以線性變換,數學公式具體如下:
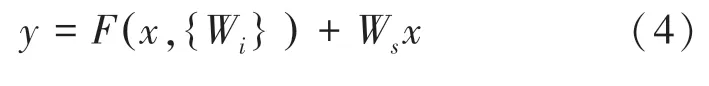
1.3 PCA+白化降維算法
研究中,可以從預先訓練過的網絡模型中提取出整個圖像特征,但卻具有高維數。本文通過主成分分析(PCA)和白化算法進行降維,同時也降低了關鍵幀的冗余程度。
PCA 是可以提升無監督特征學習速度的數據降維算法。算法的設計原理是將維特征投影到維()。輸入樣本集,,…,x,使其映射到空間,并實施中心化,選取個最大特征值,輸出映射矩陣。中心化時需用到的數學公式為:
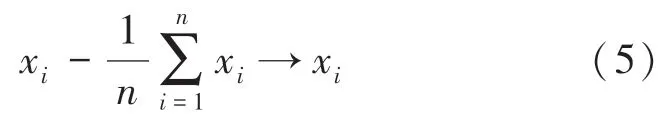
降維后,通過白化算法對每一維除以其標準差,公式如下:
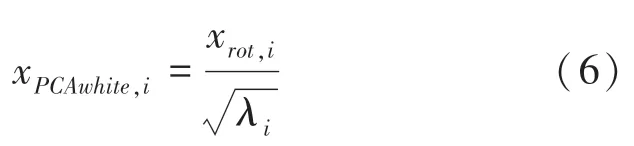
1.4 相似度計算
通過降維處理后的CNN 特征,使用歐氏距離來計算圖像和之間的差異。并繪制相似矩陣圖,用于度量圖像之間的相似度。歐式距離公式如下:
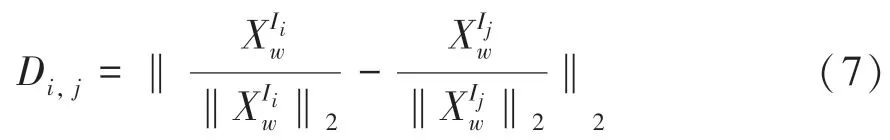
計算圖像和之間的歸一化相似性:
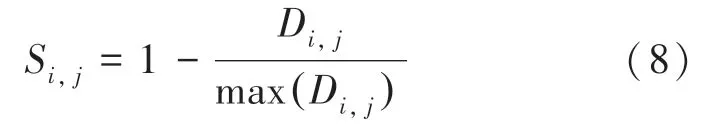
通過定義相似度矩陣,可以度量圖像之間的相似度。相似度矩陣示意如圖3 所示。由圖3 可知,矩陣的每一行都包含相似度的值,其范圍為(0,1)。不同的值用不同的顏色表示,值越高,圖像間的相似性就越高。若值為1,則表示檢測是一個循環閉合。
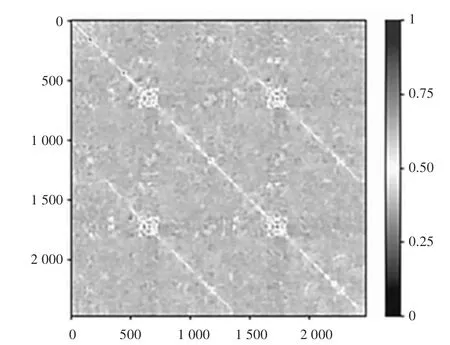
圖3 相似度矩陣示意圖Fig.3 Schematic diagram of similarity matrix
2 實驗結果與分析
2.1 數據集
實驗測試數據集為City Centre 和New College,即當機器人穿過室外城市環境時,每1.5 m 用攝像頭采集一次圖像,照明條件穩定。這2 個數據集分別是1 237 對和1 073 對圖像,數據集的更多細節見表1。

表1 數據集參數Tab.1 Data set parameters
2.2 不同模型相似性矩陣對比實驗
本文使用預先訓練過的ResNet50、ResNet101和ResNet152 模型來提取特征。根據公式(8),可以計算出圖像的相似得分,并求出相似性矩陣。研究中得到的基于ResNet 50 網絡模型的回環檢測算法的相似矩陣圖和Ground Truth 圖即如圖4 所示。圖4 中,Ground Truth 圖是相似矩陣圖的“掩碼”。

圖4 基于ResNet50 網絡模型的回環檢測算法的相似矩陣圖和Ground Truth 圖Fig.4 Schematic diagram of similarity matrix and Ground Truth based on ResNet50 network model
由圖4 中可知,較冷的顏色對圖像對的相似程度較小,而較暖的顏色對圖像對的相似程度更高。圖4 表明,該方法在檢測大部分回路方面是可行的,且ResNet50 網絡優于其它網絡。
2.3 不同算法準確率-召回率曲線對比實驗
為評估算法在回環檢測中的性能有效性,將本文改進算法與其它算法進行準確率()和召回率()計算,并通過準確率-召回率曲線進行衡量。這里,準確率是指算法得出的結果中真陽性與結果中所有回環的概率;召回率是指結果中為真陽性與檢測的所有真實回環的概率。研究推出的數學定義式如下:
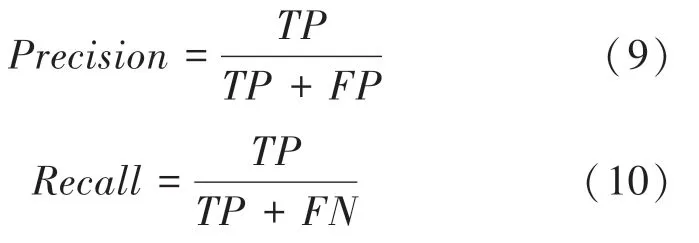
其中,表示真陽性;表示假陽性;表示假陰性。
實驗選用New College 數據集,通過將本文算法與經典算法FAB-MAP、SDA 以及詞袋模型算法進行對比試驗,得出的精度-召回率曲線如圖5 所示。
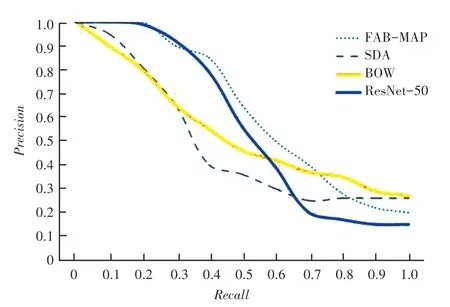
圖5 不同算法的準確率-召回率對比圖Fig.5 Comparison of precision-recall results of different algorithms
由圖5 可知,算法性能和該算法與、軸圍成的面積成正比。本文算法圍成的面積比其它算法都大,驗證了本文算法的魯棒性好。其精確值在召回率大于0.55 的情況下,達到最高水平。隨著軸數值變大,仍能保持準確率數值緩慢下降。本文算法在總體上比另外3 種算法的回環檢測效果都要好。
3 結束語
本文針對回環檢測中存在的一些問題,提出了一種基于ResNet 模型的回環檢測算法。首先對預先訓練的卷積神經網絡模型(ResNet50、ResNet101、ResNet152)進行性能對比,其次通過改進關鍵幀的選取策略,將篩選出的關鍵幀輸入預先訓練好的CNN 模型(ResNet-50),生成高維特征向量,并利用主成分分析(PCA)白化來降低特征向量的維數。最后,利用相似度矩陣檢測數據集中可能出現的回環。本文通過對比實驗結果可知,ResNet-50 模型相較其它對比模型性能更好,且本文算法對回環檢測是可行的。然而,在實時SLAM 系統中應用深度神經網絡仍然存在一定不足,有待下一步的研究解決。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
