基于視頻重建技術的視頻會議圖像傳輸方案*
2022-07-12 13:03:12莊祖江
通信技術 2022年6期
沈 宜,莊祖江,石 珺,賈 宇
(深圳市網聯安瑞網絡科技有限公司,廣東 深圳 518042)
0 引言
如今,視頻會議的需求日益增加,對視頻會議的傳輸安全技術[1]提出了挑戰。在多人實時視頻會議中,采用傳統視頻傳輸協議對網絡帶寬的需求較高。在實時視頻傳輸場景中,為了減少傳輸數據的大小,都會首先對視頻流進行編碼,其次通過網絡將視頻流傳輸到接收端進行解碼。目前常用的視頻解碼方案有H264協議[2],該協議可以壓縮視頻的大小,但是在壓縮率和傳輸圖像質量之間較難取得很好的平衡。
深度學習是最近幾年學術和工業領域研究的熱點,圖像生成也是其中受人關注的一個研究方向。當前,已有不少對人像視頻重建的研究,如NVIDIA公司在文獻[3]中采用了將提取的人臉關鍵點輸入生成網絡來進行圖像生成的方案,但該方案的生成效果受到關鍵點檢測的影響,同時對于側臉的效果較差;文獻[4]基于3D模型的重建,通過3D信息來進行視頻的生成,生成效果有所提高,但是由于受到3D模型生成的影響,因此生成速度較慢;文獻[5]采用了自監督的2D關鍵點以及圖像直接光流信息生成視頻,生成效果可以較好地還原原始的動作,但是對細節如唇部、眼睛的還原效果較差。
本文設計了一種基于視頻重建技術的單人像視頻會議圖像傳輸方案,將圖像生成技術中的人臉視頻重建技術引入到視頻會議圖像傳輸中。該方案先通過特征提取網絡提取發送圖像流中圖像的低維特征向量,然后在接收端通過生成網絡將低維特征向量重新還原為圖片,最后將網絡結構解耦分別部署在發送端和接收端。通過這樣的方案,達到了在減少傳輸帶寬的同時,減少圖像質量的損失的目的。本文整體方案受到文獻[5]的啟發,將原始的二維特征點轉換到三維空間上,并采用了更加先進的生成判別網絡結構,從而取得了更好的圖片生成效果,此外,還將輸入編碼和輸出解碼器網絡相隔離,因此能夠完成圖像的遠端傳輸工作。
1 圖像編碼傳輸方案
1.1 整體方案流程
視頻圖像傳輸方案整體思路如圖1所示。

圖1 視頻圖像傳輸整體方案
總體方案設計思路為,在發送端通過網絡編碼將圖像流解碼為低碼率信息傳輸到接收端,然后再經過解碼網絡恢復成圖像。具體的編碼解碼過程又分為參考幀傳輸方案和后續幀傳輸方案。本文將采用傳輸圖像流的第一幀作為參考幀。
1.2 參考幀傳輸方案
參考幀傳輸方案主要是輔助網絡生成,傳輸一些固定的特征信息,減少后續傳輸量,同時提高生成圖片質量,參考幀傳輸方案具體如圖2所示。

圖2 參考幀傳輸方案
發送端各個網絡的功能:特征向量提取網絡通過人臉特征提取網絡對圖像進行壓縮,提取原始的通用特征;頭部信息提取網絡通過頭部信息,提取網絡提取頭部的姿態信息和表情特征;人臉特征提取網絡提取參照人物身份特征。
參考幀特征信息由通用特征、參考幀頭部信息特征和參照人物身份特征共同構成,用于后續幀傳輸方案中的圖像重建網絡。這些信息僅在選定參考幀時進行傳輸,減少了網絡傳輸的數據量。參考幀傳輸時還沒有開始圖像重建,是一個系統狀態初始操作。
1.3 后續幀傳輸方案
在進行了參考幀特征傳輸后,后續的幀采用另外的方案進行傳輸,同時開始進行圖像的重建。

圖3 關鍵幀傳輸方案
后續幀的圖像在發送端需要經過頭部信息網絡提取姿態特征和表情特征,之后將處理的特征發送到接收端,接收端通過后續幀信息以及參考幀信息輸入到生成網絡中,就可以還原出發送端的原始圖像幀。
2 神經網絡結構
實現視頻會議圖像傳輸方案的神經網絡包含人臉特征提取網絡、頭部信息提取網絡、特征向量提取網絡、密集運動場網絡以及生成網絡,其中生成網絡的模型和密集運動場網絡部署在接收端,其余模型在發送端。整體神經網絡結構如圖4所示。

圖4 整體神經網絡結構
2.1 人臉特征提取網絡
人臉特征提取網絡的目的是提取參考幀人物的3D通用特征,用于最后生成器的合成,其網絡結構如圖5所示。

圖5 人臉特征提取網絡結構
輸入圖像的分辨率為256×256,輸出的特征為fr(f表示特征信息,下標r表示參考幀)。人臉特征提取網絡的設計目的是提取參考幀圖片中人物的色彩特征,輔助最后生成網絡進行生成。該網絡只用于對參考幀圖像進行特征的提取,在整個圖像傳輸系統中只需要在初始化的時間工作1次。
人臉特征提取網絡的訓練采用無監督的方式,不采用具體的loss進行輸出的約束,由整個網絡模型的生成質量損失來進行學習訓練。
2.2 頭部信息提取網絡
頭部信息提取網絡用于提取參考幀和后續幀中人物的頭部姿態、位移、表情系數特征。參考的是HopeNet[6]的網絡結構,在原始網絡的輸出端增加位移和表情系數的輸出,其結構如圖6所示,其中FC表示的是全連接層。參考幀和后續幀的圖片都需要經過頭部信息提取網絡輸入旋轉系數r、位移特征t、表情特征δ,相關特征和關鍵點特征組合后可以得到對應圖片的表達特征。
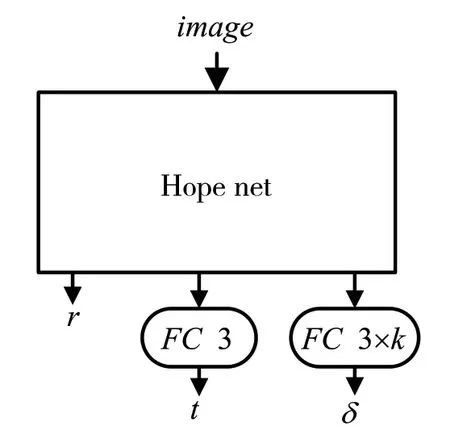
圖6 頭部信息特征提取網絡結構
頭部信息提取網絡的訓練,對旋轉系數r采用L1損失,標簽信息rgt由Hope net得到,其損失函數為Lr=||r-rgt||1;δ也采用了L1損失用于限制其值的大小,其損失函數為Lδ=||δ||1;t采用自監督的方式進行訓練。
2.3 關鍵點特征提取網絡
關鍵點特征網絡用于提取參考幀人物的身份特征,采用了MobileFaceNets[7]的預訓練權重,增加了2層全連接層下采樣到3×k維的特征,網絡如圖7所示。

圖7 關鍵特征提取網絡結構
關鍵點特征網絡輸入的變量為參考幀圖片,輸出為xk,k為選取的關鍵點數量,本文中k=15,則對于參考幀的特征向量結合頭部信息提取網絡的結果,計算公式為:

式中:下標r為參考幀的相關特征量;下標o為其他幀的相關特征量。
關鍵點特征網絡為了讓關鍵點均勻地分布在特征空間中,采用的損失函數為:
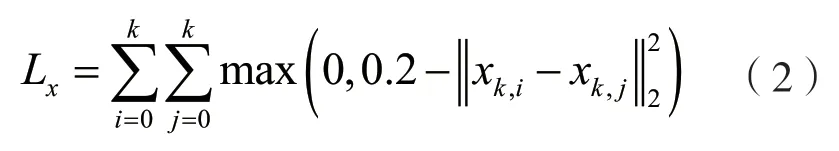
2.4 接收端模型
接收端模型包含密集運動場網絡和生成對抗網絡,其中運動場網絡用于預測參考幀提取的特征和后續幀傳輸的特征之前的運動特征,用于提高圖片的生成效果。3D運動場的輸入是將參考幀和關鍵幀的光流特征與fr相結合輸入到網絡中,網絡結構是將UNET[8]網絡結構中的2D卷積替換為3D卷積。輸出運動特征m(x)和遮罩mocc。
生成對抗網絡的網絡結構如圖8所示,中間的隱特征與3D運動場網絡輸出的遮罩特征圖相結合,解碼器部分采用了spade塊[9]替換res塊[10],提高生成圖像的質量。

圖8 生成網絡結構
對應生成網絡的訓練損失采用了Perceptual損失[11]、生成對抗網絡(Generative Adversarial Network,GAN)[12]損失。
3 實驗與結果
3.1 相關實驗準備
本文模型訓練數據集采用的是Voxceleb[13]數據集,數據集共包含1 251位不同人物說話的頭部視頻,訓練集共有21 819段視頻,測試集有677段視頻,本次實驗的評測結果的指標是在此數據集的測試集上得到的結果。本文模型訓練采用了4塊RTX3090,模型一共訓練40輪。
3.2 重建精度實驗
為了對比本文視頻重建的效果,采用了一階模型移植(First Order Model Migration,FOMM)模型[5]和Fs-vid2vid模型[3]為基線模型進行重建精度的對比,采用平均峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)[14]和結構相似性(Structural Similarity,SSIM)[15]作為圖像清晰度指標,采用平均關鍵點距離(Averary Keypoints Distance,AKD)[5]作為重建動作準確度指標。結果如表1所示。

表1 模型重建精度實驗結果
從表1中可以看出本文所提出的方案,在清晰度和準確性上都有更優的表現,這得益于選取了更加先進的網絡結構以及更高維的三維特征。為了直觀地展示結果,圖9給出了一部分測試結果。
由圖9可以進一步得到,本文的方案更加優秀,在存在面部遮擋的情況下,也能較好地還原人物的面部表情。

圖9 視頻生成實驗結果
3.3 傳輸比特率實驗
以分辨率為256×256、幀率為25的視頻為例,在后續幀傳輸階段只需要傳輸xrk,傳輸1幀圖像需要傳輸數據量為15×3×2 bit,轉換為視頻碼率為2.197 2 kbit/s。與采用H264標準進行壓縮的視頻碼率分別為28 kbit/s和38 kbit/s的圖像對比結果如圖10所示。
由圖10中可以看出,本文生成的結果不但在清晰度上優于采用H264壓縮的圖片,而且傳輸的碼率低于傳統編碼結果,因此可以得出本文所提出的方案在降低視頻傳輸碼率的同時還保證了較好的清晰度。

圖10 編碼清晰度對比實驗
4 結語
本文提出了一種基于視頻重建的會議圖像傳輸系統方案,可以用于臉部視頻會議傳輸中減少傳輸的碼率,降低網絡帶寬的壓力。在和相關圖像重建工作的對比中,本文所提出的方案取得了更好的重建圖像清晰度和人物動作精度,評價指標PSNR達到了23.44;在和傳統編碼方式的對比中,本文方案取得了更高的圖像清晰度以及更低的視頻碼率。在后續幀的傳輸中,本文碼率為2.197 2 kbit/s,同時,傳輸的信息變為特征向量,且不附帶其他信息,可以更好地保護傳輸數據的安全。
本文嘗試將深度學習中的生成網絡技術引入到視頻會議的圖像傳輸中,提出的方案具有一定的可行性,但是也存在著一些不足,如目前還只能限制使用在單人像場景下的視頻會議中,場景單一,另外對于接收端和發送端的機器配置存在一定的要求。因此,還需要進一步改進網絡和優化方案,從而能夠采用更小的網絡、適應更多的場景。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
艦船科學技術(2022年15期)2022-09-14 09:21:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年19期)2018-11-14 02:37:08
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
自動化學報(2017年11期)2017-04-04 02:52:58
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
