基于CNN-BiGRU的方言語種識別*
2022-07-12 13:03:04劉增力
通信技術 2022年6期
付 英,劉增力,湯 輝
(1.昆明理工大學,云南 昆明 650504;2.江西省科技基礎條件平臺中心,江西 南昌 330003)
0 引言
全球化的今天,不同國家不同地區的人們跨語種交流的機會越來越多,隨著深度學習技術趨于成熟,語種識別研究也成為眾多研究者關注的重點。語種辨識逐漸應用到各個領域,而能否迅速、準確判斷說話者所說的語言是其他功能正常運行的基礎[1]。方言語種識別是語種識別中的一個特例,由于方言之間具有相似性,因此針對方言語種識別的研究更具挑戰性。
語種識別是通過給定一段語音并判別所屬區域的過程,其作為語音信號處理的前端技術,在語音識別等相關領域發揮著重要作用,主要應用在語音翻譯、公共安全、多語言對話系統等方面[2]。到目前為止,許多技術已成功應用于語種識別中,特別是針對易混淆的方言語種辨識。傳統的聲學模型如高斯混合—通用背景模型(Gaussian Mixture Model-Universal Background Model,GMM-UBM)[3]、隱馬爾可夫模型(Hidden Markov Model,HMM)[4]等常用于語種辨識中,但這些聲學模型往往結構復雜且訓練時間長。
近年來,深度學習依靠快速的計算能力以及對大數據的分析處理能力,在語音研究領域被廣泛應用。早期,眾多研究者利用深度學習提取語音深度瓶頸特征(Deep Bottleneck Feature,DBF)[5],替代了傳統的GMM-UBM結合聲學特征的方法,該特征能高效表征語種信息,使語種更具有區分性,但模型結構較為復雜。之后,基于各種神經網絡結構搭建端到端語種辨識系統的方法應運而生。最早Lopez-Moreno等人[6]將深度神經網絡(Deep Neural Network,DNN)應用在短時語種識別中。之后,Gonzalez-Dominguez等人[7]提出長短時記憶遞歸神經網絡(Long Short Term Memory-Recurrent Neural Network,LSTM-RNN)用于自動語種識別,有效解決了RNN中梯度消失的問題,但此模型結構復雜且訓練時間長。Geng等人[8]搭建了基于LSTM和注意力機制的端到端語種識別系統,并應用在短時語種分類中,但由于LSTM并未考慮到語音未來的信息導致識別效果并不理想。Fernando等人[9]搭建了基于雙向長短時記憶網絡(Bidirectional LSTM,BiLSTM)的端到端語種識別系統,有效考慮了語音過去和未來的信息,經實驗表明,BiLSTM在短時語種識別中表現良好。Mao等人[10]將雙向門控循環單元網絡(Gated Recurrent Unit networks,GRU)用于多分類語種識別中,相比于BiLSTM網絡結構更加簡單且識別率有所提升。此外,卷積神經網絡(Convolutional Neural Network,CNN)[11,12]也常用于語種辨識中,它提取語音信號的局部特征,有效提升了語種識別效果。
對于語種識別辨識系統,常使用交叉熵(Cross Entropy,CE)損失函數進行分類,但并未考慮到數據不均衡和語種易混淆的問題。2017年,何凱明等相關研究者提出用于密集物體檢測的焦點損失(Focal Loss,FL),實驗表明,焦點損失能有效解決這個問題,提高模型的性能[13]。Zhao等人將焦點損失作為語音識別任務中的優化策略之一,通過對難易分類的權重不同分配來提高識別率[14]。
基于以上研究,本文首先搭建一個CNN模型,通過對比不同特征提取算法在方言語種識別中的識別效果,選取最佳輸入特征;其次,搭建基于CNN-BiLSTM的網絡,對比焦點損失不同參數對模型識別率的影響,從而選取最優參數;再次,搭建不同模型對不同時長的方言進行識別,得到最終識別模型;最后,分別采用不同的語音增強方式對數據集進行擴增,提高模型的泛化能力。
1 特征處理
語種識別中常用的聲學特征有梅爾頻率倒譜系數(Mel-Frequency Ceptral Coefficients,MFCC)[15]、對數濾波器能量(Log Mel-filterbank energy,Log Fbank)特征[16]、語譜圖特征[17]等。本文對比以上3種特征,選取識別率最高的特征作為后續模型的輸入特征,并且考慮到方言為有調語音,將聲學特征與音調特征進行融合,提高方言語種識別率。
1.1 MFCC
由于人耳對聲音頻率的感知并非呈線性關系,因此使用MFCC特征仿真人耳對聲音感知的關系,可近似表示為:

式中:FMel為人耳感知的頻率;FHz為聲音的真實頻率。
提取MFCC特征的流程如圖1所示。首先,語音信號x(n)經過預加重(預加重系數為0.97)、分幀(幀長為25 ms,幀移為10 ms)、加窗后得到每幀信號xi(n);其次,對xi(n)進行FFT變換得到頻譜Xi(k),并得到對應的能量譜Ei(k);再次,經過Mel濾波器組后得到Si(m),進行對數運算得到Yi(m);最后,進行離散余弦變換(Discrete Cosine Transform,DCT)得到MFCC特征。本文濾波器組數取26,經DCT變換后得到13維MFCC特征向量。
1.2 LogFbank
LogFbank特征的提取與MFCC特征提取過程基本一致,在圖1中不經過DCT變換即可得到LogFbank特征。相比于MFCC特征,LogFbank特征向量間具有較高的關聯性且耗時短,被廣泛應用于神經網絡中。本文提取了40維的LogFbank特征作為模型的輸入。

圖1 MFCC和LogFbank特征提取對比
1.3 語譜圖
語譜圖是語音信號的頻率隨時間變化的圖像表示,是語音信號經過短時傅里葉變換而得到的,保留了語音信號最原始的信息。語譜圖既可以觀察頻譜的變化過程,又能突出頻譜的精細結構,是信號常用的時頻分析方法之一。根據窗函數的大小,語譜圖可分為寬帶語譜圖和窄帶語譜圖。以上海話為例,圖2展示了寬、窄語譜圖的區別,圖2(a)為寬帶語譜圖,時間分辨率高,而圖2(b)頻率分辨率高,為窄帶語譜圖。

圖2 語譜圖展示
1.4 音調特征
對于漢語方言而言,音調是方言較為顯著的特征,進行漢語辨識時,可利用一種方言中存在這個音調而另一種方言中不存在進行區分。由于傳統聲學特征只保留語音的音色特征,而忽略了語音的音調特征,所以本文采用短時自相關函數法提取每一幀的基音信息表示音調特征。
2 CNN-BiGRU模型
2.1 CNN
1960年,Hubel和Wiesel[18]兩位科學家在貓的大腦中發現不同于常規神經網絡的神經元結構,受Hubel和Wiesel對貓視覺皮層電生理研究的啟發,Fukushima等人[19]提出了一個包含卷積層和池化層的神經網絡結構,由此卷積神經網絡誕生。由于CNN網絡存在權值共享以及稀疏連接,因此CNN的網絡結構大幅度減小了復雜水平。
CNN的結構主要由3部分組成:第1部分是卷積層,它對輸入圖像進行過濾并通過滑動窗口方法計算與提取有意義的值;第2部分是池化層,本質是一個下采樣過程,可減小通過卷積操作提取的特征的大小,常用的池化方式有最大池化和平均池化方法;第3部分是全連接層,和經典神經網絡結構一樣連接所有的神經元。
2.2 BiGRU
GRU是目前非常流行的一種神經網絡,它是LSTM的一種簡化網絡,2014年由Cho等人[20]首次提出,用于解決長期記憶和反向傳播中的梯度問題。與LSTM相比,GRU用更新門代替了LSTM中的遺忘門和輸入門,結構簡單且參數少,更有利于模型收斂,計算效果和LSTM差不多,一定程度上提高了模型訓練的效率,有效緩解了梯度爆炸或消失問題。由于方言之間具有一定的相關性,需要考慮語音數據中的上下文信息,所以本文采用雙向門控循環單元(Bidirectional GRU,BiGRU)搭建模型,它是由前向GRU和后向GRU組成,同時考慮了數據過去和未來的信息。
2.3 CNN-BiGRU-MFA
本文提出基于CNN和BiGRU的模型實現方言語種識別,其整體結構如圖3所示。該模型主要由Block塊、多層特征聚合(Multi-layer Feature Aggregation,MFA)、BiGRU層、全連接層組成,其中,每個Block包含卷積層、ReLU層、批量歸一化層。首先,提取方言語音信號的特征輸入到卷積塊中,利用卷積層提取方言信號的局部特征;其次,利用MFA將多層卷積層特征進行聚合,將整合特征輸入到BiGRU層中提取時序相關特征;再次,將BiGRU層的輸出特征輸入到全連接層中;最后,通過Softmax函數將輸出向量映射到(0,1)區間,并計算方言類別之間的概率來預測漢語方言的類別標簽。在訓練過程中,本文使用焦點損失代替傳統的交叉熵損失函數來優化模型參數。
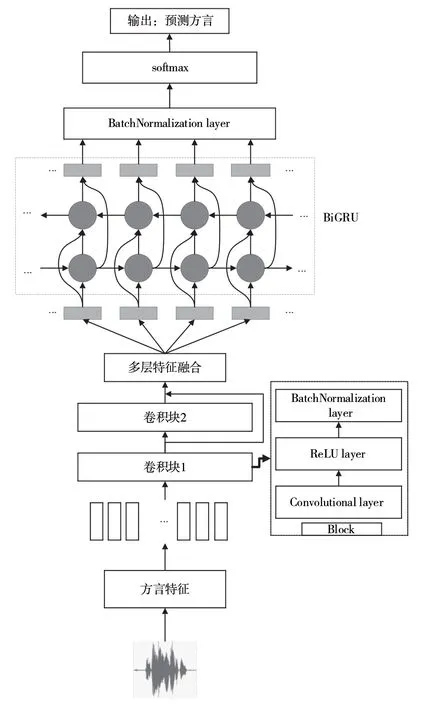
圖3 基于CNN-BiGRU的方言語種識別系統結構
3 改進多類別交叉熵損失函數
對于語種識別任務,常使用交叉熵損失函數(Cross Entropy,CE),并將其最小化進行模型優化,CE是計算真實類別標簽分布與預測的類別標簽分布之間的距離,其定義為:

則交叉熵損失函數LCE定義為:

式中:N為語音樣本數;M為語種類別數;ynm∈{0,1},如果樣本n的真實類別為m時則取值為1,否則為0;y^nm為觀測樣本n屬于類別m的預測概率值;θ為模型的參數;ym為某個類別的真實值;y^m為該類別的預測值。
交叉熵損失函數在樣本均衡且易分類的樣本中表現良好,但針對本文研究的方言數據具有易混淆性且各樣本數據不均衡的情況,引入焦點損失函數作為多語種識別的損失函數。焦點損失是交叉熵損失的一種延伸,本質是使用一個合適的函數衡量難易樣本對總損失函數的貢獻,并以此優化模型。
針對樣本不平衡問題,焦點損失(Focal Loss,FL)引入權重系數α對正負樣本的權重進行平衡,減少多樣本數據對損失函數的影響,定義為:

α雖然平衡了各個語種之間的樣本數,但不能區分相似度較高的語種樣本。因此,引入調制系數β調整難易分類的權重,將模型的訓練重點放在難分類樣本上,定義β為:

此時的焦點損失LFL定義為:

假設式(7)中的pm接近于1時,(1-pm)γ趨近于0,則預測為正確樣本數的損失很小,對總的損失貢獻減小,其權重下降;反之,當pm的值很小,(1-pm)γ趨近于1時,對總損失貢獻較大,權重增大。將α與(1-pm)γ結合,得到最終的FL定義為:

式中:α∈[0,1],γ∈[0,5],當αt=1,γ=0時為交叉熵損失。通過對權重的控制,能較好地區分易混淆的方言語音數據。
4 實驗結果與分析
4.1 實驗準備
本文實驗是基于NVIDIA RTX 3090的硬件平臺實現的,所有深度學習模型框架使用Keras框架實現。實驗數據來源于4部分,具體如下文所述。
(1)2018年科大訊飛方言保護競賽數據集。該數據集中每種方言有40人的朗讀語音,每種方言訓練集有6 000句,測試集有500句,訓練集和測試集的說話人均無重復,錄制環境有多種場景,以pcm格式存儲,16 bit量化,采樣率為16 000 Hz。選取其中的8種方言,分別為長沙、河北、合肥、南昌、寧夏、陜西、上海和四川方言。
(2)Common Voice數據集。該數據集覆蓋了世界各地幾十種不同的語音,語音數據豐富而且質量較好,數據以mp3格式存儲。從該數據集下載了粵語用于實驗分析。
(3)中國語言資源保護工程采錄展示平臺。該平臺覆蓋了全國34個省區市的數據,調查語種包括123種語言和全部漢語方言。在該平臺上收集了云南10個地方的方言組成云南話用于研究。
(4)利用各視頻網站對方言數據進行收集。考慮到收集的音頻數據集少且說話人單一,所以在視頻網站收集了長沙、河北、合肥、南昌、寧夏、陜西、上海、四川、云南和粵語10種方言的音視頻,以mp4格式存儲。
由于收集的方言數據來源廣泛,所以需要將方言音頻數據統一格式,方便語音處理,統一將數據轉化為wav格式的文件,以采樣率為16 kHz,16 bit量化,單聲道進行存儲,共有10種不同的方言種類。
4.2 評價指標
方言語種識別系統的性能評價指標以語種識別正確率Racc進行評價,則有:

4.3 參數設置
本文模型的輸入特征分別為MFCC特征、LogFbank特征、語譜圖特征以及將LogFbank特征與基音特征F0融合的特征,使用Adam優化器,初始學習率設置為0.001,最小批量大小為64,迭代次數為30,損失函數分別使用交叉熵函數和焦點損失函數對模型進行優化。
4.4 實驗仿真與分析
基于CNN-BiGRU的方言語種識別實驗主要由4部分組成。實驗1:搭建CNN系統,對比不同輸入特征的方言識別率。實驗2:針對方言易混淆性和數據的不平衡性,進一步研究焦點損失對方言識別率的影響,對焦點損失的權重因子α和調制因子γ不同參數的選取進行了實驗仿真,模型基于CNN-BiLSTM-MFA。實驗3:對比本文提出的模型與其他模型的識別率,驗證本文模型在方言語種識別中是否具有優越性。實驗4:采用數據增強方式對訓練集進行擴增,提高模型的泛化能力。
4.4.1 實驗1
將MFCC特征、LogFbank特征、語譜圖以及LogFbank+F0特征作為CNN的輸入。卷積層的卷積核大小為3,卷積步長為1,填充方式為same,卷積層輸出后經過批量歸一化層、激活層后再進行全局平均池化,最后經全連接層后對方言識別分類。實驗結果如表1所示。

表1 不同特征提取參數方言識別結果
從表1可以看出,方言語種識別結果依次是LogFbank+F0>LogFbank>語譜圖>MFCC。由于LogFbank特征向量之間的相關性以及方言的有調性,選擇LogFank+F0特征作為后續研究的輸入特征。
4.4.2 實驗2
為了選取FL的最佳參數,采用控制變量法對α∈{0.25,0.5,0.75},γ∈{1,2,3,4,5}進行不同時長方言識別率對比實驗。分類模型采用CNN-BiLSTMMFA,模型結構依次為卷積塊、卷積塊、多層特征融合、雙向LSTM層、全連接層。實驗結果圖4所示。
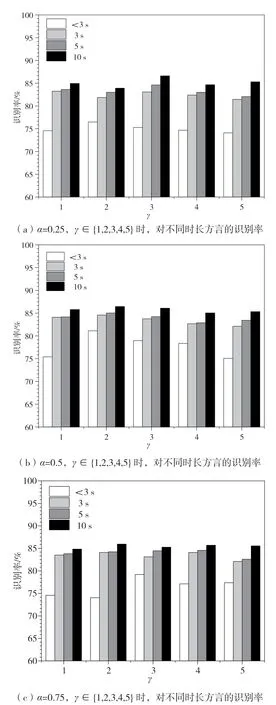
圖4 不同α和γ時,方言識別率對比
從圖4中可以看出,FL不同參數的選擇對難易樣本權重加權比例有影響。當α=0.5,γ=2時,不同時長的方言識別率都達到了最高,識別率分別達到了81.12%,84.58%,85.03%,86.44%。
4.4.3 實驗3
為了評估所提方法的有效性,對比不同模型對不同時長的方言的識別率,本文的基線系統采用2018年科大訊飛方言識別競賽所提供的識別模型LSTM-DNN-CE。模型結構依次為輸入層(輸入維度為(None,None,41))、LSTM層(隱藏層節點數為128)、全連接層(神經元個數為10),并使用Softmax函數對方言進行分類。在此基礎上分別搭建了6種不同的模型進行對比:模型1為GRU-DNNCE模型,模型結構與基線系統類似,將LSTM層換成GRU層;模型2為BiLSTM-DNN-CE模型,考慮到語音的上下文相關性,將基線系統的LSTM層替換成BiLSTM,節點數保持不變;模型3將模型2中的BiLSTM換成BiGRU層,節點數保持不變;模型4為CNN-BiLSTM-MFA-CE,具體在基線系統的基礎上加入兩層卷積塊,模型結構如實驗2所示,并使用交叉熵損失函數進行優化;模型5為CNNBiGRU-MFA-CE,具體是將模型4中的BiLSTM層換成BiGRU層,并使用交叉熵損失函數進行優化;模型6為CNN-BiGRU-MFA-FL,是將模型5中的交叉熵損失函數換成本文提出的焦點損失函數。實驗結果如表2所示。

表2 不同模型的對比結果
從表2可以看出,CNN能有效提取方言信號的局部特征,但由于方言是時序序列,LSTM等變體能較好表征語音中的時序信息,因此將兩者進行結合,可以提升對不同時長方言的識別率,進一步驗證了所提模型對方言分類有效。另外,使用FL代替CE,進一步提高了不同時長方言的識別率,相比CNN-BiGRU-MFA-CE模型,平均識別率提升了0.99%。最終,選擇CNN-BiGRU-FL作為本文的識別模型,相比于基線系統,所提方法平均識別率提升了4.09%。
4.4.4 實驗4
由于方言數據多數是在純凈環境下錄制且數據量少,所以使用audiomentations工具包對方言數據進行增強,增加方言數據量和噪聲數據,提高模型的泛化能力和魯棒性。主要增強方式如表3所示。
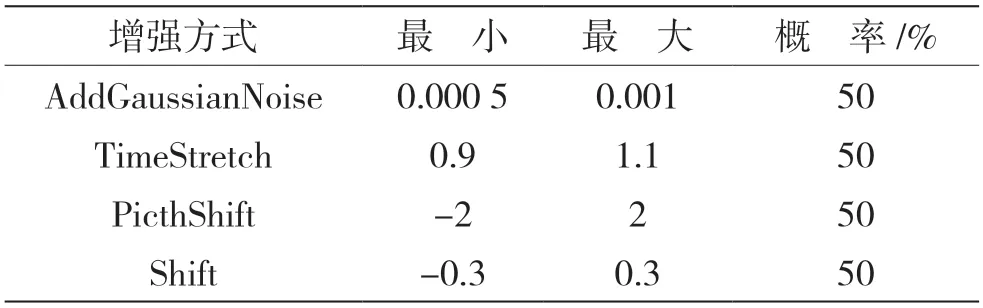
表3 數據增強參數設置
在相同環境下,使用實驗3中選擇的最優模型CNN-BiGRU-MFA-FL進行實驗仿真。通過表3中的增強方式對語音數據進行增強,比較不同時長方言識別率的大小。共仿真了5組對比實驗,其中第1組是采用原始數據進行訓練得到不同時長測試集的識別率,其余4組為隨機選取25%的數據集進行數據增強后的識別結果,實驗結果如表4所示。

表4 數據增強對方言識別率的影響
從表4可以看出,相比于不進行數據增強,使用不同的增強方法對方言識別均有一定的影響,采用添加高斯噪聲的方式增加訓練集雖然對方言識別率影響不大,但提高了模型的泛化能力,其余3種增強方法對不同時長方言數據的識別率有不同的提升,其中采用時移變換Shift的增強方法有效提升了方言語種識別率。
5 結語
針對漢語方言易混淆且識別率低的問題,本文首先應用CNN網絡搭建方言語種識別系統,對比了不同輸入特征對方言語種識別率的影響,選取了LogFbank特征融合基音特征F0作為最佳輸入特征;其次,針對方言數據集不均衡且易混淆的問題,使用焦點損失函數代替交叉熵損失函數,為難易方言種類分配不同的權重對模型進行優化,經過不同參數對比,最終選擇權重因子α=0.5和調制因子γ=2作為焦點損失函數的最終參數;再次,對比了不同模型對不同時長方言語種的識別率,實驗結果表明,本文所提模型CNN-BiLSTM-MFA-FL相比其他模型對方言語種的識別效果更好,能夠更有效地提升方言語種識別的準確率,相比于基線系統,本文所提方法準確率提升了4.09%;最后,使用語音增強的方式對方言數據進行擴增,提高模型的泛化能力和魯棒性,仿真顯示,采用數據增強的方式對方言數據進行擴充,能提升模型泛化能力和不同時長方言的識別率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
