基于改進Faster R-CNN的海上彈著點水柱目標檢測算法
2022-07-10 09:52:00王永生姬嗣愚杜彬彬
兵器裝備工程學報 2022年6期
王永生,姬嗣愚,杜彬彬
(海軍航空大學,山東 煙臺 264001)
1 引言
在執行海上演練、作戰等任務時,快速地獲取武器射擊彈著點的準確位置,有利于實時評估射擊結果,對提高部隊戰斗力水平具有重要的指導意義。
現階段主要依靠雷達號手觀察彈著點處水柱信號評判射擊效果,從使用角度來看,這種依靠人工檢測彈著點的方法主要存在測量精度不準、測量時間長、彈著點重疊時無法辨別等問題。近年來,目標檢測技術取得了巨大的成功,已在海防監視、精確制導、視頻監控等多個領域得到廣泛應用[1],為彈著點的檢測提供了新的方向。當前的目標檢測算法主要通過引入卷積神經網絡自動提取高層特征[2]。根據檢測過程中是否包含候選區域推薦,主要分為基于候選區域思想的two-stage[3-6]算法和基于回歸思想的one-stage[7-12]算法。前者的典型算法包括R-CNN系列、R-FCN等,突出優點是檢測精度較高;后者的典型算法包括YOLO系列、SSD、DSSD等,優勢在于檢測速度快。然而,雖然這些算法都在不斷地完善目標檢測的精度和速度,但是對于海上彈著點水柱信號的檢測并不完全適用。Faster R-CNN算法是精度非常高的一種two-stage目標檢測算法,但在實際應用過程中,仍然存在特征信息提取有限、檢測速度過慢的問題,本文以Faster R-CNN作為基礎模型,結合采集到的水柱信號尺寸變化大、形態變化多的特點,提出改進的Faster R-CNN模型——ST-Faster R-CNN,以Swin Transformer作為骨干網絡,結合深淺層特征融合,對攝像頭捕獲到的彈著點處的水柱信號進行目標檢測,為后續獲得彈著點的位置及距離信息奠定基礎。
2 Faster R-CNN算法原理
2.1 網絡整體架構
Faster R-CNN是在Fast R-CNN算法基礎上改進得到的,主要解決的是由選擇性搜索(selective search)生成候選區域耗時耗力的問題。Faster R-CNN算法采用RPN(region proposal networks)網絡代替選擇性搜索[5],將特征提取、生成候選區域、邊框回歸、分類都整合在了一個網絡中,在精度和速度方面都有很大提升,其整體結構如圖1所示。
Faster R-CNN的整體流程可以分為以下3步:
1) 提取特征:從VOC或COCO數據集中得到輸入圖片,經過VGG16或其他骨干網絡(backbone)提取圖片特征;
2) 生成候選區域:利用提取到的圖片特征,經過RPN網絡,獲取一定數量的感興趣區域(region of interests,RoI);
3) 分類與回歸:將感興趣區域和圖像特征輸入到RoI頭部,對這些感興趣區域進行分類,判斷其屬于什么類別,同時對位置進行微調。
2.2 RPN網絡
RPN網絡作為Faster R-CNN最大的創新點,其主要作用是實現目標的精確定位,本質上是利用一個卷積神經網絡代替選擇性搜索生成候選區域,使得輸入任意尺寸的圖片信息可以輸出待檢測目標的候選框矩陣及其得分[13]。候選框在原始圖像上的映射被稱為錨點框(anchor),RPN結構如圖2所示。
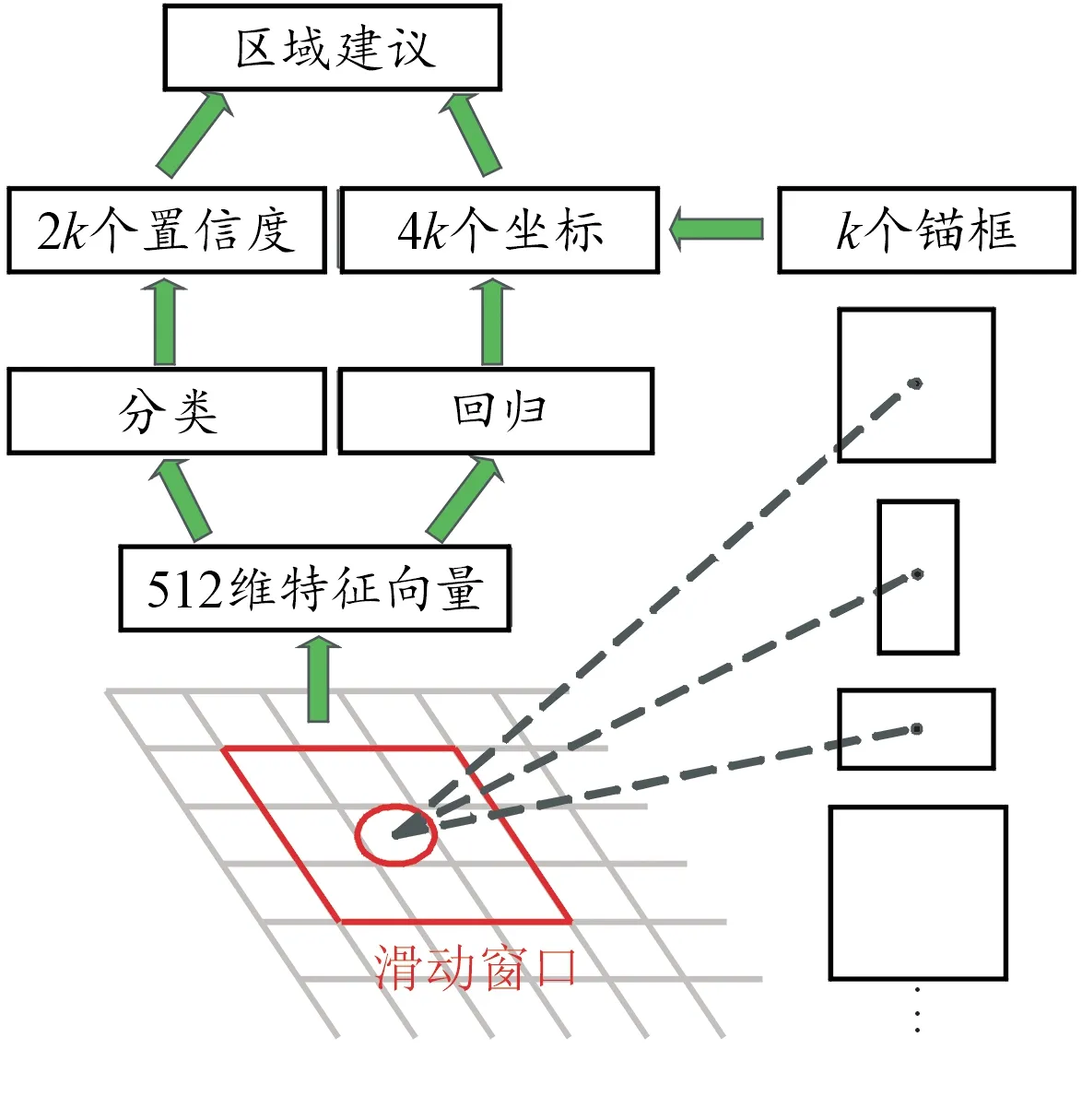
圖2 RPN結構框圖Fig.2 RPN structure diagram
通過設置不同比例尺度和面積的anchor,得到k(原算法取值為9)個不同的錨框,將每個anchor映射為512維的低維特征向量,分別輸入到分類層和回歸層中,以端到端的方式進行訓練。分類層負責預測錨框內是否含有目標,得到2k個置信得分,回歸層負責回歸邊界框的位置,得到4k個坐標位置參數,最后綜合分類層和回歸層輸出的結果,得到目標區域建議框,再輸入到后面的檢測網絡中進行目標檢測。
2.3 邊框回歸
在Faster R-CNN中,采用邊框回歸來實現錨點框(anchor)到真實標注框(ground truth box,GT)的過渡,使得原始預測框經過映射得到一個跟真實值更加接近的回歸窗口。給定原始anchor為A=(Ax,Ay,Aw,Ah),GT=(Gx,Gy,Gw,Gh),當二者相差較小時,近似認為這是一種線性變換,并用線性回歸模型來對回歸檢測框進行微調,達到接近真實值的目的[14]。相應的坐標參數回歸為:
(1)

3 改進的ST-Faster R-CNN算法
海上彈著點水柱信號具有尺寸變化大、形狀不規則的特點,原來的Faster R-CNN模型無法充分滿足檢測需求。因此,本文提出改進的ST-Faster R-CNN算法模型,以Swin Transformer作為新的骨干網絡,增強特征提取能力,同時在骨干網絡的最后1層與倒數第2層間進行深淺層特征信息的融合,采用多尺度特征圖對大小不一的目標物體的特征信息進行提取,可以有效改善漏檢誤檢的問題。
3.1 骨干網絡Swin Transformer
Transformer是一種主要基于自注意機制的深度神經網絡,最初應用于自然語言處理(natural language processing,NLP)任務,并帶來了顯著的改進[15],受其強大表示能力的啟發,許多研究人員正逐步將其擴展到計算機視覺任務。然而在應用過程中,transformer需要應對2個挑戰:一是圖像領域中實體尺度變化大,現有的Transformer架構中圖像塊(token)的尺度是固定的,無法適應大范圍變化的目標尺寸;二是圖像分辨率高,像素點多,自注意力機制會帶來龐大的計算量。為了克服上述問題,文獻[16]提出了Swin Transformer,如圖3所示。
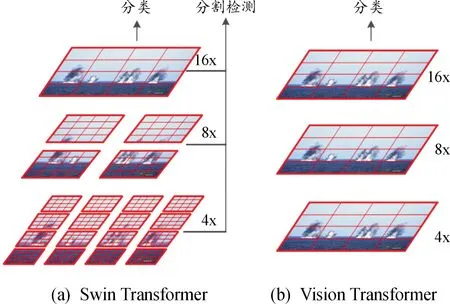
圖3 Swin Transformer與Vision TransfomerFig.3 Comparision of Swin Transformer and Vision Transfomer
針對問題1,Swin Transformer從最小的特征塊(patch)開始,通過逐層進行鄰域合并的方式構建多層級的特征圖,因此能夠方便地與密集預測網絡FPN、U-Net等配合使用;針對問題2,Swin Transformer利用滑窗操作將注意力限制在一個窗口中,使計算復雜度與輸入圖片線性相關。結合以上2點,Swin Transformer可以作為骨干網絡應用在目標檢測任務中。Swin Transformer的整體結構如圖4所示。
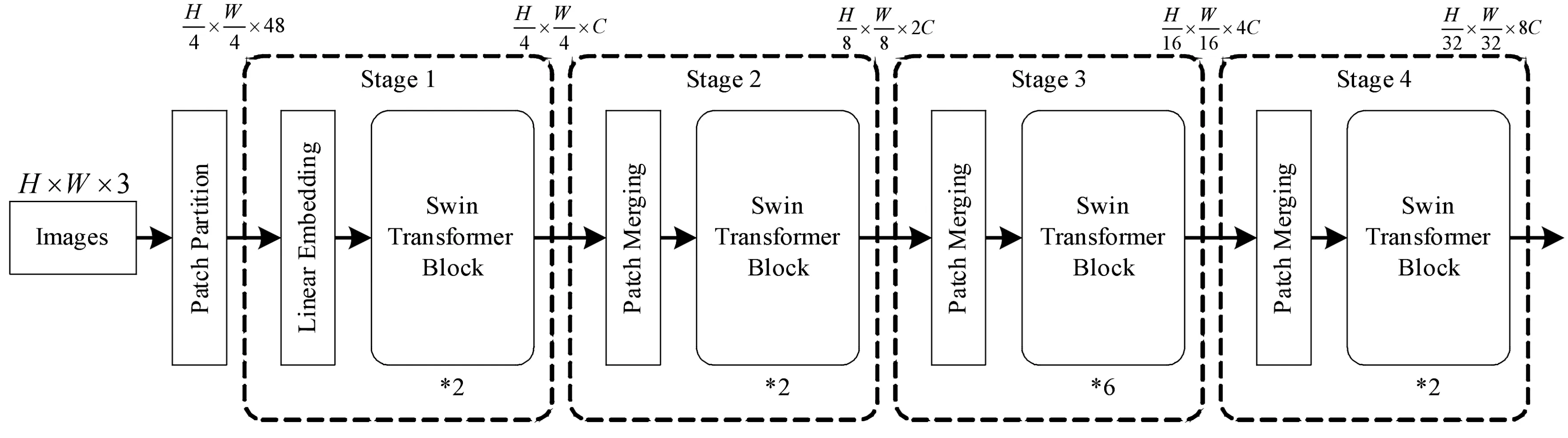
圖4 Swin Transformer整體結構框圖Fig.4 Swin Transformer structure
具體實現過程為:
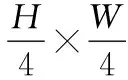
2) 在stage1中,線性嵌入(linear embedding)將每個圖像塊的特征維度變為C,然后送入Swin Transformer Block并對輸入特征進行計算;
3) stage2-stage4操作相同,通過圖像塊合并(patch merging)將2*2的相鄰圖像塊進行拼接,再經過卷積網絡對拼接后的4C維特征進行降維,因此圖像塊數量減少4倍,特征維度變為2C。
圖5為2個連續的Swin Transformer Blocks,包含了一個基于窗口的多頭自注意力模塊(windows multi-head self attention,W-MSA)和基于移動窗口的多頭自注意力模塊(shifted windows multi-head self attention,SW-MSA),實現不同窗口內特征的傳遞與交互,其中,Zl為第l層的輸出特征,在每個MSA模塊和每個多層感知器(multilayer perceptron,MLP)之前使用規范層(layer norm,LN),并在每個MSA和MLP之后使用殘差連接,其表示為:
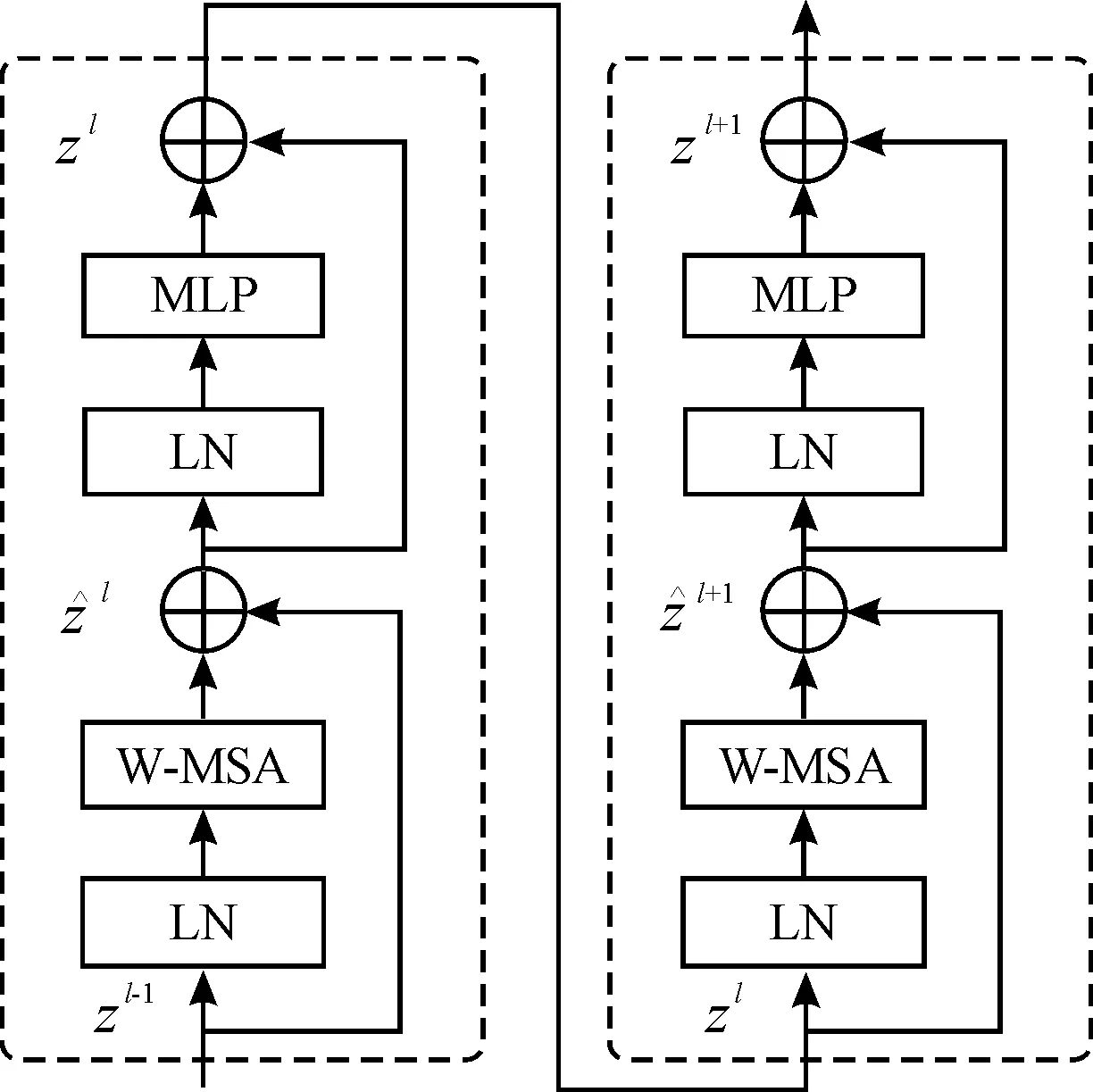
圖5 2個連續的Swin Transformer Blocks框圖Fig.5 Two consecutive Swin Transformer Blocks
(2)
(3)
(4)
(5)
為了解決自注意力帶來的龐大計算量的問題,Swin Transformer利用W-MSA將自注意力限制在不重疊的局部窗口中,利用SW-MSA中窗口的移動實現信息交互,如圖6所示,在第l層,采用常規的窗口分區方案,在每個窗口內計算自注意力,在下一層l+1中,窗口分區會被移動,產生新的窗口。新窗口中的自注意力計算跨越了l層中窗口的邊界,提供了新的關聯信息。
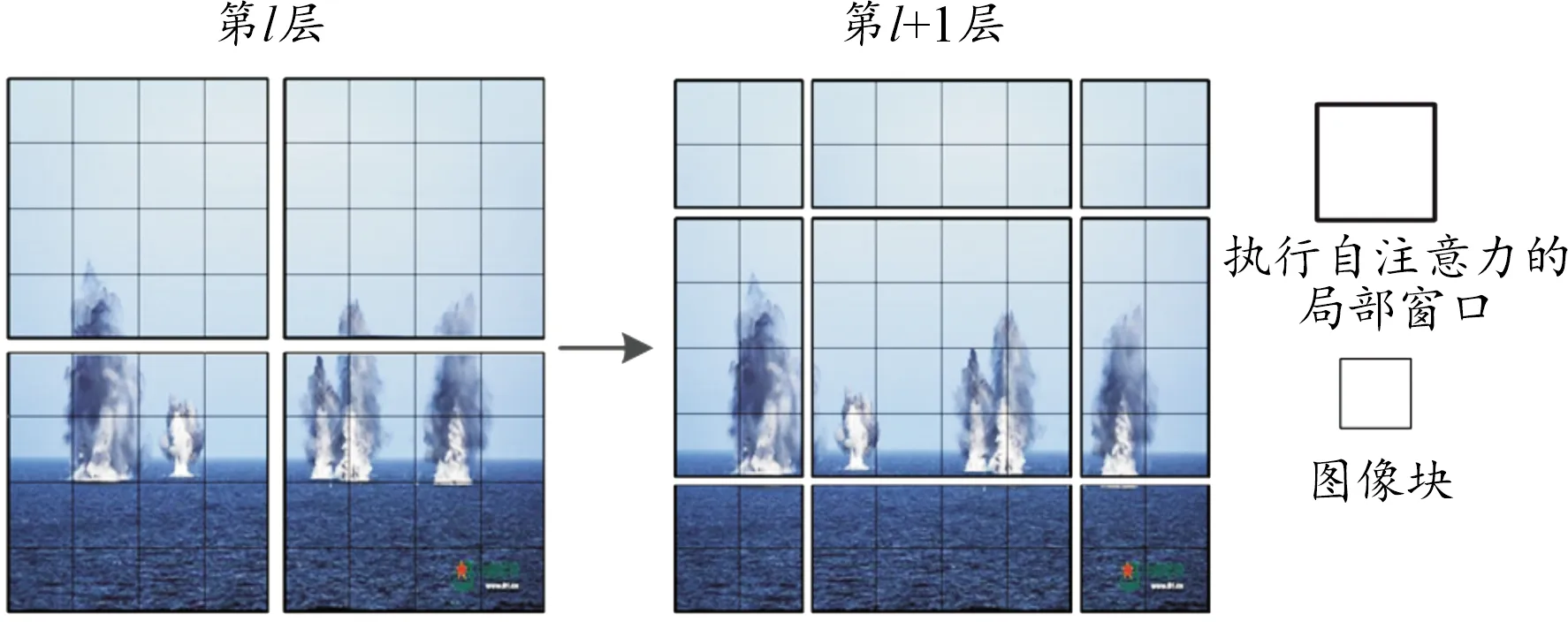
圖6 基于移動窗格的自注意力機制計算過程示意圖Fig.6 Self-attention mechanism based on moving panes
W-MSA將輸入圖片劃分成不重合的窗口,然后在不同的窗口內進行自注意力計算。假設一個圖片共有h×w個圖像塊,每個窗口中包含M×M個圖像塊,那么W-MSA的計算復雜度為:
Ω(W-MSA)=4hwC2+2M2hwC
(6)
由于窗口中包含的圖像塊數量遠小于圖片中圖像塊數量,因此在M固定的前提下,W-MSA的計算復雜度和圖像尺寸呈線性關系。
同時,為了解決窗口移動帶來的數量增加,提出了向左上角的循環移位操作(cyclic-shifting)解決方案。如圖7所示,通過對特征圖移位,組成一個可以處理的窗口,這個可處理的窗口是由幾個不相鄰的子窗口組成的,然后使用掩膜機制(mask mechanism)將自注意力在子窗口中進行計算,使得其在保持原有窗口個數下,獲得等價的計算結果。

圖7 基于circle shift的移動窗格計算過程框圖Fig.7 Calculation of moving panes based on circle shift
3.2 多尺度特征融合
原始的Faster R-CNN網絡中,由RPN根據原圖片的特征圖直接生成待檢測圖片的候選區域,而實際所需的特征圖是經骨干網絡提取特征后生成的,直接用來進行檢測會造成目標特征信息的遺漏。同時,Swin Transformer應用在Faster R-CNN網絡時必須對二者進行特征大小的匹配,在分析過程中,stage3輸出的特征圖尺寸滿足匹配要求,但淺層網絡提取的主要是細節特征,圖像的語義特征主要通過網絡更深層的stage4獲得。因此,選取Swin Transformer中最后2層輸出的不同尺度特征圖,利用上采樣和特征拼接后輸入到新的卷積模塊中,經RPN網絡生成檢測候選區域,不僅解決了特征大小匹配的問題,而且增強了網絡提取圖像特征信息的能力,具體融合結構見圖8。
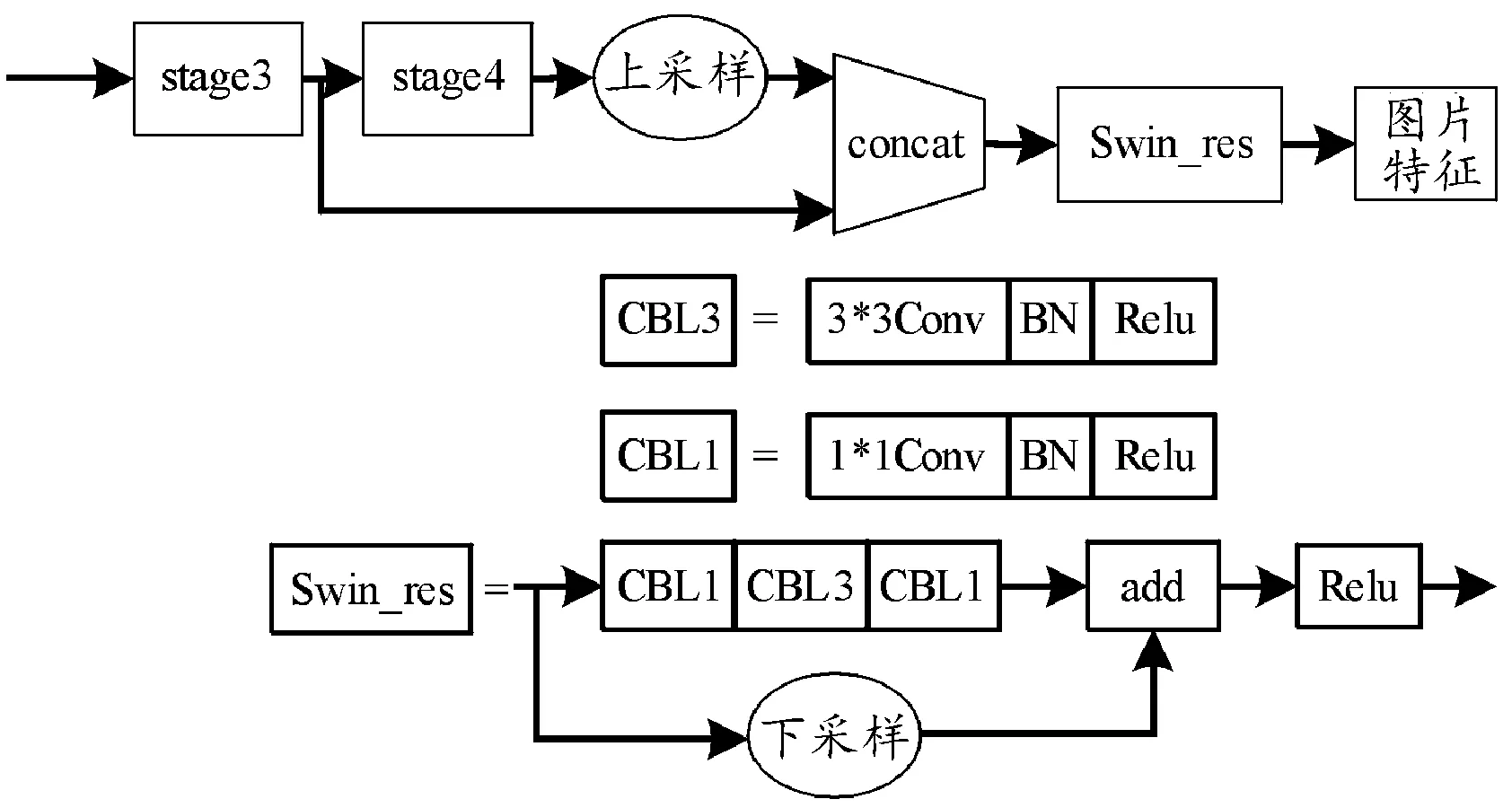
圖8 多尺度特征融合結構框圖Fig.8 Multi-scale feature fusion structure diagram
如圖8所示,在骨干網絡Swin Transformer結構中,將stage4輸出的特征圖進行上采樣,使之與stage3輸出的特征圖尺寸相同,進行特征拼接后輸入到新的模塊Swin_res中,加深網絡結構,提高網絡的泛化能力。同時,由于stage3位于較低層,提取到的信息大多是細節信息,stage4提取到的則是抽象語義信息。采用多尺度特征融合的方式可以提取到大小不一的目標的特征,從而改善漏檢誤檢的問題[17]。圖9為深淺層特征信息融合示意圖。
由圖9可以看出,相比于原來的stage4輸出的高層語義特征圖,經過特征拼接后的特征信息融合圖,其信息更加豐富,目標紋理及輪廓等細節信息展示得更加充分。

圖9 深淺層特征信息融合示意圖Fig.9 Deep and shallow layer information fusion feature diagram
3.3 改進后的ST-Faster R-CNN
由3.1節和3.2節可知,改進后的ST-Faster R-CNN網絡結構如圖10所示。
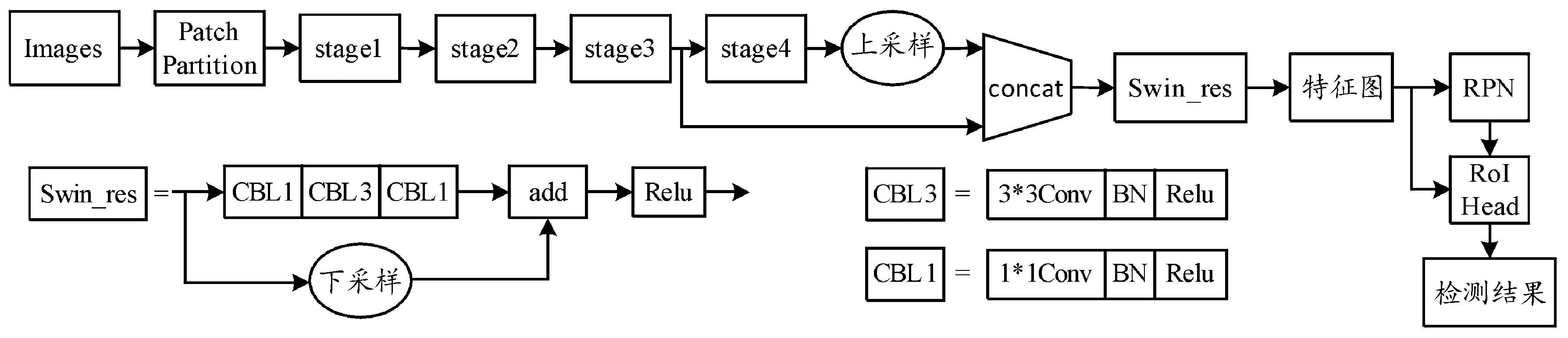
圖10 改進后的ST-Faster R-CNN網絡結構框圖Fig.10 Improved ST-Faster R-CNN network structure diagram
網絡進行目標檢測的整體實現流程為:
1) 準備數據,制作數據集并劃分訓練集、測試集;
2) 加載網絡初始化參數;
3) 加載網絡模型,進行特征提取與定位,并利用Adam優化器對各項參數進行優化;
4) 在每一輪訓練結束后計算當前模型的損失函數值,并及時存儲訓練好的模型,選擇效能更好的模型,調參后繼續訓練,直至訓練的最后一輪;
5) 訓練結束后得到本次訓練的所有模型,選擇最佳模型作為最后輸出。
4 實驗設置
4.1 實驗環境
本文利用的深度學習框架為Pytorch,實驗環境為Ubuntu18.04、CUDA11.1,所有網絡模型的訓練與測試均在CPU為Intel(R) Xeon(R) Silver 4210R CPU@2.40GHz、GPU為Geforce RTX 3090Ti的工作站上進行。
4.2 網絡訓練
本文數據集主要來自公開的海上演習或訓練任務的圖片,由于海上彈著點水柱信號搜集比較困難,利用遷移學習[17]中實例遷移的思想,將與彈著點處水柱信號具有相似特征的噴泉作為正樣本輔助訓練,共得到744幅圖片,再通過旋轉、變換飽和度等方式,最終擴充為2 200幅新的樣本數據集,將其轉化為VOC格式進行訓練,其中訓練集與測試集的比例為8∶2。
訓練過程中,實驗學習率采用StepLR機制對學習率進行更新,優化器optimizer采用Adam,其余訓練參數如表1所示。
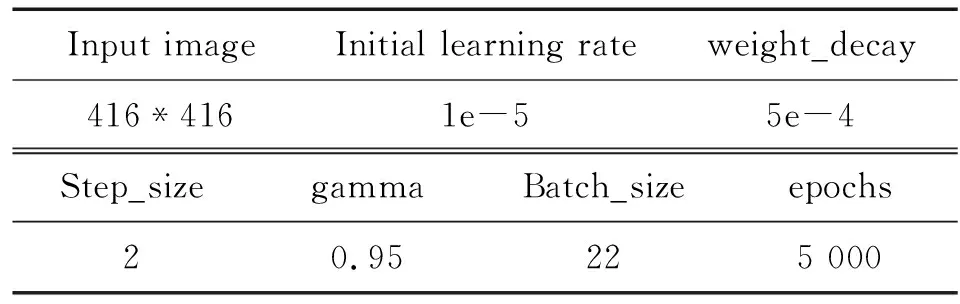
表1 訓練參數Table 1 Training super parameter setting
在訓練過程中記錄模型的損失函數曲線如圖11。由圖11可以看出:該模型在2 000次迭代訓練之后損失值漸趨平穩,經過5 000次迭代后訓練后損失值大概穩定在1.1左右,參數收斂性較好,且由于改進后的網絡結構增加了多尺度特征圖,從而引入了額外的參數,為了避免繼續訓練會產生模型過擬合的問題,因此在訓練至5 000輪時停止訓練,得到最終模型。
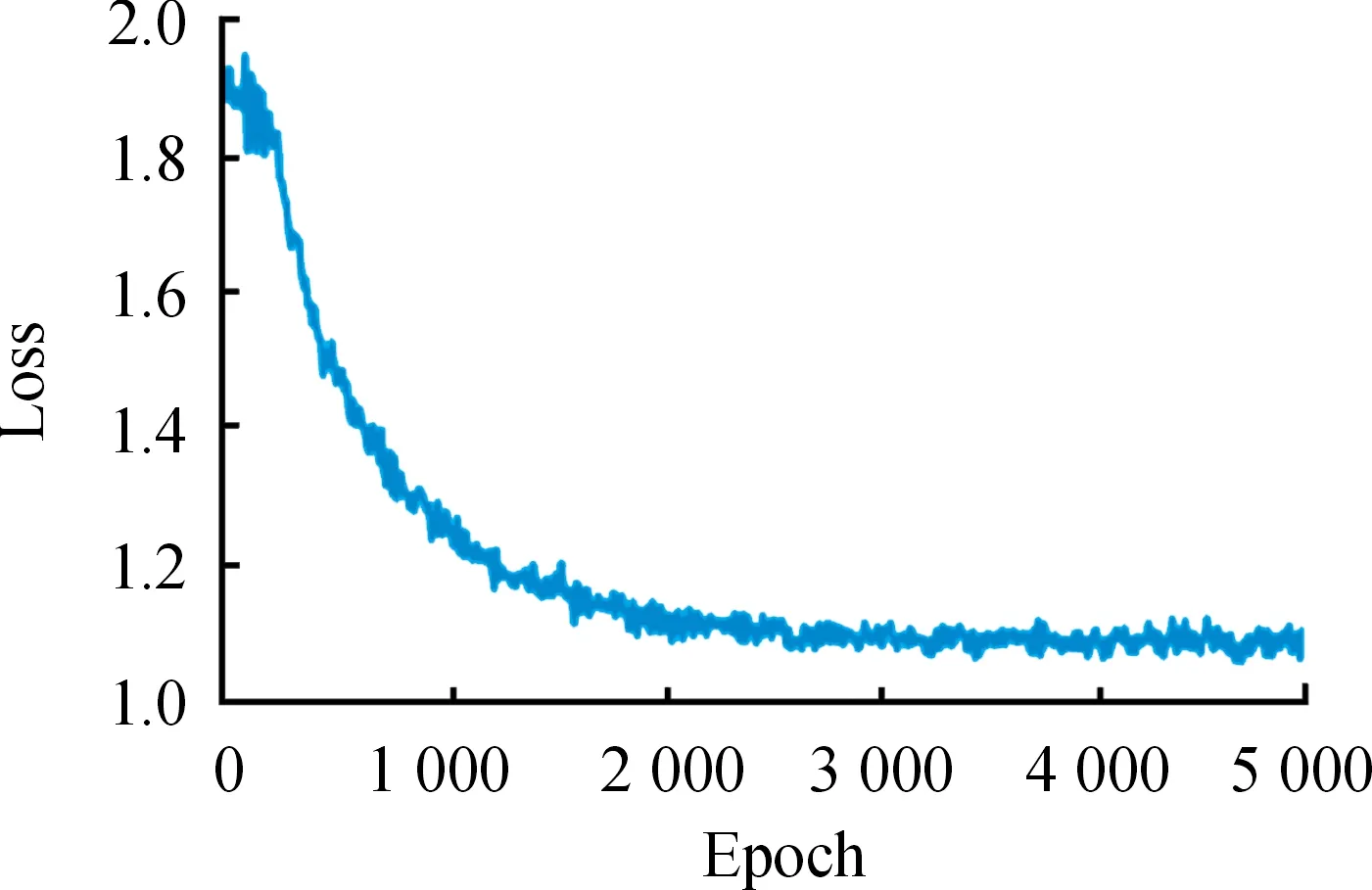
圖11 ST-Faster RCNN損失函數曲線Fig.11 ST-Faster R-CNN loss function curve
4.3 算法改進前后模型評估對比
在對模型進行評估前,需要選擇合適的評估指標。在本文中,實驗結果從準確率(precision)、召回率(recall)、平均準確率(mean average precision,mAP)、每秒處理幀數(frame per second,FPS)等4個方面進行綜合衡量,各項指標的具體計算方法如下:
召回率R表示預測目標中預測正確占總預測樣本的比例,準確率P表示某一類別預測目標中預測正確占總正確樣本的比例,其定義公式分別為:
(7)
(8)
對于二元分類問題,其標記類與預測類的判斷結果有TP、FP、TN、FN等4種,如表2所示。
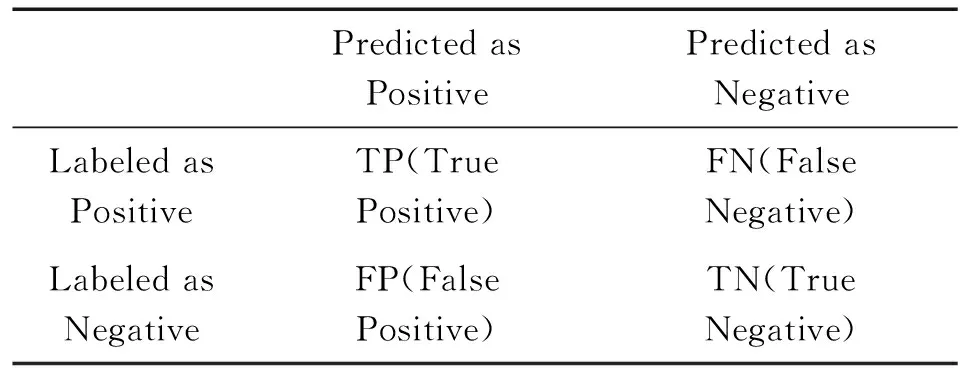
表2 標記類與預測類判斷結果Table 2 Confusion Matrix
平均準確率的均值mAP通常用來評估一個檢測算法的檢測準確度,數值越大檢測效果越好。由于準確率與召回率是一對相互矛盾的指標,因此通常采用召回率與準確率所圍成的R-P曲線面積作為最優解,用平均準確率AP衡量。AP和mAP計算公式為:
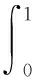
(9)
(10)
式(10)中,N為檢測的類別數。本次實驗中,由于目標類別只有一類,因此mAP值等于AP值。由實驗得知,改進前的mAP值為91.68%,改進后的mAP值提升了4.5%,達到了96.18%,其R-P曲線如圖12所示,模型算法的各項性能如表3所示。
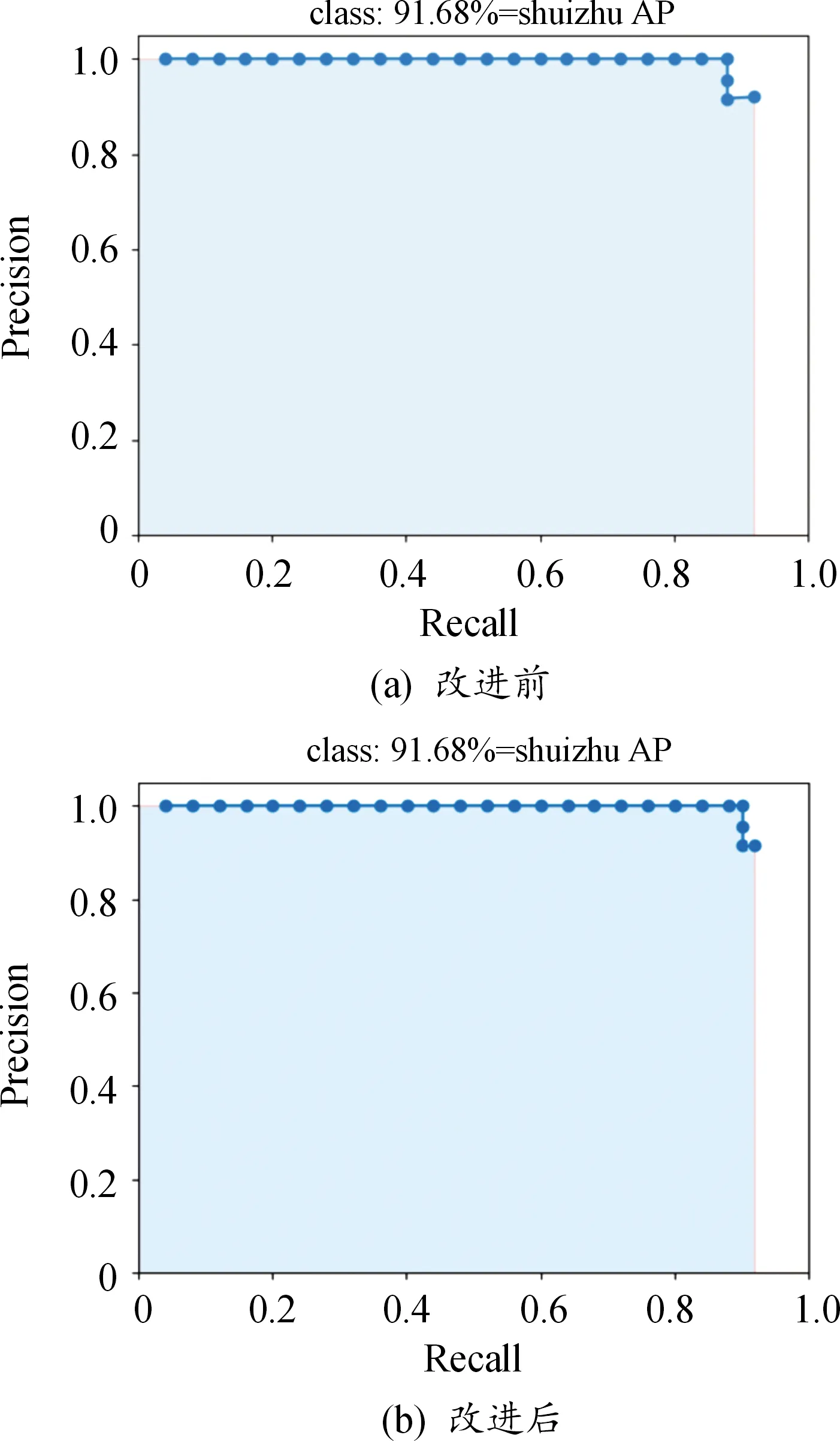
圖12 改進前后R-P曲線Fig.12 Loss function curve before and after improvement

表3 模型算法性能Table 3 Performance comparison of the algorithm
由表3可以看出,改進后的ST-Faster R-CNN模型在準確率、召回率、平均準確率和FPS值方面均有不同程度的提高,在提高檢測精度的同時,改善了漏檢和誤檢的問題。且FPS值提高了8.92幀/s,達到了18.57幀/s,大大改善了two-stage算法檢測速度慢的問題,說明改進后的模型整體效能有較大提高,運用在海上彈著點水柱目標檢測任務中效果更好。
圖13(a)、圖13(b)分別為原Faster R-CNN模型和改進后的ST-Faster R-CNN模型對部分樣本的檢測效果。由于在改進后的ST-Faster R-CNN模型中增加了多尺度特征融合機制,因此在進行目標檢測任務時,原算法中的錨框尺寸不能完全適用于多尺度特征圖,但依舊可以根據準確識別出目標中心點并畫出預測框,對目標的定位效果幾乎沒有影響。對于原前3幅圖片中的水柱信號其在角度、大小、形狀方面有較大差異,由此可以看出,改進后的ST-Faster R-CNN模型對檢測目標的置信度得分均有不同程度的提高,達到了接近滿分的水平;第4幅圖片是圖片中出現多目標時的情況,雖然錨框尺寸出現了較大程度的偏差,但預測框得分依舊有明顯提高,且定位效果比較準確,說明改進后的模型檢測效果更好。

圖13 改進前后部分樣本檢測結果圖Fig.13 Comparison of test results of some samples before and after improvement
4.4 消融實驗與不同算法檢測能力對比
為了進一步驗證本文提出改進措施的有效性及網絡的高效性,設計了消融實驗,并將其與其他經典網絡進行對比,選取平均準確率mAP和每秒處理幀數FPS作為檢測算法的評價指標,得到消融實驗結果如表4所示,不同算法實驗結果如表5所示。
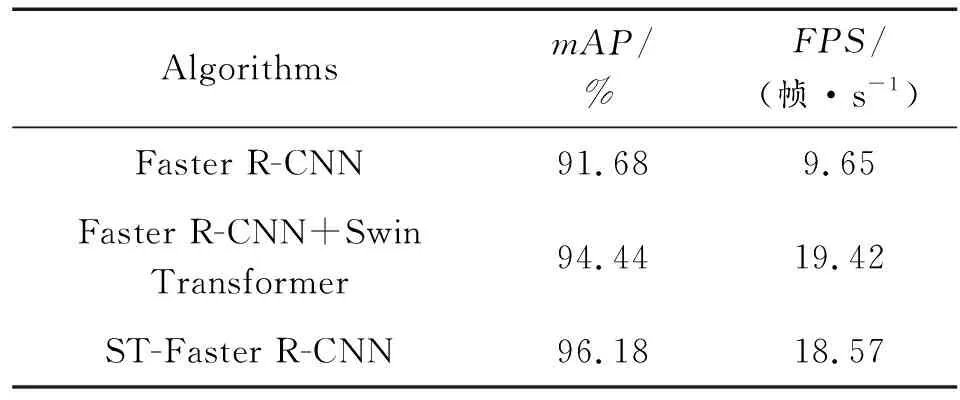
表4 消融實驗Table 4 Comparison of ablation experiments
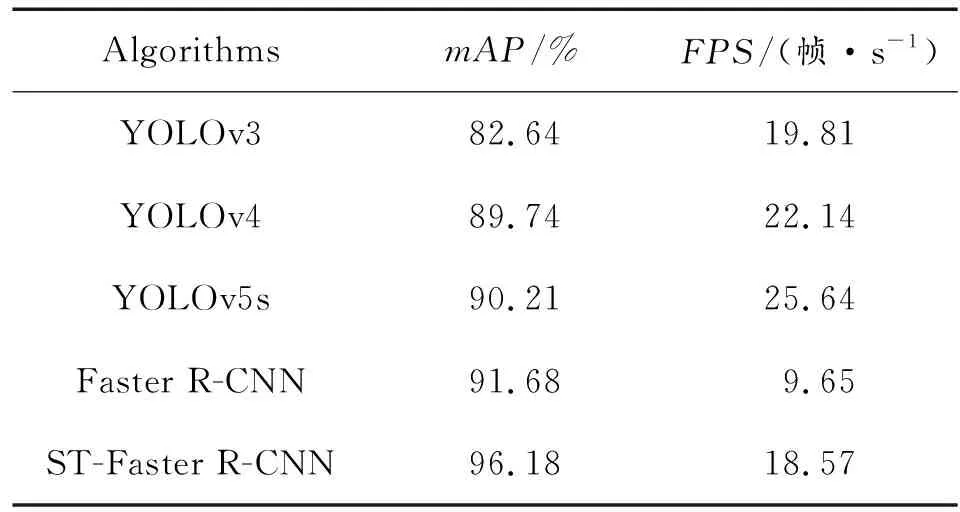
表5 不同算法實驗結果Table 5 Experiment comparison of different algorithms
考慮到特征大小匹配問題,在表4中,Faster R-CNN+Swin Transformer表示將stage3輸出的特征圖直接應用到Faster R-CNN中得到的網絡結構。由于本文提出的多尺度特征融合建立在Swin Transformer骨干網絡上,因此沒有作為單獨的一項消融實驗。通過實驗結果可以看出,引入Swin Transformer骨干網絡后,mAP值提高了2.76%,達到了94.44%,FPS值更是增長到了19.42幀/s,有力證明了新的骨干網絡在目標檢測領域的突出優勢。在進一步引入多尺度特征融合措施后,由于對圖像的深淺層特征信息進一步提取和融合,檢測準確率得到進一步提高,到達了96.18%,但伴隨網絡結構的加深,其計算量也隨之增加,因此檢測速度略有下降。
由表5可知,one-stage算法中隨著YOLO系列算法不斷改進,其檢測結果的平均準確率和檢測速度不斷提高,two-stage算法Faster R-CNN的檢測精度較高,但檢測速度最慢,無法滿足實時性要求。本文提出的ST-Faster R-CNN算法平均準確度比YOLO V5s高出5.97%,同時極大地提升了檢測速度,雖然不如YOLO V5s,但FPS值已經達到18.57幀/s,極大地弱化了檢測速度慢的劣勢,基本達到水柱目標檢測的速度要求。通過實驗證明,改進后的ST-Faster R-CNN在滿足目標檢測速度要求的前提下,準確率優勢明顯,算法綜合性能更好,可以更好地完成海上彈著點水柱信號目標檢測任務要求。
5 結論
1) 利用Swin Transformer作為新的骨干網絡,通過對圖像分塊并逐層合并的方式實現層次化,利用移動窗口將自注意力限制在一定范圍內,大幅度削減了計算量的同時,實現了非局域窗口間的交互,滿足了目標檢測任務中對骨干網絡的要求,同時擁有更高效的特征提取能力;
2) 運用多尺度特征融合的方式,將深淺層特征信息進行融合,加深網絡結構,增強了水柱特征在網絡層之間的傳播和利用效率;
3) 改進后的Faster R-CNN算法模型平均準確率達到96.18%,速度達到18.57幀/s,不僅進一步提高了two-stage算法的檢測準確率,而且大幅提高了目標檢測速度,可以更好地完成海上彈著點水柱目標檢測任務。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
