基于B-CNN模型的異構網絡大數據知識擴充算法研究
2022-07-10 10:00:44張偉華王海英
兵器裝備工程學報 2022年6期
張偉華,王海英
(鄭州商學院 信息與機電工程學院, 河南 鞏義 451200)
1 引言
異構網絡大數據存在多元性與分布式傳播等特性,因此降低質量較差數據干擾屬于數據知識工程急需解決的問題,對數據傳播時的數據知識庫重建關注度越來越高。數據知識擴充數據解決該問題的有效途徑。李直旭等人通過屬性與屬性值的共現關系實現數據知識擴充,應堅超等人以集合論內互逆/對稱關系為核心思想,提出關系統計的知識擴展方法,上述2種方法均可有效實現知識擴充,但擴充效果并不理想,原因是這2種方法無法剔除無效數據,導致擴充效率較低。雙線性卷積神經網絡(bilinear convolution neural networks,B-CNN)通過兩路VGGNet組建而成,可增強特征表達效果,完成端到端訓練的預測分類,具備較優的分類效果;為此研究基于B-CNN模型的異構網絡大數據知識擴充算法,利用B-CNN模型提取有效三元組,剔除無效數據,降低質量低下數據的干擾,提升知識擴充效果。
在B-CNN各個特征通道內引進比例因子,結合正則化激活方式構建稀疏層,實現通道篩選,根據比例因子的大小衡量特征通道的重要性,裁剪掉重要程度較低的通道,實現B-CNN模型的改進,避免網絡過分擬合,增強提取特征的顯著性;利用改進B-CNN構建異構網絡大數據知識表示模型,在三元組矩陣內,通過維度變換方式增加卷積滑動窗口的滑動步數,在不同維度中,提高該矩陣中實體與關系的信息共享作用,獲取不同維度中三元組的全部信息=(,,),其中,異構網絡大數據實體集是,知識描繪對象是,內全部元素的知識屬性集是;利用可變粒度策略處理(,,),實現異構網絡大數據知識擴充。
2.1 基于B-CNN的異構網絡大數據知識表示模型
..BCNN模型
B-CNN的輸入是,利用2個特征提取網絡與,依據卷積核展開卷積操作獲取特征提取函數與,利用外積方式匯聚與,再通過求和池化獲取雙線性特征,傳輸至內積層展開預測。與內各個卷積層均會設置Relu激活函數,公式如下:
()=max(0,)
(1)
B-CNN的主要部分通過三元組=(,,)組成,與屬于一種函數映射∶×→×,輸入的的位置信息是,維度是×;池化函數是;將與映射為×維的特征×,經由外積方式匯聚與的輸出特征,獲取雙線性特征,公式如下:
(,,,)=(,)(,)
(2)
其中,∈,∈。
的作用為將全部位置的特征融合為一個總特征,公式如下:
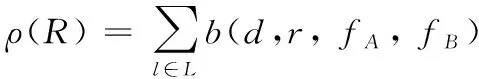
(3)
令與提取的特征維度分別是×與×,因此輸出的矩陣為×。
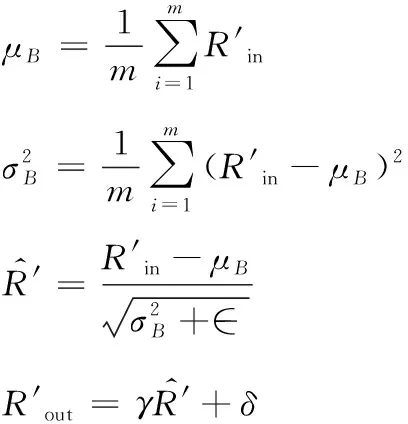
(4)
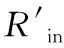
通過引進稀疏懲罰項,調整的稀疏程度,引進位置為訓練目標函數,的表達公式如下:
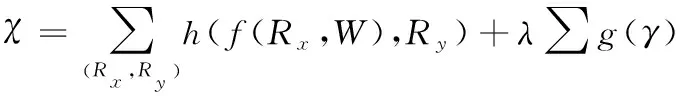
(5)
其中,訓練權重是;輸入數據實體集與真實標簽是(,);調整稀疏程度的參數是;正則化操作是(·);交叉熵損失函數是,表達公式如下:
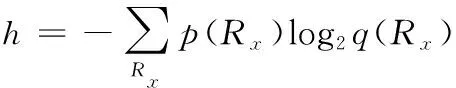
(6)
其中,的精度值是();的預測值是()。
通道稀疏處理后,改進B-CNN網絡內存在很多與零接近的,裁剪掉這些完成通道的修剪,在修剪時設置一個閾值,避免出現過擬合現象;改進B-CNN整體是有向非循環圖,僅需求解特征提取網絡梯度便能實現網絡訓練。
利用改進B-CNN構建異構網絡大數據知識表示模型,該模型的作用是利用改進B-CNN學習、訓練并輸出各個三元組(,,)的科學性的打分函數′(,,),科學的(,,)知識得分不得低于不科學的(,,)知識得分。令改進B-CNN構成的有向非循環知識圖譜為=(,),關系集是;知識表示模型將與描繪為維向量空間內的向量,各個三元組下向量為(,,),將(,,)融合為一個三列矩陣=[,,]∈×3,利用知識表示模型以維度變換方式變更,獲取=×,其中×=×3,知識表示模型將輸入改進B-CNN的與網絡內卷積層,利用卷積操作,再經由外積方式與求和池化操作,提取(,,)的雙線性特征。令的集合是,的數量是=||,令獲取的特征矩陣維度是×。利用知識表示模型向量化處理×,獲取向量∈×1。乘上權重矩陣×,并映射至維向量空間內,再和權重向量∈×1內積獲取(,,)的打分。知識表示模型的′(,,)表達公式如下:
′(,,)=((*))×·
(7)
其中,卷積操作是“*”;內積操作是“·”;向量化操作是;非線性函數是;通過式(7)獲取有效三元組。
Adam優化器最小化損失函數,實現知識表示模型內參數的訓練,的計算公式如下:


(8)
其中,(,,)是常數,取值為1或-1;有效與無效三元組集合為、′,當(,,)∈時,(,,)=1,當(,,)∈′時,(,,)=-1;利用內各個(,,)的頭實體或尾實體任意更改成其余實體獲取′。
2.2 可變粒度的知識擴充算法
利用可變粒度策略對21小節獲取的有效三元組=(,,)展開知識擴充。令?∈,?∈,線性關系屬性映射為:→,內隨機一個元素的知識屬性映射關系為。令粗糙權重是;多粒度粗糙知識工程為;則粗糙的知識工程是=(,∩(),∪)。

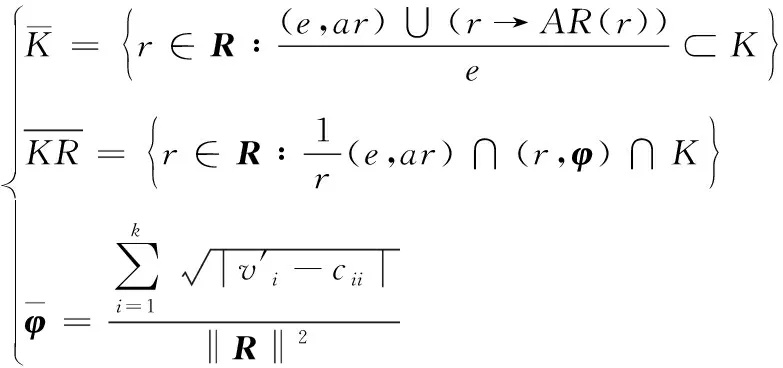
(9)
針對,基于可變粒度設計知識的參數與屬性,表達公式如下:

(10)

可變粒度更換方程如下:
=(×sin+×cos)(,,)
(11)
其中,可變粒度是;的多維向量空間水平交叉弧度是;在空間降維時形成的垂直交叉弧度是。
和知識工程的迭代關系如下:
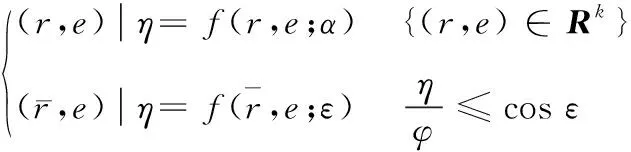
(12)


(13)
3 實驗分析
為驗證本文算法的有效性,通過15臺計算機構建一個實驗集群,每臺計算機的內存是16 GB,硬盤存儲空間是2 T。異構網絡數據知識庫空間配置如下:
利用nginx安裝1個中心節點與14個處理節點,通過處理節點完成差異化服務,該數據知識空間屬于內部局域網,通過Oracle Load Test軟件仿真大量并發請求,將JetBrains WenStorm/VS Code當成開發環境,操作系統是CentOS 7.3,各節點的聯絡方式是千兆以太網,令數據知識發送請求的時間是70 s。建立兩路VGGNet,通過維度變換增加進行卷積操作提取特征函數進行計算,獲取不同維度中三元組矩陣的信息,經由求和池化操作,實現B-CNN模型的應用。圖1為B-CNN模型網絡結構示意圖。
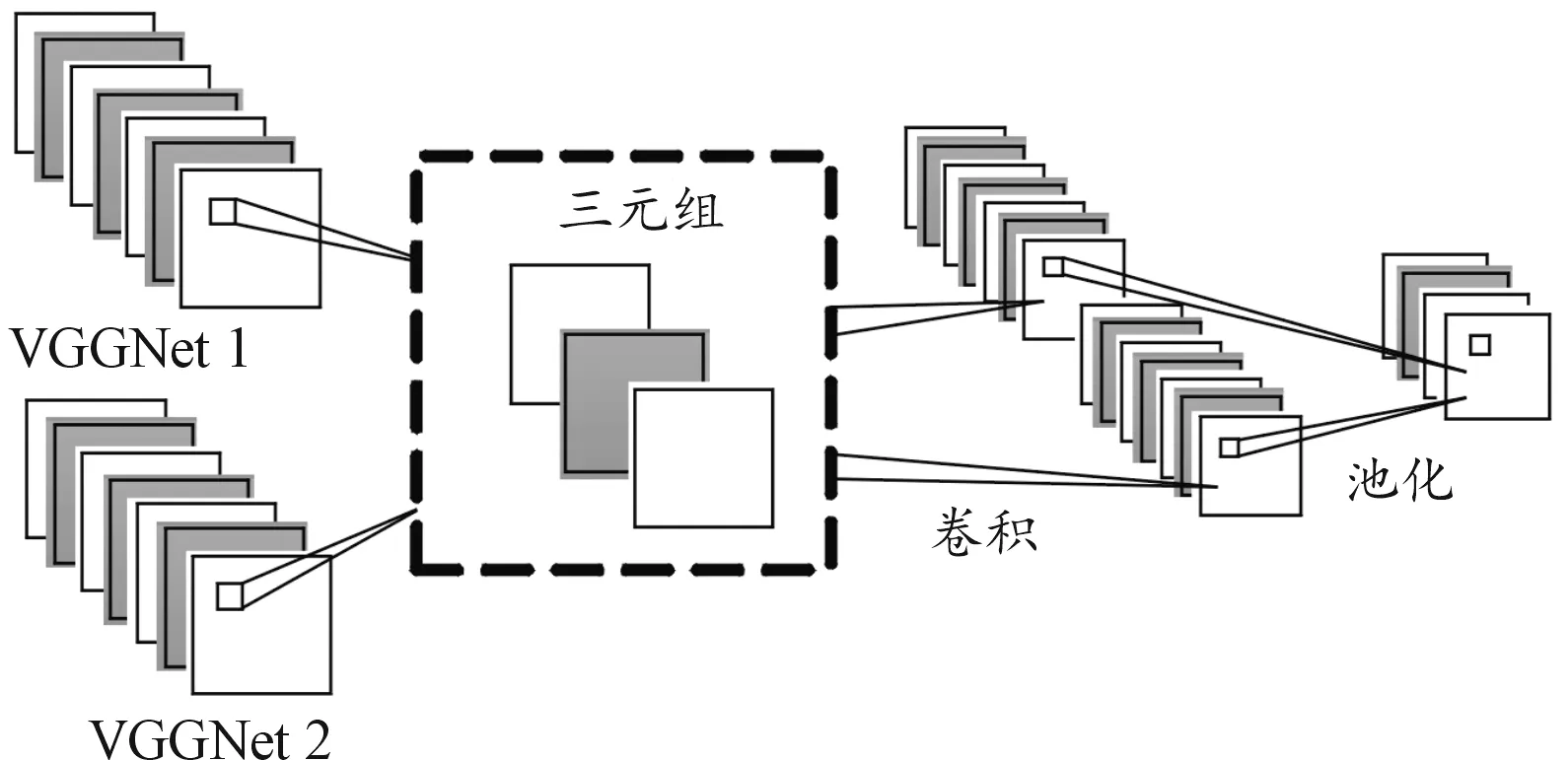
圖1 B-CNN模型網絡結構示意圖Fig.1 B-CNN Model network structure
將平均排名(Mean Rank,MR)與前8名存在預測準確三元組的比例(Hits@8)作為評價本文算法中知識表示模型有效性的指標,MR指三元組集合的平均排名;MR低或Hits@8高說明本文算法的知識表示效果較優。調整稀疏程度參數過大或過小均會影響知識表示模型的效果,當過大時,會導致大量知識特征被抑制,造成獲取有效三元組的精度較低;當過小時,會導致比例因子失去意義,無法篩選特征通道;一般情況下的取值為10≤≤10;利用本文算法獲取異構網絡數據庫內的有效三元組,完成數據知識表示,測試本文算法在不同的取值時的MR與Hits@8,測試結果如圖2與圖3所示。

圖2 MR測試結果曲線Fig.2 Mr test results

圖3 Hits@8測試結果曲線Fig.3 Hits@8 test result
根據圖2與圖3可知,隨著訓練周期的不斷增加,在不同取值時本文算法的MR逐漸下降,Hits@8逐漸提升;當=10時,MR的收斂速度最快,在訓練周期為20時趨于平穩,最終的MR值也顯著低于其余2種取值;=10時的收斂速度雖快于=10,在訓練周期為30時趨于平穩,但最終MR值卻高于=10時的MR值;當λ=10時,Hits@8的收斂速度依舊最快,在訓練周期為20時趨于平穩;=10與=10時的收斂速度較慢,分別在訓練周期為40、50時趨于平穩,且最終Hits@8值顯著低于=10時最終Hits@8值;綜合分析可知,當=10時,MR值最低且Hits@8值最高,因此,此時本文算法的知識表示效果較優。

表1 NMI與ARI測試結果曲線Table 1 NMI and Ari test results
根據表1可知,在不同數據集中,本文算法的NMI與ARI隨著細粒度閾值提升出現先提升后下降的趨勢,且在擴充不同數據集時,本文算法的NMI值與ARI值均較高,與1較為接近,說明本文算法具備較優的知識擴充效果;綜合分析細粒度閾值為0.4時,本文算法在擴充不同數據集知識時的NMI與ARI值最高。實驗證明:本文算法具備較優的知識擴充效果,且細粒度閾值為0.4時,知識擴充效果最佳。
測試本文算法在擴充上述3個數據集知識時,隨著處理節點增加,該算法完成知識擴充所需的迭代次數,驗證本文算法的收斂效果,測試結果如圖4所示。
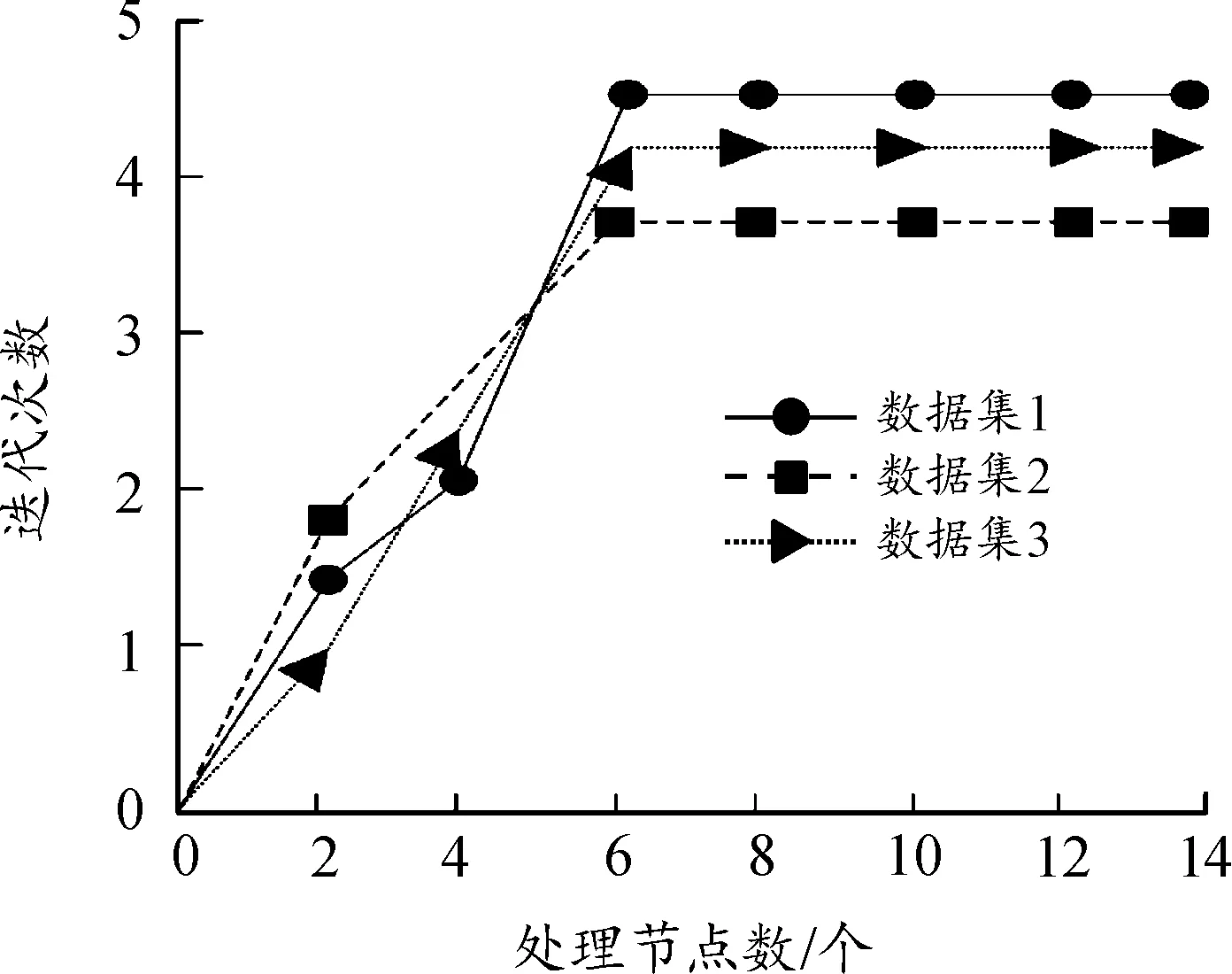
圖4 收斂效果Fig.4 Convergence effect
根據圖4可知,在擴充不同數據集的知識時,隨著處理節點數量的提升,本文算法的迭代次數逐漸上升,在節點數達到6個以上的時候,迭代基本維持在5次以下,并且不再有上升趨勢,原因是本文算法通過粒度可變調度處理粗粒度數據,并展開降維處理,確定不確定性的線性描繪,去掉不確定性的數據,降低知識獲取迭代次數,提升知識獲取效率,迅速完成數據知識擴充。
4 結論
1) 利用B-CNN構建知識表示模型,獲取異構網絡大數據的有效三元組,通過可變粒度策略對有效三元組展開知識擴充。
2) 所提出算法可增強知識擴充效果,提升知識獲取效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
