基于多層雙向長短時記憶網絡的水聲多載波通信索引檢測方法
2022-06-25 08:28:46朱雨男解方彤張明亮葛慧林
電子與信息學報 2022年6期
朱雨男 解方彤 張明亮 王 彪 葛慧林
(江蘇科技大學電子信息學院 鎮江 212100)
1 引言
水聲信道的復雜多徑和時變空變特性對實現穩健的高速率水聲通信提出了巨大挑戰。以正交頻分復用(Orthogonal Frequency Division Multiplexing,OFDM)[1]為代表的水聲多載波調制技術頻帶利用率高且能有效抵抗頻率選擇性衰落,其諸多的衍生調制方式如正交信號分割復用[2]、濾波器組多載波(Filter Bank MultiCarrier, FBMC)[3,4]、索引調制OFDM[5,6]等均已成為水聲通信領域的研究熱點。
索引調制技術最初用于多輸入多輸出系統對空域中的激活天線進行選擇,文獻[7]將其應用到頻域來控制激活的子載波位置,增加了活躍子載波間的稀疏性,進一步降低了頻率偏移帶來的影響。文獻[8]將索引調制與FBMC聯合(Index Modulated FBMC, FBMC-IM),一方面充分利用了原型濾波器組優良的時頻聚焦特性來減少帶外輻射、抵抗符號間干擾和載波間干擾,另一方面靜默子載波的存在也削弱了FBMC系統中時頻格點1階鄰域內的固有虛部干擾。但由于發送端將部分數據比特作為索引比特來激活子載波,FBMC-IM系統在均衡后需對活躍子載波的位置進行檢測,在恢復信號時引起誤碼的形式包括子載波星座符號映射錯誤和活躍子載波位置檢測錯誤。針對后者,目前常用能量檢測(Energy Detection, ED)、最大似然(Maximum Likelihood, ML)和對數似然比(Log-Likelihood Ratio, LLR)算法進行檢測[5]。ML檢測對所有可能出現的子載波位置映射組合進行窮舉;LLR檢測通過計算最大后驗概率來進行判別,后驗概率的值越大則被看作活躍子載波的可能性越大。近年來隨著大數據和人工智能技術的發展,神經網絡廣泛用于調制識別[9]、信道建模[10]和信號恢復[11,12]等,其不需要嚴格定義的模型就可以處理模糊信息或逼近非線性曲線,在信號處理領域具有很好的應用前景。文獻[10]將條件生成對抗網絡引入自編碼網絡通信系統中模擬信道所帶來的影響,連接了發送端的編碼網絡和接收端的譯碼網絡,實現端到端的智能通信。文獻[11]將卷積神經網絡引入水聲多載波通信接收端實現信道估計和信號檢測,相比傳統的最小二乘估計和基于全連接網絡的接收機,深度模型具有更好的特征提取效率和系統誤碼率性能。文獻[12]通過兩個級聯的子網絡將信道估計和均衡過程加入到樣本數據預處理中,相比前者“強解調”式的直接輸出所預測的發送比特,提升了深度學習方法的可解釋性。
將深度學習應用到水聲通信系統的理念剛剛起步[13],針對索引調制中的活躍子載波位置檢測問題,本文提出一種基于雙向長短時記憶網絡(Bidirectional Long Short-Term Memory, BLSTM)的水聲FBMC-IM索引檢測器,自動獲取活躍子載波位置信息特征,采用數據驅動的方式判定系統子載波的活躍狀態,提高檢測精度。將均衡后的分組載波序列作為特征向量,利用one-hot編碼思想設計該組對應的標簽向量,送入BLSTM網絡進行離線學習和在線檢測。
2 水聲FBMC-IM通信系統
2.1 系統模型

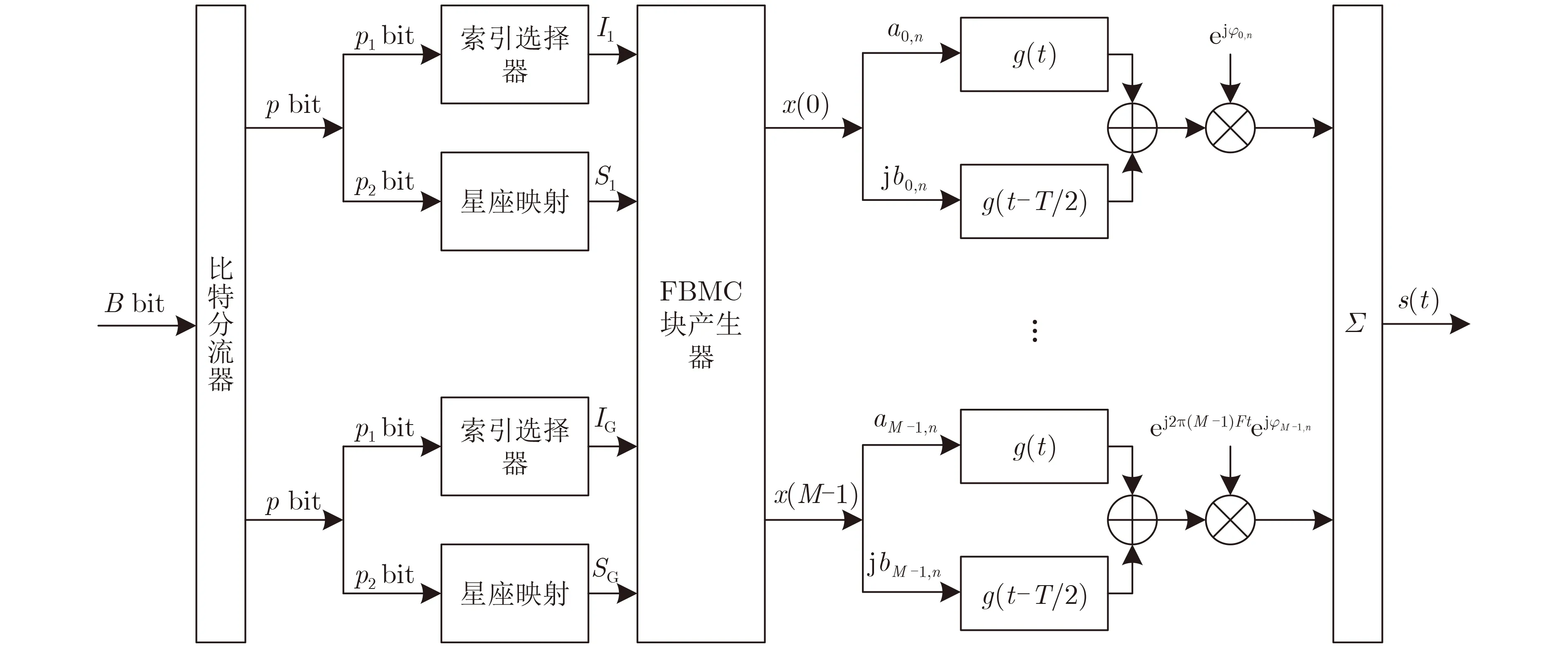
圖1 FBMC-IM系統發送端框圖

2.2 檢測算法


3 基于BLSTM的索引檢測
3.1 網絡模型


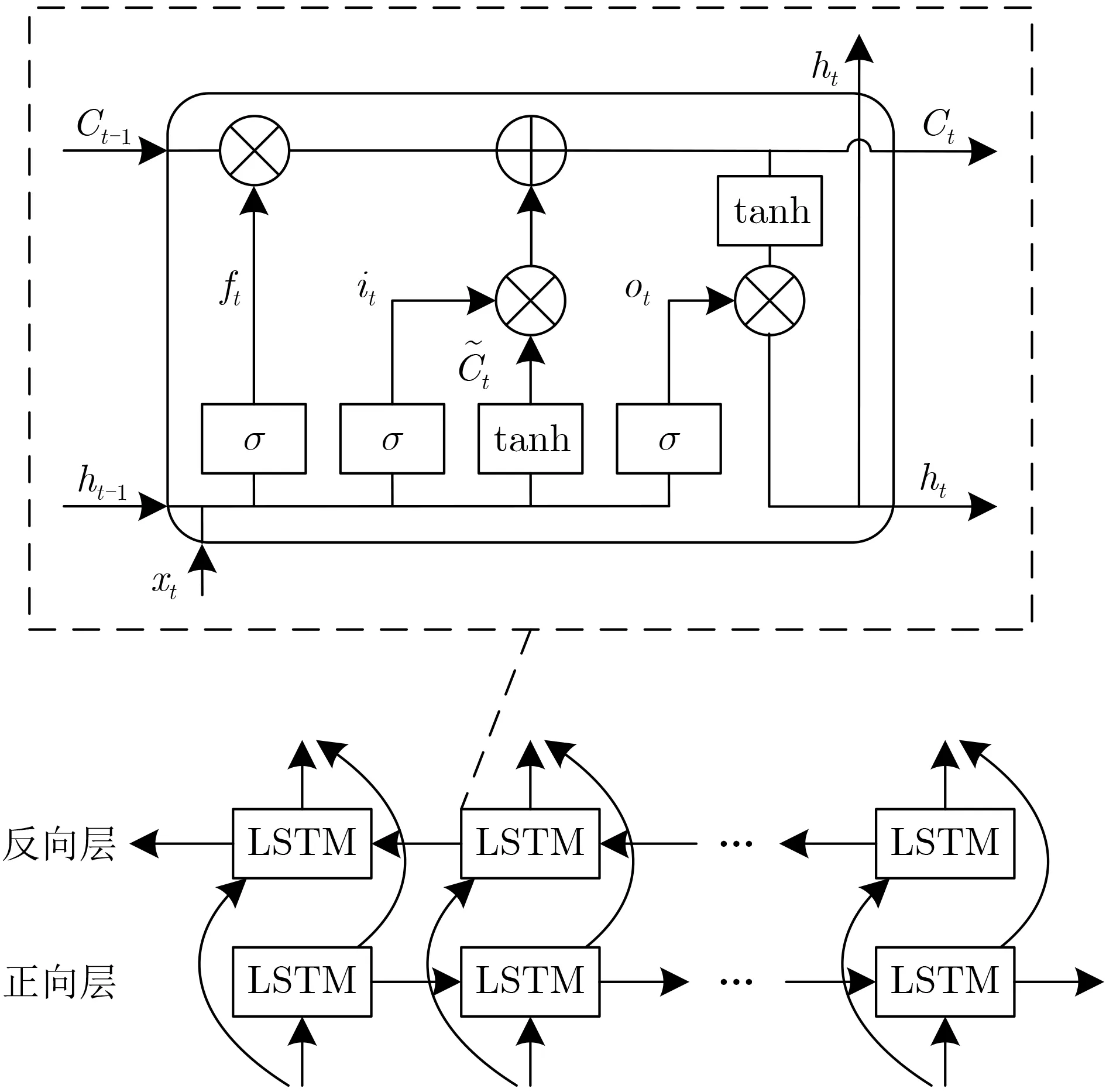
圖2 BLSTM結構圖

3.2 索引檢測器構建
與ML算法相似,均衡后的數據yg一方面經過BLSTM檢測活躍子載波位置,另一方面通過符號譯碼器計算出星座比特誤碼率。以(K,L)=(4,2)為例,共有6種活躍子載波組合可供選擇,若選用其中組合C1~C4,索引調制的映射關系如表1所示,經one-hot編碼后形成 1 ×4的標簽矩陣。圖3所示網絡結構由多個BLSTM隱藏層、1個全連接輸出層級聯而成,輸出層采用softmax激活函數,輸出結果是一個4維的概率陣。將yg與對應的one-hot標簽作為一組輸入輸出數據來訓練BLSTM網絡,通過反向傳播算法不斷減小輸出值與標簽值之間的誤差。本文中采用多分類問題下的交叉熵損失函數來衡量網絡輸出與真實標簽間的誤差

表1 ( K,L)=(4,2)索引調制映射表
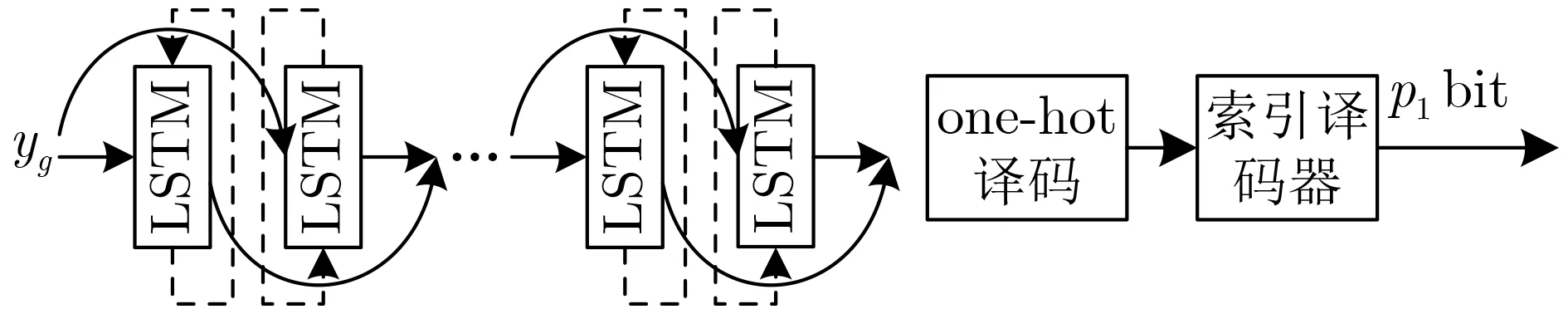
圖3 基于多層BLSTM的索引檢測框圖

當損失值隨著迭代訓練的進行達到預設閾值或一定輪次后損失值不再減小時,網絡離線學習完成。各神經元和LSTM單元所產生的參數都保存在網絡模型中,在FBMC-IM接收端在線索引檢測時直接輸出預測結果,進一步通過譯碼恢復出索引比特。
3.3 復雜度分析
對于第g組子載波塊,本文所提索引檢測器與傳統檢測算法的復雜度對比如表2所示。ML檢測的復雜度與Ig和sg的實現種類成正比,與p1和L呈指數倍增長。ED檢測和LLR檢測分別對比K個子載波上的最大符號能量和最大后驗概率,大大降低了檢測復雜度。基于BLSTM的方法將索引檢測任務看作 2p1元分類識別,計算量主要集中在網絡迭代訓練過程中,在網絡測試階段直接輸出識別結果,相較于子載波塊整體估計的ML檢測復雜度也有明顯的提升,相較于ED檢測和LLR檢測在計算中不會出現未曾選用的活躍子載波組合情況,系統誤碼率也更低。

表2 索引檢測算法復雜度對比
4 仿真分析

FBMC-IM系統的誤碼存在兩種形式:當索引位置檢測正確時,由于干擾和噪聲導致的星座比特錯誤;當索引位置檢測錯誤時,存在索引比特檢測錯誤和因此導致的星座比特錯誤。本文采用類似信號識別的概念來進行FBMC-IM活躍子載波索引檢測,表3所示各信噪比下的BLSTM檢測與傳統檢測算法的誤索引率(Index Error Ratio, IER)對比,結果表明LLR的逐子載波計算后驗概率與ED的IER相近,BLSTM在低信噪比時由于樣本帶噪嚴重,無法有效學習到數據的特征,但在高信噪比下對整組載波進行識別的速度和準確率均有提升,且隨著活躍子載波數量的增加效果越明顯。
圖4所示以 (K,L)=(4,1)為例,本文所提索引檢測算法在不同接收信噪比下的誤碼率性能,此時傳輸的索引比特和符號比特占比相等。仿真結果表明在VTRM均衡后,LLR檢測和ED檢測的兩種形式誤碼都較為嚴重,相比之下BLSTM檢測直接大幅降低了索引比特出錯,抑制了第2種形式的誤碼,間接地提升了符號比特的性能,整體的系統誤碼率優于傳統索引調制檢測算法的任一誤碼形式。
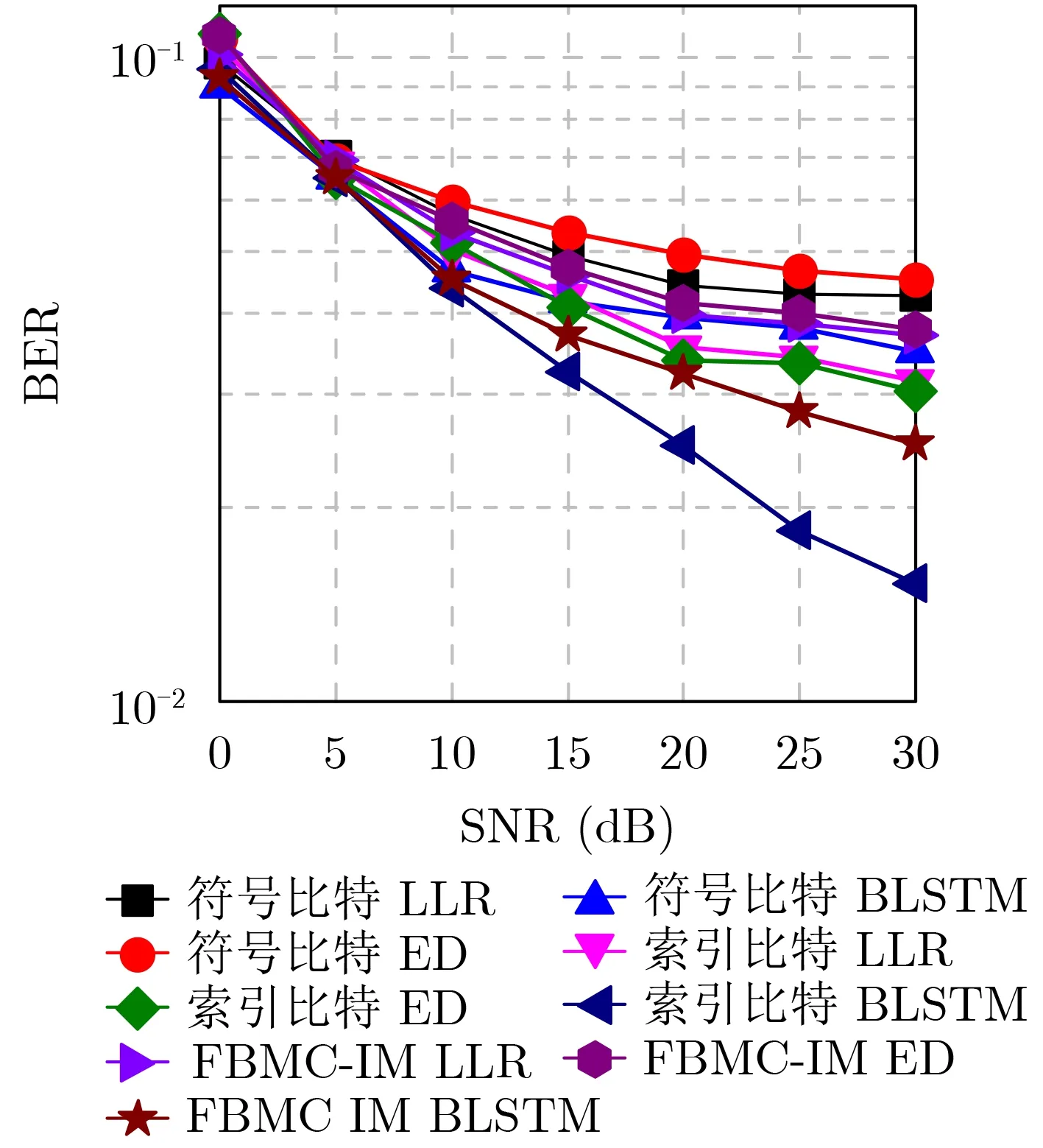
圖4 基于BLSTM索引檢測的FBMC-IM系統誤碼率性能
圖5對比了3種子載波占空比下的FBMC-IM系統誤碼率,此時系統以不同的頻譜效率作為代價來增加每個載波塊中靜默子載波數量,降低子載波間干擾,穩步提升了系統的誤碼率性能。仿真結果表明BLSTM檢測在各個模式下的表現均優于傳統方法,且隨著靜默子載波數量的增加,性能提升的效果越明顯,與表3的IER值相互對應,對于索引模式的切換具有較高的魯棒性。同時可以發現在(K,L)=(4,3) ,(K,L)=(4,2)時采用BLSTM索引檢測算法取得了傳統算法在 (K,L)=(4,2) ,(K,L)=(4,1)時的誤碼率性能,在同等條件下本文方法可以有效提高水聲FBMC-IM通信系統的頻譜效率,提高信息傳輸速度。
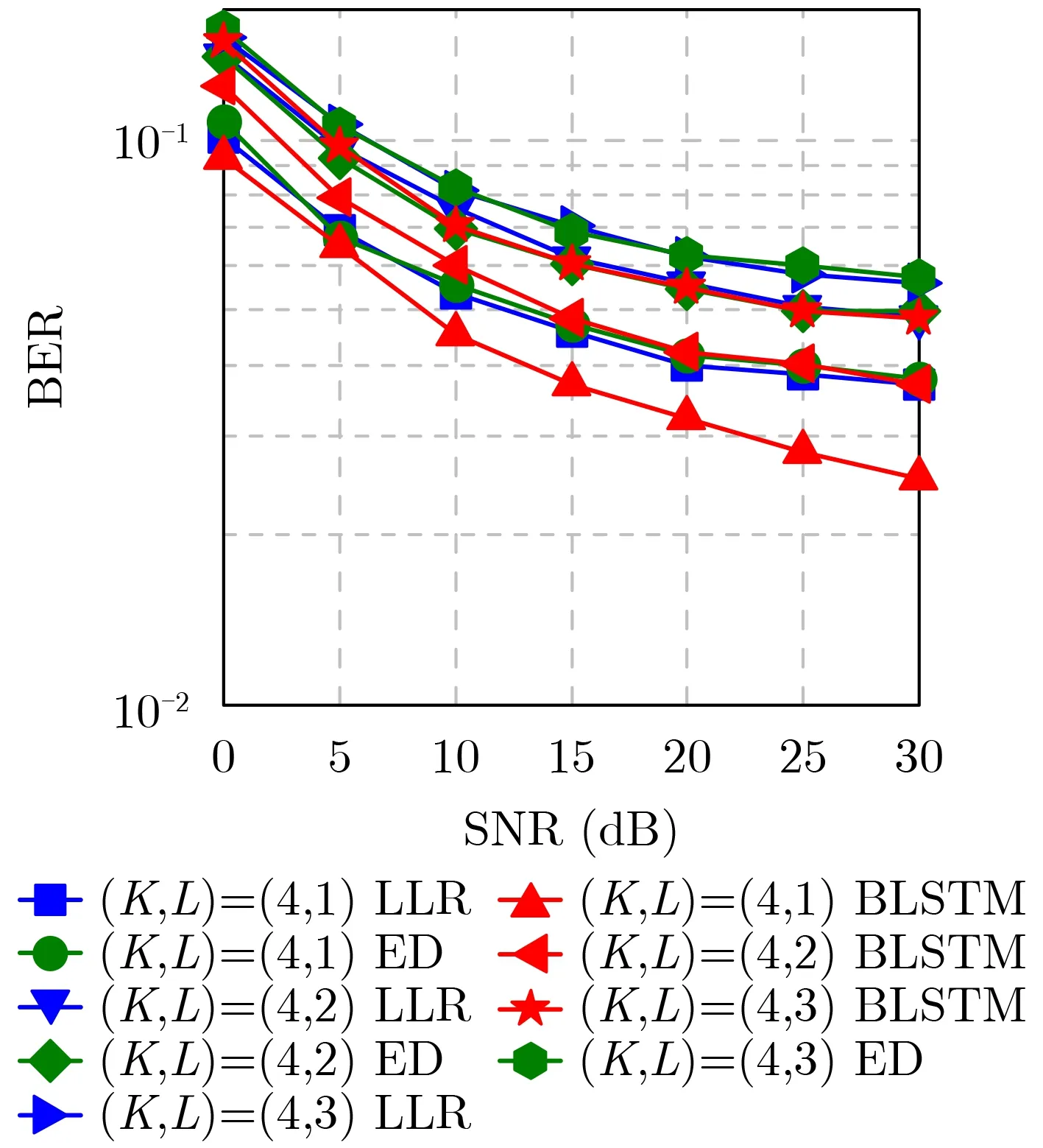
圖5 不同模式下的BLSTM索引檢測性能
為了進一步驗證所提索引檢測方法在不同通信場景下的魯棒性,FBMC-IM系統的各項通信參數設置和BLSTM的各項網絡超參數保持不變,加入時頻聚焦特性各異的擴展高斯函數(Extended Gaussian Function, EGF)原型濾波器組進行仿真。表4對比了在(K,L)=(4,1)時 ,軸比例因子α分別為1/2, 1, 2時EGF濾波器下的IER。仿真結果表明表3的PHYDYAS濾波器與表4的EGF(α=2)濾波器IER相近,這兩種濾波器具有比較好的時域聚焦特性,能夠有效抑制符號間干擾即抵抗多徑效應的能力更強,與當前信道特征一致。而各向同性的EGF(α=1)濾波器下的BLSTM檢測的性能有所弱化,但仍優于傳統算法。頻率聚焦特性更佳的EGF (α=1/2)濾波器下的檢測結果比ED, LLR差,這是由于此時所得的訓練樣本中未作處理的多徑干擾更多,使得神經網絡的特征提取效率大大下降。因次,BLSTM檢測方法對于所選原型脈沖設計與當前信道時頻特征的匹配程度較為敏感,所得的IER結果與選用的濾波器的性能成反比。
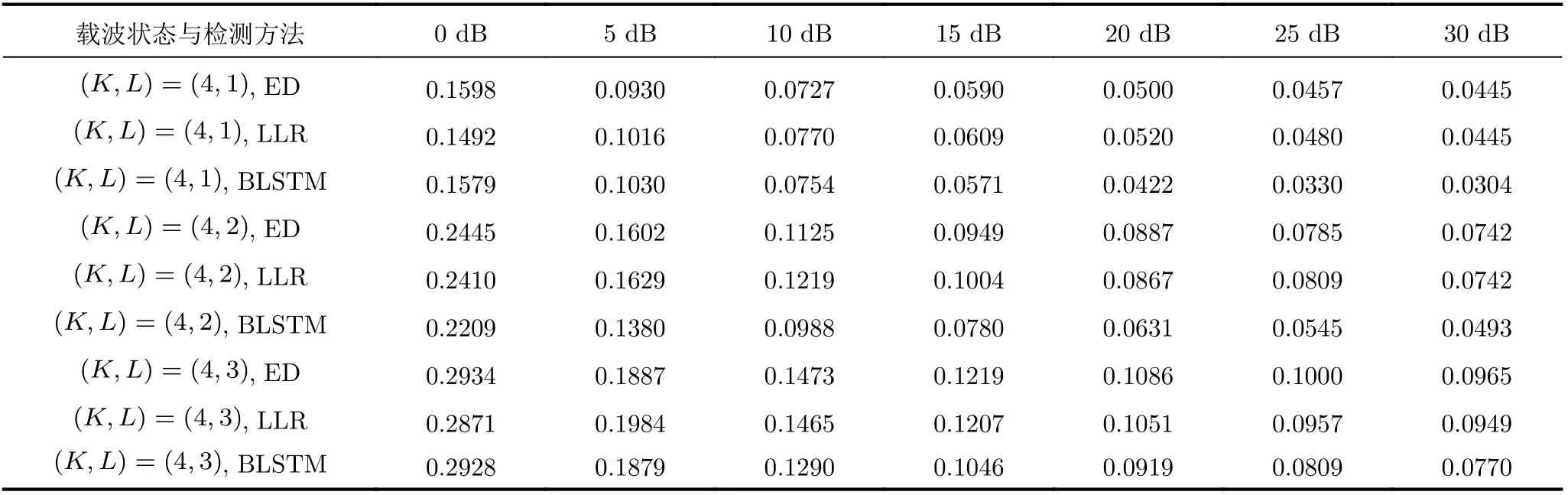
表3 各信噪比下活躍子載波位置檢測誤索引率(IER)
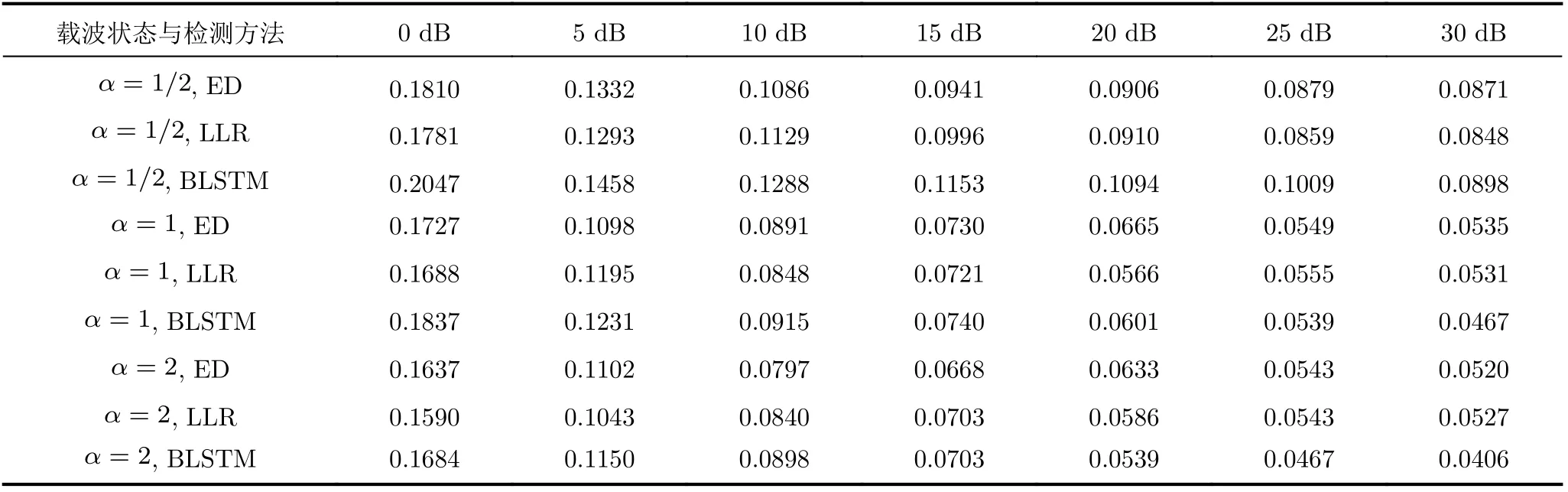
表4 ( K,L)=(4,1)時 不同α 值的EGF濾波器組系統誤索引率(IER)
5 結論
在水聲信號處理領域應用深度學習理論的思想逐漸得到了廣泛的認可,本文提出一種結合BLSTM網絡的子載波索引檢測方法來降低水聲多載波通信系統的誤碼率。不同于傳統ED檢測和LLR的逐載波比較,利用BLSTM網絡對時間序列多元分類的思想進行整體子載波塊索引識別,檢測結果表明所得IER優于傳統算法,有效降低了索引檢測誤碼和星座符號檢測誤碼。同時基于外場實驗信道數據仿真分析了不同子載波占空比和不同原型濾波器選擇下的系統性能,驗證了所提方法的有效性和魯棒性,有望成為索引調制機制下的通用檢測手段。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
