基于生成對抗網絡的艦船輻射噪聲分類方法研究
2022-06-25 08:28:46李向欣殷敬偉
電子與信息學報 2022年6期
李 理 李向欣 殷敬偉
(哈爾濱工程大學水聲技術重點實驗室 哈爾濱 150001)
(哈爾濱工程大學海洋信息獲取與安全工信部重點實驗室 哈爾濱 150001)
(哈爾濱工程大學水聲工程學院 哈爾濱 150001)
1 引言
在水聲信號處理領域中,艦船目標識別是一項重要的研究內容。過去幾十年,艦船目標識別很大程度上依賴于受專業訓練的聲吶操作員來實現,這個過程與人心理和情緒等狀態有關,對識別結果有很大影響。隨著機器學習的發展,越來越多的算法被應用于目標識別領域,文獻[1]指出使用機器學習算法進行目標識別往往需要大量數據作為支撐。由于水聲領域的特殊性,目標數據的獲取往往代價昂貴,導致實際獲取的樣本較為稀少,從而使得目標識別算法效果不佳,因此需要進行數據增強,以提高算法的泛化能力。
近年來,深度神經網絡迅速發展,已經對許多領域產生了重要影響,如計算機視覺、機器翻譯等領域。該方法通過對大量原始數據進行訓練,能夠實現對上百萬參數的模型進行優化,最終得到高性能模型。但是,隨著計算能力和相應的加速算法的快速發展,訓練樣本逐漸成為分類和識別的瓶頸。傳統的數據增強方法包括對原始數據進行幾何變換、頻率域變換、添加噪聲等,以及基于少量樣本進行合成的SMOTE(Synthetic Minority Oversampling TEchnique)算法[2]。該算法通過對附近的幾個樣本進行合并來生成新的樣本,從而緩解數據不平衡帶來的影響,其本質是使用插值法來生成新樣本,數據的多樣性并未得到提升,難以提高算法的泛化性能。近年來使用較多的還有谷歌公司提出的AutoAugment算法[3],用增強學習從數據本身尋找最佳的圖像變換策略。
生成對抗網絡(Generative Adversarial Network,GAN)自2014年Goodfellow等人[4]提出后迅猛發展,其基本思想是通過對抗學習的方法來學習真實數據的概率分布,在此基礎上進行隨機采樣得到的生成數據與原始數據有著十分接近的分布,與此同時還能夠保持生成數據的多樣性,這一優良特性對于數據增強十分重要。GAN自提出后迅速發展,已經有上百種變體。近年來許多研究者將生成技術應用于信號的生成中,Gao等人[5]使用DCGAN和Dense-Net構建了數據增強和性能評估框架,以生成高質量特征圖,Liu等人[6]提出一種聯合色譜和條件生成對抗網絡的水聲測距方法,該方法對聲源測距有一定的改進,Yang等人[7]使用CGAN來生成多尺度水下圖像,使得生成結果更先進真實和自然,實驗證明該方法優于目前最先進的水下圖像增強方法。
本文提出了一種基于深度卷積生成對抗網絡(Deep Convolutional Generative Adversarial Network, DCGAN)的艦船輻射噪聲數據增強算法。首先對艦船輻射噪聲數據進行特征提取,獲得了能夠反映艦船物理特性的DEMON調制譜,然后搭建基于條件生成的DCGAN來對艦船輻射噪聲數據進行對抗生成,并分析了其在樣本不平衡條件下以及小容量條件下對于偏置類別以及總體分類結果的影響。
2 艦船輻射噪聲特征提取
研究表明,艦船輻射噪聲由機械噪聲、螺旋槳噪聲和水動力噪聲3部分組成,其中水動力噪聲在時間上是平穩的,表現為連續譜。而空調機、通風機和泵等機械部件運行時產生的機械噪聲都表現為線譜。周期性的機械運動和齒輪的運轉是船舶輻射噪聲的主要來源。
通常對艦船輻射噪聲提取特征的方法包括文獻[8]中對信號進行短時傅里葉變換(Short-Time Fourier Transform, STFT)得到的LOFAR譜、文獻[9]中使用到的離散小波變換(Discrete Wavelet Transformation, DWT)以及文獻[10]中對信號進行寬帶解調得到其調制包絡的DEMON譜分析法。由于DEMON譜具有明確的物理意義,可以獲得艦船螺旋槳轉速和槳葉數等艦船物理特性,對于目標識別有十分重要的意義,韓雪等人[11]提出了節拍響度變化量特征,分析了艦船輻射噪聲在不同調制方式下的識別準確率,陳雪峰等人[12]利用DEMON譜處理技術提取了目標軸頻特征和槳葉數特征并使用海上實測數據進行了實驗驗證。
由于艦船的離散線譜分量相比于海洋的環境噪聲來說較小,被其蓋過的可能性較大,而通過對較高頻的信號進行包絡解調,可以獲取到艦船噪聲的調制譜,從而可以得到關于槳葉轉速等許多信息。DEMON譜提取方法流程如圖1所示。

圖1 DEMON譜解調方法
比較常用的兩種檢波方法分別為絕對值解調和平方解調。在絕對值解調方法中,首先是將信號通過帶通濾波器濾除低頻段的海洋環境噪聲,然后對得到的輸出信號計算其絕對值以提取包絡,再將信號通過低通濾波器,最后得到包絡時域信號再執行FFT運算,即可提取出DEMON譜。
3 模型設計
3.1 生成對抗網絡
GAN能夠不依賴先驗假設來對學習數據的高維分布,這一強大能力具有比以往生成模型更加強大的表征能力,文獻[13]中指出GAN及其變體已在圖像、音頻等領域取得了十分顯著的成果,GAN一般包含生成器、判別器兩個主要模塊,如圖2所示。

圖2 GAN基本結構
GAN最初的想法來源于博弈論中兩個人進行零和博弈,其中生成器(G)和判別器(D)被視為在博弈中的兩個進行對抗的玩家。在GAN模型的訓練過程中的生成器和判別器會分別對自己的參數進行更新以使得相應的損失函數達到最小,經過多次的迭代優化,最后模型達到納什均衡的狀態,此時得到的GAN模型即為最優模型。GAN目標函數定義為
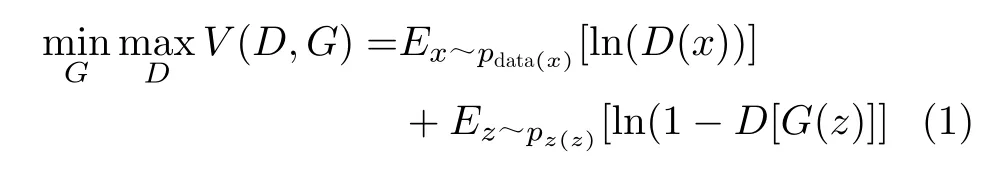
其中,G表示生成器,D表示判別器,x表示真實樣本,z表示隨機噪聲。
最初的GAN訓練非常不穩定,存在許多問題,其中模式崩潰和梯度消失的問題嚴重限制了生成模型的訓練穩定性。之后研究人員對原始GAN提出了許多改進,文獻[14]提出了基于條件生成的CGAN(Conditional Generative Adversarial Network),以及加入了卷積運算的DCGAN(Deep Conditional Generative Adversarial Network)等多種變體。
DCGAN對GAN的發展有著巨大的推動作用,其將卷積算法引入到GAN中,使生成數據的質量有了質的提高,自提出后得到許多領域的廣泛應用。在文獻中作者提出了一系列措施來提高訓練的穩定性,在實際使用中通常能夠有較為穩定和有效的表現,因此本文將構建基于條件生成的DCGAN對艦船輻射噪聲進行數據增強。
3.2 基于條件DCGAN的艦船噪聲分類模型設計
本文設計了基于條件DCGAN的數據增強及分類評估模型,模型整體分為3部分,分別為特征提取部分,用于條件生成數據的DCGAN訓練網絡以及將生成對抗網絡中判別器的末級輸出由原來的全連接層改為有利于小樣本分類的集成分類器,下面將對數據增強和分類評估兩部分結構進行詳細說明。模型整體結構如圖3所示。
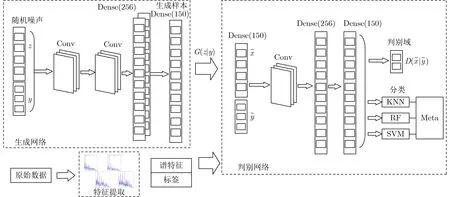
圖3 模型整體框架
生成網絡部分輸入為128維的隨機向量和2個維度的標簽編碼的拼接,用以控制生成樣本的類別,后面是兩個連續的卷積層,卷積核數目均為16,寬度為3,輸出特征圖再經過兩個全連接層將特征尺寸降維到150維作為輸出的生成樣本。判別器有兩個輸入,分別為生成樣本以及來自真實樣本提取的譜特征,兩者尺寸相同,然后經過1個卷積層和2個全連接層實現樣本特征的2次提取進而完成后面的域判別及類別輸出,通常在DCGAN的訓練過程中判別網絡除了能夠輸出訓練數據的判別域,還能夠通過1個全連接層(Full Connection, FC)直接輸出分類的結果,而由于水聲領域的樣本量較少,神經網絡分類器在數據量較少時往往結果不佳,本文將傳統生成對抗網絡的用于分類的判別器末級改為有利于小樣本分類的集成分類器,以提高分類器的泛化性能。
DCGAN的對抗訓練實質上是一個交替進行的過程。當對生成網絡進行訓練時,固定判別器D的網絡參數,更新生成網絡G的參數。生成器的目標就是希望通過G生成的數據被判別器D識別為真實數據,故其目標函數為最大化 ,即

生成器G的能力往往會受到判別器D的影響,所以一般在訓練過程中,每訓練生成網絡3次,訓練判別網絡1次。如此,可以使生成器訓練足夠多的次數,不斷更新損失值,從而更快地將損失函數降低到合理值,生成器和判別器的交替訓練結構如圖4所示。
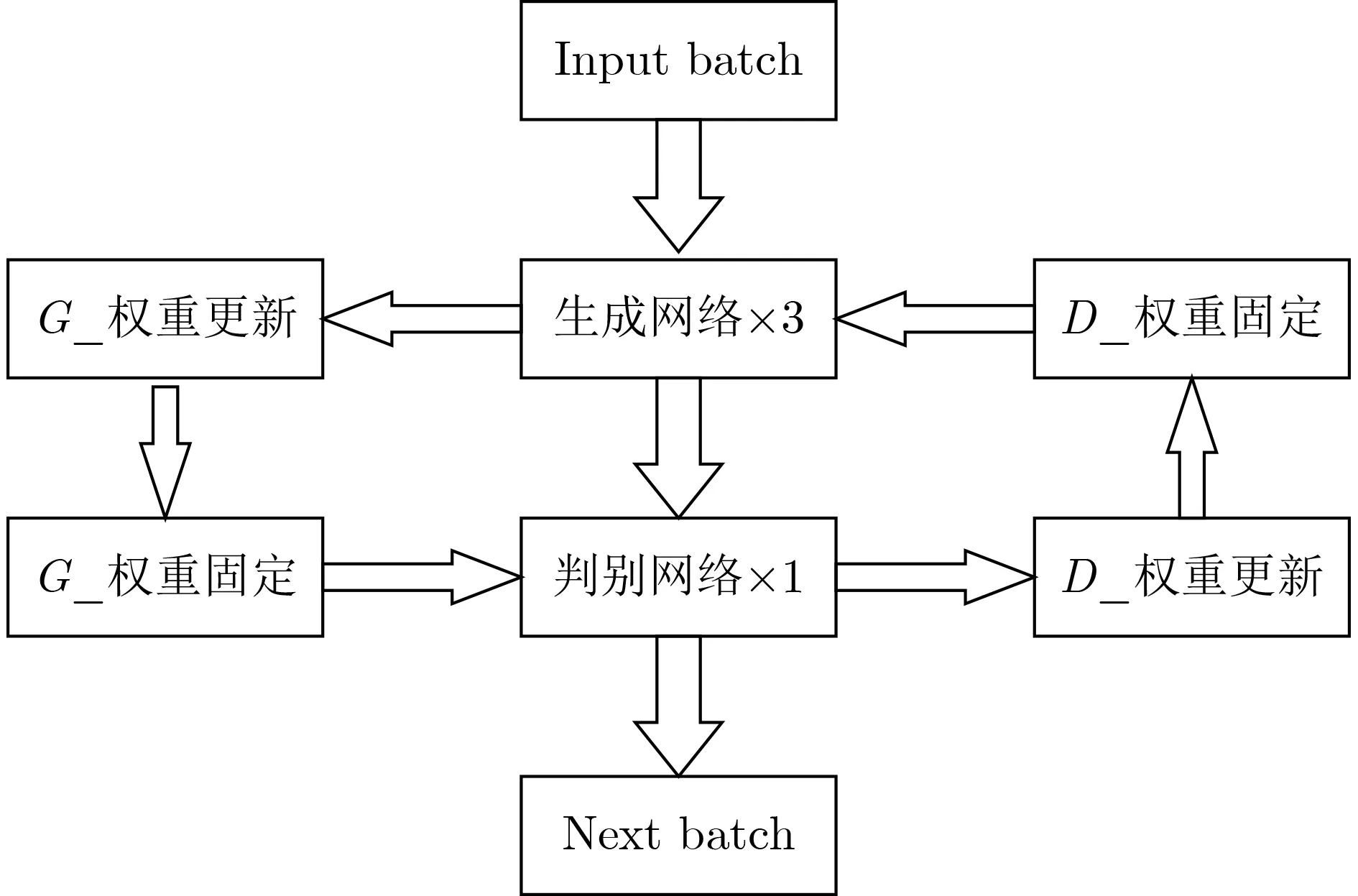
圖4 DCGAN訓練過程
判別器末級的分類器使用文獻[15]提出的基于Stacking結構的集成分類器,近年來,集成算法在各種數據科學競賽中大放異彩,將多種學習算法通過一定方式組合到一起來獲得更好的模型表現,往往比單一模型能夠取得更好的效果。Stacking是一種異構集成算法,文獻[16]中提出可以將不同分類器進行Stacking集成,從而使分類結果融合多個分類器的優點。本文構建了使用K近鄰(KNN)、隨機森林(RF)、支持向量機(SVM)作為基分類器的集成分類器對數據進行綜合評估,分類器結構如圖5所示。
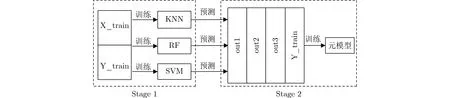
圖5 分類器結構
在對數據進行分類評估時,分為Stage1和Stage2兩個階段,第1階段將訓練數據分別經過3個基分類器進行訓練,然后將輸出結果以及標簽作為Stage2的輸入,在Stage2中為了避免過擬合通常采用弱分類器,這里使用Logistic作為元模型,從而獲得更具代表性的分類結果。
4 實驗結果及分析
本文使用的艦船噪聲數據來自西班牙維戈大學的Santos-Dominguez等人[17]于2016年發表在Applied Acoustics期刊采集的Shipsear數據集。該團隊在大西洋的沿岸并且位于西北部的多個地區采集了過往的許多船只的噪聲數據。該團隊使用自容式水聽器來對過往船只的噪聲信號進行采集,采集頻率為52734 Hz。水聽器的布放如圖6所示。
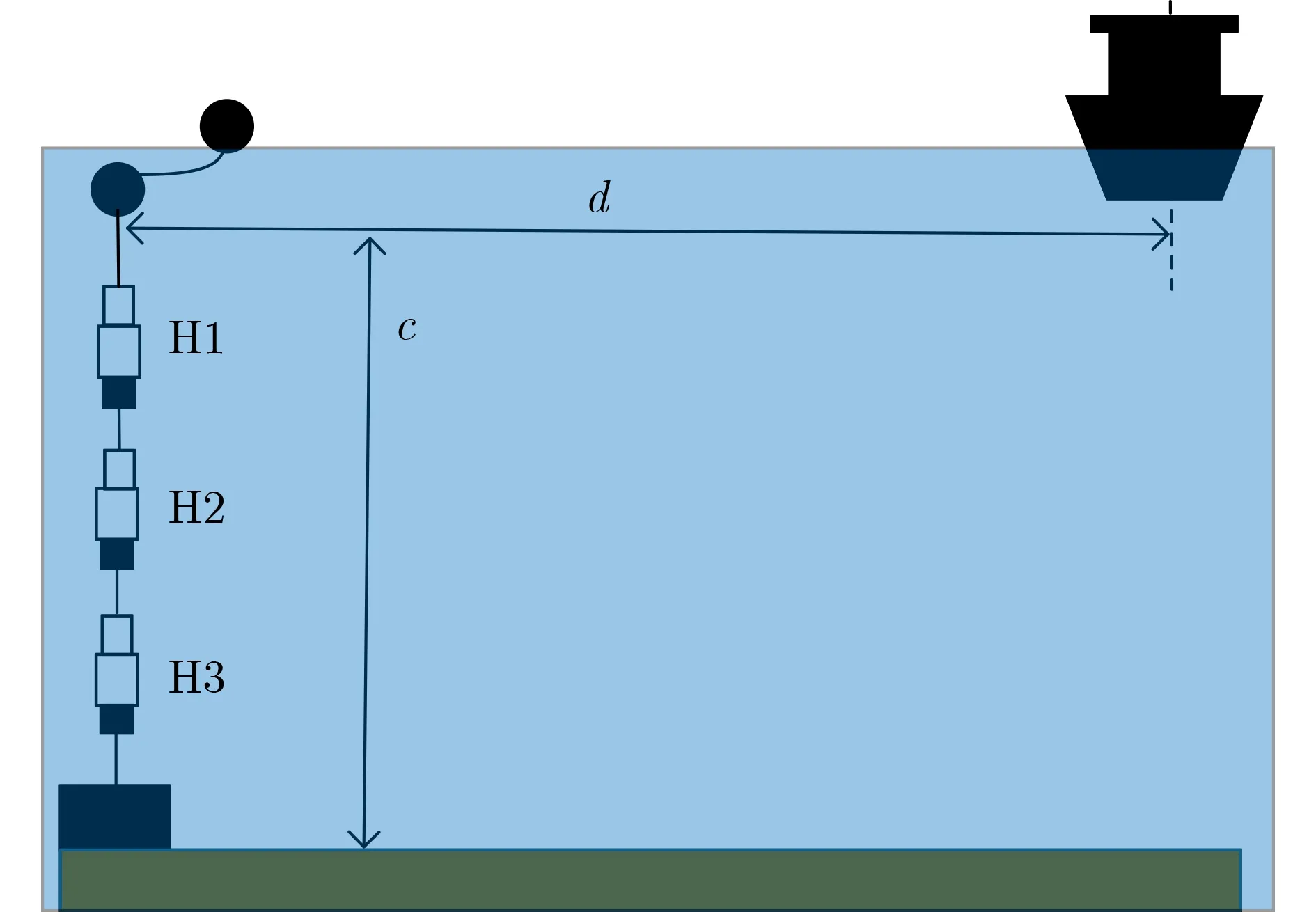
圖6 水聽器布放圖
其中,H1, H2, H3為水聽器布放深度,由于ShipsEar數據集中一些船只噪聲樣本的數量有限,因此將其剔除。本文選取了其中時常達到5 min以上的船只作為實驗數據,并制作數據集。
實驗選取了其中4種不同的客船作為目標。由于水聽器在位于H2處位置時采集的信號較好,因此本實驗均選取位置為H2處采集的音頻數據,根據vesselfinder網站提供的數據,4種船只的長寬分別為16/6, 27/10, 19/6, 24/8 m,本文將對4種船只提取能夠反映艦船物理特性的DEMON譜進行數據增強及分類實驗。實驗選取的船只如圖7所示。

圖7 艦船目標類型
艦船噪聲信號采樣頻率為52734 Hz,為了盡可能保留其頻率分辨率,這里選取每0.5 s時長為1個樣本,對應頻率分辨率為2 Hz,每段信號點數為15820。最終得到每類樣本數240個,樣本總數為960個。將數據集混合并隨即打亂順序,選取720個樣本作為訓練集,其余240個樣本作為測試集。
4.1 信號預處理
聲信號在水下傳播過程中,相對于低頻成分,高頻成分會衰減得更快,一般對于目標來說低頻分量要明顯高于高頻分量,使得采集得到的信號在高頻處相比于低頻處會有一定的缺失。為了使信號盡可能包含更多信息,一般要對信號進行預加重,避免信號中低頻分量過大從而抑制了高頻分量。一般使用FIR濾波器對采集的信號進行預加重。這里FIR濾波器使用的傳輸函數為

其中,a為 預加重系數,一般取0.9~1.0,在實驗中取0.97。
由于不同信號所處的接收距離跨度較大,在模型進行反向傳播計算時會影響梯度值,不利于模型的收斂,故對數據進行歸一化操作將其范圍控制在[0,1]。
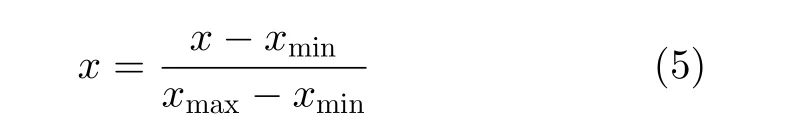
4.2 DEMON譜特征提取及數據生成
對本文選取的4種艦船輻射噪聲樣本進行DEMON提取,其中帶通濾波器的通頻帶為1~4 kHz,低通濾波器的通頻帶為0~200 Hz,得到4種艦船的DEMON譜圖如圖8所示。
圖8可以看出4種船只均包含有低頻的包絡調制線譜,基本都分布在200 Hz以下,并且其調制譜的組成都不相同,便于后續的數據增強以及分類識別。
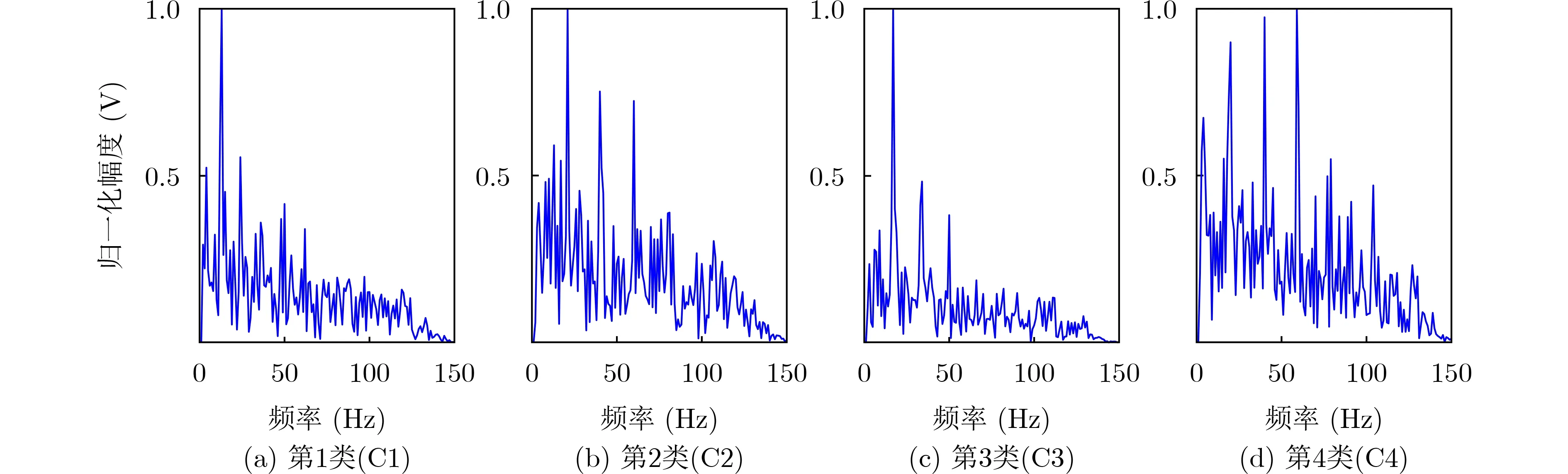
圖8 DEMON譜提取結果
經過上文提取的DEMON譜為150維,在輸入到網絡之前先進行歸一化操作,之后將數據按照小批次輸入到網絡中,每個批次的數據個數為10。生成網絡輸入設置為維度100的隨機向量,經過卷積和上采樣逐漸向原始數據的尺度進行變換;經過實驗發現判別器網絡結構不能過于復雜,否則由于判別器分類能力遠遠強于生成器會造成網絡難以收斂,因此判別器網絡相比生成網絡在結構上要進行一定的輕量化,網絡的優化器均使用學習率為0.001的Adam優化器。
經過生成器和判別器的20000次對抗訓練后,將模型進行保存并進行樣本生成, 4種艦船原始信號的DEMON譜、生成器生成樣本的對比如圖9所示。
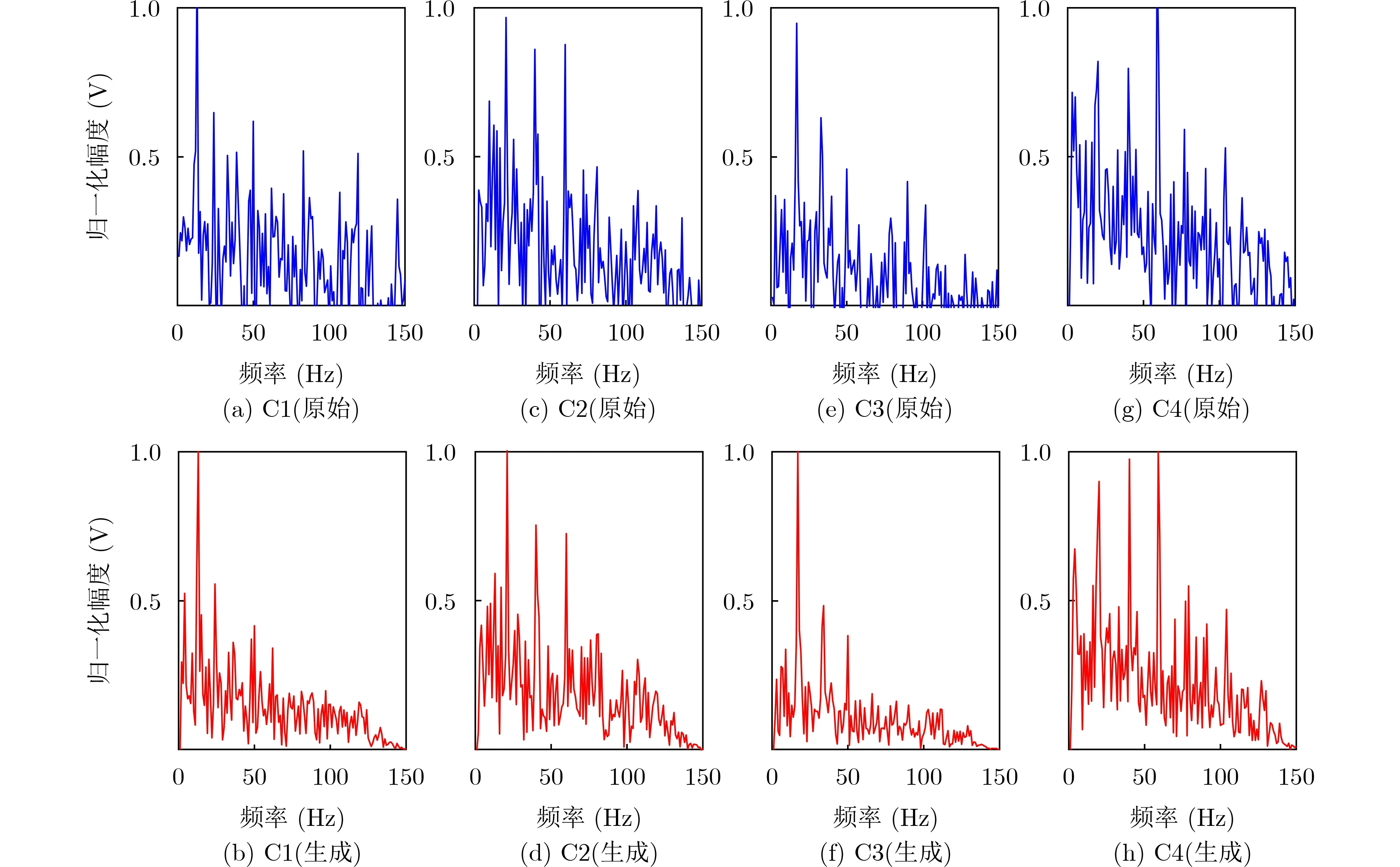
圖9 原始數據與生成數據對比
從圖9得出由生成對抗網絡訓練生成的DEMON譜相比原始的DEMON譜,對噪聲有明顯的抑制作用,信號的峰值相比噪聲更加突出。下面使用文獻[18]中的t-SNE算法將4類生成數據壓縮至3維空間,以了解4種船只DEMON譜特征在特征空間分布的差異性,得到結果如圖10所示。
由圖10可以看出在對數據壓縮至3維空間后4種樣本都具有自己的聚類中心,彼此的重合度較小。為了驗證改進條件DCGAN生成樣本與原始樣本的分布相似度,使用同樣方法將生成樣本和原始樣本的所有特征降至3維,并分別以50%的比例進行混合,然后執行t-SNE算法,得到可視化結果如圖11所示。

圖10 生成的4種樣本特征空間分布對比
圖11中原始數據與生成數據在壓縮后的3維空間中聚類存在顯著的重合區域,說明文本的條件DCGAN很好地學習了原始數據的特征,而由生成器生成的不同類別樣本間也存在著明顯的區分度,潛在說明在原始樣本間摻入人工生成的樣本有利于提升分類模型的表現。
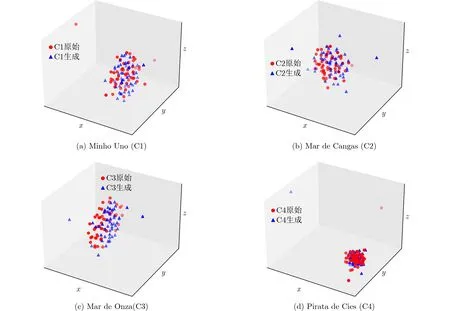
圖11 4類艦船數據真實樣本與生成樣本分布對比
4.3 生成數據在樣本不均衡下的應用
為了驗證在樣本數量不均衡狀態下生成數據的數據增強作用,本文設計了4組對照實驗,第1組實驗構建了樣本不平衡的樣本集,其中前3類樣本數分別為120個,第4類樣本僅設置40個來模擬樣本不均衡的情況,分類結果如表1所示;第2組實驗在第1組實驗的基礎上,對第4類樣本使用生成對抗網絡進行數據增強,使各個類別樣本數一致,直接采用判別器加全連接層來進行分類,得到結果如表2所示;第3組實驗使用經典的SMOTE算法對第4類樣本進行擴充,使每類樣本數一致,利用上面構建的Stacking集成分類器得到的分類結果如表3所示;第4組實驗對于前3類樣本依舊保持120個樣本數不變,但第4類樣本由40個真實樣本和80個由改進后的條件DCGAN生成的樣本組成,從而使第4類樣本的數據與其他3類相同,此外訓練樣本與測試樣本完全獨立,用于測試的樣本均為原始樣本,不包含生成樣本及訓練樣本。

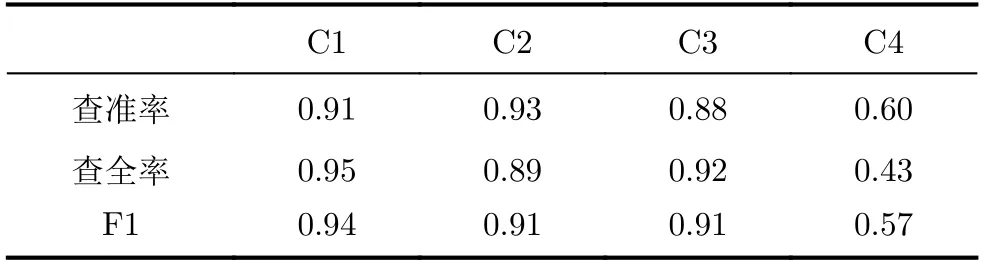
表1 樣本不均衡下分類結果(第4類樣本不足)
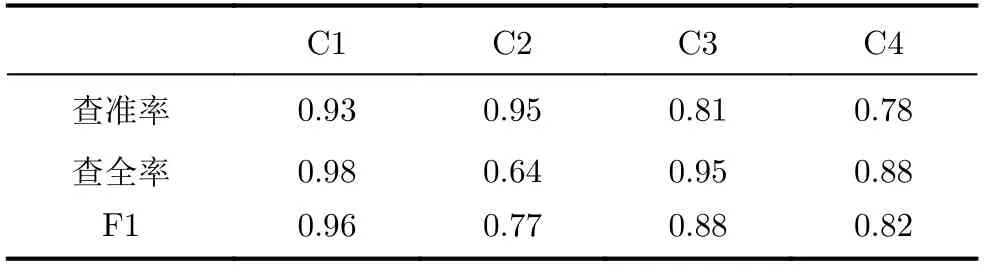
表2 使用常規DCGAN網絡分類結果
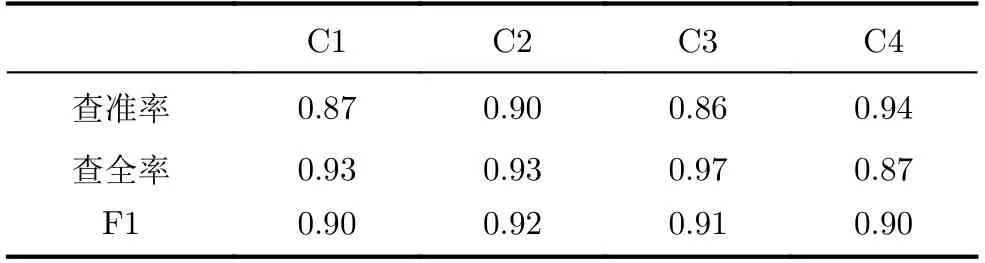
表3 使用SMOTE算法擴充樣本+Stacking分類結果

本文使用查準率(precision, pr)、查全率(recall,re)以及F1分數作為分類評價指標,公式為其中,查準率被預測為正類的實例中有多少為真正的正例,而查全率表示樣本中的正例有多少被預測為正例,其中TP表示預測為真,實際也為真;TN表示預測為假,實際也為假;FP表示預測為真,而實際為假;FN表示預測為假而實際為真。
在本次實驗中設置KNN的近鄰數量為5;對于隨機森林使用基尼指數作為分類決策標準,隨機森林中決策樹的數量固定為10;對于支持向量機,經過實驗證明使用高斯徑向基(RBF)核函數的分類效果要好于其他核函數,故本實驗的支持向量機使用的均為RBF核函數,gamma值設置為0.1。基于Stacking結構的集成分類器將上述3種分類器的輸出進行組合,使用logistics回歸作為最頂層輸出,從而得到更加具有代表性的結果,分類器訓練測試結果如下。
通過表1和表2-表4的對比,在樣本不均衡時,即第4類的樣本數量遠小于其他幾類時,總體的分類準確率有明顯下降,并且對于數量較少的類別F1分數會大幅下降,說明在樣本量較少時難以形成獨立的聚類空間,導致分類的表現不佳。在使用生成對抗網絡進行數據增強后(表2),第4類的樣本的F1分數提高了0.25,有效提高了不均衡樣本的分類準確率。但同時也應該注意到,C2的查全出現了顯著的下滑而查準并沒有顯著變化,說明C4數據量擴充導致歸類為C2的樣本大幅減少(同時包括FP樣本和FN樣本),而C3的查準相比于表1略微降低,也說明由于C4數據量的增加干擾了分類器對于C3的判斷,說明在當前數據量下,只使用全連層作為分類器的性能存在瓶頸。與表4的結果比較更說明了這一點,通過比較可以看出,在數據增強算法相同的情況下,相比于使用全連層輸出分類結果,使用了條件DCGAN網絡連接stacking分類器進行分類不僅使得C4的分類精度大幅提升,同時也促進了C2和C3的F1分數的提升,因此最終取得了整體分類性能最優的結果。表3中第3組實驗使用經典的基于人工合成樣本的SMOTE算法對不平衡樣本進行擴充后有效提高了該類別的各項識別分數,由表3和表4的對比,第4組實驗使用生成對抗網絡對第4類樣本進行擴充后與實驗3中使用的SMOTE算法相比,4類樣本的F1分數均有進一步提升,并且查全率和查準率更加均衡。表5將4組實驗的平均分類精度進行了對比,說明了基于本文的改進條件DCGAN來對樣本擴充在一定程度上可以改善樣本不均衡情況下的分類效果,并且綜合效果要優于傳統的SMOTE算法進行數據增強以及使用常規DCGAN進行分類識別。
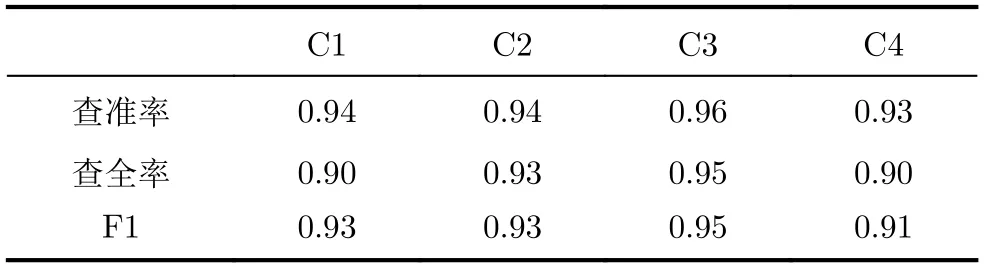
表4 使用改進的條件DCGAN分類結果
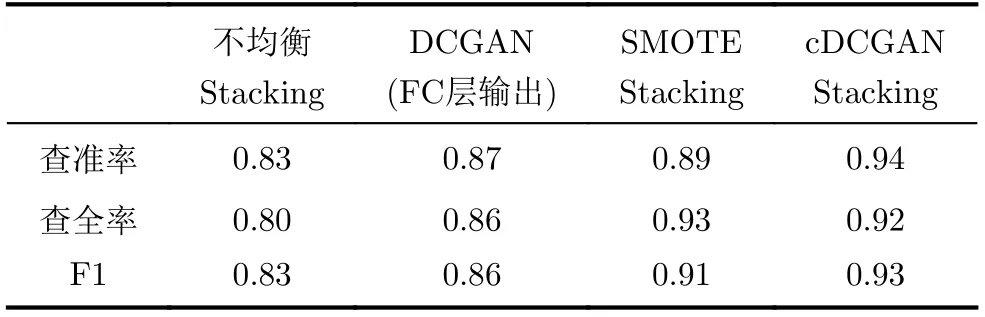
表5 分類結果總體對比
4.4 樣本容量較小時的數據增強
為了衡量生成對抗網絡在小樣本容量下對于數據增強的效果,本節設置了3組實驗,其中第1組4類樣本數量均為75個,第2組在第1組的數據的基礎上使用SMOTE算法對每個類別生成75個樣本并加入到訓練樣本中,第3組使用生成對抗網絡對每個類別數據進行擴充,訓練樣本總數為400個。分類器依舊使用Stacking模型來對KNN, RF, SVM的分類結果進行組合,經過對分類器進行網格搜索得到分類器的最優參數,第1組實驗分類結果如表6所示。
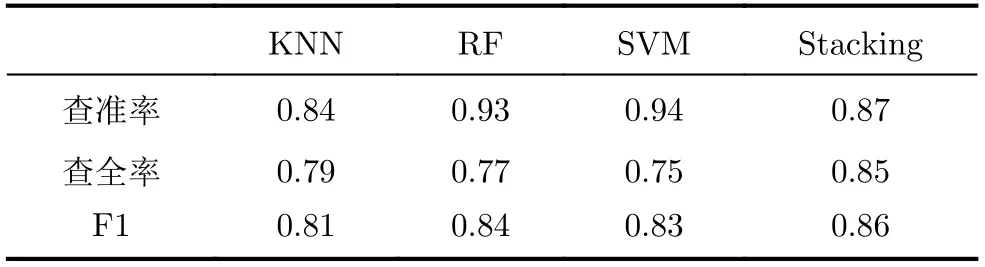
表6 原始小樣本數據集分類結果
從表中4種分類器結果的對比可知F1分數最高的分類器為SVM,其余兩種基分類器的效果較為一般,查準率和查全率指標此消彼長,而集成后的Stacking分類器融合了多個模型的優點,查全率和查準率較為均衡,使用集成后的Stacking分類器對4類樣本進行分類得到混淆矩陣并按行進行歸一化得到結果如圖12所示。
從圖12可以看出在樣本容量較小時,對應類別4種樣本的分類結果有較大差異。原因可能是在小樣本容量下,某些類別的聚類中心與其他類較為接近,從而造成分類效果不佳,使用SMOTE方法對訓練樣本進行擴充后得到4種分類器的分類結果如表7所示。

表7 使用SMOTE對數據擴充后分類結果
得到混淆矩陣如圖13所示。
通過圖12與圖13對比,使用SMOTE方法對原始數據進行擴充后,有效提高了第1類、第3類以及第4類樣本的分類準確率,但第2類樣本的準確率反而下降了13%,說明基于原始樣本進行數據合成無法有效豐富特征空間,導致分類器在訓練數據上過擬合,而在測試集上有可能出現表現不佳的情況。表8是使用本文構建的條件卷積生成對抗網絡生成的樣本對數據集進行擴充后的分類結果。
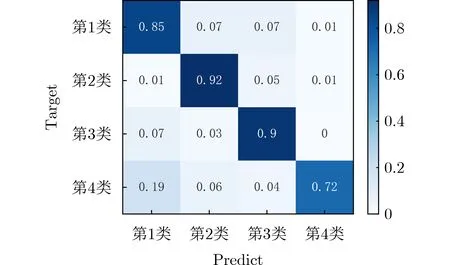
圖12 小樣本下分類混淆矩陣

圖13 使用SMOTE對數據擴充后混淆矩陣
從表8實驗結果看出在使用改進DCGAN對小樣本數據集進行擴充后,4種分類器的分類效果均有明顯提高,并且查準和查全指標均為均衡,從而得到較高的F1分數。其中使用Stacking模型對4類樣本進行分類得到的混淆矩陣如圖14所示。
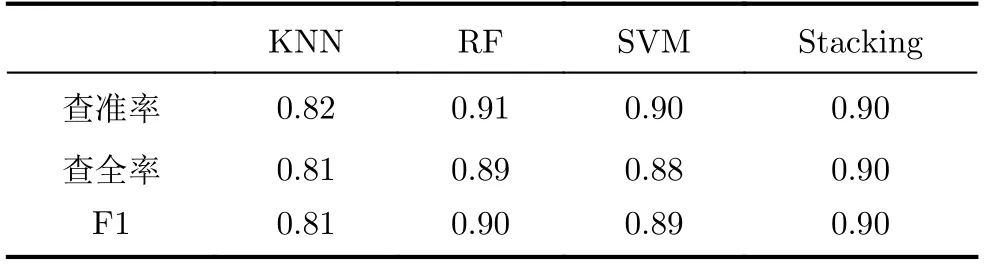
表8 使用改進條件DCGAN對數據擴充后分類結果
由圖14可知,第3組實驗在使用生成數據對第1組實驗數據進行擴充后,對應每種類別的查準結果均有一定提升,對于第1、第3和第4類樣本的提升尤為明顯,并且相比于圖13中SMOTE算法的分類結果,本文提出的條件DCGAN生成樣本在分類中的效果更加穩定。以上實驗說明生成對抗網絡對于小樣本容量的數據集能夠有效對進行數據增強,從而提高水聲目標識別精度。
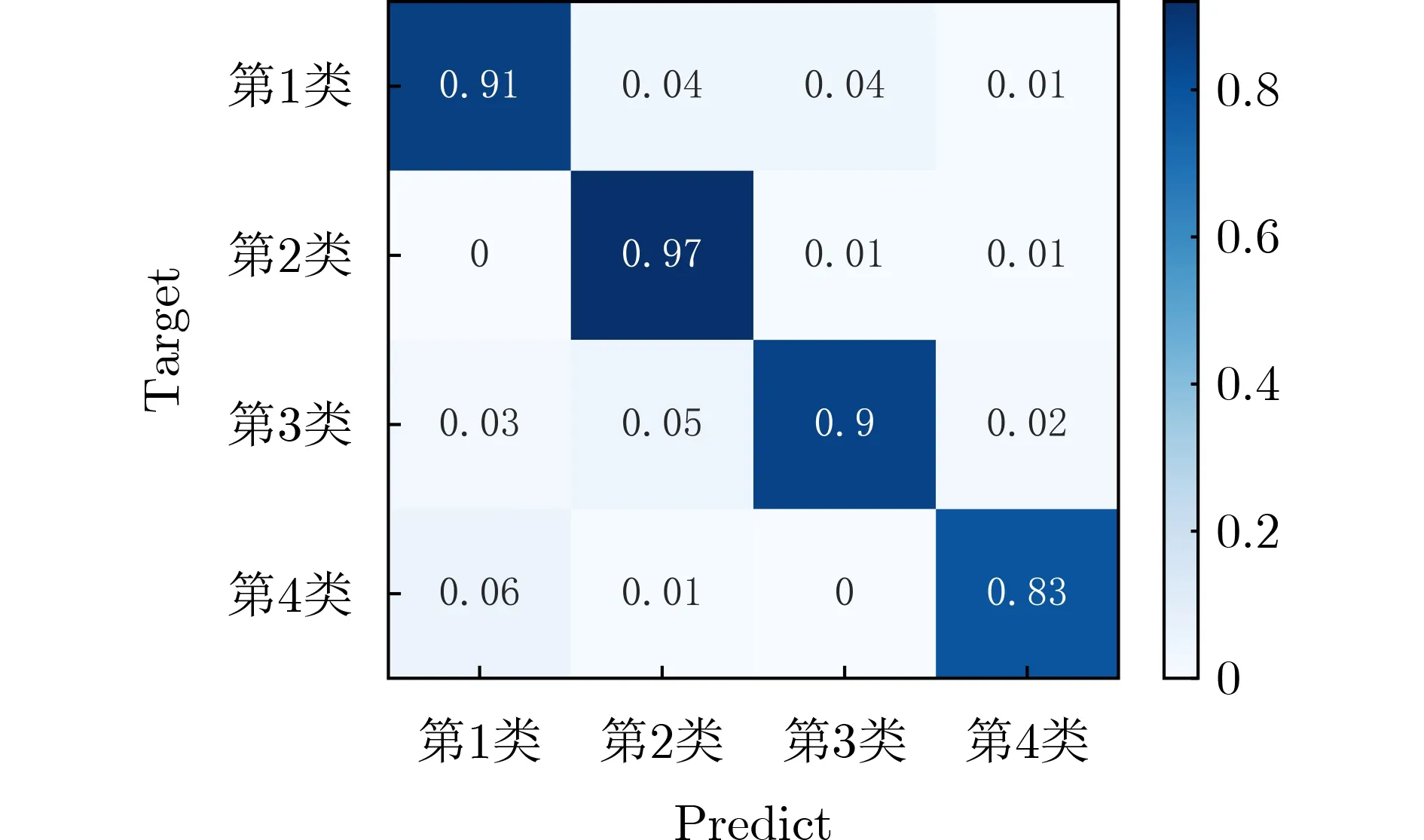
圖14 使用改進條件DCGAN擴充數據后混淆矩陣
5 結束語
針對水聲領域數據量較少且難以獲取的問題,本文提出了一種基于改進條件卷積生成對抗網絡進行數據增強的方法,通過對抗訓練來學習原始數據的分布,生成與真實數據在特征空間分布相近的數據。為綜合評價生成數據的質量,本文評估了該方法在樣本不均衡條件下以及對于小樣本容量下的數據增強效果,實驗證明了本文提出的改進的條件DCGAN在樣本量較小時能夠有效提高分類器的表現,并豐富了數據的多樣性,綜合效果要優于傳統的SMOTE算法以及原始生成對抗網絡,為生成對抗網絡在水聲領域的數據增強提供了一定的參考。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
