基于近鄰成分分析的短期風(fēng)電功率集成預(yù)測(cè)
2022-06-14 09:51:34姚岱偉崔雙喜戚元星
科學(xué)技術(shù)與工程 2022年14期
姚岱偉, 崔雙喜, 戚元星
(新疆大學(xué)電氣工程學(xué)院, 烏魯木齊 830047)
隨著新能源技術(shù)和工業(yè)的進(jìn)一步發(fā)展,風(fēng)電裝機(jī)容量占比越來(lái)越大。由于風(fēng)力資源受到氣象條件的制約,其波動(dòng)性、間歇性等不穩(wěn)定特性對(duì)電力系統(tǒng)穩(wěn)定運(yùn)行和優(yōu)化調(diào)度帶來(lái)了巨大的挑戰(zhàn)[1]。精準(zhǔn)的風(fēng)電功率預(yù)測(cè)是提高電力系統(tǒng)經(jīng)濟(jì)運(yùn)行效率,減少系統(tǒng)備用容量,保證電網(wǎng)安全穩(wěn)定運(yùn)行[2],提高風(fēng)電消納水平,優(yōu)化電力市場(chǎng)的重要方法[3]。
短期風(fēng)電功率預(yù)測(cè)方法可分為物理模型、時(shí)間序列和人工智能模型。目前研究以人工智能模型為主,可分為神經(jīng)網(wǎng)絡(luò)和統(tǒng)計(jì)學(xué)習(xí)模型,具體包括長(zhǎng)短期記憶網(wǎng)絡(luò)[4],高斯過(guò)程回歸[5](gaussian process regression,GPR),最小二乘支持向量機(jī)[6](least squares support vector machine,LSSVM),極限梯度提升樹(shù)[7]等。為改善模型的預(yù)測(cè)性能,已有大量研究對(duì)單一模型的結(jié)構(gòu)或參數(shù)進(jìn)行優(yōu)化,文獻(xiàn)[8]采用遺傳算法優(yōu)化卷積和長(zhǎng)短期記憶混合神經(jīng)網(wǎng)絡(luò);文獻(xiàn)[9]采用緞藍(lán)園丁鳥(niǎo)優(yōu)化算法對(duì)LSSVM的超參數(shù)進(jìn)行尋優(yōu),均獲得了更高的風(fēng)電預(yù)測(cè)精度。這種方法改善了原本的模型的弊端,提升了預(yù)測(cè)性能,但單一模型呈現(xiàn)的假設(shè)空間有限,難以精確描述潛在的真實(shí)假設(shè)。集成預(yù)測(cè)不局限于單一模型,而是將多個(gè)預(yù)測(cè)器組合,協(xié)調(diào)工作共同完成預(yù)測(cè)任務(wù)。為訓(xùn)練出具有差異的一測(cè)器,一種方法是基于某一學(xué)習(xí)算法,通過(guò)設(shè)置不同的數(shù)據(jù)結(jié)構(gòu)或模型參數(shù)生成同質(zhì)的預(yù)測(cè)模型,常用方法包括Bagging[10]和Boosting[11],文獻(xiàn)[12]采用自適應(yīng)提升算法將BP神經(jīng)網(wǎng)絡(luò)集成,通過(guò)誤差平方倒數(shù)優(yōu)化BP網(wǎng)絡(luò)的結(jié)合權(quán)重,有效地改善了預(yù)測(cè)模型的泛化能力。但同質(zhì)模型基于相近的假設(shè)空間,差異性較小。另一種方法是采用不同的學(xué)習(xí)算法產(chǎn)生異質(zhì)預(yù)測(cè)器,研究以結(jié)合策略為主。除了以傳統(tǒng)的簡(jiǎn)單平均法和加權(quán)平均法,文獻(xiàn)[13]采用三種異質(zhì)模型預(yù)測(cè)風(fēng)電功率,以約束最小二乘回歸(constrained least squares regression,CLS)作為結(jié)合策略,改進(jìn)預(yù)測(cè)精度,雖然每次預(yù)測(cè)前對(duì)CLS重新訓(xùn)練,但CLS產(chǎn)生的是依然是固定的結(jié)合權(quán)重,難以適應(yīng)風(fēng)電功率的變化特性。以上研究表明,集成預(yù)測(cè)模型可有效避免單一模型或方法的弊端,異質(zhì)預(yù)測(cè)器可反映多個(gè)假設(shè)空間,但需要進(jìn)一步改進(jìn)結(jié)合策略。
預(yù)測(cè)模型學(xué)習(xí)到的映射關(guān)系依賴給定的訓(xùn)練樣本輸入特征,除了對(duì)預(yù)測(cè)模型參數(shù)或結(jié)構(gòu)的改善從而提升預(yù)測(cè)性能之外,引入關(guān)于數(shù)值天氣預(yù)報(bào)(numerical weather prediction,NWP)的特征工程也是改善模型預(yù)測(cè)性能的有效手段。目前已有大量研究針對(duì)NWP特征選擇與提取。文獻(xiàn)[14-15]采用最大相關(guān)-最小冗余(minimal redundancy maximal relevance,mRMR)提取NWP特征子集,并分析了不同特征子集對(duì)預(yù)測(cè)精度的影響。文獻(xiàn)[16]采用深度自編碼器對(duì)NWP和歷史功率信息降維,該方法具有優(yōu)越的降維和原像重構(gòu)性能。文獻(xiàn)[17]采用核主成分分析挖掘特征信息,避免“維數(shù)災(zāi)”問(wèn)題,提升了預(yù)測(cè)性能。以上研究表明,NWP特征工程可進(jìn)一步挖掘影響功率的深度信息,不僅減少預(yù)測(cè)模型的訓(xùn)練時(shí)間,也對(duì)預(yù)測(cè)性能也有很大的提升,但沒(méi)有考慮特征重要性程度的差異對(duì)預(yù)測(cè)效果的影響,可引入特征權(quán)重進(jìn)一步優(yōu)化特征空間。
針對(duì)上述問(wèn)題,現(xiàn)提出一種基于NCA特征加權(quán)和Stacking集成學(xué)習(xí)的短期風(fēng)電功率預(yù)測(cè)模型。首先利用NCA計(jì)算歷史樣本的NWP特征權(quán)重,構(gòu)建加權(quán)輸入特征。然后分別構(gòu)建多組異質(zhì)的預(yù)測(cè)器用于預(yù)測(cè)風(fēng)電功率。最后,以多個(gè)預(yù)測(cè)值作為特征輸入,以GPR模型作為結(jié)合器,將風(fēng)電功率預(yù)測(cè)值融合,構(gòu)建Stacking集成預(yù)測(cè)模型。通過(guò)對(duì)2014全球能源預(yù)測(cè)競(jìng)賽實(shí)際風(fēng)電功率數(shù)據(jù)的預(yù)測(cè)分析和比較,驗(yàn)證該方法的有效性和優(yōu)越性。
1 算法原理
1.1 近鄰成分分析原理
近鄰成分分析[18]同屬于度量學(xué)習(xí)和降維領(lǐng)域,學(xué)習(xí)算法基于隨機(jī)K近鄰模型(stochasticK-nearest neighbor,SKNN),以留一驗(yàn)證誤差最小作為優(yōu)化目標(biāo),尋找最優(yōu)特征權(quán)重,其學(xué)習(xí)過(guò)程就是降維過(guò)程,訓(xùn)練結(jié)果為特征權(quán)重。NCA原理如下。
對(duì)于包含n個(gè)樣本的訓(xùn)練集:
S={(xi,yi),i=1,2,…,n}
(1)
式(1)中:xi為p維特征向量;yi為輸出值。學(xué)習(xí)目標(biāo)為根據(jù)輸入特征x在給定的樣本集S下預(yù)測(cè)輸出值y。假定存在一個(gè)隨機(jī)回歸模型具有如下特點(diǎn)。
(1)從S中隨機(jī)選擇一個(gè)樣本Ref(x)作為x的參考點(diǎn)(樣本)。
(2)將x的預(yù)測(cè)值設(shè)置為參考點(diǎn)Ref(x)的輸出值。
該方法選擇最近點(diǎn)的輸出作為預(yù)測(cè)值,類似于1-NN方法。在NCA算法中所有點(diǎn)都有可能被選作參考點(diǎn)。根據(jù)距離函數(shù)dw,與x的鄰近程度越高被選作的參考點(diǎn)的概率越高,dw計(jì)算公式為
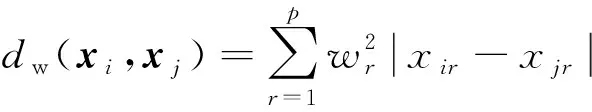
(2)
式(2)中:xir和xjr表示第i個(gè)和第j個(gè)樣本點(diǎn)對(duì)應(yīng)第r個(gè)特征的數(shù)據(jù)值;wr為第r個(gè)特征對(duì)應(yīng)的特征權(quán)重。假設(shè)選中xj為參考點(diǎn)的概率滿足:
P[Ref(x)=xj|S]∝k[dw(x,xj)]
(3)
式(3)中:Ref(x)為從樣本集S中選取出x的參考點(diǎn);k為核函數(shù)或相似性函數(shù);dw越小則k越大,k的表達(dá)式為

(4)
式(4)中:exp表示以自然常數(shù)e為底的指數(shù)函數(shù);σ為核寬度,用于控制每個(gè)點(diǎn)被選中的概率,如果x中所有特征在同一尺度,σ選定為1是合理的,因此在計(jì)算前需要對(duì)數(shù)據(jù)歸一化。
從S中選取某一點(diǎn)xj作為參考點(diǎn)的概率為
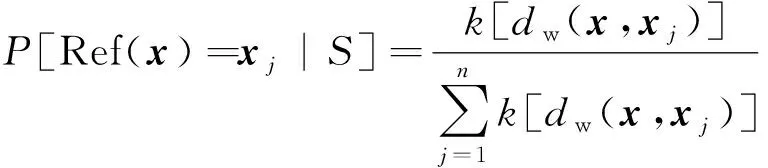
(5)
式(5)中:距離度量dw受特征權(quán)重wr影響,從而間接影響xj被選作參考點(diǎn)的概率。
為調(diào)整模型中特征權(quán)重wr,使用留一法預(yù)測(cè)S中xi的輸出值,此時(shí)訓(xùn)練集S-i中不包含樣本(xi,yi),則xj被選作xi參考點(diǎn)的概率為
pij=P[Ref(xi)=xj|S-i]
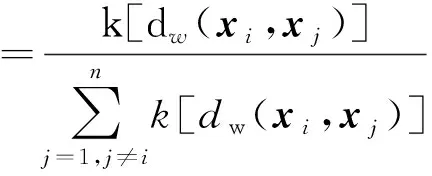
(6)
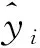
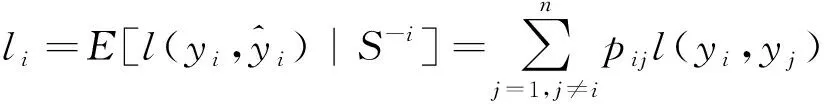
(7)
式(7)中:E為期望運(yùn)算。在此基礎(chǔ)上引入正則項(xiàng),作為最小化目標(biāo)函數(shù):
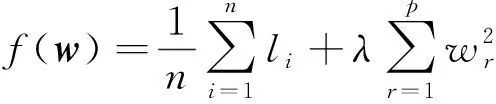
(8)
式(8)中:w為由特征權(quán)重wr構(gòu)成的向量;正則化參數(shù)λ> 0,可以驅(qū)使w中某些特征權(quán)重變?yōu)?。根據(jù)給定的超參數(shù)σ和λ,優(yōu)化任務(wù)為尋找合適的權(quán)重向量w使目標(biāo)函數(shù)最小化:
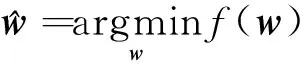
(9)
該優(yōu)化問(wèn)題的最終解w元素的大小反映了各個(gè)特征的權(quán)重,從而實(shí)現(xiàn)特征選擇和加權(quán)的功能。
1.2 Stacking集成預(yù)測(cè)原理
集成學(xué)習(xí)是一種模型融合的框架,可以將不同預(yù)測(cè)模型融合以改善單一模型的預(yù)測(cè)精度或泛化能力[19],在預(yù)測(cè)領(lǐng)域中稱為集成預(yù)測(cè),包含基預(yù)測(cè)器和結(jié)合策略兩個(gè)重要部分。集成預(yù)測(cè)模型中基預(yù)測(cè)器應(yīng)具備較好的預(yù)測(cè)能力且具有較大的差異性,差異性在于預(yù)測(cè)器采用不同的數(shù)據(jù)結(jié)構(gòu)或?qū)W習(xí)算法訓(xùn)練,從不同的空間觀測(cè)角度反映NWP特征到風(fēng)電功率的映射關(guān)系。傳統(tǒng)的結(jié)合策略以簡(jiǎn)單平均或加權(quán)平均為主,當(dāng)樣本規(guī)模較大時(shí)以機(jī)器學(xué)習(xí)模型作為結(jié)合策略可以進(jìn)一步提升模型的預(yù)測(cè)性能,作為結(jié)合策略的模型稱為元學(xué)習(xí)器或結(jié)合器,該方法即為Stacking集成預(yù)測(cè)。和其他集成方法一樣,Stacking集成預(yù)測(cè)模型關(guān)注基預(yù)測(cè)器的差異性,而改善預(yù)測(cè)性能的任務(wù)由結(jié)合器完成。
在Stacking集成模型中,結(jié)合器同樣需要學(xué)習(xí)產(chǎn)生,訓(xùn)練結(jié)合器的樣本輸入是基預(yù)測(cè)器的輸出,輸出對(duì)應(yīng)原樣本的輸出。由于基預(yù)測(cè)器對(duì)原訓(xùn)練集的擬合程度很高,如果直接用基預(yù)測(cè)器的訓(xùn)練集產(chǎn)生結(jié)合器的訓(xùn)練集,容易導(dǎo)致最終模型過(guò)擬合,即結(jié)合器無(wú)法學(xué)習(xí)到結(jié)合策略對(duì)應(yīng)的映射關(guān)系。因此一般采用k折交叉驗(yàn)證或留出法分別訓(xùn)練兩層模型。以留出法為例,按比例將歷史樣本集劃分為訓(xùn)練集和測(cè)試集。首先通過(guò)訓(xùn)練集訓(xùn)練多個(gè)基預(yù)測(cè)器,訓(xùn)練完成后,將驗(yàn)證集樣本的輸入特征輸入基預(yù)測(cè)器,預(yù)測(cè)值和驗(yàn)證集的輸出構(gòu)成結(jié)合器的訓(xùn)練樣本。采用留出法的Stacking模型學(xué)習(xí)流程的偽代碼如表1所示。留出法適用于樣本數(shù)量較多的情況。而k折交叉驗(yàn)證將上述過(guò)程遍歷k輪,可得到數(shù)量相同的樣本用于結(jié)合器的訓(xùn)練。但每次遍歷都需要重新訓(xùn)練基預(yù)測(cè)器,計(jì)算開(kāi)銷較大,在大規(guī)模的樣本集的預(yù)測(cè)任務(wù)中難以適用。

表1 Stacking集成預(yù)測(cè)流程
2 短期風(fēng)電功率預(yù)測(cè)模型的建立
2.1 集成預(yù)測(cè)模型的基預(yù)測(cè)器和結(jié)合器
模型輸入特征為預(yù)測(cè)時(shí)刻的NWP數(shù)據(jù),來(lái)源于氣象部門的預(yù)測(cè),數(shù)據(jù)含有噪聲,基預(yù)測(cè)器應(yīng)具有較好的魯棒性。因此選取GPR、SKNN、分類回歸樹(shù)(classification and regression tree, CART)、LSSVM和極限學(xué)習(xí)機(jī)(extreme learning machine, ELM)作為基預(yù)測(cè)器,同時(shí)選取GPR作為結(jié)合器。各個(gè)模型的原理和特點(diǎn)如下。
(1)SKNN:傳統(tǒng)的KNN模型預(yù)測(cè)值根據(jù)確定的K個(gè)近鄰的輸出值表示,在SKNN中所有的樣本都可能被選作近鄰,被選中的概率由相似性函數(shù)給出,SKNN的預(yù)測(cè)值即為期望值。
(2)GPR:基于貝葉斯框架實(shí)現(xiàn)映射函數(shù)從先驗(yàn)分布到后驗(yàn)分布的轉(zhuǎn)換,同時(shí)也是一種基于核函數(shù)的方法,訓(xùn)練過(guò)程就是超參數(shù)尋優(yōu)的過(guò)程。
(3)CART:基于樹(shù)形結(jié)構(gòu),通過(guò)一系列決策過(guò)程實(shí)現(xiàn)分類或回歸功能。CART采用二分法簡(jiǎn)化決策樹(shù)規(guī)模,使用基尼系數(shù)作為劃分變量的標(biāo)準(zhǔn),生成效率高,魯棒性好。
(4)LSSVM:通過(guò)核函數(shù)將原始特征映射至高維空間進(jìn)行回歸,將SVM訓(xùn)練中的凸優(yōu)化過(guò)程轉(zhuǎn)化為求解線性方程組,提高了訓(xùn)練速度。模型的性能對(duì)懲罰因子和核參數(shù)較為敏感。
(5)ELM:網(wǎng)絡(luò)結(jié)構(gòu)基于傳統(tǒng)的單隱層神經(jīng)網(wǎng)絡(luò),輸入層和隱含層的權(quán)值閾值隨機(jī)產(chǎn)生,隱含層輸出層的權(quán)值通過(guò)線性方程組求解得出,較傳統(tǒng)的BP算法具有訓(xùn)練速度極快、泛化性強(qiáng)等優(yōu)點(diǎn)。
基預(yù)測(cè)器SKNN、GPR和LSSVM中含有距離度量結(jié)構(gòu),采用加權(quán)NWP特征可強(qiáng)化關(guān)鍵特征對(duì)距離度量的影響程度,進(jìn)而改善模型預(yù)測(cè)性能。此外,權(quán)重大的特征具有更大的方差和取值范圍,進(jìn)而具有更大影響程度,因此也選用加權(quán)特征作為CART和ELM的輸入。
采用留出法的方式訓(xùn)練Stacking預(yù)測(cè)模型,避免訓(xùn)練時(shí)間過(guò)長(zhǎng)。考慮到在預(yù)測(cè)時(shí)刻N(yùn)WP特征已知,為了使訓(xùn)練出的模型更適用于預(yù)測(cè)時(shí)刻的情景,采用加權(quán)KNN搜索選取與預(yù)測(cè)時(shí)刻中樣本相似度最高的一部分樣本作為驗(yàn)證集,這部分樣本可以訓(xùn)練結(jié)合器使之沿著適應(yīng)預(yù)測(cè)時(shí)刻樣本的方向修正基預(yù)測(cè)器的預(yù)測(cè)結(jié)果。
2.2 預(yù)測(cè)流程
預(yù)測(cè)流程主要包括NWP特征選擇與加權(quán)、訓(xùn)練Stacking集成預(yù)測(cè)模型和預(yù)測(cè)3個(gè)方面。短期風(fēng)電功率集成預(yù)測(cè)流程如圖1所示,步驟描述如下。
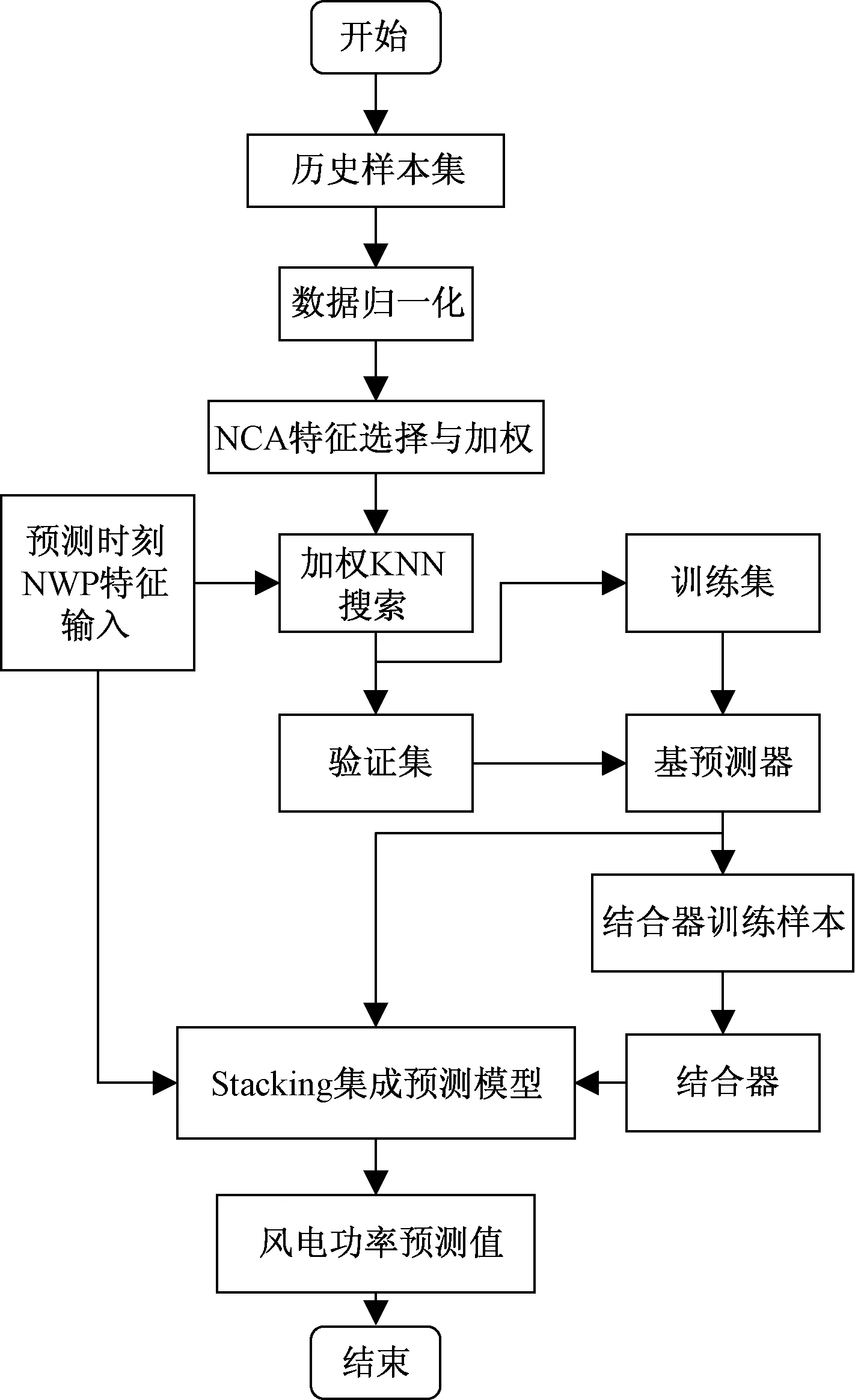
圖1 風(fēng)電功率預(yù)測(cè)流程Fig.1 Flow chart of wind power prediction
步驟1以歷史數(shù)據(jù)的NWP氣象驗(yàn)證和風(fēng)電功率構(gòu)建歷史樣本集和預(yù)測(cè)時(shí)刻的輸入特征,并將樣本數(shù)據(jù)歸一化。
步驟2采用NCA計(jì)算模型歷史樣本的輸入特征權(quán)重,并對(duì)篩選后的特征加權(quán)。
步驟3根據(jù)預(yù)測(cè)時(shí)刻輸入特征采用加權(quán)KNN算法在歷史樣本中所搜相似樣本,將歷史樣本劃分為訓(xùn)練集和驗(yàn)證集,訓(xùn)練Stacking集成預(yù)測(cè)模型。
步驟4將預(yù)測(cè)時(shí)刻N(yùn)WP特征輸入集成預(yù)測(cè)模型,得到風(fēng)電功率預(yù)測(cè)值。
2.3 預(yù)測(cè)評(píng)價(jià)指標(biāo)
選取標(biāo)準(zhǔn)均方根誤差(ENRMSE)和標(biāo)準(zhǔn)平均相對(duì)誤差(ENMAPE)作為衡量預(yù)測(cè)精度的評(píng)價(jià)準(zhǔn)則[20],計(jì)算公式為
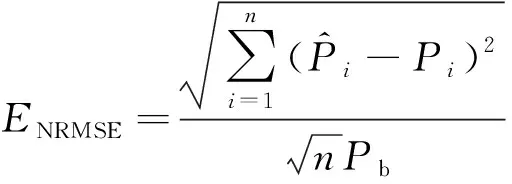
(10)
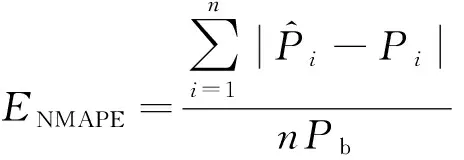
(11)
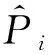
3 算例分析
基于2014全球能源預(yù)測(cè)競(jìng)賽數(shù)據(jù)進(jìn)行建模與算例分析。原始數(shù)據(jù)包含10個(gè)風(fēng)電場(chǎng)的功率出力,以及同時(shí)刻10 m和100 m高的經(jīng)向和緯向風(fēng)速的預(yù)測(cè)值,時(shí)間分辨率為1 h。數(shù)據(jù)中10個(gè)風(fēng)電場(chǎng)的具體位置未被披露,但預(yù)測(cè)某一風(fēng)電場(chǎng)功率出力時(shí)依然可以考慮場(chǎng)外數(shù)據(jù)[21]。因此選取10個(gè)風(fēng)電場(chǎng),共40組風(fēng)速數(shù)據(jù)作為輸入特征,以3號(hào)風(fēng)電場(chǎng)的功率出力作為輸出值,構(gòu)建原始樣本集。考慮到風(fēng)電功率對(duì)風(fēng)速更敏感,將原始特征的經(jīng)緯風(fēng)速轉(zhuǎn)換為風(fēng)速和風(fēng)向特征。
選取兩組預(yù)測(cè)時(shí)段作為測(cè)試集,分別為2012年9月7—13日和2013年3月7—13日。每組測(cè)試集預(yù)測(cè)時(shí)刻點(diǎn)數(shù)為168,并將前180日數(shù)據(jù)作為訓(xùn)練集。
3.1 NCA氣象特征加權(quán)及驗(yàn)證
采用NCA計(jì)算預(yù)測(cè)時(shí)刻N(yùn)WP特征權(quán)重,原始數(shù)據(jù)采用Z-score歸一化,內(nèi)核寬度σ設(shè)置為1。模型中正則化參數(shù)λ采用貝葉斯優(yōu)化算法尋優(yōu)(圖2),搜索區(qū)間為(0, 1],根據(jù)加權(quán)SKNN在訓(xùn)練集的5折交叉驗(yàn)證的預(yù)測(cè)均方誤差作為目標(biāo)函數(shù),最終λ設(shè)置為0.001 4。經(jīng)計(jì)算得到各個(gè)特征的權(quán)重分布如圖3所示。
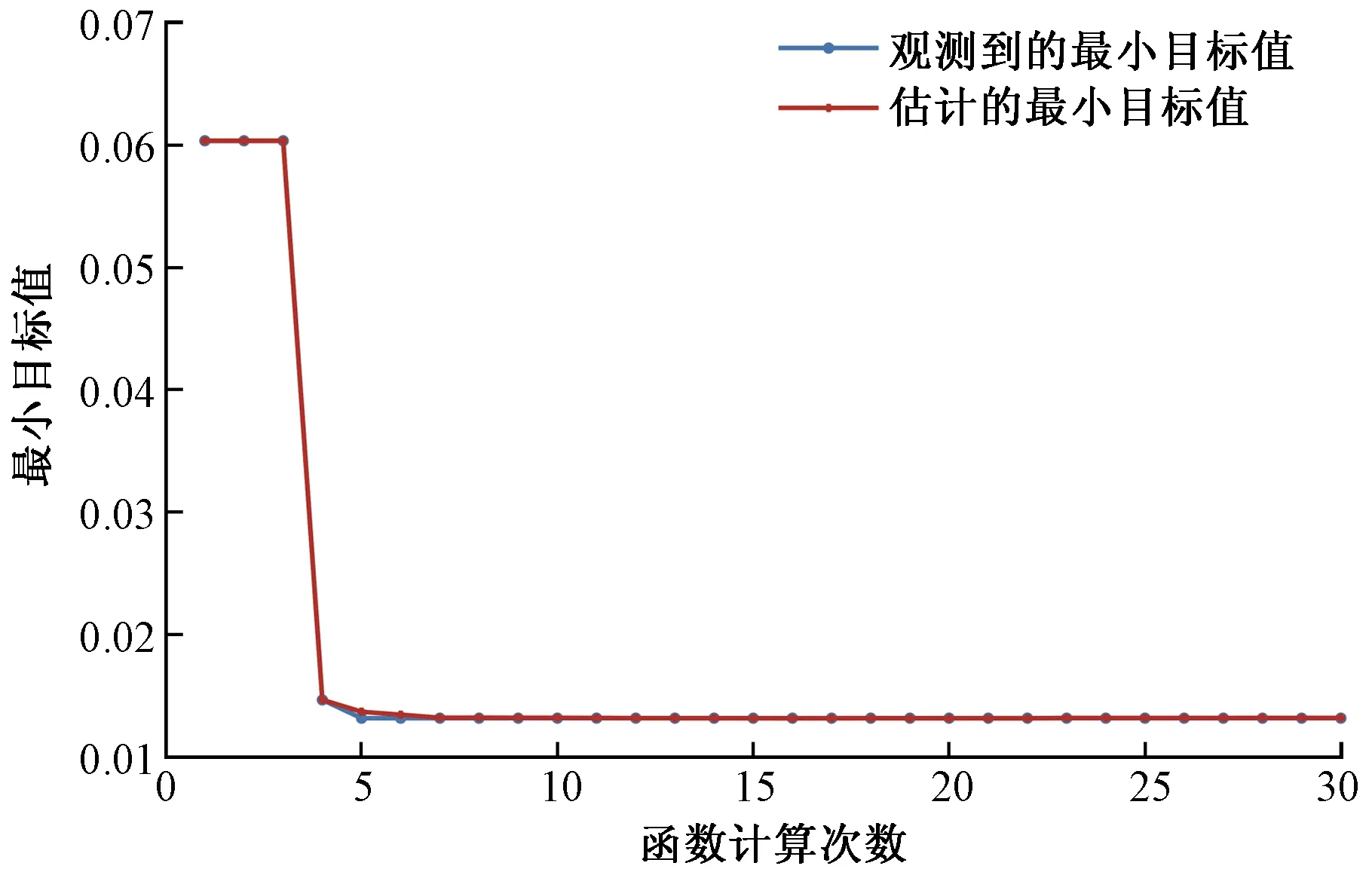
圖2 λ尋優(yōu)過(guò)程Fig.2 Optimization process of λ
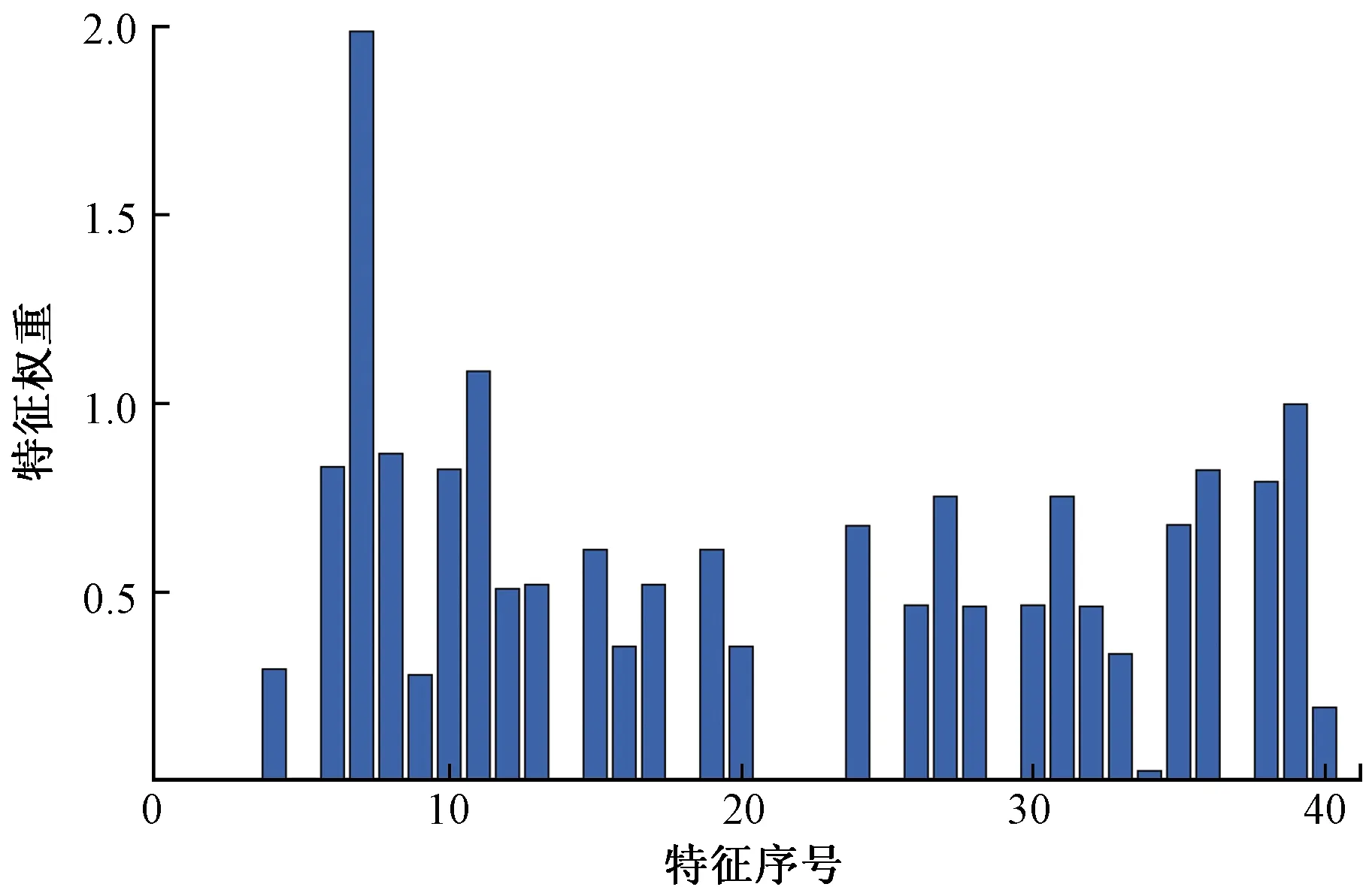
圖3 特征權(quán)重分布Fig.3 Feature weight distribution
為驗(yàn)證NCA特征加權(quán)的有效性,選取mRMR、主成分分析(principal component analysis,PCA),灰色關(guān)聯(lián)分析(grey relation analysis,GRA)進(jìn)行對(duì)比。其中mRMR計(jì)算出特征的重要性評(píng)分,GRA計(jì)算出每個(gè)特征和功率的關(guān)聯(lián)度,可根據(jù)指標(biāo)分配相應(yīng)的權(quán)重。PCA是一種特征提取方法,變換后的主成分中已經(jīng)包含了重要性信息,因此PCA選取貢獻(xiàn)度大于95%的前12個(gè)主成分作為輸入。將上述加權(quán)特征作為預(yù)測(cè)模型SKNN的輸入特征,計(jì)算不同方法在第一組驗(yàn)證集的預(yù)測(cè)誤差,預(yù)測(cè)誤差如表2所示。
以2012年9月7—13日的預(yù)測(cè)時(shí)段為例,當(dāng)輸入特征為NCA加權(quán)特征時(shí),預(yù)測(cè)誤差最小,其ENRMSE較mRMR降低了3.65%,較GRA降低了3.9%,較PCA降低了4.03%,其ENMAPE同樣優(yōu)于其他特征加權(quán)方法。另一預(yù)測(cè)時(shí)段具有相同的規(guī)律。說(shuō)明基于NCA特征加權(quán)可以有效改善模型的預(yù)測(cè)性能,提高短期風(fēng)電功率預(yù)測(cè)精度,因此在預(yù)測(cè)之前引入NWP特征加權(quán)有效可行的。
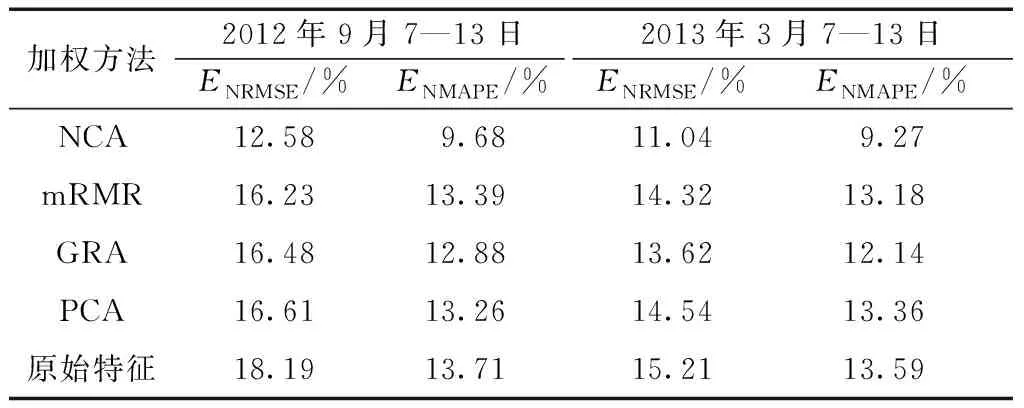
表2 不同特征加權(quán)方法預(yù)測(cè)誤差對(duì)比
3.2 預(yù)測(cè)結(jié)果對(duì)比
在訓(xùn)練之前按照2.2節(jié)中方法劃分訓(xùn)練集和驗(yàn)證集。為了控制訓(xùn)練集和驗(yàn)證集的比例規(guī)模,選取每個(gè)測(cè)試樣本的10個(gè)近鄰樣本作為驗(yàn)證集,最終選取的驗(yàn)證集占?xì)v史樣本比例約為15%。
模型的超參數(shù)都會(huì)對(duì)其預(yù)測(cè)性能有較大影響,為使最終的預(yù)測(cè)效果達(dá)到最優(yōu),需要對(duì)超參數(shù)進(jìn)行尋優(yōu)。基預(yù)測(cè)器SKNN預(yù)測(cè)過(guò)程基于訓(xùn)練樣本,不包含任何參數(shù)。其余模型的超參數(shù)優(yōu)化根據(jù)預(yù)測(cè)時(shí)段2012年9月7—13日的訓(xùn)練集計(jì)算得出,最終確定的超參數(shù)結(jié)果如表3所示,另一預(yù)測(cè)時(shí)段的預(yù)測(cè)模型設(shè)置相同的超參數(shù)。
為驗(yàn)證Stacking集成方法對(duì)預(yù)測(cè)性能的改進(jìn)和合理性,現(xiàn)將其預(yù)測(cè)結(jié)果和基預(yù)測(cè)器進(jìn)行對(duì)比。兩組預(yù)測(cè)時(shí)段的風(fēng)電功率預(yù)測(cè)曲線和實(shí)際曲線如圖4所示,預(yù)測(cè)誤差ENRMSE和ENMAPE如表4所示。
以預(yù)測(cè)時(shí)段2012年9月7—13日為例,從表4可看出,基預(yù)測(cè)器中SKNN和GPR預(yù)測(cè)精度相當(dāng),優(yōu)于其他3種預(yù)測(cè)器。集成預(yù)測(cè)模型將五組預(yù)測(cè)結(jié)果融合,ENRMSE和ENMAPE較GPR分別降低了0.66%和0.89%,優(yōu)于單一模型。而另一預(yù)測(cè)時(shí)段風(fēng)功率較低且較平穩(wěn),基預(yù)測(cè)器均具有較高的預(yù)測(cè)精度,集成后預(yù)測(cè)誤差ENRMSE和ENMAPE較CART分別降低了1.57%和1.13%,有更顯著的下降。因此,融合多預(yù)測(cè)器的Stacking集成模型可顯著提高預(yù)測(cè)精度。

表3 各類模型的參數(shù)
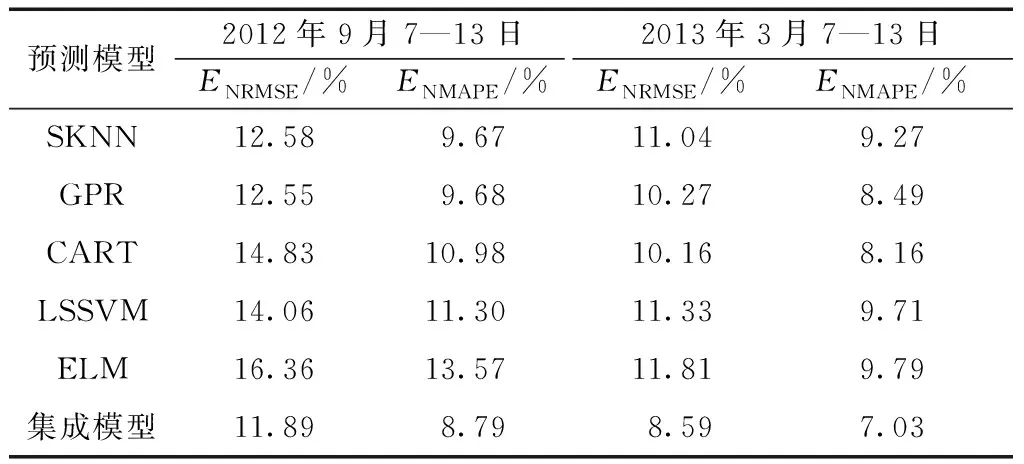
表4 不同預(yù)測(cè)模型預(yù)測(cè)誤差對(duì)比
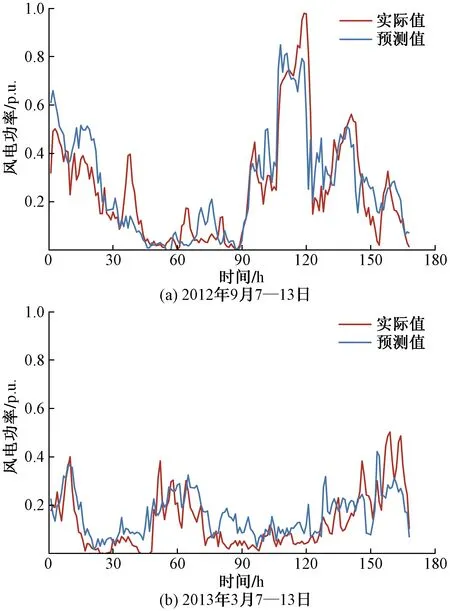
圖4 風(fēng)電功率預(yù)測(cè)曲線Fig.4 Curves of wind power prediction
為進(jìn)一步驗(yàn)證Stacking集成模型以結(jié)合器GPR作為集成策略的有效性,對(duì)不同結(jié)合策略下集成模型的預(yù)測(cè)性能進(jìn)行比較。另選取最小二乘(least squares regression,LSR)回歸,簡(jiǎn)單平均法和基于誤差倒數(shù)加權(quán)平均法作為結(jié)合策略。預(yù)測(cè)曲線和預(yù)測(cè)誤差對(duì)比分別如圖5和表5所示。
對(duì)比表5各個(gè)結(jié)合策略的集成模型可看出,采用簡(jiǎn)單平均法作為結(jié)合策略,得到的集成模型預(yù)測(cè)誤差接近預(yù)測(cè)性能最佳基預(yù)測(cè)器。誤差倒數(shù)法根據(jù)基預(yù)測(cè)器在驗(yàn)證集的誤差ENRMSE倒數(shù)分配組合權(quán)重,較簡(jiǎn)單平均法預(yù)測(cè)性能有所改善,但實(shí)際上由于基預(yù)測(cè)器的誤差比較接近,導(dǎo)致其分配的權(quán)重大小相當(dāng),其性能和簡(jiǎn)單平均法接近。
相較于傳統(tǒng)的結(jié)合策略,以機(jī)器學(xué)習(xí)模型作為結(jié)合策略具有更高的預(yù)測(cè)精度。LSR即線性回歸,學(xué)習(xí)能力弱于GPR,但LSR作結(jié)合器依然使集成模型預(yù)測(cè)誤差有所降低。在兩組預(yù)測(cè)時(shí)段ENRMSE比最佳的基預(yù)測(cè)器降低了0.37%和0.94%,ENMAPE降低了0.34%和0.27%。而學(xué)習(xí)能力更強(qiáng)的GPR作為結(jié)合器進(jìn)一步減少預(yù)測(cè)誤差,ENRMSE進(jìn)一步降低了0.29%和0.63%,ENMAPE降低了0.55%和0.89%。說(shuō)明以學(xué)習(xí)能力更強(qiáng)的GPR作為集成預(yù)測(cè)模型的結(jié)合策略是進(jìn)一步改善集成預(yù)測(cè)性能有效方案。
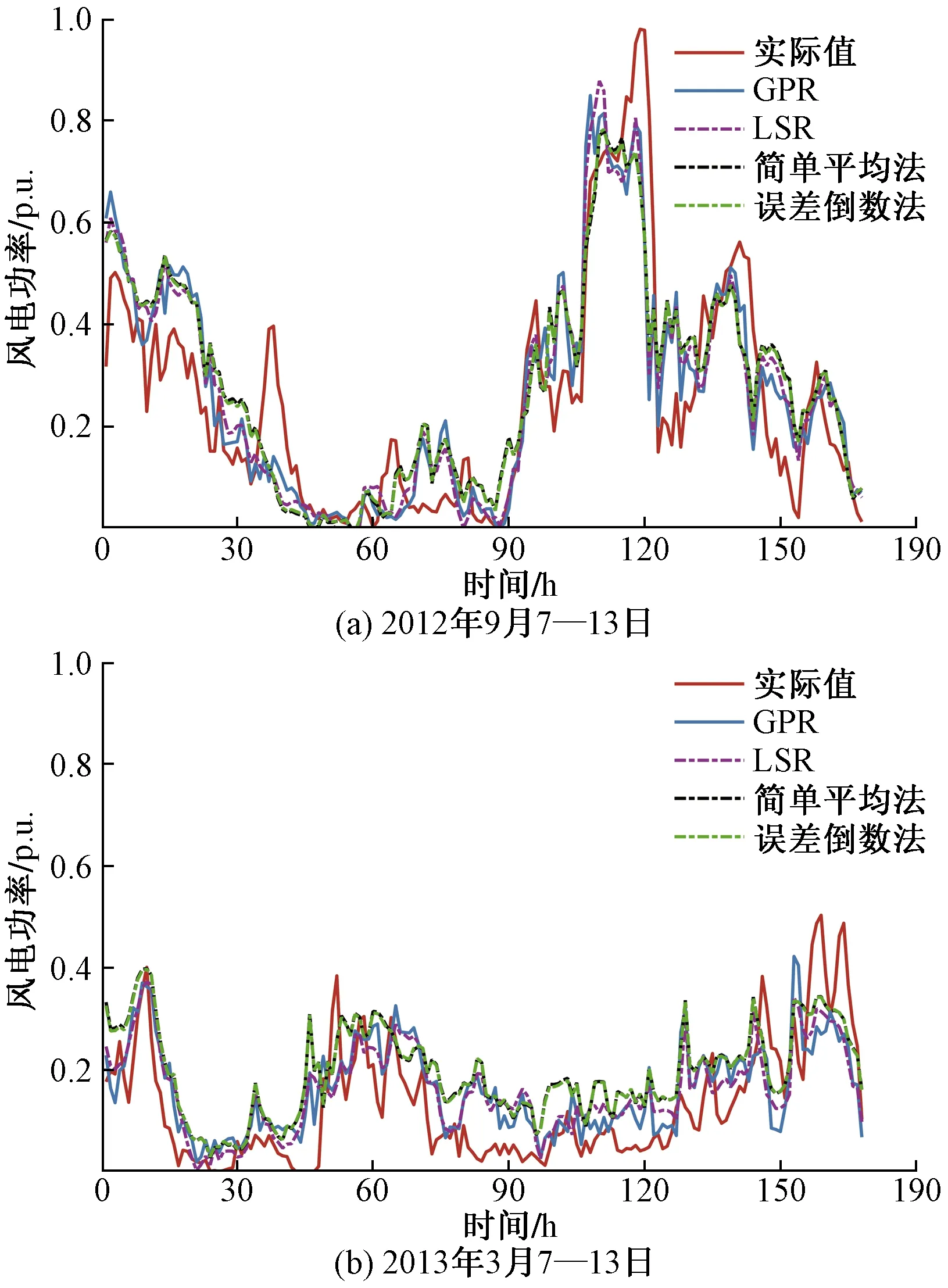
圖5 不同結(jié)合策略風(fēng)電功率預(yù)測(cè)結(jié)果對(duì)比Fig.5 Comparison of wind power prediction results by different combination methods
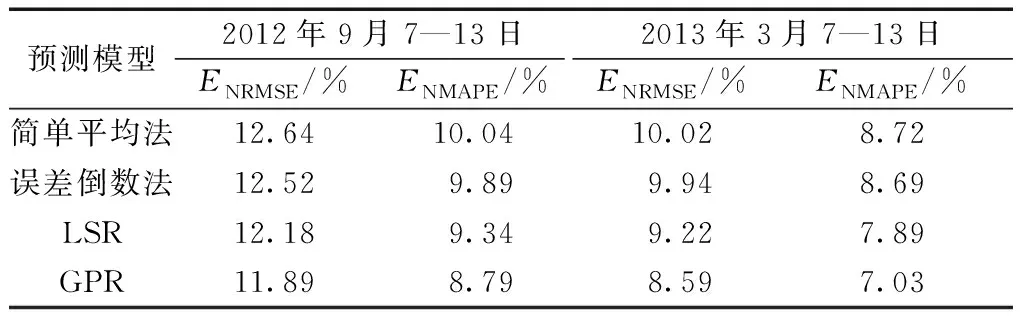
表5 不同結(jié)合策略的預(yù)測(cè)誤差對(duì)比
4 結(jié)論
以提升短期風(fēng)電預(yù)測(cè)精度為目標(biāo),提出一種基于NCA特征加權(quán)和Stacking集成預(yù)測(cè)的短期風(fēng)電功率預(yù)測(cè)模型。經(jīng)過(guò)分析研究,得出以下結(jié)論。
(1)特征權(quán)重可以優(yōu)化特征空間,改進(jìn)模型預(yù)測(cè)性能,NCA特征加權(quán)優(yōu)于其他方法。
(2)集成預(yù)測(cè)模型可以避免單一方法預(yù)測(cè)性能的局限性,得到比單一模型更高的預(yù)測(cè)精度。
(3)相較于簡(jiǎn)單平均法和誤差倒數(shù)法,以學(xué)習(xí)能力較強(qiáng)的GPR作為Stacking集成預(yù)測(cè)模型的結(jié)合策略可進(jìn)一步降低預(yù)測(cè)誤差,其性能優(yōu)于以LSR作為結(jié)合策略的Stacking集成預(yù)測(cè)模型。
預(yù)測(cè)模型的差異性是集成預(yù)測(cè)的關(guān)鍵,本文選取的輸入特征僅考慮了預(yù)測(cè)時(shí)刻,未考慮其時(shí)序性。如何從多特征類型建立集成預(yù)測(cè)模型將是下一步研究的內(nèi)容。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
