多源數據驅動的高速公路服務區運營狀態評價
2022-06-14 10:29:54羅二娟劉文輝原國華趙一翰趙建東
科學技術與工程 2022年14期
關鍵詞:評價
羅二娟, 劉文輝, 原國華, 趙一翰, 趙建東*
(1.山西省交通新技術發展有限公司, 太原 030012; 2.北京交通大學交通運輸學院, 北京 100044)
服務區作為高速公路的窗口,是其不可或缺的重要部分。良好的高速公路服務區服務能力及運營狀態不僅可以提高公眾出行效率與滿意度,還可以傳遞出當地風土人情文化、拉動當地消費水平。
現有高速公路服務區運營狀態研究主要分為信息監測、數據處理以及能力評價三方面。在信息監測方面,張海燕[1]用車位探測器和車位顯示燈進行停車位管理,并連接區域引導信息屏和入口信息顯示屏顯示服務區當前使用信息,使車輛到達服務區前了解停車等信息;黃豪等[2]對服務區氣象、人流、車流、路況等信息全面感知,并進行建模和大數據分析。在數據處理方面,邵奇可等[3]運用出入停車場的車輛信息及車位占用情況匯總,通過全球廣域網端(world wide web,WEB)和手機軟件(application,APP)方式發布,使用戶能在互聯網設備上獲取信息;田佳[4]根據服務區實時車輛駛出與駛入基礎數據、服務區高清卡口系統視頻識別數據、各項服務設施效率等建立高速公路服務區運行指數模型,其中高清卡口系統能識別車牌號、車型并記錄車輛通過時間和車輛信息。卞軍[5]在對服務區大數據進行深入整合后,實現了服務區運營管理、資源分配、車流量預測、路況信息匹配、人流預測、市場營銷等多方關聯應用。在能力評價方面,張海峰等[6]結合天津市高速公路服務區特征,探索研究了區域性高速公路綠色服務區評價指標體系;王殊[7]建立多個服務區橫向評價指標體系,通過逼近理想解排序方法模型(technique for order preference by similarity to an ideal solution,TOPSIS)和距離綜合評價法,依據指標數值大小對多個服務區服務水平進行高低排序。
綜上分析可知,目前中外對于高速公路服務區的服務運營狀態并沒有一個標準的評價體系[8],大多數只是依靠車流,人流等單一數據判斷。因此,本文融合車流、客流、經營數據流等多源數據,制定服務區運營狀態指標體系[9],劃分服務區營運狀態等級,評估預判服務區的運營狀態,為服務區智能運營提供信息支撐[10]。
1 數據處理
1.1 原始數據獲取
圖1所示為山西盂縣服務區信息化建設項目,包括卡口、車位管理、收銀稽查、安防監控、智慧廁所5個系統,在服務區布設了多種智能攝像設備,采用先進的圖像識別算法和技術,實現服務區車輛信息采集、車輛流量監測和統計、客流檢測及管理等功能,為服務區的經營管理提供信息服務。
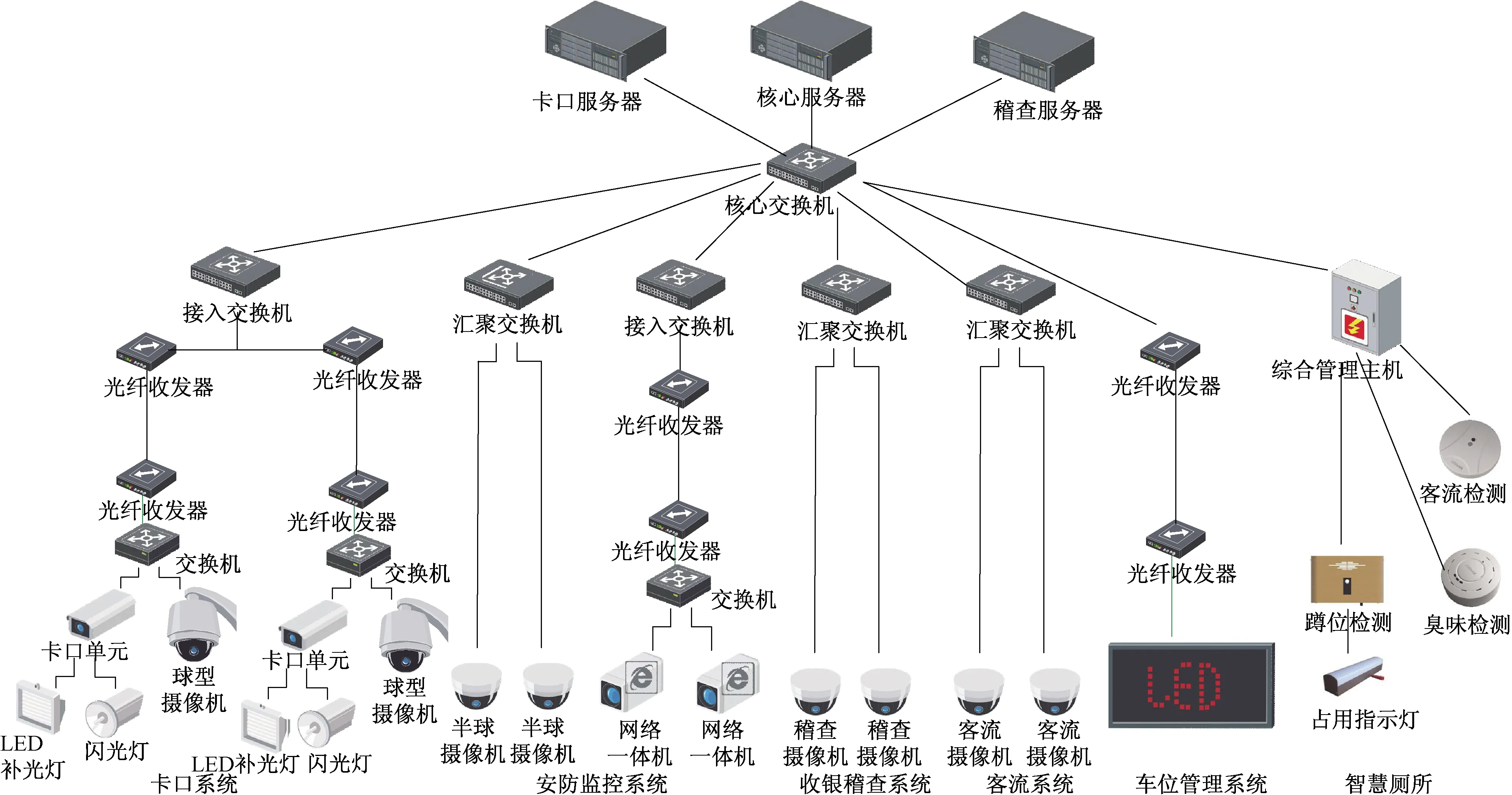
圖1 盂縣服務區信息化系統拓撲結構圖Fig.1 Topology of information system in Yuxian service area
各系統可獲取數據有:①卡口系統:服務區出入口抓拍攝像機,能獲取車輛車牌、車型、歸屬地、進出時間,進而計算出車型比例、歸屬地比例、單車停留時間;②車位管理系統:利用安防監控視頻,采用圖像識別算法,分區域識別剩余車位數量;③安防監控系統:服務區綜合樓各出入口的雙目客流攝像機,獲取進出各門口的客流數據,可得到時段、天的客流曲線;④收銀稽查系統:可獲取每個檔口的收銀數據、每筆訂單的交易清單以及交易場景錄像數據;⑤廁所數據;布設蹲位檢測器、廁位指示燈,在終端實時展示廁位使用情況;通過客流檢測單元、環境采集單元,獲取廁所人流量、溫濕度、臭味濃度數據。
將所采集數據進行分類。如表1所示,包括車流數據、客流數據以及經營現金流3個不同種類數據。所有數據均為每15 min統計一次。

表1 盂縣高速公路服務區多源數據Table 1 Multi-source data of Yuxian expressway service area
1.2 異常數據處理
因采集數據為原始數據,存在數據異常現象,故需對數據進行處理及分析。異常數據類型分為缺失數據及噪聲數據。
1.2.1 缺失數據處理
數據缺失主要是由于數據傳輸、采集、存儲等過程中人為或系統誤差等因素導致,一般如果數據缺失項較多,導致數據完整性下降明顯,則應對該數據作刪除處理。例如,因服務器關閉而導致數據大量缺失,則將這些數據進行刪除處理。此外,如圖2中標黃部分所示的個別數據缺失現象,采用歷史均值法進行填充,即用前后一周同一天同一時刻的平均值填充。
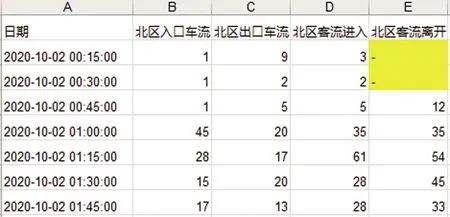
圖2 缺失數據Fig.2 Missing data
1.2.2 噪聲數據處理
噪聲數據定義為數據表內由于一些系統隨機偏差或錯誤產生的和其他數據不一致的部分數據。分析發現有兩類數據可能屬于噪聲數據,一類是在客流高峰時期,突然出現前后15 min內客流變化極大、該時段客流出入為0或者接近于0的數據,取三天南區客流進入數據,如圖3(a)所示,高峰時段,前后兩段時間客流較大,但中間出現客流量為0現象,取某一周時間數據驗證,如圖3(b)所示,發現均存在該現象,故判定該數據為噪聲數據。
另一類是在客流或車流低峰時期,突然出現前后15 min變化極大,車流或客流量較大的值,通過箱型圖觀察數據范圍,篩選出噪聲數據。如圖4所示,數據的最小值為0,最大值為311。上下四分位數分別為19和68,將距離上下四分位數1.5倍四分位距的數據,認為是噪聲數據,如圖5(a)中紅色點所示。將異常數據用前一天同一時刻和后一天同一時刻的數據平均值進行填充,結果如圖5(b)所示。
采用歷史均值法對噪聲數據進行數據填充修復。最終數據處理前后對比如圖6所示,圖6中藍色的線表示未處理前的數據,橙色的線是第一次處理后的數據,綠色的線是處理完成的數據。可以發現,處理后圖線趨勢變得更平穩。
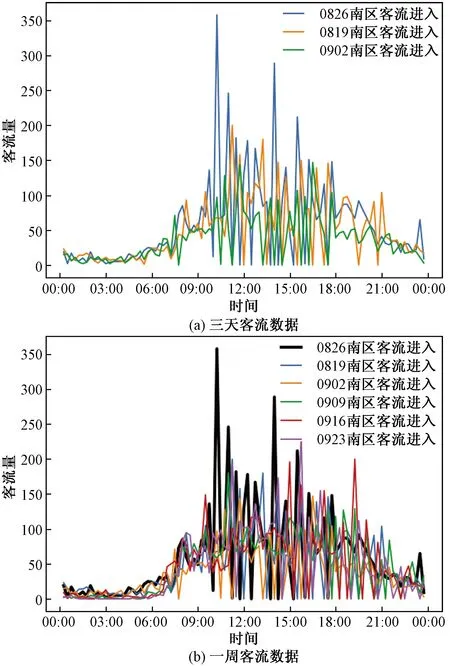
圖3 客流量統計圖Fig.3 Statistical diagram of passenger flow
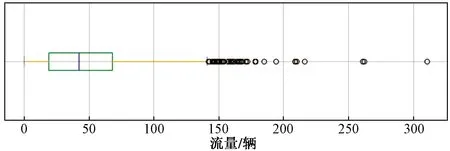
圖4 客流量箱型圖Fig.4 Box chart of passenger flow
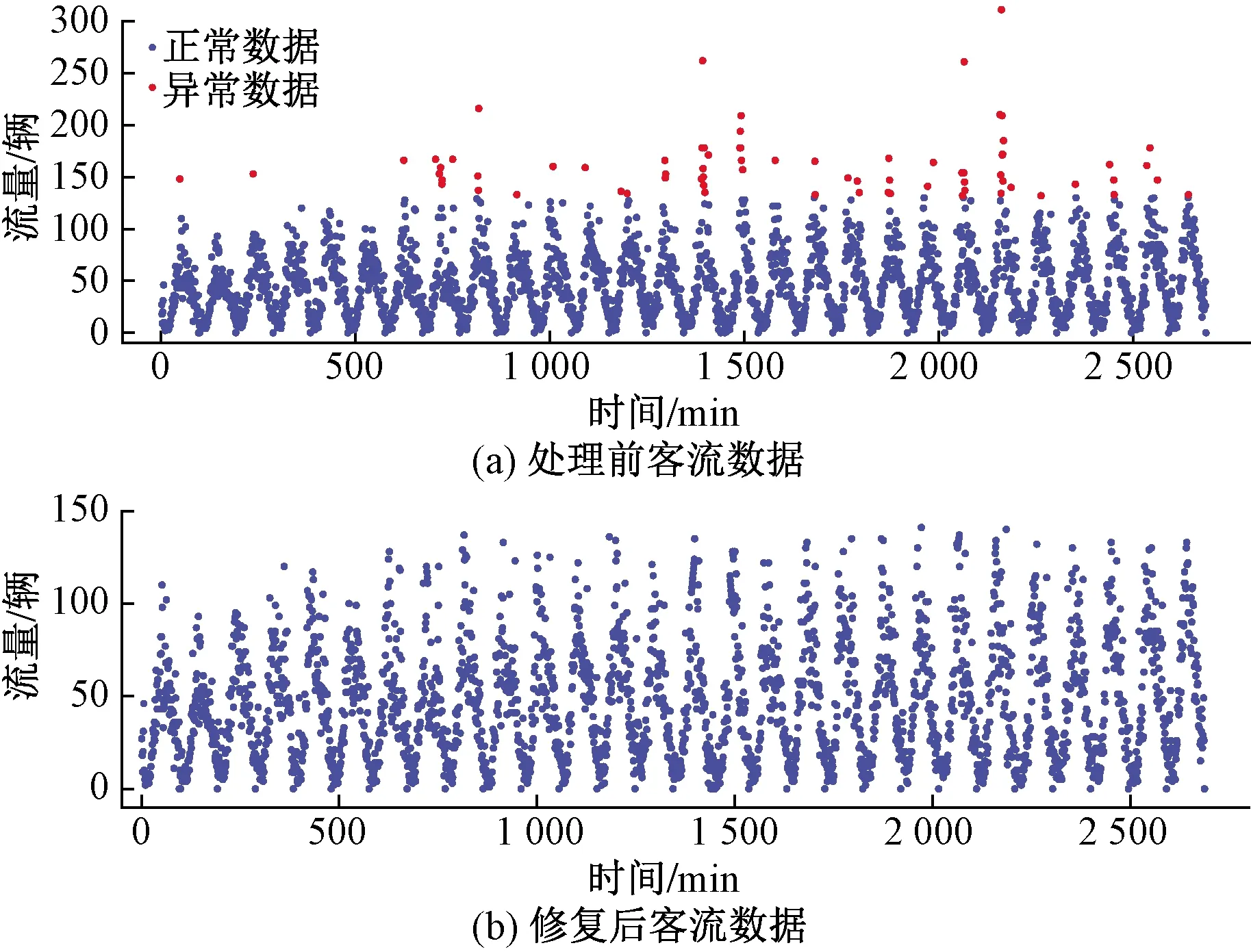
圖5 數據處理前后圖Fig.5 Before and after data processing
圖6 異常數據處理前后對比Fig.6 Comparison of abnormal data before and after processing
1.3 數據特征分析
(1)車流分析。車流分析過程中,先取某一天車流初步總結規律,再取多天車流,驗證規律[11]。發現服務區的南北區入口、出口車流規律大致相同,在中午和下午時間段,車流量較大,且出口車流量峰值總體在對應入口車流量峰值時刻之后,在一周中,休息日和工作日的車流量無明顯差別。
車流出現這種規律可能原因是:11:00左右私家車主進入服務區用餐、休息;在下午時段,可能有部分車主長途駕駛后,進入服務區短暫休息。
(2)客流分析。客流分析過程中,先取某一天客流初步總結規律,再取多天客流,驗證規律。因南北區客流規律相近,故以北區出入客流為例進行分析,可以發現,隨著時間增長,北區客流呈先迅速增長、到達峰值后逐漸下降的趨勢;此外,北區進入客流在12:00左右到達高峰值,離開人數在17:00左右到達峰值。
以周的角度進行分析,選取8月19日至9月23日客流數據,發現隨著時間推移,從8月19日至9月2日,客流人數逐漸減少,可能原因可能是8月19日前后為大學生新生開學季,但這幾周變化不明顯;9月2日人數最少;9月2日至9月23日,后面周三比前面周三人數明顯增多,估計其原因主要是時間上逐漸接近國慶。
2 基于K-means聚類算法的分級評價
K-means算法[12]在聚類過程中其收斂速度較快。當結果簇是密集的,而簇與簇之間區別明顯時, 效果較好,而本文數據正是具有這種特點,較為適合K-means聚類算法,除此之外,該算法的K值可預先設定,可更靈活地設置數據的類別數,從而更好地進行分類。故選擇K-means算法對服務區運營狀態進行分級評價研究。
2.1 K-means聚類算法
2.1.1 算法理論
K-means聚類算法主要思想是:首先確定K個初始的中心點,即確定數據的分類數,之后將每個數據按照距離分配到離其最近的簇中心點所代表的簇中,直至所有的數據都被分配完畢,再根據一個簇內的所有數據重新計算該類簇的中心點(取平均值),然后再迭代的進行分配點和更新類簇中心點的步驟,直至類簇中心點的變化很小,或者達到指定的迭代次數,其基本原理如下:
對于K-means,首先定義一個數據樣本集合Ω,包含了n個對象,其中每個對象都具有d個維度的屬性,如式(1)所示。K-means算法的目標是將n個對象依據對象間的相似性聚集到指定的K個類簇中,每個對象屬于且僅屬于一個其到類簇中心距離最小的類簇中。
Ω={xi|xi=(xi1,xi2,…,xid)},i=1,2,…,n
(1)
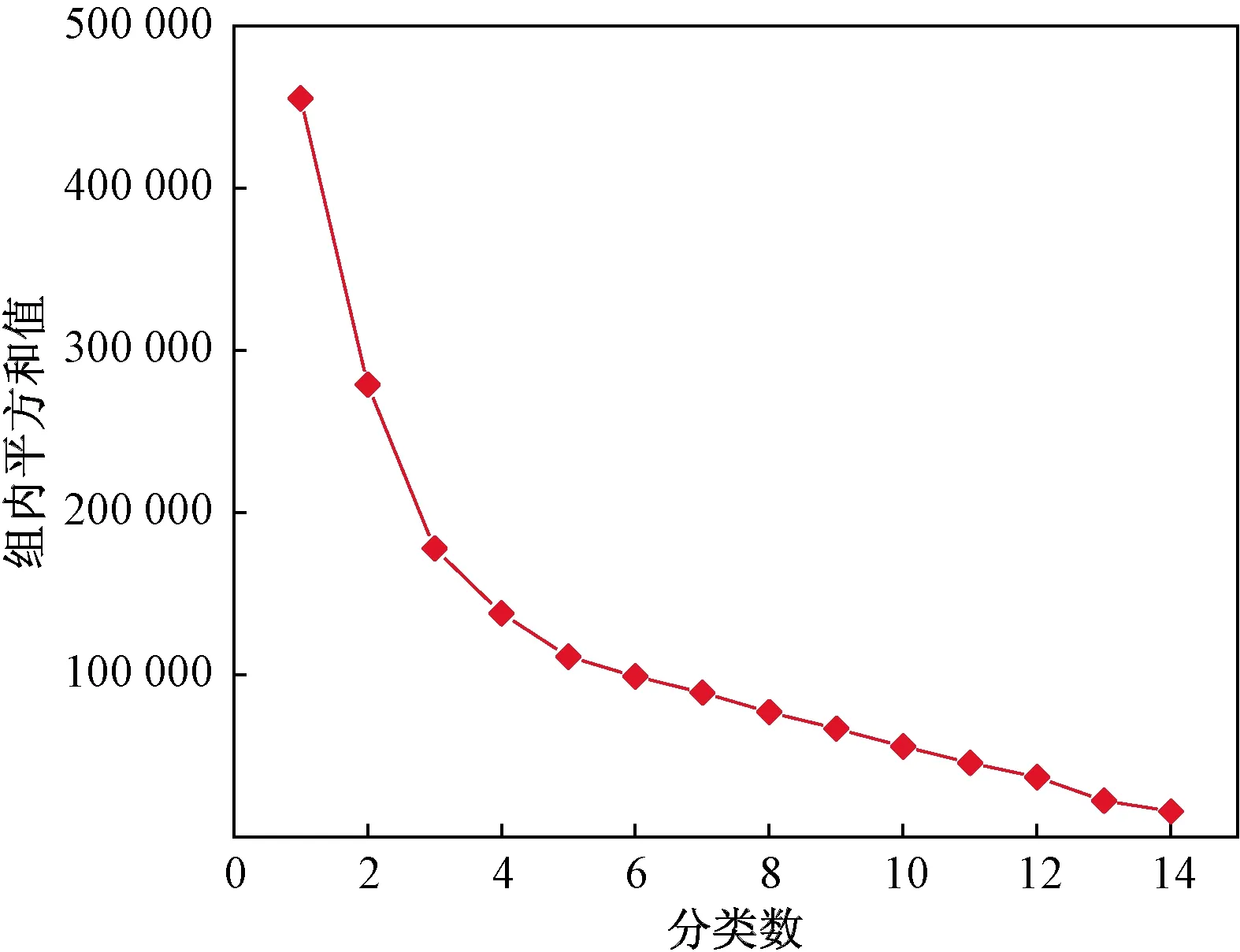
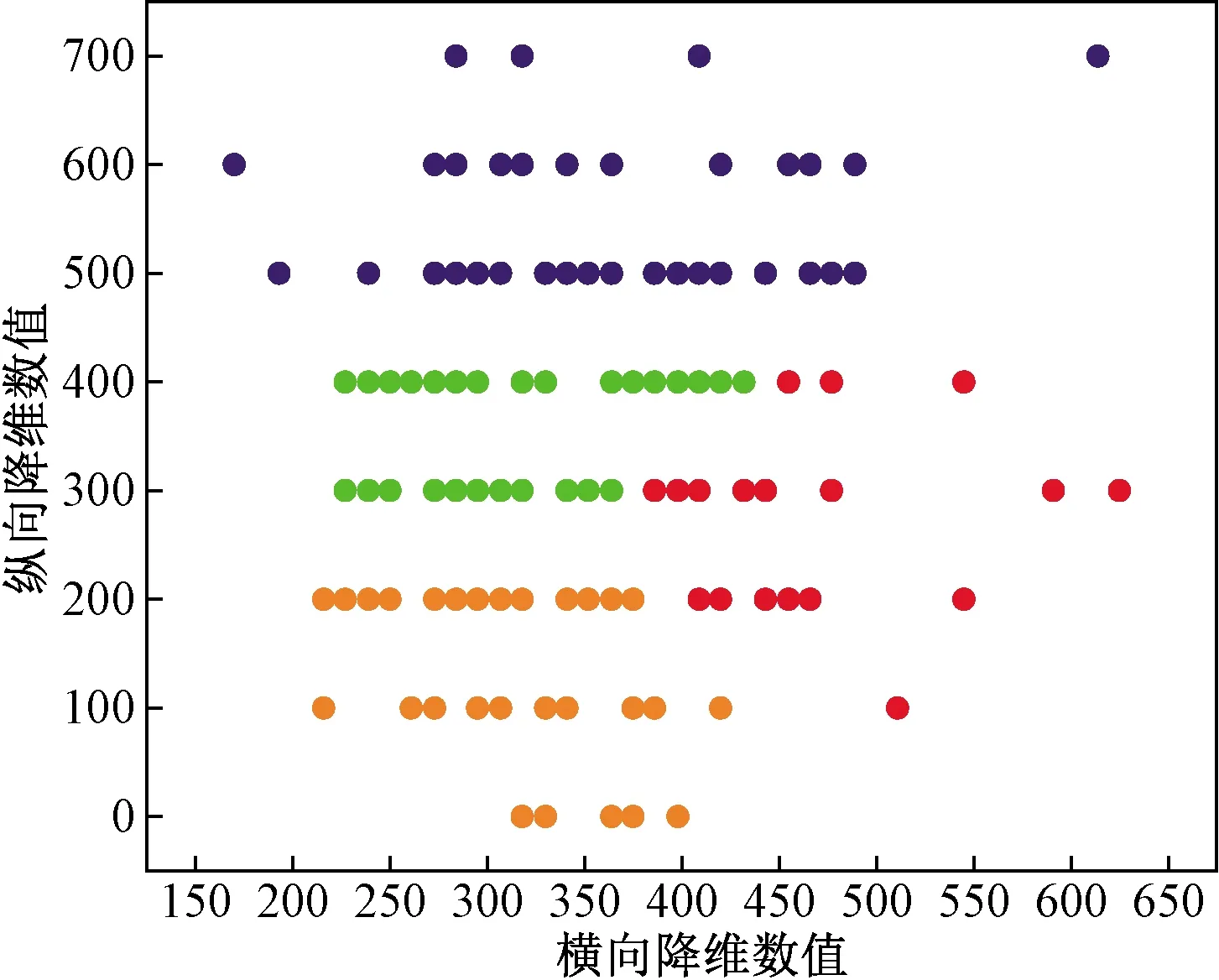
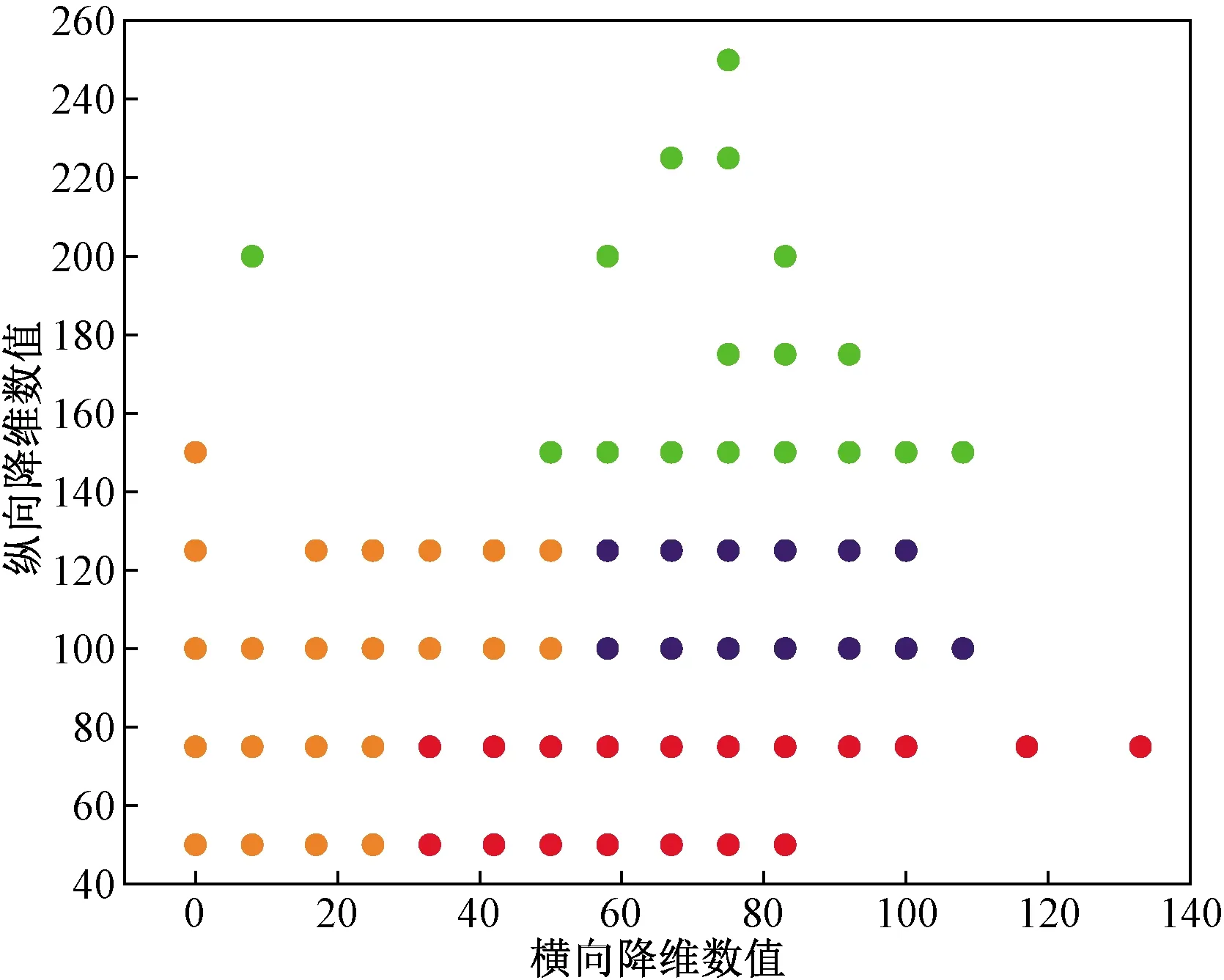
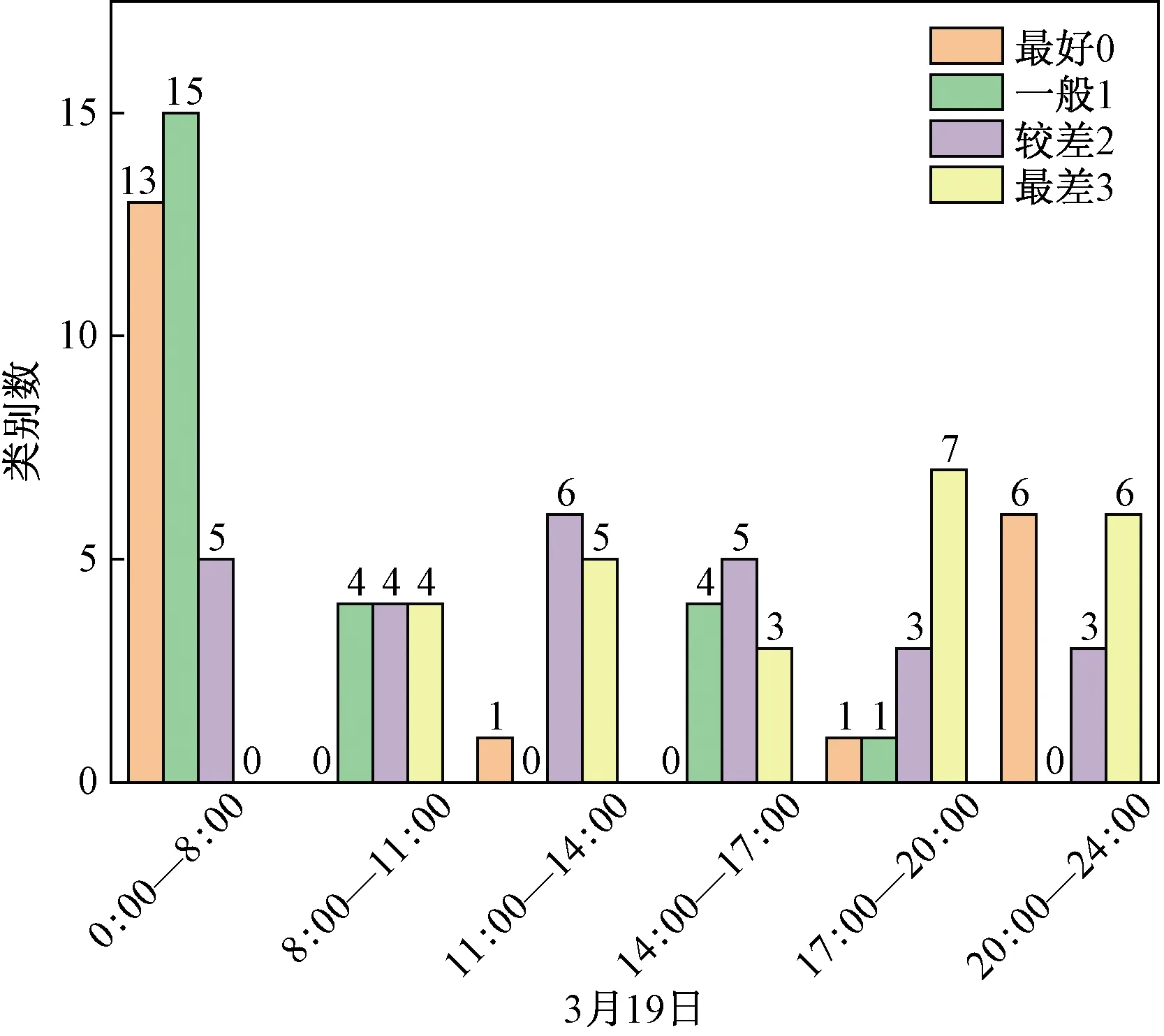
再初始化K(1 C={cj|cj=(cj1,cj2,…,cjd)},j=1,2,…,K (2) 式(2)中:Cj為第j個聚類中心;Cjd為第j個聚類中心的第d個屬性。 然后計算每一個對象到每一個聚類中心的歐氏距離,即 (3) 式(3)中:Xi為第i個對象;Xid為第i個對象的第d個屬性。 依次比較每一個對象到每一個聚類中心的距離,將對象分配到距離最近的聚類中心的類簇中,得到K個類簇。 2.1.2 算法流程 K-means聚類算法具體流程如圖7所示。 圖7 K-means聚類算法流程Fig.7 K-means clustering algorithm flow 2.2.1 數據選擇 由于K-means算法需要不斷迭代來確定數據類別,因此需要大量數據提高其分類準確度。以15 min為周期的數據進行分類研究。 2.2.2K值確定 合理地確定K值和K個初始類簇中心點對于聚類效果的好壞有很大的影響[13]。在統計學中,組內平方和(sum of squares for error,SSE),表示每個水平或組的各樣本數據與其組均值的誤差平方和,反映每個樣本各觀測值的離散情況,又稱誤差平方和或殘差平方和。故采用SSE對K值進行選取,計算公式如式(4)所示。當SSE圖像出現拐點時,該點對應的K即為最佳。 (4) 式(4)中:Ci為第i個簇;p為Ci的樣本點;mi為Ci的質心;SSE為所有樣本的聚類誤差,代表了聚類效果的好壞。 將數據輸入計算得到SSE圖像,如圖8所示。可以看出,該圖像的拐點出現在3~4。因此,理論上可以將服務等級分為3類或4類。 圖8 SSE圖像Fig.8 SSE image 若是選擇將服務等級分為3類,根據后續程序計算輸出結果,可以得出其分類效果并不理想。因此最后決定將服務等級分為4類。 2.2.3 降維處理 因原始數據集是高維數據,難以將聚類效果用圖表現出來,故需要對其進行降維處理,再可視化。使用T分布式隨機相鄰嵌入(T-stochastic neighbor embedding,TSNE)算法將原始高維數據進行降維處理。隨機近鄰嵌入是由SNE (stochastic neighbor embedding,TSNE)衍生出的一種算法,SNE將高維和低維中的樣本分布都看作高斯分布,而TSNE將低維中的坐標當作T分布,這樣可以讓距離大的簇之間的距離拉大,從而解決SNE所產生的擁擠問題。TSNE原理如下。 高維空間中的兩數據點的相似性采用聯合概率Pij度量: (5) 低維空間中的兩個數據點的相似性采用聯合概率qij度量: (6) 為使得高維空間點映射到低維空間后,盡可能保持一樣分布,采用KL(Kullback-Leibler divergence)距離進行衡量。KL距離損失函數為 (7) 梯度的計算公式為 (8) 以盂縣高速公路服務區3月15日—3月21日的一周數據為例。選取盂縣高速公路服務區該日期內午高峰時段(11:00—14:00數據)以15 min為跨度的84組數據,每組數據包括車流情況、客流情況、經營現金流情況。 程序聚類結果如圖9所示,數據橫縱坐標越大,即離原點越遠,代表著該數據所表示的服務區越擁擠,運營狀態越差;反之數據橫縱坐標越小,即離原點越近,代表服務區運營狀態越好。 所評價的3月15日—3月21日一周內每日午高峰時段高速公路服務區運營狀態類別數統計如圖10所示,類別0~3分別代表該時段運營狀態為最好、一般、較差以及最差。 從圖10中可知,3月20日以及3月21日數據的0、1類別較多,而2、3類別較少,判斷這兩天午高峰時段服務區運營狀態較高;而16日、17日的2、3,數據類別較多,0、1類別較少,判斷這兩日午高峰時段服務區運營狀態較差。 圖9 聚類結果Fig.9 Clustering results 圖10 分類結果(周)Fig.10 Classification result (one week) 選取3月19日,以15 min為一個周期的96組數據,每組數據包括車流、客流、經營現金流,與2.2節評價過程一致。程序聚類結果如圖11所示,同樣可以看出聚類效果較好。 從圖12可知,3月19日類別為0的數據多集中于凌晨時段及23:00以后,該時段服務區較為空曠,運營狀態最好。類別為1的數據多集中于凌晨時段,8:00之前以及夜間晚高峰之后,該時段車流量較少,服務區可提供較好服務能力。類別為2的數據多集中于非高峰時段,該時段服務區服務能力一般。類別為3的數據多數集中于高峰時段,該時段服務區人車擁擠,服務區運營狀態較差。 圖11 聚類結果Fig.11 Clustering results 圖12 分類結果(日)Fig.12 Classification result(one day) 研究發現,K-means聚類算法對服務區運營狀態分級評價的判斷結果為:在一周中,3月20日運營狀態最好,而3月17日運營狀態最差。在一天各時段運營狀態分級評價的研究過程中K-means聚類算法的判斷為:凌晨以及白天較早時間段內服務區的運營狀態最好,而在高峰時段以及下午時段服務區較為擁擠,運營狀態較差。 相比于算法,K-means聚類具有如下優缺點:計算機迭代速度很快,并且收斂速度快,適合處理大量數據。且可以任意設定K值,使數據被分成指定的K類。但其并不適合處理較少量的數據,如果數據量較少,其分類結果可能每次迭代都不同,并且極易受異常數據的干擾,使其計算結果受到較大影響。除此之外,雖然理論上可任意設定K值,但如果設定不合理,數據聚類效果將不會理想。而本文以15 min為周期,收集車流、客流以及經營現金流等大量數據,數據量達到計算精度要求,且根據SSE來進行K值選取,分析SSE圖像拐點,選定K為4,此時評價結果較為理想。 利用山西省盂縣服務區監測系統的多源異構數據,從車流情況、客流情況以及服務區經營現金流情況三個角度綜合考慮,使用K-means聚類算法對高速公路服務區數據進行分級評價。得出如下結論。 (1)針對本文研究對象山西省盂縣高速公路服務區的原始數據建立一套數據清洗規則,有效識別出了缺失數據與噪聲數據,并且做了相應的數據刪減和增補,并初步識別了車流、客流規律,邏輯正確且符合實際情況。 (2)以15 min時間粒度整理了一天96個原始數據,從一周同一時段及一天各時段兩個角度出發,運用K-means聚類算法進行分類,綜合分析評判了服務區運營狀態實時變化情況。驗證了夜間車輛少服務能力強,高峰時段運營狀態較差的現象。 (3)綜合評判了K-means聚類算法的特點優劣以及適用范圍。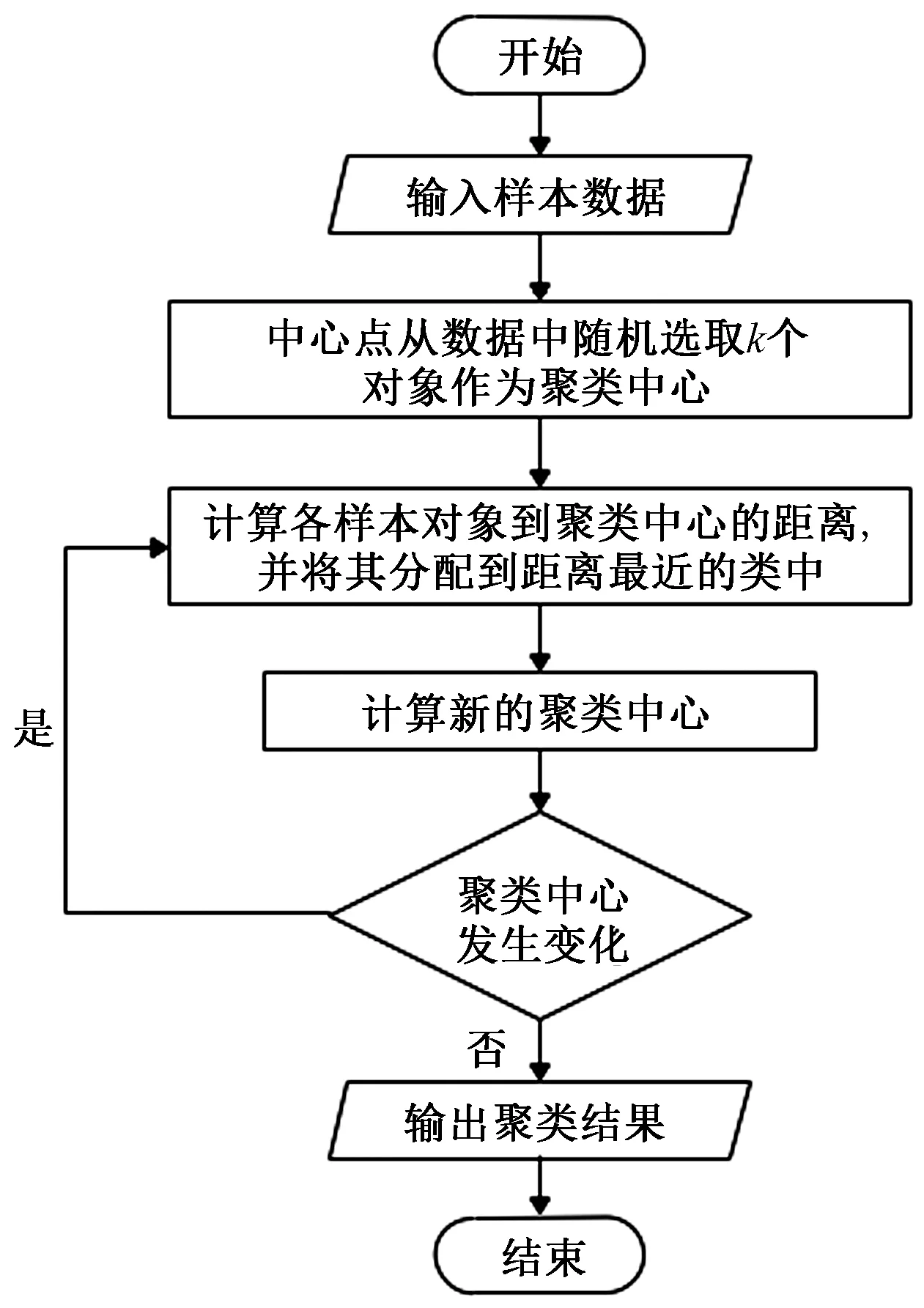
2.2 評價過程
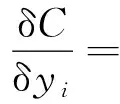
2.3 一周同一時段運營狀態分級評價
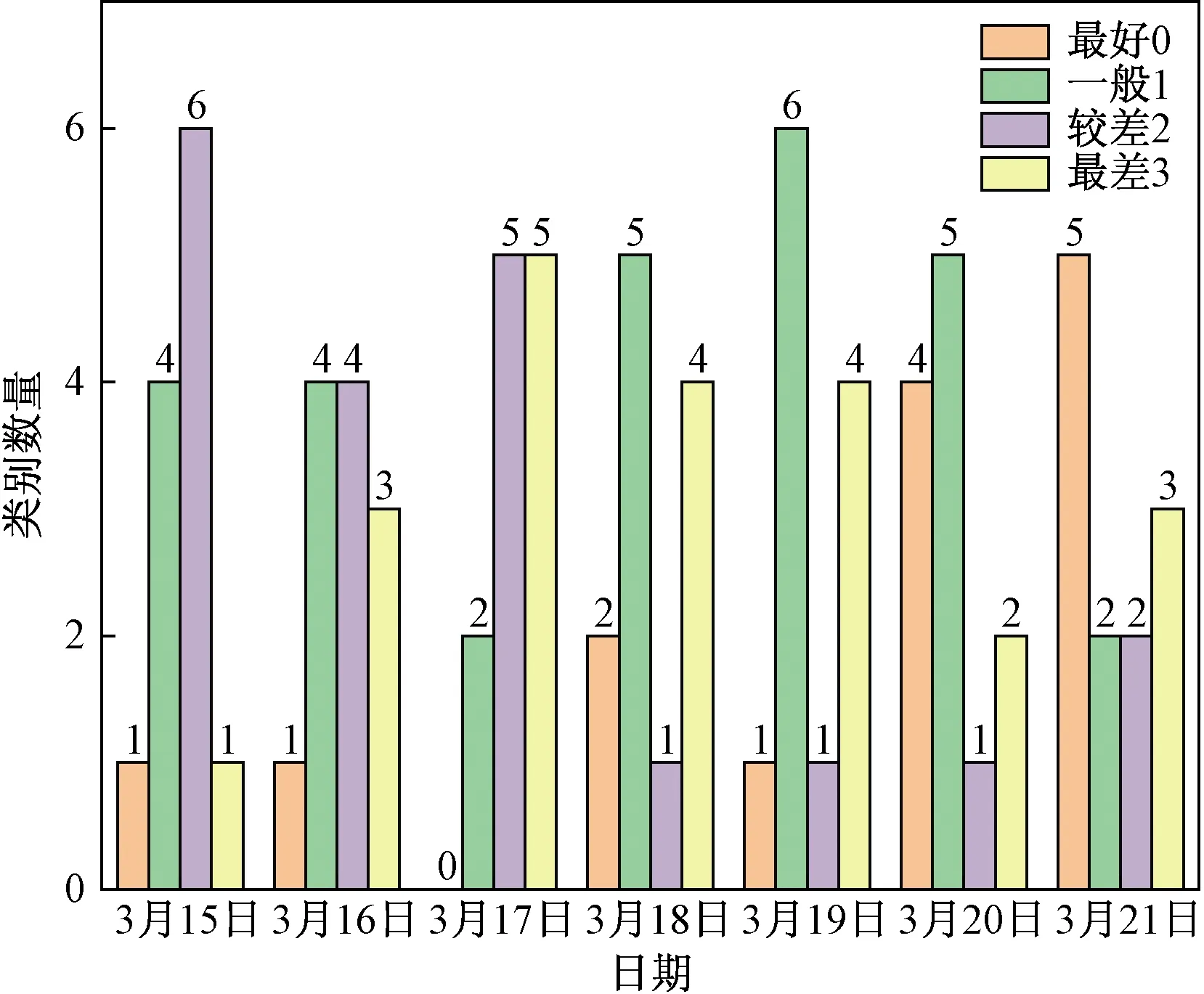
2.4 一天各時段運營狀態分級評價
3 評價方法分析
4 結論
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
現代檢驗醫學雜志(2016年3期)2016-11-15 01:59:56
中學語文(2015年21期)2015-03-01 03:52:11
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
西南軍醫(2015年1期)2015-01-22 09:08:16
中國音樂教育(2014年9期)2014-05-20 10:26:24
治淮(2013年1期)2013-03-11 20:05:18
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
