基于機器學習混合模型的滑坡易發性評價
2022-06-14 10:27:08鄧念東李宇新崔陽陽石輝郭亞雷
科學技術與工程 2022年14期
鄧念東, 李宇新, 崔陽陽, 石輝, 郭亞雷
(西安科技大學地質與環境學院, 西安 710054)
安康市漢濱區地處陜南秦巴山區,坡陡谷深,地質構造復雜,斷裂發育,巖體破碎,松散堆積層廣布,地質環境與自然生態環境脆弱,加之濫砍亂挖等不合理人為因素,致使地質環境嚴重惡化,滑坡、崩塌等地質災害問題十分突出,嚴重威脅人民群眾生命、財產安全,阻礙當地經濟發展[1]。為提供該區域防災減災的基礎依據,現開展漢濱區滑坡易發性評價研究。
自20世紀90年代以來,中外學者展開了大量滑坡易發性評價相關研究,主要集中在評價指標與評價方法的選擇。評價指標通常結合研究區地質環境背景分析,目前尚無統一標準[2]。從評價方法上看,主要分為定性和定量模型[3]。定性評價采用專家經驗進行指標權重賦值,適用于小區域滑坡易發性評價,但具有較強的主觀性[4]。隨著研究的深入,研究方法逐步向半定量以及定量模型過渡。許沖等[5]通過分析斷層、巖性、高程、坡度、坡向、河流、公路7個因素與汶川地震區滑坡分布的關系采用層次分析法賦予因素權重,結果表明滑坡易發性分區效果較好,高易發區滑坡占比達到60.5%。牛瑞卿等[6]采用粗糙集理論對評價因子進行篩選,通過構建支持向量機模型對三峽庫區秭歸至巴東段進行滑坡易發性分區,結果表明預測結果與野外調查情況高度吻合,采用支持向量機進行評價預測能力強、效率高。Hong等[7]采用J48決策樹進行構建自適應提升算法(adaptive boosting,Adaboost)、裝袋算法(bootstrap aggregating,Bagging)及旋轉森林模型,對撫州市廣昌縣滑坡易發性進行對比研究,結果表明三種模型在該區域評價精度均較高,其中旋轉森林模型空間預測適用性更好。劉淵博等[8]采用旋轉森林模型對三峽庫區萬州段滑坡易發性進行研究,結果顯示滑坡高易發區主要集中在萬州主城區和長江及支流兩岸,模型預測精度達90.7%,再次體現機器學習模型預測精度高的特點。連志鵬等[9]分別采用信息量、證據權和頻率比模型進行五峰縣滑坡易發性研究,并通過歸一化、主成分分析和優勢融合,研究表明多模型混合是一種新的評價思路,其分區結果比單一模型更精確。基于前人研究成果,以隨機森林為代表的集成學習模型在滑坡易發性評價中被廣泛采用,為進一步驗證混合模型在滑坡易發性評價的泛化能力,現選取集成學習中具有代表性的自適應提升與隨機森林模型,分別進行單一模型與混合模型評價,采用受試者工作特性曲線(receiver operating characteristic curve,ROC)驗證其預測效果,通過隨機森林模型降低自適應提升模型訓練誤差為滑坡易發性評價方法的改進提供新的思路。
1 研究方法
1.1 自適應提升模型
自適應提升模型由Freund和Schapire率先提出,是一種解決二分類問題的集成學習算法,屬于經典集成學習算法Boosting算法族種的一類[10]。核心思想是通過一個基分類器得到二分類預測結果,根據分類結果計算加權訓練誤差,若誤差大于0.5,重復在訓練集重新生成均勻的權值分布直到誤差滿足小于0.5。再根據滿足誤差要求的分類結果對每個訓練樣本的權值進行調整,使得錯誤分類樣本的權值提高。最終使用加權多數投票規則對基分類器的分類結果進行組合得到各評價單元的滑坡易發性指數(landslide susceptibility index,LSI)。
1.2 隨機森林模型
隨機森林模型是集成學習Bagging算法族的代表算法[11]。首先,對初始訓練集進行多次bootstrap隨機抽樣。每次bootstrap隨機抽樣是指對于有放回的隨機抽樣所組成的新訓練樣本集與初始一致。通過構建決策樹作為基分類器,采用信息增益率在屬性集合中隨機候選最優分裂屬性子集,對每個不同的新訓練樣本集進行訓練,通過樣本與分裂節點的多樣性,從而提高分類的預測準確率。最終通過簡單多數投票原則對各訓練樣本的結果整合。
2 研究區概況及數據源
安康市漢濱區位于陜西省南部山區,108°30′E~109°25′E,32°22′N~33°17′N,轄內共34個鄉鎮(街道),總面積為3 643.5 km2(圖1)。研究區地勢南北高,中部低,最高點為秦嶺佛爺嶺,高程2 135 m,最低點為漢江彭家溝,高程134 m,相對高差2 001 m。地處北亞熱帶濕潤季風氣候區,具有明顯的垂直地帶性特征。平均氣溫15.5 ℃,南北山區氣溫低,中部河谷與丘陵區氣溫高。區內降水具有空間和時間分布不均的特點:多年平均降水量799.3 mm,總的趨勢為自北向南逐漸遞增;降水量年際變化大,70%年內降水集中在7—9月。研究區內河流密集,漢江橫貫研究區南部。區內主要出露地層有震旦系白云母石英片巖、寒武系炭質片巖、奧陶系灰巖、志留系千枚巖、泥盆系鈣質片巖、新近系細砂巖和第四系粉土。

圖1 研究區位置及滑坡編錄圖Fig.1 Location of study area andlandslide catalog
根據《漢濱區地質災害詳細調查報告》(以下簡稱《詳查報告》)和解譯研究區遙感影像,在實地調查的基礎上,共圈定509處滑坡。使用地理信息系統(geographic information system,GIS)將滑坡周界轉為滑坡點,生成滑坡編目圖,區內各行政單元滑坡密度統計如表1所示。滑坡影響因子數據主要由以下方式獲取:①通過“地理空間數據云”平臺下載研究區30 m分辨率的數字高程模型(digital elevation model,DEM)數據,使用表面分析工具獲取坡度、坡向、曲率和地表切割深度因子;②通過矢量化《詳查報告》中1∶50 000地質圖得到地層巖性、斷層數據;③通過清華大學2017年全球地表覆蓋監測數據獲取研究區土地利用數據;④通過研究區氣象站觀測數據獲取多年平均降雨量數據;⑤通過“Bigemap”地圖軟件獲取研究區行政單元劃分、水域及道路矢量化數據。
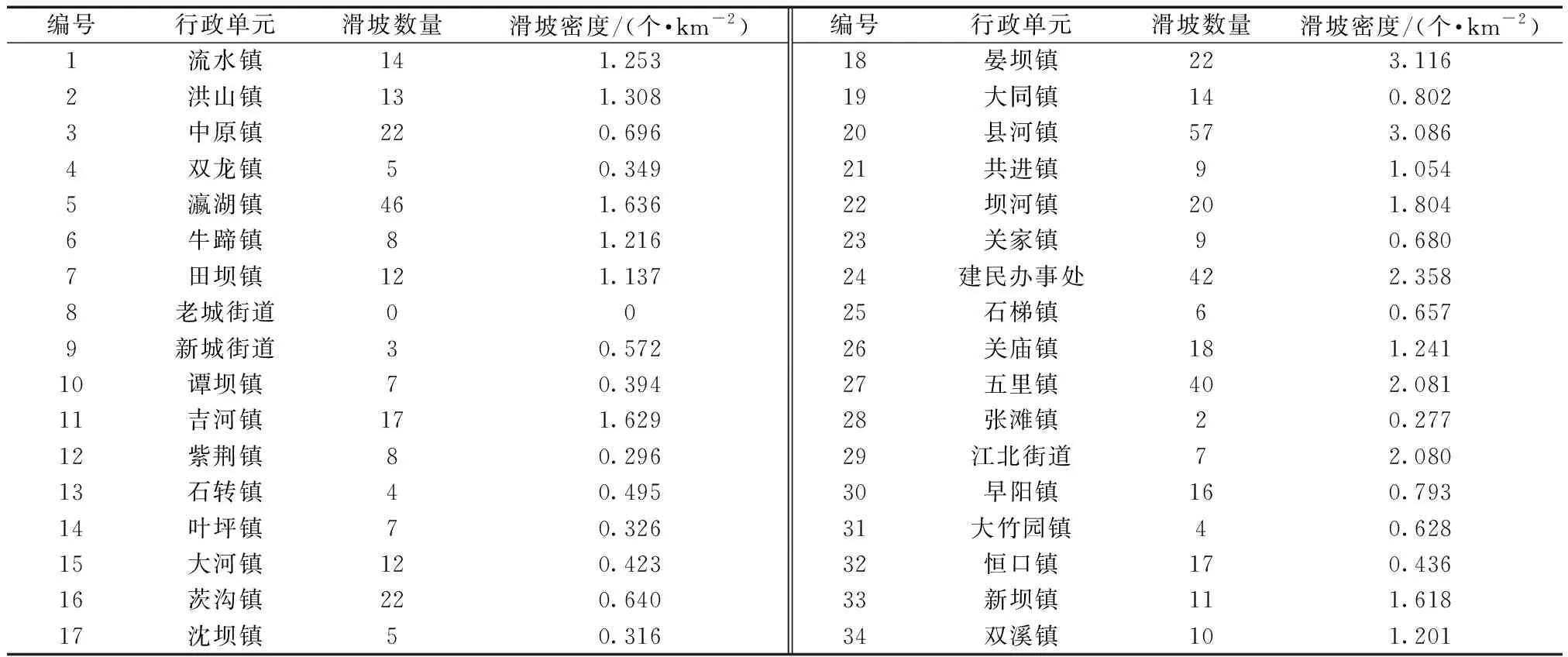
表1 研究區各鎮(街道)滑坡統計Table 1 Landslide statistics of towns (streets) in the study area
3 評價因子的選取
3.1 影響因子選取
參照《詳查報告》中研究區地質環境背景與地質災害形成條件,區內滑坡主要取決于地質環境條件內外力因素共同作用,包括地形的控制、斷層活動的地形改造、低強度的破碎巖石及地表水的側蝕等。從上述數據源中初步選取高程、坡度、坡向、年均降雨量、地層巖性、平面曲率、剖面曲率、土地利用、地表粗糙度、地表切割深度、地形濕度指數(topographic wetness index,TWI)、距斷層距離、距道路距離和距水系距離,在ArcGIS中采用自然間斷法生成研究區影響因子專題圖(圖2)。
3.2 影響因子分析
進一步定量分析研究區滑坡影響因素,可削弱無關因子對評價的不利影響,亦對區內滑坡調查具有借鑒意義。信息增益比是統計學進行特征不確定性選擇的方法,本文用來分析所選因子的重要性[12](圖3)。結果顯示,所選影響因子與研究區孕災均有一定關聯,其中土地利用、高程、地表切割深度、粗糙度、坡度以及地層巖性對滑坡產生更加密切。頻率比分析顯示區內滑坡主要分布在耕地與林地、高程介于134~737 m、地表切割深度介于2.65~83.83 m、粗糙度介于1~1.05、坡度介于10.1°~25.6°及地層為志留系云母石英片巖的區域。
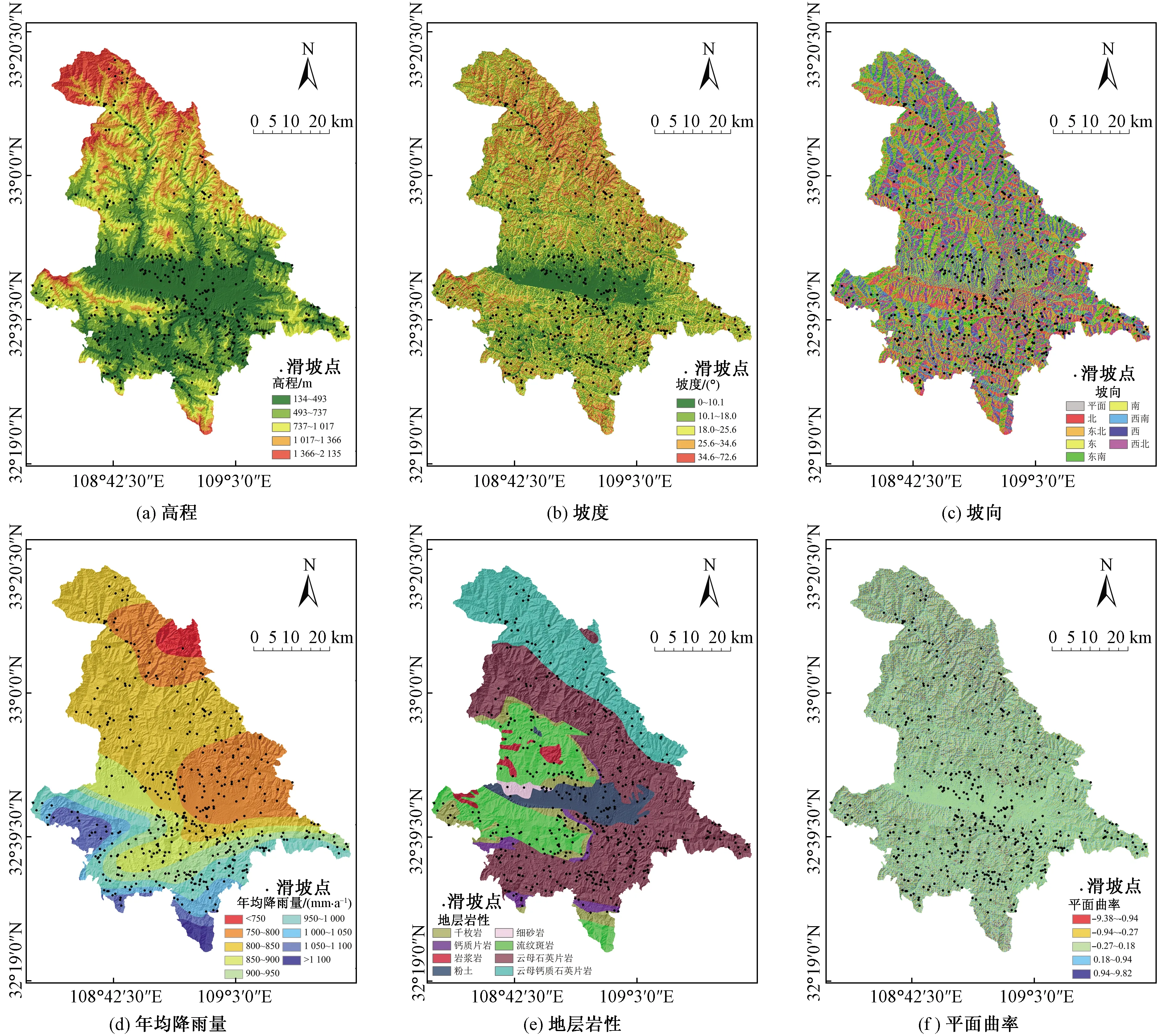

圖2 研究區因子專題圖Fig.2 Study area factor thematic map
機器學習模型對樣本數據集有一定共線性要求,數據間的共線性易造成模型訓練精度下降[13]。通過SPSS軟件進行方差膨脹因子分析(variance inflation factor,VIF)。當VIF大于10時,表示數據間存在嚴重的共線性,需要進行剔除。分析結果如表2所示,剔除粗糙度屬性(VIF為10.966),最終采用剩余13類因子進行評價。
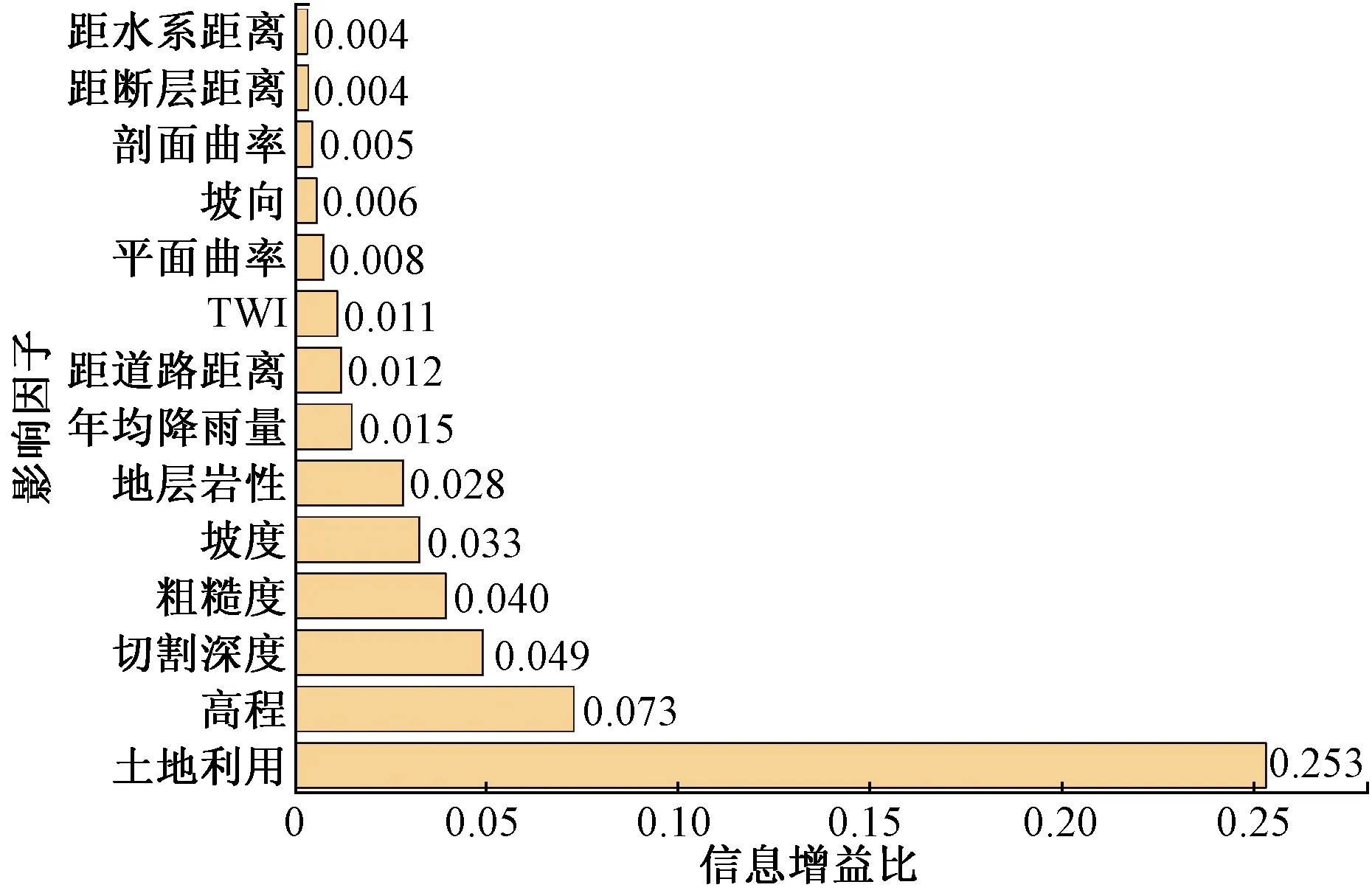
圖3 影響因子信息增益比Fig.3 Impact factor information gain ratio
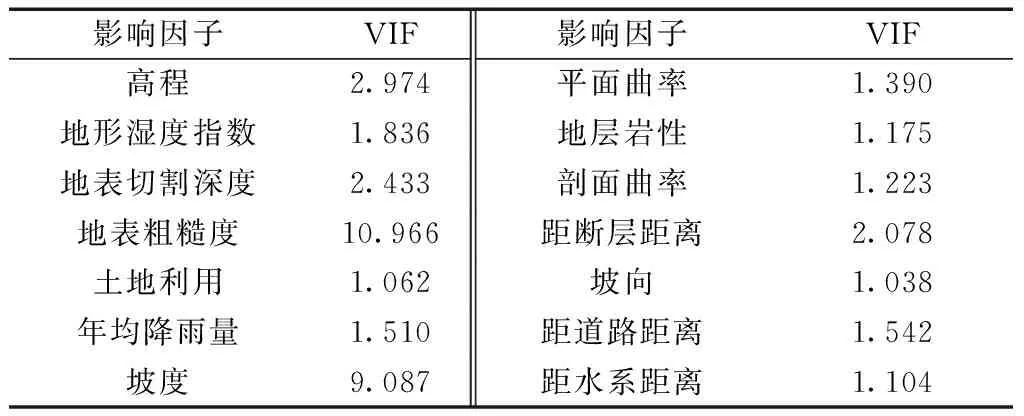
表2 影響因子共線性分析Table 2 Collinearity analysis of impact factors
4 滑坡易發性評價
采用30 m×30 m柵格作為評價單元[14],研究區共被劃分為4 049 150個單元。在滑坡范圍外隨機提取等量的非滑坡數據,與滑坡數據組建樣本數據庫[15-16],隨機選擇70%(712處)作為訓練集,其余30%(356處)作為驗證集,將研究區所有柵格數據作為驗證集。懷卡托智能分析環境(waikato environment for knowledge analysis,WEKA)是集數據處理、學習算法與評估方法為一體的數據挖掘工具,本文研究借助該軟件構建自適應提升、隨機森林模型以及基于兩者的混合模型。
4.1 基于自適應提升模型的滑坡易發性評價
使用AdaboostM1算法構建自適應提升模型,基分類器選擇C4.5決策樹,它基于最大化標準化信息增益的屬性的選擇構造決策樹,樹進行修剪并且置信因子設置為0.25。模型迭代次數為10次,訓練集正確率為76.9%,驗證集預測率為75.3%,代入驗證集得到基于自適應提升的LSI。采用自然間斷法分為低易發區(0~0.258)、中等易發區(0.258~0.738)和高易發區(0.738~1),得到基于自適應提升模型的滑坡易發性圖,如圖4(a)所示。
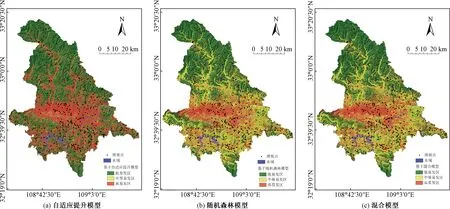
圖4 基于三種模型的滑坡易發性圖Fig.4 Landslide susceptibility mapping based on three models
4.2 基于隨機森林模型的滑坡易發性評價
在WEKA中選擇隨機森林算法,迭代次數為100次,通過十倍交叉驗證進行訓練,正確率為83.0%,驗證集預測率為80.1%。得到基于隨機森林的LSI值后,重分類為低易發區(0~0.316)、中等易發區(0.316~0.656)和高易發區(0.656~1),從而生成基于隨機森林模型的滑坡易發性圖,如圖4(b)所示。
4.3 基于混合模型的滑坡易發性評價
將隨機森林模型作為自適應提升模型的基分類器,調整上述參數,以此構建混合模型。同樣代入訓練集進行十倍交叉驗證訓練,正確率為82.6%,驗證集預測率為80.8%。將LSI值分為低易發區(0~0.316)、中等易發區(0.316~0.656)和高易發區(0.656~1),生成基于混合模型的滑坡易發性圖,如圖4(c)所示。
對比三種模型的滑坡易發性圖,自適應提升模型的分區結果較為極端,受權值調整影響主要集中分為低易發區和高易發區,中易發區較少。隨機森林與混合模型的易發區分布規律基本一致。
(1)高易發區主要集中在區內中部恒口鎮、大同鎮、五里鎮、建民辦事處、江北街道及關廟鎮6處區域,該區域出露地層為志留系千枚巖與新近系細砂巖,巖質軟弱,節理裂隙發育。坡體覆蓋第四系破殘積土及粉土,結構松散,平緩處均開發為耕地,人類活動強烈,道路工程與房屋修建密集。
(2)中易發區主要位于區內北部、中南部中山及低山丘陵區。北部包括大河鎮、譚壩鎮、雙溪鎮等,該區域溝谷縱橫,多呈V形,滑坡沿道路與水系發育。中南部包括瀛湖鎮、縣河鎮、關家鎮等,主要地層為震旦系云母石英片巖、流紋斑巖及志留系千枚巖,巖性弱、易風化,道路與水系密集,為孕災提供了基礎條件。
(3)低易發區主要分布于區內南北端及東南端,包括葉坪鎮、中原鎮、紫荊鎮、早陽鎮、雙龍鎮等地區。該區域地勢較高,降水充沛,主要用地為林地,人口分布較少,滑坡發生頻率少。
對上述三種區劃結果進行易發性等級統計(圖5),三種模型的滑坡密度隨之易發性等級的提升而增加,證明分區結果符合歷史滑坡分布。其中混合模型的滑坡密度在高易發區達到1.94,同比高于自適應提升模型(1.68)和隨機森林模型(1.86),說明混合模型較單一模型對研究區滑坡預測更加敏感,也體現出對單一模型進行混合提高了預測能力。
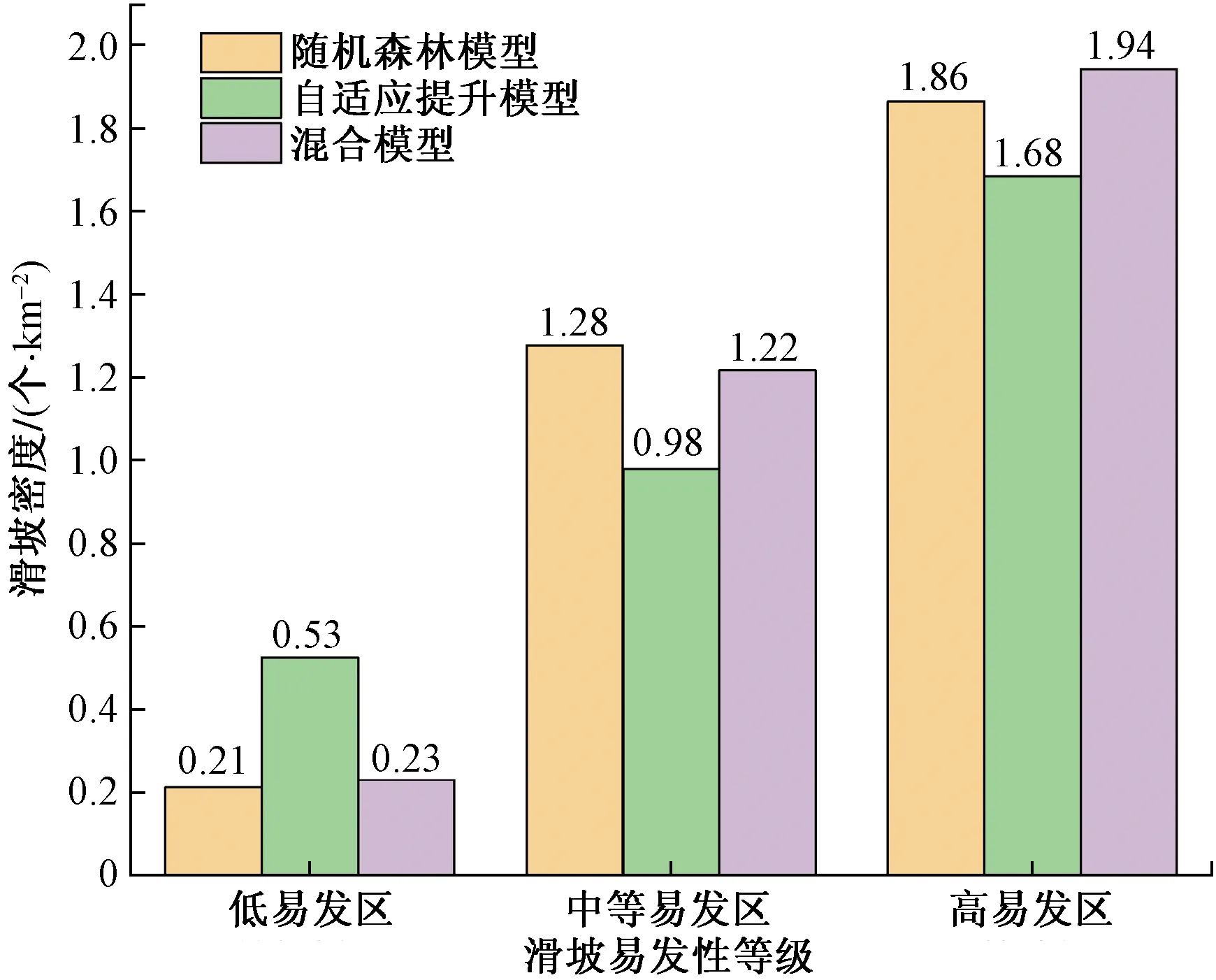
圖5 各模型滑坡易發性等級統計Fig.5 Landslide susceptibility grade statistics of each model
4.4 模型精度比較
接受者操作特性曲線(receiver operating characteristic,ROC)被廣泛應用于模型對比評價,其線下面積(area under curve,AUC)取值介于0~1,值越大代表預測精度越高[17-18]。通過統計各模型的敏感度(即預測為滑坡的滑坡樣本)和1-特異性(即預測為滑坡的非滑坡樣本)生成ROC曲線(圖6)。由表3可以看出,混合模型的訓練集與驗證集AUC值均高于單一的自適應提升模型和隨機森林模型,95%置信區間結果與AUC值一致,說明混合模型預測精度最高,其區劃結果可靠性高。

圖6 各模型ROC曲線對比Fig.6 Comparison of ROC curves of each model
4.5 典型滑坡驗證
在模型評價與統計的基礎上,針對混合模型的區劃結果,選擇區內檬樹埡滑坡、李典前房后滑坡以及桑樹埫滑坡共三處滑坡進行對比驗證[19],如圖7所示。
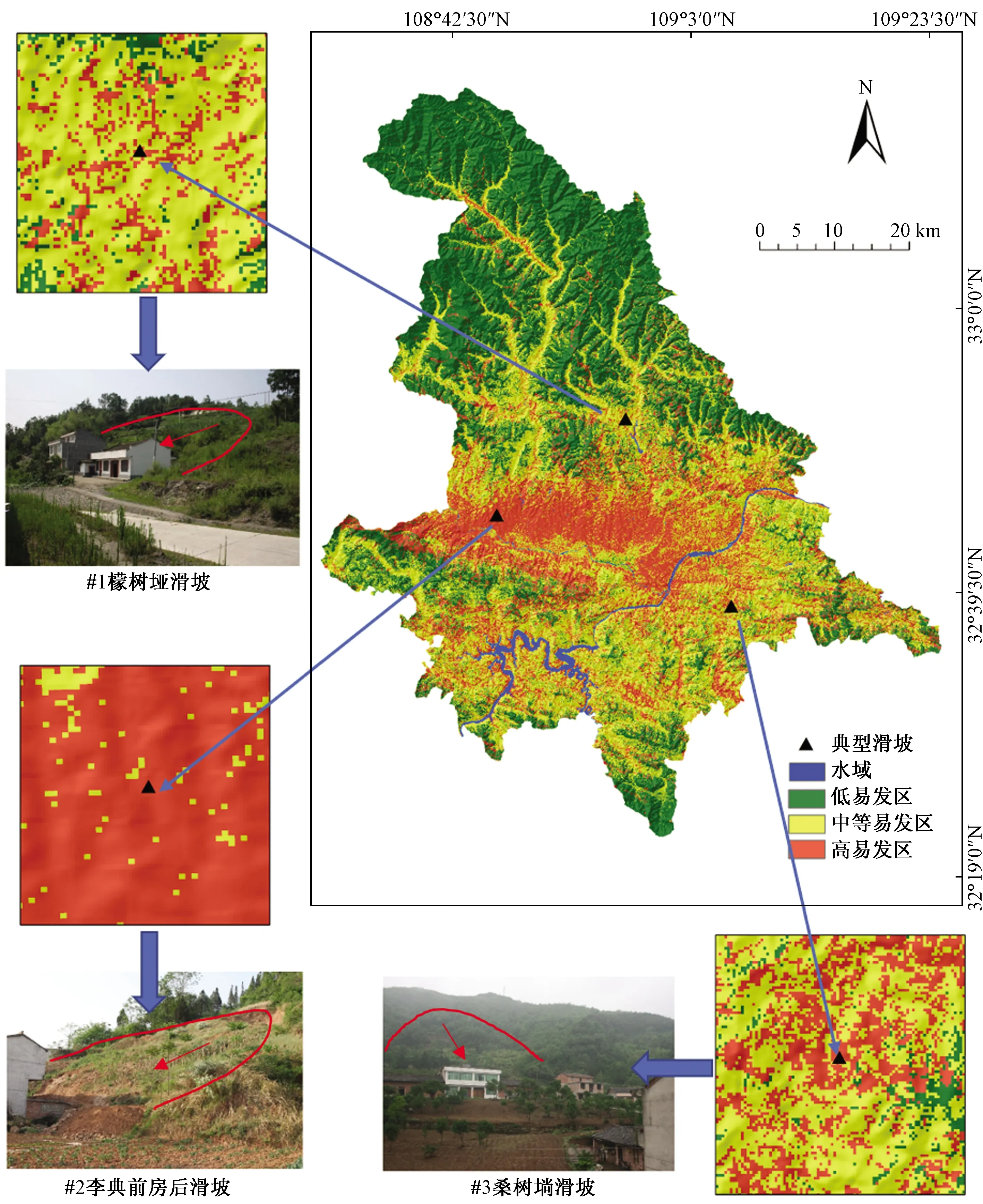
圖7 典型滑坡驗證Fig.7 Typical landslide verification
檬樹埡滑坡位于譚壩鎮后溝村1組,屬基巖順層滑坡,滑體長200 m,寬100 m,平均厚10 m,體積約2×105m3,規模為中型,滑向30°;滑面為片巖層,呈弧型;滑體為殘坡積層和志留系強風化片巖,產狀30°∠50°,滑坡后壁高約5 m,坡體整體滑動可能性較大。
李典前房后滑坡位于恒口鎮青龍村7組,屬低山丘陵地貌,滑體為下新近系砂巖與泥巖互層,及其上覆厚約2 m的第四系中下更新統沖洪積含礫砂質黏土,基巖產狀180°∠20°;坡上為坡耕地,坡度30°,坡高約30 m,為基巖順層滑坡;因建房開挖坡腳形成高約1.5 m陡坎,滑體下滑,水平移動約15 m。

表3 模型精度評價Table 3 Evaluation of model accuracy
桑樹埫滑坡位于縣河鎮紅霞村1組,地處低山地貌、淺凹槽地形,坡體上陡下緩,坡度約35°,上部陡坡樹木茂密,下部為坡耕地,住戶緊鄰坡腳,房前為大面積平緩坡地。滑體為殘坡積層,下伏基巖為志留系千枚巖,產狀90°∠45°。后緣坡體高陡,局部下錯明顯,殘坡積層從上往下依次變厚,前緣臨空面較大,住戶緊鄰坡腳,坡體滑動可能性大。
對比圖4(c),三處歷史滑坡均位于區劃圖中高易發性區域,再次驗證基于該混合模型區劃結果的可靠性,其結果可作為相關部門進行區域滑坡防治的借鑒。
5 結論
提出了基于自適應提升-隨機森林混合模型進行滑坡易發性評價,主要有以下結論。
(1)結合研究區地質環境背景與地質災害形成條件選取高程、坡度、坡向等13類影響因子。采用信息增益比進行因子重要度分析,結果顯示土地利用、高程、地表切割深度、粗糙度、坡度以及地層巖性與研究區滑坡發生更密切,主要分布在耕地與林地、高程介于134~737 m、地表切割深度介于2.65~83.83 m、粗糙度介于1~1.05、坡度介于10.1°~25.6°及地層為志留系云母石英片巖的區域。
(2)采用WEKA軟件分別構建自適應提升、隨機森林以及混合模型。ROC曲線表明,三種模型預測分類擬合程度較好,正確率均較高,其中自適應提升-隨機森林混合模型的訓練正確率和驗證預測率均高于單一模型,進一步驗證混合模型較單一模型具有更高的泛化能力,為滑坡易發性評價模型的選擇提供了新方法。
(3)通過對比各易發性等級的滑坡密度,混合模型高易發區滑坡密度最高;同時通過研究區三處滑坡對混合模型的易發性區劃結果進行驗證,表明其評價結果可靠性高,易發性區劃圖可作為當地相關部門進行防災減災的參考依據。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
石油瀝青(2021年4期)2021-10-14 08:50:44
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
光學精密工程(2016年6期)2016-11-07 09:07:19
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
