基于機器學習的學生成績預警模型研究
2022-06-07 08:01:30廊坊衛生職業學院侯婧
內江科技 2022年5期
◇廊坊衛生職業學院 侯婧
中國人民警察大學 賈南
對于學生學習成績進行預警進行提前預警有助于及時調整教學策略,對提升教學效果具有重要意義。傳統的學生成績預警方法在很大程度上依賴于設計者對測評指標權重的設計,存在主觀性強和誤差略高的問題。隨著教育大數據的不斷完善和人工智能技術的快速發展,基于機器學習算法的學生成績預警已成為可能。本文基于真實的學生學習情況數據,通過特征選擇建立特征工程,采用K-近鄰法建立學生學習成績預警模型,利用訓練集數據訓練模型,并使用測試集數據來測試模型。結果表明,本文設計的基于K-近鄰算法的學生成績預警模型準確率為90.5%,并得到了影響學生掛科的若干重要因素,可為教師及時調整教學策略、提升教學效果提供參考。
1 引言
近年來,大數據研究的快速發展,不斷影響著社會生活的各個領域。2015年8月31日,國務院印發了《關于促進大數據行動綱要的通知》,其中明確要求加大數據技術在教育領域的應用。在人工智能時代,將大數據分析技術與時俱進地應用于教育教學研究中,不僅可為教學改革提供新的思路,也符合我國教育事業發展要求[1]。
在學生學習效果的評價體系中,掛科是較為重要的指標。因此,對學生成績特別是掛科情況進行預警具有重要意義。傳統的預警方法主要采用人為選取學生學習指標、設置指標權重的方法,具有較強的主觀性[2-3]。本文擬基于教育大數據,運用機器學習算法中的K近鄰算法建立模型[4-5],較客觀的對學生成績進行預警,并對影響學生掛科與否的指標重要性進行排序分析,有助于提升教學效果。
2 算法介紹
K近鄰算法是機器學習中的典型算法。該算法1967年由Cover T和Hart P提出,是一種較易理解的分類算法。其原理為:假定存在一個帶有標簽的數據樣本集合,即每個樣本的類型是已知的,用該集合作為訓練集;現在要預測某個未知標簽的新數據的類型,我們將已知標簽的數據樣本按照其特征維度建立N維度坐標系,將已知標簽的數據樣本投放到N維空間中,對于要預測的未知標簽樣本也按N維坐標投放到坐標系中,圈定距離其最近鄰的K個樣本,K個樣本中哪種標簽類型最多,則認為該未知樣本屬于這一類型。
K值的選取是K近鄰算法預測準確率的重要指標,對于有已知經驗的情況,通常按照經驗對K值進行設置;對于無已知經驗的情況,可遍歷K的取值(K一般為整數,通常不大于20),取準確率最大時的K值。
3 模型建立和實例驗證
3.1 特征工程建立
為準確預測學生掛科情況,本文選取章節測驗、章節學習次數、作業、隨堂練習、綜合評分、教學視頻觀看時長、參與討論次數、模擬考試和期末成績九個特征建立特征工程。其中前八個特征為自變量,期末成績為因變量,即使用前八個變量預測學生的期末成績。其中期末成績按照是否大于60分劃分為“及格”和“不及格”,分別用1和0表示。
3.2 數據探索性分析
特征工程各特征之間若存在較強相關性則會影響預測準確率,因此對各特征間的相關性進行分析很有必要。表1為9個變量之間的相關系數矩陣,從其中可以看出,大部分變量之間不存在明顯的相關性。各變量與期末成績之間的相關系數處于0.005-0.34之間。
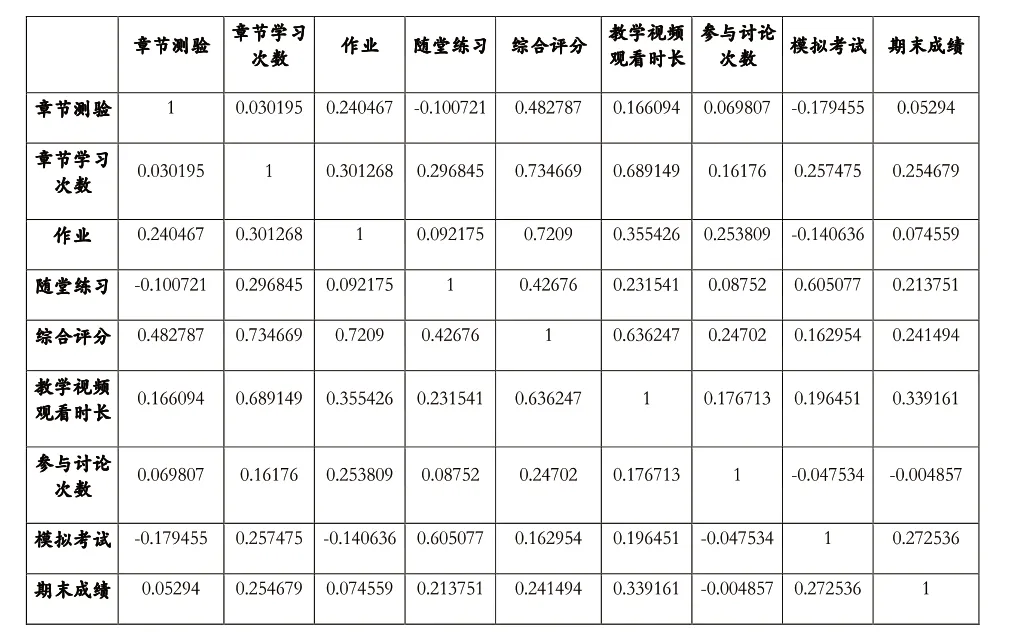
表1 各變量間相關系數矩陣
3.3 模型建立和訓練
建立基于K近鄰算法的學生成績預警模型,首先從sklearn模塊中加KNeighborsClassifier,然后設置n_neighbors的值,從而實例化KNeighborsClassifier,實現模型建立[6]。數據集中70%的數據用于訓練模型,剩余的30%用于測試模型。
4 結果分析
4.1 模型準確率分析
K值是影響K近鄰算法的重要參數,為取得最佳K值,本文分別測試了K取1-19之間全部數值時的模型的準確率,如圖1所示。從圖中可以看出,隨著K值的逐漸變大,模型的準確率逐漸提升,當K取12時,模型準確率達到最大值90.5%。說明K近鄰算法建立的學生成績預警模型預測效果較好。

圖1 模型準確率隨K值變化圖
4.2 特征重要性分析
除了得到較高準確率,分析影響學生期末成績的影響因素也同樣重要。本文運用隨機森林算法的feature_importances_屬性得到預測期末成績的八個特征的重要性排序[7],如圖2所示。從圖中可以看出影響預測精度的最重要的三個特征為“作業”、“教學視頻觀看時長”、“模擬考試”,教師在教學過程中應重點關注在這三個方面表現不佳的同學。
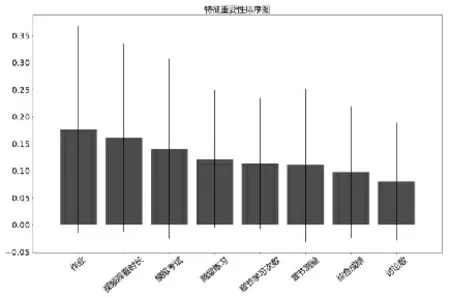
圖2 學生成績預警特征重要性排序圖
5 結束語
本文為解決學生成績預警問題,運用機器學習中的K近鄰算法建立了學生成績預警模型,通過調整K值大小,模型最高準確率為90.5%,具有較高的預測效果,對預測學生是否掛科具有一定指導意義。另外,影響學生掛科與否的最重要的三個特征分別為“作業”、“教學視頻觀看時長”、“模擬考試”,教師在教學過程中應重點關注在這三個維度表現欠佳的學生,及時予以針對性、個體化的教學指導,以提升教學效果,降低掛科率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
光學精密工程(2016年6期)2016-11-07 09:07:19
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
