基于POI-K-means地鐵車站聚類方法研究
2022-05-27 06:56:28趙源,王越,胡華
智能計算機與應用 2022年5期
關鍵詞:分類
趙 源,王 越,胡 華
(1同濟大學 道路與交通工程教育部重點實驗室,上海 201804;2上海軌道交通運營管理中心,上海 200070;3上海工程技術大學 城市軌道交通學院,上海 201620)
0 引 言
隨著城市軌道交通的快速發展,車站的數量也在迅速增長,截止2020年底,全國軌道交通累計投運車站共計4 681座,不同類型的車站客流特征不同,管理方式不同。也有些研究要基于車站的分類,例如在研究客流時間分布特征時需要將車站準確分類才能總結出不同類型車站的客流系數。因此研究車站分類以及建立車站分類模型可以為客流特征研究與預測、地鐵車站管理以及周邊土地開發提供依據。
馬壯林等人采用主成分分析(PCA)方法對軌道交通進出站客流進行特征提取,采用Hopkins統計量分析聚類趨勢并探討聚類數量確定方法,采用CH系數、輪廓系數和DB指標對比分析高斯混合模型(GMM)和K-means聚類的優劣,目前大多數分類方法包括:按車站所處的城市位置,分為都市中心站、交通樞紐站等;按場所導向型標準,分為城市外圍區、成熟居住區等;按功能導向型標準,分為起點站、換乘站、終點站等;按運營性質,分為中間站、區域站;按車站交通重要性,分為二線換乘、三線換乘等。既有分類方法稍顯簡單,標準較單一,可能導致一個車站屬于多個類別的情況。
為了得到車站的精細化分類,本文總結了影響車站分類的因素:車站自身屬性,即是否為起/終點站或者是幾線換乘站、客流特征,即早晚高峰時段5 min粒度客流占全天客流的比重、POI特性,即地鐵車站800 m范圍內土地利用情況。構建了POI-Kmeans車站聚類模型并將上海14條線、共計416座車站,分為6類,驗證了模型的實用性。
1 車站分類影響因素
1.1 車站屬性
車站是軌道交通線網的重要節點,由于在線路中的位置不同,功能不同,所以在確定車站屬性類聚類指標時,選取了起點站、終點站、非換乘站、二線換乘站、三線換乘站、四線換乘站5個指標,輸入數值為0,1型,是為1,否為0。詳見表1。
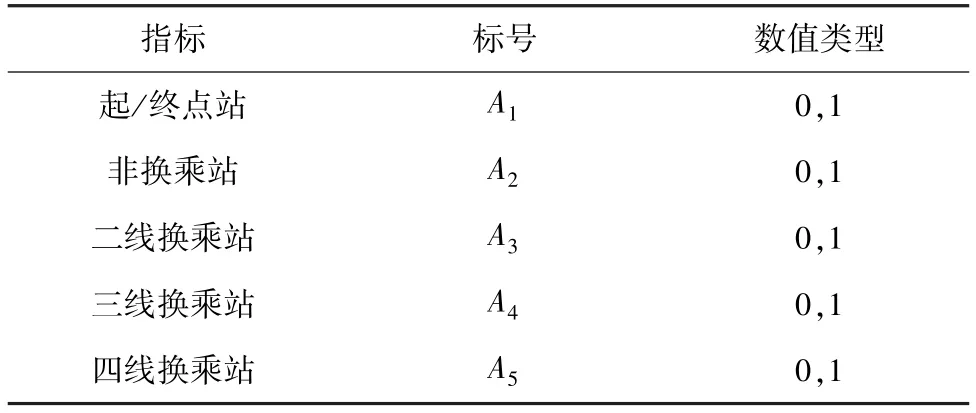
表1 車站屬性聚類指標Tab.1 Stations attribute clustering index
1.2 車站客流特征
相比道路流量、公交客流量,城市軌道交通客流量有很大的不同,由于城市軌道交通有著固定的發車間隔與營業時間,使得其統計的客流量在不同時間粒度(如5 min、15 min、30 min、60 min)都可以顯示出客流本質特征,要使車站做到精細化的分類,所以選擇5 min時間粒度,而在全天客流中早晚高峰最具代表性,為了使指標更能代表客流趨勢,這里將5 min客流與當天進站或者出站總客流的比值作為聚類客流特征指標,其中包括早晚高峰各2 h進出站客流各48個、共96個指標,見表2。
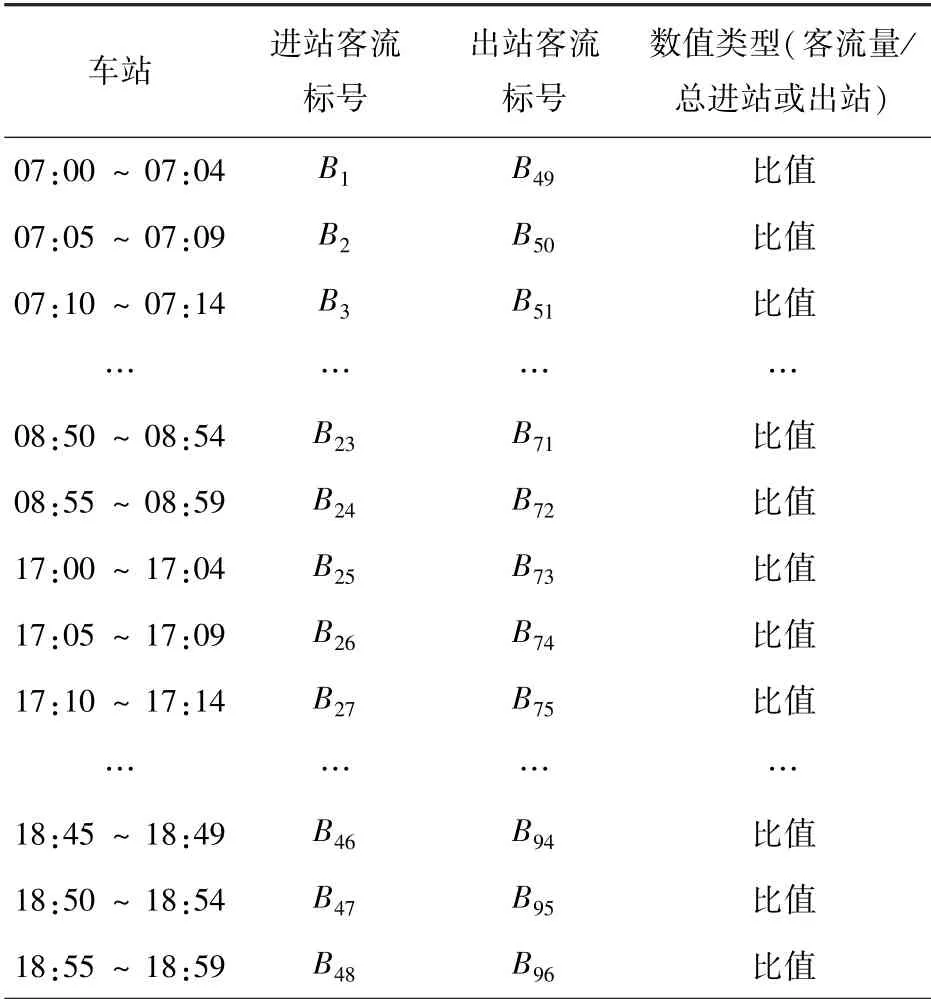
表2 客流特征指標Tab.2 Passenger flow characteristic index
1.3 車站客流吸引范圍內POI
POI(一般作為Point of Interest的縮寫,也有Point of Information的說法),通常稱作興趣點,泛指互聯網電子地圖中的點類數據,POI數據目前可通過高德地圖或者百度地圖等方式獲取,主要包含名稱、地址、坐標、類別四個屬性;源于基礎測繪成果、即數字線劃地圖(Digital Line Graphic,DLG)產品中點類地圖要素矢量數據集;在地理信息系統(Geographic Information System,GIS)中指可以抽象成點進行管理、分析和計算的對象。通常情況下,POI分類一共有3級,但是對于分類的個數大同小異。高德地圖針對全上海的POI分類中,一級分類有23個,二級分類有267個,三級分類有869個。研究中給出部分POI分類見表3。具體的餐飲類別POI數據見表4。表4中包含了經緯度等重要信息。

表3 POI分類Tab.3 POI classification

表4 車站POI指標Tab.4 Stations POI indicators
為了更好地統計地鐵車站附近POI數量,故劃分一定范圍,對于站點吸引范圍,學者認為根據實際情況取400 m到800 m之間,目前應用較為廣泛的是800 m,以800 m為半徑畫圓為地鐵車站的緩沖區域,統計緩沖區內各類POI數據的個數作為車站分類的POI指標。
在確定POI分類指標時,選取對地鐵車站影響較大的興趣點作為車站分類的指標,并且將個別POI分類進行了整合或拆分,例如將汽車服務、汽車維修、汽車銷售、摩托車服務統一為汽車服務,將“事件活動”、“地名地址信息”、“室內設施”、“道路附屬設施”對車站無影響的類別不納入指標選取中。由表4可知,車站附近POI數據指標共16個。
2 K-means算法
2.1 算法原理
K-means聚類算法是由Steinhaus(1955年)、Lloyd(1957年)、Ball&Hall(1965年)、McQueen(1967年)分別在各自不同的科學研究領域獨立地探討提出的。K-means算法、也稱作快速聚類法,是一種非監督的聚類算法。對于給定的樣本集,按照樣本之間的距離大小,將樣本集劃分為個簇。讓簇內的點盡量緊密地連在一起,而讓簇間的距離盡量地大。如果用數據表達式表示,假設簇劃分為(,,…,C),那么最小化平方誤差可用如下公式計算求出:
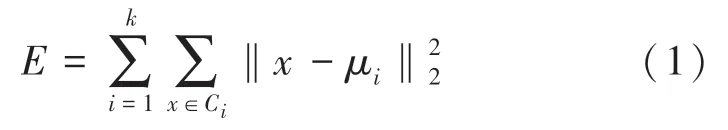
其中,μ是簇C均值向量,有時也稱為質心,表達式如下所示:
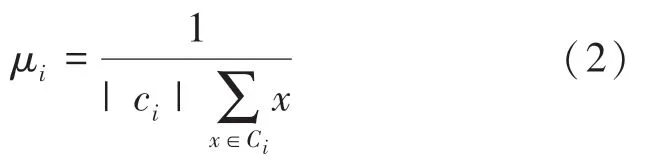
聚類過程示例如圖1所示。圖1(a)表達了初始的數據集,假設2。圖1(b)中,隨機選擇了2個類所對應的類別質心,即圖中的紅色質心和藍色質心,并分別求取樣本中所有點到這2個質心的距離,再標記每個樣本的類別為和該樣本距離最小的質心的類別,見圖1(c),經過計算樣本和紅色質心與藍色質心的距離,得到了所有樣本點的第一輪迭代后的類別。此時標記為紅色和藍色的點分別求其新的質心,見圖1(d),新的紅色質心和藍色質心的位置已經發生了變動。圖1(e)和圖1(f)重復了圖1(c)和圖1(d)的過程,即將所有點的類別標記為距離最近的質心的類別并求得新的質心。最終得到的2個類別見圖1(f)。
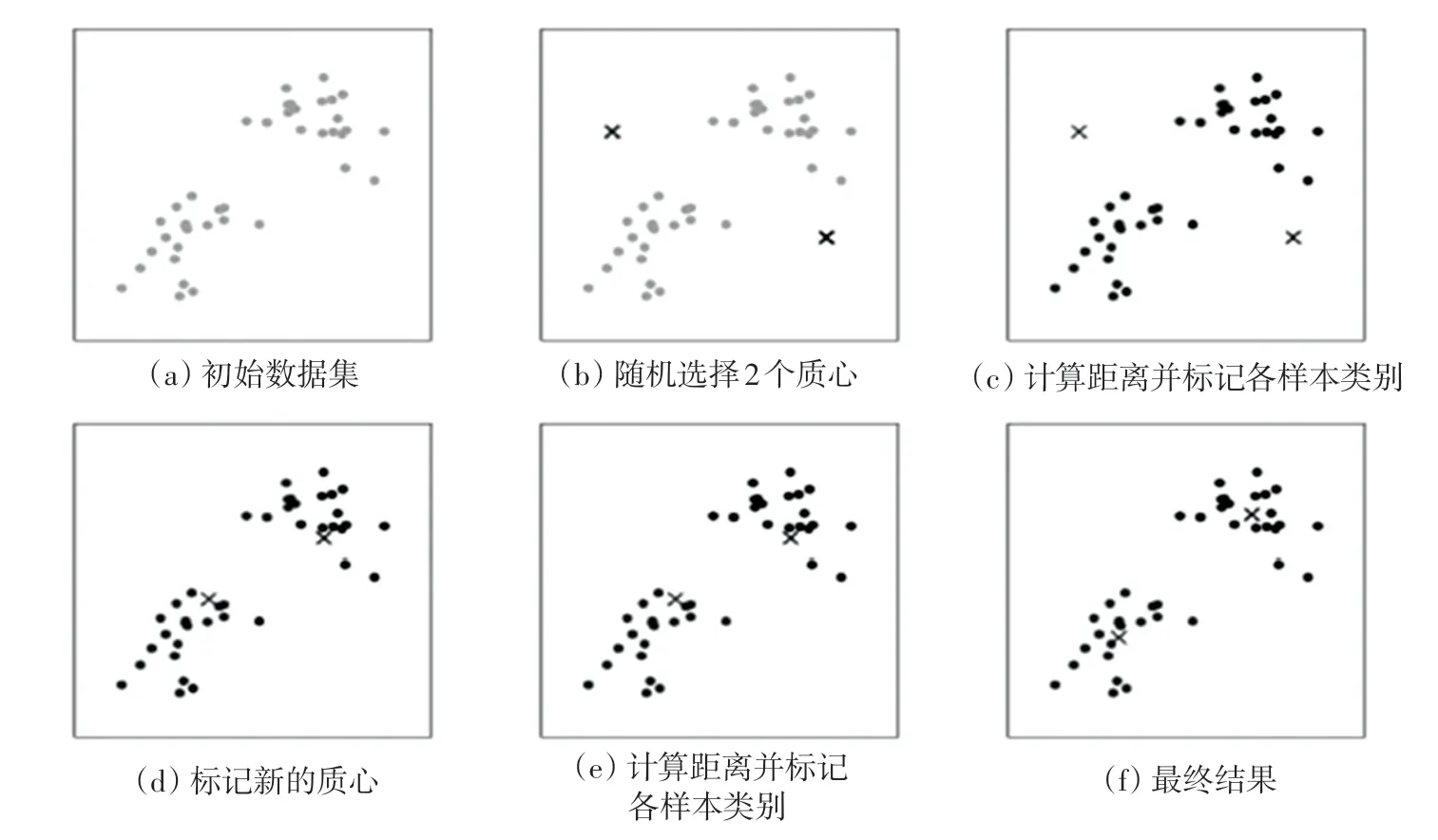
圖1 聚類過程示例Fig.1 An example of clustering process
總地來說,K-means算法步驟為:
選擇個聚類的初始中心。
對任意一個樣本點,求其到個聚類中心的距離,將樣本點歸類到距離最小的中心的聚類,如此迭代次。
每次迭代過程中,利用均值等方法更新各個聚類的中心點(質心)。
對個聚類中心,利用Step2、Step3迭代更新后,如果位置點變化很小(可以設置閾值),可判定為達到了穩定狀態,迭代結束。對不同的聚類塊和聚類中心可選擇不同的顏色標注。
2.2 基于POI-K-means地鐵車站聚類模型
在分類過程中,最主要的是對分類指標的選取,本研究分類指標共包含3個部分,分別是:車站屬性指標、車站客流特征指標以及車站附近POI數據指標。
在選取完車站聚類指標后,形成的初始矩陣見表5。由于指標數值的類型和單位不同,而且數值差距過大,故將矩陣歸一化,歸一化方法對K-means聚類的有效性也通過各種數值實驗證明,基本上是Z-Score、Min-Max和小數縮放方法。實驗分析表明,Z-Score在3個歸一化過程中表現良好,準確度更高,因此該方法減少了迭代次數。所以本模型使用Z-Score標準化,將變量統一轉化為同一個量級,可以將數據有效地轉換為統一的標準,Z-Score的數學公式可寫為:
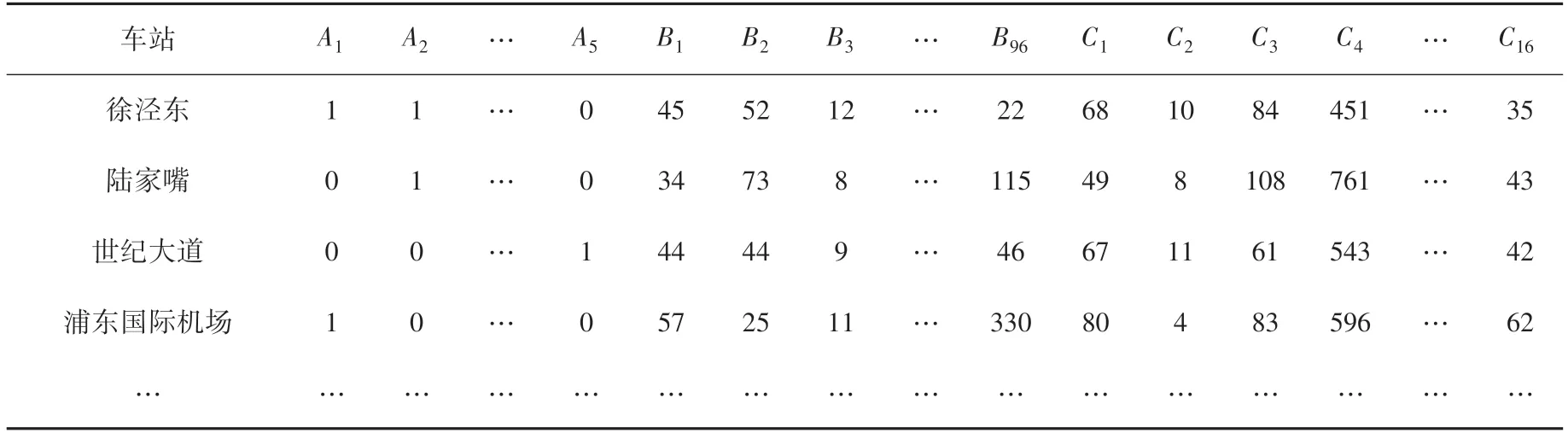
表5 車站初始矩陣Tab.5 Stations initial matrix

其中,為總體數據的均值;為總體數據的標準差;為個體的觀測值。
Z-Score最突出的優點就是簡單,容易計算,能夠應用于數值型的數據,并且不受數據量級的影響,因為其作用就是消除量級給分析帶來的不便。但是需要指出的是,Z-Score本身沒有實際意義,具體的現實意義需要在比較中得以實現,這也是Z-Score的缺點之一。
手肘法是一種利用和值的關系圖確認最優值的方式,還可以替換為樣本點到聚類中心歐式距離平均值,本文選用利用手肘法確定最佳值。在K-means算法中,最主要的步驟就是確定值,每一步都可以計算出值、又稱為。值的計算方式就是每個聚類的點到其質心的距離的平方,如式(4)所示:
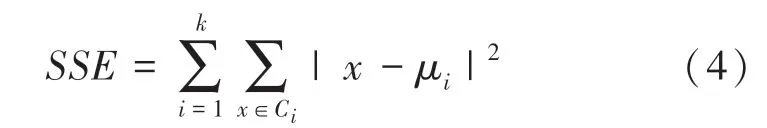
指定一個值,即可能的最大類簇數。然后將類簇數從1開始遞增,一直到,計算出個。根據數據的潛在模式,當設定的類簇數不斷逼近真實類簇數時,呈現快速下降態勢,而當設定類簇數超過真實類簇數時,也會繼續下降,但下降會迅速趨于緩慢。通過畫出曲線,找出下降途中的拐點,即可較好地確定值。
利用Python編程實現確定值與分類的部分,總的分類模型如圖2所示。
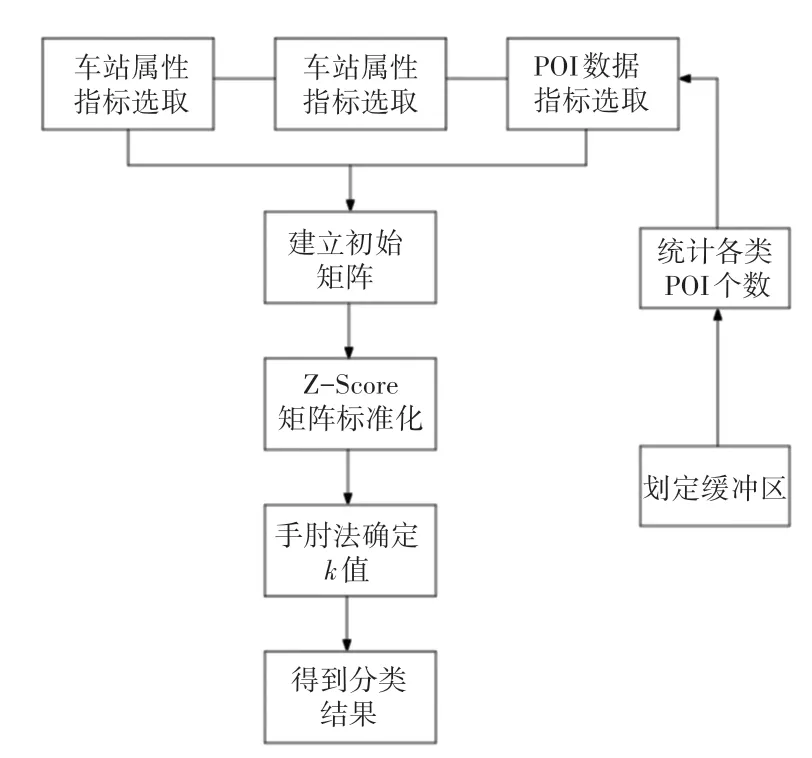
圖2 分類流程圖Fig.2 Classification flow chart
3 實例驗證
3.1 上海地鐵車站分類
上海城市軌道交通線網截止2020年底共有運營車站430座,本次研究選取運營時間較長的416座,其中包括1號線、2號線、3號線、4號線、5號線、6號線、7號線、8號線、9號線、10號線、11號線、12號線、16號線、17號線。
基于AFC數據、上海POI數據,分別確定車站屬性、車站附近POI數據、早晚高峰客流特征三類指標進行聚類,如圖3所示,利用手肘法得到最佳值,在6時出現明顯的拐點,所以將上海地鐵車站分為6類,聚類結果見表6。
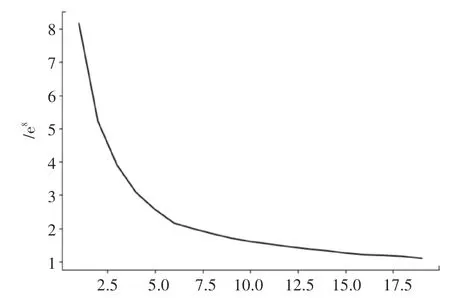
圖3 上海地鐵車站分類k值手肘圖Fig.3 The elbow diagram of the k-value of Shanghai subway stations classification

表6 K-means聚類結果Tab.6 K-means clustering results
3.2 各類車站特征分析
根據統計每個類別POI個數,分析其土地利用特點以及客流特征,得到以下類型描述。
(1)商務型:地鐵車站周邊用主要有辦公樓、密集的公司、少量的住宅和商戶,地面大部分建筑為高層辦公樓,土地開發強度高,土地利用率高,高峰時期的交通較為復雜,接駁方式眾多,POI類別中商務寫字樓占比最多。
(2)休閑旅游型:地鐵車站周邊多為景區、音樂廳、體育場、公園等公共場所及建筑,這種類型涉及土地范圍稍廣,往往換乘線路比較多,配套商業也較多,土地開發率也相對較高,在節假日客流較多,POI中餐飲服務、購物服務占比較多。
(3)居住型:地鐵車站周邊多為住宅,商業用地較少且開發程度已經完成,功能比較單一,早晚高峰客流特征明顯,接駁方式多以公交、單車為主。
(4)交通樞紐型:地鐵車站以大型客運站、火車站、高鐵站、機場為主,該類型往往對地上、地下空間利用范圍較廣,有一些配套的商業,客流量也較大,接駁方式最為全面,從POI占比看交通設施服務類占比最大。
(5)活動型:地鐵車站周圍以大型場館為主,在活動期間客流驟增,周邊場地大,可容納大量客流,接駁方式主要為地鐵、出租。
(6)混合型:地鐵車站周邊土地利用復雜,多為住宅及學校、辦公,商業用地較多且開發程度較高,潮汐客流特征明顯,接駁方式眾多,POI類別中生活服務類占比較多。
4 結束語
本文為了得到車站精細化分類,總結了影響車站分類的因素:車站自身屬性,即是否為起終點站或者是幾線換乘站、客流特征,即早晚高峰時段5 min粒度客流占全天客流的比重、POI特性,即地鐵車站800 m范圍內土地利用情況。構建了POI-K-means車站聚類模型,并將上海14條線、共計416座車站,分為6類,驗證了模型的實用性。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
