融合關鍵字的注意力機制的淋巴水腫病歷診斷推理算法
2022-05-11 07:32:36王帥帥
智能計算機與應用 2022年2期
王帥帥, 徐 臻
(中國電子科技南湖研究院, 浙江 嘉興 314000)
0 引 言
淋巴水腫是以淋巴管堵塞引起肢體腫脹為代表的一種疾病。 根據世界衛生組織統計,淋巴水腫在常見慢性病中列第11 位,致殘類疾病中列第2 位,全球淋巴水腫患者約達1.7 億,中國淋巴水腫患者也高達千萬人。 淋巴水腫是世界醫學難題,目前尚不可治愈,如果早期發現,診斷治療及時得當,可以不同程度得以緩解。 目前國內系統有效診斷治療淋巴水腫的醫療機構還很少,相關專業醫生缺口巨大,淋巴水腫的相關知識尚不普及,大多數患者在發病后得不到有效的診斷和治療,導致病情不斷惡化,因此構建一個淋巴水腫疾病的智能診斷模型具有重要意義。 本文利用深度學習技術,使數字賦能病理診斷,通過訓練和學習醫院收集的淋巴水腫電子病歷,快速實現對電子病歷內容的的識別與理解,從而大大提升病理診斷的效率和準確率,輔助專業醫師,服務更多的患者。
1 診斷推理模型
1.1 電子病歷關鍵詞的提取
關鍵詞是文檔中能夠表達重要內容的詞語,關鍵詞提取在信息檢索、自動摘要、文本聚類等方面有重要應用。 本文認為電子病歷中一些關鍵詞語和檢查結果對病歷診斷結果有重要作用,尤其淋巴水腫相關疾病,不僅要識別出淋巴水腫類型,還需要識別出身體患淋巴水腫的部位。 提取病歷中關鍵癥狀、部位、疾病等關鍵詞,可以更好地幫助模型理解病歷的內容。 關鍵詞抽取常用的算法有詞頻-逆文本頻率(TF-IDF)、文本排序(TEXTRANK)算法和主題模型算法。 本文關鍵詞提取使用TF-IDF 算法。 TF-IDF 的含義是如果某個詞或短語在一篇文章中出現的頻率() 高,并且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來分類。 詞頻() 是指某一個給定的詞語在該文中出現的頻率,式(1)。
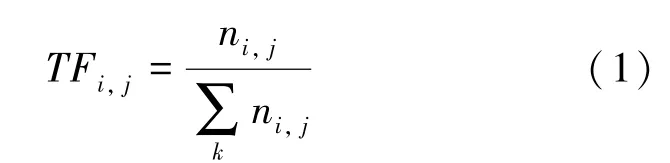
其中,n 表示該詞在文件中的出現次數,分母為文件中所有詞的出現次數之和。
TF-IDF 假設高頻率詞應該具有高權重,除非其在所有的文檔中出現的頻率都很高。 而逆文檔頻率() 的大小與一個詞的常見程度成反比,即最常見的詞賦予最小的權重,較常見的詞賦予較小的權重,而較小頻率的詞賦予較大的權重,式(2)。
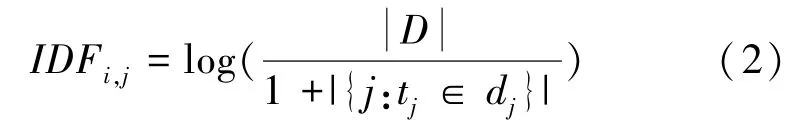
其中,|D |表示語料庫中的文檔總數,{:t∈d}表示包含詞語t的文檔數目。
在分別計算得到和后,將其相乘就能得到TF-IDF 的值,如式(3)所示。
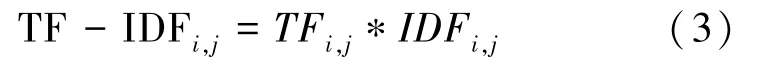
計算得到文本的關鍵詞特征向量和TF-IDF 特征向量后,將其拼接為一維的長向量,該向量就是最終機器學習算法要學習的特征向量。 本文使用的淋巴水腫電子病歷數據,如圖1 所示。 對其中一個電子病歷主訴、現病史、個人史、家族史和體格檢查內容使用TIIDF 提取關鍵詞,按重要性排序如圖2 所示。

圖1 淋巴水腫電子病歷Fig.1 Lymphedema electronic medical record

圖2 關鍵詞排序Fig.2 Keyword ranking
1.2 融合關鍵詞的注意力診斷推理模型
在自然語言領域序列到序列(seq2seq)模型和注意力機制(attention)為生成式推理提供了一種可行方法。 但這些模型存在兩個問題:
(1)不能準確把握文章細節,無法處理未登錄單詞問題;
(2)傾向于重復自己的內容,使生成的句子不連貫。
指針生成網絡(PGN)通過指向從源文本中復制單詞,有助于準確地復制信息,同時保留通過生成器產生新單詞的能力,使用覆蓋(coverage)機制來跟蹤已總結的內容,防止重復。 PGN 是在seq2seq 模型的基礎上構建,PGN 模型架構如圖3 所示。
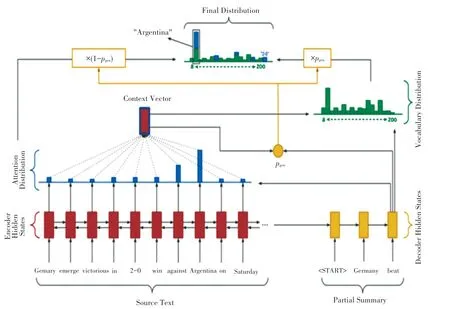
圖3 PGN 模型Fig.3 PGN model
該模型在seq2seq+attention 模型的基礎上增加了P,在每個解碼器過程中,計算一個生成概率P[0,1],該值決定有多大的概率從單詞表中生成單詞,模型中的最終分布根據詞匯分布和注意分布加權求和得到,根據最終分布進行預測。 PGN 既允許通過指針復制單詞,也允許根據詞匯生成單詞。在指針生成器模型中,時間步長的生成概率P是根據上下文向量h、解碼器狀態S和解碼器輸入x計算,如式(4)式(6) 所示。 本文的編碼端和解碼端使用的是長短時記憶網絡(LSTM)。 編碼端的輸入為(,…,x), 解碼端的輸入為(,…,y)。
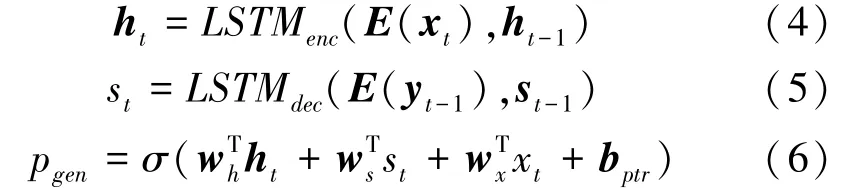
其中,(x) 為單詞的詞向量;向量w、w、w、b是學習參數;是激活函數。
P用來決定從詞匯表生成單詞,還是從源文本復制單詞的概率,用來對詞匯分布和注意力分布進行加權平均,得到擴展詞匯表上的概率分布,如式(7)所示。
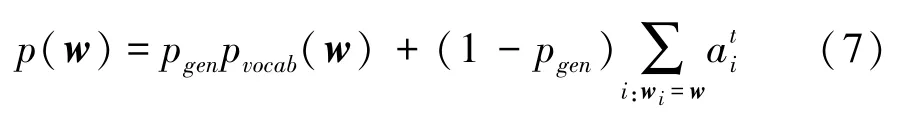

使用PGN 進行病歷診斷結果生成的結果往往會忽略一些重要的詞,比如部位等,而且現有的深度學習生成方法只關注結果與原始文本的總體關系,有時可能會對文本中的主要細節內容把握不準確,導致生成的結果不全面,很容易丟失病歷中部位、癥狀等關鍵信息。 將病例中關鍵詞作為PGN 模型生成結果的提示,病歷的關鍵詞可以是部位、疾病之類名詞,也可以是癥狀類的描述性短語,讓模型在解碼時更加關注這些關鍵詞匯,從而使生成的結果更加準確。 如圖4 所示,將病歷關鍵詞通過注意力機制融入到PGN 模型中,模型就可以通過關鍵詞所包含的語義和病歷中其他信息生成概括性的診斷結論。
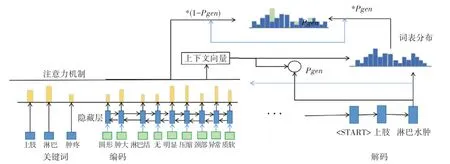
圖4 融合關鍵詞的注意力模型Fig.4 Attention model fused with keywords
病歷輸入時使用word2vec 訓練生成詞向量,對于本文選取到的關鍵詞,使用word2vec 生成詞向量{,,…,k},將所有的相加作為輸入融合注意力機制。 計算方法如式(8) 和式(9) 所示。
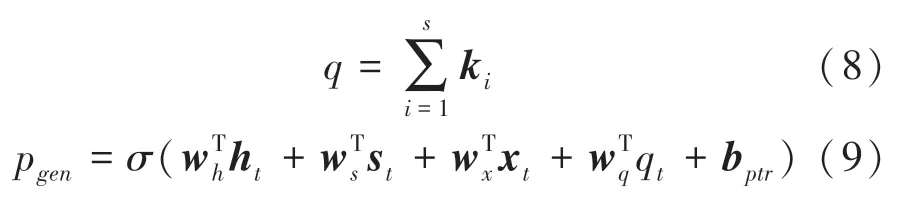
2 數據與驗證
2.1 實驗設置與數據
本文使用8 000 份電子病例作為實驗的訓練集,使用500 份電子病歷作為測試集,300 份淋巴水腫病歷作為驗證數據集。 實驗在GPU 服務器上進行,采用pytorch 深度學習框架。 本文使用的詞匯表大小為8 000 詞,單詞向量的維度是128,編碼器和解碼器的輸入維度是256,batch_size 大小為64。
2.2 評價方法
本實驗使用的評價指標為rouge(recall-oriented understudy forgisting evaluation),是文章摘要提取和機器翻譯常用的評價指標。 ROUGE 主要有ROUGEN、ROUGE-L 和ROUGE-W 3 種方法,本文使用的是ROUGE-L 方法, l 指最長公共子序列,使用了機器譯文C 和參考譯文S 的最長公共子序列,式(10)~式(12)。
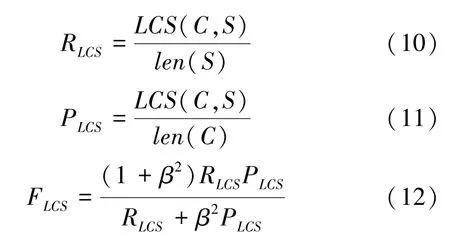
其中,表示文本公共長度;R表示召回率;P表示精確率; F就是ROUGE-L。
3 結果與分析
本文使用每個病歷數據集經處理后長度為900字左右,一個病歷診斷結果生成示例如圖5 所示。

圖5 診斷結果生成Fig.5 Diagnosis result generation
為了驗證算法的有效性,本文對比了序列到序列,注意力機制和指針生成網絡模型,評價指標使用ROUGE-1、ROUGE-2,ROUGE-L,實驗結果見表1。實驗表明, 本文提出的融合關鍵字的注意力機制疾病診斷推理模型識別準確率優于其他的算法。
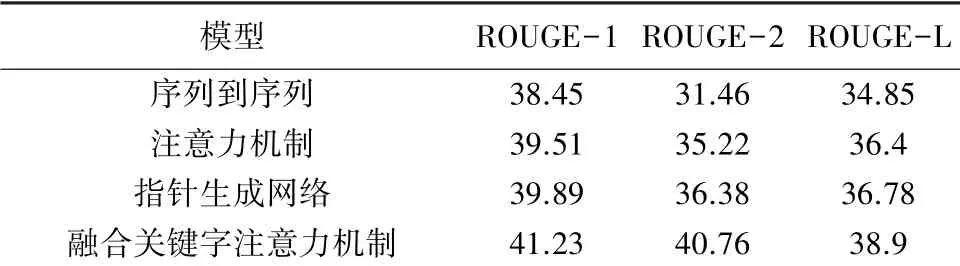
表1 模型結果對比Tab.1 Comparison of model results
由表1 可以看出,在將病歷中關鍵信息加入到模型后,本文的融合關鍵字的注意力機制明顯優于指針生成網絡,在生成的診斷結論中,融合關鍵字的注意力機制可以有效的提取到病歷中關鍵信息,ROUGE-2 指標提升最多,能夠得到性能更好地淋巴水腫診斷推理模型,為淋巴水腫相關疾病診斷提供了可靠的輔助支持。
4 結束語
本文提出的融合關鍵詞的注意力機制模型即保持了模型的文本生成能力,又可以讓模型可以向醫生一樣依據病歷中的核心癥狀和核心部位等信息進行疾病的推理,生成的診斷結果更加連貫,更能覆蓋病歷信息。 利用深度學習技術構建水腫診斷推理模型可以幫助醫生進行疾病的快速診斷,讓患者可以及時得到治療,在一定程度上緩解醫療資源不足問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
