基于群落學習的空中博弈對抗模型
2022-05-11 07:32:34沈賢杰
智能計算機與應用 2022年2期
沈賢杰
(中國電子科技南湖研究院JS 大腦實驗室, 杭州 314000)
0 引 言
博弈對抗算法在現實生活中應用場景非常廣泛,例如棋類、商業投標、作戰等。 對于棋類等存在大量的融合人類專家先驗知識的局內數據作為訓練數據的場景,即使不采用強化學習,只采用監督學習即可獲得接近甚至超越普通人類的表現。 然而,對于其它一些難以獲得大量實際數據的場景,現有表現較好的解決方案,是使用結合先驗知識的強化學習模型進行自博弈對抗。
PSA-Air 模型首先針對空中博弈對抗的場景,設計了多階段的強化學習模型訓練,并將原先樸素的行動策略方案改進為一種更穩定有效的基于相對位置的行動方案;針對不同階段的模型訓練設計不同的群落學習機制,來解決模型訓練的冷啟動、過擬合等問題。 此外,該模型利用Transformer中的自注意力機制,對多智能體環境狀態進行編碼,實驗證明相比LSTM具有更高的性能。
1 環境描述
本文算法模型解決的問題環境為態勢完全透明的5V5 空戰問題。 雙方均由1 架有人機與4 架無人機組成,雙方性能完全對等;可行動空域長寬均為300 km,高度約為10 km 的矩形。 初始狀態雙方各從空域俯視圖的正方形一對頂角,同一高度同時出發,每架飛機各攜2 枚導彈。 在限制時間20 min 內,若一方無人機被擊落或者全部導彈已被發射則判負;若超過限制時間,當前剩于戰力(飛機總架數、導彈剩余總數量)多者獲勝;若剩余戰力相等,則占據對戰空域中間部分時間較長的一方獲勝。 對戰過程中,內部機群之間的機載雷達可以互相提供制導功能。
2 先驗知識
2.1 群落學習
群落學習技術最初由DeepMind 提出,用于挑選神經網絡最優超參數。 具體地說,多個被隨機賦予超參數的神經網絡模型并行地訓練。 類似于遺傳學習,在每輪訓練中獲得較好表現的網絡超參數組合,會被用于改進現有的超參數組合,表現較差的超參數組合則會被放棄。 在AlphaGo中同樣存在類似的思想,在自博弈階段會初始化一系列不同參數的對手用于對抗學習,來防止訓練階段的過擬合問題。
2.2 自注意力機制
Transformer 在自然語言處理等多個領域取得了非常優秀的成績,其主要歸功于其對于自注意力機制的應用。 假設輸入為[,]維的矩陣,則需要3個均為[,]維的矩陣、、, 分別代表、與,將輸入矩陣轉換成[,]維的矩陣。 輸入矩陣經過矩陣得到其矩陣,將該矩陣與經過矩陣得到的矩陣進行內積,再與經過矩陣轉換后的矩陣相乘后,得到處理后的輸入。 該機制主要意義在于將輸入視為個維的向量,使向量之間進行交互,挖掘輸入之間的關系,凸顯更重要的輸入維度。 具體公式如式(1) 所示,分母中的用于防止矩陣內積結果過大。
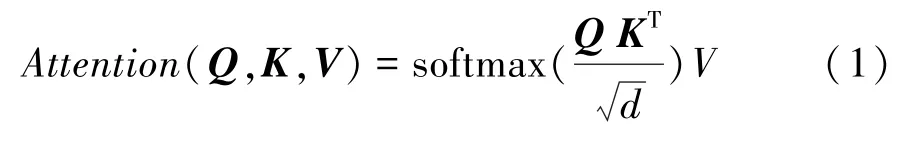
3 算法模型描述
3.1 模型結構與輸入輸出
PSA-Air 模型主要由Critic 和Actor組成,并遵循MADDPG集中式評價、分布式訓練的原則,使用經驗回放池以及目標網絡機制。 其中,Critic 接收整體環境的輸入、編碼得到當前環境的嵌入向量,并輸出衡量當前優劣情況的值;Actor 接收各個行動體的局部環境,并輸出對應的行動策略。
每架飛機的狀態由一個10 維的向量表示, 分別為、、軸方向的方位,表示飛機飛行角度的航向角、俯仰角、橫滾角,以及縱向加速度、 切向加速度、導彈的剩余量等。 以上參數均被標準化到0 ~1之間,使訓練過程更為高效穩定。 若該飛機已被擊落則全設為0。 每一架飛機由一個獨立的Actor 控制,以往模型對于Actor 會直接輸出三維空間下各個角度的偏轉角以及加速度,但采用這種方式,在訓練期間會有較多的不穩定性,且由于在訓練初期飛機容易飛離指定空域,所以訓練效率較低。
Actor 和Critic 接收輸入后,都會經過全連接層連接的若干個自注意力層,將不同行動體的狀態向量進行交互,再經過帶非線性激活函數的全連接層進行編碼。 同時該模型避免了使用LSTM 對歷史數據進行編碼存儲,主要考慮到LSTM 的訓練速度慢且對于強化學習模型訓練難度較高。 為了利用歷史數據,模型的輸入會同時得到該時刻以及上一時刻的數據,雖然輸入層維度會翻倍,但大大降低了對計算資源的需求以及訓練難度。
3.2 對戰階段設定
對于一局對戰,主要分為開局階段以及開火階段。 開局階段定義為:雙方機群之間,兩架飛機之間距離大于3 倍最大開火范圍時,認為處于開局階段。該階段的主要任務是機群內部組成一個良好的隊形,使其能夠在很大程度上保護有人機,并且利于攻擊敵方。 經過開局階段后,會進入對戰開火階段。主要表現為無人機之間的短兵相接以及有人機的適當介入。 在兩個階段分別會使用不同的策略網絡。
3.3 獎勵函數設置
PSA-Air 模型主要使用如下3 種獎勵函數。
第一種:使用最終對戰結果的勝負獎勵。 勝平負分別對應+1、0、-1。 然而一場對局往往需要經過上百次行動決策,僅有終局獎勵太過稀疏。
第二種:對于當前戰力的消耗進行評估。 若某一時刻無人機被擊落,則會給予負向獎勵0.5;若導彈發射,但并未擊落目標,也會給予負向獎勵0.16;反之,對另一方則會進行正向獎勵。
第三種:獎勵用于指導保護己方有人機以及攻擊敵方無人機。 具體來說,對每一個時刻都會記錄一個環境值,其值為己方有人機距對方最近無人機距離與對方有人機距己方最近無人機距離的比值。 若該比值較大,則說明己方有人機處在相對更安全的位置(只考慮仍然攜帶剩余導彈的無人機),反之則說明己方有人機有被擊落的風險。時刻的該獎勵為時刻的比值與1 時刻比值的變化值。
3.4 訓練流程
PSA-Air 模型的訓練主要分為預熱階段與自博弈訓練階段。 預熱階段包括整個模型群落的預熱訓練,自博弈訓練為群落內的不同智能體之間進行對抗訓練。
3.4.1 預熱訓練
模型預熱訓練階段對戰的是基于規則的模型。規則模型在開局階段會讓有人機在原地打轉一定時間,其余無人機往敵方有人機飛行,這樣可讓有人機處在相對安全的位置又不至于脫離集群太遠。 當敵方有人機進入攻擊范圍,則會使用貪心法讓最近距離的不在攻擊狀態的飛機攻擊。 若被敵方飛機攻擊,則有一定概率放棄攻擊,自主進行繞圈飛行躲避攻擊。 同時在每一步的行為中增加一定的隨機性以提升魯棒性。
3.4.2 融合群落學習的自博弈訓練
模型自博弈階段,會使用群落學習的概念,隨機初始化一組策略網絡,用于和經過預熱訓練的模型進行自博弈訓練,并同時訓練兩邊對戰的模型。 在以往使用群落學習的強化學習模型中,每一輪的對手策略網絡都會被隨機選擇,然而這樣訓練的效率較低,會浪費許多訓練資源。 PopAir 模型提出運用上限置信區間公式(Upper Confidence Bound,UCB)對策略網絡群落進行采樣。 UCB 公式常被用于蒙特卡洛搜索樹中的節點采樣,以提升搜索效率。 具體如式(2)所示:
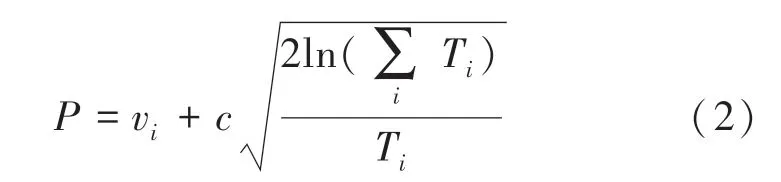
式中,表示每輪被挑選的概率; v為該網絡的對戰勝率;T表示各網絡的對戰次數。 若該策略網絡的對戰勝率較高或參與對戰的次數較少,則被挑選的概率越大。
3.4.3 訓練細節
模型在預熱及自博弈訓練階段,都使用時間差分誤差(TD error)版本的策略梯度下降法,TD error的具體定義如式(3)所示:
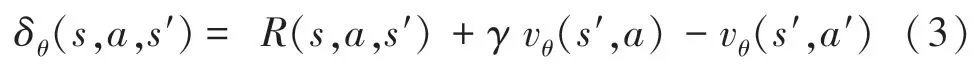
其中,是立即回報;是折扣系數;v是價值網絡的輸出。
策略網絡和價值網絡更新如式(4)、式(5)所示。
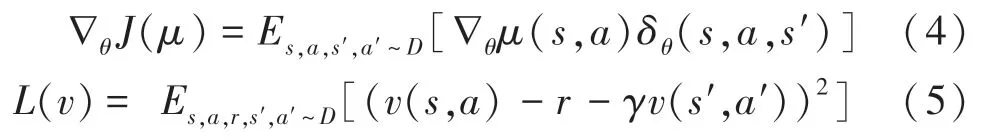
其中,代表經驗存儲池。
4 實驗結果分析
4.1 實驗環境
本文實驗在Ubuntu 20.04 系統上進行,模型由Pytorch 實現,訓練流程使用單張Quadro P4000 顯卡。
4.2 基于UCB 的采樣算法分析
實驗比較了本文基于UCB 公式采樣訓練出來的模型與使用平均采樣概率種群學習訓練出來的模型之間的優劣,訓練時間統一控制為前者自博弈訓練3 000 輪次后。 共進行了3 次訓練,每次訓練完的兩個模型之間進行100 局對戰,綜合勝負情況展示見表1。 當使用UCB 公式對對手智能體進行采樣時,訓練所得的模型明顯有更高的勝率。 由表1 中數據分析可知,由于UCB 公式在有限的時間內能夠更好的平衡各個對手智能體的對戰權重,若當前模型對戰某個隨機初始化訓練的模型勝率較低時,該公式則會鼓勵當前模型多與該模型進行對戰,盡快彌補缺點,因此提升了訓練的效率。

表1 對戰平均采樣群落學習100 局表現Tab.1 Results of 100 games against average sampling PBL
4.3 自注意力層分析
嘗試將LSTM 以及自注意力層進行替換,來驗證在該問題中是否自注意力比LSTM 更快地收斂并得到更優的解。 如圖1 所示,使用LSTM 的變體模型在訓練時Actor loss 的波動情況更加明顯、更不穩定,且收斂速度更慢,最終收斂的loss 值略大于使用自注意力層的模型。
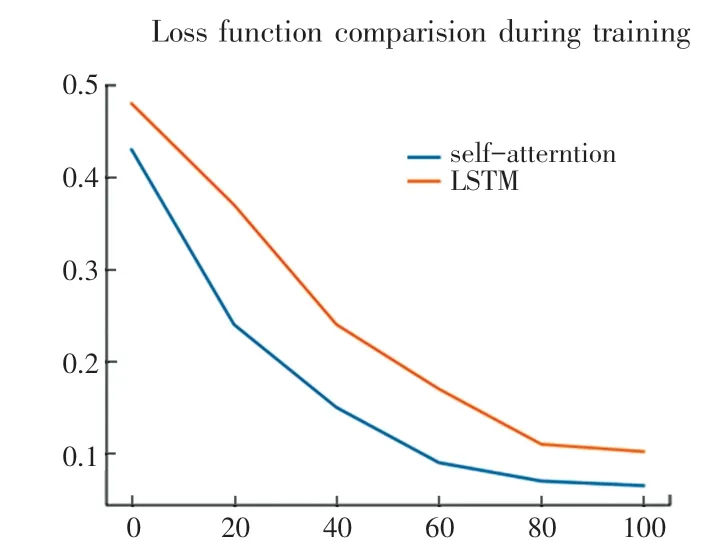
圖1 不同算法收斂速度比較Fig.1 Comparison of convergence rate with different algorithm
經分析得出,導致該問題的原因:一是LSTM 結構的網絡,在強化學習訓練中訓練難度較大,表現不穩定;二是在空戰問題中,由于有較明顯的開局、交火等不同階段,行動策略有明顯變化,而LSTM 無法直接屏蔽上一階段策略數據的影響,并且LSTM 的訓練速度明顯慢于使用近段數據進行自注意力機制交互對歷史數據進行建模的方法。
5 結束語
本文針對空戰博弈對抗問題提出了一種訓練性能效率高,且性能優秀的強化學習模型PSA-Air。該模型首先提出了一種基于智能體相對位置的行動方式,在處理環境輸入時借鑒Transformer 中的疊層自注意力機制,來進行各個智能體狀態的交互解析。實驗證明,PSA-Air 比直接使用LSTM 進行解析有更快的收斂速度以及更好的表現。 實驗中,結合UCB 公式的群落學習算法相比平均采樣的變體更加適合于訓練深度強化模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
