航行通告信息抽取方法研究
2022-04-14 03:27:12潘正宵羅銀輝李榮枝
現(xiàn)代計(jì)算機(jī) 2022年2期
潘正宵,羅銀輝,李榮枝
(中國(guó)民用航空飛行學(xué)院計(jì)算機(jī)學(xué)院,四川 618300)
0 引言
航行通告是以電信方式發(fā)布,告知飛行人員與飛行業(yè)務(wù)相關(guān)人員關(guān)于航空設(shè)施、服務(wù)、程序等的建立、情況或者變化,以及對(duì)航空有危險(xiǎn)的出現(xiàn)和變化的通知。一份標(biāo)準(zhǔn)的航行通告報(bào)文應(yīng)包括航行通告標(biāo)志、Q項(xiàng)(限定行)、A項(xiàng)(發(fā)生地)、B項(xiàng)(生效時(shí)間)、C項(xiàng)(失效時(shí)間)、D項(xiàng)(分段時(shí)間)、E項(xiàng)(航行通告正文)、F項(xiàng)(下限)和G項(xiàng)(上限)。以上各項(xiàng)內(nèi)容除E項(xiàng)外,均有標(biāo)準(zhǔn)的發(fā)布規(guī)范,而航行通告的E項(xiàng)報(bào)文屬于自由文本,采用明語的形式編寫來表達(dá)豐富的內(nèi)容,故E項(xiàng)中的內(nèi)容難以采用統(tǒng)一的格式進(jìn)行處理。因此,如何自動(dòng)化提取E項(xiàng)中所包含的重要信息一直是業(yè)界的難題。
文本信息抽取是自然語言處理任務(wù)中的一項(xiàng)。信息抽取(information extraction),即從自然語言文本中,抽取出特定的事件或事實(shí)信息,用于從海量的信息中,將內(nèi)容自動(dòng)分類,提取關(guān)鍵信息和重構(gòu)。抽取出的信息通常包括命名實(shí)體(entity),關(guān)系(relation)和事件(event)。
基于神經(jīng)網(wǎng)絡(luò)模型進(jìn)行建模的CNN和LSTM等方法廣泛應(yīng)用于信息抽取,然而神經(jīng)網(wǎng)絡(luò)的訓(xùn)練,依賴大量數(shù)據(jù),這阻礙了它在小數(shù)據(jù)集上的運(yùn)用。而符號(hào)主義,是一種將符號(hào)系統(tǒng)和有限合理性原理知識(shí)系統(tǒng)整合起來,形成公理體系的一種方式。利用符號(hào)進(jìn)行知識(shí)表達(dá)的規(guī)則系統(tǒng),及模式匹配系統(tǒng),在少量數(shù)據(jù)集或需要明確解釋性的場(chǎng)景中廣泛使用。
由于航行通告信息沒有公開的標(biāo)注集,沒有制定航行通告中實(shí)體的依存關(guān)系的關(guān)系圖譜,故而在當(dāng)前條件下無法使用深度學(xué)習(xí)等方法,只能在模式匹配技術(shù)的基礎(chǔ)之上,實(shí)現(xiàn)信息抽取任務(wù)。
文本信息的抽取,具有較強(qiáng)的目的性,要求提取出來的信息具有一定的邏輯關(guān)聯(lián),能以指定的框架進(jìn)行展示。本文根據(jù)識(shí)別出來的命名實(shí)體之間的位置,分析其依存關(guān)系,形成邏輯框架,并依照此框架,采用模式匹配的方法,抽取出航行通告中實(shí)體間的關(guān)系。本文的研究課題源于實(shí)習(xí)期間公司的航行通告信息處理同事的痛點(diǎn),旨在促進(jìn)航行通告信息的高效利用,開展對(duì)航行通告信息抽取的方法研究,提高航行通告信息處理的效率。該方法實(shí)現(xiàn)了航行通告中實(shí)體和關(guān)系的標(biāo)注及抽取,并生成格式統(tǒng)一的標(biāo)注數(shù)據(jù)集,具有工程實(shí)用價(jià)值與學(xué)術(shù)研究?jī)r(jià)值。
1 理論基礎(chǔ)
1.1 令牌化
分詞是NLP(nature language processing)的基礎(chǔ),分詞的準(zhǔn)確度直接影響了后續(xù)的詞性標(biāo)注,以及文本分析的質(zhì)量。本項(xiàng)目主要處理AIP文件中的航行通告E項(xiàng),以英文的形式呈現(xiàn)。英文語句使用空格將單詞進(jìn)行分隔,具有分詞效果。但在航行通告中,存在諸如連詞符等特殊字符,需要重新自定義分詞邏輯。
在分詞的工作中,采用令牌化思想。令牌化的作用在于處理的過程中,標(biāo)記文本,基于某些預(yù)定義規(guī)則將文本轉(zhuǎn)換為較小子文本,把句子拆分成單詞、標(biāo)點(diǎn)符號(hào)等元素。
令牌化分為詞級(jí)標(biāo)記,字符級(jí)標(biāo)記與子字級(jí)標(biāo)記。本文采用子字符級(jí)標(biāo)記,屬于前兩種方式的綜合形式。由于航行通告中大部分都是縮寫且意義不連貫的單詞,故采取詞級(jí)標(biāo)記,能取得較為良好的效果。但在有特殊字符的情況下,對(duì)特定字符采用字符級(jí)標(biāo)記,可更精準(zhǔn)地對(duì)所有詞進(jìn)行標(biāo)記并分隔。
1.2 詞嵌入與相似度
文本匹配是NLP中常見的一個(gè)問題,本文中命名體的識(shí)別,實(shí)際上就是一個(gè)文本匹配的過程,通過判斷兩個(gè)令牌之間的相似度,來判斷這兩個(gè)令牌是否屬于同一個(gè)類別信息。
在識(shí)別特定的命名實(shí)體時(shí),采取了詞嵌入(word embedding)的方法。首先通過詞向量算法,得到每個(gè)經(jīng)由分詞后單詞的詞向量,然后將已訓(xùn)練好的詞嵌入模型遷移至任務(wù)中來,讓原本的維度較高的詞向量降維成維度較低的詞嵌入向量,每一個(gè)詞就是詞嵌入模型空間中的一個(gè)點(diǎn)。這時(shí),命名體識(shí)別的任務(wù),就轉(zhuǎn)變?yōu)榱宋谋局忻恳粋€(gè)詞嵌入向量v,與提取出來的每個(gè)類別的命名實(shí)體的樣例詞嵌入向量v之間的距離關(guān)系判別任務(wù)。計(jì)算其相似度的相似值sim(v,v)采用余弦相似度公式,如公式(1)所示。


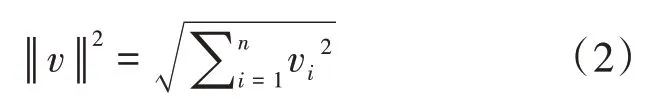
sim(v,v)越接近1則說明兩個(gè)詞越相似,文本中的詞與樣例間的相似值超過一個(gè)設(shè)定的閾值后,即可認(rèn)為該部分文本屬于此類別的命名實(shí)體。
1.3 模式匹配與改進(jìn)KMP算法
由于命名體之間的距離及順序是天然具有一定關(guān)系的,這就意味著,可以通過歸納一定距離內(nèi)的命名實(shí)體的順序,從而分析它們之間的關(guān)系,形成一種特定的邏輯關(guān)聯(lián),并將信息重新組合成一套固定的框架。
在匹配的過程中,相較于普通的遍歷匹配,本文采用了字符串匹配中用的KMP算法并加以改進(jìn)。KMP算法主要通過消除主串指針的回溯來提高匹配的效率,其核心思路是提取并運(yùn)用了加速匹配的信息,即在模式串中加入next標(biāo)簽。采用這種方式,在每次匹配失敗的時(shí)候,不需要回退到模式串開始匹配的位置往后一位重新匹配,而是往后k-1位開始重新匹配。
而改進(jìn)的KMP算法是在此基礎(chǔ)之上,將匹配串中也加入類似于next數(shù)組的標(biāo)簽。采用此改進(jìn)方式,則可在原本的減少模式串回退的基礎(chǔ)之上,進(jìn)一步減少匹配串的回退過程,加快匹配速度。本文中由于匹配的是標(biāo)簽順序,因此參考KMP算法匹配字符串的思想,匹配標(biāo)簽列表。
1.4 評(píng)價(jià)指標(biāo)
在評(píng)估相似值是否符合預(yù)期要求時(shí),引入精確率和召回率進(jìn)行評(píng)估。其中精準(zhǔn)率是針對(duì)預(yù)測(cè)結(jié)果而言,它表示預(yù)測(cè)為正的樣本中有多少是真正的樣本,用P來表示。P的計(jì)算如公式(3)所示。其中TP是準(zhǔn)確地將正類預(yù)測(cè)為正類的數(shù)量,F(xiàn)P是錯(cuò)誤地把負(fù)類預(yù)測(cè)為正類的數(shù)量。
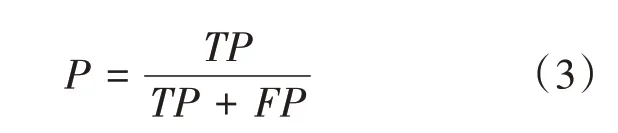
而召回率是針對(duì)樣本而言,它表示樣本中有多少正類被成功預(yù)測(cè)了,用R來表示,R的計(jì)算如公式(4)所示。其中FN表示把錯(cuò)誤地把正類預(yù)測(cè)為負(fù)類的數(shù)量。
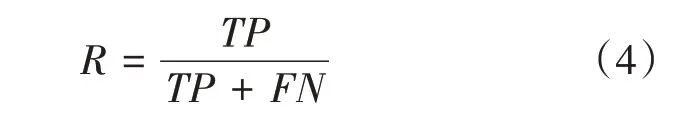
在評(píng)判實(shí)體間距離與關(guān)系抽取準(zhǔn)確率之間的關(guān)系時(shí),引入F值作為評(píng)估標(biāo)準(zhǔn),F(xiàn)的計(jì)算如公式(5)。
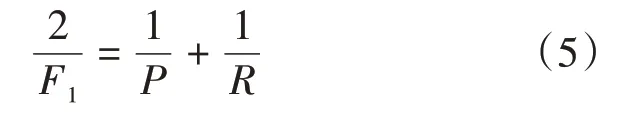
2 實(shí)現(xiàn)方法
針對(duì)航行通告數(shù)據(jù)的特點(diǎn),使用自定義的規(guī)則對(duì)通告內(nèi)容進(jìn)行分詞。采用詞向量算法對(duì)分詞進(jìn)行向量化處理,并由詞嵌入的方法,標(biāo)記自定義分類的命名實(shí)體并抽取。從航行通告的實(shí)際意義出發(fā),結(jié)合命名實(shí)體的位置關(guān)系,總結(jié)歸納出實(shí)體間的關(guān)系模式,采用改進(jìn)的KMP算法,進(jìn)行模式匹配,抽取航行通告中的重要信息。文章中的研究流程如圖1所示。
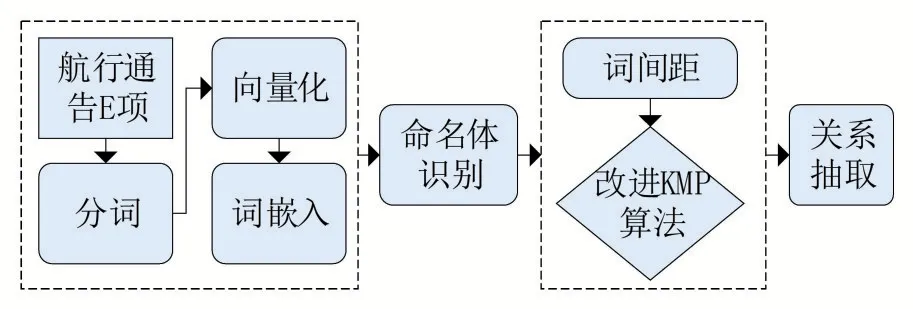
圖1 信息抽取流程
2.1 分詞過程
(1)定義標(biāo)記規(guī)則。未經(jīng)處理的文本會(huì)被以空格進(jìn)行分割。在標(biāo)記之前,可以加入自定義的需要進(jìn)行特殊標(biāo)記的符號(hào),如“-~”等,或是其余的基于詞綴的標(biāo)記規(guī)則。
(2)將文本從左到右根據(jù)定界符進(jìn)行標(biāo)記,初步形成子字符串。
(3)每一個(gè)子字符串需要再進(jìn)行兩個(gè)檢測(cè):該字符串是否匹配其他的特殊標(biāo)記規(guī)則;該字符串是否有前綴、后綴或中綴。
(4)輸出所有經(jīng)由標(biāo)記化后的令牌。
圖2是標(biāo)記化規(guī)則的示例,分詞工作完成之后,將獲得一段文本S,文本S如公式(6)所示,其中w為文本S中的第i個(gè)分詞。
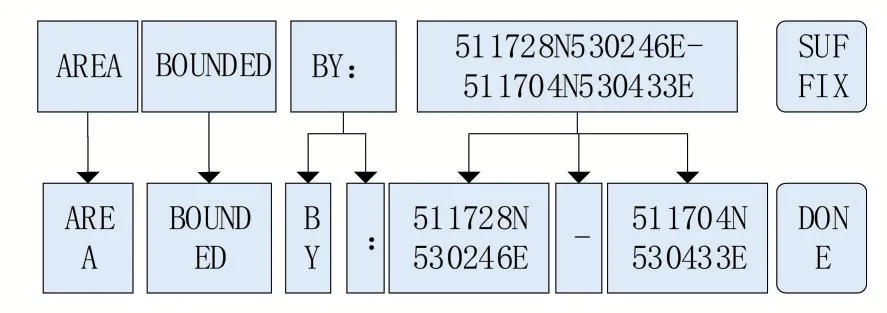
圖2 分詞示例

2.2 命名實(shí)體識(shí)別
本文主要提取了航行通告中五類信息,分別為空域關(guān)閉,危險(xiǎn)區(qū)域開放,限制區(qū)開放,跑道啟停,導(dǎo)航臺(tái)航路點(diǎn)。在系統(tǒng)性分析航行通告信息后,從中劃分出了六類命名體并自定義其標(biāo)簽,標(biāo)簽及其代表的意義如表1。
阿里知道他們?cè)谡f他。他吃著飯,一忽兒偏頭看看阿東,一忽兒又偏頭看看父親。突然就冒一句:“姆媽說了,阿里蠻乖。”

表1 自定義標(biāo)簽
每個(gè)命名實(shí)體可由如公式(7)所示的向量E來表示,其中E為該命名實(shí)體的詞向量,E表示該向量的起始字符位置,E表示該向量的中止字符位置。
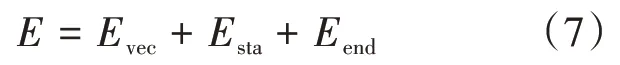
在獲取到向量E之后,根據(jù)自定義的標(biāo)簽,將E轉(zhuǎn)換為根據(jù)規(guī)則匹配上的標(biāo)簽E,隨后將新的向量E′放入T命名體集合中,T如公式(8)所示,其中E′表示的第i個(gè)向量。
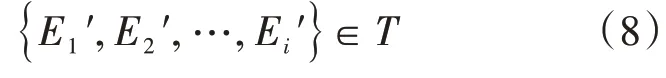
2.3 關(guān)系抽取
結(jié)合航行通告的實(shí)際意義,本文提出了五種類型的邏輯,如表2。其中action類別中的實(shí)體間距離無特殊關(guān)聯(lián),故忽略其距離關(guān)系。其他類別的關(guān)系中,關(guān)系的界定范圍與命名實(shí)體間的距離有嚴(yán)格的關(guān)系,需要在匹配的過程中,加入對(duì)于距離的判斷。

表2 邏輯關(guān)聯(lián)意義
在提取出命名實(shí)體之后,根據(jù)設(shè)定的模式串,可以進(jìn)行關(guān)系抽取,一個(gè)類別的關(guān)系,具有多個(gè)模式串,如表3中,展示的是抽取圓形區(qū)域和導(dǎo)航臺(tái)區(qū)域時(shí),出現(xiàn)的不同的模式串。
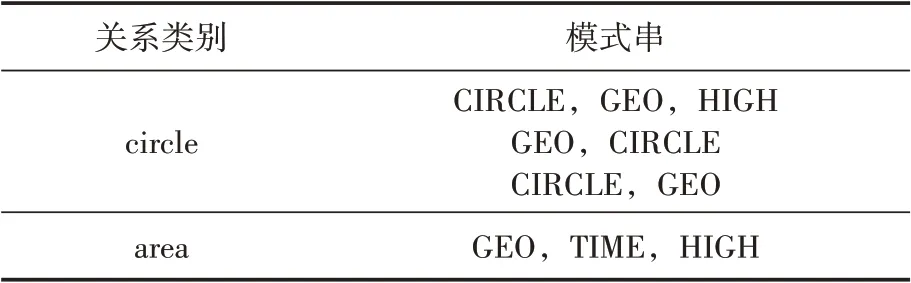
表3 模式串
采用模式匹配,可以將標(biāo)簽列表與模式串進(jìn)行匹配,獲取標(biāo)簽之間的關(guān)系,即形成三元組關(guān)系串<主體,客體,關(guān)系>。在航行通告中,一個(gè)關(guān)系串常常有多個(gè)客體,需要將對(duì)應(yīng)的多個(gè)客體轉(zhuǎn)換成一個(gè)向量來進(jìn)行存儲(chǔ)。
在2.2中獲得輸入T后,結(jié)合詞間距信息,運(yùn)用改進(jìn)的KMP算法,與表2中的五類框架所形成的模式串進(jìn)行匹配,從而實(shí)現(xiàn)關(guān)系抽取。
3 實(shí)驗(yàn)驗(yàn)證
實(shí)驗(yàn)基于Windows 10環(huán)境,編程語言為Python版本3.7,其中spaCy庫(kù)的版本為2.3.5。實(shí)驗(yàn)的數(shù)據(jù)源于2020年航行通告。提取其中航行通告的E項(xiàng)信息213851條作為實(shí)驗(yàn)的數(shù)據(jù)。
3.1 命名實(shí)體抽取方法驗(yàn)證
項(xiàng)目共提取六類命名實(shí)體,其中subject和act這兩個(gè)類別的對(duì)象根據(jù)實(shí)際經(jīng)驗(yàn)總結(jié),需要更為精準(zhǔn)的匹配,其余類別因文本差異較大,不用過于精準(zhǔn)。
使用人工標(biāo)注命名實(shí)體的數(shù)據(jù)進(jìn)行實(shí)驗(yàn),精準(zhǔn)率、召回率與匹配值的關(guān)系如圖3所示。
從圖3中可以看出,隨著相似值的上升,精準(zhǔn)率得到了提高但召回率明顯下降。根據(jù)不同命名實(shí)體類別的要求,subject和act類對(duì)精準(zhǔn)度的要求更高,而其他類要求在保證精確率的情況下,提高召回率,因此對(duì)于這兩種要求,分別采用了不同的相似值,前兩類的相似值為90%,其余類的相似值為85%。
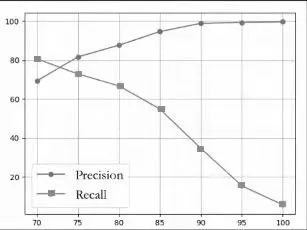
圖3 精準(zhǔn)率與召回率
對(duì)于出現(xiàn)的FP,如表4所示,可通過正則匹配或人工篩查的方式對(duì)數(shù)據(jù)進(jìn)一步地篩選,精準(zhǔn)率得以進(jìn)一步的提高。最終提取出的內(nèi)容如表5所示。

表4 錯(cuò)誤樣例

表5 命名實(shí)體提取
在實(shí)驗(yàn)結(jié)果樣例中,需要被識(shí)別的信息被//包裹、分割開來用以展示,提取出來的命名實(shí)體按照類別分別儲(chǔ)存展示。從結(jié)果可以看出,所有應(yīng)該被識(shí)別的信息都得到了有效的識(shí)別,分別打上了標(biāo)簽,且都記錄了字符串在原文中所處的位置,為后續(xù)的關(guān)系識(shí)別提供了輸入文本基礎(chǔ)。
3.2 關(guān)系抽取方法驗(yàn)證
在本文中,采用了改進(jìn)的KMP算法替代傳統(tǒng)遍歷,在遍歷速度上得到了提升,時(shí)間對(duì)比如表6所示。

表6 運(yùn)行時(shí)間對(duì)比
在實(shí)驗(yàn)過程中,發(fā)現(xiàn)航行通告中命名實(shí)體之間的距離,與它們是否產(chǎn)生關(guān)系具有較強(qiáng)的關(guān)系,定義命名實(shí)體之間的距離為D,定義當(dāng)距離大于D時(shí),兩命名實(shí)體之間不再產(chǎn)生關(guān)系。根據(jù)2.2中E的值,可計(jì)算出D。使用人工標(biāo)注了關(guān)系的數(shù)據(jù)進(jìn)行試驗(yàn),
由圖4可以看出,當(dāng)D等于5時(shí),F(xiàn)1值最高,在后續(xù)的關(guān)系抽取實(shí)驗(yàn)中,引入?yún)?shù)D,對(duì)關(guān)系自動(dòng)抽取進(jìn)行約束。
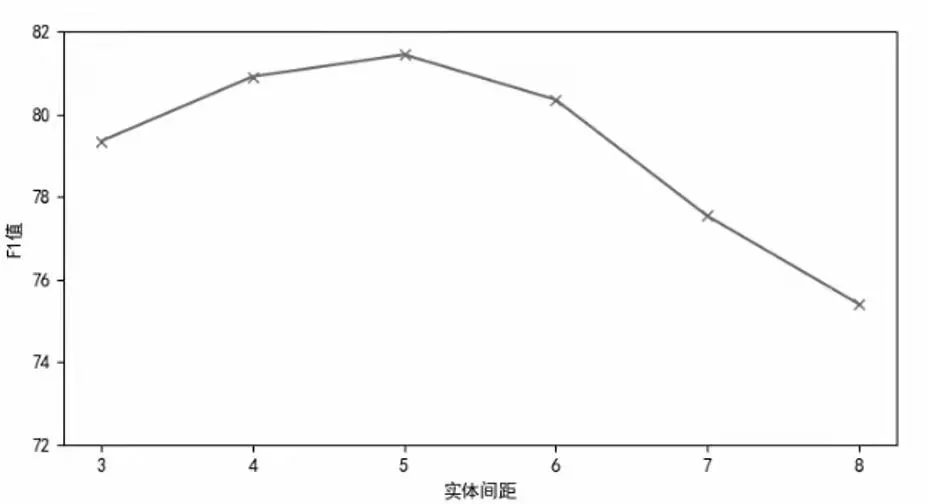
圖4 F1值與距離的關(guān)系
關(guān)系抽取后,根據(jù)工程需求對(duì)信息進(jìn)一步提取重組,信息重組之后的內(nèi)容如表7所示。

表7 關(guān)系提取
將被標(biāo)識(shí)出的命名實(shí)體經(jīng)由它們之間的關(guān)系,進(jìn)行信息重組之后,邏輯性大大加強(qiáng),能夠快速對(duì)重組后的信息進(jìn)行理解。
4 結(jié)語
本文研究了航行通告信息提取的方法,由于航行通告E項(xiàng)中的信息不具備嚴(yán)格語法特征,且在此之前,無任何公開的標(biāo)注數(shù)據(jù)集,相比基于標(biāo)注數(shù)據(jù)集進(jìn)行訓(xùn)練的模型,本文所使用的方法更具實(shí)用性。
本文實(shí)現(xiàn)了對(duì)于航行通告信息之間的關(guān)系抽取,實(shí)現(xiàn)了在該領(lǐng)域內(nèi),關(guān)系標(biāo)注從無到有的突破,可為后續(xù)無監(jiān)督條件下的信息提取技術(shù)奠定基礎(chǔ)。其余類型的航信通告信息需要重新建立關(guān)系邏輯框架,這是本文所使用的方法的局限性所在。如何針對(duì)航行通告信息弱語法的特征建立更好的關(guān)系抽取模型,需要繼續(xù)深入研究。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
中外會(huì)展(2014年4期)2014-11-27 07:46:46
語文知識(shí)(2014年1期)2014-02-28 21:59:13
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32

- 現(xiàn)代計(jì)算機(jī)的其它文章
- 基于Django的施工數(shù)據(jù)共享平臺(tái)設(shè)計(jì)與實(shí)現(xiàn)
- 基于微信小程序的教學(xué)設(shè)備維護(hù)系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
- 面向室內(nèi)環(huán)境的便攜式甲醛和總揮發(fā)性有機(jī)物監(jiān)測(cè)系統(tǒng)
- 基于Python電子設(shè)計(jì)競(jìng)賽查詢系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)
- 基于Android和微信小程序的實(shí)驗(yàn)器材設(shè)計(jì)
- 基于飛行數(shù)據(jù)的航跡精度的優(yōu)化與分析