基于網評文本的LDA游客目的地印象分析
2022-04-14 03:26:24張超群郝小芳王大睿李曉翔完顏兵
現代計算機 2022年2期
張超群,郝小芳,王大睿,李曉翔,完顏兵
(1.廣西民族大學人工智能學院,南寧 530006;2.廣西民族大學電子信息學院,南寧 530006)
0 引言
隨著大數據時代的到來,各類網絡大數據百花齊放,信息量大、可獲取性強、傳播力廣已成為網絡大數據不可替代的優勢。國家《“十三五”旅游業發展規劃》專門提到“全面建成小康社會后對旅游業發展提出更高要求,為旅游發展提供重大機遇,旅游業將迎來新一輪黃金發展期。”旅游業順應時代發展趨勢,不斷向前發展。游客滿意度是游客在到達旅游地之前的期望與游客在目的地實際體驗相對比,依據期望與實際體驗的比較結果形成的愉快或失望的狀態。目的地美譽度則是由多個因素影響,而游客對目的地的感知信任直接影響目的地美譽度。鑒于游客滿意度直接影響目的地美譽度,國內外學者對此進行了相關研究。例如,有些研究者通過遺傳算法支持向量回歸、基于經驗模型分解和神經網絡模型、上下文知識方法和在線數據來預測目的地旅游需求;有些研究者使用決策樹分析入境游客的行為,并從社會大數據中提取有用信息用于制定目的地管理策略;有些研究者運用多元回歸分析、結構化方程建模、分析搜索引擎和運用SPSS等軟件技術進行頻數、方差、因子、相關性及回歸分析獲取游客目的地形象感知,從而了解游客的行為特征。這些研究主要分析游客的行為特征,以此預測游客的偏好。
在信息化時代,游客傾向于查閱各種旅游攻略來制定個人旅游計劃,而如何從海量的網評文本數據中獲得游客的旅游偏好,成為我們的研究目標。有別于已有的相關研究重點關注行為分析,本文側重于主題分析,主要是對在線網評文本運用數據挖掘技術提取高頻詞匯,來分析游客的旅游趨向,從而了解游客的總體需求,進而優化旅游資源配置,提高游客滿意度,提升目的地美譽度,促進旅游業的可持續發展。
1 研究方法
1.1 數據來源
本文需要分析的數據來源有兩個:①由2021年第九屆“泰迪杯”全國數據挖掘挑戰賽官(https://www.tipdm.org:10010/#/competition/1354705811842195456/question)提供的數據;②爬取窮游網(https://place.qyer.com/china/citylist-0-0-1)獲得的在線網評數據。這兩個網站均提供不同類別的網評文本數據,也都包含游客對旅游目的地的印象評價。
1.2 數據處理
對源數據進行處理的總體流程如圖1所示,主要包括數據預處理、數據分析、數據篩選。首先,對網評文本主要進行re去重和Jieba分詞的預處理。然后用詞頻-逆文檔頻率(term frequency-inverse document frequency,TF-IDF)算法提取關鍵字,通過K-means算法找出聚類中心,結合K最近鄰(K-Nearest Neighbor,KNN)算法對其分類。最后,統計數據并將其按詞頻排序,在構建專業語料庫的基礎上,計算高頻詞與語料庫長度,篩選出符合隱含狄利克雷分布(latent dirichlet allocation,LDA)主題模型分析的數據,并將其映射為特征需求,從而獲得游客的旅游偏好。
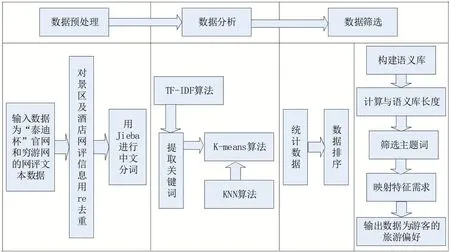
圖1 數據處理總體流程
1.2.1 數據預處理
(1)數據清理。數據清理一般是指清除噪聲、補充缺失信息和刪除離群點等過程。由于“泰迪杯”數據存在一定的單一性,在“泰迪杯”數據基礎上,為了更好地對游客目的地印象進行分析,從窮游網爬取172個網評文本頁面作為分析的基礎語料庫,該語料庫包含中國全部城市、區域名稱及相關評論。由于兩者數據包含大量的標簽信息、圖片、視頻以及一些特殊字符等無效信息,本文通過Python語言及re正則表達式,對網評文本進行數據清理,其處理過程如下:
1)清理原始數據中的特殊字符,如空格、標點符號等。
2)在大規模數據中將數據逐條讀入,清理重復出現的字段、格式不正確、時間不匹配等記錄。
3)利用re正則表達式清理每條記錄中的屬性和標簽等其他與數據分析無關的特殊符號。
4)將非結構化的文本數據轉換為計算機能夠識別的結構化數據,并將結構化數據按UTF-8編碼格式逐條寫入CSV文件中。
(2)中文分詞與停用詞過濾。中文分詞是指以空格作為分隔詞來分割出構成文本的單詞。中文文本是按單詞連字的,并且單詞之間沒有間隙。因此,在處理中文文本消息時,首先需要做的一件事情是拆分單詞,稱其對應的技術為自動分詞技術。中文分詞技術主要分為如圖2所示的四類。
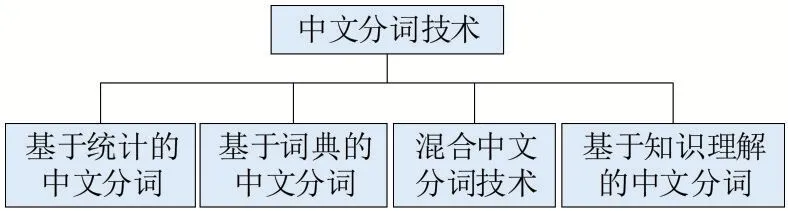
圖2 中文分詞技術分類
本文采用Python Jieba庫對中文進行分詞。Jieba庫采用基于前綴詞典實現高效詞圖掃描,獲取每個詞的詞頻,用正則表達式切分語句并對其分詞,生成所有可能成詞情況的有向無環圖,采用動態規劃查找最大概率路徑,找出基于詞頻的最大切分組合;對于未登錄詞,采用基于漢字成詞能力的隱馬爾科夫模型(hidden markov model,HMM),使得中文分詞效果最優化。
在對文本數據分詞后,仍然存在很多對數據分析無意義的詞,這些詞統稱為停用詞。為了進一步減輕數據分析難度和提高建模分析效果,需要對網評文本去停用詞。本文中的停用詞主要來源于網絡中通用的停用詞,通過過濾掉文檔中的停用詞,可以大大減少內存的占比并降低停用詞帶來的噪聲,從而有效提高分詞的精確性。
1.2.2 數據分析
(1)TF-IDF算法。在對網評文本數據分詞后,需要把這些詞語轉化為向量,以供挖掘分析使用,這里采用TF-IDF算法,把網評信息轉換為權重向量。TF-IDF算法的具體原理如下:
1)計算詞頻,即TF權重(term frequency)。

2)計算逆文檔頻率(inverse document frequency),即IDF權重。
建立一個語料庫,用于模擬文本的使用情景。若文本中的詞條與語料庫吻合度低,則IDF越大,表明該詞條類別區分能力較強。

TD-IDF與詞條在文本中出現的次數成正比,與在整個語言中出現的次數成反比。求文本中每個詞的TF-IDF值,并進行排序,詞頻較高的即為特征詞。
生成TF-IDF向量的具體步驟如下:
1)運用TF-IDF算法,找出每個網評信息中與服務、位置、設施、衛生、性價比相關的關鍵詞。
2)從網評文本中提取1)得到的關鍵詞,組成集合,計算每個集合分詞的詞頻,若無,則記為0。
3)按公式(3)計算每個網評信息的TF-IDF權重向量。
(2)特征提取。特征提取的流程如圖3所示,文本處理一般是將詞語作為特征項,如果直接使用分詞后的數據不僅會造成“維數災難”,而且會給后續的評分預測模型的構建與分析帶來很大困難。若將無關詞語提取出來,將會對模型評分預測造成干擾,影響最后結果,因此,需要根據詞語在評論文本中的重要性,賦予其權重值,特征詞權重越大就越能表示評論文本的情感,對最后結果影響越大。根據特征詞的權重將影響評分預測的詞語特征選出,運用TF-IDF過濾掉在網評文本中出現次數較少的詞并計算特征詞的權重。
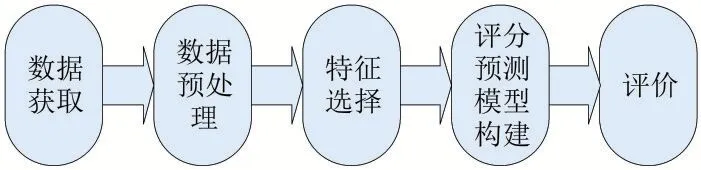
圖3 特征提取流程
(3)K-means聚類。通過去重后對文本進行分詞,運用K-means算法提取五個關鍵詞的聚類中心。根據“少數服從多數”判定聚類中心所屬類別。K-means算法的大致步驟如圖4所示。

圖4 K-means算法步驟
(4)KNN算法。由K-means分類得到聚類中心,并結合KNN算法得出中心相似元素,從而判斷其類別。KNN算法是一種簡單的無參數的文本分類方法,不需要給定額外數據,即使存在噪聲也可以對給定實驗樣本數據通過比較進行有效的分類,其處理流程如圖5所示。

圖5 KNN算法處理流程
1.2.3 數據篩選
對網評文本進行數據預處理后,統計每一條評論內容的中文字符數,并和爬取窮游網得到的語料庫進行比較來區分評論文本的有效性。對數據分類,將其區分為有效評論和無效評論兩類。其中,有效評論是指大于5個詞且符合語料庫的評論;而無效評論是指小于5個詞且不符合語料庫的評論。對網評文本進行分類處理的流程如圖6所示。
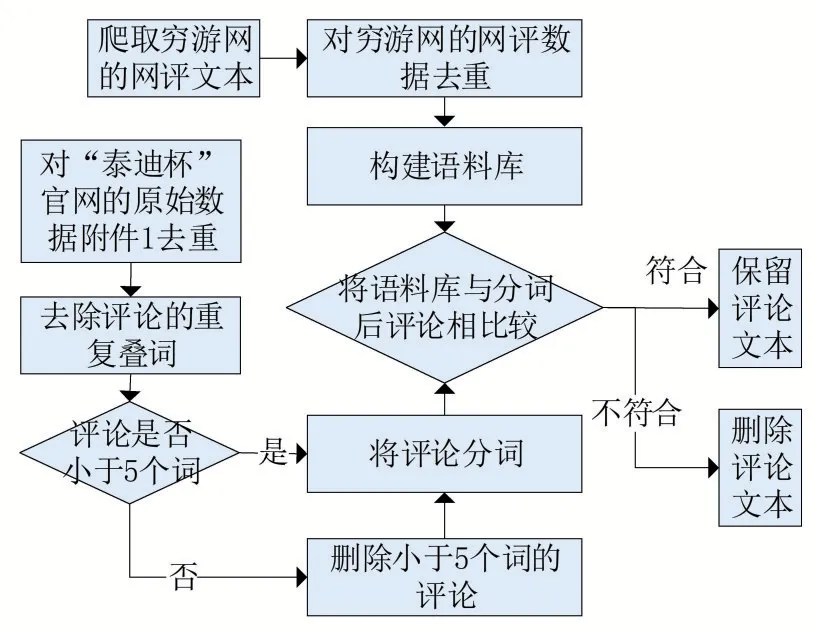
圖6 網評文本分類處理流程
圖7、圖8分別是對景區、酒店的評論數據進行處理前后的數據量變化對比圖,這說明對網評文本進行數據處理可以有效減少后續分析要處理的數據量。
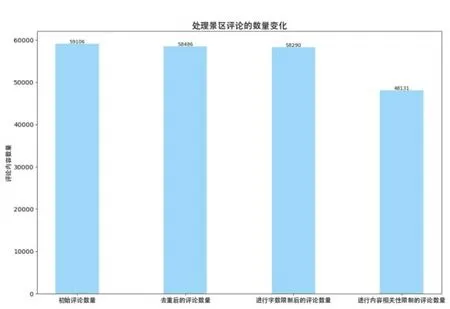
圖7 景區評論數據數量變化對比
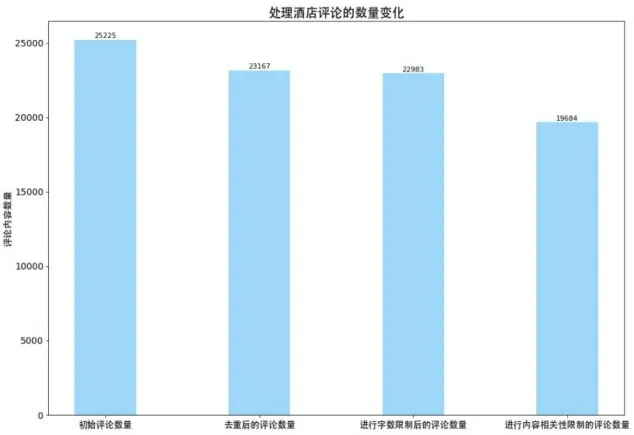
圖8 酒店評論數據數量變化對比
2 旅游目的地形象感知分析
2.1 旅游感知形象高頻特征詞分析
通過對網評文本進行詞頻分析,從文本中提取出排名在前20名的熱門旅游目的地,其結果如表1所示,詞頻越高表示游客對其關注度越高。用詞云圖對游客目的地進行可視化,其結果如圖9所示,詞頻越高,詞語呈現越大;反之,詞頻越低,詞語呈現越小。
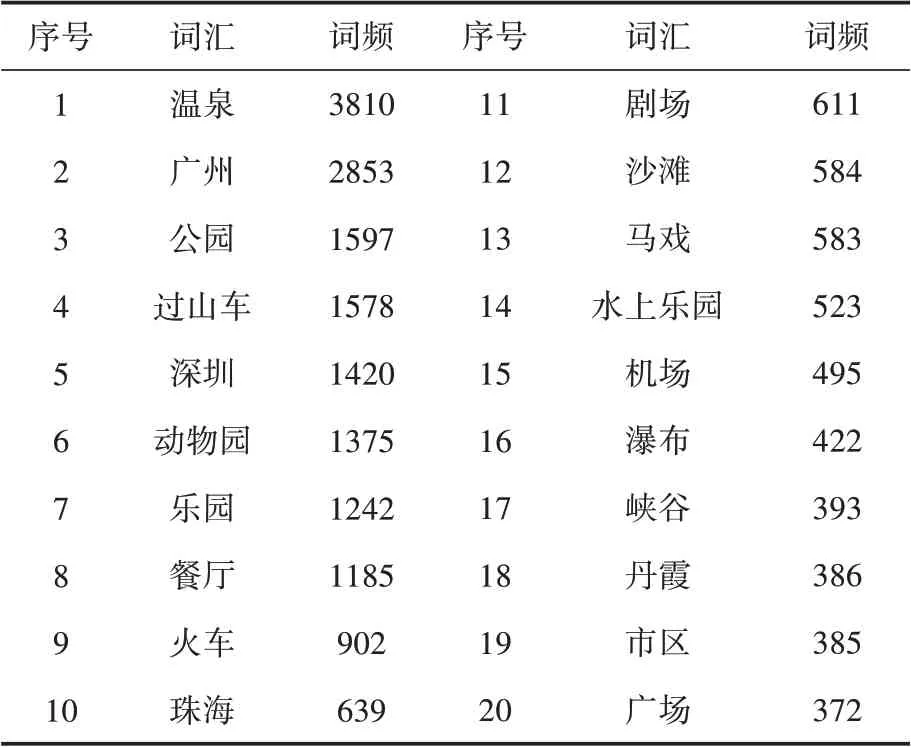
表1 排名前20的旅游目的地熱門詞

圖9 游客目的地詞云圖
由表1和圖9可知,頻次較高的旅游目的地景點有溫泉、公園、過山車、動物園、樂園、沙灘、瀑布、峽谷等,說明游客在業余時間喜歡戶外游玩,偏向于去景點放松和參加集體游玩項目,體現當代廣大人民群眾的休閑旅游的特征。此外,頻次較高的旅游目的地有廣州、深圳、珠海等,說明游客傾向于去南方城市游玩。
2.2 旅游感知形象主題維度分析
利用LDA主題模型進行景區及酒店主題挖掘,并對聚類的結果進行可視化展示,呈現出聚類主題和每個主題中的關鍵詞。根據主題中體現的游客評論的關注點,整理、歸納并總結出游客關注指標,對用戶關注差異進行分析。
由于網評數據量大,從海量文本中直接獲取有用的信息較為困難。在網評文本挖掘的過程中,對網評文本預處理后,用LDA模型對其進行主題識別,以挖掘網評語料中隱藏的用戶需求,獲得的主題識別圖如圖10—圖14所示。
圖10—圖14是對網評文本數據進行主題分析,根據高頻詞的分布情況,將其從5個維度進行可視化。在主題識別圖的左側,每個圓圈代表海量文本的一個主題;圓圈之間的距離體現主題之間的相似度,如果距離越近,則說明兩個主題越相似;圓圈的大小表示主題出現的概率,越大說明其所代表的主題核心度越高,小圓圈代表次要主題。在主題識別圖右側的條形圖中,每列對應的主題詞與文本詞語的關聯度表示為:
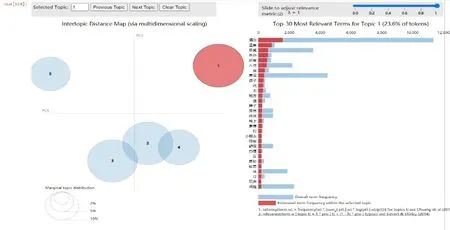
圖10 評論數據識別主題1(服務)
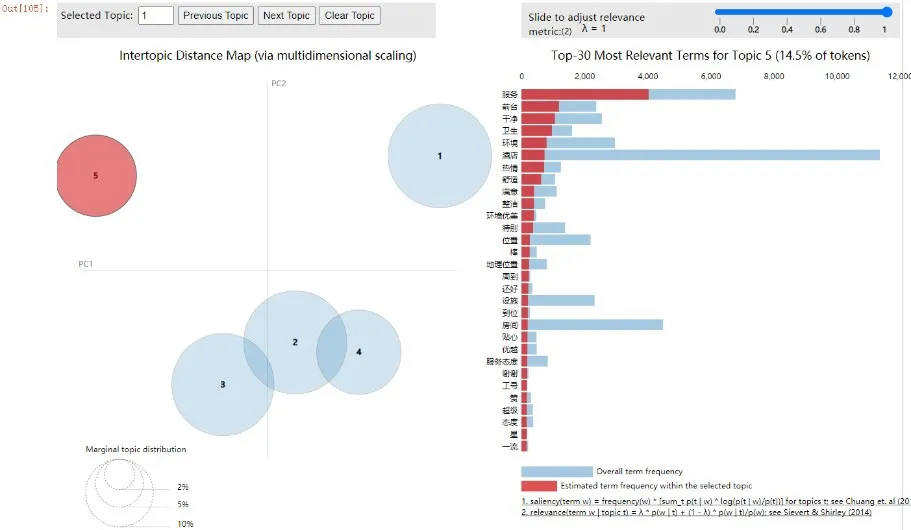
圖14 評論數據識別主題5(衛生)
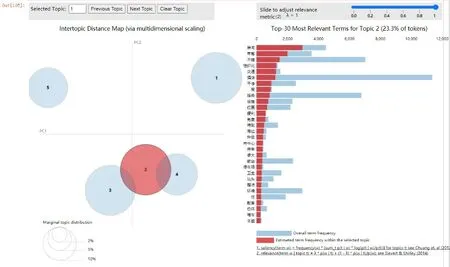
圖11 評論數據識別主題2(位置)
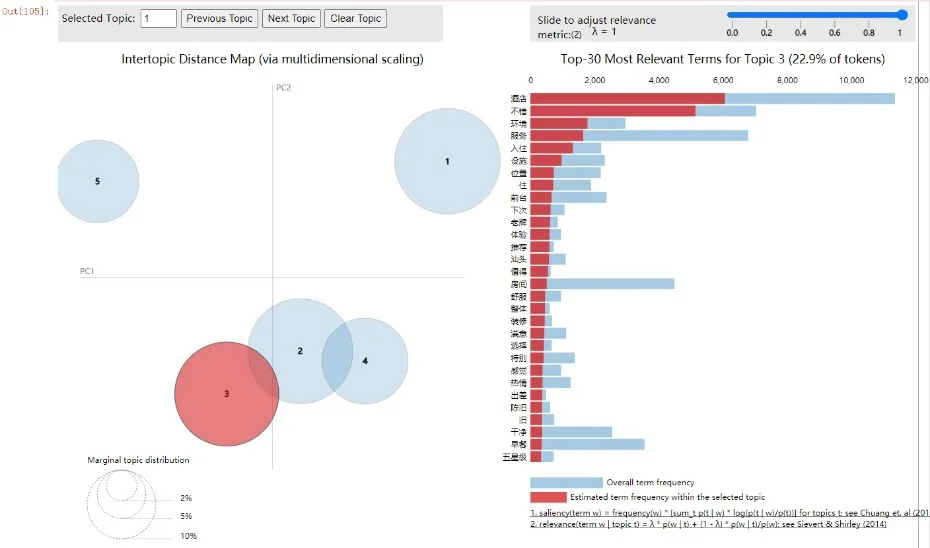
圖12 評論數據識別主題3(設施)
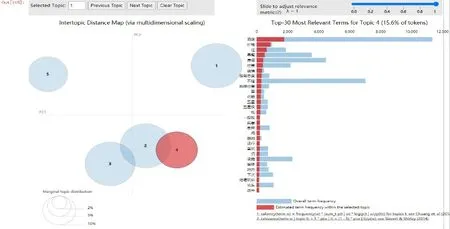
圖13 評論數據識別主題4(性價比)
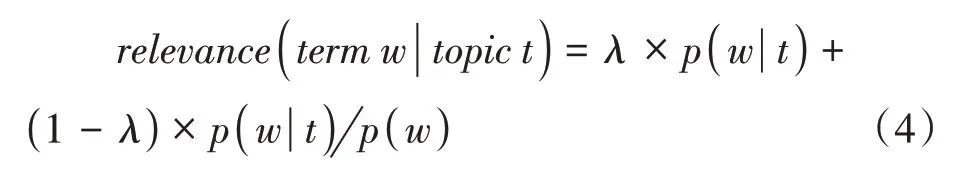
主題和文本詞語間的關聯度由詞頻和詞語表現,并且可以通過調節參數λ(0≤λ≤1)來調節關聯度。若λ越趨近于1,則認為該主題下詞頻越高的詞與主題越相關,但這些出現次數較多的詞可能同時出現在其他主題中。若λ越趨近于0,則表明該主題下特征詞與主題越相關,這些詞通常僅趨向于該主題。
本文取λ=1,對于圖10—圖14,圖中5個圓圈的大小表示主題出現的概率大小,每個圓圈之間的距離為不同主題之間的關聯度,條形圖為每個主題的可視化展示,不同的主題對應不同的條形圖,每個條形圖中標紅部分為該主題詞在對應的主題中出現的頻次,即為游客特征需求。從圖10—圖14中可知,主題1(服務)和主題5(衛生)清晰分明,與其他主題沒有重疊和交叉現象;而主題2(位置)、主題3(設施)和主題4(性價比)之間有交叉重疊現象,說明這幾個主題之間有重復的主題詞。
通過LDA模型對網評文本進行主題識別,將圖10—圖14中條形圖的每個主題映射為特征需求,根據每個主題的分類屬性,可將所有的評論數據集識別為“服務”“位置”“設施”“性價比”“衛生”這5個主題,根據公式(4)可計算出每個主題詞與文本詞語之間的關聯度分別為23.6%、23.3%、22.9%、15.6%和14.5%,關聯度表示主題詞與文本詞語間的關聯關系,具體關聯程度由詞頻和詞語表現,詞頻越高則表示與該主題的關聯度越高,具體實驗結果如表2所示。由表2可知,游客對服務的關聯度最大,有酒店、溫泉、早餐、房間、適合、感覺、體驗等特征需求,這表明游客更關注對目的地服務的評價。
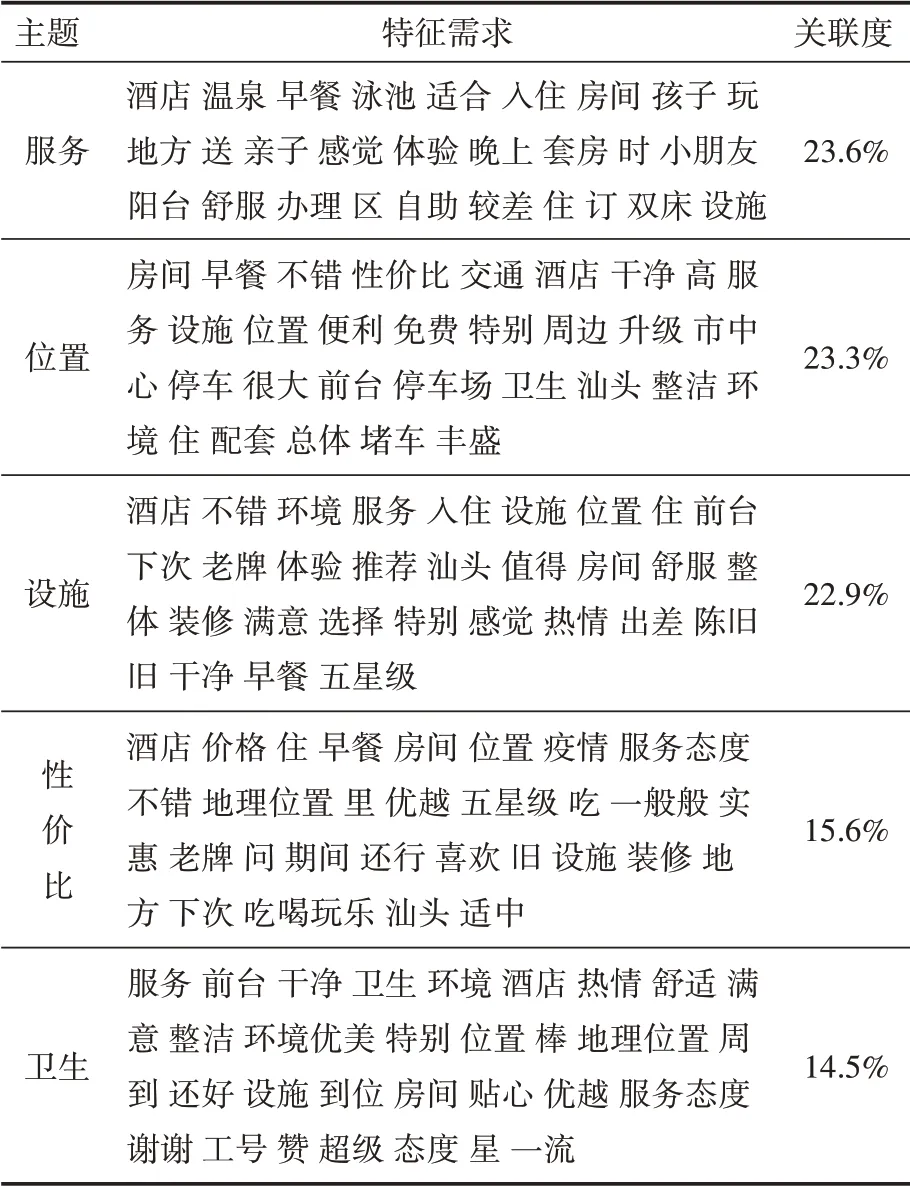
表2 游客特征主題需求映射
在旅游過程中,游客最關注景區及酒店的特征需求,游客通過對旅途的真實反饋,在一定程度上能將自身需求傳遞給旅游企業,以便企業對旅游方案做出針對性調整。表2正是將游客網評數據映射為企業最關注的特征需求,以此來挖掘游客更深層次的需求,有助于企業將未來規劃與游客的旅游偏好密切聯系起來。
3 旅游企業健康持續發展建議
網評文本數據已成為旅游企業獲取游客需求的主要渠道。隨著經濟的不斷發展,人們開始追求更高質量的生活,對旅游也有更高的要求。為了精準定位目標游客,旅游企業應充分了解游客喜好,提供大眾喜聞樂見的服務。基于上文的分析結果,對旅游企業的健康持續發展建議如下:
(1)針對服務方面,了解游客真正需求,提供精準個性化服務。針對不同客戶群體,推出多種特色旅游服務套餐。例如,針對親子旅游,可選擇成人和小孩游樂設施并存的景區,并提供家庭式的酒店客房;針對青年游客,可選擇當下熱門刺激、性價比高的游樂項目,并提供現代化簡約風格的酒店客房;針對情侶游客,可為其提供浪漫的情侶套房,個性化定制浪漫景區的旅游路線,還提供旅行拍攝的服務;針對老年游客,可為其制定紅色或自然景區路線,選擇環境舒適、價格實惠的酒店。
(2)針對位置、設施和性價比方面,借助大數據分析與預測,開發旅游景區流量監控系統,為游客提供最佳的旅游路線,并且大力加強基礎設施建設,建立智慧景區和智慧酒店,保證旅游服務和價值付出成正比。
近年來,旅游需求猛增和時空分布不均,熱門景區高度集中,資源供不應求。對此應該充分利用交通、地理位置、社交媒體、氣候、住宿等大數據,開發流量檢測系統,提前對游客流量進行有效監控。同時應該推動旅游的信息化發展,如提供景區電子門票售票、進出口電子檢票、智能排隊、電子導游、二維碼識別語音講解、酒店自助入住等,不斷提高景區和酒店基礎設施建設,提高性價比。
(3)針對衛生方面,應該加強對酒店和景區的衛生監管,加大衛生的宣傳力度。
隨著景區的游客量增大,景區也面臨著衛生問題,因此,在景區應該修建適量的衛生區,方便游客處理旅途中產生的垃圾。與此同時,應設立相應的監管部門,對破壞景區衛生的行為做出相應處罰。同時,政府加強保護環境的宣傳力度,增強公民的衛生環保意識。
4 結語
隨著大數據時代的到來及人民生活水平不斷提高,旅游業發展也應順勢而為。有別于已有的相關研究重點關注游客的行為分析,本文主要根據文本分析理論,對“泰迪杯”挑戰賽官網、窮游網的網評文本數據先用正則表達式等方法進行數據清理,再用Jieba庫分詞,接著用TF-IDF算法提取關鍵詞,根據K-means聚類得出聚類中心,結合KNN算法將其分類,用LDA模型進行主題分析,并將主題詞映射為特征需求。實驗結果表明,游客主要關注目的地的服務、位置、設施、性價比、衛生,并根據分析得到這五個方面的特征需求對旅游企業健康持續發展提出三條有益建議,有助于旅游企業將游客的旅游偏好與企業的未來規劃結合起來,優化旅游資源配置,不斷提高游客滿意度,從而提升目的地美譽度,盡量滿足游客多元化的旅游需求。
由于數據的安全性和保密性,獲取數據難度較大,本文僅對“泰迪杯”挑戰賽官網和窮游網的網評文本數據進行分析。下一步將通過多渠道方式獲取形式多樣的數據進行全面深入的研究,使研究成果更具有普適性。
猜你喜歡
少兒科技(2022年4期)2022-04-14 23:48:10
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
好孩子畫報(2018年7期)2018-10-11 11:28:06
今古傳奇·故事版(2016年24期)2017-02-07 04:29:04
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
數學大王·低年級(2014年7期)2014-08-11 16:36:44
語文知識(2014年1期)2014-02-28 21:59:13
