基于自注意力膠囊網(wǎng)絡(luò)的偽造人臉檢測(cè)方法
2022-02-24 05:06:40李邵梅吉立新
計(jì)算機(jī)工程 2022年2期
李 柯,李邵梅,吉立新,劉 碩
(解放軍戰(zhàn)略支援部隊(duì)信息工程大學(xué)信息技術(shù)研究所,鄭州 450003)
0 概述
隨著深度學(xué)習(xí)技術(shù)的發(fā)展,以換臉為代表的人臉偽造視頻開(kāi)始在社交媒體上廣泛傳播,包括基于計(jì)算機(jī)圖形學(xué)的方法FaceSwap、Face2Face[1]以及基于深度學(xué)習(xí)的方法DeepFakes、NeuralTextures[2]等主流的人臉偽造生成方法。該技術(shù)的濫用將對(duì)個(gè)人隱私和國(guó)家政治安全帶來(lái)巨大的威脅。
針對(duì)當(dāng)前以換臉為代表的偽造視頻的危害,國(guó)內(nèi)外學(xué)者對(duì)視頻中偽造人臉的檢測(cè)方法進(jìn)行了大量研究。目前,視頻偽造人臉檢測(cè)的方法主要包含基于幀間特征的檢測(cè)方法和基于幀內(nèi)特征的檢測(cè)方法兩類(lèi)。基于幀間特征的檢測(cè)方法主要關(guān)注視頻前后幀中的時(shí)序信息,文獻(xiàn)[3]將視頻每一幀的特征向量經(jīng)過(guò)處理后,輸入到LSTM 網(wǎng)絡(luò)中得到幀間特征,作為分類(lèi)的依據(jù)。文獻(xiàn)[4]利用視頻相鄰幀中人臉圖像存在差異的特性提出一種檢測(cè)方法。基于幀間特征的檢測(cè)方法無(wú)法判斷單幀的真?zhèn)危瑫r(shí)對(duì)待檢測(cè)視頻的長(zhǎng)度存在需求,對(duì)模型訓(xùn)練條件的要求也較高,因此在實(shí)際應(yīng)用中存在限制。
基于幀內(nèi)特征的檢測(cè)方法是采用傳統(tǒng)卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)進(jìn)行特征學(xué)習(xí),訓(xùn)練分類(lèi)器區(qū)分偽造與真實(shí)人臉圖片。文獻(xiàn)[5]利用偽造視頻在合成時(shí)需要進(jìn)行仿射變換才能匹配,從而導(dǎo)致人臉區(qū)域與周?chē)h(huán)境分辨率不一致的特點(diǎn)訓(xùn)練分類(lèi)器。文獻(xiàn)[6]利用生成視頻時(shí)存在的人為視覺(jué)上的缺陷進(jìn)行判別,具體可包括合成圖片存在的左右眼虹膜顏色不一致、在處理光照時(shí)對(duì)入射光的錯(cuò)誤處理導(dǎo)致產(chǎn)生特定的偽影、對(duì)頭發(fā)建模錯(cuò)誤導(dǎo)致的空洞等問(wèn)題,通過(guò)提取這些特征,訓(xùn)練較小的分類(lèi)器完成分類(lèi)任務(wù)。文獻(xiàn)[7]發(fā)現(xiàn)在使用2D 面部圖像估計(jì)3D 頭部姿態(tài)(比如頭的方向和位置)合成偽造圖片時(shí)會(huì)存在誤差,進(jìn)而利用該特征進(jìn)行判別。文獻(xiàn)[8]使用集成多種CNN 的網(wǎng)絡(luò)進(jìn)行視頻中的偽造人臉檢測(cè)。
針對(duì)CNN 在圖像處理中沒(méi)有考慮部件間的相對(duì)位置、角度等信息以及可解釋性較差等不足,文獻(xiàn)[9]提出了基于動(dòng)態(tài)路由的膠囊網(wǎng)絡(luò)。隨后膠囊網(wǎng)絡(luò)被應(yīng)用于計(jì)算機(jī)視覺(jué)的多個(gè)領(lǐng)域,文獻(xiàn)[10]使用膠囊網(wǎng)絡(luò)進(jìn)行肺部CT 圖像分割檢測(cè),文獻(xiàn)[11]將基于二元分類(lèi)的膠囊網(wǎng)絡(luò)應(yīng)用于醫(yī)學(xué)圖像的乳腺癌檢測(cè),文獻(xiàn)[12]嘗試將膠囊網(wǎng)絡(luò)運(yùn)用于偽造視頻檢測(cè)領(lǐng)域,提出算法模型Capsule-Forensics,在多種類(lèi)型的視頻偽造人臉檢測(cè)上均具有良好的性能。
為進(jìn)一步提高膠囊網(wǎng)絡(luò)對(duì)視頻偽造人臉的檢測(cè)效果,本文在Capsule-Forensic 的基礎(chǔ)上,提出一種基于自注意膠囊網(wǎng)絡(luò)的視頻偽造人臉檢測(cè)算法Xception-Attention-Capsules。該算法使用部 分Xception 網(wǎng)絡(luò)作為特征提取部分,在Primary Capsule部分構(gòu)建Attention-Capsules 結(jié)構(gòu),并在此基礎(chǔ)上提出新的損失函數(shù)Dimension-Focal Loss。最后運(yùn)用模型可視化技術(shù)對(duì)本文算法的檢測(cè)結(jié)果進(jìn)行分析。
1 Capsule-Forensics視頻偽造人臉檢測(cè)算法
膠囊網(wǎng)絡(luò)中的膠囊結(jié)構(gòu)是一組向量或矩陣的集合,不同輸出向量代表圖像中出現(xiàn)的特定實(shí)體的各種屬性,例如輸出向量的模長(zhǎng)表示實(shí)體存在可能性的大小。膠囊網(wǎng)絡(luò)使用向量輸出代替值輸出,可以在識(shí)別物體類(lèi)別的同時(shí)保留其位置和姿態(tài)信息;使用動(dòng)態(tài)路由算法[9]更新膠囊層間的權(quán)重,使得向量值能在不同的膠囊層間進(jìn)行傳遞。因此,與CNN 等傳統(tǒng)神經(jīng)網(wǎng)絡(luò)相比,膠囊網(wǎng)絡(luò)具有更好的泛化能力,同時(shí)對(duì)圖形變換具有更強(qiáng)的魯棒性。
NGUYEN 等[12]提出基于膠囊網(wǎng)絡(luò)的視頻偽造人臉檢測(cè)算法Capsule-Forensics,其網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。Capsule-Forensics 特征提取部分使用部分VGG-19 網(wǎng)絡(luò);Primary Capsules 部分使用了N個(gè)相同的膠囊結(jié)構(gòu),中間部分引入了Stats Pooling(Stattistic Pooling);在Primary Capsules 和Classifier Capsules 間運(yùn)用動(dòng)態(tài)路由算法進(jìn)行權(quán)重更新;Classifier Capsules 中真假膠囊將分別輸出一組N維向量,將兩組N維向量每個(gè)維度的兩兩組合進(jìn)行Softmax 運(yùn)算,最后取N個(gè)Softmax 結(jié)果的均值作為最終的預(yù)測(cè)類(lèi)別。訓(xùn)練過(guò)程中使用交叉熵(Cross Entropy,CE)損失函數(shù)。
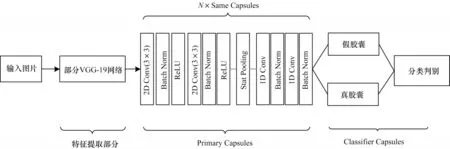
圖1 Capsule-Forensics 網(wǎng)絡(luò)結(jié)構(gòu)Fig.1 Capsule-Forensics network structure
通過(guò)分析,本文認(rèn)為該網(wǎng)絡(luò)有以下不足:一是特征提取部分參數(shù)量較大,模型訓(xùn)練速度較慢;二是Primary Capsules 中相同的膠囊結(jié)構(gòu)不利于模型關(guān)注到人臉不同位置的特征;三是交叉熵?fù)p失函數(shù)未考慮數(shù)據(jù)集中正負(fù)樣本不均衡的問(wèn)題。
2 基于自注意力膠囊網(wǎng)絡(luò)的偽造人臉檢測(cè)技術(shù)
2.1 Xception-Attention-Capsules 結(jié)構(gòu)組成
本文設(shè)計(jì)的檢測(cè)模型Xception-Attention-Capsules的網(wǎng)絡(luò)結(jié)構(gòu)如圖2 所示,分為特征提取部分、Primary Capsules、Classifier Capsules 3個(gè)部分。
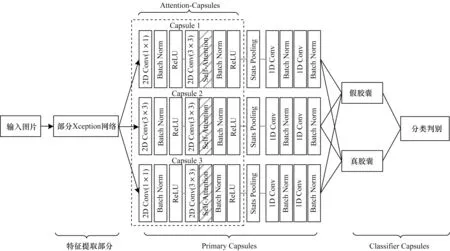
圖2 Xception-Attention-Capsules 網(wǎng)絡(luò)結(jié)構(gòu)Fig.2 Xception-Attention-Capsules network structure
相較Capsule-Forensics,本文進(jìn)行了以下3 個(gè)部分的改進(jìn):
1)特征提取部分使用部分Xception 網(wǎng)絡(luò),該改進(jìn)使模型在僅損失微小精度的情況下,相較原模型減少了85.7%的參數(shù)量,訓(xùn)練速度提高了57.3%。
2)Primary Capsules 部分提出Attention-Capsules,該部分使用3 個(gè)不同結(jié)構(gòu)的膠囊模塊,其中Capsule 1使用步長(zhǎng)為1 的1×1 卷積核;Capsule 2 使用步長(zhǎng)為1 的3×3 卷積核;Capsule 3 使用步長(zhǎng)為2 的1×1 卷積核,以保留更多的人臉信息。每個(gè)膠囊模塊中均加入了自注意力層Self-Attention。Primary Capsules 和Classifier Capsules 間使用動(dòng)態(tài)路由算法[9]更新參數(shù)。
3)Classifier Capsules 部分沿用了文獻(xiàn)[12]類(lèi)別預(yù)測(cè)的方法。通過(guò)對(duì)比分析輸出向量維度為2 維、4 維、8 維、16 維的檢測(cè)效果,本文將輸出維度設(shè)置為4,使模型在準(zhǔn)確率和收斂速度間的平衡達(dá)到最優(yōu)。另外,提出新的損失函數(shù)Dimension-Focal Loss。
2.2 基于部分Xception 網(wǎng)絡(luò)的特征提取
Xception[13]主要由殘差網(wǎng)絡(luò)與深度可分離卷積組成。Xception 包括36 個(gè)卷積層,共包含3 個(gè)flow,分別是Entry flow、Middle flow、Exit flow;包括14 個(gè)Block,其中Entry flow 中4 個(gè)、Middle flow 中8 個(gè)、Exit flow 中2 個(gè);中間12 個(gè)Block 都包含線性殘差連接。同時(shí),模型對(duì)輸入數(shù)據(jù)的每一個(gè)通道分別進(jìn)行空間逐層卷積,再對(duì)其結(jié)果進(jìn)行逐點(diǎn)卷積。如圖3所示,Xception 模型第1 步通過(guò)1×1 卷積進(jìn)行通道分離,第2 步獨(dú)立繪制每個(gè)輸出通道的空間相關(guān)性,用3×3 卷積單獨(dú)處理,最后合并。
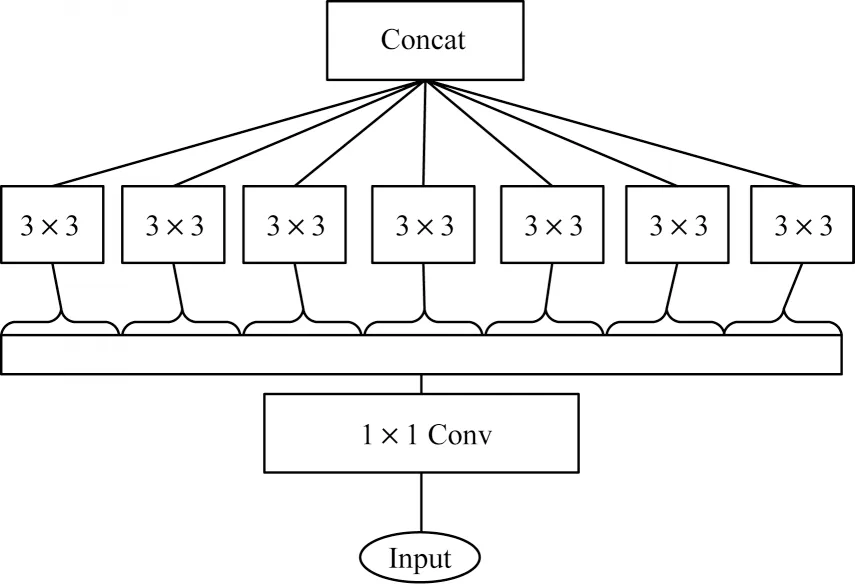
圖3 Xception 基本模塊Fig.3 Xception basic module
作為偽造視頻檢測(cè)數(shù)據(jù)集FaceForensics++[14]的基線模型,Xception 在該數(shù)據(jù)集上具有良好的效果。為 此,本文選取Xception 中Entry flow的前3 個(gè)Block 模塊作為Xception-Attention-Capsules 的特征提取部分。
2.3 基于自注意力機(jī)制的Attention-Capsules
偽造人臉大部分的操作作用于面部五官區(qū)域,面部平坦區(qū)域的信息對(duì)分類(lèi)的幫助較少。文獻(xiàn)[15]指出在神經(jīng)網(wǎng)絡(luò)中引入注意力機(jī)制,有助于使模型關(guān)注具有豐富細(xì)節(jié)的面部五官部分。
在傳統(tǒng)神經(jīng)網(wǎng)絡(luò)中,由于每個(gè)卷積核的尺寸有限,因此每次卷積操作只能獲得像素點(diǎn)周?chē)苄∫粔K鄰域,不易捕捉到距離較遠(yuǎn)的特征[16]。為此,本文采用多個(gè)膠囊模塊,每個(gè)模塊中使用大小不同的卷積核,利用不同結(jié)構(gòu)的膠囊模塊關(guān)注到不同尺寸的特征。另外,本文提出在膠囊中加入Self-Attention層[17],通過(guò)計(jì)算圖像中任意兩個(gè)像素點(diǎn)之間的關(guān)系,從而學(xué)習(xí)到某一像素點(diǎn)和其他所有位置(包括較遠(yuǎn)位置)的像素點(diǎn)之間的關(guān)系,這樣可以捕獲到更大范圍內(nèi)像素間的關(guān)系,獲取圖像的全局幾何特征。
Self-Attention 自注意力模塊結(jié)構(gòu)如圖4[17]所示,其原理是將輸入分別通過(guò)1×1 的卷積層;然后在輸出特征圖的矩陣上進(jìn)行運(yùn)算得到注意力圖;最后的注意力模塊部分將逐漸學(xué)習(xí)到如何將注意力特征圖加在原始的特征圖上,從而得到增加了注意力部分的特征圖。
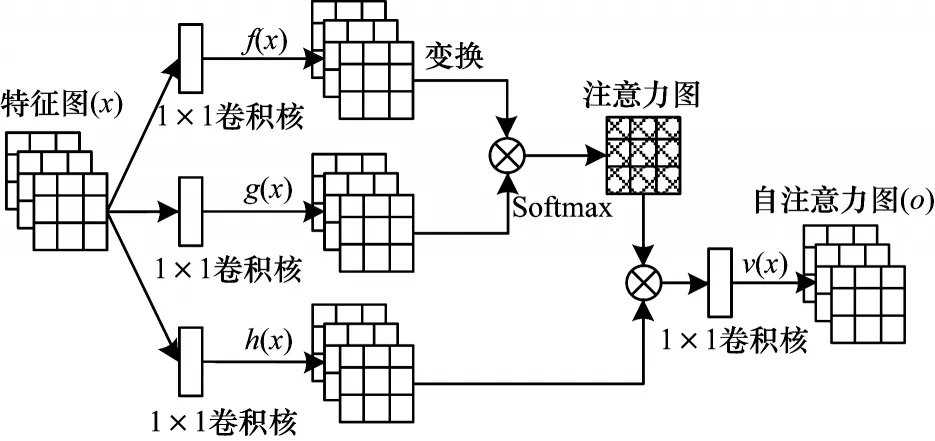
圖4 自注意力模塊結(jié)構(gòu)Fig.4 Self-attention module structure
2.4 Dimension-Focal Loss 損失函數(shù)
偽造人臉數(shù)據(jù)集普遍存在正負(fù)樣本不均衡問(wèn)題,且不同的偽造生成方法生成的視頻檢測(cè)難易也存在差別。因此,本文在Focal Loss[17]損失函數(shù)的基礎(chǔ)上提出了Dimension-Focal Loss 損失函數(shù)。該方法使用真假膠囊每個(gè)批次輸出維度損失的均值之和作為該批次最終的損失。相較于文獻(xiàn)[9]僅將最終預(yù)測(cè)結(jié)果與標(biāo)簽做交叉熵的損失計(jì)算方法,該方法可以考慮到每個(gè)維度的輸出值,并將其體現(xiàn)到損失函數(shù)上,更精準(zhǔn)地指導(dǎo)Classifier Capsule 進(jìn)行學(xué)習(xí)。
Dimension-Focal Loss 的計(jì)算步驟如下:分別計(jì)算單個(gè)樣本的單維度Focal Loss 損失,如(1)所示:
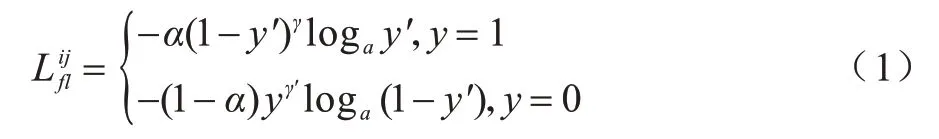
其中:α表示平衡因子;γ表示難易樣本權(quán)重;表示計(jì)算的單個(gè)樣本的單維度損失;i表示每批次對(duì)應(yīng)的單個(gè)樣本編號(hào);j表示當(dāng)前運(yùn)算的維數(shù);y表示預(yù)測(cè)標(biāo)簽;y′表示經(jīng)過(guò)激活函數(shù)Softmax 的輸出。

其中:n為批次大小;m為當(dāng)前輸出膠囊的總維數(shù);j表示當(dāng)前運(yùn)算的維數(shù);代表批次維度平均損失;loss 代表最終損失。
3 實(shí)驗(yàn)結(jié)果與分析
3.1 數(shù)據(jù)集
為評(píng)估本文方法的性能,本文在公開(kāi)數(shù)據(jù)集FaceForensics++[14]上進(jìn)行實(shí)驗(yàn)。FaceForensics++包含從國(guó)外視頻網(wǎng)站采集的1 000 個(gè)真實(shí)視頻。每條原始視頻時(shí)長(zhǎng)約為15 s,然后使用計(jì)算機(jī)圖形學(xué)和深度學(xué)習(xí)方法生成偽造視頻。使用的偽造生成方法包含F(xiàn)ace Swap、Fac2Face、Fac2Face、NeuralTextures 4 種類(lèi)型,每種方法各生成1 000 條假視頻。FaceForensics++數(shù)據(jù)集將所有視頻依據(jù)H.264 編碼進(jìn)行壓縮,共生成了3 個(gè)版本,其中Raw版本表示未進(jìn)行壓縮,HQ(High Quality)版本的壓縮參數(shù)為23,LQ(Low Quality)版本的壓縮參數(shù)為40。
3.2 實(shí)驗(yàn)設(shè)置
3.2.1 數(shù)據(jù)處理
由于該數(shù)據(jù)集中視頻的偽造區(qū)域集中在人臉面部,因此提前使用人臉檢測(cè)方法檢測(cè)并提取面部區(qū)域,將其單獨(dú)保存作為訓(xùn)練集和測(cè)試集的輸入有助于使分類(lèi)算法集中于被篡改的面部區(qū)域,減弱背景的影響,提高檢測(cè)算法的收斂速度和分類(lèi)精度。本文使用RetinaFace[18]作為人臉檢測(cè)算法,首先將每條視頻流按幀進(jìn)行截取,然后利用算法識(shí)別每幀中得分最高的人臉,以人臉為中心裁剪后并縮放至320×320 大小(該尺寸易于執(zhí)行裁剪和縮放)分別保存在對(duì)應(yīng)的視頻文件夾中。
在訓(xùn)練模型的過(guò)程中,對(duì)其增加一定概率的水平翻轉(zhuǎn)和垂直翻轉(zhuǎn)以及隨機(jī)的圖片切割。目的是增加數(shù)據(jù)集的隨機(jī)擾動(dòng),同時(shí)避免模型對(duì)圖像部分區(qū)域的過(guò)度關(guān)注,以提高模型的泛化能力。最后將圖片縮放至指定的大小,以符合模型的輸入要求,本文統(tǒng)一使用224×224 的輸入。
本文在對(duì)比測(cè)試中分別對(duì)不同壓縮版本的偽造視頻進(jìn)行了單獨(dú)實(shí)驗(yàn)和混合實(shí)驗(yàn)。在優(yōu)化方法對(duì)比測(cè)試中使用了網(wǎng)絡(luò)上最為普遍的HQ 版本進(jìn)行實(shí)驗(yàn)。視頻級(jí)則使用了LQ 和HQ 兩個(gè)版本的視頻進(jìn)行測(cè)試,每個(gè)視頻每隔10 幀抽樣進(jìn)行檢測(cè),綜合10 幀的檢測(cè)結(jié)果對(duì)視頻的真?zhèn)芜M(jìn)行判別。參考文獻(xiàn)[12]中的實(shí)驗(yàn)數(shù)據(jù)劃分,分別設(shè)置訓(xùn)練集720 條,驗(yàn)證集和測(cè)試集各為140 條,本文實(shí)驗(yàn)中FaceForensics++中每個(gè)類(lèi)別的訓(xùn)練集和測(cè)試集數(shù)量如表1 所示,其中新增Mix 類(lèi)別為4 種偽造類(lèi)型的混合。
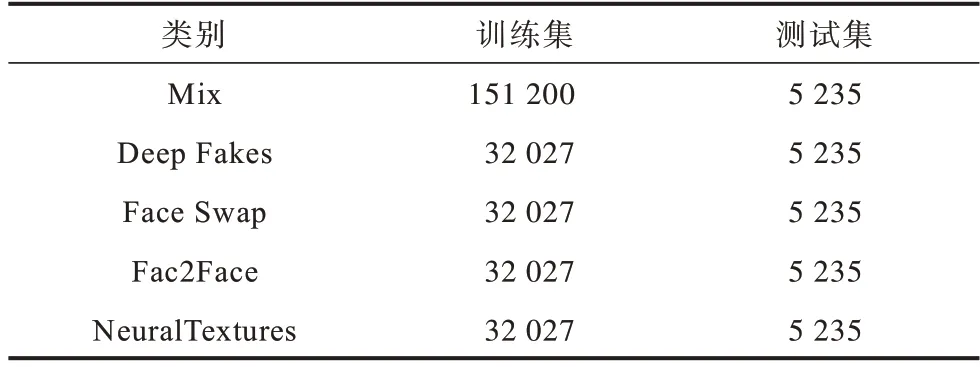
表1 FaceForensics++中每個(gè)類(lèi)別訓(xùn)練集和測(cè)試集圖片數(shù)Table 1 Uumber of images in the training set and test set of each category in FaceForensics++
3.2.2 評(píng)價(jià)指標(biāo)
為方便與其他算法對(duì)比,本文實(shí)驗(yàn)使用加權(quán)平均準(zhǔn)確率(Weighted Average Accuracy,WAA)作為評(píng)價(jià)指標(biāo)。在正負(fù)樣本不平衡的數(shù)據(jù)集中,該指標(biāo)可以更好地評(píng)估模型的分類(lèi)能力。
計(jì)算公式如式(4)和式(5)所示:

其中:TP(True Positive)表示將假樣例正確識(shí)別為假樣例的數(shù)量;FP(False Positive)表示將真樣例錯(cuò)誤識(shí)別為假樣例的數(shù)量;Pi表示類(lèi)別i的準(zhǔn)確率;C表示樣本的總數(shù);ci表示第i類(lèi)類(lèi)別的樣本總數(shù);n表示類(lèi)別總數(shù)。
3.2.3 實(shí)驗(yàn)配置
本文實(shí)驗(yàn)平臺(tái)為Ubuntu 16.04 操作系統(tǒng),使用了4 塊Nvidia TitanX 顯卡,所有代碼都在PyTorch 框架下實(shí)現(xiàn)。使用在ImageNet 上預(yù)訓(xùn)練的權(quán)重對(duì)Capsule-Forensics 和Xception-Attention-Capsules 的特征提取部分進(jìn)行初始化。
3.3 實(shí)驗(yàn)結(jié)果
3.3.1 Xception-Attention-Capsules 消融實(shí)驗(yàn)
本文首先評(píng)估對(duì)Capsule-Forensics 改進(jìn)的合理性。訓(xùn)練和測(cè)試使用HQ 版本,實(shí)驗(yàn)結(jié)果如表2所 示。表2 中的第2、3、4 行分別為Xception-Capsules、Xception-Capsules+A、Xception-Capsules+F的結(jié)果,第5行為Xception-Attention-Capsules 的結(jié)果。

表2 Xception-Attention-Capsules 消融實(shí)驗(yàn)的加權(quán)平均準(zhǔn)確率Table 2 Weighted average accuracy rate of Xception-Attention-Capsules ablation experiment %
1)Xception-Capsules:在Capsule-Forensics模型的基礎(chǔ)上僅替換特征提取部分為Xception 部分(如2.2 節(jié)所述)。
2)Xception-Capsules+A:在 Xception-Capsules的基礎(chǔ)上增加Attention-Capsules(如2.3 節(jié)所述)。
3)Xception-Capsules+F:在Xception-Capsules 的基礎(chǔ)上增加Dimension-Focal Loss(如2.4 節(jié)所述)。
如表2 所示,增加不同優(yōu)化機(jī)制的模型準(zhǔn)確率Xception-Attention-Capsules>Xception-Capsules+A>Xception-Capsules+F>Xception-Capsules。可以看出,在增加Attention-Capsules 和Dimension-Focal Loss優(yōu)化方法后模型的準(zhǔn)確率均有提升,其中Attention-Capsules 對(duì)模型準(zhǔn)確率的提升更加有效。在綜合兩種方法后,模型的準(zhǔn)確率在5 種類(lèi)型數(shù)據(jù)集上分別有1.94%、0.62%、1.87%、1.16%、1.37%的提升,證明本文提出的改進(jìn)方法是合理有效的。
3.3.2 Xception-Attention-Capsules與其他模型對(duì)比
為驗(yàn)證模型的改進(jìn)效果,分別在FaceForensics++不同壓縮率下進(jìn)行了對(duì)比實(shí)驗(yàn)。不同偽造類(lèi)別圖片級(jí)和視頻級(jí)實(shí)驗(yàn)結(jié)果如表3~表5所示,分別表示視頻RAW、HQ、LQ 版本的結(jié)果。
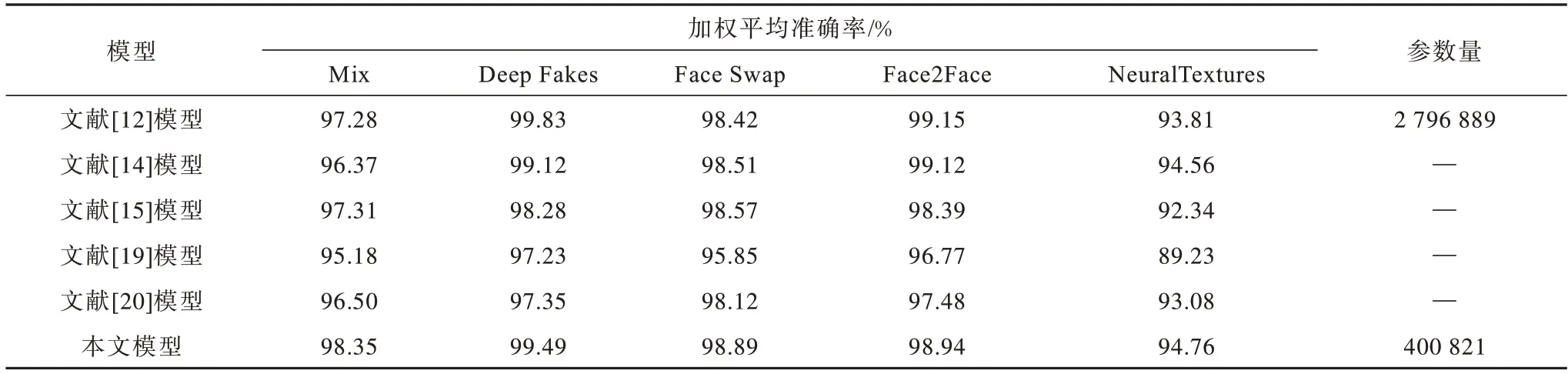
表3 FaceForensics++RAW 數(shù)據(jù)集上的加權(quán)平均準(zhǔn)確率Table 3 Weighted average accuracy rate on FaceForensics++RAW datasets
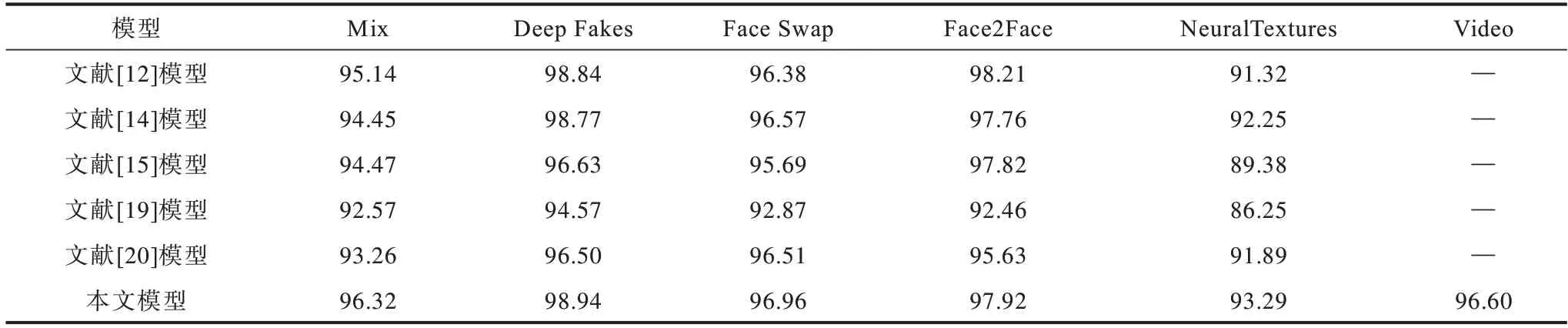
表4 FaceForensics++HQ 數(shù)據(jù)集上的加權(quán)平均準(zhǔn)確率Table 4 Weighted average accuracy rate on FaceForensics++HQ datasets %
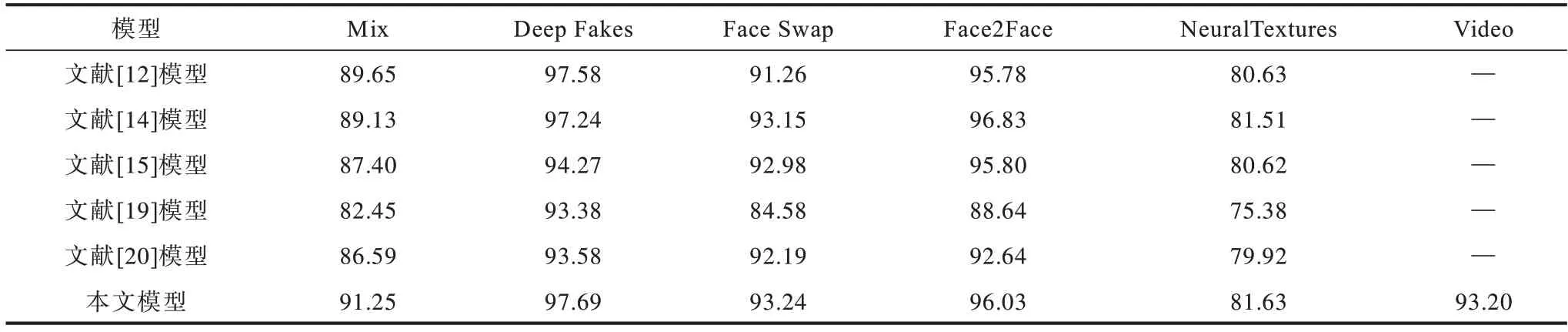
表5 FaceForensics++LQ 數(shù)據(jù)集上的加權(quán)平均準(zhǔn)確率Table 5 Weighted average accuracy rate on FaceForensics++LQ datasets %
從以上實(shí)驗(yàn)結(jié)果可以看出:
1)本文改進(jìn)的膠囊網(wǎng)絡(luò)Xception-Attention-Capsules 相較原模型參數(shù)量減少85.7%,在LQ 數(shù)據(jù)集上分別提高1.6%、0.11%、1.98%、0.25%、1.0%。HQ數(shù)據(jù)集除Face2Face 類(lèi)型下降0.29%,其余類(lèi)型分別提高1.18%、0.1%、0.58%、1.9%,表明本文改進(jìn)方法在多數(shù)情況下能得到更高的準(zhǔn)確率。
2)相較其他模型,本文模型在Mix、Face Swap、NeuralTextures 數(shù)據(jù)集的不同壓縮率下均具有最高的準(zhǔn)確率。
3)在壓縮率上升時(shí),各模型在NeuralTextures 和Face2Face 偽造方法的準(zhǔn)確率均有較大下降,說(shuō)明這兩種偽造類(lèi)型的低質(zhì)量圖片較難判別。
4)對(duì)比本文方法在視頻級(jí)和圖片級(jí)測(cè)試的結(jié)果,視頻級(jí)結(jié)果的檢測(cè)準(zhǔn)確率較圖片級(jí)有所上升,說(shuō)明本文模型在視頻級(jí)判別時(shí)通過(guò)綜合多幀的判別結(jié)果,可以提高判別的準(zhǔn)確率。
3.4 有效性可視化分析
3.4.1 決策區(qū)域可視化分析
為分析本文Attention-Capsules 中不同膠囊模塊在鑒別偽造人臉時(shí)是否關(guān)注人臉不同位置,本文使用Grad-CAM[19]對(duì)FaceForensics++數(shù)據(jù)集中幾種偽造方法生成的樣本進(jìn)行可視化分析。
對(duì)Face Forensics++的每種偽造方法,分別使用訓(xùn)練好的模型通過(guò)Grad-CAM 生成熱力圖[21],結(jié)果如圖5 所示,其中,第1 行是輸入圖片,其余行分別是3 個(gè)膠囊的激活圖,第1 列是原始圖片樣例,其余列分別對(duì)應(yīng)原始樣例的4 種偽造類(lèi)型。

圖5 不同膠囊在FaceForensics++中偽造方法的Grad-CAM 熱力圖Fig.5 Grad-CAM heat map of different capsules in FaceForensics++manipulated methods
根據(jù)圖5可以觀察到Origion樣例和Deepfake樣例主要的激活區(qū)域在眼睛和鼻子下方,這與圖像的偽造區(qū)域一致。Face2Face 樣例的激活區(qū)域主要為兩側(cè)下巴和鼻尖區(qū)域,分析原因?yàn)镕ace2Face 使用基于計(jì)算機(jī)圖形學(xué)的方法,對(duì)五官區(qū)域的形變支持較差,容易在鼻部區(qū)域留下較大的偽造痕跡,同時(shí)其下巴區(qū)域的激活符合原始偽造區(qū)域的位置。Face Swap 樣例的激活區(qū)域集中在嘴部和眼睛區(qū)域,同時(shí)面部的其他區(qū)域具有不同程度的激活,分析原因?yàn)樵摷夹g(shù)進(jìn)行的是全臉替換,因此其面部區(qū)域均得到了激活,同時(shí)其嘴部和眼睛區(qū)域符合原始偽造區(qū)域的位置。NeuralTextures 樣例的激活區(qū)域集中在臉的下半部分,因?yàn)樵摷夹g(shù)基于紋理渲染合成,主要用于偽造人物的說(shuō)話口型,因此其嘴部區(qū)域得到了激活。
總體而言,3 個(gè)膠囊均激活了臉部的關(guān)鍵區(qū)域,該區(qū)域由該類(lèi)偽造類(lèi)型的主要修改區(qū)域決定。但是對(duì)于臉部非關(guān)鍵部分,其激活區(qū)域的位置和范圍存在一定的差別,說(shuō)明3 個(gè)膠囊會(huì)關(guān)注到人臉的不同區(qū)域,這與本文使用不同大小的卷積核和步長(zhǎng)所預(yù)期的效果一致。由于3 個(gè)膠囊在識(shí)別出關(guān)鍵區(qū)域的同時(shí),不同的膠囊層之間學(xué)習(xí)到的特征可以相互補(bǔ)充進(jìn)行判別。相較與傳統(tǒng)CNN 通常只能激活一整塊熱區(qū),本文模型的激活區(qū)域更加準(zhǔn)確,這有助于最后的分類(lèi)結(jié)果,因此,可以一定程度上解釋本文的改進(jìn)方法在不同的偽造類(lèi)型上均表現(xiàn)出較好的分類(lèi)效果。
3.4.2 膠囊輸出可視化分析
為說(shuō)明本文模型是否將真?zhèn)稳四槝颖具M(jìn)行有效的區(qū)分,利用T-SNE[22](T-distributed Stochastic Neighborhood Embedding)將同一個(gè)樣本真假膠囊的共8 個(gè)輸出維度的數(shù)據(jù)降維至2 個(gè)維度,進(jìn)行可視化分析。
使用HQ版本的Mix測(cè)試集的測(cè)試數(shù)據(jù)進(jìn)行T-SNE可視化,其結(jié)果如圖6 所示。其中方框表示真樣本,圓形表示假樣本,可以看出,大部分的假樣本集中分布在左邊區(qū)域,真樣本集中分布在右邊區(qū)域,可見(jiàn)本文模型輸出的8 維向量值對(duì)真?zhèn)螛颖揪哂休^好的可區(qū)分性。

圖6 模型輸出的T-SNE 可視化結(jié)果Fig.6 T-SNE visualization results of model output
4 結(jié)束語(yǔ)
為提高膠囊網(wǎng)絡(luò)對(duì)視頻偽造人臉的檢測(cè)能力,本文以Capsule-Forensics 為基礎(chǔ),提出一種結(jié)合自注意力膠囊網(wǎng)絡(luò)的偽造人臉檢測(cè)方法。使用部分Xception 網(wǎng)絡(luò)替代VGG-19 作為特征提取部分,并給出基于自注意力機(jī)制的Attention-Capsules,使模型更加關(guān)注面部的五官區(qū)域,降低背景的影響,在此基礎(chǔ)上提出考慮不同維度輸出和度量學(xué)習(xí)的損失函數(shù)Dimension-Focal Loss。在FaceForensics++上的實(shí)驗(yàn)結(jié)果表明,本文方法對(duì)多數(shù)偽造方法生成的偽造人臉均具有較高的檢測(cè)準(zhǔn)確率。
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
中國(guó)科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
電測(cè)與儀表(2015年5期)2015-04-09 11:30:52
