融入雙注意力的高分辨率網絡人體姿態估計
2022-02-24 05:07:10羅夢詩葉星鑫
計算機工程 2022年2期
羅夢詩,徐 楊,2,葉星鑫
(1.貴州大學 大數據與信息工程學院,貴陽 550025;2.貴陽鋁鎂設計研究院有限公司,貴陽 550009)
0 概述
隨著計算機視覺技術的發展,人體姿態估計作為人機交互[1]不可或缺的組成部分,逐漸引起研究人員的關注。人體姿態估計任務在不同領域中扮演著不同的角色,被廣泛應用于智能監控、醫療康復與體育事業中的人體分析。在人體姿態估計中,通過一張圖片或者一段視頻對人體的2D 姿態進行估計是一個相當重要的基礎階段,例如人體跟蹤、動作認知、3D 姿態的研究或者人機交互應用都需要精確的人體2D 姿態估計作為支撐。因此,對2D 姿態估計的研究尤為重要。
人體姿態估計分為兩個步驟進行,即人體目標檢測和人體關鍵檢測[2]。目前主要通過深度學習方法[3-4]進行人體姿態估計,而用于人體關鍵點檢測的網絡主要為深度卷積神經網絡[5],深度卷積神經網絡的方法又可細分為關鍵點熱圖的估算[6-7]方法和關鍵點位置的回歸[8-9]方法兩種。通過對每張圖片學習后提取相應的特征信息,然后選擇熱值最高的位置作為關鍵點,從而可以學習得到人體的關鍵點。
2016 年NEWWLL[10]等提出堆 疊沙漏網 絡,按照從高到底的分辨率子網[11]串聯組成。因此,堆疊沙漏網絡是通過下采樣和上采樣的方式對不同分辨率從高到低,再從低到高進行操作。而此過程不能完全有效地利用空間特征信息,導致部分空間特征信息丟失,從而使輸出的高分辨率表征不夠完善。文獻[12]提出的級聯金字塔網絡(CPN)則彌補了堆疊沙漏網絡的這一缺點,在采用上采樣的操作時能夠融合低分辨率和高分辨率的特征圖信息。
2019 年SUN 等[13]提出了高 分辨率網 絡(HRNet),HRNet 摒棄了以往常規網絡所用的串聯方式,它采用并聯的方式將不同分辨率子網從高到底地進行并行連接,在實現多尺度融合時能有效利用特征信息。
盡管HRNet 相比其他高分辨率網絡可以得到更好的預測結果,但其在通道分配權重和空間域上分配權重依然存在難點。文獻[14]提出的ECA-Net 通過一維卷積實現,避免了降維,能夠有效捕獲跨通道交互的信息。相比文獻[15]的通道注意力,ECA-Net 只增加了少量的參數,可以更輕量、穩定、高效地建模通道關系,從而獲得明顯的性能增益。
2018 年WANG[16]等提出的 空間注意 力模型最大特點是擁有非局部均值去噪的思想。優點在于針對全局區域進行操作,對全局信息能夠得到有效的利用,防止特征信息的丟失或損失。
受以上研究的啟發,本文以高分辨率網絡作為實驗的基礎網絡架構,在其基礎上進行相應的優化,提出一種融入雙注意力的高分辨率網絡ENNet。通過融合通道注意力機制的殘差模塊(E-ecablock 模塊、E-ecaneck 模塊)和結合空間注意力的多分辨率融合模塊,增強網絡對多通道信息的提取及多尺度融合時對空間信息提取和融合能力。
1 高分辨率網絡
高分辨率網絡摒棄了以往網絡從高分辨率到低分辨率之間的串聯方式。高分辨率網絡結構總體分為4 個階段,第一階段由一個高分辨率子網構成,第二階段~第四階段則和第一階段有所不同,由多分辨率塊組成,多分辨率塊可分為多分辨率組卷積和多分辨率卷積兩種。圖1為多分辨率組卷積,圖2為多分辨率卷積。將每一階段的多分辨率子網以并行的方式進行連接,然后在每一子網上反復交換信息進行多尺度特征的重復融合,使網絡從始至終保持高分辨率的特征表示,最后通過上采樣的方式輸出高分辨率的特征表示。
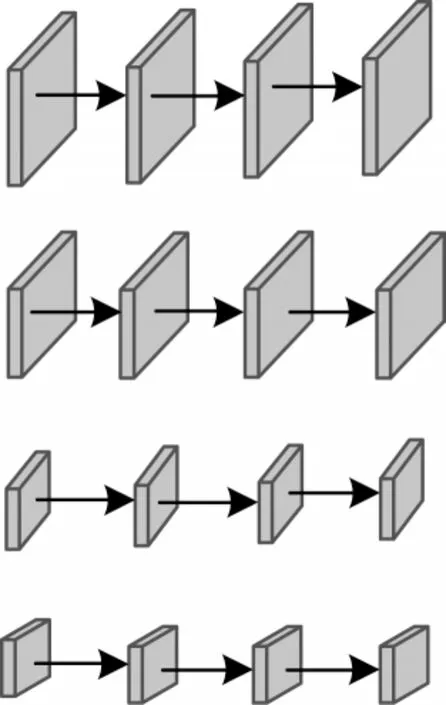
圖1 多分辨率組卷積Fig.1 Multiresolution group convolution
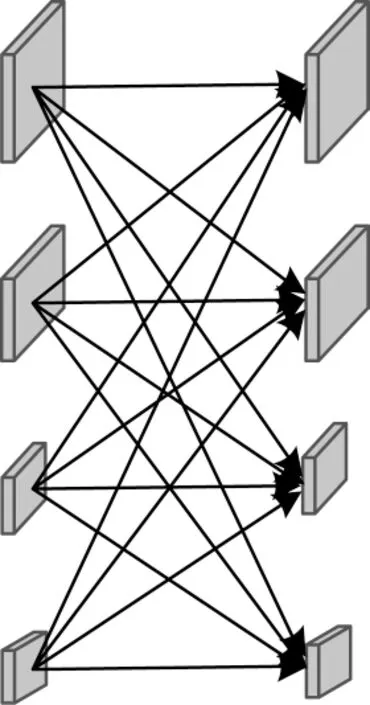
圖2 多分辨率卷積Fig.2 Multiresolution convolution
2 ENNet 方法
本文以HRNet 網絡作為基礎網絡進行改進得到融入雙注意力的高分辨率網絡ENNet,其整體的網絡結構如圖3 所示。融入雙注意力的高分辨率網絡ENNet 分為4 個階段,由4 個通過并行連接的從高到低的分辨率子網所構成。每一個子網從上往下,每一級分辨率以1/2 的倍數逐步降低,通道數則以2 倍的速度升高。第一階段由一個高分辨率子網構成,包含了4 個線性變換的E-ecaneck 殘差模塊;第二階段~第四階段均由改進的E-ecablock 模塊和空間注意力機制的融合模塊(Non-localblock)組成,其目標是對特征進行更廣泛且更深層提取與融合。
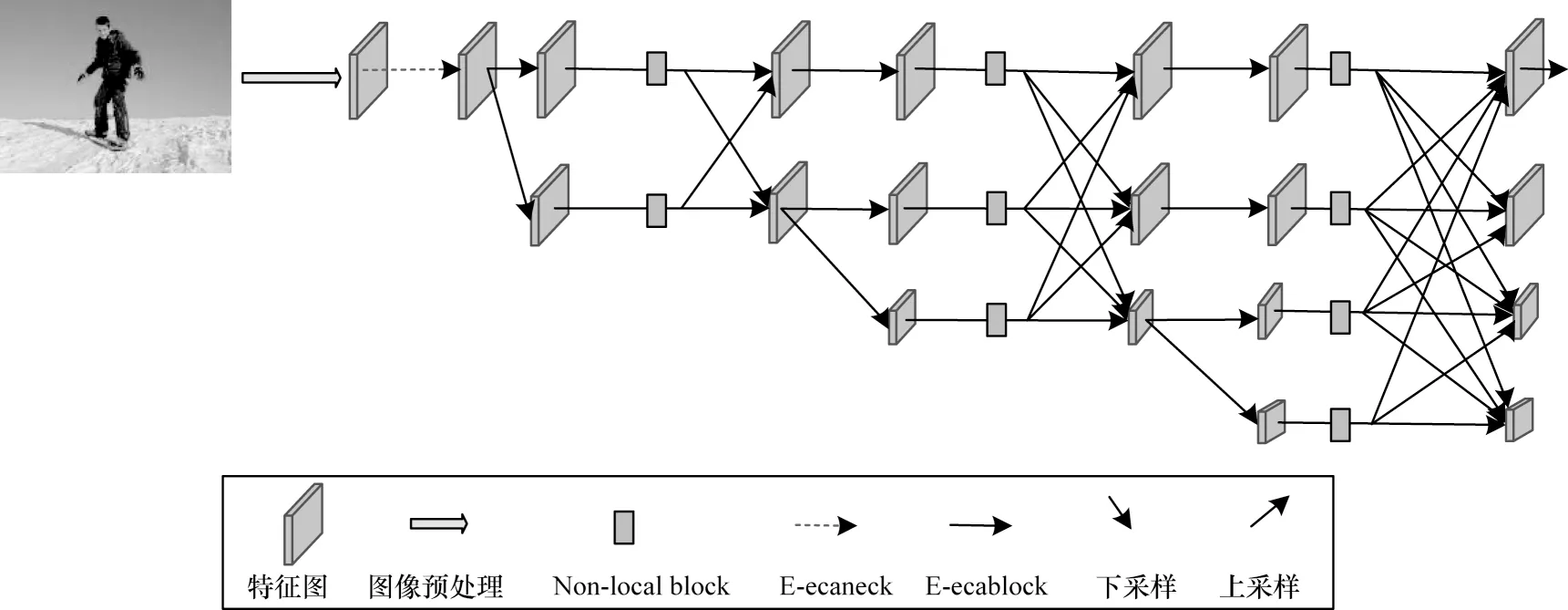
圖3 ENNet 網絡結構Fig.3 ENNet network structure
本文首先通過融入通道注意力構造出E-ecaneck模塊和E-ecablock 模塊作為基礎模塊,最大程度地提取更多更有用的通道信息。然后在融入通道注意力機制的基礎上融入空間注意力機制中的Non-localblock模塊,實現空間信息的有效提取與融合。最后通過上采樣操作將經過重復融合的信息表征以高分辨率的形式輸出,從而實現人體關鍵點檢測任務和人體姿態估計。
2.1 通道注意力模塊的融入
ECA 模塊是一種新的捕捉局部跨通道信息交互的方法,它在不降低通道維數的情況下進行跨通道信息交互,旨在保證計算性能和模型復雜度。ECA模塊可以通過卷積核大小為K的一維卷積來實現通道之間的信息交互,如圖4 所示。
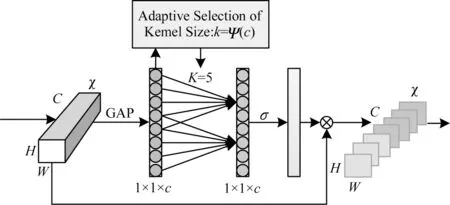
圖4 ECA 結構Fig.4 ECA structure
設一個卷積塊的輸出為χ∈RW×H×C,其中,W、H和C分別表示寬、高和通道數,GAP 表示全局平均池化。ECA 模塊通過卷積核大小為k的一維卷積來實現通道之間的信息交互,如式(1)所示:

其中:σ是一個sigmoid 函數;C1D 代表一維卷積;k代表k個參數信息;y為輸出信號。這種捕捉跨通道信息交互的方法保證了性能結果和模型效率。
本文參考了ResNet 網絡模塊中的bottleneck 模塊與basicblock 模塊的設計方法,將ECABlock 模塊融入到高分辨率網絡(HRNet)的瓶頸模塊(bottleneck)和殘差模塊(basicblock)中,得到改進的E-ecablock 模塊和E-ecaneck 模塊,并將其代替原網絡的bottleneck 模塊與basicblock 模塊,從而實現不降低通道維數來進行跨通道信息交互。
本文提出的E-ecablock 模塊包含2 個3×3 卷積核尺寸大小的ECABlock 模塊和1 個殘差連接,如圖5 所示。E-ecaneck 模塊包含2 個1×1 卷積核尺寸大小的ECABlock 模塊、1 個3×3 卷積核尺寸大小的ECABlock 模塊以及1 個殘差連接,如圖6 所示。
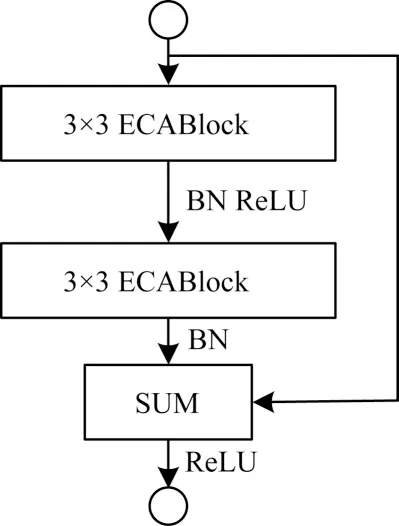
圖5 E-ecablock 模塊Fig.5 E-ecablock module
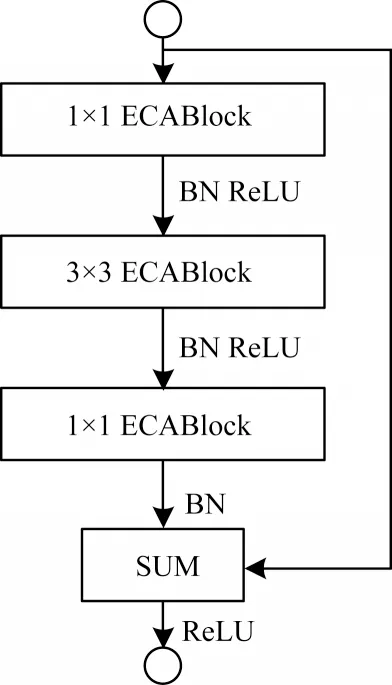
圖6 E-ecaneck 模塊Fig.6 E-ecaneck module
受文獻[17]啟發,本文在卷積操作前加入通道注意力模塊可以使特征提取得到較好的效果,因此,本文在E-ecablock 模塊中的2 個3×3 的卷積操作前加入一個ECABlock 模塊,每一次進行卷積操作前先通過對輸入特征圖的不同通道進行注意力權重賦值得到有意義的特征,然后進行卷積操作后輸出,最后將卷積操作后輸出的結果與初始輸入的特征信息通過殘差連接進行求和再輸出,從而獲得更優的通道特征提取效果。
為了使通道信息的提取效率增高,采用相同的方法,在E-ecaneck 模塊中的每一層卷積操作前添加ECABlock 模塊。通過ECABlock 模塊對特征圖通道維度進行降低和提高,并多次卷積操作進行特征提取,使網絡得到更多有用的特征信息。
2.2 空間注意力融合模塊的融入
Non-localblock 模塊是空間域注意力模型的核心模塊,它作為非局部的空間注意力方法,不僅局限于局部范圍,而是針對全局區域進行操作,計算公式如式(2)所示:

其中:i和j是某個空間位置;C(x)是歸一化因子,x和y分別為尺寸大小相同的輸入和輸出信號;xi為向量,f(xi,xj)是計算xi與所有xj之間的相關性函數;g(xj)計算輸入信號在位置j處的特征值。
通過式(2)可得到式(3):

其中:z為最后的輸出;Wz是由1×1 的卷積操作實現的線性轉換矩陣。
本文采用空間注意力模塊(Non-localblock)模塊對第二階段~第四階段的融合模塊進行改進,在融入通道注意力的基礎上將其加在各個分辨率表征融合前,如圖7 所示。Non-localblock 模塊是在全局區域進行操作,可以擴大感受野。因此,它能有效提取更多有利信息進入不同分辨率表征的信息交互環節,即先提取盡可能多的有用信息,再進行多尺度融合,從而使多尺度特征融合時的效果得到較好的改善。
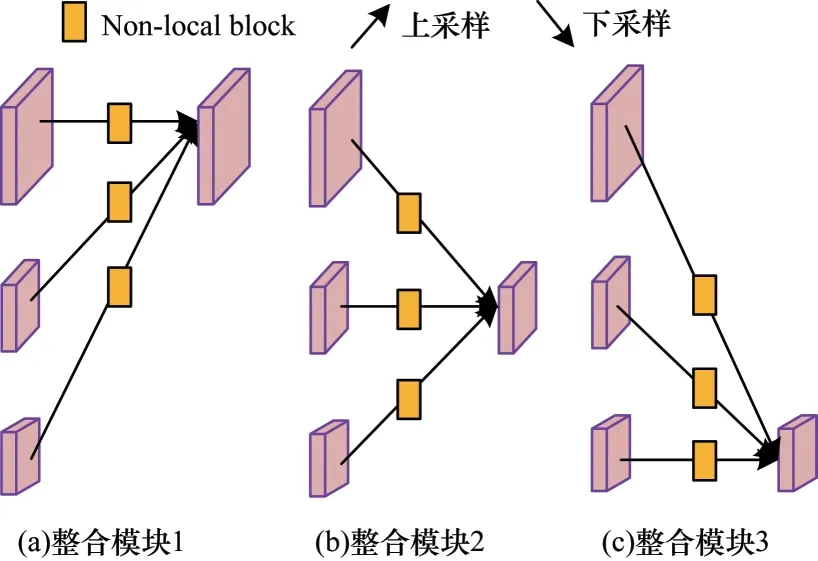
圖7 融入空間注意力的融合模塊Fig.7 Fusion module with spatial attention
3 實驗結果與分析
3.1 COCO 數據集
在COCO2017 數據集上對本文方法進行評估。數據集包含了200 000 張圖片,其中含有17 個關鍵點的人體樣本為250 000 個。在57K 張圖像的訓練集上進行訓練,在5K 張圖像的驗證集上進行驗證,在20K 張圖像的測試集上進行測試。在COCO 據集中人體姿態的17 個關鍵點分別是鼻子、右眼、左眼、右耳、左耳、右肩、右肘、右手腕、左肩、左肘、左手腕、右臀、右膝蓋、右腳踝、左臀、左膝蓋、左腳踝。
3.2 圖像預處理
由于MS COCO2017 數據集中收錄的原始圖片大小不一,需對圖像進行預處理再進行訓練。本文需對兩種尺寸大小的圖像訓練進行對比,因此,預處理過程分為如下2 個部分:
1)從數據集圖像中以主要人體髖部為中心進行裁剪,圖像的尺寸大小裁剪為256×192,并調整為固定比例,高寬的比例為4∶3,便于網絡訓練。
2)使用隨機旋轉(-45°,45°)和隨機縮放規模(0.65,1.35)的數據增強方式來對數據進行處理。從數據集圖像中以主要人體髖部為中心進行裁剪,按照高寬為4∶3 的比例,將圖像的尺寸大小裁剪為384×288,從而達到網絡訓練所需的輸入效果。
3.3 評估標準
本文在COCO2017 數據集上進行實驗驗證,評估方法有以下2 種:
1)采用MS COCO 官方給定的關鍵點相似性(OKS)進行評估。
2)采用正確關鍵點百分比(Percentage of Correct Keypoints,PCK)[18]作為實驗評估指標。
3.4 實驗環境與實驗設置
本文實驗使用的軟件平臺是Python3.6,服務器的系統是Ubuntu18.04 版本,顯卡是NVIDIA GeForce GTX 1080Ti,深度學習框架是PyTorch1.6.0。
在本文實驗中,選用Adam 優化器對模型進行優化。將訓練周期設置為200,訓練批量大小設置為20,學習率為0.001。
3.5 實驗過程
本文方法使用深度卷積神經網絡的方法中的關鍵點熱圖的估葉算法,用多分辨率的熱圖(Heatmap)圖像去學習關節點的坐標,此時需要估算圖像中每個像素對應的概率的值,將與關節點最接近的像素點處的概率值記為1,與關節點距離最遠的像素點處的概率記為0,若所檢測到的像素點處的概率越接近1,則越接近目標點。對圖像進行訓練后將所得到的熱圖結果映射到原圖像,經過整合,得到人體對應的各個關節點的坐標位置,從而實現關鍵點的檢測來完成人體姿態估計的任務。
Heatmap 示意圖如圖8 所示。

圖8 Heatmap 圖像示意圖Fig.8 Schematic diagram of Heatmap image
3.6 實驗驗證與分析
本文通過對原網絡進行改進和優化后,在COCO VAL 2017 數據集上進行實驗。將輸入尺寸為256×192時結果與其他方法在同一數據集上的結果進行比較,如表1 所示。從表1 結果可以看出,本文方法ENNet相比于CPN、CPN+OHKM、SimpleBaseline-152[19]、SimpleBaseline-101[19]、SimpleBaseline-50[19],在mAP 上的估計精確度都得到了較好的提升。相比于HRNet-32,AP50提高了4.1%,AP75提高了3%,APL提高了3.4%,APM提高了3.1%,mAP 整體提高了3.4%。
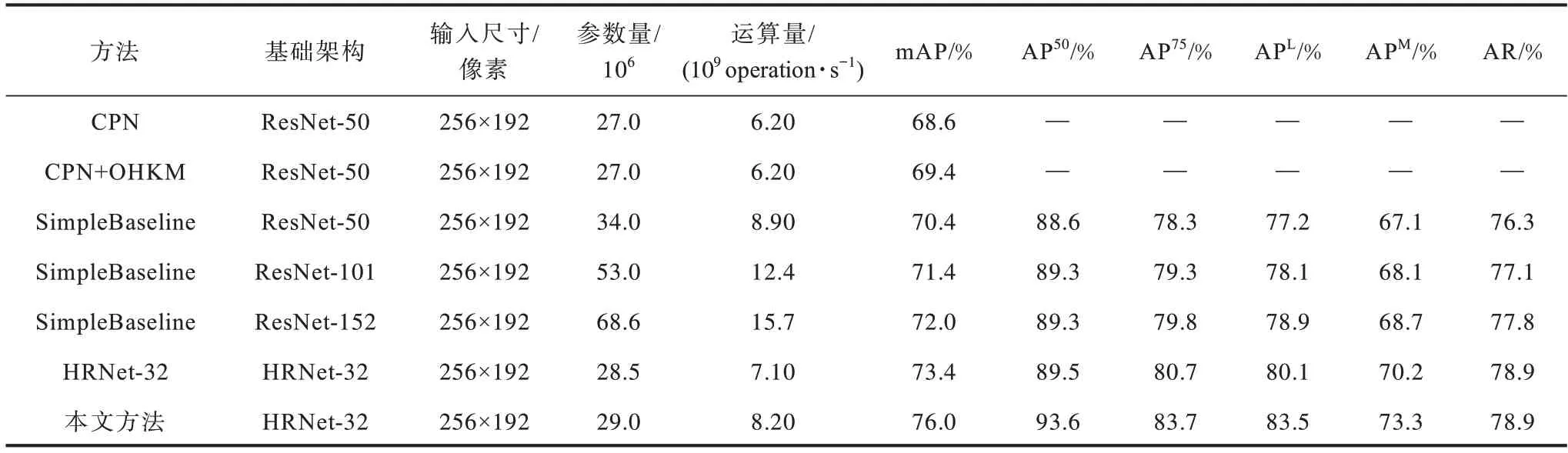
表1 不同方法在COCO VAL 2017 數據集上的對比結果Table 1 Comparison results of different methods on COCO VAL 2017 dataset
通過實驗結果可以看出,本文方法在HRNet-32上引入雙注意力機制,不僅在原網絡的基礎上提高了關鍵點的估計精確度,更進一步地提升了網絡在高精度要求下的關鍵點估計精確度。
表2 是本文方法在COCOtest-dev2017 數據集上與其他方法測試結果的對比實驗。實驗結果表明,與文獻[20-21]、CPN、CPN+OHKM、SimpleBaseling、HRNet-32 等方法相比,在輸入尺寸相同的情況下,本文方法在降低網絡復雜度的同時,mAP、APL和APM的估計精確度都具有較好的效果。
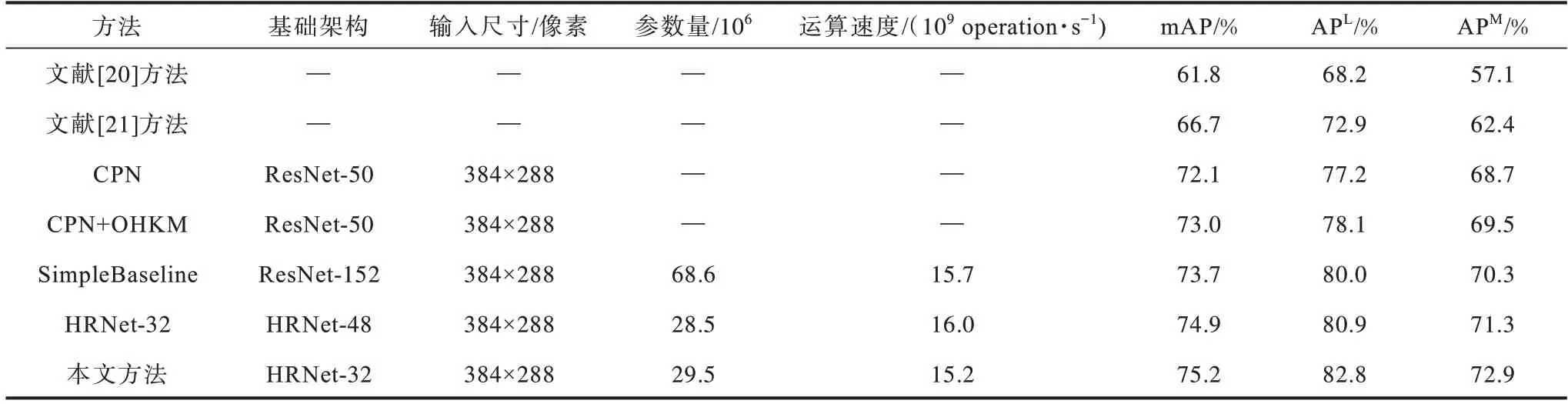
表2 不同方法在COCOtest-dev2017 數據集上的對比結果Table 2 Comparison results of different methods on COCOtest-dev2017 dataset
表3 是本文方法在COCO2017 驗證集上圖像輸入尺寸均為384×288 時與不同網絡模型對關鍵點估計精確度的對比。通過計算關鍵點正確估計的比例PCK 來對比不同網絡模型對人體關鍵點的估計精確度。其中頭部、肩部、肘部、腕部、臀部、膝部和腳踝分別代表頭部5 個關節點平均值、肩部兩關節點平均值、肘部兩關節點平均值、腕部兩關節點平均值、臀部兩關節點平均值、膝蓋兩關節點平均值和腳踝兩關節點平均值,平均代表所有關節點平均值。實驗結果表明,本文方法具有較高的平均估計精確度,在單個關節點的估計精確度上都有一定程度的提升。
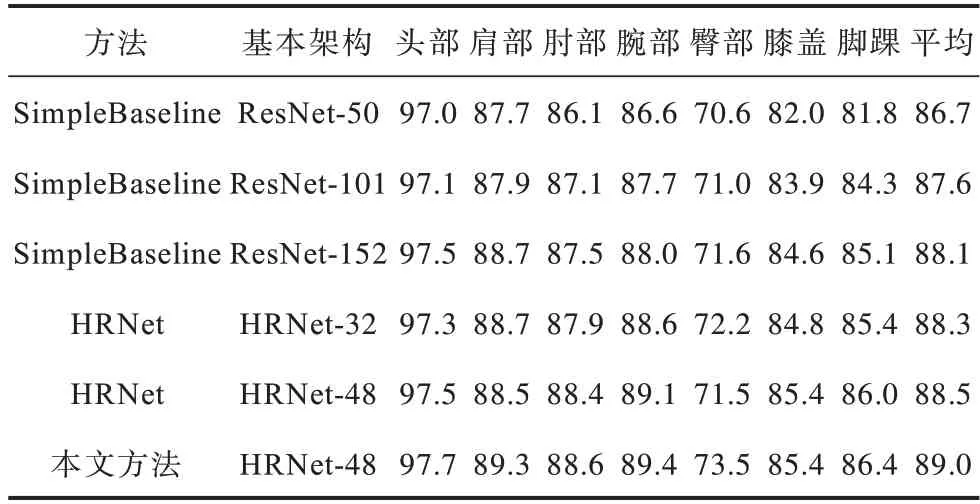
表3 不同網絡對不同關鍵點檢測的PCK 值比較Table 3 Comparison of PCK values detected by different networks for different key points %
3.7 模塊分解實驗
本文實驗通過在通道注意力的基礎上引入空間注意力來對網絡模型(基礎網絡架構為HRNet-32時)進行改進,最終使平均估計精確度提高3.4%。在COCO VAL2017 數據集上對本文方法進行模塊分解實驗,其結果如表4 所示。

表4 融入雙注意力方法的模塊分解實驗結果比較Table 4 Experimental results comparison of module decomposition with dual attention method
通過引入通道注意力構造E-ecaneck 模塊和E-ecablock 模塊作為基礎模塊,提取特征圖的不同通道信息,網絡的平均估計精確度相比較于高分辨率網絡(HRNet)提升1.2%。單獨將空間注意力引入到網絡的多分辨率融合階段,網絡的平均估計精確度相比較于高分辨率網絡(HRNet)提升1.6%,相比較于僅含有通道注意力的網絡平均估計精確度提升了0.4%。
在引入通道注意力的基礎上引入空間注意力的網絡,相比較于原HRNet,平均估計精確度提升3.4%,在僅含有通道注意力融合方法基礎上獲得1.4%的性能提升,在僅含有空間注意力融合方法基礎上獲得1%的性能提升。
3.8 可視化實驗分析
圖9 為本文方法對COCO2017 數據集測試的部分結果展示。從圖9(a)~圖9(d)可以看出,在相同光照情況下,圖像中人體無遮擋時可準確地檢測出各個部位的關鍵點,只有當圖像中人體存在嚴重遮擋時檢測出的關鍵點出現稍微的偏差。圖9(a)和圖9(c)表明,當圖像中人體無遮擋時,在不同光照情況下都可以檢測出準確的關鍵點位置。圖9(e)和圖9(f)表明,在針對不同分辨率的圖像時,網絡仍然可以得到準確的結果。

圖9 本文方法在COCO2017 數據集上的測試結果Fig.9 Test results of this method on COCO2017 dataset
以上實驗結果表明,在不同光照條件、人體是否遮擋、不同圖像分辨率的情況下,本文方法有一定的魯棒性,能準確地檢測出人體各個關鍵點,從而估計人體的姿態。
4 結束語
本文提出一種融入雙注意力的高分辨率人體姿態估計網絡ENNet。以高分辨率網絡(HRNet)為基礎網絡架構進行優化,設計2 種注意力模塊E-eacblock 和E-ecaneck 作為基礎模塊,在多分辨力融合階段融入空間注意力,從而使網絡在進行特征提取時可以增強網絡對多通道信息的提取,改善多分辨率階段特性信息的融合能力。在公開數據集MS COCO2017 上的測試結果表明,相比于HRNet,本文方法的mAP 綜合提高了3.4%,有效改善了網絡多分辨率表征的信息融合能力。本文網絡模型復雜度還有待提高,如何在保持估計精確度較高的前提下降低模型參數量和復雜度,將是下一步的研究方向。
猜你喜歡
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年19期)2022-01-12 06:16:36
今日農業(2021年8期)2021-11-28 05:07:50
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國衛生(2014年2期)2014-11-12 13:00:16
