基于有向圖模型的旅游領(lǐng)域命名實(shí)體識別
2022-02-24 05:07:08崔麗平古麗拉阿東別克王智悅
計(jì)算機(jī)工程 2022年2期
崔麗平,古麗拉·阿東別克,王智悅
(1.新疆大學(xué) 信息科學(xué)與工程學(xué)院,烏魯木齊 830046;2.新疆多語種信息技術(shù)重點(diǎn)實(shí)驗(yàn)室,烏魯木齊 830046;3.國家語言資源監(jiān)測與研究少數(shù)民族語言中心哈薩克和柯爾克孜語文基地,烏魯木齊 830046)
0 概述
隨著信息化建設(shè)的加快,旅游逐漸成為人們休閑放松的重要方式。在旅游過程中,游客利用智能化的應(yīng)用軟件解決出行問題,例如景點(diǎn)的智能線路推薦、景區(qū)的智能問答系統(tǒng)實(shí)現(xiàn)等,旅游領(lǐng)域的命名實(shí)體識別(Named Entity Recognition,NER)作為智能化服務(wù),逐漸引起研究人員的關(guān)注。
NER 是自然語言處理的一項(xiàng)研究任務(wù),是信息檢索、問答系統(tǒng)、機(jī)器翻譯等諸多任務(wù)的基礎(chǔ)。以往的NER 任務(wù)大多針對通用領(lǐng)域,近年來,NER 被應(yīng)用在某些特定領(lǐng)域上,文獻(xiàn)[1]在生物醫(yī)學(xué)領(lǐng)域中利用支持向量機(jī)(Support Vector Machine,SVM)進(jìn)行蛋白質(zhì)、基因、核糖核酸等實(shí)體識別;文獻(xiàn)[2]在社交媒體領(lǐng)域中對微博中的實(shí)體進(jìn)行研究;文獻(xiàn)[3]對電子病歷中的實(shí)體進(jìn)行研究。此外,研究人員對一些實(shí)體(如化學(xué)實(shí)體[4]、古籍文本中的人名[5]等)研究較少。
旅游領(lǐng)域的NER 研究相對較少。文獻(xiàn)[6]提出基于隱馬爾科夫模型(Hidden Markov Model,HMM)的旅游景點(diǎn)識別方法,該方法首次在旅游領(lǐng)域上進(jìn)行NER 任務(wù),但未充分考慮到上下文信息,解決一詞多義的問題表現(xiàn)欠佳。因?yàn)楹芏鄬?shí)體在不同的語境中會代表不同的意思,例如“玉門關(guān)”在其他的文本中指的是地名,在旅游文本中指的是旅游景點(diǎn)玉門關(guān)。文獻(xiàn)[7]提出使用層疊條件隨機(jī)場(Conditional Random Field,CRF)識別景點(diǎn)名的方法,該方法過于依賴人工特征的建立,而且規(guī)則制定要耗費(fèi)大量的人力,以致于不能廣泛使用。文獻(xiàn)[8]提出一種基于CNN-BiLSTM-CRF 的網(wǎng)絡(luò)模型,避免了人工特征的構(gòu)建,但該方法是基于字進(jìn)行識別,未能充分利用詞典信息。對于特定領(lǐng)域的NER 任務(wù),詞典是十分重要的外部資源,尤其是旅游文本中存在許多較長的景點(diǎn)名,例如阿爾金山自然保護(hù)區(qū)、巴音布魯克天鵝湖等,可以利用詞典獲取這類詞匯信息進(jìn)而提高NER 的準(zhǔn)確率。
本文提出一種有向圖神經(jīng)網(wǎng)絡(luò)模型用于旅游領(lǐng)域中的命名實(shí)體識別。將預(yù)訓(xùn)練詞向量通過具有多個卷積核的卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)提取字特征,基于詞典構(gòu)建每個句子的有向圖,生成對應(yīng)的鄰接矩陣,通過邊的連接融合詞特征與字特征,將詞向量和鄰接矩陣輸入圖神經(jīng)網(wǎng)絡(luò)進(jìn)行全局語義信息的提取,并引入CRF 得到最優(yōu)序列。
1 相關(guān)工作
1.1 命名實(shí)體識別
NER 主要是基于規(guī)則和詞典、基于統(tǒng)計(jì)機(jī)器學(xué)習(xí)、基于深度學(xué)習(xí)的方法。基于規(guī)則和詞典的方法需要考慮數(shù)據(jù)的結(jié)構(gòu)和特點(diǎn),在特定的語料上取得較高的識別效果,但是依賴于大量規(guī)則的制定,手工編寫規(guī)則又耗費(fèi)時間和精力。基于統(tǒng)計(jì)機(jī)器學(xué)習(xí)的方法具有較好的移植性,對未登錄詞也具有較高的識別效果。常用的機(jī) 器學(xué)習(xí)模型有SVM[9]、HMM[10]、條件隨機(jī)場[11]、最大熵(Maximum Entropy,ME)[12]等,這些方法都被成功地用于進(jìn)行命名實(shí)體的序列化標(biāo)注,然而都需要從文本中選擇對該項(xiàng)任務(wù)有影響的各種特征,并將這些特征加入到詞向量中,所以對語料庫的依賴性很高。
隨著深度學(xué)習(xí)在圖像和語音領(lǐng)域的廣泛應(yīng)用,深度學(xué)習(xí)的眾多方法也被應(yīng)用在自然語言處理任務(wù)中。文獻(xiàn)[13]提出基于神經(jīng)網(wǎng)絡(luò)的NER 方法,該方法利用具有固定大小的窗口在字符序列上滑動以提取特征。由于窗口的限制,該方法不能考慮到長距離字符之間的有效信息。循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)的優(yōu)勢在于它通過記憶單元存儲序列信息,但是在實(shí)際的應(yīng)用中,RNN 的記憶功能會隨著距離的變長而衰減,從而喪失學(xué)習(xí)遠(yuǎn)距離信息的能力。文獻(xiàn)[14]基于RNN 提出長短時記憶(Long Short Term Memory,LSTM)神經(jīng)網(wǎng)絡(luò),該方法利用門結(jié)構(gòu)解決梯度消失的問題,然而3 個門單元增加了計(jì)算量。門循環(huán)單元(Gated Recurrent Unit,GRU)[15]只用了2 個門保存和更新信息,能夠減少訓(xùn)練參數(shù),縮短訓(xùn)練的時間。由于單向的RNN 不能滿足NER 任務(wù)的需求,文獻(xiàn)[16]提出雙向LSTM模型(BiLSTM)用于序列標(biāo)注任務(wù),通過不同方向充分學(xué)習(xí)上下文特征。文獻(xiàn)[17]構(gòu)建BiLSTM 與CRF結(jié)合的模型,用CRF 規(guī)范實(shí)體標(biāo)簽的順序。因此,BiLSTM+CRF結(jié)構(gòu)成為NER 任務(wù)中的主流模型[18-19]。
文獻(xiàn)[20]提出一種基于注意力機(jī)制的機(jī)器翻譯模型,摒棄之前傳統(tǒng)的Encoder-Decoder 模型結(jié)合RNN 或CNN 的固有模式,使用完全基于注意力機(jī)制的方式。由于Transformer 有強(qiáng)大的并行計(jì)算能力和長距離特征捕獲能力,因此在機(jī)器翻譯、預(yù)訓(xùn)練語言模型等語言理解任務(wù)中表現(xiàn)出色,逐漸取代RNN 結(jié)構(gòu)成為提取特征的主流模型。在NER 任務(wù)上,基于自注意力的Transformer 編碼器相較于LSTM 的效果較差,雖然自注意力可以進(jìn)一步獲得字詞之間的關(guān)系,卻無法捕捉字詞間的順序關(guān)系,并且經(jīng)過自注意力計(jì)算后相對位置信息的特性會丟失。位置信息的丟失和方向信息的缺失影響NER 的效果[21]。
在英文的NER 任務(wù)上主要使用基于詞的方法,但是在中文NER 任務(wù)中,由于中文存在嚴(yán)重的邊界模糊現(xiàn)象,基于詞的方法會產(chǎn)生歧義,進(jìn)而影響NER結(jié)果。基于字的方法比基于詞的方法更適合中文NER 任務(wù)[22-23],然而基于字的方法存在無法提取詞匯信息的缺陷,這些潛在詞的信息對NER 任務(wù)十分重要。因此,構(gòu)造字詞結(jié)合訓(xùn)練的方法[24-26]成為研究熱點(diǎn)。
文獻(xiàn)[27]提出Lattice LSTM 結(jié)構(gòu),使用詞典動態(tài)將字詞信息送入LSTM 結(jié)構(gòu)中進(jìn)行計(jì)算,在多個數(shù)據(jù)集上取得了最好成績。RNN 的鏈?zhǔn)浇Y(jié)構(gòu)和缺乏全局語義的特點(diǎn)決定了基于RNN 的模型容易產(chǎn)生歧義,Lattice LSTM 結(jié)構(gòu)如圖1 所示。“市長”和“長江”兩個詞共同包含“長”字,RNN 會嚴(yán)格按照字和詞匯出現(xiàn)的順序進(jìn)行信息傳遞,因此,“長”會優(yōu)先被劃分到左邊的“市長”一詞中[28],這顯然是錯誤的。針對這個問題,本文使用圖神經(jīng)網(wǎng)絡(luò)進(jìn)行信息傳遞,在每次計(jì)算時,每個節(jié)點(diǎn)都會同時獲得與其相連節(jié)點(diǎn)的信息,以削弱字符語序和匹配詞序?qū)ψR別的影響。
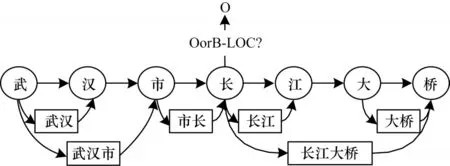
圖1 Lattice LSTM 結(jié)構(gòu)Fig.1 Structure of Lattice LSTM
1.2 圖神經(jīng)網(wǎng)絡(luò)
圖是由一系列對象(節(jié)點(diǎn))和關(guān)系類型(邊)組成的結(jié)構(gòu)化數(shù)據(jù)。文獻(xiàn)[29]提出圖神經(jīng)網(wǎng)絡(luò)的概念。文獻(xiàn)[30]提出基于譜圖論的一種圖卷積的變體。圖神經(jīng)網(wǎng)絡(luò) 包括圖注 意力網(wǎng)絡(luò)[31](Graph Attention Network,GAT)、圖生成網(wǎng)絡(luò)[32]等。圖神經(jīng)網(wǎng)絡(luò)在自然語言處理領(lǐng)域的應(yīng)用逐漸成為研究熱點(diǎn),文獻(xiàn)[33]提出將圖卷積神經(jīng)網(wǎng)絡(luò)(GCN)用于文本分類,文獻(xiàn)[34]利用依存句法分析構(gòu)建圖神經(jīng)網(wǎng)絡(luò)并用于關(guān)系抽取。
2 L-CGNN 模型
L-CGNN 模型的整體結(jié)構(gòu)分為特征表示層、GGNN 層、CRF 層3 個部分。特征表示層的主要任務(wù)有:1)獲取預(yù)訓(xùn)練詞向量并使用具有不同卷積核的CNN 提取局部特征,充分獲得每個字的局部特征;2)通過詞典匹配句子中的詞匯信息,構(gòu)建句子的有向圖結(jié)構(gòu)得到相應(yīng)的鄰接矩陣用于表示字與詞匯的關(guān)系。GGNN 層接收特征表示層傳入的詞向量矩陣和鄰接矩陣,動態(tài)融合字詞信息獲得全局的語義表示。通過CRF 層進(jìn)行解碼獲得最優(yōu)標(biāo)簽序列。L-CGNN 模型結(jié)構(gòu)如圖2 所示。
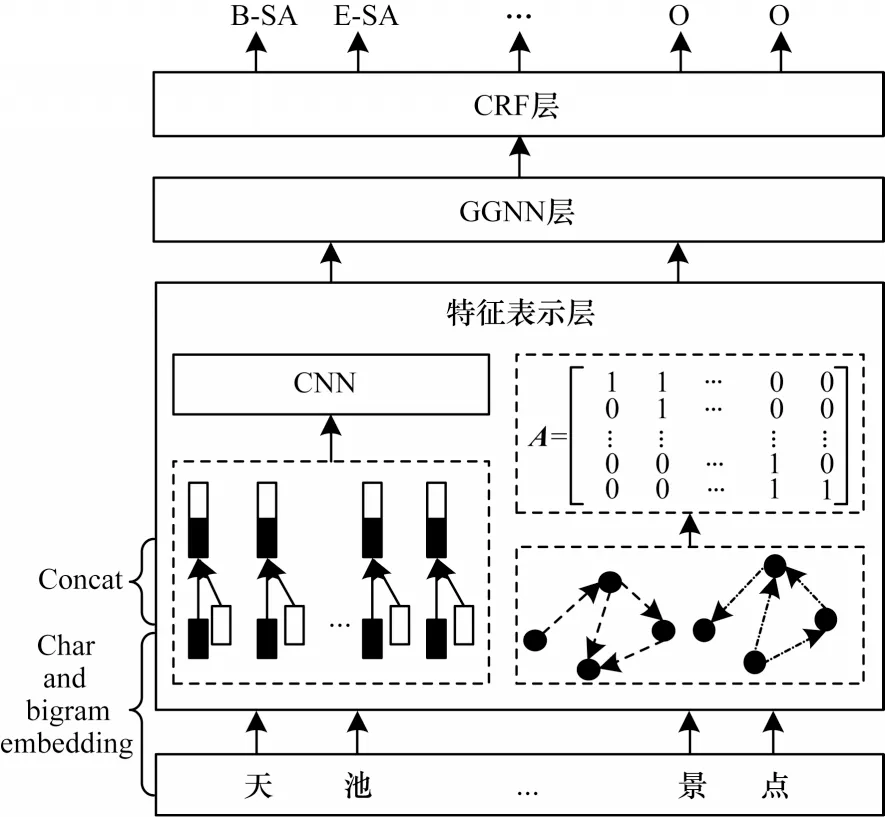
圖2 L-CGNN 模型結(jié)構(gòu)Fig.2 Structure of L-CGNN model
2.1 特征表示層
特征表示層首先對文本進(jìn)行詞向量表示,然后構(gòu)建文本的圖結(jié)構(gòu)。
1)詞向量
神經(jīng)網(wǎng)絡(luò)的輸入是向量矩陣,因此先將字轉(zhuǎn)換成向量矩陣形式。詞向量給定包含n個字的句子S={c1,c2,…,cn},其中ci是第i個字,每個字通過查詢預(yù)訓(xùn)練字向量表,轉(zhuǎn)換為基于字的詞向量,如式(1)所示:

其中:Ec為預(yù)訓(xùn)練詞向量表。通過引入bigram 特征后得到的詞向量是由基于字的向量、前向bigram 詞向量、后向bigram 詞向量3 個部分組成,以提高NER效果[35-36]。加入bigram 的詞向量如式(2)所示:

其中:Eb為預(yù)先訓(xùn)練的bigram 向量矩陣。因?yàn)槁糜挝谋镜膶?shí)體名通常較長,并且嵌套現(xiàn)象嚴(yán)重,字向量和bigram 向量并不能很好表示局部信息。例如天山大峽谷是新疆著名景點(diǎn),對于山字,除了字向量特征外,只能獲取到天山和山天的信息,導(dǎo)致天山可能被當(dāng)作單獨(dú)的一個景點(diǎn)名被識別,然而這里的天山大峽谷是一個完整的景點(diǎn)名,需要更多的信息輔助識別。
卷積神經(jīng)網(wǎng)絡(luò)逐漸被用于自然語言任務(wù)中提取局部特征。CNN 結(jié)構(gòu)包含卷積層、激活層、池化層,由于池化層會削弱位置特征的表達(dá),而位置特征對于序列標(biāo)注任務(wù)十分重要,所以本文沒有使用池化操作,而是使用3 個不同大小的卷積核提取特征,對卷積核進(jìn)行填充操作以獲得相同維度的表示。3 個卷積核的大小為k×w,其中k依次取1、3、5,對應(yīng)w依次取d、d+2、d+4,d為詞向量xi的維度,局部特征提取流程如圖3 所示。
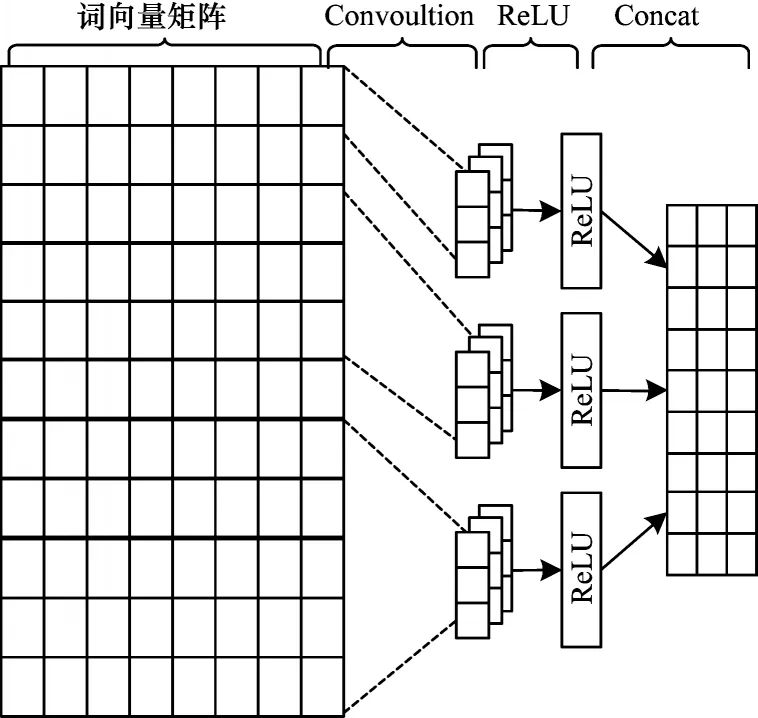
圖3 局部特征提取流程Fig.3 Extraction procedure of local feature
局部特征的提取如式(3)、式(4)所示:
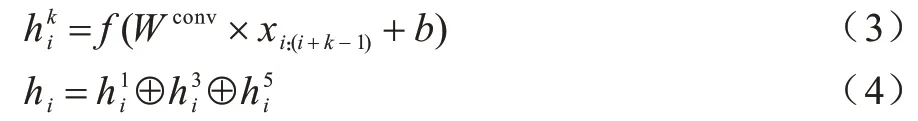
其中:Wconv∈?k×w;f為線性修正單元(ReLU);b為偏置項(xiàng),將不同卷積核提取的局部特征拼接,得到最終的特征表示。
2)文本圖結(jié)構(gòu)
對于一個有n個節(jié)點(diǎn)的圖,文本圖結(jié)構(gòu)可以用形狀為n×n的鄰接矩陣表示。本文中圖結(jié)構(gòu)的構(gòu)建主要分為兩個步驟。給定包含n個漢字的句子S={c1,c2,…,cn},將句子中每個字作為圖的節(jié)點(diǎn)。首先連接所有相鄰的節(jié)點(diǎn),由于信息傳遞的方向性對于序列標(biāo)注任務(wù)具有重要意義,因此在句子的第i個字和第i+1 個字之間(ci,ci+1之間)都連接2 條方向相反的邊。其次連接詞匯邊,若i和j是第i個字從字典中匹配到詞的開始節(jié)點(diǎn)和結(jié)束節(jié)點(diǎn),本文在這2 個節(jié)點(diǎn)之間連 接2 條方向相反的 邊,即 令A(yù)i,j=1,Aj,i=1。字詞結(jié)合的有向圖如圖4 所示。

圖4 字詞結(jié)合的有向圖Fig.4 Directed graph containing word-character
從圖4 可以看出,如果一個節(jié)點(diǎn)在字典中匹配到詞匯數(shù)不止一個,則該節(jié)點(diǎn)和與之構(gòu)成詞匯的所有節(jié)點(diǎn)之間都存在相應(yīng)的邊,這樣在后續(xù)的傳遞過程中可以同時學(xué)習(xí)所有詞匯與字的信息,有效消除字或詞匯固有序列的影響。
2.2 基于門控機(jī)制圖神經(jīng)網(wǎng)絡(luò)
門控圖神經(jīng)網(wǎng)絡(luò)(GGNN)是一種基于GRU 的經(jīng)典空間域消息傳遞模型[37],與GCN 等其他圖神經(jīng)結(jié)構(gòu)相比,GGNN 在捕捉長距離依賴方面優(yōu)于GCN,更適合于中文的NER 任務(wù)。本文將特征表示層得到的詞向量和鄰接矩陣傳入GGNN 進(jìn)行上下文語義學(xué)習(xí)。信息傳遞過程如式(5)~式(10)所示:
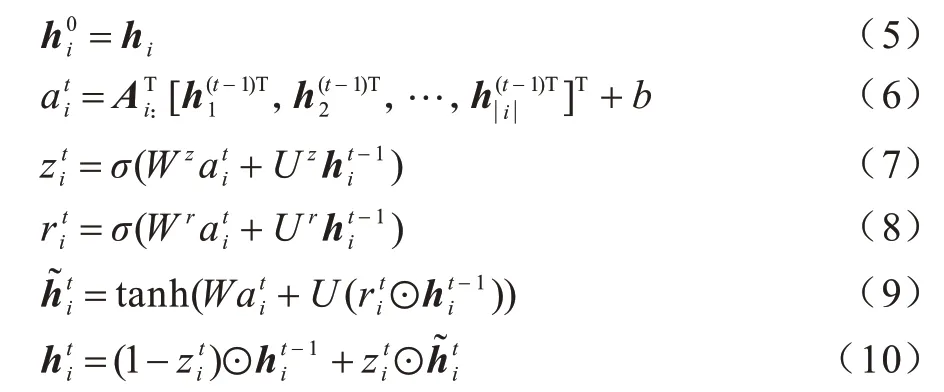
2.3 條件隨機(jī)場層
條件隨機(jī)模型可以看成是一個無向圖模型或馬爾科夫隨機(jī)場,用于學(xué)習(xí)標(biāo)簽的約束,解決標(biāo)簽偏置問題。對于給定的觀察列,通過計(jì)算整個標(biāo)記序列的聯(lián)合概率的方法獲得最優(yōu)標(biāo)記序列。隨機(jī)變量X={x1,x2,…,xn} 表示觀察序列,隨機(jī)變量Y={y1,y2,…,yn}表示相應(yīng)的標(biāo)記序列,P(Y|X)表示在給定X的條件下Y的條件概率分布,則CRF 計(jì)算如式(11)所示:

其中:Y(x)為所有可能的標(biāo)簽序列;f(yt-1,yt,x)用于計(jì)算yt-1到y(tǒng)t的轉(zhuǎn)移分?jǐn)?shù)和yt的分?jǐn)?shù)。最后使得P(y|x)分?jǐn)?shù)最大的標(biāo)記序列y,即句子對應(yīng)的實(shí)體標(biāo)簽序列如式(12)所示:

3 實(shí)驗(yàn)
3.1 數(shù)據(jù)集
本文實(shí)驗(yàn)的數(shù)據(jù)集包括旅游數(shù)據(jù)集和簡歷數(shù)據(jù)集。
Beats1作為一個綜合性的音樂信息傳播平臺,將音樂的電臺傳播和網(wǎng)絡(luò)傳播的特點(diǎn)綜合在一起,形成了具有實(shí)時性、主動性和社交性的全球網(wǎng)絡(luò)音樂電臺,加之自身運(yùn)營平臺的大眾化優(yōu)勢、傳播內(nèi)容的專業(yè)化和覆蓋范圍的全球化,使其具備了成為世界性音樂電臺的基本條件。
1)旅游數(shù)據(jù)集,目前還沒有公認(rèn)度較高的旅游領(lǐng)域數(shù)據(jù)集,本文從去哪兒網(wǎng)、攜程、馬蜂窩等旅游網(wǎng)站收集有關(guān)新疆的旅游攻略,經(jīng)過去除空白行、空格、非文本相關(guān)內(nèi)容等預(yù)處理操作,得到旅游領(lǐng)域文本1 200 余篇。旅游數(shù)據(jù)集使用NLTK 工具對預(yù)處理后的語料進(jìn)行半自動化標(biāo)注,之后進(jìn)行人工校對、標(biāo)注,構(gòu)建用于旅游領(lǐng)域?qū)嶓w識別的訓(xùn)練集、評估集和測試集,并通過高德地圖旅游景點(diǎn)數(shù)據(jù)和旅游網(wǎng)站檢索構(gòu)造旅游景點(diǎn)詞典。
針對旅游領(lǐng)域?qū)嶓w類型的定義,本文參考文獻(xiàn)[7]的分類標(biāo)準(zhǔn),將旅游領(lǐng)域?qū)嶓w分為地名、景點(diǎn)名、特色美食3 大類。考慮到新疆地域的特點(diǎn),本文新增了人名、民族2 種實(shí)體類型,采用BIOES 標(biāo)注體系進(jìn)行實(shí)體標(biāo)注,例如天山大峽谷位于烏魯木齊縣境內(nèi),按照采用的標(biāo)注體系可以標(biāo)記為“天/B-SA 山/I-SA 大/I-SA 峽/I-SA 谷/E-SA 位/O 于/O 烏/B-LOC魯/I-LOC 木/I-LOC 齊/I-LOC 縣/E-LOC 境/O 內(nèi)/O”。旅游數(shù)據(jù)集訓(xùn)練集合計(jì)4 176,驗(yàn)證集合計(jì)541,測試集合計(jì)540。旅游數(shù)據(jù)集實(shí)體信息如表1 所示。
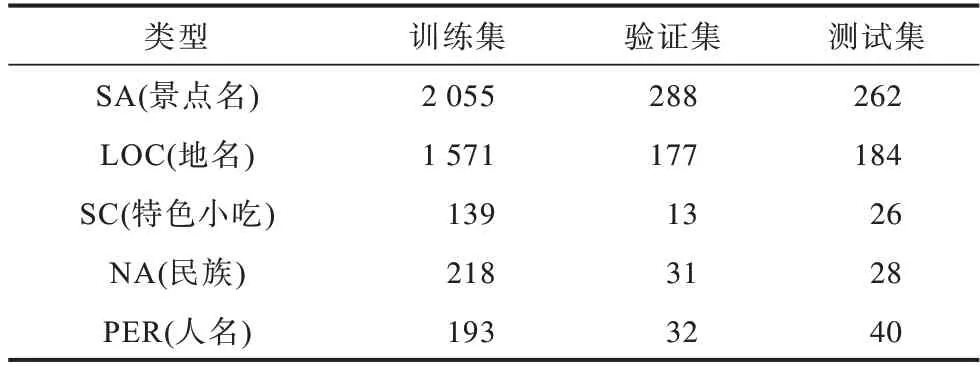
表1 旅游數(shù)據(jù)集實(shí)體信息Table 1 Entities information of tourism dataset
2)簡歷數(shù)據(jù)集,文獻(xiàn)[27]提出該數(shù)據(jù)集共有CONT(country)、EDU(educational institution)、LOC、PER、ORG、PRO(profession)、RACE(ethics background)和TITLE(job title)8 種不同的實(shí)體類型。
旅游數(shù)據(jù)集和簡歷數(shù)據(jù)集的數(shù)據(jù)統(tǒng)計(jì)如表2所示。

表2 旅游數(shù)據(jù)集和簡歷數(shù)據(jù)集的數(shù)據(jù)統(tǒng)計(jì)Table 2 Data statistics of tourism and resume datasets
實(shí)驗(yàn)使用的預(yù)訓(xùn)練詞向量表來源于文獻(xiàn)[38],通用的詞典來源于文獻(xiàn)[27],該字典包含704.4×103個詞,其中單個字有5.7×103個,2個字構(gòu)成的詞有291.5×103個,3 個字構(gòu)成的詞有278.1×103個,其他129.1×103個。
3.2 模型對比
為驗(yàn)證模型的有效性,本文使用現(xiàn)有的應(yīng)用于旅游領(lǐng)域NER 任務(wù)的機(jī)器學(xué)習(xí)方法和主流的深度學(xué)習(xí)模型進(jìn)行對比。
1)HMM 模型[6],以HMM 算法為原理,用于旅游領(lǐng)域NER 任務(wù);
3)BiLSTM+CRF 模型是NER 任務(wù)的經(jīng)典模型;
4)BiLSTM+CRF(融 合bigram)模型為驗(yàn) 證bigram 對NER 任務(wù)的作用,設(shè)計(jì)包含bigram 特征的BiLSTM+CRF 模型進(jìn)行對比分析;
5)Transformer+CRF 模型[21],Transformer 具有強(qiáng)大的特征提取能力,在很多的自然語言處理任務(wù)中逐漸取代RNN 模型,所以本文加入該模型的對比;
6)ID-CNN+CRF 模型[24],膨脹卷積、空洞卷積主要是通過擴(kuò)大感受域的方法獲得更廣泛的序列信息,在英文NER 任務(wù)上曾取得最佳成績;
7)Lattice LSTM 模型[27],該模型是字詞結(jié)合訓(xùn)練的代表性方法,創(chuàng)造性地將字符和詞匯通過網(wǎng)格的方法融合在一起,并且在MSRA、Weibo、OntoNotes4、Resume 這4 個數(shù)據(jù)集上取得最好成績;
8)Bert+CRF 模型,Bert 作為一種預(yù)訓(xùn)練模型,在自然語言處理的多項(xiàng)任務(wù)中逐漸成為主流模型。
3.3 實(shí)驗(yàn)環(huán)境與參數(shù)設(shè)置
本文模型使用的GPU 為GeForce GTX 1080Ti,操作系統(tǒng)為Ubuntu18.04,編程語言為Python3.6,框架為PyTorch 1.1.0。為實(shí)體識別算法的一致性,本文設(shè)置初始化參數(shù),預(yù)訓(xùn)練詞向量維度為300,GGNN 神經(jīng)元個數(shù)為200,丟碼率為0.5,初始學(xué)習(xí)率為0.001,衰減率為0.05。
3.4 評價(jià)指標(biāo)
評價(jià)指標(biāo)采用準(zhǔn)確率(P)、召回率(R)和F1 值,如式(13)、式(14)所示:
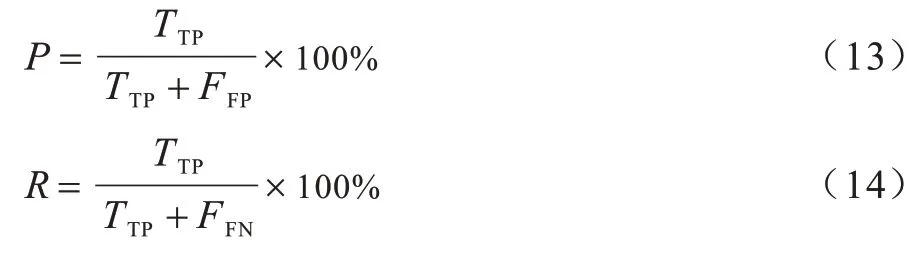
其中:TTP為正確識別的實(shí)體個數(shù);FFP為識別不相關(guān)的實(shí)體個數(shù);FFN為數(shù)據(jù)集中存在且未被識別出來的實(shí)體個數(shù)。
通常精確率和召回率的數(shù)值越高,代表實(shí)驗(yàn)的效果好。一般精確率和召回率會出現(xiàn)矛盾的情況,即精確率越高,召回率越低。F1 值綜合考量兩者的加權(quán)調(diào)和平均值,F(xiàn)1 值如式(15)所示:

3.5 實(shí)驗(yàn)結(jié)果分析
在旅游領(lǐng)域NER 數(shù)據(jù)集上,本文選擇HMM、CRF、BiLSTM+CRF、BiLSTM+CRF(融合bigram)、Transformer+CRF、ID-CNN+CRF、Lattice LSTM、Bert+CRF 等模型進(jìn)行實(shí)驗(yàn)。不同模型的實(shí)驗(yàn)結(jié)果對比如表3 所示,*Dic 為自建詞典。
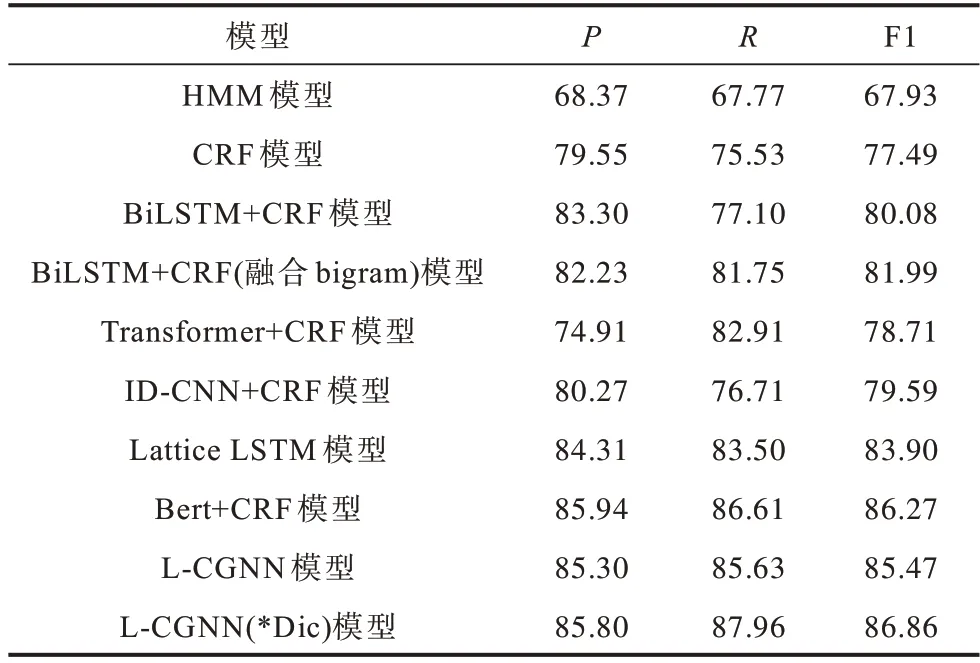
表3 在旅游數(shù)據(jù)集上不同模型的實(shí)驗(yàn)結(jié)果對比Table 3 Experimental results comparison among different models on tourism dataset %
從表3 可以看出,HMM 和CRF 模型在旅游領(lǐng)域NER 任務(wù)上的P、R、F1 數(shù)值都低于其他深度學(xué)習(xí)模型,HMM 模型僅依賴于當(dāng)前狀態(tài)和對應(yīng)的觀察對象,序列標(biāo)注問題不僅與單個詞相關(guān),還與觀察序列的長度、單詞的上下文等相關(guān)。CRF 模型解決了標(biāo)注偏置問題,識別效果相較于HMM 模型有很大程度的提高。由于CRF 模型不能充分捕捉上下文語義信息,因此在不規(guī)范的旅游文本上識別效果不佳。
與ID-CNN+CRF模型相比,BiLSTM+CRF模型的識別效果較優(yōu),BiLSTM 模型能夠獲得長距離依賴關(guān)系,加強(qiáng)對語義的理解,ID-CNN 模型雖然通過擴(kuò)大感受域的方法加強(qiáng)距離關(guān)系的捕捉,但仍存在不足。BiLSTM+CRF 模型融合bigram 特征后,對實(shí)體識別的效果略有提升,表明加入bigram 特征可以提高NER 效果。
對比Transformer+CRF 與BiLSTM+CRF 模型,Transformer+CRF 模型在命名實(shí)體識別效果上低于BiLSTM+CRF模型。Transformer在方向性、相對位置、稀疏性方面不適合NER 任務(wù)。雖然Transformer對位置信息進(jìn)行編碼,但在NER 任務(wù)上,效果仍然不理想。
Lattice LSTM 模型通過字典的方式融合詞匯信息與字符信息以提升NER 效果,由于其嚴(yán)格的序列學(xué)習(xí)特性,每次都會按照匹配詞出現(xiàn)的順序?qū)W習(xí),因此會出現(xiàn)歧義現(xiàn)象。Lattice LSTM 模型實(shí)驗(yàn)效果相較于L-CGNN 模型較差。
Bert+CRF 模型在該任務(wù)上的結(jié)果優(yōu)于Lattice LSTM 模型。Bert 利用Transformer 編碼器提高特征提取能力,獲得充分的上下文信息。對于旅游領(lǐng)域,詞典是非常重要的外部資源,對于NER 等任務(wù)具有十分重要的意義。因此,L-CGNN(*Dic)模型在旅游數(shù)據(jù)集上識別效果優(yōu)于Bert+CRF 模型。
本文提出L-CGNN 模型通過詞典構(gòu)建有向圖結(jié)構(gòu),利用圖神經(jīng)網(wǎng)絡(luò)獲得語義信息,不僅融合字符與詞匯信息,還可以利用圖特殊的結(jié)構(gòu)進(jìn)行傳遞。在每次計(jì)算時,L-CGNN 模型同時將節(jié)點(diǎn)匹配到與所有詞匯信息相融合,從而減少詞序?qū)е碌钠缌x現(xiàn)象。
為驗(yàn)證L-CGNN 模型解決匹配詞先后順序?qū)ER 效果的影響,本文在公開的簡歷數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如表4 所示。
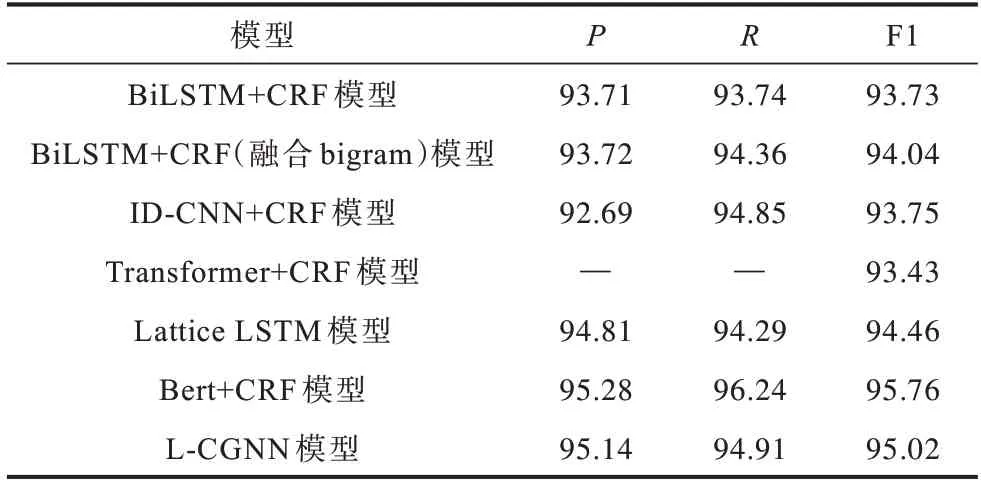
表4 在簡歷數(shù)據(jù)集上不同模型的實(shí)驗(yàn)結(jié)果對比Table 4 Experimental results comparison among different models on resume dataset %
從表4 可以看出,Transformer+CRF 中的P、R沒有公布,所以未能獲取。與其他模型(除Bert+CRF模型外)相比,L-CGNN 模型在P、R、F1 值上的分?jǐn)?shù)較高。本文模型略低于Bert+CRF 模型,主要是因?yàn)橛邢驁D結(jié)果依賴于字典的質(zhì)量,通用的詞典質(zhì)量低于專有領(lǐng)域詞典,未能取得與旅游領(lǐng)域一樣高于Bert+CRF 模型的數(shù)值。這組實(shí)驗(yàn)進(jìn)一步表明L-CGNN 模型具有一定的泛化能力。
3.6 消融實(shí)驗(yàn)
為探討不同特征對實(shí)驗(yàn)結(jié)果的影響,本文分別去除某些特征進(jìn)行命名實(shí)體的識別,實(shí)驗(yàn)結(jié)果如表5所示。W/O 代表去除該特征,例如W/O lexicon 代表去除字典信息。
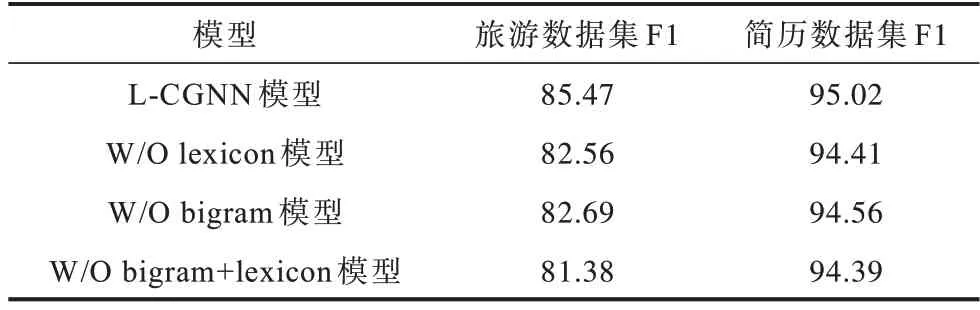
表5 不同特征對實(shí)驗(yàn)結(jié)果的影響Table 5 Influence of different features on experimental results %
從表5 可以看出,在兩個數(shù)據(jù)集上,如果去除字典特征,最終的識別效果較差。同樣的,在去除bigram 特征的情況下,模型的識別效果也會被削弱。同時去除字典和bigram 兩個特征后,F(xiàn)1 值有了很大程度降低,說明加入的特征能夠改善最終的識別效果。
3.7 收斂速率與資源消耗對比
為進(jìn)一步說明本文模型的性能,本文對比BiLSTM+CRF、Lattice LSTM 和L-CGNN 這3 種模型的收斂速度。不同模型的收斂曲線對比如圖5所示。
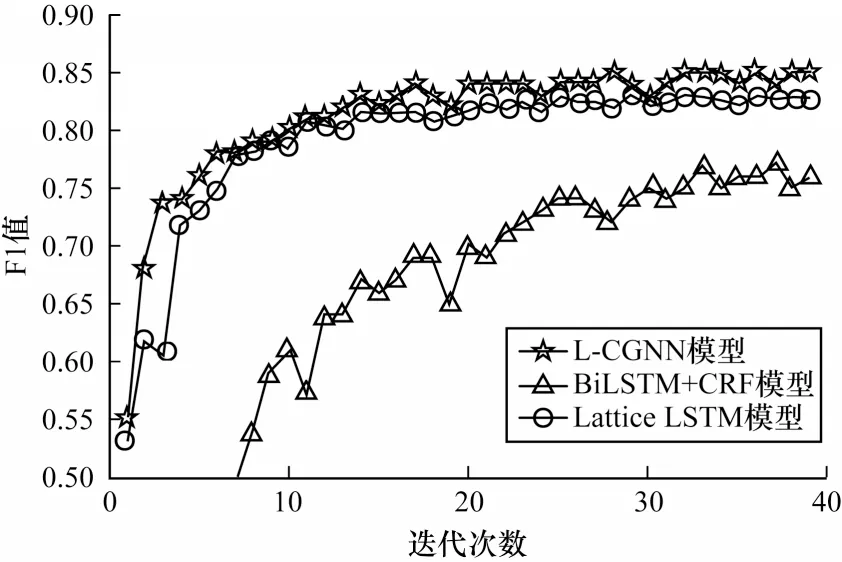
圖5 不同模型的收斂曲線對比Fig.5 Convergence curves comparison among different models
從圖5 可以看出,L-CGNN 模型的收斂速度優(yōu)于其他模型。BiLSTM+CRF 模型通過雙向LSTM 學(xué)習(xí),使得信息更新較慢,并且沒有包含任何詞匯特征,因此,識別速率提升較慢。Lattice LSTM 和L-CGNN 模型都包含字典外部信息,識別效果相對較好。在一段時間后,L-CGNN 模型識別效果明顯優(yōu)于Lattice LSTM 模型,說明本文模型在融合詞匯方面具有較優(yōu)的效果。
在資源消耗方面,本文從訓(xùn)練時間上分別對HMM、CRF、BiLSTM+CRF、Lattice LSTM、L-CGNN等模型進(jìn)行對比實(shí)驗(yàn),結(jié)果如表6 所示。

表6 在旅游數(shù)據(jù)集上不同模型的訓(xùn)練時間對比Table 6 Training time comparison among different models on tourism dataset s
從表6 可以看出,HMM 和CRF 模型是基于機(jī)器學(xué)習(xí)方法,所以訓(xùn)練速度較快,但識別效果欠佳。相比BiLSTM+CRF 模型,由于L-CGNN 模型構(gòu)建鄰接矩陣,因此在訓(xùn)練上的時間消耗略大。對比融合詞典的Lattice LSTM 模型,L-CGNN 模型的時間消耗較低,且具有最優(yōu)的識別效果。
4 結(jié)束語
針對旅游領(lǐng)域的命名實(shí)體識別任務(wù),本文提出基于字典構(gòu)建文本的有向圖結(jié)構(gòu)模型,通過卷積神經(jīng)網(wǎng)絡(luò)提取字特征,利用詞典構(gòu)建句子的有向圖,生成對應(yīng)的鄰接矩陣,并將包含局部特征的詞向量和鄰接矩陣輸入圖神經(jīng)網(wǎng)絡(luò)中,引入條件隨機(jī)場得到最優(yōu)的標(biāo)記序列。實(shí)驗(yàn)結(jié)果表明,相比Lattice LSTM、ID-CNN+CRF、CRF 等模型,本文模型具有較高的識別準(zhǔn)確率。后續(xù)將研究更有效的圖神經(jīng)網(wǎng)絡(luò),用于命名實(shí)體識別,進(jìn)一步提高實(shí)體識別準(zhǔn)確率。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
今古傳奇·故事版(2016年24期)2017-02-07 04:29:04
中外會展(2014年4期)2014-11-27 07:46:46
數(shù)學(xué)大王·低年級(2014年7期)2014-08-11 16:36:44
河南科技(2014年23期)2014-02-27 14:19:15
海外英語(2013年8期)2013-11-22 09:16:04
祝您健康(1987年3期)1987-12-30 09:52:32
