基于動態采樣策略的微服務鏈路追蹤方法①
2022-02-15 06:40:24顏復海李培軍張澤華陳文輝許舒人
計算機系統應用 2022年1期
顏復海,李培軍,張澤華,陳文輝,許舒人
1(中國科學院 軟件研究所 軟件工程技術研究開發中心,北京 100190)
2(中國科學院大學,北京 100490)
3(廈門物之聯智能科技有限公司,廈門 361022)
1 引言
由于具備高可用性、支持動態伸縮與分布式部署等特點,微服務架構已成為云原生時代設計與構建大型分布式應用系統的主要技術架構之一.在微服務架構中,應用系統被劃分為多個高內聚、功能單一、可獨立部署的服務,并通過服務之間的輕量級遠程調用來構建復雜的業務邏輯[1,2].
可觀察性是指系統可由外部輸出推斷其內部狀態的程度.對微服務架構而言,當服務數量龐大時,服務之間的調用關系變得復雜,使得故障分析與排查的困難程度顯著上升,因此微服務架構也面臨著如何提高可觀察性的問題.分布式鏈路追蹤(distributed tracing)是提升微服務架構的可觀察性的關鍵技術之一,其通過收集應用系統處理服務請求的詳細信息來為系統行為建模,以幫助開發與運維人員獲得系統運行時的全局視角[3].
應用系統對一次外部請求的完整處理稱為一次執行(execution).以一次執行中是否出現異常為依據可將該次執行劃分為正常執行或異常執行.跟蹤(trace)是對執行的記錄,一個跟蹤對應一次執行,其內容包含該次執行中各服務之間的調用關系以及各服務處理調用請求的詳情與結果.跟蹤由插樁代碼生成并上報至負責匯總處理的遠程進程.
出于減小對應用系統的性能影響、節約存儲資源等方面的考慮,在分布式鏈路追蹤中通過特定的采樣策略來只收集一部分執行的跟蹤[3–5].常見的開源鏈路追蹤系統或框架實現的采樣策略有固定采樣、概率采樣、限速采樣、自適應采樣等[6–8].以上采樣策略雖然實現簡單且有效避免了插樁代碼對應用系統造成較大工作負載,但是存在收集過多無助于故障分析與排查等任務的正常執行的跟蹤等問題[4,5].以概率采樣為例,收集的跟蹤當中各類執行的跟蹤占比與其出現的概率一致,因此高頻的正常執行的跟蹤占比將遠大于低頻的異常執行.但是對于故障分析這一需求而言,異常執行的跟蹤占比越大、跟蹤數量越多則提供給系統管理人員進行故障分析等任務的信息量越大[4,5].
針對以上問題,本文提出一種動態采樣策略:通過采樣策略樹解決如何自動調整跟蹤采樣率的問題;通過執行軌跡圖解決如何快速準確地找到需要調整跟蹤采樣率的服務的問題;通過以上兩種數據結構的協作提高異常執行的跟蹤占比.基于以上工作,本文實現了原型系統并通過實驗對動態采樣策略的有效性進行了驗證.
2 基于采樣策略樹的跟蹤采樣率自動調整方法
2.1 問題分析
任一執行類型的調用鏈路中最先處理外部請求的服務稱為該類執行的入口服務.提高入口服務的跟蹤采樣率將會增加其對應執行類型的跟蹤數量,從而消耗更多的存儲資源.若要提高存儲資源的利用率,那么當提升某一入口服務的跟蹤采樣率時就應適當減小其他部分入口服務的跟蹤采樣率,使得跟蹤數量保持動態平衡.本文設計了一種稱為采樣策略樹的數據結構來解決跟蹤采樣率的自動調整問題.
2.2 采樣策略樹的定義
定義1.一棵m階的采樣策略樹是滿足以下性質的m叉樹:
1)樹中任一節點至多有m個子節點;
2)除根節點外,其他節點要么沒有子節點,要么子節點數大于1.
圖1所示為采樣策略樹的樹節點結構.父節點指針為指向該樹節點的父節點的指針.若樹節點為根節點,則父節點指針為空.子孫葉子節點計數為以當前樹節點為根節點的m叉樹中所有葉子節點的計數.樹中只保存入口服務.標簽為當前樹節點保存的服務的唯一標識符.所有服務只保存在葉子節點中,因此枝干節點的標簽的值為空.子節點指針集為固定容量的集合,用于保存當前節點的所有子節點的指針,其底層由一個指針哈希表和一個雙向鏈表來實現.

圖1 采樣策略樹的樹節點結構
2.3 采樣策略樹的操作
采樣策略樹支持的操作有插入、剪枝、生成和提升等.插入操作將新服務的葉子節點插入到離根節點盡可能近的位置.剪枝操作將某一服務對應的葉子節點從樹中刪除.
生成操作以路徑概率積作為樹中服務的跟蹤采樣率.路徑概率積的定義如下:
定義2.設葉子節點l且葉子節點的父節點不為根節點r,其到根節點的路徑為s=(l,n1,n2,···,nk,r),ni為路徑上的枝干節點,則該葉子節點的路徑概率積為:

其中,Nx為節點x的子節點數量;若葉子節點l的父節點為根節點,則該節點的路徑概率積為:

提升操作將提升樹中服務的跟蹤采樣率,其偽代碼如算法1 所示.提升操作內部包含了降級操作,遭到降級的葉子節點,其保存的服務的跟蹤采樣率也隨之降低.

算法1.采樣策略樹的提升操作算法輸入:葉子節點 leafNode 1.function Promote(leafNode)2.if leafNode的父節點為根節點 then 3.return 4.end if 5.grandparent:=leafNode的祖父節點6.parent:=leafNode的父節點7.從parent的子節點集合中刪除leafNode 8.if grandparent的子節點數小于最大值 then 9.將leafNode 添加到 grandparent的子節點集中10.將leafNode的父節點指針指向 grandparent 11.if parent 只剩一個子節點 then 12.將parent 唯一的子節點添加到parent的父節點的子節點集合當中,刪除parent//路徑壓縮13.else 14.更新parent的子孫葉子節點計數值15.end if 16.else 17.lruNode:=grandparent的最近最久未使用子節點18.if parent的子節點數大于2 then 19.Merge(lruNode,leafNode)20.else 21.替換lruNode 與leafNode的位置22.enf if 23.更新parent的子孫葉子節點計數值24.end if 25.end function 26.function Merge(a,b)27.在a的父節點與a 之間插入一個新的枝干節點28.將a,b的父節點指針指向新的枝干節點29.將a,b 移動到新枝干節點的子節點集合當中30.end function
圖2為一棵3 階采樣策略樹的發生降級的提升操作示例.一個節點的子節點以從左到右的順序表示其最近被使用過的時間順序,即最右邊的為最近最久未被使用的子節點.需要被提升的服務為D.由于grandparent的子節點數量已達最大值3,因此需要降級該節點的最近最久未被使用的子節點C,使其與D 交換位置.
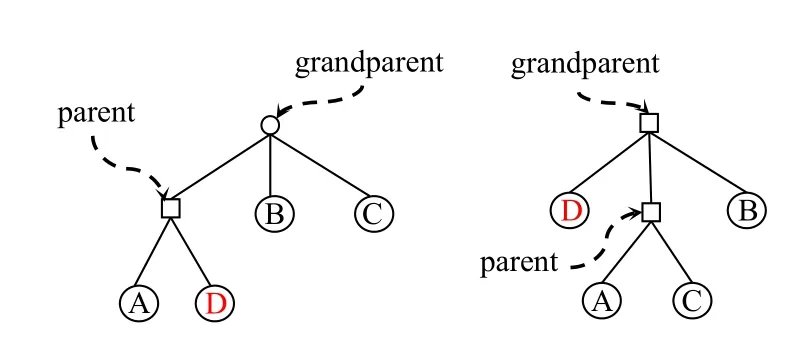
圖2 發生降級的提升操作
2.4 跟蹤采樣率的自動調整
給定服務并找到對應的葉子節點之后,提升操作將改變該葉子節點處于樹中的位置使其離根節點更近.根據路徑概率積的定義可推導出:一個服務的葉子節點被提升之后,該服務根據路徑概率積計算所得的跟蹤采樣率隨之提高.提升操作可能觸發降級操作,即某一服務的葉子節點被下放到樹的更深處,因此被降級的葉子節點的服務的跟蹤采樣率會隨之降低.跟蹤采樣率的變化方向與其是否被提升有關且執行提升操作的條件可自行設定.跟蹤采樣率變化的幅度與樹結構的變化有關,具體數值取決于所涉及樹節點的子節點數.
在提升操作中加入降級操作是為了提高存儲資源的利用率.一個服務的吞吐量和跟蹤采樣率共同決定了以該服務作為入口服務的執行類型的跟蹤數量.當吞吐量不變時,跟蹤采樣率與跟蹤數量呈正相關.根據路徑概率積的定義可推導出:采樣策略樹中所有服務根據路徑概率積計算所得的跟蹤采樣率總和為1.因此,當提高其中一個服務的跟蹤采樣率時,必定導致樹中另外一部分服務的跟蹤采樣率的降低,使得跟蹤數量保持動態平衡,從而有效提高存儲資源利用率.
3 基于流言協議的執行軌跡圖全局更新算法
3.1 問題分析
入口服務中的插樁代碼做出采樣決策并將其寫入請求上下文之后,采樣決策會隨著調用鏈路傳播給該入口服務遞歸調用的其他服務,并且各服務根據請求上下文中的采樣決策判斷是否上報跟蹤,因此任一服務的跟蹤采樣率等于其入口服務的跟蹤采樣率.當某一非入口服務出現異常時,要提升其跟蹤采樣率以提高異常執行的跟蹤占比,則需找到與之對應的入口服務.針對以上問題,本文利用執行軌跡圖這一數據結構來刻畫服務之間的調用關系.
3.2 執行軌跡圖的定義
定義3.執行軌跡圖G=(V,E)是一個有向圖,其中,節點集V表示服務集合,邊集E表示調用關系集合,邊的箭頭指向被調用的服務.
圖3為一個執行軌跡圖示例.A為入口服務,且A 調用服務B 與服務C 來完成其本身的請求處理.圖中其他服務的調用關系與之類似.

圖3 執行軌跡圖示例
3.3 全局更新算法
執行軌跡圖的更新是一個動態的過程,即每次發現新的服務或調用關系,就把表示新服務的頂點、表示新調用關系的邊添加到執行軌跡圖當中.基于執行軌跡圖,在給定任一服務的前提下,可通過圖搜索算法快速找到該服務對應的入口服務.在實際應用中,出于容災和性能上的考慮,需要冗余地部署跟蹤收集進程,因此需要在多個跟蹤收集進程之間同步執行軌跡圖,使得所有執行軌跡圖的副本能夠反映各服務之間的實時調用關系.本文提出一種基于流言協議的執行軌跡圖全局同步算法以解決上述問題.
圖4為本文用到的基于流言協議的組件:種子、注冊中心,以及兩者的通信關系.注冊中心用于種子發現,即當新的種子加入時向注冊中心登記其路由信息.種子定期向注冊中心發送心跳信號并獲得所有其他種子的實時路由信息,以及將新調用關系封裝成消息散播給其他種子.在實現中,每個跟蹤收集進程都會維護一個種子,而注冊中心是全局唯一的.當跟蹤收集進程發現新調用關系時,會向本地的種子發起消息散播請求,將新調用關系同步給其他跟蹤收集進程中的執行軌跡圖.執行軌跡圖的全局更新算法偽代碼如算法2 所示.算法2 參照了流言協議的SIR 模型[9],即每個種子對于任一消息在任一時刻只對應以下3 種狀態之一:S (susceptible),未收到該消息;I (infected),已收到該消息且正在參與該消息的散播過程;R (removed),已收到該消息且已退出該消息的散播過程.

圖4 基于流言協議的組件及通信關系

算法2.執行軌跡圖的全局更新算法輸入:新調用關系 newRel 1.function Synchronize(newRel)2.msgID:=由snowflake 算法生成全局唯一消息ID 3.msg:=(msgID,newRel)//消息格式4.Monger(msg)5.end function 6.function Monger(msg)7.if not msg的ID 存在于LRU 緩存中 then 8.提取調用關系,更新執行軌跡圖9.將msg的ID 放入LRU 緩存10.end if 11.if not 本地節點對msg 處于R 狀態 then 12.peers:=隨機選取n 個對等節點13.for each 對等節點peer in peers:14.以msg為參數,遠程調用peer的Monger 方法15.end for 16.以概率p 轉換成R 狀態,否則為I 狀態17.end if 18.end function
4 原型系統
4.1 系統架構
本文參考開源分布式鏈路追蹤系統Jaeger的數據模型與架構并參照OpenTracing 規范[10]實現了原型系統,其系統架構如圖5所示.插樁代碼負責生成、上報跟蹤以及周期性地向配置服務器拉取采樣策略.代理負責為插樁代碼屏蔽配置服務器和收集器的路由信息.配置服務器負責處理采樣策略的拉取請求以及更新采樣策略的請求并且通過策略管理器維護全局唯一的采樣策略樹.注冊中心用于種子發現,維護所有種子的路由信息.種子用于執行全局更新算法.收集器負責收集、分析以及持久化跟蹤.
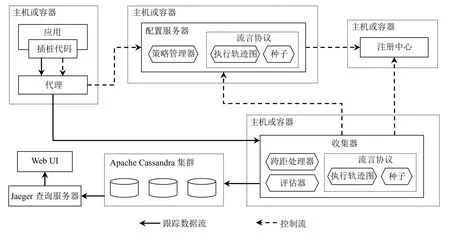
圖5 原型系統的架構
4.2 跟蹤收集過程
跨距(span)是跟蹤的基本組成單元,一個跨距記錄一個服務處理一次請求處理的詳細信息以及調用關系.收集一個跟蹤即收集該跟蹤的所有跨距.跟蹤收集的詳細過程如下:
(1)當外部請求到達應用系統時,入口服務中的插樁代碼將做出采樣決策并將其寫入請求上下文使其在調用鏈路中傳播;
(2)所有服務中的插樁代碼都將在其嵌入的服務處理請求之前分析請求上下文并創建一個跨距,且請求上下文中的采樣決策會被寫入跨距上下文;
(3)待請求處理完成之后,插樁代碼將根據跨距上下文中的采樣決策判斷是否上報該跨距,若執行采樣則將跨距發送至代理,再由代理上報至收集器;
(4)收集器分析跨距獲得調用關系,判斷是否為新調用關系,若為新調用關系則執行全局更新算法;
(5)收集器調用評估器判斷該次執行是否為預先定義的執行類型,若是則向配置服務器發送請求以提升該執行的入口服務的跟蹤采樣率;
(6)收集器將跨距保存至數據庫中.
4.3 采樣策略拉取過程
插樁代碼周期性地發送拉取采樣策略的請求,該請求包含兩個參數:服務唯一標識符和該服務從上一次發送請求到目前為止這一時間段內的每秒請求數,即QPS (request per second)值.
配置服務器為所有入口服務維護一個QPS 值的哈希表.當接收到采樣策略拉取請求時,配置服務器首先會用參數中的QPS 更新該哈希表,然后通過以下等式計算采樣率:
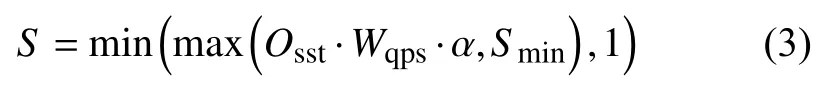
其中,Osst為采樣策略樹的生成操作的路徑概率積計算結果,α ∈(0,+∞)為縮放因子,Smin為最小采樣率,Wqps為QPS 權重函數的輸出,其計算方式如下:

其中,qi表示第i個入口服務的實時QPS 值,E為入口服務數.
計算所得的采樣率會被封裝成概率采樣為底層采樣方式的采樣策略作為響應返回給插樁代碼,由插樁代碼分析響應結果并據此更新本地的采樣策略.
4.4 采樣策略樹與執行軌跡圖的協作過程
為評估器設置評估條件作為判斷HTTP 服務的某次執行是否為異常執行的依據:HTTP_STATUS_CODE≠200.
圖6所示為HTTP 服務出現一次異常執行時采樣策略樹與執行軌跡圖的協作過程.

圖6 采樣策略樹與執行軌跡圖的協作過程
(1)分析調用服務E 時由插樁代碼生成的跨距,調用評估器分析其標簽,發現其滿足評估條件;
(2)調用執行軌跡圖的查詢接口,由其利用圖搜索算法找到服務E的入口服務,即服務A;
(3)調用一棵2 階采樣策略樹的提升操作接口,提升服務A的葉子節點并降級服務X的葉子節點以提升服務A的跟蹤采樣率、降低服務X的跟蹤采樣率.
實際上執行類型是高度可定制的,可根據不同的任務與場景為評估器設置不同的評估條件,并由插樁代碼在預設的異常情況發生時為跨距設置與評估條件對應的標簽名稱以及標簽值.
5 實驗驗證與分析
5.1 實驗方案
本文在3 臺主機上部署Kubernetes 集群、Istio 服務網格并開發與部署對應8 個執行類型的32 個HTTP微服務作為模擬云環境部署的實驗環境.每臺主機的操作系統為CentOS 7.9,處理器為Inter(R) Xeon(R) E5-2620 @ 2.00 GHz,內存容量為32 GB,Kubernetes 版本為1.19.0,Istio 版本為1.7.本文使用基于Python 開發的壓測工具Locust 來模擬多用戶的并發請求.在實驗中以容器組(pod)的形式冗余部署了3 個收集器.
本文著重關注兩個實驗指標:任一時間段內各執行類型的跟蹤占比和跟蹤數.本文將比較固定采樣、概率采樣、限速采樣、自適應采樣以及動態采樣的實際表現.以上各采樣策略的實驗參數如表1所示.
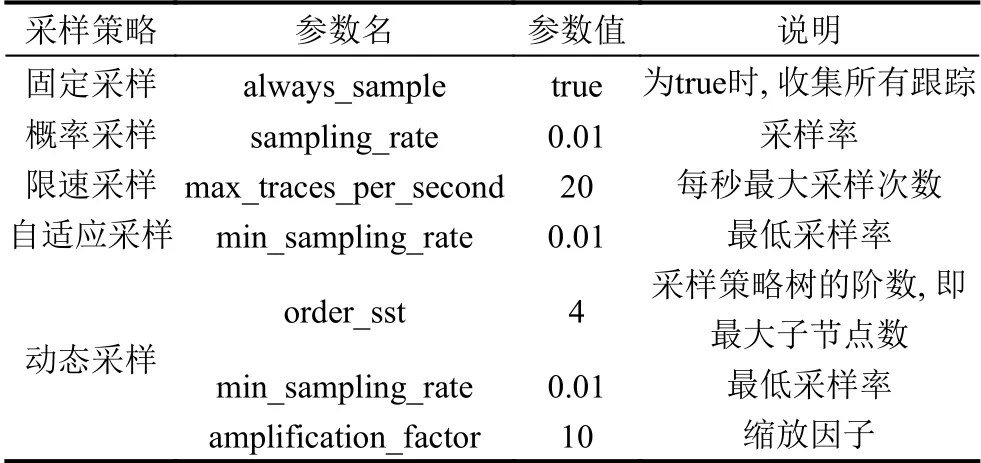
表1 實驗中各采樣策略的參數
在各采樣策略的實驗中,每隔固定長度的時間段則為某一類執行注入故障且在對下一類執行注入故障之前,修復上一類執行的故障.注入的故障類型為內部錯誤,具體表現形式為調用服務所返回的HTTP 狀態碼為500,因此在實驗中設定評估條件為:HTTP 狀態碼不等于200.當插樁代碼捕捉到該異常時會將HTTP狀態碼以及對應的值500 寫入跨距標簽.
5.2 實驗結果
各采樣策略的實驗中跟蹤占比的變化情況如圖7–圖11所示.圖11表明在動態采樣策略的實驗中,對于任一時間段內被注入故障的執行類型的跟蹤占比顯著上升.各采樣策略的實驗中的跟蹤數變化情況如圖12所示.在動態采樣的實驗中,各時間段內被注入故障的執行類型的入口服務的跟蹤采樣率顯著上升,其對應的跟蹤數也顯著增多,但是由于同時降低了另一部分入口服務的跟蹤采樣率,因此任一時間段的跟蹤數相對于前一時間段沒有明顯地上升或下降,使得跟蹤數保持動態平衡而異常執行的跟蹤占比顯著上升,從而提高了存儲資源的利用率.

圖7 固定采樣實驗的跟蹤占比變化

圖9 限速采樣實驗的跟蹤占比變化

圖10 自適應采樣實驗的跟蹤占比變化
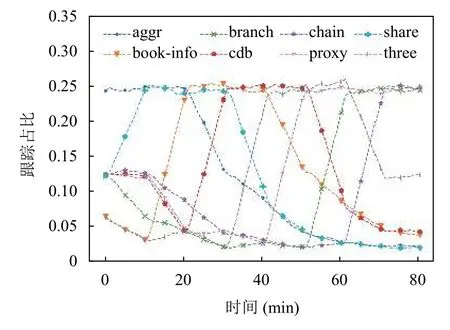
圖11 動態采樣實驗的跟蹤占比變化

圖12 跟蹤數隨時間的變化情況
實驗結果表明,動態采樣有效提升了任一時間段內異常執行的跟蹤占比并且高效利用了存儲資源.
6 總結
針對現有開源分布式鏈路追蹤系統或框架的采樣策略存在的收集過多無助于故障分析等任務的正常執行的跟蹤這一問題,本文提出一種基于動態采樣策略的微服務鏈路追蹤方法:通過基于采樣策略樹的跟蹤采樣率自動調整方法解決了跟蹤采樣率的自動調整問題;通過基于流言協議的執行軌跡圖全局更新算法解決了如何快速準確地找到需要調整跟蹤采樣率的入口服務的問題.實驗結果表明,本文方法在任一時間段內均有效地提升了異常執行的跟蹤占比并且高效利用了存儲資源.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
數學大世界(2018年1期)2018-04-12 05:39:14
商周刊(2017年9期)2017-08-22 02:57:56
發明與創新(2016年38期)2016-08-22 03:02:52
