基于條件生成式對抗網絡的情感語音生成模型①
2022-02-15 06:41:28崔新明周潔美慧
計算機系統應用 2022年1期
崔新明,賈 寧,周潔美慧
(大連東軟信息學院 計算機與軟件學院,大連 116023)
在人與人或人與計算機的交互中,話語的表達方式傳遞著重要的副語言信息,特別是蘊含著與潛在情感有關的信息.因此,需要現代言語分析系統能夠分析這種與情感相關的非語言維度,以及話語本身的信息,以適應更好的人機交互操作.近年來,自動識別口語情感內容和情感語音對話等技術引起了越來越多研究人員的關注.語音情感識別和對話均是典型的有監督的音頻任務,它們均涉及低級音頻特征映射到具有不同情感的高級類標簽或情感維度的映射.因此,帶精確標注的數據集在構建和評估語音情感識別系統中是非常重要的.然而,在現實生活中,真實表達情感的開源語料庫少之又少,而且大多數語料庫使用的是非漢語語言.
基于此,本文提出了一個基于條件生成對抗網絡(conditional generative adversarial networks,條件GAN)的語音生成技術,用于合成海量的漢語情感語音,并實現情感的精確表達,在實驗過程中,通過情感識別模型驗證了生成情感語音的有效性.
1 相關工作
語料庫規模不足或高度傾斜的數據是語音生成和語音識別過程中的一個常見問題.在數據采集和標注過程中,中性語音樣本的使用頻率遠高于含有情感的語音樣本,或者存在大量情感表達有歧義的語音,這些問題均導致數據集出現高度不平衡的現象.解決數據不平衡的一種常見方法是使用數據增強技術[1].Wong 等人[2]利用過采樣和變換生成數據空間合成樣本,有利于數據空間的擴展以進行數字分類.Schluter 等人[3]評估了七種不同的數據增強技術,用于檢測語音譜圖中的情緒表達,發現音高的偏移量和隨機頻率的濾波是最有效的情感表達.此外,研究表明音調增強有利于環境聲音分類[4]和音樂流派分類[5]等任務.對于語音生成等任務,Aldeneh 等人[6]對原始信號應用了語速的微調,證明了情感表達的有效性.
除了傳統的數據增強方法,生成對抗網絡(generative adversarial networks,GAN)作為一種強大的生成模型,其應用范圍越來越廣.GAN 通過同時訓練兩個相互競爭的網絡(一個生成器和一個鑒別器)來近似數據分布.GAN的計算流程與結構如圖1所示.許多研究集中在提高生成樣本的質量和穩定GAN 訓練等領域中[7].

圖1 GAN的計算流程與結構
生成性對抗網絡已經成功地應用于各種計算機視覺任務以及與語音相關的應用,如語音增強[8]和語音轉換[9].Sahu 等人部署對抗式自動編碼器在壓縮特征空間中表示語音,同時保持情感類之間的區分性[10].Chang和Scherer 利用一個深層卷積GAN 以半監督的方式學習情感言語的區別表示[11].Han 等人提出了一個由兩個網絡組成的條件對抗訓練框架.一個學習預測情緒的維度表示,而另一個旨在區分預測和數據集的真實標簽[12],其識別精度可以和傳統的合成網絡相當.
最近,基于GAN的強大合成能力,許多研究人員開發了GAN的變換版本,Antoniou 等人[13]訓練了一個生成類內樣本的GAN.Zhu 等人[14]設計了CycleGAN架構適用于面部表情的情感分類.對于語音領域,Sahu 等人[15]綜合特征向量用于提高分類器在情感任務中的性能.Mariani 等人[16]提出了一種條件GAN 結構來解決數據不平衡問題.基于上述現有的研究基礎,本文選擇使用條件對抗生成網絡實現對于情感語音的合成,其中涉及權重學習和條件GAN的微調過程,此外在實驗中設計了一個判別模型用于驗證合成情感的有效性.
2 基于條件GAN的語音生成模型設計
作為人機交互系統的重要功能之一,本文在生成對應文本信息的基礎上,針對個體用戶的語音模型,以說話者的低級描述符特征標簽為條件,設計條件對抗生成網絡模型生成語音.
在生成過程中,生成模型的設計起到決定性的作用,傳統的生成模型需要預先獲得一個標準模型才可進行數據的生成,該模型的獲取較為困難,且容易出現誤差,可以采用具有學習和模仿輸入數據分布的GAN模型實現目標.
GAN 由一個鑒別器和一個發生器組成,它們協同工作,以學習目標的基礎數據分布,這種無需預先建模的方法,對于較大的數據是不可控的.為了解決GAN 太過自由這個問題,可以為GAN 加一些約束,即一種帶條件約束的GAN,在生成模型(G)和判別模型(D)的建模中均引入條件變量,指導數據生成過程.
本文利用條件GAN 模型生成語音情感識別的生成特征向量.它學習以標簽或其所屬的情感類為條件y的高維特征向量的分布.在生成網絡的基礎上,輸入增加了一個情感約束條件p(z),輸出是一個綜合打分或者輸出兩個分數,分別表示真實與條件GAN的相符程度.具體網絡結構如圖2所示.
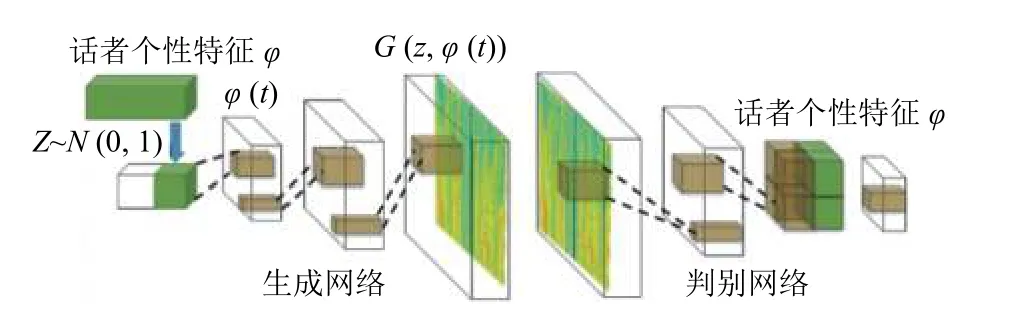
圖2 條件GAN 模型網絡結構
條件GAN的目標函數是帶有條件概率的二人極小極大值博弈.如式(1)所示.
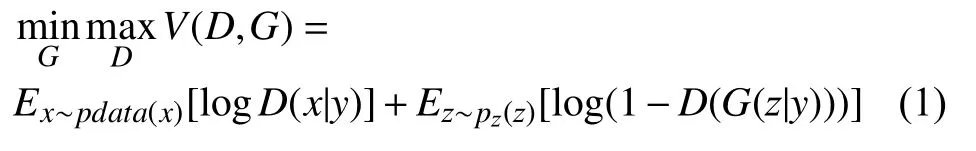
同一般形式的GAN 類似,條件GAN 也是先訓練判別網絡,再訓練生成網絡,然后循環此過程,即兩個網絡交替的完成訓練.訓練判別網絡的樣本與之前的樣本稍有不同,此時需要這3 種樣本,分別是:
(1)與條件相符的真實語音,期望輸出為1;
(2)與條件不符的真實語音,期望輸出為0;
(3)生成網絡生成的輸出,期望輸出為0.
如圖3所示,本文中條件GAN中生成數據生成以標簽為條件.給定一組數據點及其對應的標簽,真實數據的類信息均為one-hot 編碼.條件GAN 學習條件分布,將含有噪聲的語音以及情感條件通過生成器,生成增強后的語音,增強后的語音和相似情感的語音通過判別器,判別器的功能是找出語音的正確類別,并實現對語音的標記,生成器的目標則是讓判別器實現對于生成語音的合理判別,在實現過程中,雙方不斷的微調各自的結果,最終達到一種平衡狀態,即生成器生成的語音可以真實的模擬情感,而判別器可以從語音中識別出的目標情感.基于此,可以獲得與相似情感語音的情感描述相同的生成結果.
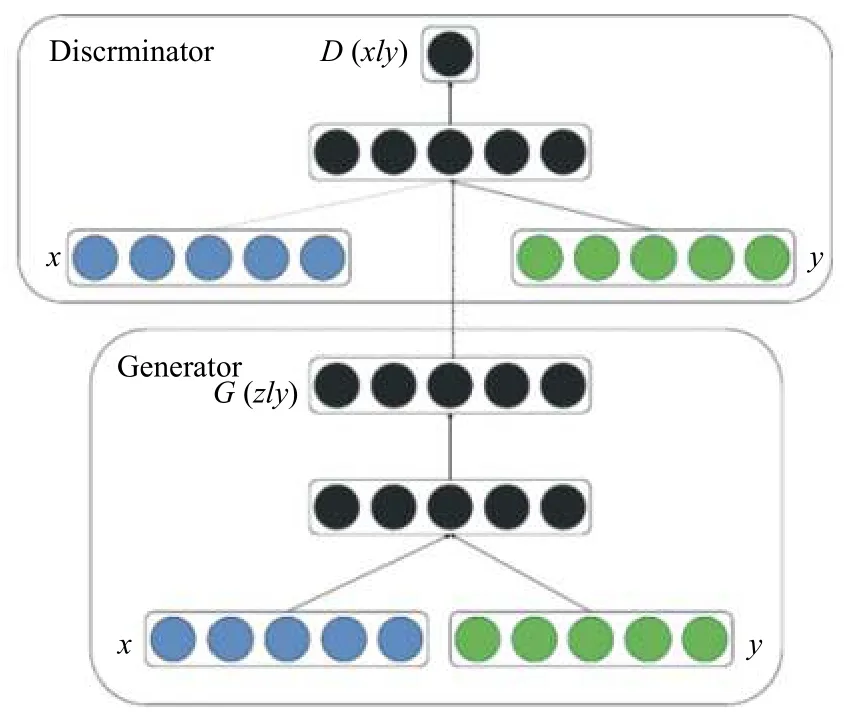
圖3 條件GAN 生成模型
在條件GAN 模型初始化時,需要將學習到的權值傳輸到GAN 模塊,編碼器權值分別傳輸到判別器和解碼器權值傳輸到生成器.對于類條件,需要計算與每個類的圖像相對應的自動編碼器的學習潛在向量的均值和協方差矩陣.此時可用多元正態分布對每一類進行建模,然后,從一個特定類的分布中隨機抽取一個潛在向量,并將其作為輸入提供給生成器,因此條件GAN需具有明確的類別信息.
另一個關鍵技術是條件GAN的微調過程,即條件GAN是使用少數和大多數類別的訓練數據進行微調的.通過這種方式,學習類之間共享的特性.這些特征有助于為少數類創造定性的條件.在微調期間,生成器從類條件潛在向量生成器中提取的潛在特征作為輸入.后者以均勻分布的類標簽作為輸入.然后,將一批真實語音和生成的語音轉發給判別器.兩個競爭網絡中的每一個的目標是使用交叉熵優化其損失函數,對判別器進行優化后,使真實語音與正確的類標簽相匹配,生成的語音與假標簽相匹配.GAN 微調后,使用生成器分別為每個類別生成人工情感語音,以接近大多數類別的情感真實表達.
3 實驗及相關結果
本文采用IEMOCAP和自建情感語料庫分別進行實驗分析.
IEMOCAP 數據集包含兩個演員之間的對話記錄,數據的總量是來自10 個發言者的12 小時音頻和視頻信息,其中注釋了11 類情感標簽(憤怒,幸福,悲傷,中立,驚訝,恐懼,沮喪和興奮)和尺寸標簽(激活和效價的值)從1 到5).本文事先完成了數據過濾步驟:保留的樣本中,其中至少兩個注釋者就情感標簽達成一致,丟棄話語注釋不同的情緒的樣本,并僅使用注釋為中性,憤怒,高興和悲傷的樣本,產生4 490 個樣本(憤怒的1 103,高興的595,中性的1 708和悲傷的1 084),其中使用4 個會話進行訓練,余下的1 個會話用于驗證和測試.
自建情感語料庫是由本校60 余名學生及教師錄制的語音樣本集合,數據總量為包含40 條文字樣本的21 000 條音頻數據,每個音頻時長約2–4 s,均采用中性,憤怒,高興和悲傷4 種情感進行錄制.每類的樣品數量較為均衡.與IEMOCAP 數據集的處理方法類似,只保留至少兩個注釋者的情感標簽一致的數據,同時使用5 折交叉驗證的方式進行測試.
對于IEMOCAP的評估實驗,我們使用5 折交叉驗證,即使用4 個會話進行訓練,使用1 個會話進行測試.此設置是相關SER 庫中IEMOCAP的常見做法.我們使用80%–20%的切分策略,分別進行訓練和驗證.
此處選擇深度學習方法建立情感特征驗證模型,使用TensorFlow 作為開發框架.此處采用了雙向3 層的長短期記憶網絡(long-short term memory,LSTM)模型,雙向是指存在兩個傳遞相反信息的循環層,第1 層按時間順序傳遞信息,第2 層按時間逆序傳遞信息.它意味著過去和未來的信息均可以成功捕獲,這是由于情感表達的時序因素可以由當前時刻的前后若干幀的信息共同決定.因此按照上述思路設計了3 層雙向LSTM 模型,利用條件GAN 模型獲得的新語音進行模型的訓練和參數學習.此模型的結構如圖4所示.

圖4 語音情感驗證模型
設計相關的實驗驗證其有效性,本節將對比情感語音的識別效果.采用加權精度(weighted accuracy,WA)和未加權精度(unweighted accuracy,UA)作為指標,采用圖4中描述的情感分類模型進行測試.IEMOCAP語料庫和自建語料庫的測試結果見表1和表2.

表1 IEMOCAP 測試結果 (%)

表2 自建語料庫測試結果 (%)
從IEMOCAP 語料庫和自建語料庫的測試結果可以看出,使用條件GAN 模型生成語音的情感識別效果高于使用GAN 模型生成語音的結果,而且,它們的測試精度與原始語音的精度相當,由此可以得出結論,當前的條件GAN 模型可以生成與原始語音信號表達情感相似的信號.
進一步對比驗證生成語音與原始語音的相似度及可用性.分別使用原始語音、生成語音和上述語音集合作為訓練數據,采用生成語音、原始語音和混合語音作為測試數據,搭建如圖4所示的情感分類模型.IEMOCAP 語料庫和自建語料庫的測試結果見表3和表4.

表3 IMOCAP 測試結果 (%)

表4 自建語料庫測試結果 (%)
從測試結果可以看出生成語音與原始語音相似且可用,使用生成語音與原始語音的集合可以進一步提升語音情感識別的有效性.
最后,將原始數據與生成數據結合進一步對情感語音分類,現有方法測試結果如表5,自建語料庫模型測試結果如表6.由測試結果可以看出自建語料庫后對情感語音進行分類,并對比現有方法,自建語料庫后的模型相比現有方法識別精度有所提升.

表5 現有方法測試結果

表6 自建語料庫測試結果
4 結論與展望
本文利用條件GAN 模型對大量情感語音進行訓練,其生成樣本接近原始學習內容的自然語音信號的情感表達,通過實驗表明,使用IEMOCAP 語料庫和自建語料庫獲得的新語音具有與原語音相匹配的情感表達.
在未來的研究過程中,作者將進一步擴充現有的情感語料庫,同時進一步改進條件GAN 模型,以提升生成新語音的情感表達效果.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭醫學(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年6期)2016-08-21 13:49:38
