基于GBDT的衛星工程參數異常檢測①
2022-02-15 06:40:04馬文臻王愛玲李旭東黎建輝鄒自明李云龍
計算機系統應用 2022年1期
馬文臻,王愛玲,李旭東,黎建輝,鄒自明,李云龍
1(中國科學院 計算機網絡信息中心,北京 100190)
2(中國科學院 國家空間科學中心,北京 100190)
3(中國科學院大學,北京 100049)
衛星與載荷的運轉異常往往不是一蹴而就的,運轉出現異常時,往往伴隨著相關參數的變化,而這些信息可以通過衛星工程數據反映出來,例如在近期某個時間段內電壓持續偏高、溫度持續偏高、姿態發生偏離等.異常可能由載荷軟硬件故障引起,也可能由單粒子事件等空間環境因素引起,還可能是由觀測到異常目標或者引力波、伽瑪暴等特殊空間事件引起.及時識別數據異常,并在此基礎上挖掘分析出潛在的知識,進而開展預測分析,對于判斷衛星與載荷健康狀態、評估器件壽命、及時有效進行故障處置、快速發現特殊空間事件等都有重要的意義.
空間科學衛星的工程數據是衛星通過地面站傳回的關于自身運轉工作狀態的遙測參數,是地面數據處理系統判斷衛星平臺及載荷在軌運行健康狀態的依據,其異常檢測是地面數據處理系統研究的重點技術,是增強衛星在軌可靠性和安全運行的重要依據.
空間科學衛星的工程數據與其他所有類型航天器的工程數據具有通用的特點,數量大、維度高、參數相關性復雜,此外,由于空間科學衛星搭載的有效載荷工作模式和科學實驗具有高度的特殊性、多樣性和創新性,載荷的工程數據具有更強的專業性,為高檢測率、低誤檢率、強解釋性的工程數據異常檢測實現帶來了嚴峻的挑戰.
1 衛星異常檢測方法綜述
在國內外的衛星數據處理領域,異常檢測的傳統方法是統計學方法,近十幾年來人工智能方法也有廣泛應用[1].
1.1 基于統計學的衛星異常檢測方法
基于統計學的衛星異常檢測方法最常用的有閾值門限法、協方差分析和數據相關性分析.工程數據的維度通常較為龐大,一方面,每個維度的衛星工程數據可以看作一條時間序列,在統計計算過程中可將其看作一個向量,通過分析各個維度參數變化趨勢進行單通道或者多通道聯合檢測;另一方面,某些維度的參數可能具有相關性,可使用多元回歸分析法,通過對每一個維度的參數構建多元非線性回歸模型,實現對多個參數之間的相關關系的深層次分析[2].
閾值門限法的優點是設定的閾值與載荷設計一致,工程實現簡單,而且對于具有固定閾值的參數來說準確率是最高的,但是也有明顯的缺點:適用范圍僅限于可用閾值規則表達的參數,然而很多類型的異常并不會引起變量的超限,因此不能表征全部的異常類型,對于某些參數正確率和某些參數的漏檢率不能兼得;不具備普遍適應性,可擴展性差,且當衛星載荷發生性能變化時,需要不停地重新設定閾值來適應載荷的變化;閾值有時候會出現設置不合理的情況,閾值太寬容易發生漏檢,閾值太窄容易發生大量虛假報警,導致真正的異常事件被埋沒忽視[3].
協方差分析法是針對周期內變化趨勢相同的數據來進行異常檢測的,通過參數之間的協方差構造卡方統計量,在一定的置信水平上判斷數據是否出現異常.該方法的優點是可以有效地檢測出周期性數據的異常,但是對于周期時間長、數據量大的數據,耗時較長,且對于局部異常數據不敏感[4,5].
相關性分析法是針對多個參數之間的相關關系建立的,通過挖掘其相關系數或關聯規則來判定數據是否異常.該方法的優點是對衛星中存在相互影響的遙測數據有很好的檢測效果,排除了單一參數因素產生的誤判漏判干擾,但是對于一些參數同時發生變化的數據來說,檢測效果并不是很理想[6].
1.2 基于人工智能的衛星異常檢測方法
人工智能及計算機技術的飛速發展,為衛星異常檢測技術提供了新的理論基礎,產生了基于知識的智能診斷方法,并顯示出強大的生命力和優越性.比較成熟的方法是專家系統,其采用產生式規則來表示專家的知識,較適合于復雜系統的分析,在國際眾多空間科學衛星任務中均有應用,其局限在于準確且完備的專家知識、系統模型的構建很難通過自動化的方式實現,人工知識獲取與模型構建過程耗時、費力,專家的知識來源也成為其診斷能力的瓶頸,此外一旦航天器設計發生變化,知識和模型往往需要推倒重建[7].
近年來,一些新的研究都嘗試利用機器學習算法進行衛星異常檢測,主要有聚類方法、神經網絡算法、支持向量機算法和決策樹算法等[8].
聚類算法有基于距離、基于密度、基于子空間等多種類型[9].例如,典型的增量聚類算法是通過學習構建反映各參數之間關系的正常數據模型,根據模型匹配返回的系統偏離值監測系統異常行為,可以有效地檢測出閾值檢測方法中在閾值門限之內的異常,避免漏判錯判,但是需要根據經驗確定聚類的數量,且對離散值比較敏感[10].
長短期記憶網絡(long short-term memory,LSTM)是基于循環神經網絡的改進算法,輸入門、輸出門、遺忘門控制信息在神經元之間的信息傳遞,通過迭代更新權重,最終得到理想的輸出值.LSTM 相對于深度神經網絡和循環神經網絡來講,能更好的記憶其在過去長時間內的數據相關性,適合處理序列數據,但是對于一些在時間序列上相關性不是很強的遙測數據來說,檢測效果并不是很理想[11].另外,網絡層數規模往往需通過實驗或經驗值確定,存在局部極值問題,換一個載荷就需要重來一遍,往往不具有擴展性和普適性.
支持向量機(support vector machine,SVM)算法將邊際定義為決策邊界和任何樣本之間的最小距離,基于最小二乘支持向量機(LS-SVM)定義最小二乘代價函數,將二次規劃問題轉換成線性規劃問題,實現類內距離最小化、類間距離最大化,具有良好的準確性,但是由于通常結合主成分分析方法(principal component analysis,PCA)對數據進行預處理降維,在處理非線性問題方面有局限性,可能導致異常檢測效果不明顯[12].
梯度提升決策樹(gradient boosting decision tree,GBDT)算法是以決策樹為基函數的集成學習方法,利用加法模型 (即基函數的線性組合)和前向分布算法實現學習的優化過程,通過將學習得到的多個樹模型進行集成,可以達到同時減少模型方差和偏差的效果,而且具有對數據缺失值不敏感、模型易于構建、數據預處理要求低、速度快、效率高的優點,同時可避免決策樹算法的過擬合現象[13].目前GBDT 算法在電力負荷預測[14]、電路故障診斷[15]、交通流量分析[16]、礦物識別[17]、航班延誤分類預測[18]等領域,均有成熟的應用研究實例,顯示出很好的應用潛力.
2 基于GBDT的衛星工程參數異常檢測模型
對于空間科學衛星異常檢測這一復雜系統,上文1.2 節所述的機器學習方法普遍不夠通用,均需針對具體的樣本特性與應用場景構建不同的模型,在實現方面它們各有優缺點.如何針對性提高檢測的準確率和方法的通用性,是空間科學衛星數據處理領域長期努力的研究焦點.本文根據科學衛星的數據特性設計了基于GBDT的衛星異常檢測分類模型,在相對小的調參復雜度下實現了很高的檢測準確率,而且可以靈活處理包括連續值和離散值的各種類型的數據,通用性更好.
2.1 異常類型分析
本文基于量子科學實驗衛星(空間科學先導專項系列衛星之一)的長管運行經驗,依據工程數據表現特征從總體上將異常類型歸納為6 大類,包括時間碼異常、供電異常、實驗控制機異常、星務異常、數傳通信異常、測控與姿控異常.
(1)時間碼異常
衛星工程參數數據的時間碼字段精確到日內秒,用“年-月-日T 時-分-秒”的格式表達.時間碼錯誤也為異常.有的參數采樣頻率為1 次/s,故時間碼逐條遞增1 s,如果有缺失、錯誤的時間碼,標記為異常.有的參數為固定間隔采樣,那么設置采樣間隔閾值來判定異常.例如,對于16 s 采樣一次的參數,當其兩個樣本之間的間隔小于14 或者大于18 時判為異常.時間與其他參數之間無相關性.
(2)供電異常
平臺與載荷的所有設備的與電源相關的工程參數,包括電壓、電流以及開關機狀態等.每個參數有自己的閾值,不同設備的電壓、電流閾值不相同,閾值范圍內短期變化劇烈或者長時間不變化均為異常,同一設備的電流、電壓、開關機標志位之間有相關性約束.
(3)載荷與實驗控制異常
各載荷(包括量子密鑰通信機、量子糾纏發射機、量子糾纏源、高速相干通信機、載荷溫控儀、實驗控制機)的所有組成部分(例如通信板、實驗板、存儲板、電源板、相機等)的工程參數,包括各種溫度、復位計數、工作模式、看門狗屏蔽有效性、極化檢測光開關狀態、極化檢測光檔位、泵浦光驅動主備狀態、PPS 秒脈沖檢測狀態、各類遙測總線標識、數傳數據處理狀態、各類電阻、功率、事件表的各類事件數、軟件狀態、接收/發送幀計數、載荷指令的各類計數、隨機數模式、密鑰輸出狀態、量子通信狀態、隱形測量狀態、各類測量狀態、GPS 狀態、GPS 各方向計算角度、粗跟蹤狀態與角度、精跟蹤狀態與角度、同步光觸發狀態、各方向轉速、各類單光子計數、各類符合計數、存儲容量、存儲壞塊數、存儲錯誤數、各相機的視場與質心、增益、校正、背景等.
每個參數有自己的閾值設置,閾值范圍內短時間劇烈變化或者長時間固定不動均為異常.部分參數之間有相關性約束,例如開關機不同狀態下,溫度、電阻有所不同;不同的工作模式下,各種觸發狀態與測量狀態有所不同.
(4)星務異常
衛星平臺的星務分系統的工程參數,包括主控CPU 標志、星務模式、星務狀態、采集模式、采集狀態、遙控模式、遙控狀態、遙測模式、遙測狀態、軌道模式、軌道狀態、姿控模式、姿控狀態、載荷模式、載荷狀態、軟件系統運行模式、進程加載狀態等.
(5)數傳通信異常
衛星平臺的數傳分系統的工程參數,包括Flash 壞塊計數、Flash 存儲錯誤計數、Flash 擦除錯誤計數、數傳CPU復位計數、EDAC 糾錯計數、數傳EEPROM校驗和等.對于某些異常計數類的參數,閾值內如果發生加1 則為異常,不變化或者一定時間后自動清零均為正常.對于某些計數,只要大于0 即為異常.有的參數為固定取值,一旦出現其他取值即為異常.部分參數之間有相關性約束.
(6)測控與姿控異常
衛星平臺的測控、姿控、熱控分系統的工程參數,包括單機狀態、姿控模式、角度、角速度、軌道GPS、軌道速度、熱敏及電阻溫度等.
2.2 異常檢測流程
通過實驗找到合適的擬合函數,在訓練得出基于工程數據的分類模型之后,便可以使用模型對新接收到的工程數據進行分析判斷.正常工程數據預示著衛星有較低的異常風險,用標簽“0”標注;異常工程數據預示著衛星有較高的異常風險,用標簽“1”標注.那么可以將異常識別轉化為一個分類問題.檢測分類的結果可以為衛星及載荷的異常及時發現與處置干預提供有力的支持.
GBDT是一種串聯式模型,每一層具有低方差高偏差特性,結合后形成方差和偏差的調和,使用CART回歸樹模型,基于前向分布算法進行迭代計算.基本思想是在損失函數負梯度的方向上生成若干棵弱回歸樹,將這些樹組合在一起生成一棵強回歸樹,即最終的異常檢測模型.模型檢測的時候,對于輸入的一個樣本實例,首先會賦予一個初值,然后會迭代遍歷每一棵決策樹,每棵樹都會對預測值進行調整修正,最后得到預測的結果.
在迭代過程中,假設前一輪迭代得到的強學習器是ft-1(x),損失函數是L(y,ft-1(x)),本輪迭代的目標是找到一個CART 回歸樹模型的弱學習器ht(x),使本輪的損失L(y,ft(x))=L(y,ft-1(x)+ht(x)) 最小.也就是說,本輪迭代找到決策樹要讓樣本的損失盡量變得更小.
依據機器學習的“數據處理-模型訓練-模型評估”標準流程,結合GBDT 算法特性,依據衛星工程參數特征與異常分布情況,設計了基于GBDT的衛星工程參數異常檢測流程,如圖1所示.首先選擇量子科學實驗衛星的工程數據的樣本數據,并對其進行預處理,整合形成3 類樣本數據,將離散變量轉為one-hot 編碼.之后,構造出訓練集與測試集,如果已有數據已經覆蓋所有異常類型,則采取分層采樣的方法獲得訓練集;如果已有數據未覆蓋所有異常類型,需要為訓練集插入人造的異常數據,保證異常特征的覆蓋性.然后確定損失函數和算法模型評價指標,利用訓練集經過多輪弱決策樹的遍歷迭代生成強決策樹,獲得GBDT 衛星及載荷工程參數異常檢測模型.最后利用該模型對測試集進行檢測,發現異常并識別異常類型,再對檢測結果進行評價,輸出評價指標供驗證分析.
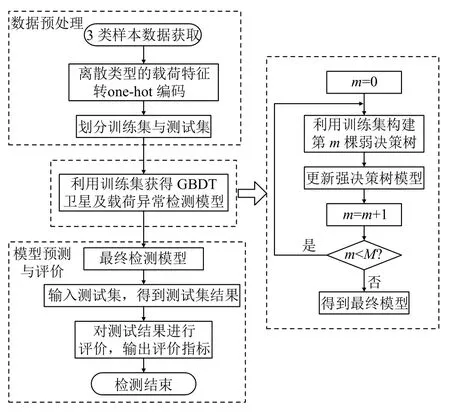
圖1 基于GBDT的衛星工程參數異常檢測流程圖
(1)數據預處理
分類器往往默認數據是連續并且有序的.如果簡單按照數字特征處理,那么GBDT 樹學到的是一段一段的值域劃分規則.而屬性離散數據值并不是有序的,而是隨機分配的.本模型中,將離散變量轉為onehot 編碼,可解決分類器不好處理屬性數據的問題,同時在一定程度上也起到了擴充特征的作用.
衛星工程參數數據有很多屬性特征采用了多位數字編碼,如“終端A 機數據狀態”這個特征有初態、發送、空閑、上行4 種狀態,原本使用0、1、2、3 表示,使用one-hot 編碼表示為1000、0100、0010、0001,每種狀態擴充為4 種特征來表示,為后續實驗中使用交叉熵損失函數奠定了基礎.
(2)特征參數的選取與優化
在使用衛星參數進行訓練建模的環節中,對于每一類數據,使用網格搜索尋找最優參數,調節的參數包括學習率learning_rate、集成的樹的數目n_estimators、每棵樹的最大深度max_depth 等,需要聯合調參以獲得最優性能.為了減少由網格搜索帶來的偶然性因素的影響,采用K折交叉驗證法來更加準確有效地評估該模型的泛化能力.經過測試優化,設置K值為10,將數據集分成10 等份,使用其中9 份數據作為訓練數據,另外1 份數據作為測試數據,進行模型的訓練,使用準確率作為度量測度來衡量模型的預測性能,對10 個驗證結果取平均.學習率的搜索范圍為{0.1,0.05,0.01},n_estimators的搜索范圍為{5,10,20,50,100},max_depth的搜索范圍為{3,5,10}.
(3)損失函數的選取
損失函數可以有多種選擇,比如平方損失函數、指數損失函數等,其中交叉熵損失函數是分類問題的首選,因為在分類問題上,樣本輸出不是連續的值,而是離散的類別,導致我們無法直接從輸出類別去擬合類別輸出的誤差,而最小化交叉熵實際上等價于極大似然估計,交叉熵損失函數更容易收斂到泛化能力強的地方.它將多種類型的異常轉化為多個二分類問題的聯合,針對第i 類異常,標簽為y,模型輸出的概率為p,交叉熵損失函數可以表示如下:
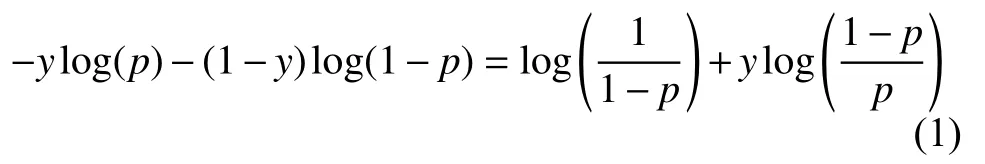

綜上,二分類損失函數為:

3 實驗驗證與分析
在量子科學實驗衛星任務中原本采用的是“閾值+規則表達式”的衛星異常檢測方法,本文對基于GBDT的衛星異常檢測方法與原傳統方法二者進行了檢測準確率和檢測效率方面的比較.實驗所用數據資源由國家科技資源共享服務平臺-國家空間科學數據中心提供,計算資源由中國科學院國家空間科學中心公共技術服務中心提供.
3.1 實驗數據
本文選取了量子科學實驗衛星的3 大類工程數據,合并組織為3 類文件作為實驗對象,分別為載荷及實驗控制機工程參數(1 類樣本)、星務/測控/姿控分系統工程參數(2 類樣本)和數傳通信分系統工程參數(3 類樣本),每一類樣本數據可能存在多種異常.
樣本數覆蓋衛星在軌運行期間的兩年時間,從2017年1月1日到2018年12月31日.一個文件包含一天內的數據樣本,每個樣本包含幾百個參數.不同文件的采樣率為1 s 到幾秒不等,所以每個文件的樣本數在到幾千個到86 400 個之間,3 類文件總計樣本接近八千萬(8e+7)條數據,詳情如表1所示.

表1 實驗數據說明表
3.2 各樣本種類的檢測準確率
依據模型輸出結果,3 類樣本的平均準確率(AP,average precision),即該類樣本中分類正確的樣本占全部樣本的比例如下:
AP (1 類樣本)=98.11%
AP (2 類樣本)=98.15%
AP (3 類樣本)=99.62%
對于同一批實驗樣本,使用“閾值+規則表達式”的異常檢測方法進行處理,平均準確率分別為:96.48%,96.93%,94.87%,如圖2所示.
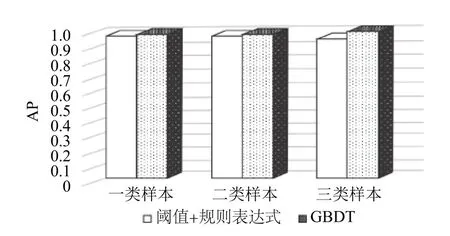
圖2 兩種異常檢測方法的平均準確率比較
可見,基于GBDT的衛星異常檢測方法可提升平均準確率約兩個百分點,達到98%以上.
3.3 各異常種類的檢測準確率
在具體的3 類樣本中,針對各異常類型繪制其P-R(Precision-Recall)曲線并計算平均準確率(AP),以評價模型的分類檢測效果.
P-R 曲線刻畫精確率(Precision,即查準率)和召回率(Recall,即查全率)之間的關系,精確率是在所有預測為正例的數據中,真正例所占的比例,召回率是預測為真正例的數據占所有正例數據的比例,將判斷閾值從0 逐漸調節至1,即得到P-R 曲線.圖3所示為本實驗的第1 類樣本中3 類異常各自的P-R 曲線,x軸為召回率,y軸為精確率.

圖3 第一類樣本中的3 類異常的P-R 曲線
針對各類樣本,計算每一類異常的AP,可以衡量GBDT 學習得到的模型對每個類別的分類能力,對所有類別異常的AP 取平均值得到mAP (mean average precision),可以衡量模型對所有類別的分類能力.
本實驗的3 類樣本中各異常類型的AP 及mAP結果如表2所示,可見本模型對于不同的異常種類的檢測效果都是非常好的.
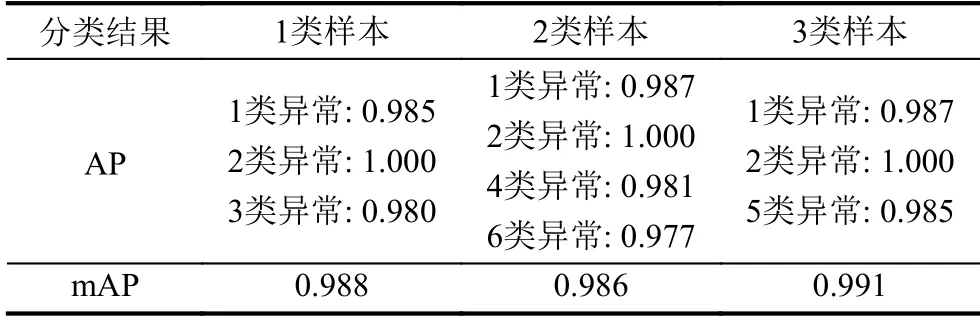
表2 分類檢測效果評價表
3.4 檢測效率
在空間科學衛星任務中,異常檢測是在每次數傳站接收數據之后進行的,也就是針對每一軌接收的數據進行一次檢測,本文針對單軌接收數據進行了檢測性能比對.算法的運行環境為PC 單機,Windows 7 操作系統,Intel i5 處理器@2.6 GHz,8 GB 內存.“閾值+規則表達式”的檢測方法與GBDT的運行時間,如圖4所示.
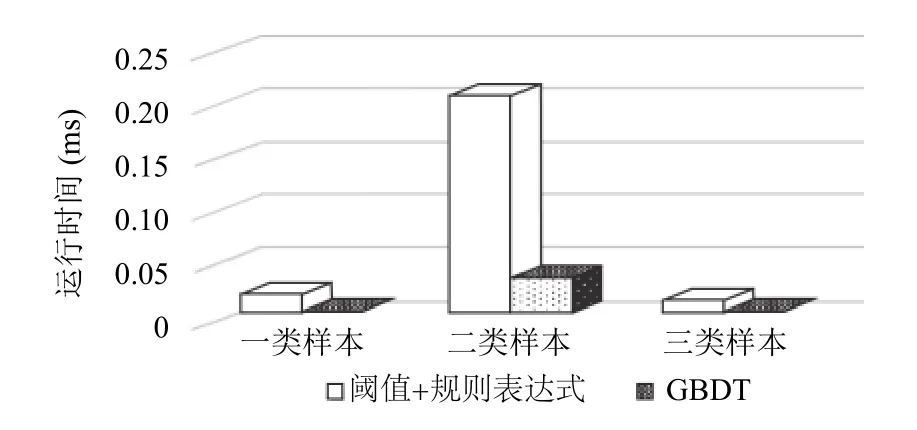
圖4 兩種異常檢測方法的運行時間比較
使用基于GBDT的衛星工程參數異常檢測方法,單軌接收的3 類樣本的異常檢測消耗時間分別為2.3 ms、38.6 ms、1.4 ms.使用原本的“閾值+規則表達式”的衛星異常檢測方法,單軌接收的3 類樣本的異常檢測消耗時間分別為17.6 ms、219.5 ms、11.0 ms.可見,采用基于GBDT的衛星異常檢測方法使檢測速度有了平均6 倍以上的提升.
此外,與深度網絡這些計算密集型算法相比,基于GBDT的衛星工程參數異常檢測方法對運行內存等計算資源需求很小,甚至可以在星載FPGA (field programmable gate array)上使用,未來可以探討放到衛星上面執行,以支持在星上開展實時的工程數據異常分析與數據壓縮下行.
4 結論與展望
基于GBDT的衛星異常檢測方法將多種類型的衛星異常轉化為多個二分類問題的聯合,不僅能正確區分正常與異常兩種狀態的數據,而且能夠準確識別異常類型.在特征參數的選取與優化過程中采用交叉驗證的方式來減少偶然性,避免了陷入局部極小值的問題.通過對量子科學實驗衛星在軌運行兩年的真實工程數據進行驗證,與衛星任務中原本采用的“閾值+規則表達式”異常檢測方法相比,基于GBDT的衛星異常檢測方法將平均準確率提升了約兩個百分點,達到98%以上,并將檢測速度提升了大約6 倍,可以更為高效、快速地開展衛星異常檢測工作,在空間科學衛星任務中產生了較大的應用價值.目前的實驗驗證只覆蓋了主要的異常類型,后續工作中可針對其它異常類型進行擴展和細化,以達到更好的異常分類檢測效果,并擴展應用到其他衛星的異常檢測中.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
太空探索(2016年6期)2016-07-10 12:09:06
海峽科技與產業(2016年3期)2016-05-17 04:32:12
筑路機械與施工機械化(2015年11期)2015-07-01 16:28:43
