基于視觸數(shù)據(jù)融合的多模態(tài)細(xì)分類系統(tǒng)
2022-02-13 11:53:04郭睿華宋俊鵬王文旭楊琨
科學(xué)技術(shù)與工程 2022年36期
郭睿華, 宋俊鵬, 王文旭, 楊琨
(太原理工大學(xué)信息與計(jì)算機(jī)學(xué)院, 晉中030600)
隨著全自動(dòng)化時(shí)代的到來(lái),機(jī)械臂已被應(yīng)用到越來(lái)越多的場(chǎng)景,如航天、深潛、工業(yè)以及殘障輔助等諸多領(lǐng)域[1-4]。在這些場(chǎng)景中,機(jī)械臂幫人們節(jié)省了大量的人力資源成本。但同時(shí),人們對(duì)機(jī)械臂的要求也日益提高。
眾多研究者基于機(jī)械臂的物體分揀開展研究。視覺技術(shù)結(jié)合機(jī)械臂的發(fā)展已經(jīng)趨向于成熟,并在物體分類領(lǐng)域中已經(jīng)有了非常不錯(cuò)的表現(xiàn),將機(jī)器視覺技術(shù)應(yīng)用于分揀領(lǐng)域可減少人工分揀工作量、降低分揀差錯(cuò)率,極大地提升工業(yè)生產(chǎn)效率,實(shí)現(xiàn)分揀作業(yè)的自動(dòng)化和智能化[5]。Cheng等[6]針對(duì)傳統(tǒng)的圖像分類方法在工業(yè)環(huán)境中照明不均勻且存在遮擋的條件下表現(xiàn)不佳的問(wèn)題設(shè)計(jì)了隨機(jī)裁剪集成神經(jīng)網(wǎng)絡(luò)(resource constrained edge-neural networks, RCE-NN),該網(wǎng)絡(luò)對(duì)于具有重疊部分的圖像,將集成學(xué)習(xí)與隨機(jī)裁剪相結(jié)合,最終在十類包括顏色相同但輪廓不同、以及不同顏色、形狀和紋理的物體組成的數(shù)據(jù)集下進(jìn)行了測(cè)試,分類準(zhǔn)確率達(dá)到98.14%;Harel等[7]為實(shí)現(xiàn)機(jī)械臂在采摘過(guò)程中對(duì)甜椒成熟度進(jìn)行分類,使用隨機(jī)森林算法處理相機(jī)從多視點(diǎn)采集的甜椒的RGB-D圖像,并在不同成熟度的紅辣椒和黃辣椒上進(jìn)行測(cè)試,分類準(zhǔn)確率達(dá)到95%;Kaymak等[8]為使用四自由度樹莓派機(jī)械手加相機(jī)完成對(duì)工作平臺(tái)上的物體的分類,使用不同的局部特征匹配算法進(jìn)行組合,最終使用尺度不變特征轉(zhuǎn)換(scale invariant feature transform, SIFT)+SIFT的組合匹配算法對(duì)20個(gè)物體進(jìn)行了測(cè)試,分類準(zhǔn)確率達(dá)到了97%。Liong等[9]為了實(shí)現(xiàn)對(duì)特定類型小牛皮上的蜱咬缺陷進(jìn)行識(shí)別,提出了一種執(zhí)行皮革缺陷分類的自動(dòng)機(jī)制,該機(jī)制通過(guò)手工制作邊緣檢測(cè)器和人工神經(jīng)網(wǎng)絡(luò)通過(guò)多個(gè)分類器(即決策樹、支持向量機(jī)、最近鄰分類器和集合分類器)對(duì)皮革上的缺陷進(jìn)行識(shí)別,最終在2 500塊400×400的皮革樣片中獲得了84%的分類準(zhǔn)確率。但單一視覺的機(jī)械臂系統(tǒng)仍然存在著缺陷,這種系統(tǒng)過(guò)度的依賴于工作環(huán)境的光線強(qiáng)度,以及對(duì)于一些外觀相近但實(shí)則分屬不同的物體缺乏感知能力。
Fishel等[10]使用BioTac傳感器對(duì)117種不同的材料進(jìn)行分類,在具有精確控制接觸力和牽引力的測(cè)試臺(tái)設(shè)置中,針對(duì)牽引力,粗糙度和細(xì)度3個(gè)特征使用貝葉斯分類,準(zhǔn)確率為達(dá)到了95.4%;Xu等[11]使用安裝在Shadow Hand上的BioTac基于貝葉斯探索框架執(zhí)行多個(gè)探索運(yùn)動(dòng),針對(duì)10種不同的材料可以達(dá)到99%的分類精度;Omarali等[12]為了實(shí)現(xiàn)遠(yuǎn)程操作材料觸覺分類,使用基于光纖的觸覺和接近傳感器的遠(yuǎn)程控制機(jī)器人操縱器來(lái)掃描遠(yuǎn)程環(huán)境中物體的表面,并采用隨機(jī)森林、卷積神經(jīng)和多模態(tài)卷積神經(jīng)網(wǎng)絡(luò)等機(jī)器學(xué)習(xí)技術(shù)進(jìn)行材料分類,最后在5種不同材料上進(jìn)行了測(cè)試,分類精度達(dá)到了90%;Zhang等[13]為了用安裝觸覺傳感器的機(jī)械手實(shí)現(xiàn)對(duì)目標(biāo)的準(zhǔn)確分類,提出了一種新的模型,即將卷積神經(jīng)網(wǎng)絡(luò)和殘差網(wǎng)絡(luò)相結(jié)合,并優(yōu)化了模型的卷積核、超參數(shù)和損失函數(shù)通過(guò)K均值聚類方法進(jìn)一步提高目標(biāo)分類的準(zhǔn)確性,最終將分類效果最佳的目標(biāo)的準(zhǔn)確率提高到80.098%,將分類結(jié)果較好的3個(gè)類的準(zhǔn)確率提高到92.72%。僅憑觸覺實(shí)現(xiàn)對(duì)物體的分類面臨著諸如傳感器成本高,特征提取不全面等問(wèn)題,從而存在著一定的局限性。
由此可見,實(shí)現(xiàn)一個(gè)具有優(yōu)良性能的機(jī)械臂分揀系統(tǒng)顯然不是一個(gè)輕松的工作。復(fù)雜的工作環(huán)境,各種各樣的物品對(duì)于這項(xiàng)工作都是巨大的挑戰(zhàn)。單一感官的機(jī)械臂分揀系統(tǒng)總是存在著各種各樣的局限性,并不能勝任復(fù)雜的分類環(huán)境。因此研究者開展了多傳感信息融合的相關(guān)研究。Watkins-Valls等[14]研究了機(jī)械臂在光線不足且物體存在部分遮擋的環(huán)境下的機(jī)械臂分類任務(wù),通過(guò)構(gòu)建三維卷積神經(jīng)網(wǎng)絡(luò)融合視覺與觸覺信息對(duì)10個(gè)具有不同幾何形狀的物體進(jìn)行分類,分類準(zhǔn)確率達(dá)到95%比單一視覺的分類準(zhǔn)確率提高了25%。Wang等[15]為了使機(jī)械臂能夠識(shí)別3D物體的形狀,提出了一種3D感知的新模型,該模型綜合物體的視覺觸覺信息,在對(duì)14種不同物體的測(cè)試中,物體形狀3D復(fù)現(xiàn)的匹配準(zhǔn)確率達(dá)到了91%。但這些研究都比較側(cè)重于對(duì)物體形狀的識(shí)別,觸覺信息則作為視覺分析的輔助數(shù)據(jù),當(dāng)環(huán)境中出現(xiàn)外觀相似但材質(zhì)不同的物體時(shí)分類工作則會(huì)面臨巨大的挑戰(zhàn)。
為此,提出一種基于視覺-觸覺數(shù)據(jù)融合的機(jī)械臂細(xì)分類系統(tǒng)。系統(tǒng)通過(guò)OpenCV進(jìn)行目標(biāo)定位并通過(guò)快速搜索隨機(jī)樹(rapid-exploration random tree,RRT)路徑規(guī)劃算法實(shí)現(xiàn)對(duì)物體的抓取進(jìn)而獲取觸覺信息,利用雙輸入的卷積神經(jīng)網(wǎng)絡(luò)將兩類不同種類的數(shù)據(jù)分別提取特征,最后在連接層進(jìn)行融合,完成綜合物體視覺觸覺信息的分類任務(wù)。
1 系統(tǒng)構(gòu)成
搭建系統(tǒng)開展算法驗(yàn)證。系統(tǒng)采用Kinova公司生產(chǎn)的JACO系列機(jī)械臂完成運(yùn)動(dòng)及抓取功能,同時(shí)依靠深度相機(jī)及壓敏傳感器實(shí)現(xiàn)目標(biāo)的定位及觸覺感知。系統(tǒng)結(jié)構(gòu)如圖1所示。
JACO2-j2n6s200機(jī)械臂具有6個(gè)自由度,本體重量4.4 kg,負(fù)載能力為2.6 kg,最大臂展為984 mm,平均功耗為25 W。機(jī)械臂末端抓手為2指,抓手總重量為556 g,每個(gè)抓手都安裝一個(gè)執(zhí)行器,其抓取力為25 N,抓手打開或關(guān)閉的行程時(shí)間為1.2 s。
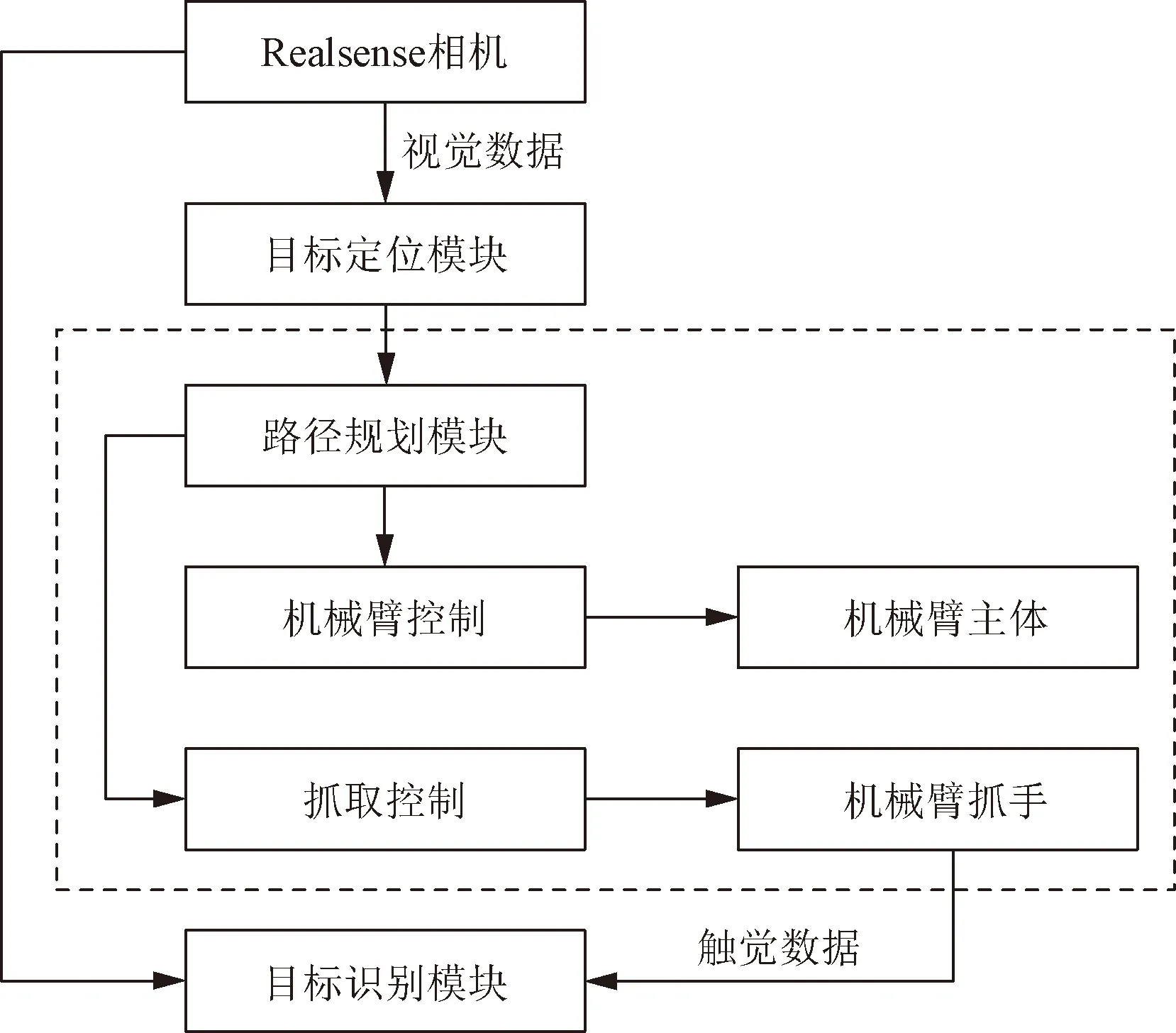
圖1 系統(tǒng)結(jié)構(gòu)圖Fig.1 System structure diagram
視覺模塊相機(jī)使用的是Intel RealSense Depth Camera D435i深度相機(jī),相機(jī)被固定于機(jī)械臂的側(cè)上方用于獲取目標(biāo)的距離信息以及獲取用于模型預(yù)測(cè)的輸入圖像;物體定位模塊使用OpenCV現(xiàn)對(duì)物體的目標(biāo)檢測(cè)和目標(biāo)定位;運(yùn)動(dòng)規(guī)劃模塊分為兩部分,一部分完成機(jī)械臂主體的運(yùn)動(dòng)規(guī)劃,另一部分完成機(jī)械臂抓手的運(yùn)動(dòng)規(guī)劃,采用機(jī)器人操作系統(tǒng) (robot operating system, ROS)運(yùn)動(dòng)規(guī)劃庫(kù)結(jié)合目標(biāo)檢測(cè)的位置信息控制機(jī)械臂到達(dá)目標(biāo)位置并進(jìn)行抓取。
觸覺模塊將RP-C10-LT壓敏傳感器粘貼于機(jī)械臂手指用于獲取抓取物體時(shí)的壓力數(shù)據(jù),RP-C電阻式壓敏傳感器具有靜態(tài)/動(dòng)態(tài)壓力感應(yīng)特性,響應(yīng)速度快,耐久性壽命長(zhǎng)等優(yōu)點(diǎn),隨著壓力增大,電阻呈現(xiàn)變小的趨勢(shì)。整個(gè)實(shí)驗(yàn)系統(tǒng)場(chǎng)景設(shè)置如圖2所示。

圖2 實(shí)驗(yàn)場(chǎng)景示意圖Fig.2 Overview of the experimental scene
2 機(jī)械臂目標(biāo)定位與數(shù)據(jù)采集
2.1 目標(biāo)定位
機(jī)械臂在運(yùn)動(dòng)時(shí),需要依據(jù)視覺信息進(jìn)行目標(biāo)的定位,將相機(jī)坐標(biāo)系下的物體轉(zhuǎn)換到機(jī)械臂自身的坐標(biāo)系下就顯得尤為重要,相機(jī)與機(jī)械臂的結(jié)合有兩種形式,一種為相機(jī)安裝于機(jī)械臂上,一種為相機(jī)在機(jī)械臂外,為了獲得更好的全局視野,采用相機(jī)固定在機(jī)械臂的外部(上方)的方式,如圖3所示。

B為基底;E為末端執(zhí)行器;P為標(biāo)定靶;C為相機(jī)圖3 相機(jī)標(biāo)定示意圖Fig.3 Schematic diagram of camera calibration
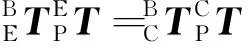
(1)
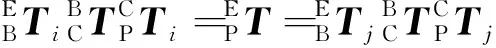
(2)
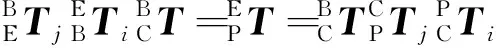
(3)
RARX=RXRD
(4)
RAtX+tA=RXtD+tX
(5)
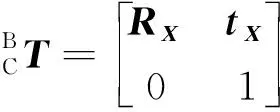
(6)
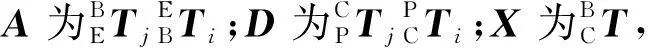
獲取物體圖像后,使用Canny邊緣檢測(cè)算子將相機(jī)捕獲到的圖像進(jìn)行邊緣處理,并尋找到物體在像素坐標(biāo)系下的中心點(diǎn),如圖4所示。
根據(jù)式(6),像素坐標(biāo)系與相機(jī)坐標(biāo)系的轉(zhuǎn)換關(guān)系可以得到物體在相機(jī)坐標(biāo)系下的位置CQ。
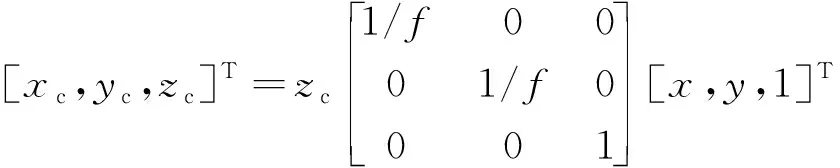
(7)
式(6)中:(x,y)為中心點(diǎn)的像素坐標(biāo);CQ(xc,yc,zc)為相機(jī)坐標(biāo)系下的坐標(biāo);zc為深度值;f為相機(jī)的焦距。
由此獲得物體中心在機(jī)械臂坐標(biāo)系下的坐標(biāo)BQ為
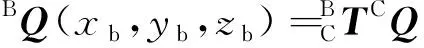
(8)

B為基底;E為末端執(zhí)行器;P為標(biāo)定靶;C為相機(jī)圖4 提取圖像的輪廓與中心點(diǎn)Fig.4 Extract the contour and center point of the image
2.2 機(jī)械臂運(yùn)動(dòng)規(guī)劃
抓取物體時(shí)為增加抓取的穩(wěn)定性,統(tǒng)一按照?qǐng)D5所示從物體上方進(jìn)行抓取。
過(guò)程中使用增加了概率導(dǎo)向的RRT算法進(jìn)行路徑規(guī)劃使機(jī)械臂運(yùn)動(dòng)到抓取點(diǎn)。相比于傳統(tǒng)的RRT算法,增加了概率導(dǎo)向的RRT算法在路徑尋找過(guò)程中的收斂速度更快。算法的偽代碼如下。其中,M為機(jī)械臂工作的空間邊界(包含障礙物位置信息),Ei為從qnear到qnew的連接邊。

圖5 機(jī)械臂抓取物體Fig.5 Robotic arm grabs objects

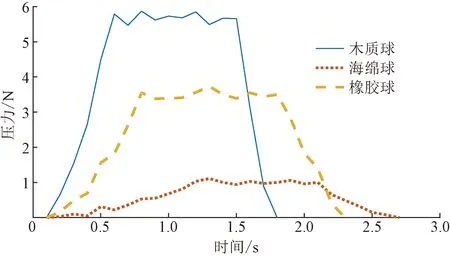
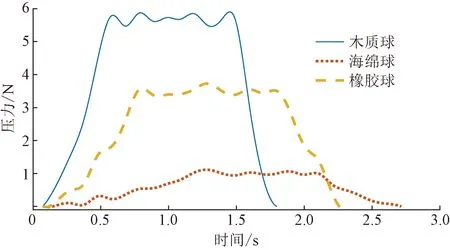
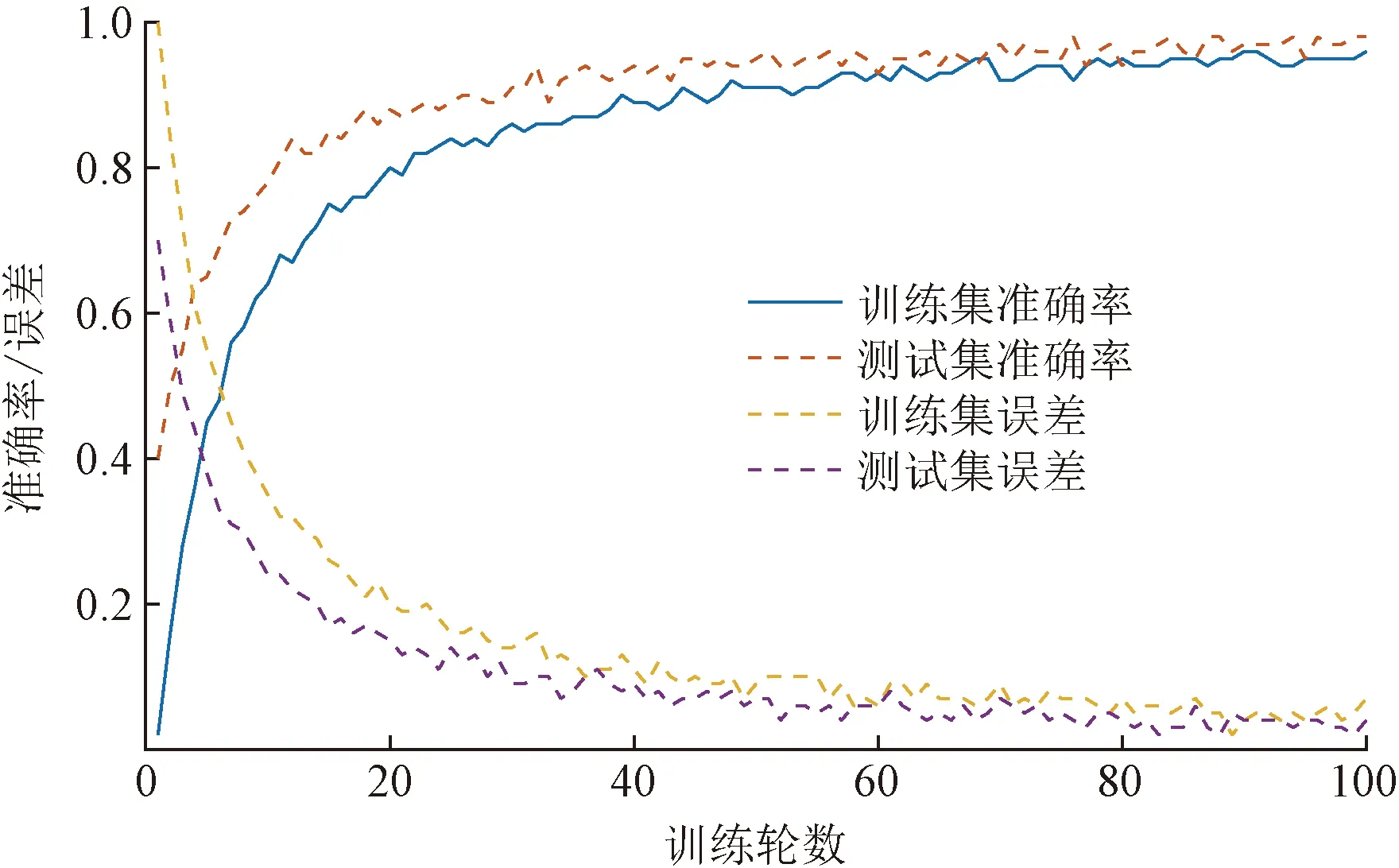
RRT-P(M, qinit, qgoal)1 T = {?};i=0;2 while (i 算法輸入為工作空間M,機(jī)械臂起始狀態(tài)qinit、機(jī)械臂目標(biāo)狀態(tài)qgoal。首先初始化路徑T,?為空集;i為循環(huán)變量;N為算法終止門限值。采用ChooseTarget函數(shù)從起始狀態(tài)開始依據(jù)概率P選擇下一組機(jī)械臂關(guān)節(jié)狀態(tài)qrand是朝向目標(biāo)狀態(tài)還是隨機(jī);運(yùn)用Near函數(shù)從路徑中選取最接近qrand的一點(diǎn)qnear;在Steer函數(shù)中,依據(jù)StepSize,向qrand進(jìn)行移動(dòng)得到新的一組關(guān)節(jié)狀態(tài)qnew;使用Edge函數(shù)建立qnear到qnew的連接邊Eedges;通過(guò)CollisionFree函數(shù)檢測(cè)是否與環(huán)境發(fā)生碰撞,如果不發(fā)生碰撞則通過(guò)addNode和addEdge兩個(gè)函數(shù)把qnew和Eedges加入路徑集合T中。最后,通過(guò)AreaDectect函數(shù)檢測(cè)qnew是否到達(dá)了qgoal的附近,誤差區(qū)間半徑為ε,如果返回TRUE則返回整條路徑。采用ROS中的Rviz軟件進(jìn)行運(yùn)動(dòng)規(guī)劃過(guò)程中各關(guān)節(jié)角度與角速度變化。 將壓敏傳感器集成于機(jī)械臂手爪上采集對(duì)不同物體抓取過(guò)程中的力的變化,采樣頻率為10 Hz。機(jī)械臂到達(dá)抓取點(diǎn)后開始記錄壓力數(shù)值,為使數(shù)據(jù)具有范圍統(tǒng)一性,對(duì)物體進(jìn)行恒速抓握,抓住物體后保持一秒間隔,然后松開。一次抓取中木質(zhì)球,橡膠球,海綿球的典型壓力曲線如圖6所示。 為使圖像更加平滑使用3次樣條插值算法對(duì)壓力曲線進(jìn)行平滑處理,在每?jī)蓚€(gè)采樣點(diǎn)中插入10個(gè)點(diǎn)。平滑后的曲線如圖7所示。 圖6 不同物品的抓取壓力曲線Fig.6 Grasping pressure curves of different objects 圖7 經(jīng)平滑處理的壓力曲線Fig.7 Smoothed rasping pressure curves 針對(duì)視覺數(shù)據(jù)與壓力圖像數(shù)據(jù)的特點(diǎn)設(shè)計(jì)了具有雙輸入的卷積神經(jīng)網(wǎng)絡(luò)模型,先對(duì)兩類數(shù)據(jù)分別進(jìn)行特征提取,然后通過(guò)全連接層進(jìn)行連接進(jìn)行同步學(xué)習(xí),視覺觸覺融合神經(jīng)網(wǎng)絡(luò)模型如圖8所示。 視覺圖像處理共包含4層卷積層與4層池化層,并在卷積層與池化層中間加入標(biāo)準(zhǔn)歸一化層。卷積層的主要作用為提取輸入視覺圖像數(shù)據(jù)的特征信息,池化層采用最大池化主要作用為降低上層輸入數(shù)據(jù)的數(shù)據(jù)規(guī)模以便于在最后用全連接層進(jìn)行處理。 (1)輸入層。輸入圖像為經(jīng)過(guò)處理的224×224×3 的RGB圖像。 (2)視覺模型第1層。用16個(gè)大小為3×3的卷積核對(duì)RGB圖像進(jìn)行same卷積,卷積后的特征矩陣大小為224×224×16,卷積完成后進(jìn)行標(biāo)準(zhǔn)歸一化處理并使用ReLU函數(shù)激活,然后進(jìn)行2×2的最大池化,步長(zhǎng)為2。池化后的特征矩陣大小為112×112×16。 Conv2d為二維卷積;ReLU為激活函數(shù); MaxPooling為最大值池化; Flatten為展平; Fc為全連接; Output為輸出圖8 視覺觸覺融合神經(jīng)網(wǎng)絡(luò)模型Fig.8 Visual and haptic fusion neural network model (3)第2層。用16個(gè)大小為3×3的卷積核對(duì)第1層傳入的112×112×16的特征矩陣進(jìn)行same卷積,卷積后的特征矩陣大小為112×112×16,卷積完成后進(jìn)行標(biāo)準(zhǔn)歸一化處理并使用ReLU函數(shù)激活,然后進(jìn)行2×2的最大池化,步長(zhǎng)為2。池化后的特征矩陣大小為56×56×16。 (4)第3層。用32個(gè)大小為3×3的卷積核對(duì)第2層傳入的56×56×16的特征矩陣進(jìn)行same卷積,卷積后的特征矩陣大小為56×56×32,卷積完成后進(jìn)行標(biāo)準(zhǔn)歸一化處理并使用ReLU函數(shù)激活,然后進(jìn)行2×2的最大池化,步長(zhǎng)為2。池化后的特征矩陣大小為28×28×32。 (5)第4層。用32個(gè)大小為3×3的卷積核對(duì)第3層傳入的28×28×32的特征矩陣進(jìn)行same卷積,卷積后的特征矩陣大小為28×28×32,卷積完成后進(jìn)行標(biāo)準(zhǔn)歸一化處理并使用ReLU函數(shù)激活,然后進(jìn)行2×2的最大池化,步長(zhǎng)為2。池化后的特征矩陣大小為14×14×32。 將卷積完成的14×14×32視覺特征矩陣展平為大小為1×6 272的特征向量。 觸覺圖像處理共有4層卷積層與4層池化層,并在卷積層與池化層中間加入標(biāo)準(zhǔn)歸一化層。卷積層的主要作用為提取觸覺圖像輸入數(shù)據(jù)的特征信息,池化層采用最大池化主要作用為降低上層輸入數(shù)據(jù)的數(shù)據(jù)規(guī)模以便于在最后用全連接層進(jìn)行處理。 (1)輸入層:輸入圖像為經(jīng)過(guò)處理的64×64的灰度圖像。 (2)視覺模型第1層。用8個(gè)大小為3×3的卷積核對(duì)灰度圖像進(jìn)行same卷積,卷積后的特征矩陣大小為64×64×8,卷積完成后進(jìn)行標(biāo)準(zhǔn)歸一化處理并使用ReLU函數(shù)激活,然后進(jìn)行2×2的最大池化,步長(zhǎng)為2。池化后的特征矩陣大小為32×32×16。 (3)第2層。用8個(gè)大小為3×3的卷積核對(duì)第1層傳入的32×32×16的特征矩陣進(jìn)行same卷積,卷積后的特征矩陣大小為32×32×16,卷積完成后進(jìn)行標(biāo)準(zhǔn)歸一化處理并使用ReLU函數(shù)激活,然后進(jìn)行2×2的最大池化,步長(zhǎng)為2。池化后的特征矩陣大小為16×16×16。 (4)第3層。用16個(gè)大小為3×3的卷積核對(duì)第2層傳入的16×16×16的特征矩陣進(jìn)行same卷積,卷積后的特征矩陣大小為16×16×16,卷積完成后進(jìn)行標(biāo)準(zhǔn)歸一化處理并使用ReLU函數(shù)激活,然后進(jìn)行2×2的最大池化,步長(zhǎng)為2。池化后的特征矩陣大小為8×8×16。 (5)視覺模型第4層。用16個(gè)大小為3×3的卷積核對(duì)第3層傳入的8×8×16的特征矩陣進(jìn)行same卷積,卷積后的特征矩陣大小為8×8×16,卷積完成后進(jìn)行標(biāo)準(zhǔn)歸一化處理并使用ReLU函數(shù)激活,然后進(jìn)行2×2的最大池化,步長(zhǎng)為2。池化后的特征矩陣大小為4×4×16。 將卷積完成的大小為4×4×16的觸覺特征矩陣展平為大小為1×256的特征向量。 將分別提取到的特征向量進(jìn)行拼接組成大小為(6 272+256=6 528)的視覺觸覺特征向量輸入第一層全連接層,全連接層第1層由1 000個(gè)神經(jīng)元組成,使用ReLU進(jìn)行激活,全連接層第2層由50個(gè)神經(jīng)元組成,ReLU函數(shù)進(jìn)行激活,輸出層有21個(gè)神經(jīng)元組成代表要區(qū)分的21種物體,使用Softmax函數(shù)進(jìn)行激活。 實(shí)驗(yàn)所用待分類物體包含不同形狀(球形、正方體、長(zhǎng)方體、圓柱、半球、半圓柱和圓臺(tái))與不同材質(zhì)(木質(zhì),橡膠,海綿)的21種實(shí)心物體(木球、橡膠球、海綿球、木質(zhì)正方體塊、橡膠正方體塊、海綿正方體塊、木質(zhì)長(zhǎng)方體塊、橡膠長(zhǎng)方體塊、海綿長(zhǎng)方體塊、木質(zhì)半球、橡膠半球、海綿半球、木質(zhì)半圓柱、橡膠半圓柱、海綿半圓柱、木質(zhì)圓臺(tái)、橡膠圓臺(tái)和海綿圓臺(tái))各3個(gè)(不同顏色尺寸),共計(jì)實(shí)驗(yàn)物品63個(gè),其中44個(gè)用于采集數(shù)據(jù),剩余21個(gè)用于最后實(shí)際測(cè)試。對(duì)44個(gè)實(shí)驗(yàn)物體以不同角度(正上方、正面、正側(cè)面、正斜側(cè)面和側(cè)斜側(cè)面)、不同亮暗程度(采用夜間打光的方式,設(shè)置3個(gè)等級(jí),調(diào)節(jié)光源為100%、50%和20%)及不同遮擋(無(wú)遮擋以及30%遮擋)進(jìn)行拍照,將圖片的分辨率處理為224×224,由此組建成由3960張圖片組成原始數(shù)據(jù)集,再對(duì)原始圖片進(jìn)行翻轉(zhuǎn)、伸縮變換,最終組建成由7 920張圖片組成的視覺數(shù)據(jù)集。 使機(jī)械臂從不同角度進(jìn)行抓取,抓取過(guò)程中為勻速抓取并勻速釋放,每個(gè)物體抓取20次,最終構(gòu)建成由880個(gè)壓力圖像組成的原始數(shù)據(jù)集。 由于視覺圖像數(shù)據(jù)與觸覺數(shù)據(jù)并無(wú)強(qiáng)關(guān)聯(lián)性,因此采用在同材質(zhì)物體中隨機(jī)組合視覺數(shù)據(jù)與觸覺數(shù)據(jù),即對(duì)于同材質(zhì)物體的圖像隨機(jī)選擇兩個(gè)同材質(zhì)物體的壓力圖像構(gòu)成視覺觸覺數(shù)據(jù)對(duì),最終形成由15 840個(gè)數(shù)據(jù)對(duì)組成的視覺觸覺數(shù)據(jù)集。 為了驗(yàn)證本文模型在實(shí)際環(huán)境中的有效性,對(duì)模型進(jìn)行了訓(xùn)練以及調(diào)整優(yōu)化,所用電腦的配置信息如表1所示。 數(shù)據(jù)集按照1∶1∶6的比例分別劃分為測(cè)試集,驗(yàn)證集以及訓(xùn)練集。其中通過(guò)訓(xùn)練集與驗(yàn)證集訓(xùn)練獲得模型的參數(shù)并對(duì)模型的超參數(shù)進(jìn)行調(diào)整,測(cè)試集用來(lái)評(píng)估模型的真實(shí)有效性。經(jīng)過(guò)100輪訓(xùn)練后,最終獲得模型的訓(xùn)練集準(zhǔn)確率達(dá)到97.8%,測(cè)試集的準(zhǔn)確率達(dá)到98.5%。訓(xùn)練曲線如圖9所示。 為驗(yàn)證模型在此分類任務(wù)中的優(yōu)勢(shì),設(shè)置了兩個(gè)單一視覺卷積神經(jīng)網(wǎng)絡(luò)AlexNet與VGG16進(jìn)行了對(duì)比實(shí)驗(yàn),用相同的數(shù)據(jù)集各自進(jìn)行了100輪的訓(xùn)練。實(shí)驗(yàn)結(jié)果表明,兩種方法對(duì)于不同物品的檢測(cè)準(zhǔn)確率僅為62.8%和74.5%。例如,兩類網(wǎng)絡(luò)分別有47.5%和39.6%的概率把木質(zhì)玩具球識(shí)別成為橡膠彈力球。可見單一視覺在具有較多相似物體的分類場(chǎng)景中并不適用。 表1 模型訓(xùn)練設(shè)備參數(shù)Table 1 The parameters of the model training equipment 圖9 神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練曲線Fig.9 Neural network model training curve 針對(duì)基于視觸數(shù)據(jù)融合的多模態(tài)細(xì)分類系統(tǒng)進(jìn)行研究,得出如下結(jié)論。 (1)搭建了用于機(jī)械臂細(xì)分類的硬件模塊,包括機(jī)械臂的配置、深度相機(jī)標(biāo)定以及傳感器的部署;基于OpenCV與ROS系統(tǒng)進(jìn)行了目標(biāo)的定位以及路徑規(guī)劃。 (2)提出了一種有效的視覺觸覺卷積神經(jīng)網(wǎng)絡(luò)模型,使用較少層數(shù)的卷積層完成了數(shù)據(jù)的融合分類。并通過(guò)實(shí)驗(yàn)驗(yàn)證了在具有較多具有相似外觀不同材質(zhì)物體的工作環(huán)境下,分類準(zhǔn)確率達(dá)到98.5%,相較于傳統(tǒng)的單視覺模型準(zhǔn)確率有較大提升。 實(shí)驗(yàn)仍然存在可以改進(jìn)的地方,今后可以對(duì)傳感器的使用部署進(jìn)行優(yōu)化,并進(jìn)一步提升算法效能,使系統(tǒng)具有更好的普適性。2.3 觸覺數(shù)據(jù)采集
3 融合模型
3.1 視覺圖像處理

3.2 觸覺圖像處理
3.3 連接層
4 算法驗(yàn)證
4.1 數(shù)據(jù)準(zhǔn)備
4.2 算法對(duì)比

5 結(jié)論
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
當(dāng)代工人(2020年8期)2020-05-25 09:07:38
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小溪流(畫刊)(2017年12期)2018-01-10 16:07:29
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
科技知識(shí)動(dòng)漫(2016年8期)2016-07-29 20:40:09
