施工組織設計文檔智慧輔助審查中的文本分類問題研究
2022-02-13 11:53:28郭瀟楠王仁超毛三軍彭相國
科學技術與工程 2022年36期
郭瀟楠, 王仁超*, 毛三軍, 彭相國
(1.天津大學建筑工程學院, 天津 300354; 2.長江三峽技術經濟發展有限公司, 北京100043)
21世紀以來,以深度學習、大數據為核心的人工智能技術正推動傳統合同審查模式進行變革,人工智能技術已經廣泛應用于合同修改與審核業務當中。1987年,首次國際人工智能法律會議(ICAIL)在美國波士頓東北大學舉辦,會議討論了人工智能與法律的跨學科領域的研究和應用;1991年,國際人工智能與法律協會(IAAIL)正式成立,協會的主要議題包括法律文本自動分類、摘要自動生成等人工智能技術;2016年,IBM公司基于IBM沃森(Watson)智能電腦平臺研發了世界首個人工智能律師Ross,自此以后,法律自動化合規審查、合同審核不斷涌現。
施工組織設計是指導工程建設全過程活動的技術、經濟和組織的綜合性文件,其編制質量對于工程建設成本、質量、進度、安全具有重要的影響。工程建設不同階段,需要編制大量不同類型的施工組織設計文件,這些施組文件編制、審查是工程技術人員主要日常工作之一,提高施組文件的編制、審查效率和質量,對于提高工程建設管理水平具有重要的作用。
傳統的施組文件審查主要依靠具有一定經驗的技術負責人員人工審查,審查質量一方面取決于審查人員的經驗知識,另一方面,與審查人員的責任感、可利用時間以及手頭已有規范資料等有關。在時間倉促、資料有限情況下,難免對施組文件存在問題出現遺漏審查的情況。
近年來,隨著深度學習、大數據等人工智能技術,尤其是基于自然語言理解的文本分析、知識挖掘技術的發展,使得施工組織設計文檔智慧輔助審查成為可能。基于自然語言理解的文本分析、知識挖掘技術在法律合同文本審查[1-2]、醫療文檔處理[3]、新聞摘要提取[4]等方面的研究和成功應用,可為施工組織設計智慧輔助審查提供一定的借鑒。在工程建設領域,有關建筑工程管理規范條文[5]檢索、有關混凝土壩施工文檔知識智能識別及挖掘[6]、有關工程施工進度關鍵工序詞提取與信息挖掘[7]、調水工程巡檢文本智能分類[8]等方面的研究表明:非結構化文檔知識挖掘正成為工程建設領域研究的重要方向之一。
但是,由于施工組織設計文檔具有類型多樣、長文本、針對對象類型多、涉及內容廣等特點,要實現智慧輔助審查還存在較大的難度。為此,針對施工組織設計文檔智慧輔助審查中基礎性工作之一——文本分類問題開展研究。施工組織設計審查主要包括施工組織設計文本的全面性、可操作性、針對性、先進性等。其中全面性指的是施工組織設計文檔依據施工組織設計編制規范編制基本內容,包括工程概況、施工部署、施工進度計劃、施工準備與資源配置計劃、主要施工方法等;可操作性指的是施工組織設計文本中各項作業是否符合實際,合理可行,如頂管施工中黃土土質條件不適用于偏心破碎泥水平衡掘進機;針對性主要指施工組織設計文本是否對工程重難點把握到位;先進性審查施工組織設計是否采用新技術新工藝等;施工組織設計文本分類可以對施工組織設計文本快速精準分類,劃分文本主題,為施工組織設計的全面性審查提供依據;此外通過對施工組織文本的分類挖掘,對后續依據主題類別應用知識圖譜挖掘其中有關地質條件、水文以及氣象條件、工程重難點、施工新技術新方法等信息提供基礎,是實現施工組織設計文檔智慧輔助審查的重要手段之一。
基于Bi-LSTM Attention的施工組織設計文本分類方法,利用房建、隧道、公路、橋梁施工組織設計以及污水管道等常見的施工組織設計文檔,利用工程概況這一部分內容訓練施工組織設計文本分類模型,并進行了幾種分類方法所得結果比較研究。
1 文獻綜述
自然語言處理中,文本分類的目的主要是通過將已經被標注的訓練集通過分類模型訓練,實現新的文檔類別的自動判斷,文本分類早起源與國外,從基于知識的方法轉變為基于機器學習的方法,現在被廣泛應用于中文專利[9]、影視評價[10]、醫學文獻[11]等各個領域。
對于文本分類的研究起源于20世紀50年代,Luhn[12]提出了利用詞頻統計來進行文本分類的方法;Maron等[13]提出了利用關鍵詞給文本分類的方法,基于此方法,文本自動分類也在逐步應用;Salton等[14]基于空間密度計算的方法為文檔選取最佳索引詞匯,但是這需要人工的定義分類規則,無法適應于大規模的分類任務。
文本分類主要包括數據預處理、文本表示、特征降維。目前,詞向量的表示有基于One-hot(獨熱編碼),還有基于詞向量(Word2vec),One-hot是一個詞袋模型,它基于詞與詞之間相互獨立的假設,不能考慮上下文的關系。Collobert等[15]提出了基于詞向量訓練的神經網絡模型;Huang等[16]提出了運用上下文訓練詞向量的方法;Mikolov等[17]首次提出了Word2vec詞向量模型,連續詞袋模型(continuous bag-of-word model,CBOW)模型類似于神經網絡模型,其目的是通過上下文相關單詞去預測目標單詞的出現概率,跳字模型(continuous skip-gram model, Skip-gram)模型恰恰相反,它是利用某個單詞去預測其相關的上下文單詞。Word2vec模型應用CBOW或Skip-gram作為詞嵌入的工具,根據給定的語料庫,通過訓練模型將詞語表達成向量形式,訓練生成的詞向量要比傳統的One-hot(獨熱表示)富含更多語義信息,并且避免了詞向量維度過高難以計算以及不能充分表示詞與詞之間的關系的問題。特征降維主要是對特征向量進行降維處理,特征向量維度過高,分類模型可能無法處理,常用的方法有文檔頻次法(document frequency,DF)、互信息(mutual information,MI)法、信息增益(information gain)法、卡方檢驗(CHI)法等[18]。
Bahdanau等[19]首次將Attention 機制運用于機器翻譯任務中;Zhang等[20]基于循環神經網絡(gate recurrent unit,GRU)提取上下文語義信息,結合 Attention 機制,模型的準確率和訓練速度均有提升;滕金保等[10]利用多通道注意力機制對輸出信息進行融合,有效提高文本分類的效果。
基于長短時記憶網絡(long short-term memory,Bi-LSTM)的文本分類模型,只考慮到上文語境并提取文本特征向量。Shu等[21]提出了雙向長短時記憶網絡(bi-directional long short-term memory,Bi-LSTM),Bi-LSTM綜合考慮文本的上下文語境,通過正向隱藏層和反向隱藏層兩個方向捕捉文本特征,提取更為豐富的語義信息,提高分類模型性能。近年來,基于FastText[22]、BERT[11]、深度金字塔卷積神經網絡DPCNN[23]、Transformer[24]等新型模型以及各種集成模型廣泛應用于文本分類的任務中。
基于以上研究,結合當前市政施工領域工作需求,采用Bi-LSTM Attention模型,將其應用于市政施工組織設計文本分類研究當中,首先利用Word2vec訓練詞向量,獲取具有豐富語義信息的詞向量,接著利用雙向LSTM提取上下文語義信息,得到更加全面的特征向量,最后加入Attention機制,在保留全面性的前提下關注關鍵信息,以期提升模型的分類性能。
2 文本分類流程
文本分類在自然語言處理中扮演著非常重要的角色,最早的文本分類依賴于手工構建分類數據集,耗時費力,不利于大規模投入使用。目前,基于自動文本分類通過有監督學習,將非結構化的信息處理為計算機可處理的數據結構,是文本分類任務的一大難點。文本分類的一般流程如圖1所示,文本分類在輸入分類器之前主要步驟有:①文本預處理;②Word2vec詞向量表示;③特征降維。
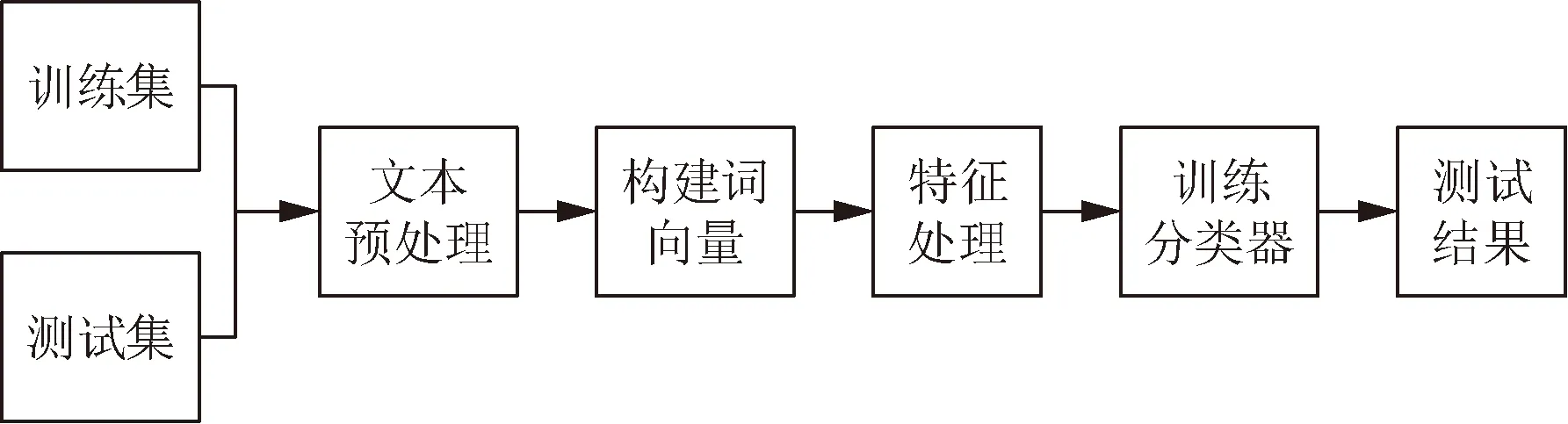
圖1 文本分類一般流程圖Fig.1 General flowchart for text classification
2.1 文本預處理
文本預處理主要包括分詞和去除停用詞等操作。首先利用開源軟件包jieba進行中文分詞,把文本內容劃分為以詞為單位的序列,去除停用詞主要指的是將文本中反復出現并無特殊意義的詞進行去除處理,這些詞的存在對于分類器的訓練起不到任何作用,甚至會對文本分類的效果存在干擾,因此需要創建停用詞表,對文檔中含有停用詞的文本進行過濾。
2.2 Word2vec詞向量表示
CBOW于2013年由 Mikolov等[17]提出,主要是將高維稀疏的詞向量轉化為低維稠密的向量空間,CBOW模型內在思想主要是通過給文本上下文建模,將上下文詞語加權平均,最后用softmax函數計算的到中心詞的概率,并且得到詞向量。圖2展示了Word2vec詞嵌入構造向量的過程。
CBOW模型的結構類似神經網絡模型,目標函數可表示為


(1)
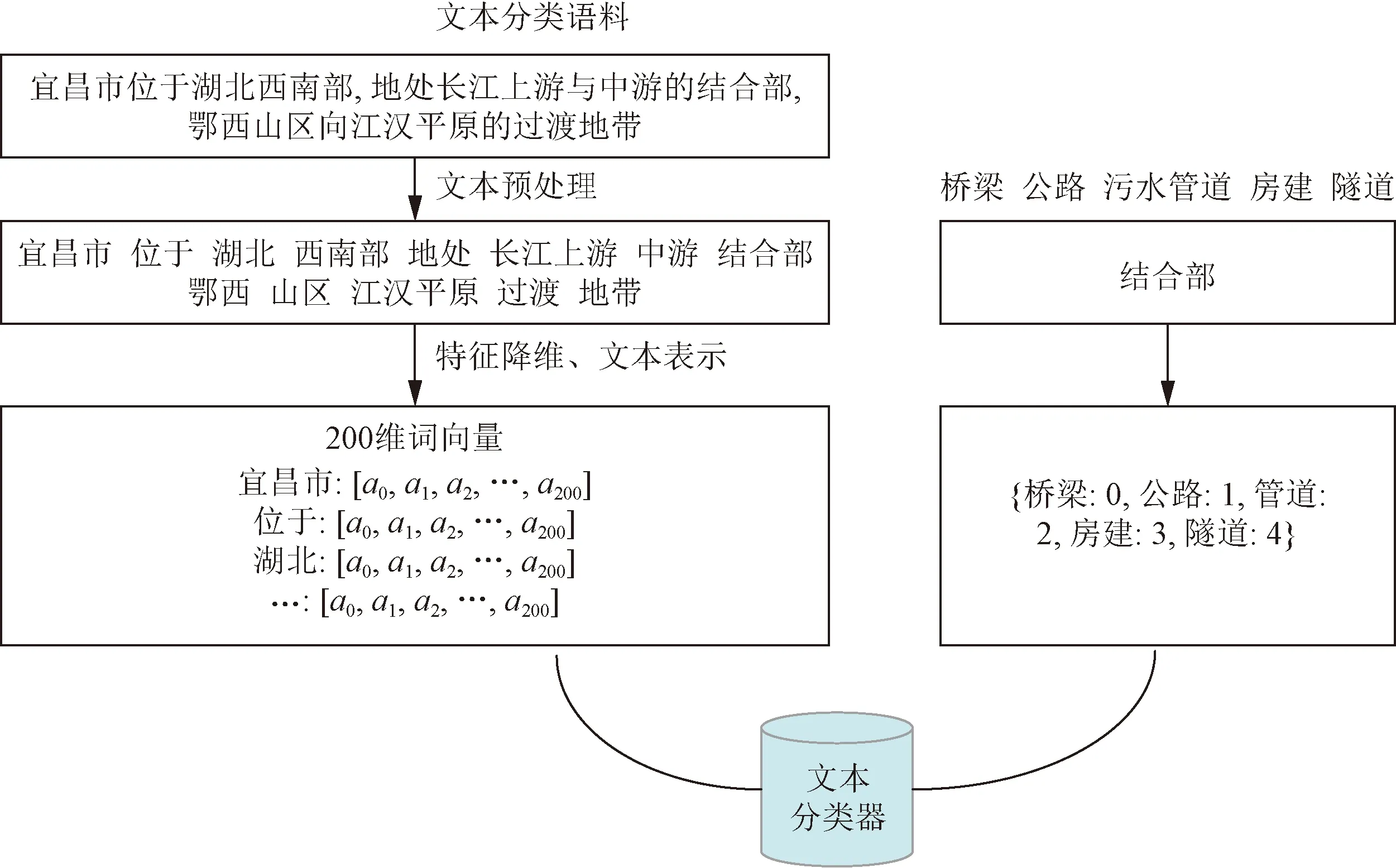
圖2 Word2vec詞嵌入構造向量流程Fig.2 Word2vec word embedding construction vector process
式(1)中:p為條件概率;T為訓練語料庫中出現詞匯的數量;Context為中心詞上下文窗口大小;wt-c、wt-1、wt+1、wt+c表示輸入的詞向量;wt為輸出的詞向量。
在實際計算過程中會將目標函數轉換為對數似然函數L,其表達式為
(2)
CBOW采用三層前饋神經網絡,結構包括輸入層、映射層、輸出層,w(t-2),w(t-1),…,w(t+2)為輸入向量,映射層為計算過程,w(t)為輸出變量,如圖3所示。CBOW沒有隱藏層,在整個的網絡傳播過程中減少很多矩陣計算,節省了計算時間。輸出層通過上下文計算中心詞出現的概率,模型通過softmax函數進行歸一化計算,具體表達式為
(3)
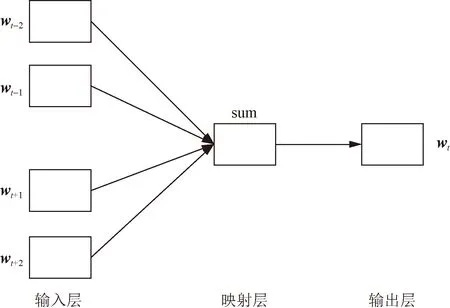
sum為映射層,主要是對輸入層的向量做求和累加,表示一個計算的 過程圖3 CBOW 模型結構示意圖Fig.3 Schematic diagram of CBOW model structure
式(3)中:T為訓練語料庫中出現詞匯的數量;yw(i)為向量y中第i個分量值。
應用CBOW詞向量訓練,得到訓練后的詞向量可表示為
(4)
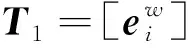
(5)
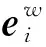
2.3 特征降維
文檔頻率(document frequency,DF)是指文本集中包含某個特征的文檔個數。文檔頻率是最簡單的一種無監督的特征降維方法,其時間復雜度和文本集的大小呈線性關系,不依賴類別信息,多用于文本分類。
文檔頻率主要就是計算訓練集中每個特征詞的文檔頻率,再將文檔頻率小于設定閾值的特征詞移除,不作為訓練的特征詞向量,在文本分類任務中,一般認為出現頻率較多次數的詞匯更能表現文本特征,出現頻率少的詞匯要么是無用詞匯,要么對整體性能沒有影響。但實際上,小頻率的特征詞未必就是無用詞匯,大量的刪除出現次數少卻對分類特征明顯的詞匯可能會導致特征集類別判定能力下降,影響文本分類的效果。
3 Bi-lSTM-Attention文本分類模型
在BiLSTM 的基礎上,本文提出基于雙向長短時記憶網絡的改進注意力模型,Attention機制的加入能夠進一步的優化文本特征向量,解決信息冗余的問題,提高文本分類的準確度,Bi-LSTM模型架構圖4所示。
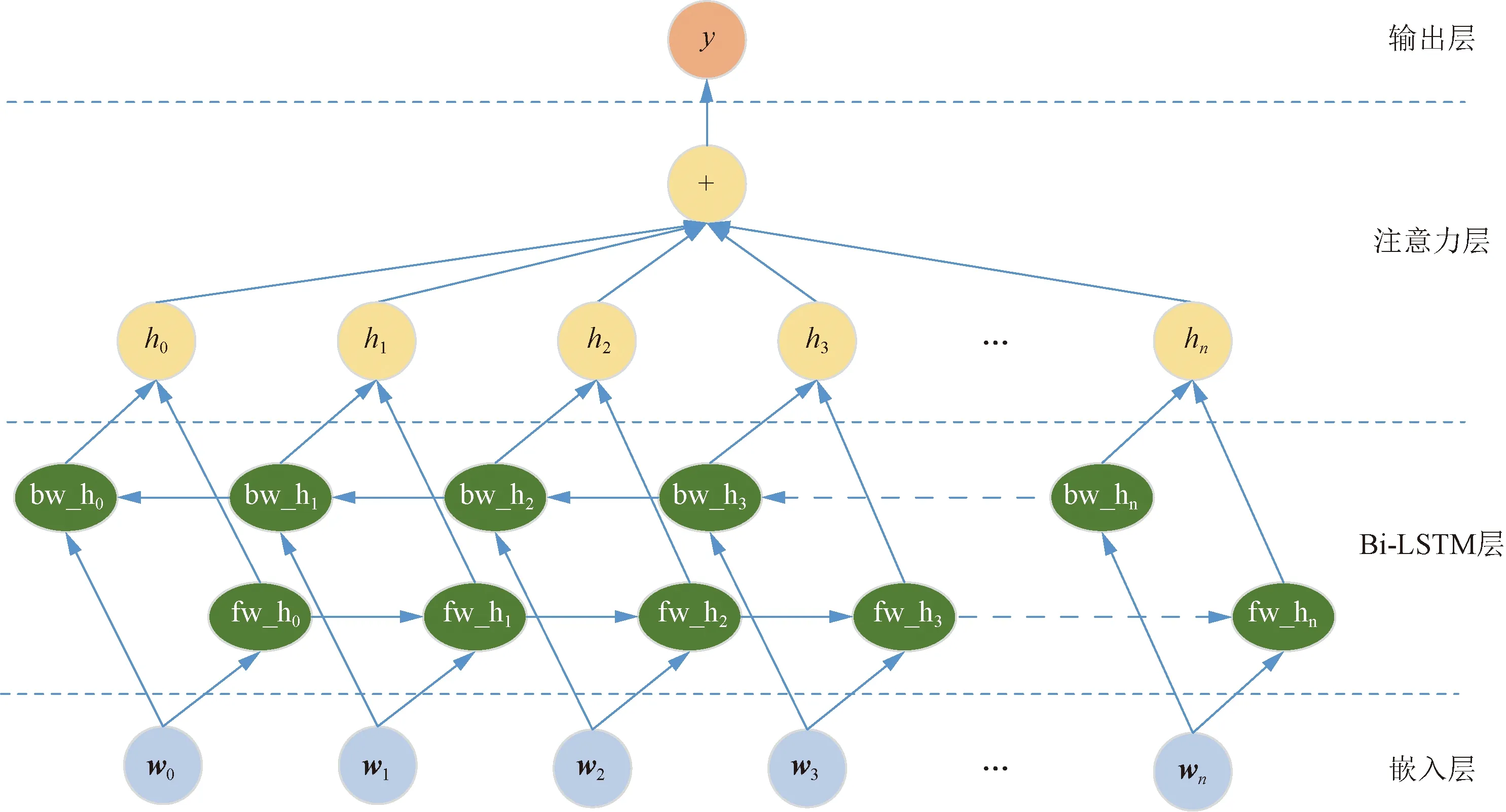
bw_hn為句子后向信息;fw_hn為句子前向信息圖4 Bi-LSTM模型架構圖Fig.4 Bi-LSTM model architecture
所提出的模型包含5部分,即①嵌入層:將每個詞g映射成低維向量;②LSTM層:利用BLSTM從①獲得高層特征;③注意層:產生一個權重向量,通過將權重向量相乘,將每個時間步長的詞級特征合并成句子級特征向量;④輸出層:最終使用句子級特征向量進行關系分類。
3.1 嵌入層
給定一個由n個詞組成的句子S為[w0,w1,w2,…,wn],每個單詞wi轉換為一個200維度的實數向量,在句子中的每個單詞,查詢詞嵌入矩陣Wwrd∈Rdw|V|,其中,V為一個固定詞匯數的詞典,本文模型中的詞匯數是6 002,dw為詞向量的維度,Wwrd通過訓練詞向量得到,詞向量維度dw可控,輸入的詞通過從詞典查找的方式得到相應的詞向量,詞典中沒有的詞通過隨機生成的方式得到,文本通過預處理之后輸入到嵌入層,完成文本的向量化表示。
3.2 雙向長短時記憶網絡層
BiLSTM是對LSTM進行了改進,其與LSTM結構大體相似,區別于LSTM的單向傳播,BiLSTM引入了兩個傳播方向相反,相互獨立的隱藏層,相較于LSTM,它能夠得到兩個關于輸入信息的向量,從正向和反向得到序列的上下文語義信息,提高模型的性能,參考Shu等[21]提出的BiLSTM結構,其表達式見式(6)~式(10)。
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(6)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
(7)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
(8)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo)
(9)
ht=ottanhct
(10)
式中:σ為sigmoid作為激活函數;it、ft、ot、ct分別為輸入門、遺忘門、輸出門和記憶單元,其中,遺忘門ft決定細胞需要舍棄哪些特征信息,輸入門it決定給細胞狀態添加哪些特征信息;tanh為激活函數;ht-1為前一個時間步的輸出;xt為當前時間步的輸入;Wxi、Whi、Wci為輸入門it的權重;Wxf、Whf、Wcf為遺忘門ft的權重;Wxc、Whc為記憶單元ct的權重;Wxo、Who、Wco為輸出門ot的權重;bi、bf、bc、bo分別為輸入門偏置、遺忘門偏置、候選細胞偏置和輸出門偏置。
3.3 注意力層
Attention機制被用于自然語言處理(NLP)最早是在Encoder-Decoder[25]中,多用于機器翻譯和人機對話當中,將Attention機制引入文本分類模型,其優勢在于使輸入的數據具有不同的權重信息并側重于權重較高的信息,提高分類效果。
M=tanhH
(11)
α=softmax(wTM)
(12)
r=HαT
(13)
式中:M為隱藏層單元;α為注意力向量;H為 BiLSTM 的輸出;r為Attention機制的輸出向量;w為訓練好的詞向量。
最終被用來分類的句子可表示為
h*=tanhr
(14)
3.4 輸出層
使用softmax分類器來預測類別,將分類器注意力層的h*作為輸入,可表示為
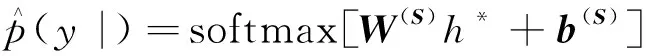
(15)
式(15)中:y為具體類別;S為輸入的句子向量。
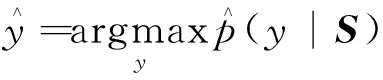
(16)
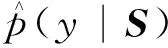
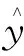

(17)
式(17)中:ti為樣本的正確標簽;yi為樣本的預測標簽;m為所有文本的數量;θ為代價函數的參數,θ越小,代價越小;λ為L2正則化超參數,將dropout和L2正則化相結合來緩解過擬合。
4 實驗
4.1 實驗環境
本實驗是基于Tensorflow框架上實現的,Tensorflow 是一款用于深度學習的開源框架,利用節點之間的數據流傳遞數據并進行計算。Tensorflow最開始由Google大腦的研究院以及工程師研發,用于機器學習和神經網絡的研究,2015年10月開源,其架構靈活,能夠支持各種網絡模型,具有良好的通用性。本實驗的計算機配置情況如表1所示。

表1 計算機配置情況Table 1 Computer configuration situation
4.2 對比方法
本實驗一共運用了5種文本分類的算法做對比實驗,在相同的數據集上進行實驗。4種對比實驗分別為:基于Word2Vec詞向量表示,RCNN(region-convolutional neural networks)文本分類方法、CNN文本分類方法、Transformer文本分類方法、Bi-lSTM文本分類方法、Bi-lSTM-Attention文本分類方法。
4.3 實驗語料數據集
目前,文本分類大多采用已經開源的數據集,通過手機郵件語料數據集[18]、IMDB影評數據集、復旦大學中文語料庫以及利用Python爬蟲從專業網站上獲取相關專業文本數據集,然后利用神經網絡方法實現施工組織設計文本自動分類,采用通過網絡下載以及調研等各種方式收集不同類型的施工組織設計文檔,構建文本分類的數據集。
通過對“土木在線”網站(https://bbs.co188.com/)數據以及長江大保護相關單位所提供數據進行收集整理,本實驗語料數據主要集中于市政相關的施工組織設計文檔,主要涵蓋了房建、污水管道、公路、隧道、橋梁5個領域。施工組織設計文檔的編寫應以相關編制規范為依據,內容上都必須包括涵蓋整個工程項目的概況信息、施工部署、全程進度安排、施工準備工作、主要機械人員配置情況、采用的施工方法、施工現場總平面布置等,選擇最具有分類特征的工程概況作為分類文本,工程概況包括工程地理位置、主要工程量等以及水文、地質、氣象條件等現場施工條件信息。
鑒于收集數據的難度較大,本實驗收集了房建、污水管道、公路、隧道、橋梁的數據集,總計1 720份施工組織設計文檔,其中房建868份、污水管道224份、公路282份、隧道和橋梁分別為143和203份,本實驗選定80%的文本作為訓練數據集,20%的文本作為測試數據集。
4.4 實驗細節
使用分詞工具jieba和停用詞表分別進行分詞和去除停用詞后利用Word2vec進行詞向量的構造,Word2vec預訓練詞向量維度為200,窗口大小設置為10,利用CBOW進行訓練。
(1)Bi-LSTM文本分類模型的參數設置。Bi-LSTM隱藏層神經元設置為128,單詞訓練樣本batch size設置為128,驗證集比率rate為0.8,詞匯量vocab_size為6 000。所有樣本共進行20輪循環訓練,學習率為0.001。
(2)對比實驗中的參數設置。RCNN隱藏層神經元為256,丟棄率Dropout為0.5;CNN卷積核的數目為128,卷積核的大小為2、3、4,Dropout為0.5;Transformer中內層一維卷積核的數量為64,多頭注意力數目為8,transformer block的數量為1,LayerNorm中的最小除數為1×10-8,Dropout為0.5;Bi-LSTM 和Bi-lSTM-Attention文本分類模型中隱藏層神經元為128,Dropout為0.5。
4.5 評價指標
精確率(precision,記為P)、召回率(recall,記為R)、F值是評價單個類型文本分類效果的主要指標。共包含5種類別,分別用A1、A2、A3、A4、A5表示。TP(true positive)表示原本類別為Ai并且被分類到Ai的樣本數;FP(false positive)表示原本類別不是Ci卻被分類到Ci的樣本數;FN(false negative)表示原本類別為Ci卻被劃分到其他類別中的樣本個數;TN(true negative)表示原本不屬于Ci也沒有被分類到Ci的樣本數。
精確率P指正確分類到某個類別的樣本數量占全部被分類器劃分到這個類別樣本數量的百分比,其計算公式為
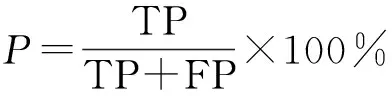
(18)
召回率R指正確分類到某個類別的樣本數量占全部樣本中實際屬于這個類別的樣本數量的百分比,其計算公式為
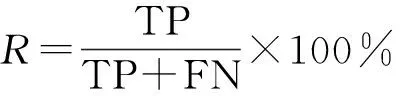
(19)
F值是一個綜合指標,是精確率和召回率的倒數平均值,其計算公式為
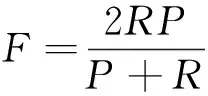
(20)
對于評估分類器對于所有分類文本的性能時,采用準確率、微平均、宏平均、以及加權平均。
準確率(accuracy,記為Accuracy)指的是分類正確的樣本數和總樣本數的比值,其計算公式為
(21)
對于評估分類器對于所有分類文本的性能時,采用微平均、宏平均以及加權平均作評估。
微平均精確率(Micro_P)、微平均召回率(Micro_R)、微平均F值(Micro_F)計算公式分別為
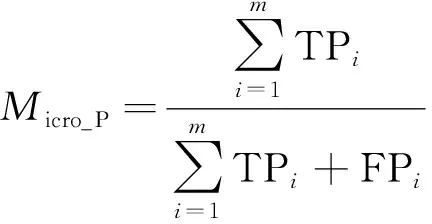
(22)

(23)
(24)
宏平均精確率(Macro_P)、宏平均召回率(Macro_R)、宏平均F值(Macro_F)計算公式分別為
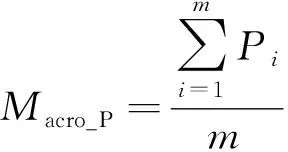
(25)
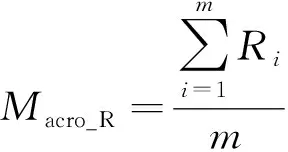
(26)
(27)
式中:Pi、Ri分別為第i類的精確率、召回率;m為總類別數。
加權平均精確率Weight_P、加權平均召回率Weight_R、加權平均F值Weight_F的計算公式分別為
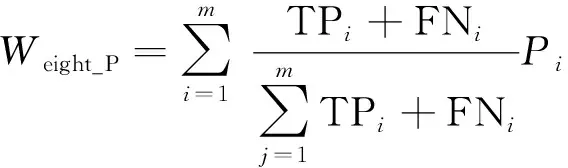
(28)
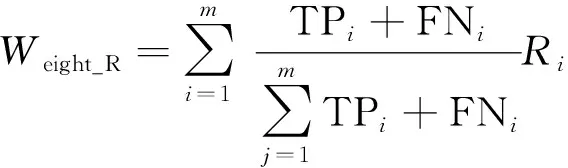
(29)
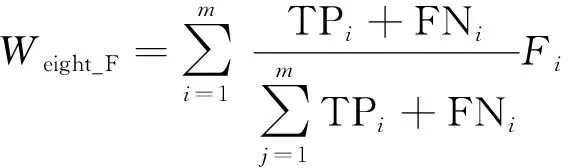
(30)
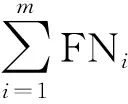
4.6 結果與分析
4.6.1 各類別文檔分類結果與分析
對基于Attention的Bi-LSTM特征提取與其他4種文本分類模型進行對比實驗,結果如表2所示。
表2為房建、污水管道、鐵路、公路、隧道數據集在5種文本分類模型上分類精確率、召回率、F值,表中依次表示為Pre、Rec、F。可以看出,基于Attention的Bi-LSTM的文本分類模型基本在每個分類上的3個評價指標均高于其他模型。在數據收集上,房建類施工組織設計文本收集數量868份,Bi-LSTM-Attention、CNN、Bi-LSTM的精確率、召回率、F值均在0.9以上;RCNN和Transformer精確率分別為0.84和0.82;公路收集數據分別為282份,其在CNN和Bi-LSTM-Attention模型的分類效果較好,精確率分別為0.64和0.75,召回率分別為0.95和0.92,F值分別為0.77和0.82,在其他3種模型的表現稍次;污水管道、橋梁、隧道等數據較少的文本中,CNN和Bi-LSTM-Attention依然優于其他模型,其中RCNN表現最差,在污水管道以及隧道的數據集上并沒有得到有效的訓練,Transformer在隧道數據集上訓練效果較差。總體來說,在房建這個數據集較多的類別上,幾種模型的分類效果約為0.9,Bi-LSTM-Attention精確率、召回率、F值均為0.97,分類性能最好。結果表明,融入Attention機制Bi-LSTM文本分類模型的精確度、召回率、F值等相比于其他模型均有明顯提升。
4.6.2 整體分類結果與分析
在Sk-learn里,Micro-average平均下,多分類的Accuracy、Recall和Precision是一致的,因此只給出模型準確率(Accuracy)、宏平均(Macro-average)、以及加權平均(Weight-average)的統計結果,如表3所示。
Bi-LSTM-Attention、CNN、Bi-LSTM、Transformer、RCNN分類準確率、宏平均值及加權平均值依次降低。Bi-LSTM-Attention和CNN的模型準確率最佳,分別為0.85和0.82;Bi-LSTM-Attention在Macro_P、Macro_R、Macro_F分別為0.8、0.75、0.75,比表現稍差的CNN分別高出5%、6%、5%;Bi-LSTM-Attention在Weight_P、Weight_R、Weight_F分別為0.86、0.85、0.85,比CNN分別高出2%、3%、4%。實驗表明,加入 Attention 機制的文本分類模型能夠綜合考慮上下文信息,其能夠存儲更多的語義信息,提取更多的文本特征,Attention機制加強了關鍵信息對分類的影響,可提升文本分類模型的精度。

表2 5種模型文本分類性能Table 2 Text classification performance of five models

表3 模型整體分類性能Table 3 Overall classification performance of the model
5 結論
(1)為實現市政相關施工組織設計文本的分類,基于Bi-LSTM加入Attention機制,利用注意力機制進一步對提取到的特征向量進行優化,BiLSTM則是對LSTM進行了改進,區別于LSTM的單向傳播,BiLSTM引入了兩個傳播方向相反,相互獨立的隱藏層,它能夠得到兩個關于輸入信息的向量,從正向和反向得到序列的上下文語義信息,提高了模型的性能。通過設置實驗,對比了5種文本分類方法,通過統計各類別文檔分類結果的準確率、召回率、F值等評價指標評估模型在單個類別數據集的分類性能,通過Accuracy、Macro_F、Weighted_F評估模型在整體數據集上的分類性能。實驗表明,融入 Attention 機制Bi-LSTM文本分類模型相比于其他模型均有明顯提升。
(2)不足之處在于在做分類研究使用的是施工組織設計文本數據集,數據有限,導致數據少的分類模型訓練效果差;后續考慮將CNN和Attention Bi-LSTM集成來提高文本分類模型性能并通過研究少樣本文本分類模型提高模型應用能力;基于文本分類研究利用知識圖譜進行規則推理挖掘施工組織設計文本關鍵信息以輔助施工組織設計文檔智慧審查。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
