基于級聯網絡人臉五特征點檢測及其應用
2022-02-09 02:04:58郭克友賀云霞
計算機仿真 2022年12期
郭克友,賀云霞,胡 巍
(北京工商大學,北京 100048)
1 引言
以據統計,疲勞駕駛、酒駕等人為因素是引發交通事故的主要原因,這都與駕駛員的精神狀態和注意力集中程度密切相關,因此對駕駛員駕駛狀態進行有效檢測有利于防止交通事故的發生。對于駕駛員的注意力檢測大致可以分為三類:一是根據駕駛員的生理參數判斷,比如通過眼睛閉合時間占特定時間的百分率作為疲勞程度的衡量指標[1,2];二是根據車輛行駛的狀態[3];三是根據駕駛員面部姿態估計[4],精確的人臉特征點定位可以估計出人臉偏轉的角度,遮擋、光照的明暗、較大的頭部旋轉和夸張的表情變化等因素都會影響特征點定位的準確性。人臉特征點檢測的主流方法是先進行人臉檢測,檢測出人臉的邊界框,再預測出眼睛、鼻子、輪廓等關鍵點。
人臉特征點檢測方法大致分為三類。一是ASM[5](Active Shape Model)和AAM[6](Active Appearnce Model)基于模型的方法;二是2010年,Dollar提出CPR[7](Cascaded Pose Regression)基于回歸的方法;三是基于深度學習[8]的方法:2013年,Sun等人[9]首次將卷積神經網絡應用到人臉關鍵點檢測;2016年,Zhang等人[10]提出一種多任務級聯卷積神經網絡MTCNN(Multi-task Cascaded Convolutional Networks)用以同時處理人臉檢測和人臉關鍵點定位問題。香港中文大學的湯曉鷗教授團隊提出TCDCN[11],同時進行多任務學習,通過性別、是否戴眼鏡和臉部姿態輔助定位特征點。
特征點提取這塊由于目前是基于深度神經網絡的,計算量特別大,因此考慮對五特征點檢測的網絡進行簡化,達到節約時間的目的。針對DCNN三級預測比較復雜的問題,提出了一種優化方式,將原來的檢測模型改為兩級檢測模型。選取五個固定點即眼角、鼻子、嘴角作為特征點進行預測,選用級聯卷積網絡,將上一級的輸出作為下一級的輸入,在不同層選用不同大小的卷積濾波器,有效提高速度與精度,更快的檢測出人臉的特征點。然后運用檢測出的人臉特征點像素坐標輸入線性方程,計算得出單應性矩陣,從而求出面部轉過的角度。通過實驗證明了提出的方法在簡化網絡的同時精度還有略微的提升,并且檢測出的特征點能進行注意力檢測。
下面首先簡要介紹原始的DCNN網絡,然后重點介紹優化和改進方式。實驗從兩方面展開,第一部分介紹優化方式相比于原始DCNN的提升效果,接著用提出方法檢測出的特征點去計算面部轉角來證明所提出的方法可以用于注意力檢測。
2 基于級聯網絡人臉五特征點檢測
2.1 DCNN
DCNN的總體思想是有粗到細實現人臉關鍵點的定位,整個網絡結構分為三層:level1、level2、level3,每層都包含多個神經網絡模型。level1是粗略定位,分三層負責部分或全部關鍵點定位,每個關鍵點至少被預測兩次,取結果的平均值得到第一層粗定位的結果。Level2是將第一層的輸出五個特征點截成五張小圖像,分別輸入到level2中的十層網絡組,每個特征點被訓練兩次,輸出兩次平均定位,以獲得準確的定位。將level2輸出的五特征點,裁剪成更小的五張圖像,輸入到level3中,level3的結構與作用與level2一致,以獲得更精確的五特征點定位。
2.2 DCNN結構改進
改進過的五特征點檢測網絡是由兩個小網絡組成級聯網絡,完成人臉邊界框內的五個特征點回歸的任務,五個特征點分別為左眼角(LE)、右眼的右眼角(RE)、鼻尖(N)、左嘴角(LM)和右嘴角(M)。具體流程如圖1所示:首先輸入已知人臉框圖的圖像輸入第一級網絡,第一級網絡有1F、1EN和1NM三層深度神經網絡,將人臉邊界框resize到39×39尺寸后輸入1F網絡,預測人臉出五個特征點,再將人臉邊界框裁剪至31×39尺寸,圖像包括眼角和鼻尖輸入1EN,預測出三個特征點,最后一層網絡1NM的輸入圖像包括鼻尖和嘴角,預測出鼻尖和嘴角三個特征點,將三個深度卷積網絡預測出的特征點做均值處理,輸出人臉五個特征點的粗定位。第二級網絡包括十個淺層卷積神經網絡,分別表示為2LE1、2LE2、2RE1、2RE2、2N1、2N2、2LM1、2LM2、2RM1以及2RM2,由第一級網絡得到五個特征點的粗定位,以預測特征點位置為中心的局部位置裁剪至15×15的圖像作為第二級網絡各個淺層神經網絡的輸入,2LE1表示第二級中預測左眼角的第一個卷積網絡,以此類推,每個特征點會被訓練兩次,對兩次訓練輸出的特征點位置進行平均處理,得出較精確的定位,第二級網絡是對第一級網絡預測的結果進行微小的修改。
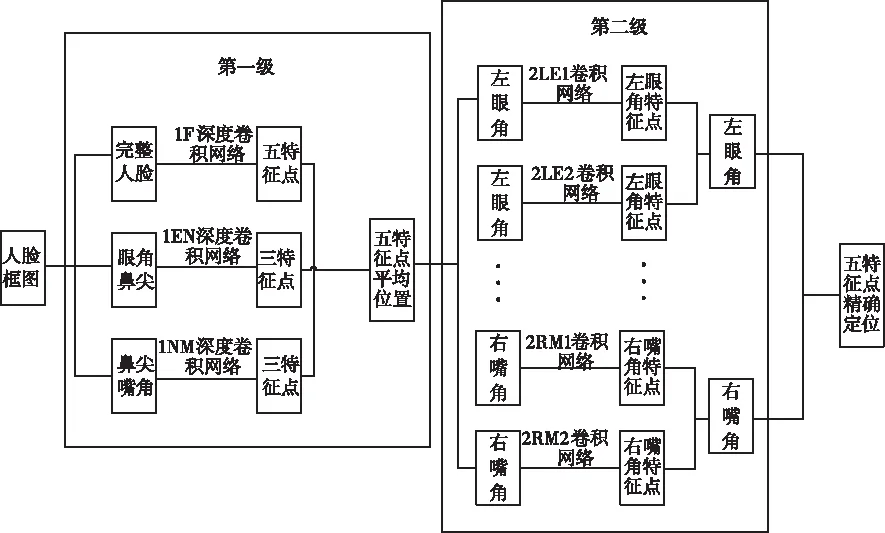
圖1 級聯DCNN結構圖
2.3 卷積神經網絡結構改進
第一級網絡需要從輸入的人臉框圖中直接檢測出五個特診點,這是比較困難并且難以訓練的任務,卷積神經網絡需要足夠的深度才能從全局出發,形成更高層次的特征。通過結合低層提取的空間鄰近特征,高層神經元可以從較大區域提取特征。除此之外,高層次的特征通常是高非線性的,可以通過在卷積層后添加激活函數用于增加從輸入到輸出的非線性。第一級深度神經網絡選用vanilla CNN,其網絡結構如圖2所示,深度卷積神經網絡由一個卷積核為5×5的卷積層,兩個卷積核為3×3的卷積層以及一個卷積核為2×2的卷積層和兩個全連接層組成,選擇最大池化。vanilla CNN是用來訓練面部的特征點,這是一個基于回歸面部特征點網絡的松散網絡,選擇此模型是因其簡單性。該網絡應從輸入的人臉框圖中預測出五個特征點,1F深度神經網絡的檢測窗口大小為39×39,1EN和1NM的檢測窗口大小為39×31,將1F、1EN和1NM三張圖像分別輸入速度卷積神經網絡,經過四個卷積層和兩個全連接層后進行損失計算,四層卷積層使用的卷積核逐層遞減,即感受野逐層減少,池化層選用最大池化。經過三個深度卷積網絡的訓練,眼角和嘴角會被訓練兩次,鼻尖會被訓練三次,將訓練輸出的特征點做均值處理即可得到五個特征點的粗定位。對于卷積層中的神經元選用雙曲正切激活函數后的絕對值校正,此激活函數可以有效地提高性能。實踐研究表明,該方法在實際應用中也是有效的。

圖2 第一級深度卷積神經網絡結構圖
第二級是在局部位置精確特征點的位置,只需淺層的神經網絡即可達到目的,所有卷積神經網絡都共享一個較淺的網絡結構,如圖3所示。以2LE卷積神經網絡為例,將第一級網絡所預測的左眼粗定位為中心,裁剪檢測窗口至15×15,經過兩個卷積層和兩個全連接層后進行損失計算,兩個卷積層選用的卷積核大小分別為4×4和3×3,池化層依舊為最大池化層。每一個特征點會經過兩個淺層神經網絡訓練,最后對兩次訓練輸出的特征點位置進行平均處理,得出局部位置較精確的定位。對于卷積層中選用ReLU激活函數。

圖3 第二級淺層卷積神經網絡結構圖
在同一特征圖上局部共享神經元的權重可以提高網絡性能。傳統的卷積網絡基于兩個考慮共享同一特征圖上所有神經元的權值。首先,假設相同的特征可能出現在圖像的任何地方。因此,能應用于某一地方的過濾器,也能應用于其它地方。其次,權值共享有助于防止梯度擴散,由于共享權值的梯度是聚集的,這使得深層結構的監督學習更加容易。然而,全局共享權重在固定空間布局的圖像上效果并不好。比如在人臉檢測時,雖然眼睛和嘴巴可能有像邊緣這樣的共同低級特征,但它們在高層次上是非常不同的。因此,對于輸入包含不同語義區域的網絡,在高層上局部共享權值對于學習不同的高層特征更有效。
2.4 網絡訓練
第一級的三個網絡依次訓練,先訓練1F深度卷積神經網絡,再訓練1EN深度卷積神經網絡,最后訓練1NM深度卷積神經網絡。卷積神經網絡的訓練流程是輸入圖像I(h,w),h和w分別為圖像的高和寬,C(s,n,p,q)定義為有n個特征圖、卷積核邊長為s的卷積層,p、q為權值共享參數。卷積層的計算為式(1)。P(s)定義為池化區域邊長為s的最大池化層,如式(2),進行正切非線性處理和絕對值修正。經過多層卷積與池化,最后進入全連接層F(n),如式(3)

(1)

(2)

(3)
第二級是以第一級人臉特征點的預測位置為中心的局部位置作為輸入,只是對特征點的位置進行微調,輸入大小為15×15,提取低層特征,神經網絡只有兩次卷積,為淺層的神經網絡,迭代次數不宜過大。第二級網絡與第一級網絡類似,十個淺層卷積神經網絡依次訓練,每個網絡迭代100,000 次。ω權重的學習率為0.01,b常數向量的學習率為0.02,通過隨機梯度下降進行學習。學習率的更新策略為Poly,即每次反向傳播以后使用式(4)更新每次的學習率

(4)
其中base_lr為基礎學習率,iter為當前迭代次數,maxiter為迭代次數,學習率曲線主要由power值控制。
3 實驗
3.1 實驗設置
首先用改進的算法進行五特征點檢測,然后再用檢測出的特征點計算面部轉角來證明所提出的方法能用于注意力檢測。本實驗用到的環境:Ubuntu16.04,caffe深度學習框架,opencv4.1.0。
本實驗的訓練集包含5590張LFW圖像和7876張來自網絡的圖像,所有的圖片都被標記為5個面部標記。將圖片中眼珠的標記,改成眼角的標記。刪除側臉與嚴重遮擋的圖像,剩下的面孔被隨機分割,其中8000張用于訓練,1856張用于驗證。測試集包括1521張BioID圖像、781張LFPW圖像和249張LFPW測試圖像。
3.2 五特征檢測實驗
針對人臉特征點檢測,對測試集1856張圖片進行測試,得到失敗率以及平均誤差,如表1所示。誤差為預測值與真實值間的橫向像素距離占輸入人臉框圖寬度的比例,當誤差大于0.05時,被定義為無效預測即預測失敗,失敗率為預測無效的圖片占測試集圖片的比例。平均誤差為所有測試集誤差的平均值。
與未改進的DCNN[12]相比,只運用了兩級網絡便達到了使用三級網絡的效果,甚至得到了更高的準確率,改進后的DCNN只需要訓練兩級網絡,大大縮短了訓練的時間,并用相同的數據在MTCNN上進行實驗。結果對比如表2所示。

表1 人臉特征點檢測準確率

表2 實驗結果對比
3.3 人臉轉角實驗
在檢測出五個人臉特征點的基礎上,使用單應性矩陣[13]計算人臉偏轉角度。面部轉向一般繞頭部中心軸轉動,此轉角與相機繞相機中心軸轉過的角度相同,因此可以轉化為兩個不同位置的相機對同一物體拍攝,運用單應性矩陣求兩個相機相對位置的問題。單應性矩陣用于描述物體在世界坐標系和像素坐標系之間的位置映射關系,如式(5)。

(5)
其中M為相機的內參矩陣,T為相機的外參矩陣,由旋轉矩陣的前兩列r1、r2和平移矩陣t組合而成。
本課題組對人臉偏轉角度誤差進行實驗,實驗結果表明運用單應性矩陣計算出的角度與實際偏轉角度相差1-5°。本實驗在計算角度誤差的基礎上,驗證人臉偏轉角度的大小對單應性矩陣計算角度準確率的影響。
首先在正對駕駛員的位置固定相機,用相機拍攝出駕駛員左右偏轉10°、20°、30°時的姿態;其次用級聯卷積神經網絡檢測出人臉五特征點;然后選用眼角和嘴角四個特征點,將八個點的像素坐標帶入式(6)、(7),計算出單應性矩陣H;最后鼻尖特征點用于驗證單應性矩陣的像素誤差,人臉檢測出的實際鼻子坐標與單應性矩陣計算出的坐標點的誤差。

(6)

(7)

針對人臉轉角計算,實驗以Y軸為中心軸做轉向實驗,在左右偏轉10°、20°、30°以及正視時定格,拍攝7張照片,照片的像素為1280×720。圖4為每偏轉10°拍攝的圖像,圖5為每偏轉20°拍攝的圖像,圖6為每偏轉30°拍攝的圖像,五角星代表根據單應性矩陣計算出的鼻子像素點,點代表級聯卷積神經網絡測試的鼻子特征點,兩點之間存在一定的誤差。表3列出了偏轉10°、20°、30°時單應性矩陣計算出的鼻子像素點和改進后DCNN的鼻子特征點之間的平均像素誤差,誤差率為平均像素誤差占輸入人臉框圖寬度的比例。針對人臉特征點的選擇對偏轉角度的影響,選擇利用眼角和眼珠分別作為特征點帶入單應性矩陣計算人臉偏轉角度,對比偏轉誤差,如表4所示。

圖4 偏轉10°像素誤差圖

圖5 偏轉20°像素誤差圖

圖6 偏轉30°像素誤差圖

表3 像素誤差結果對比

表4 眼珠與眼角偏轉誤差結果對比
結果表明偏轉角度越大,由單應性矩陣計算得出的鼻子像素點與人臉定位得出的鼻子特征點之間的誤差越大。由此可得,在駕駛員偏轉較小的角度時,計算得出的誤差較小,當駕駛員瞬時偏轉較大角度時,根據單應性矩陣求出的偏轉角度可能會存在較大誤差。相比于眼珠作為特征點,眼角作為特征點所得的人臉偏轉角度誤差較小。
4 結論
文中對傳統的級聯深度卷積神經網絡檢測人臉五特征點做出了改進,將原先的三級級聯神經網絡縮減為兩級級聯神經網絡,在縮短訓練時間的同時,略提高了檢測的準確率。將檢測出的特征點運用在單應性矩陣計算人臉偏轉上也取得了較好的成果。基于級聯網絡人臉五特征點的檢測的輸入是已檢測出人臉的圖像,后期可加入人臉框的檢測。若當駕駛員瞬時偏轉的角度過大時,會導致計算的角度偏差較大。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
